Creare ed eseguire le pipeline di Machine Learning con Azure Machine Learning SDK
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Questo articolo illustra come creare ed eseguire pipeline di Machine Learning usando Azure Machine Learning SDK. Usare le pipeline di ML per creare un flusso di lavoro che unisce varie fasi di Machine Learning. Pubblicare quindi la pipeline per operazioni successive di accesso o condivisione con altri utenti. Tenere traccia delle pipeline di ML per verificare le prestazioni del modello in situazioni reali e rilevare la deriva dei dati. Le pipeline di ML sono ideali per scenari di assegnazione dei punteggi in batch, che usano vari ambienti di calcolo, riutilizzano i passaggi invece di ripeterne l'esecuzione e condividono flussi di lavoro di ML con altri utenti.
Questo articolo non è un'esercitazione. Per indicazioni sulla creazione della prima pipeline, vedere Esercitazione: Creare una pipeline di Azure Machine Learning per l'assegnazione di punteggi batch o Usare ML automatizzato nella pipeline di Azure Machine Learning in Python.
Anche se è possibile usare un tipo diverso di pipeline denominato Azure Pipeline per l'automazione CI/CD delle attività di ML, tale tipo di pipeline non viene archiviato nell'area di lavoro. Confrontare queste diverse pipeline.
Le pipeline di ML create sono visibili ai membri dell'area di lavoro di Azure Machine Learning.
Le pipeline di ML vengono eseguite in destinazioni di calcolo (vedere Cosa sono le destinazioni di calcolo in Azure Machine Learning?). Le pipeline possono eseguire operazioni di lettura e scrittura dei dati da e verso le posizioni di Archiviazione di Azure supportate.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Prerequisiti
Un'area di lavoro di Azure Machine Learning. Creare le risorse dell'area di lavoro.
Configurare l'ambiente di sviluppo per installare Azure Machine Learning SDK o usare un'istanza di ambiente di calcolo di Azure Machine Learning con l'SDK già installato.
Per iniziare, collegare l'area di lavoro:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Configurare le risorse di Machine Learning
Creare le risorse necessarie per eseguire una pipeline di ML:
Configurare un archivio dati che verrà usato per accedere ai dati necessari nei passaggi della pipeline.
Configurare un oggetto
Datasetin modo che punti a dati persistenti che si trovano in un archivio dati o che sono accessibili da tale archivio. Configurare un oggettoOutputFileDatasetConfigper i dati temporanei passati tra un passaggio e l'altro della pipeline.Configurare le destinazioni di calcolo in cui verranno eseguiti i passaggi della pipeline.
Configurare un archivio dati
Un archivio dati contiene i dati a cui accede la pipeline. Ogni area di lavoro ha un archivio dati predefinito. È possibile registrare più archivi dati.
Quando si crea l'area di lavoro, File di Azure e Archiviazione BLOB di Azure vengono collegati all'area. Viene registrato un archivio dati predefinito per la connessione ad Archiviazione BLOB di Azure. Per altre informazioni, vedere Decidere quando usare BLOB di Azure, File di Azure o Dischi di Azure.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
I passaggi utilizzano in genere i dati e producono dati di output. Un passaggio può creare dati, ad esempio un modello, una directory con modello e file dipendenti o dati temporanei. Questi dati sono quindi disponibili per altri passaggi successivi nella pipeline. Per altre informazioni sulla connessione della pipeline ai dati, vedere gli articoli Come accedere ai dati e Come registrare i set di dati.
Configurare i dati con gli oggetti Dataset e OutputFileDatasetConfig
Il modo preferito per fornire dati a una pipeline è un oggetto Dataset. L'oggetto Dataset punta ai dati che si trovano in un archivio dati o che sono accessibili da tale archivio oppure da un URL Web. La classe Dataset è astratta, quindi si creerà un'istanza di FileDataset (che fa riferimento a uno o più file) o di TabularDataset creato da uno o più file con colonne di dati delimitate.
Per creare un oggetto Dataset, si usano metodi come from_files o from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
I dati intermedi (o l'output di un passaggio) sono rappresentati da un oggetto OutputFileDatasetConfig. output_data1 viene prodotto come output di un passaggio. Facoltativamente, questi dati possono essere registrati come set di dati chiamando register_on_complete. Se si crea un oggetto OutputFileDatasetConfig in un passaggio e lo si usa come input per un altro passaggio, tale dipendenza dei dati tra i passaggi crea un ordine di esecuzione implicito nella pipeline.
Gli oggetti OutputFileDatasetConfig restituiscono una directory e per impostazione predefinita l'output viene scritto nell'archivio dati predefinito dell'area di lavoro.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Importante
I dati intermedi archiviati con OutputFileDatasetConfig non vengono eliminati automaticamente da Azure.
È consigliabile eliminare i dati intermedi a livello di codice alla fine di un'esecuzione della pipeline, usare un archivio dati con criteri di conservazione dei dati di breve durata o eseguire regolarmente la pulizia manuale.
Suggerimento
Caricare solo i file rilevanti per il processo in questione. Anche se viene specificato il riutilizzo, eventuali modifiche apportate ai file all'interno della directory dei dati verranno considerate motivi per ripetere il passaggio alla successiva esecuzione della pipeline.
Configurare una destinazione di calcolo
In Azure Machine Learning il termine ambiente di calcolo (o destinazione di calcolo) si riferisce ai computer o ai cluster che eseguono i passaggi di calcolo nella pipeline di Machine Learning. Vedere l'articolo sulledestinazioni di calcolo per il training del modello per un elenco completo delle destinazioni di calcolo e Creare destinazioni di calcolo per informazioni su come crearle e collegarle all'area di lavoro. Il processo per la creazione e il collegamento di una destinazione di calcolo è lo stesso indipendentemente dal fatto che si stia eseguendo il training di un modello o un passaggio della pipeline. Dopo aver creato e collegato la destinazione di calcolo, usare l'oggetto ComputeTarget nel passaggio pipeline.
Importante
L'esecuzione di operazioni di gestione su destinazioni di calcolo non è supportata dall'interno di processi remoti. Poiché le pipeline di Machine Learning vengono inviate come processo remoto, non usare le operazioni di gestione in destinazioni di calcolo all'interno della pipeline.
Ambiente di calcolo di Azure Machine Learning
È possibile creare un ambiente di calcolo di Azure Machine Learning per eseguire i passaggi. Il codice per altre destinazioni di calcolo è simile, con parametri leggermente diversi, a seconda del tipo.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Configurare l'ambiente dell'esecuzione del training
Il passaggio successivo consiste nel verificare che per l'esecuzione remota del training siano presenti tutte le dipendenze necessarie per i passaggi di training. Le dipendenze e il contesto di esecuzione vengono impostati creando e configurando un oggetto RunConfiguration.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
Il codice precedente mostra due opzioni per la gestione delle dipendenze. Come illustrato, con USE_CURATED_ENV = True, la configurazione si basa su un ambiente curato. Gli ambienti curati sono "preconfezionati" con librerie interdipendenti comuni e possono essere portati online più rapidamente. Per gli ambienti curati esistono immagini Docker predefinite nel Registro Container Microsoft. Per altre informazioni, vedere Ambienti curati di Azure Machine Learning.
Il percorso seguito se si modifica USE_CURATED_ENV in False mostra il criterio per impostare in modo esplicito le dipendenze. In questo scenario verrà creata e registrata una nuova immagine Docker personalizzata in un Registro Azure Container all'interno del gruppo di risorse. Vedere Introduzione ai registri contenitori Docker privati in Azure. La creazione e la registrazione di questa immagine possono richiedere alcuni minuti.
Creare i passaggi della pipeline
Dopo aver creato la risorsa di calcolo e l'ambiente, è possibile definire i passaggi della pipeline. Molti passaggi predefiniti sono disponibili tramite Azure Machine Learning SDK, come descritto nella documentazione di riferimento per il pacchetto azureml.pipeline.steps. La classe più flessibile è PythonScriptStep, che esegue uno script Python.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Il codice riportato in precedenza illustra un tipico passaggio della pipeline iniziale. Il codice di preparazione dei dati si trova in una sottodirectory (in questo esempio "prepare.py" nella directory "./dataprep.src"). Durante il processo di creazione della pipeline, questa directory viene compressa e caricata in compute_target e il passaggio esegue lo script specificato come valore per script_name.
I valori di arguments specificano gli input e gli output del passaggio. Nell'esempio precedente i dati di base sono il set di dati my_dataset. I dati corrispondenti verranno scaricati nella risorsa di calcolo perché il codice li specifica come as_download(). Lo script prepare.py esegue tutte le attività di trasformazione dei dati appropriate per l'attività e restituisce i dati in output_data1, di tipo OutputFileDatasetConfig. Per altre informazioni, vedere Spostamento di dati in e tra i passaggi della pipeline ML (Python).
Il passaggio verrà eseguito nel computer definito da compute_target, usando la configurazione aml_run_config.
Il riutilizzo dei risultati precedenti (allow_reuse) è fondamentale quando si usano pipeline in un ambiente collaborativo, perché l'eliminazione di riesecuzioni non necessarie offre maggiore agilità. Il riutilizzo è il comportamento predefinito quando script_name, input e parametri di un passaggio rimangono invariati. Quando il riutilizzo è consentito, i risultati dell'esecuzione precedente vengono inviati immediatamente al passaggio successivo. Se allow_reuse è impostato su False, verrà sempre generata una nuova esecuzione per questo passaggio durante l'esecuzione della pipeline.
È possibile creare una pipeline con un singolo passaggio, ma quasi sempre si sceglierà di suddividere l'intero processo in diversi passaggi. Ad esempio, è possibile definire passaggi per la preparazione dei dati, il training, il confronto dei modelli e la distribuzione. Si può, ad esempio, immaginare che dopo il passaggio data_prep_step specificato in precedenza, il passaggio successivo sia il training:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Il codice riportato in precedenza è simile a quello del passaggio di preparazione dei dati. Il codice per il training si trova in una directory diversa rispetto a quella del codice per la preparazione dei dati. L'output OutputFileDatasetConfig del passaggio output_data1 di preparazione dei dati viene usato come input del passaggio del training. Viene creato un nuovo oggetto training_results di OutputFileDatasetConfig che conterrà i risultati per un passaggio di distribuzione o un confronto successivo.
Per altri esempi di codice, vedere gli articoli su come creare una pipeline di ML in due passaggi e come scrivere di nuovo i dati negli archivi dati al completamento dell'esecuzione.
Dopo la definizione dei passaggi, si crea la pipeline usando alcuni o tutti i passaggi definiti.
Nota
Quando si definiscono i passaggi o si crea la pipeline, non viene eseguito alcun caricamento di file o dati in Azure Machine Learning. I file vengono caricati quando si chiama Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Uso di un set di dati
Come input per qualsiasi passaggio della pipeline è possibile usare i set di dati creati da Archiviazione BLOB di Azure, File di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, database SQL di Azure e Database di Azure per PostgreSQL. È possibile scrivere l'output in DataTransferStep o in DatabricksStep. Se si vogliono scrivere dati in un archivio dati specifico, usare OutputFileDatasetConfig.
Importante
L'operazione di riscrittura dei dati di output in un archivio dati usando OutputFileDatasetConfig è supportata solo per gli archivi dati BLOB di Azure, di condivisione file di Azure e ADLS Gen1 e Gen2.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
È quindi possibile recuperare il set di dati nella pipeline usando il dizionario Run.input_datasets.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Vale la pena soffermarsi sulla riga Run.get_context(). Questa funzione recupera un oggetto Run che rappresenta l'esecuzione sperimentale corrente. Nell'esempio precedente viene usato per recuperare un set di dati registrato. Un altro uso comune dell'oggetto Run consiste nel recuperare sia l'esperimento stesso che l'area di lavoro in cui risiede l'esperimento:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Per altri dettagli, incluse soluzioni alternative per passare e accedere ai dati, vedere Spostamento di dati in e tra i passaggi della pipeline ML (Python).
Memorizzazione nella cache e riutilizzo
Per ottimizzare e personalizzare il comportamento delle pipeline, è possibile eseguire alcune operazioni per la memorizzazione nella cache e il riutilizzo. Puoi ad esempio scegliere di:
- Disattivare il riutilizzo predefinito dell'output dell'esecuzione del passaggio impostando
allow_reuse=Falsedurante la definizione del passaggio. Il riutilizzo è fondamentale quando si usano pipeline in un ambiente collaborativo, perché l'eliminazione di riesecuzioni non necessarie offre maggiore agilità. Tuttavia, è possibile rifiutare esplicitamente il riutilizzo. - Forzare la rigenerazione dell'output per tutti i passaggi di un'esecuzione con
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
Per impostazione predefinita, allow_reuse è abilitato per i passaggi e l'oggetto source_directory specificato nella definizione del passaggio viene sottoposto a hashing. Pertanto, se lo script per un determinato passaggio rimane invariato (script_name, input e parametri) e non vengono apportate altre modifiche a source_directory, viene riutilizzato l'output di un'esecuzione precedente, il processo non viene inviato all'ambiente di calcolo e i risultati dell'esecuzione precedente sono immediatamente disponibili per il passaggio successivo.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Nota
Se i nomi degli input di dati cambiano, il passaggio verrà rieseguito, anche se i dati sottostanti non cambiano. È necessario impostare in modo esplicito il campo name dei dati di input (data.as_input(name=...)). Se non si imposta in modo esplicito questo valore, il campo name verrà impostato su un GUID casuale e i risultati del passaggio non verranno riutilizzati.
Inviare la pipeline
Quando si invia la pipeline, Azure Machine Learning controlla le dipendenze per ogni passaggio e carica uno snapshot della directory di origine specificata. Se la directory di origine non è specificata, viene caricata la directory locale corrente. Lo snapshot viene inoltre archiviato come parte dell'esperimento nell'area di lavoro.
Importante
Per evitare che i file non necessari vengano inclusi nello snapshot, impostare un file ignore (.gitignore o .amlignore) nella directory. Aggiungere i file e le directory da escludere. Per altre informazioni sulla sintassi da utilizzare in questo file, vedere sintassi e criteri per .gitignore. Il file .amlignore utilizza la stessa sintassi. Se sono presenti entrambi i file, viene usato il file .amlignore, mentre quello .gitignore non viene usato.
Per altre informazioni, vedere Snapshot.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
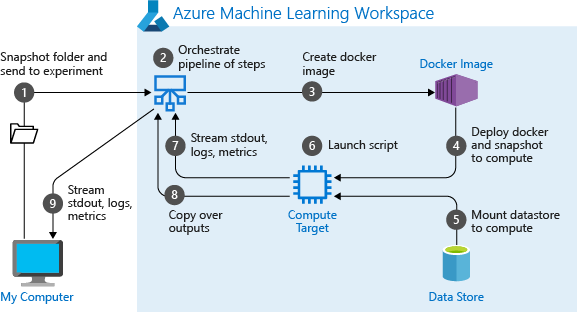
Quando si esegue una pipeline per la prima volta, Azure Machine Learning:
Scarica lo snapshot del progetto nella destinazione di calcolo dalla risorsa di archiviazione BLOB associata all'area di lavoro.
Crea un'immagine Docker corrispondente a ogni passaggio nella pipeline.
Scarica l'immagine Docker per ogni passaggio nella destinazione di calcolo dal registro contenitori.
Configura l'accesso agli oggetti
DataseteOutputFileDatasetConfig. Per la modalità di accessoas_mount(), si usa FUSE per fornire l'accesso virtuale. Se il montaggio non è supportato o se l'utente ha specificato l'accesso comeas_upload(), i dati verranno invece copiati nella destinazione di calcolo.Esegue il passaggio nella destinazione di calcolo specificata nella definizione del passaggio.
Crea gli artefatti, ad esempio i log, stdout e stderr, le metriche e l'output specificati dal passaggio. Questi artefatti vengono quindi caricati e conservati nell'archivio dati predefinito dell'utente.
Per altre informazioni, vedere le informazioni di riferimento sulla classe Experiment.
Usare i parametri della pipeline per gli argomenti che cambiano in fase di inferenza
In alcuni casi, gli argomenti di singoli passaggi all'interno di una pipeline sono correlati al periodo di sviluppo e di training, ad esempio momentum e velocità del training, oppure percorsi di dati o file di configurazione. Quando si distribuisce un modello, tuttavia, è consigliabile passare dinamicamente gli argomenti su cui esegue l'inferenza (ovvero la query creata per consentire la risposta del modello). È consigliabile impostare questi come tipi di parametri della pipeline degli argomenti. A tale scopo in Python, usare la classe azureml.pipeline.core.PipelineParameter, come illustrato nel frammento di codice seguente:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Funzionamento degli ambienti Python con i parametri della pipeline
Come illustrato in precedenza in Configurare l'ambiente dell'esecuzione del training, per specificare lo stato dell'ambiente e le dipendenze della libreria Python si usa un oggetto Environment. In genere, è possibile specificare un oggetto Environment esistente facendo riferimento al relativo nome e, facoltativamente, a una versione:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Tuttavia, se si sceglie di usare oggetti PipelineParameter per impostare in modo dinamico le variabili in fase di esecuzione per i passaggi della pipeline, non è possibile usare questa tecnica per fare riferimento a un oggetto Environment esistente. Se invece si vogliono usare oggetti PipelineParameter, è necessario impostare il campo environment dell'oggetto RunConfiguration su un oggetto Environment. È responsabilità dell'utente verificare la corretta impostazione delle dipendenze di tale oggetto Environment da pacchetti Python esterni.
Visualizzare i risultati di una pipeline
Visualizzare l'elenco di tutte le pipeline e i relativi dettagli di esecuzione in Studio:
Accedere ad Azure Machine Learning Studio.
A sinistra selezionare Pipeline per visualizzare tutte le esecuzioni della pipeline.
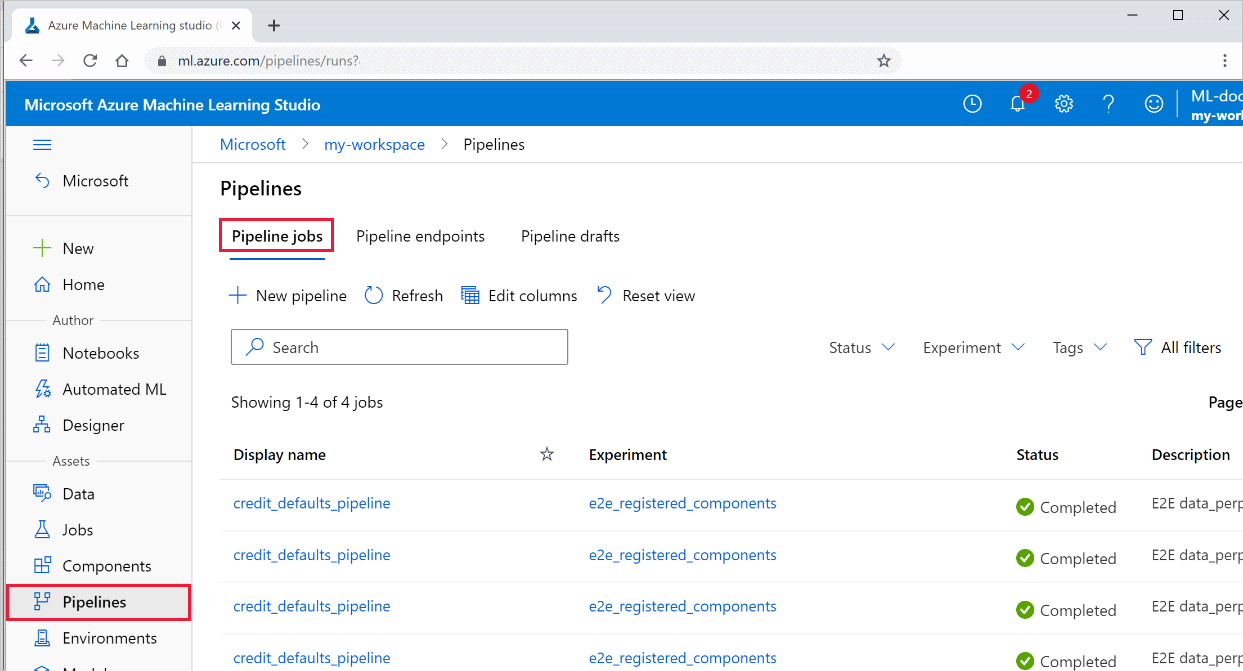
Selezionare una pipeline specifica per visualizzare i risultati dell'esecuzione.
Rilevamento e integrazione di Git
Quando si avvia un'esecuzione di training in cui la directory di origine è un repository Git locale, le informazioni sul repository vengono archiviate nella cronologia di esecuzione. Per altre informazioni, vedere Integrazione di Git con Azure Machine Learning.
Passaggi successivi
- Per condividere la pipeline con colleghi o clienti, vedere Pubblicare pipeline di Machine Learning.
- Usare questi notebook di Jupyter in GitHub per esplorare più in dettaglio le pipeline di Machine Learning.
- Vedere la guida di riferimento dell'SDK per i pacchetti azureml-pipeline-core e azureml-pipelines-steps.
- Vedere le procedure per suggerimenti sul debug e la risoluzione dei problemi delle pipeline.
- Per informazioni su come eseguire i notebook, vedere l'articolo Esplorare Azure Machine Learning con notebook Jupyter.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per