Distribuire modelli di Machine Learning in Azure
APPLICABILE A: estensione ML dell'interfaccia della riga di comando (CLI) di Azure v1azureml Python SDKv1
estensione ML dell'interfaccia della riga di comando (CLI) di Azure v1azureml Python SDKv1
Informazioni su come distribuire il modello di Machine Learning o Deep Learning come servizio Web nel cloud di Azure.
Nota
Gli endpoint di Azure Machine Learning (v2) offrono un'esperienza di distribuzione più semplice e ottimizzata. Gli endpoint supportano scenari di inferenza batch e in tempo reale. Gli endpoint forniscono un'unica interfaccia per richiamare e gestire le distribuzioni di modelli tra i tipi di calcolo. Consultare Che cosa sono gli endpoint di Azure Machine Learning?.
Flusso di lavoro per la distribuzione di un modello
Il flusso di lavoro è simile indipendentemente dal punto in cui si distribuisce il modello:
- Registrare il modello.
- Preparare uno script di immissione.
- Preparare una configurazione di inferenza.
- Distribuire il modello in locale per assicurarsi che tutto funzioni correttamente.
- Scegliere una destinazione di calcolo.
- Distribuire il modello nel cloud.
- Testare il servizio Web risultante.
Per ulteriori informazioni sui concetti relativi al flusso di lavoro di distribuzione di Machine Learning, consultare Gestire e distribuire modelli con il servizio Azure Machine Learning.
Prerequisiti
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Importante
Alcuni comandi dell'interfaccia della riga di comando (CLI) di Azure in questo articolo usano l'estensione azure-cli-ml, o v1, per Azure Machine Learning. L'assistenza per l'estensione v1 terminerà il 30 settembre 2025. Sarà possibile installare e usare l'estensione v1 fino a tale data.
Consigliamo di passare all'estensione ml, o v2, prima del 30 settembre 2025. Per ulteriori informazioni sull'estensione v2, consultare Estensione dell'interfaccia della riga di comando (CLI) di Azure Machine Learning e Python SDK v2.
- Un'area di lavoro di Azure Machine Learning. Per ulteriori informazioni, consultare Creare risorse dell'area di lavoro.
- Un modello. Gli esempi in questo articolo usano un modello con training preliminare.
- Un computer in grado di eseguire Docker, come un'istanza di calcolo.
Connettersi all'area di lavoro
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Per visualizzare le aree di lavoro a cui si ha accesso, usare i seguenti comandi:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Registrare il modello
Una situazione comune per un servizio di Machine Learning distribuito è che siano necessari i componenti seguenti:
- Risorse che rappresentano il modello specifico da distribuire (ad esempio, un file di modello pytorch).
- Codice che verrà eseguito nel servizio che esegue il modello in un determinato input.
Azure Machine Learnings consente di separare la distribuzione in due componenti separati, in modo da poter mantenere lo stesso codice, aggiornando semplicemente il modello. Viene definito il meccanismo con cui si carica un modello separatamente dal codice come "registrazione del modello".
Quando si registra un modello, il modello viene caricato nel cloud (nell'account di archiviazione predefinito dell'area di lavoro) e quindi montato nello stesso ambiente di calcolo in cui è in esecuzione il servizio Web.
I seguenti esempi illustrano come registrare un modello.
Importante
È consigliabile usare solo i modelli creati o ottenuti da un'origine attendibile. I modelli serializzati andranno trattati come codice, perché sono state individuate vulnerabilità di sicurezza in numerosi formati più diffusi. Inoltre, è possibile che venga intenzionalmente eseguito il training dei modelli con finalità dannose, per fornire un output errato o non accurato.
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
I seguenti comandi scaricano un modello per poi registrarlo nell'area di lavoro di Azure Machine Learning:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Impostare -p sul percorso di una cartella o di un file da registrare.
Per ulteriori informazioni su az ml model register, consultare la documentazione di riferimento.
Registrare un modello da un processo di training di Azure Machine Learning
Se si necessita di registrare un modello creato in precedenza tramite un processo di training di Azure Machine Learning, è possibile specificare l'esperimento, l'esecuzione e il percorso del modello:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
Il parametro --asset-path fa riferimento alla posizione cloud del modello. In questo esempio viene usato il percorso di un singolo file. Per includere più file nella registrazione del modello, impostare --asset-path sul percorso di una cartella contenente i file.
Per ulteriori informazioni su az ml model register, consultare la documentazione di riferimento.
Nota
È anche possibile registrare un modello da un file locale tramite il portale dell'interfaccia utente dell'area di lavoro.
Attualmente, nell'interfaccia utente sono disponibili due opzioni per caricare un file di modello locale:
- Da file locali, la quale registrerà un modello v2.
- Da file locali (basati su framework), la quale registrerà un modello v1.
Notare che solo i modelli registrati tramite l'ingresso Da file locali (basati su framework) (noti come modelli v1) possono essere distribuiti come servizi Web usando SDKv1/CLIv1.
Definire uno script di immissione fittizio
Lo script di avvio riceve i dati inviati a un servizio Web distribuito e li passa al modello. Restituisce quindi la risposta del modello al client. Lo script è specifico al modello. Lo script di immissione deve riconoscere i dati previsti e restituiti dal modello.
Le due operazioni da eseguire nello script di immissione sono le seguenti:
- Caricamento del modello (usando una funzione denominata
init()) - Esecuzione del modello sui dati di input (usando una funzione denominata
run())
Per la distribuzione iniziale, usare uno script di immissione fittizio che stampa i dati ricevuti.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Salvare il file come echo_score.py all'interno di una directory denominata source_dir. Questo script fittizio restituisce i dati inviati, quindi non fa uso del modello. Tuttavia, è utile per testare che lo script di assegnazione dei punteggi sia in esecuzione.
Definire una configurazione di inferenza
Una configurazione di inferenza descrive il contenitore e i file Docker da usare durante l'inizializzazione del servizio Web. Tutti i file all'interno della directory di origine, incluse le sottodirectory, verranno compressi e caricati nel cloud durante le distribuzione del servizio Web.
La seguente configurazione di inferenza specifica che la distribuzione di Machine Learning userà il file echo_score.py nella directory ./source_dir per elaborare le richieste in ingresso e che userà l'immagine Docker con i pacchetti Python specificati nell'ambiente project_environment.
È possibile usare qualsiasi ambiente di inferenza di Azure Machine Learning curato come immagine Docker di base durante la creazione dell'ambiente di progetto. Le dipendenze necessarie verranno installate nella parte superiore e l'immagine Docker risultante verrà archiviata nel repository associato all'area di lavoro.
Nota
Il caricamento della directory di origine dell'inferenza di Azure Machine Learning non rispetta .gitignore o .amlignore
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Una configurazione di inferenza minima può essere scritta come segue:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Salvare il file con il nome dummyinferenceconfig.json.
Per una descrizione più approfondita delle configurazioni di inferenza, vedere questo articolo.
Definire una configurazione di distribuzione
Una configurazione di distribuzione specifica la quantità di memoria e core necessari per l'esecuzione del servizio Web. Inoltre, fornisce i dettagli di configurazione del servizio Web sottostante. Ad esempio, una configurazione di distribuzione consente di specificare che il servizio necessita di 2 gigabyte di memoria, 2 core CPU, 1 core GPU, e che si desidera abilitare la scalabilità automatica.
Le opzioni disponibili per una configurazione di distribuzione variano a seconda della destinazione di calcolo scelta. In una distribuzione locale, è possibile specificare solo la porta in cui verrà gestito il servizio Web.
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Le voci del documento deploymentconfig.json vengono associate ai parametri di LocalWebservice.deploy_configuration. La tabella seguente descrive il mapping tra le entità nel documento JSON e i parametri per il metodo:
| Entità JSON | Parametro per il metodo | Descrizione |
|---|---|---|
computeType |
N/D | La destinazione di calcolo. Per le destinazioni locali, il valore deve essere local. |
port |
port |
La porta locale su cui esporre l'endpoint HTTP del servizio. |
Il codice JSON seguente è un esempio di configurazione della distribuzione da usare con l'interfaccia della riga di comando:
{
"computeType": "local",
"port": 32267
}
Salvare il codice JSON come file denominato deploymentconfig.json.
Per ulteriori informazioni, consultare lo schema di distribuzione.
Distribuire il modello di Machine Learning
È ora possibile distribuire il modello.
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Sostituire bidaf_onnx:1 con il nome del modello e il relativo numero di versione.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Chiamare il modello
Verificare che il modello echo sia stato distribuito correttamente. Dovrebbe essere possibile eseguire una semplice richiesta di attività, nonché una richiesta di assegnazione dei punteggi:
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Definire uno script di immissione
È ora possibile caricare il modello. Prima di tutto, modificare lo script di immissione:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Salvare il file come score.py all'interno di source_dir.
Notare l'uso della AZUREML_MODEL_DIR variabile di ambiente per individuare il modello registrato. Ora che sono stati aggiunto alcuni pacchetti pip.
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Salvare il file con nome inferenceconfig.json
Effettuare nuovamente la distribuzione e chiamare il servizio
Effettuare nuovamente la distribuzione del servizio:
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Sostituire bidaf_onnx:1 con il nome del modello e il relativo numero di versione.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Assicurarsi quindi di poter inviare una richiesta di invio al servizio:
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Scegliere una destinazione di calcolo
La destinazione di calcolo usata per ospitare il modello influirà sul costo e sulla disponibilità dell'endpoint distribuito. Usare questa tabella per scegliere una destinazione di calcolo appropriata.
| Destinazione del calcolo | Utilizzo | Supporto GPU | Descrizione |
|---|---|---|---|
| Servizio Web locale | Test/debug | Usare per attività limitate di test e risoluzione dei problemi. L'accelerazione hardware dipende dall'uso di librerie nel sistema locale. | |
| Azure Machine Learning Kubernetes | Inferenza in tempo reale | Sì | Eseguire carichi di lavoro di inferenza nel cloud. |
| Istanze di Azure Container | Inferenza in tempo reale Consigliato solo a scopo di sviluppo/test. |
Usare per carichi di lavoro basati su CPU su scala ridotta che richiedono meno di 48 GB di RAM. Non richiede la gestione di un cluster. Adatto solo per i modelli di dimensioni inferiori a 1 GB. Supportato nella finestra di progettazione. |
Nota
Per la scelta dello SKU di un cluster, aumentare prima le risorse dei sistemi esistenti e poi il numero di sistemi. Iniziare con un computer dotato del 150% della RAM richiesta dal modello, profilare il risultato e trovare un computer con le prestazioni necessarie. Dopo aver appreso questo, aumentare il numero di computer in base all'esigenza di inferenza simultanea.
Nota
Gli endpoint di Azure Machine Learning (v2) offrono un'esperienza di distribuzione più semplice e ottimizzata. Gli endpoint supportano scenari di inferenza batch e in tempo reale. Gli endpoint forniscono un'unica interfaccia per richiamare e gestire le distribuzioni di modelli tra i tipi di calcolo. Consultare Che cosa sono gli endpoint di Azure Machine Learning?.
Distribuire nel cloud
Dopo aver confermato il funzionamento del servizio in locale e aver scelto una destinazione di calcolo remota, si è pronti per la distribuzione nel cloud.
Modificare la configurazione di distribuzione in modo che corrisponda alla destinazione di calcolo scelta, in questo caso Istanze di Azure Container:
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Le opzioni disponibili per una configurazione di distribuzione variano a seconda della destinazione di calcolo scelta.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Salvare il file come re-deploymentconfig.json.
Per ulteriori informazioni, consultare questa guida di riferimento.
Effettuare nuovamente la distribuzione del servizio:
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
Sostituire bidaf_onnx:1 con il nome del modello e il relativo numero di versione.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Per visualizzare i log del servizio, usare il comando seguente:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Chiamare il servizio Web remoto
Quando si distribuisce in remoto, potrebbe essere abilitata l'autenticazione con chiave. L'esempio seguente illustra come ottenere la chiave del servizio con Python per effettuare una richiesta di inferenza.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Consultare l'articolo sulle applicazioni client per l'utilizzo di servizi Web per altri client di esempio in altre lingue.
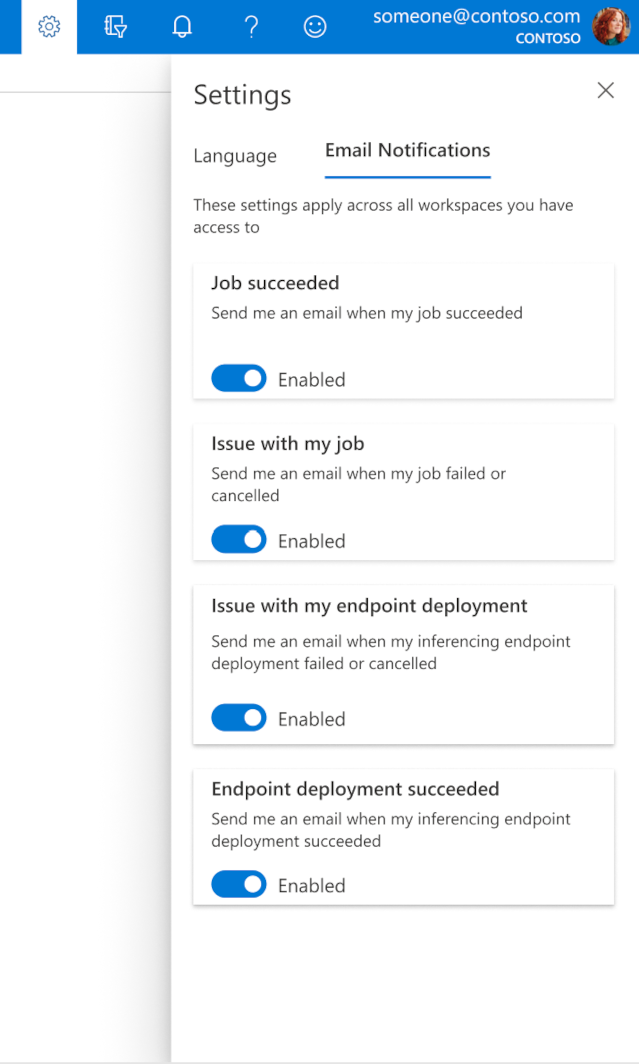
Come configurare i messaggi di posta elettronica in Studio
Per iniziare a ricevere messaggi di posta elettronica quando il processo, l'endpoint online o l'endpoint batch sono stati completati o se si verifica un problema (non riuscito, annullato), seguire questa procedura:
- In Azure ML Studio, passare alle impostazioni selezionando l'icona ingranaggio.
- Selezionare la scheda Notifiche Email.
- Attivare o disabilitare le notifiche e-mail per un evento specifico.
Informazioni sullo stato del servizio
Durante la distribuzione del modello, è possibile che lo stato del servizio cambi prima del completamento della distribuzione.
La seguente tabella descrive i diversi stati del servizio:
| Stato del servizio Web | Descrizione | Stato finale? |
|---|---|---|
| Transizione | Il servizio è in fase di distribuzione. | No |
| Unhealthy | Il servizio è stato distribuito ma non è attualmente raggiungibile. | No |
| Non pianificabile | Al momento, non è possibile distribuire il servizio per mancanza di risorse. | No |
| Non riuscito | Il servizio non è riuscito a eseguire la distribuzione a causa di un errore o di un arresto anomalo. | Sì |
| Healthy | Il servizio è integro e l'endpoint è disponibile. | Sì |
Suggerimento
Durante la distribuzione, le immagini Docker per le destinazioni di calcolo vengono compilate e caricate dal Registro Azure Container (ACR). Per impostazione predefinita, Azure Machine Learning crea un ACR che usa il livello di servizio base. La modifica di ACR per l'area di lavoro al livello Standard o Premium può ridurre il tempo necessario per la compilazione e distribuzione delle immagini nelle destinazioni di calcolo. Per altre informazioni, vedere Livelli di servizio di Registro Azure Container.
Nota
Se si distribuisce un modello nel servizio Azure Kubernetes, è consigliabile abilitare Monitoraggio di Azure per il cluster. Ciò consente di comprendere l'integrità complessiva del cluster e l'utilizzo delle risorse. Potrebbero essere utili anche le risorse seguenti:
- Controllare la presenza di eventi di Integrità risorse che influiscono sul cluster del servizio Azure Kubernetes
- Diagnostica del servizio Azure Kubernetes
Se si sta tentando di distribuire un modello in un cluster non integro o sovraccarico, è prevedibile che si verifichino problemi. Per assistenza nella risoluzione dei problemi del cluster del servizio Azure Kubernetes, contattare il supporto del servizio Azure Kubernetes.
Eliminare risorse
SI APPLICA A:Estensione ML dell’interfaccia della riga di comando di Azure v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Per eliminare un servizio Web distribuito, usare az ml service delete <name of webservice>.
Per eliminare un modello registrato dall'area di lavoro, usare az ml model delete <model id>
Ulteriori informazioni sull'eliminazione di un servizio Web e sull'eliminazione di un modello.
Passaggi successivi
- Risolvere una distribuzione non riuscita
- Aggiornare un servizio Web
- Distribuzione con un clic per le esecuzioni automatizzate di Machine Learning in Azure Machine Learning Studio
- Usare TLS per proteggere un servizio Web tramite Azure Machine Learning
- Monitorare i modelli di Azure Machine Learning con Application Insights
- Creare trigger e avvisi di eventi per le distribuzioni dei modelli