Monitorare e raccogliere dati da endpoint servizio Web di ML
SI APPLICA A:  Python SDK azureml v1
Python SDK azureml v1
Questo articolo fornisce informazioni su come raccogliere dati da modelli distribuiti in endpoint servizio Web in servizio Azure Kubernetes o Istanze di Azure Container. Usare Azure Application Insights per raccogliere i dati seguenti da un endpoint:
- Dati di output
- Risposte
- Frequenza delle richieste, tempi di risposta e percentuali di errore
- Tassi di dipendenza, tempi di risposta e percentuali di errore
- Eccezioni
Il notebook enable-app-insights-in-production-service.ipynb illustra i concetti descritti in questo articolo.
Per informazioni su come eseguire i notebook, vedere l'articolo Esplorare Azure Machine Learning con notebook Jupyter.
Importante
Le informazioni in questo articolo si basano sull'istanza di Azure Application Insights creata con l'area di lavoro. Se si elimina questa istanza di Application Insights, non sarà possibile ricrearla se non eliminando e ricreando l'area di lavoro.
Suggerimento
Se invece si usano endpoint online, usare le informazioni nell'articolo Monitorare gli endpoint online.
Prerequisiti
Una sottoscrizione Azure: provare la versione gratuita o a pagamento di Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning, una directory locale contenente gli script e Azure Machine Learning SDK per Python installato. Per altre informazioni, vedere Come configurare un ambiente di sviluppo.
Un modello di Machine Learning addestrato. Per altre informazioni, vedere l'esercitazione Eseguire il training di un modello di classificazione delle immagini.
Configurare la registrazione con Python SDK
In questa sezione, si scoprirà come abilitare la registrazione di Application Insight usando Python SDK.
Aggiornare un servizio distribuito
Per aggiornare un servizio Web esistente, seguire questi passaggi:
Identificare il servizio nell'area di lavoro. Il valore di
wsè il nome dell'area di lavorofrom azureml.core.webservice import Webservice aks_service= Webservice(ws, "my-service-name")Aggiornare il servizio e abilitare Azure Application Insights
aks_service.update(enable_app_insights=True)
Registrare tracce personalizzate nel servizio
Importante
Azure Application Insights registra solo carichi di lavoro fino a 64 KB. Se viene raggiunto questo limite, potrebbero essere restituiti errori di memoria insufficiente o potrebbe non essere possibile registrare ulteriori informazioni. Se i dati da registrare superano 64 KB, sarebbe opportuno memorizzarli in una risorsa di archiviazione BLOB usando le informazioni in Raccogliere i dati per modelli in produzione.
Per situazioni più complesse, come il tracciamento di modelli in una distribuzione di servizio Azure Kubernetes, si consiglia di usare una libreria di terze parti come OpenCensus.
Per registrare tracce personalizzate, seguire il processo di distribuzione standard per il servizio Azure Kubernetes o il servizio Istanze di Azure Container, descritto nel documento Come e dove distribuire. Seguire quindi questa procedura:
Aggiornare il file di punteggio aggiungendo istruzioni di stampa per inviare i dati ad Application Insights durante l'inferenza. Per informazioni più complesse, come i dati della richiesta e la risposta, usare una struttura JSON.
Il file
score.pydi esempio seguente registra quando è stato inizializzato il modello, l'input e l'output durante l'inferenza e l'ora in cui si sono verificati eventuali errori.import pickle import json import numpy from sklearn.externals import joblib from sklearn.linear_model import Ridge from azureml.core.model import Model import time def init(): global model #Print statement for appinsights custom traces: print ("model initialized" + time.strftime("%H:%M:%S")) # note here "sklearn_regression_model.pkl" is the name of the model registered under the workspace # this call should return the path to the model.pkl file on the local disk. model_path = Model.get_model_path(model_name = 'sklearn_regression_model.pkl') # deserialize the model file back into a sklearn model model = joblib.load(model_path) # note you can pass in multiple rows for scoring def run(raw_data): try: data = json.loads(raw_data)['data'] data = numpy.array(data) result = model.predict(data) # Log the input and output data to appinsights: info = { "input": raw_data, "output": result.tolist() } print(json.dumps(info)) # you can return any datatype as long as it is JSON-serializable return result.tolist() except Exception as e: error = str(e) print (error + time.strftime("%H:%M:%S")) return errorAggiornare la configurazione del servizio e verificare di aver abilitato Application Insights.
config = Webservice.deploy_configuration(enable_app_insights=True)Compilare un'immagine e distribuirla in Azure Kubernetes o Azure Container. Per altre informazioni, vedere Come distribuire e dove.
Disabilitare il rilevamento in Python
Per disabilitare Azure Application Insights, usare il codice seguente:
## replace <service_name> with the name of the web service
<service_name>.update(enable_app_insights=False)
Configurare la registrazione con studio di Azure Machine Learning
È anche possibile abilitare Azure Application Insights da studio di Azure Machine Learning. Quando si è pronti per distribuire il modello come servizio Web, usare i passaggi seguenti per abilitare Application Insights:
Accedere a Studio all'indirizzo https://ml.azure.com.
Passare a Modelli e selezionare il modello da distribuire.
Selezionare +Distribuisci.
Compilare il modulo Distribuisci modello.
Espandere il menu Avanzate.
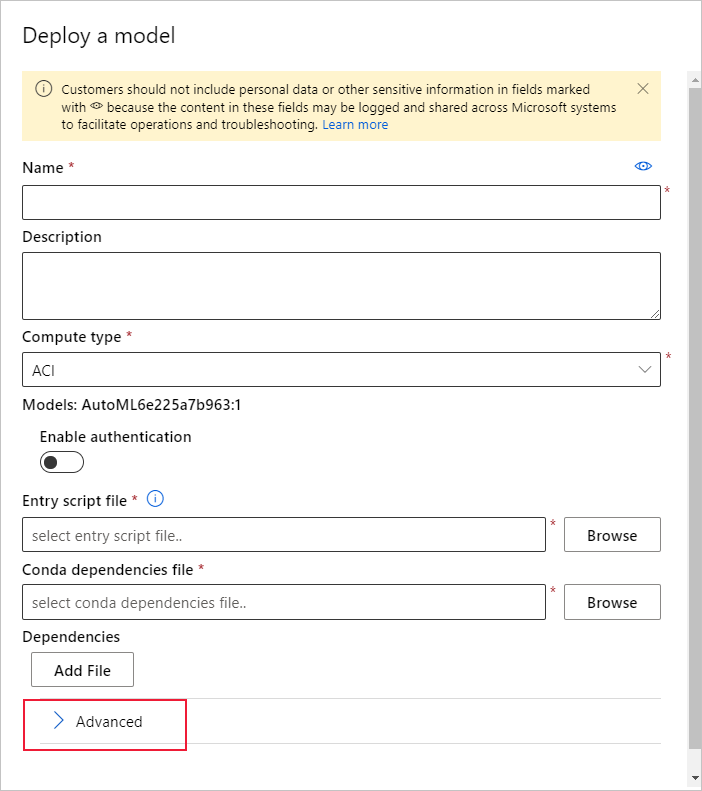
Selezionare Abilita diagnostica e raccolta dati di Application Insights.
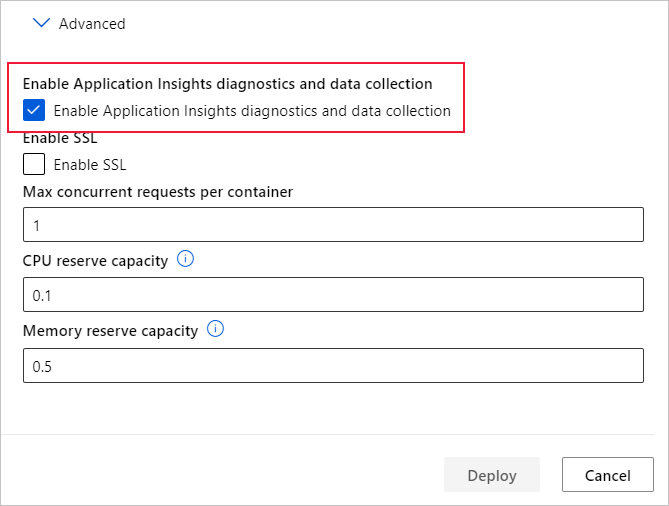
Visualizzare metriche e log
Eseguire query nei log per i modelli distribuiti
I log degli endpoint online sono i dati del cliente. È possibile usare la funzione get_logs() per recuperare i log da un servizio Web distribuito in precedenza. Il log può contenere informazioni dettagliate sugli errori che si sono verificati durante la distribuzione.
from azureml.core import Workspace
from azureml.core.webservice import Webservice
ws = Workspace.from_config()
# load existing web service
service = Webservice(name="service-name", workspace=ws)
logs = service.get_logs()
Se si dispone di più tenant, potrebbe essere necessario aggiungere il codice di autenticazione seguente prima di ws = Workspace.from_config()
from azureml.core.authentication import InteractiveLoginAuthentication
interactive_auth = InteractiveLoginAuthentication(tenant_id="the tenant_id in which your workspace resides")
Visualizzare i log in Studio
Azure Application Insights archivia i log di servizio nello stesso gruppo di risorse dell'area di lavoro di Azure Machine Learning. Seguire questa procedura seguenti per visualizzare i dati usando Studio:
Passare all'area di lavoro di Azure Machine Learning nello studio.
Seleziona Endpoint.
Selezionare il servizio distribuito.
Selezionare il collegamento all'URL di Application Insights.

In Application Insights, dalla scheda Panoramica o nella sezione Monitoraggio, selezionare Log.
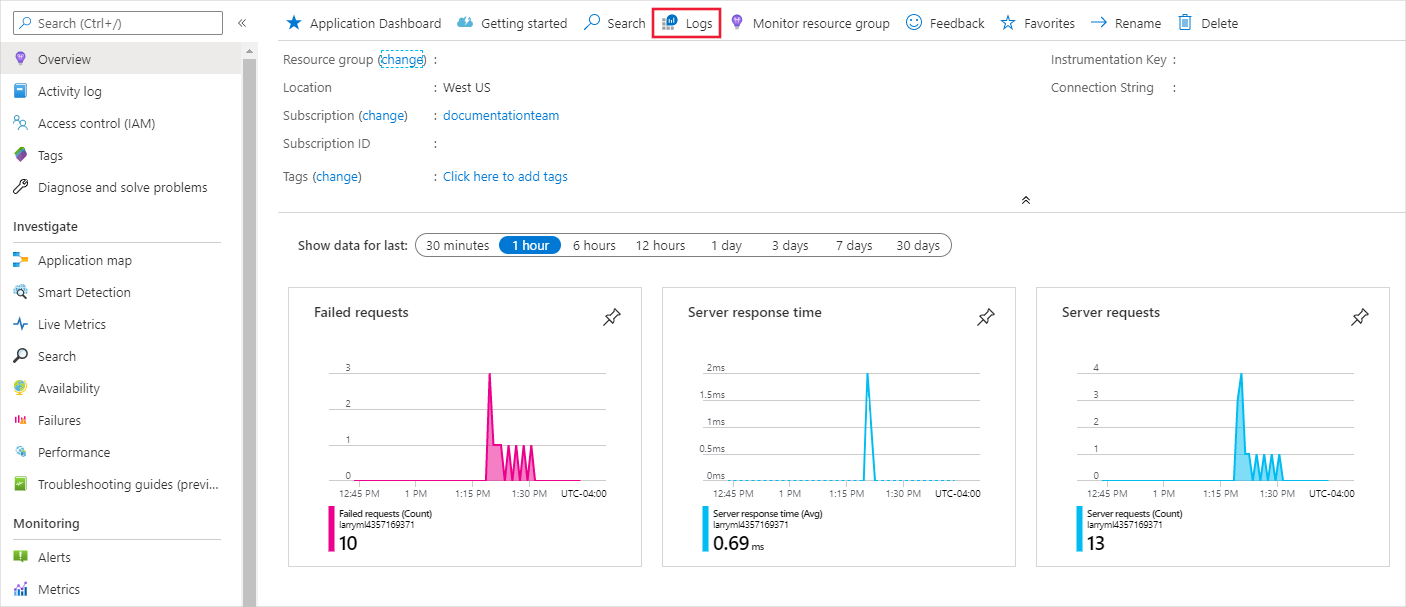
Per visualizzare le informazioni registrate nel file score.py, consultare la tabella tracce. La query seguente cerca i log in cui è stato registrato il valore input:
traces | where customDimensions contains "input" | limit 10



Per altre informazioni su come usare Azure Application Insights, vedere Informazioni su Azure Application Insights.
Metadati del servizio Web e dati di risposta
Importante
Azure Application Insights registra solo carichi di lavoro fino a 64 KB. Se viene raggiunto questo limite, potrebbero essere restituiti errori di memoria insufficiente o potrebbe non essere registrata alcuna informazione.
Per registrare le informazioni sulla richiesta del servizio Web, aggiungere le istruzioni print al file score.py. Ogni istruzioneprint genera una voce nella tabella di traccia di Application Insights in corrispondenza del messaggio STDOUT. Application Insights archivia gli output dell'istruzione print in customDimensions e nella tabella di traccia Contents. La stampa di stringhe JSON produce una struttura di dati gerarchica nell'output di traccia in Contents.
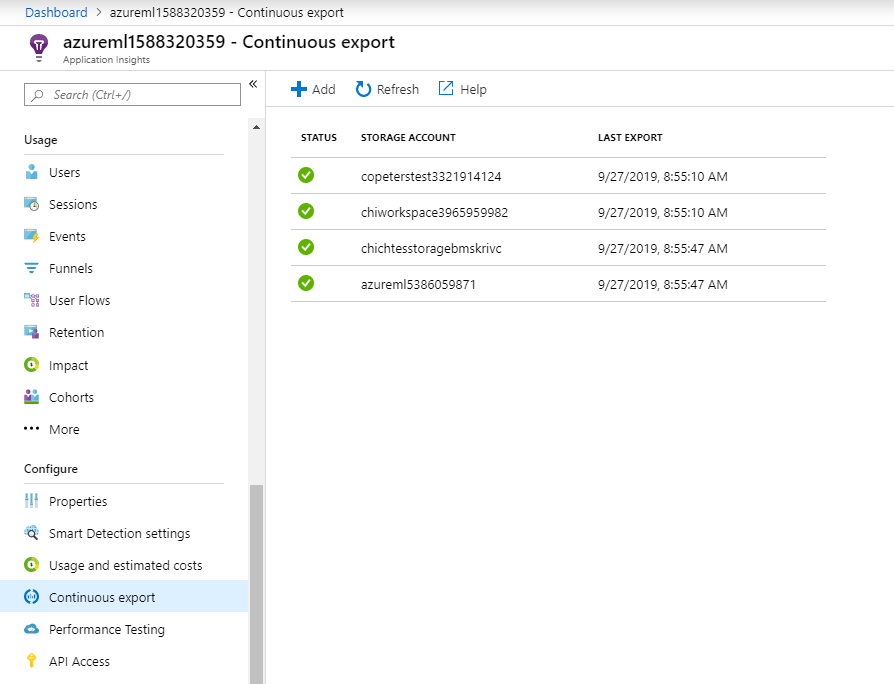
Esportare i dati per la conservazione e l'elaborazione
Importante
Azure Application Insights supporta solo le esportazioni nella risorsa di archiviazione BLOB. Per altre informazioni sui limiti di questa implementazione, vedere Esportare i dati di telemetria da App Insights.
Usare l'esportazione continua di Application Insights per esportare i dati in un account di archiviazione BLOB in cui è possibile definire le impostazioni di conservazione. Application Insights esporta i dati in formato JSON.
Passaggi successivi
In questo articolo si è visto come abilitare la registrazione e visualizzare i log per gli endpoint servizio Web. Vedere questi articoli per i passaggi successivi:
Come distribuire un modello in un cluster del servizio Azure Container
MLOps: gestire, distribuire e monitorare i modelli con Azure Machine Learning per scoprire come sfruttare i dati raccolti da modelli in produzione. Tali dati possono essere utili per migliorare continuamente il processo di Machine Learning.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per