Risoluzione dei problemi delle pipeline di Machine Learning
SI APPLICA A:  Python SDK azureml v1
Python SDK azureml v1
Questo articolo spiega come eseguire la risoluzione dei problemi quando si verificano errori durante l'esecuzione di una pipeline di Machine Learning in Azure Machine Learning SDK e nella finestra di progettazione di Azure Machine Learning.
Suggerimenti per la risoluzione dei problemi
La tabella seguente contiene problemi comuni durante lo sviluppo della pipeline, con potenziali soluzioni.
| Problema | Possibile soluzione |
|---|---|
Non è possibile passare i dati alla directory PipelineData |
Assicurarsi di aver creato una directory nello script che corrisponde alla posizione in cui la pipeline prevede i dati di output del passaggio. Nella maggior parte dei casi, un argomento di input definisce la directory di output, quindi la directory verrà creata in modo esplicito. Usare os.makedirs(args.output_dir, exist_ok=True) per creare la directory di output. Vedere l'esercitazione per un esempio di script del punteggio che mostra questo schema progettuale. |
| Bug della dipendenza | Se vengono visualizzati errori della dipendenza nella pipeline remota che non si sono verificati durante il test in locale, verificare che le dipendenze e le versioni dell'ambiente remoto corrispondano a quelle presenti nell'ambiente di test. (Vedere Compilazione, memorizzazione nella cache e riutilizzo dell'ambiente |
| Errori ambigui con le destinazioni di calcolo | Provare a eliminare e a creare nuovamente le destinazioni di calcolo. La ricreazione delle destinazioni di calcolo è rapida e può risolvere alcuni problemi temporanei. |
| La pipeline non riutilizza i passaggi | Il riutilizzo dei passaggi è abilitato per impostazione predefinita. Assicurarsi tuttavia che non sia stato disabilitato in un passaggio della pipeline. Se il riutilizzo è disabilitato, il parametro allow_reuse nel passaggio viene impostato su False. |
| La pipeline viene rieseguita inutilmente | Per assicurarsi che i passaggi siano eseguiti di nuovo solo quando i dati o gli script sottostanti cambiano, separare le directory del codice sorgente per ogni passaggio. Se si usa la stessa directory di origine per più passaggi, è possibile che si verifichino riesecuzioni non necessarie. Usare il parametro source_directory in un oggetto passaggio della pipeline per puntare alla directory isolata per tale passaggio e assicurarsi di non usare lo stesso percorso source_directory per più passaggi. |
| Rallentamento delle istruzioni su epoche di training o altri comportamenti di ciclo | Provare a cambiare qualsiasi scrittura di file, inclusa la registrazione, da as_mount() a as_upload(). La modalità di montaggio usa un file system virtualizzato remoto e carica l'intero file ogni volta che viene aggiunto. |
| L'avvio della destinazione di calcolo richiede molto tempo | Le immagini Docker per le destinazioni di calcolo vengono caricate da Registro Azure Container (ACR). Per impostazione predefinita, Azure Machine Learning crea un ACR che usa il livello di servizio Basic. La modifica di ACR per l'area di lavoro al livello Standard o Premium può ridurre il tempo necessario per compilare e caricare le immagini. Per altre informazioni, vedere Livelli di servizio di Registro Azure Container. |
Errori di autenticazione
Se si esegue un'operazione di gestione in una destinazione di calcolo da un processo remoto, si riceve uno degli errori seguenti:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Ad esempio, si riceve un errore se si prova a creare o collegare una destinazione di calcolo da una pipeline di Machine Learning che viene inviata per l'esecuzione remota.
Risoluzione dei problemi ParallelRunStep
Lo script per ParallelRunStepdeve contenere due funzioni:
init(): usare questa funzione per qualsiasi preparazione dispendiosa o comune per un'inferenza successiva. Usarla ad esempio per caricare il modello in un oggetto globale. Questa funzione viene chiamata solo una volta all'inizio del processo.run(mini_batch): la funzione viene eseguita per ogni istanza dimini_batch.mini_batch:ParallelRunSteprichiama il metodo run e passa un elenco o un PandasDataFramecome argomento al metodo. Ogni voce in mini_batch è un percorso file se l'input è un oggettoFileDatasetoppure unDataFramePandas se l'input è un oggettoTabularDataset.response: il metodo run() deve restituire unDataFramePandas o una matrice. Per append_row output_action, questi elementi restituiti vengono accodati nel file di output comune. Per summary_only, il contenuto degli elementi viene ignorato. Per tutte le azioni di output, ogni elemento di output restituito indica un'esecuzione riuscita dell'elemento di input nel mini-batch di input. Verificare che nel risultato dell'esecuzione siano inclusi dati sufficienti per eseguire il mapping dell'input al risultato dell'output dell'esecuzione. L'output dell'esecuzione viene scritto nel file di output ma non sarà necessariamente in ordine, quindi sarà necessario usare una chiave nell'output per eseguirne il mapping all'input.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Se è presente un altro file o un'altra cartella nella stessa directory dello script di inferenza, è possibile farvi riferimento individuando la directory di lavoro corrente.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parametri per ParallelRunConfig
ParallelRunConfig è la configurazione principale per l'istanza di ParallelRunStep all'interno della pipeline di Azure Machine Learning. Si usa per eseguire il wrapping dello script e configurare i parametri necessari, incluse tutte le voci seguenti:
entry_script: script utente come percorso di file locale che viene eseguito in parallelo su più nodi. Sesource_directoryè presente, usare un percorso relativo. In caso contrario, usare qualsiasi percorso accessibile nel computer.mini_batch_size: dimensioni del mini-batch passato a una singola chiamata dirun(). (Facoltativo; il valore predefinito è10file perFileDatasete1MBperTabularDataset.)- Per
FileDataset, è il numero di file con un valore minimo di1. È possibile combinare più file in un solo mini-batch. - Per
TabularDataset, sono le dimensioni dei dati. Valori di esempio sono1024,1024KB,10MBe1GB. Il valore consigliato è1MB. Il mini-batch diTabularDatasetnon supererà mai i limiti dei file. Supponiamo ad esempio di avere una serie di file CSV di varie dimensioni, comprese tra 100 KB e 10 MB. Se si impostamini_batch_size = 1MB, i file di dimensioni inferiori a 1 MB vengono considerati come un mini-batch. I file di dimensioni maggiori di 1 MB vengono suddivisi in più mini-batch.
- Per
error_threshold: numero di errori di record perTabularDatasete di errori di file perFileDatasetche devono essere ignorati durante l'elaborazione. Se il numero di errori per l'intero input supera questo valore, il processo viene interrotto. La soglia di errore è per l'intero input e non per il singolo mini-batch inviato al metodorun(). L'intervallo è[-1, int.max]. La parte-1indica di ignorare tutti gli errori durante l'elaborazione.output_action: uno dei valori seguenti indica come viene organizzato l'output:summary_only: l'output viene archiviato dallo script utente.ParallelRunStepusa l'output solo per il calcolo della soglia di errore.append_row: per tutti gli input, nella cartella di output viene creato un solo file in cui accodare tutti gli output separati per riga.
append_row_file_name: per personalizzare il nome del file di output per append_row output_action (facoltativo; il valore predefinito èparallel_run_step.txt).source_directory: percorsi delle cartelle che contengono tutti i file da eseguire nella destinazione di calcolo (facoltativo).compute_target: è supportato soloAmlCompute.node_count: numero di nodi di calcolo da usare per l'esecuzione dello script utente.process_count_per_node: numero di processi per nodo. È consigliabile impostare questo valore sul numero di GPU o CPU di un nodo (facoltativo; il valore predefinito è1).environment: definizione dell'ambiente Python. È possibile configurarlo per usare un ambiente Python esistente o per configurare un ambiente temporaneo. La definizione è anche responsabile dell'impostazione delle dipendenze dell'applicazione necessarie (facoltativo).logging_level: livello di dettaglio del log. I valori in ordine crescente di livello di dettaglio sono:WARNING,INFOeDEBUG. (Facoltativo. Il valore predefinito èINFO)run_invocation_timeout: timeout della chiamata del metodorun()in secondi. (Facoltativo. Il valore predefinito è60)run_max_try: il numero massimo di tentativi dirun()per un mini-batch. Unarun()viene considerata non riuscita se viene generata un'eccezione o se non viene restituito nulla quando viene raggiuntorun_invocation_timeout(facoltativo; il valore predefinito è3).
È possibile specificare mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout e run_max_try come PipelineParameter in modo che, quando si ripete l'esecuzione della pipeline, sia possibile ottimizzare i valori dei parametri. In questo esempio si usa PipelineParameter per mini_batch_size e Process_count_per_node e questi valori vengono cambiati quando si ripete l'esecuzione in un secondo momento.
Parametri per la creazione di ParallelRunStep
Creare ParallelRunStep usando lo script, la configurazione dell'ambiente e i parametri. Specificare la destinazione di calcolo già collegata all'area di lavoro come destinazione di esecuzione dello script di inferenza. Usare ParallelRunStep per creare il passaggio della pipeline di inferenza batch, che accetta tutti i parametri seguenti:
name: nome del passaggio, con le restrizioni di denominazione seguenti: univoco, 3-32 caratteri ed espressione regolare ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: oggettoParallelRunConfig, come definito in precedenza.inputs: uno o più set di dati di Azure Machine Learning di tipo singolo da partizionare per l'elaborazione parallela.side_inputs: uno o più set di dati o dati di riferimento usati come input secondari senza necessità di partizionamento.output: oggettoOutputFileDatasetConfigche corrisponde alla directory di output.arguments: elenco di argomenti passati allo script utente. Usare unknown_args per recuperarli nello script di immissione (facoltativo).allow_reuse: indica se il passaggio deve riutilizzare i risultati precedenti quando viene eseguito con le stesse impostazioni o gli stessi input. Se il parametro èFalse, durante l'esecuzione della pipeline viene sempre generata una nuova esecuzione per questo passaggio. (Facoltativo. Il valore predefinito èTrue).
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Tecniche di debug
Per il debug delle pipeline esistono tre tecniche principali:
- Eseguire il debug di singoli passaggi della pipeline nel computer locale
- Usare la registrazione e Application Insights per isolare e diagnosticare l'origine del problema
- Collegare un debugger remoto a una pipeline in esecuzione in Azure
Eseguire il debug degli script in locale
Uno degli errori più comuni riscontrati in una pipeline è che lo script di dominio non viene eseguito come previsto o contiene errori di runtime nel contesto dell'ambiente di calcolo remoto di cui è difficile eseguire il debug.
Le pipeline stesse non possono essere eseguite in locale. Ma l'esecuzione degli script in isolamento nel computer locale consente di eseguire il debug più velocemente perché non è necessario attendere il processo di calcolo e di creazione dell'ambiente. A questo scopo, è necessario eseguire alcune operazioni di sviluppo:
- Se i dati si trovano in un archivio dati cloud, è necessario scaricare i dati e renderli disponibili per lo script. Per ridurre il runtime e ottenere rapidamente commenti e suggerimenti sul comportamento dello script, è consigliabile usare un piccolo campione dei dati
- Se si prova a simulare un passaggio intermedio della pipeline, potrebbe essere necessario creare manualmente i tipi di oggetto che lo script specifico prevede di ottenere dal passaggio precedente
- È necessario definire il proprio ambiente e replicare le dipendenze definite nell'ambiente di calcolo remoto
Dopo aver configurato uno script per l'esecuzione nell'ambiente locale, è più semplice eseguire attività di debug quali:
- Collegamento di una configurazione di debug personalizzata
- Sospensione dell'esecuzione e controllo dello stato dell'oggetto
- Rilevamento di errori logici o di tipo che non verranno esposti fino al runtime
Suggerimento
Dopo aver verificato che lo script sia in esecuzione come previsto, un passaggio successivo valido consiste nell'eseguire lo script in una pipeline con un solo passaggio prima di provare a eseguirlo in una pipeline con più passaggi.
Eseguire operazioni di configurazione, scrittura e verifica sui log della pipeline
I test degli script in locale sono un ottimo modo per eseguire il debug di frammenti di codice principali e logica complessa prima di iniziare a creare una pipeline. A un certo punto è necessario eseguire il debug degli script durante l'esecuzione effettiva della pipeline, soprattutto durante la diagnosi del comportamento che si verifica durante l'interazione tra i passaggi della pipeline. È consigliabile usare in modo diffuso le istruzioni print() negli script di passaggio in modo da poter visualizzare lo stato dell'oggetto e i valori previsti durante l'esecuzione remota, in modo analogo a quando si esegue il debug del codice JavaScript.
Opzioni e comportamenti di registrazione
La tabella seguente fornisce informazioni sulle diverse opzioni di debug per le pipeline. Non è un elenco completo, perché esistono altre opzioni oltre a quelle di Azure Machine Learning e Python illustrate qui.
| Libreria | Type | Esempio | Destination | Risorse |
|---|---|---|---|---|
| Azure Machine Learning SDK | Metrica | run.log(name, val) |
Interfaccia utente del portale di Azure Machine Learning | Come tenere traccia degli esperimenti Classe azureml.core.Run |
| Stampa/registrazione Python | Log | print(val)logging.info(message) |
Log del driver, finestra di progettazione di Azure Machine Learning | Come tenere traccia degli esperimenti Registrazione Python |
Esempio di opzioni di registrazione
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Finestra di progettazione di Azure Machine Learning
Per le pipeline create nella finestra di progettazione, è possibile trovare il file 70_driver_log nella pagina di creazione o nella pagina dei dettagli dell'esecuzione della pipeline.
Abilitare la registrazione per gli endpoint in tempo reale
Per risolvere i problemi ed eseguire il debug degli endpoint in tempo reale nella finestra di progettazione, è necessario abilitare la registrazione di Application Insights tramite l'SDK. La registrazione consente di risolvere i problemi di distribuzione modello e utilizzo e di eseguire il debug. Per altre informazioni, vedere Registrazione per i modelli distribuiti.
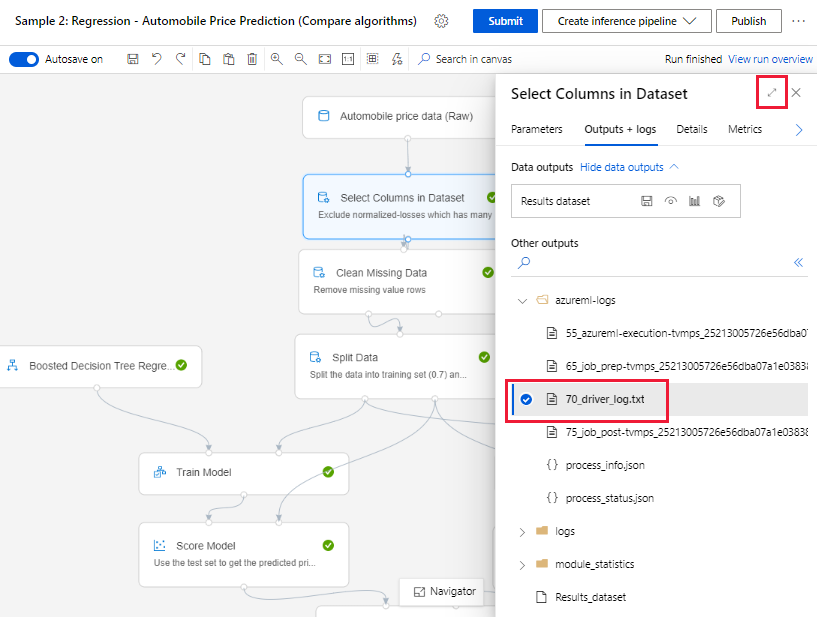
Ottenere i log dalla pagina di creazione
Quando si invia un'esecuzione della pipeline e si rimane nella pagina di creazione, è possibile trovare i file di log generati per ogni componente al termine dell'esecuzione dei singoli componenti.
Selezionare un componente di cui è terminata l'esecuzione nell'area del contenuto.
Nel riquadro di destra del componente passare alla scheda Output e log.
Espandere il riquadro di destra e selezionare il file 70_driver_log.txt per visualizzarlo nel browser. È anche possibile scaricare i log in locale.
Ottenere i log dalle esecuzioni della pipeline
I file di log per esecuzioni specifiche sono disponibili anche nella pagina dei dettagli di esecuzione della pipeline, visualizzata nella sezione Pipeline o Esperimenti di Studio.
Selezionare un'esecuzione della pipeline creata nella finestra di progettazione.
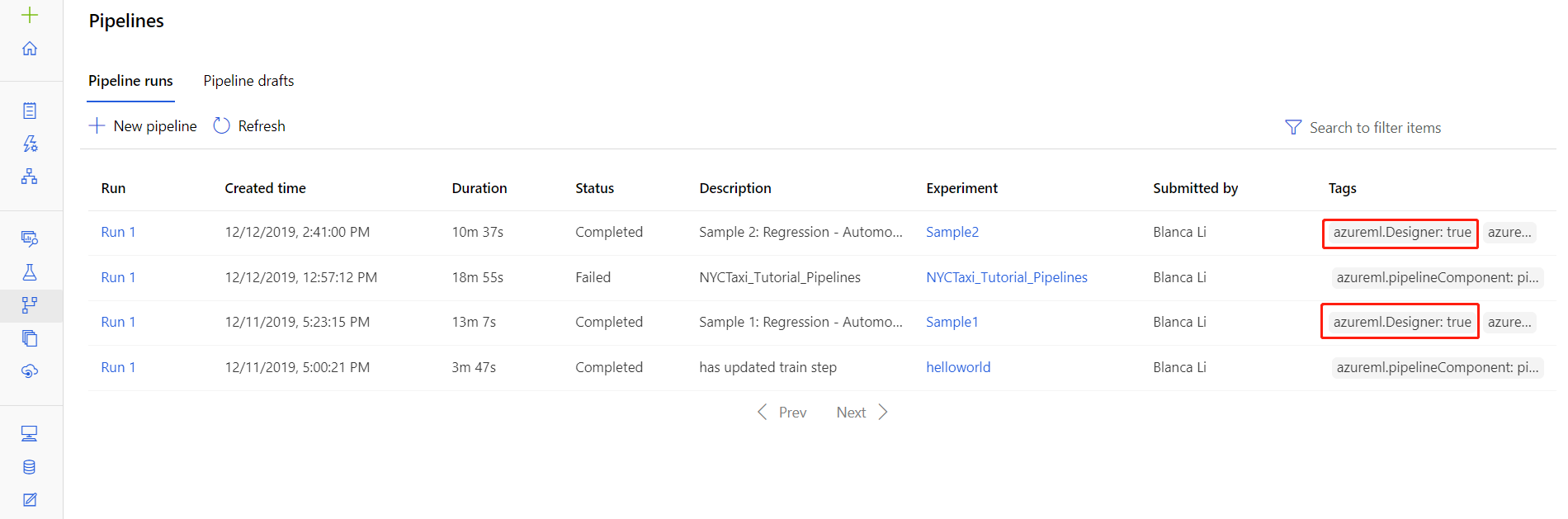
Selezionare un componente nel riquadro di anteprima.
Nel riquadro di destra del componente passare alla scheda Output e log.
Espandere il riquadro a destra per visualizzare il file std_log.txt nel browser oppure selezionare il file per scaricare i log in locale.
Importante
Per aggiornare una pipeline dalla pagina dei dettagli dell'esecuzione della pipeline, è necessario clonare l'esecuzione della pipeline in una nuova bozza di pipeline. Un'esecuzione della pipeline è uno snapshot della pipeline. È simile a un file di log e non è modificabile.
Debug interattivo con Visual Studio Code
In alcuni casi, potrebbe essere necessario eseguire il debug interattivo del codice Python contenuto nella pipeline di ML. Usando Visual Studio Code (VS Code) e debugpy, è possibile collegarsi al codice durante l'esecuzione nell'ambiente di training. Per altre informazioni, vedere il debug interattivo nella guida di VS Code.
HyperdriveStep e AutoMLStep hanno esito negativo con l'isolamento rete
Dopo aver usato HyperdriveStep e AutoMLStep, quando si tenta di registrare il modello potrebbe essere visualizzato un errore.
Si sta usando l'SDK Azure Machine Learning v1.
L'area di lavoro di Azure Machine Learning è configurata per l'isolamento della rete (VNet).
La pipeline tenta di registrare il modello generato dal passaggio precedente. Nell'esempio seguente, ad esempio, il parametro
inputsè il saved_model da un hyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Soluzione alternativa
Importante
Questo comportamento non si verifica quando si usa Azure Machine Learning SDK v2.
Per risolvere questo errore, usare la classe Esegui per creare il modello da HyperdriveStep o AutoMLStep. Di seguito è riportato uno script di esempio che ottiene il modello di output da un hyperdriveStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Il file può quindi essere usato da pythonScriptStep:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Passaggi successivi
Per un'esercitazione completa sull'uso di
ParallelRunStep, vedere Esercitazione: Creare una pipeline di Azure Machine Learning per l'assegnazione di punteggi batch.Per un esempio completo che illustra Machine Learning automatizzato in pipeline di Machine Learning, vedere Usare ML automatizzato nella pipeline di Azure Machine Learning in Python.
Leggere la guida di riferimento dell'SDK per informazioni sui pacchetti azureml-pipeline-core e azureml-pipelines-steps.
Vedere l'elenco di eccezioni e codici di errore per la finestra di progettazione.