Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
In Azure Machine Learning è possibile usare un contenitore personalizzato per distribuire un modello in un endpoint online. Le distribuzioni di contenitori personalizzati possono usare server Web diversi dal server Python Flask predefinito usato da Azure Machine Learning.
Quando si usa una distribuzione personalizzata, è possibile:
- Usare vari strumenti e tecnologie, ad esempio TensorFlow Serving (TF Serving), TorchServe, Triton Inference Server, il pacchetto Plumber R e l'immagine minima di inferenza di Azure Machine Learning.
- Sfruttare comunque i vantaggi del monitoraggio, del ridimensionamento, degli avvisi e dell'autenticazione predefiniti offerti da Azure Machine Learning.
Questo articolo illustra come usare un'immagine TF Serving per gestire un modello TensorFlow.
Prerequisiti
Un'area di lavoro di Azure Machine Learning. Per istruzioni sulla creazione di un'area di lavoro, vedere Creare l'area di lavoro.
Interfaccia della riga di comando di Azure e l'estensione
mlo Azure Machine Learning Python SDK v2:Per installare l'interfaccia della riga di comando di Azure e l'estensione
ml, vedere Installare e configurare l'interfaccia della riga di comando (v2).Gli esempi in questo articolo presuppongono che si usi una shell Bash o una shell compatibile. Ad esempio, è possibile usare una shell in un sistema Linux o in un sottosistema Windows per Linux.
Un gruppo di risorse di Azure che contiene l'area di lavoro e a cui l'utente o l'entità servizio hanno accesso come Collaboratore. Se si usano i passaggi descritti in Creare l'area di lavoro per configurare l'area di lavoro , è necessario soddisfare questo requisito.
Motore Docker, installato ed in esecuzione in locale. Questo prerequisito è altamente consigliato. È necessario per distribuire un modello in locale ed è utile per il debug.
Esempi di distribuzione
Nella tabella seguente sono elencati gli esempi di distribuzione che usano contenitori personalizzati e sfruttano diversi strumenti e tecnologie.
| Esempio | Script CLI di Azure | Descrizione |
|---|---|---|
| minimal/multimodello | deploy-custom-container-minimal-multimodel | Distribuisce più modelli in una singola distribuzione estendendo l'immagine minima dell'inferenza di Azure Machine Learning. |
| minimal/single-model | distribuzione-contenitore-personalizzato-minimale-singolo-modello | Distribuisce un singolo modello estendendo l'immagine minima dell'inferenza di Azure Machine Learning. |
| mlflow/multideployment-scikit | distribuire-contenitore-personalizzato-mlflow-multidistribuzione-scikit | Distribuisce due modelli MLFlow con requisiti Python diversi in due distribuzioni separate dietro un singolo endpoint. Usa l'immagine minima di inferenza di Azure Machine Learning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Distribuisce tre modelli di regressione in un endpoint. Usa il pacchetto Plumber R. |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Distribuisce un modello Half Plus Two usando un contenitore personalizzato TF Serving. Usa il processo di registrazione del modello standard. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Distribuisce un modello Half Plus Two usando un contenitore personalizzato TF Serving con il modello integrato nell'immagine. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Distribuisce un singolo modello usando un contenitore personalizzato TorchServe. |
| triton/modello singolo | deploy-custom-container-triton-modello-singolo | Distribuisce un modello Triton utilizzando un contenitore personalizzato. |
Questo articolo illustra come usare l'esempio tfserving/half-plus-two.
Avviso
I team di supporto Microsoft potrebbero non essere in grado di risolvere i problemi causati da un'immagine personalizzata. In caso di problemi, potrebbe essere richiesto di usare l'immagine predefinita o una delle immagini fornite da Microsoft per verificare se il problema è specifico dell'immagine.
Scaricare il codice sorgente
I passaggi descritti in questo articolo usano esempi di codice del repository azureml-examples . Seguire i comandi seguenti per clonare il repository:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Inizializzare le variabili di ambiente
Per usare un modello TensorFlow, sono necessarie diverse variabili di ambiente. Eseguire i comandi seguenti per definire tali variabili:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Scaricare un modello TensorFlow
Scaricare e decomprimere un modello che divide un valore di input per due e aggiunge due al risultato:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Testare un'immagine di TF Serving nell'ambiente locale
Usare Docker per eseguire l'immagine in locale per i test:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Inviare richieste di liveness e assegnazione dei punteggi all'immagine
Invia una richiesta di controllo di attività per verificare che il processo all'interno del contenitore sia in esecuzione. Dovresti ricevere un codice di stato della risposta 200 OK.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Inviare una richiesta di assegnazione dei punteggi per verificare che sia possibile ottenere stime sui dati senza etichetta:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Arrestare l'immagine
Al termine del test in locale, fermare l'immagine.
docker stop tfserving-test
Distribuire l'endpoint online in Azure
Per distribuire l'endpoint online in Azure, seguire questa procedura nelle sezioni seguenti.
Creare file YAML per l'endpoint e la distribuzione
È possibile configurare la distribuzione cloud usando YAML. Ad esempio, per configurare l'endpoint, è possibile creare un file YAML denominato tfserving-endpoint.yml contenente le righe seguenti:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
Per configurare la distribuzione, è possibile creare un file YAML denominato tfserving-deployment.yml contenente le righe seguenti:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Le sezioni seguenti illustrano concetti importanti sui parametri YAML e Python.
Immagine di base
environment Nella sezione in YAML o nel Environment costruttore in Python si specifica l'immagine di base come parametro. In questo esempio, docker.io/tensorflow/serving:latest viene usato come valore image.
Se si esamina il contenitore, è possibile notare che questo server usa ENTRYPOINT i comandi per avviare uno script del punto di ingresso. Tale script accetta variabili di ambiente come MODEL_BASE_PATH e MODEL_NAMEe espone porte come 8501. Questi dettagli riguardano tutti questo server ed è possibile usare queste informazioni per determinare come definire la distribuzione. Ad esempio, se si impostano le MODEL_BASE_PATH variabili di ambiente e MODEL_NAME nella definizione di distribuzione, TF Serving usa tali valori per avviare il server. Analogamente, se si imposta la porta per ogni route su 8501 nella definizione di distribuzione, le richieste utente a tali route vengono indirizzate correttamente al server tf serving.
Questo esempio si basa sul caso TF Serving. Tuttavia, è possibile utilizzare qualsiasi contenitore che rimanga attivo e risponda alle richieste dirette alle route di verifica dello stato, disponibilità e punteggio. Per informazioni su come formare un Dockerfile per creare un contenitore, è possibile fare riferimento ad altri esempi. Alcuni server usano CMD istruzioni anziché ENTRYPOINT istruzioni.
Il parametro configurazione_inferenza
Nella environment sezione o nella Environment classe, inference_config è un parametro. Specifica la porta e il percorso per tre tipi di rottae: rotta di attivazione, rotta di prontezza e rotta di valutazione. Il inference_config parametro è obbligatorio se si vuole eseguire il proprio contenitore con un endpoint online gestito.
Route di disponibilità e route di attività
Alcuni server API consentono di controllare lo stato del server. Esistono due tipi di route che è possibile specificare per controllare lo stato:
- Route di attività : per verificare se un server è in esecuzione, si usa una route di attività.
- Route di idoneità : per verificare se un server è pronto per il lavoro, usare una route di idoneità.
Nel contesto dell'inferenza di Machine Learning, un server potrebbe rispondere con un codice di stato 200 OK a una richiesta di attività prima di caricare un modello. Il server potrebbe rispondere con un codice di stato 200 OK a una richiesta di idoneità solo dopo il caricamento del modello in memoria.
Per altre informazioni sull'attività e sui probe di idoneità, vedere Configurare Liveness, Readiness and Startup Probes .For more information about liveness and readiness probes, see Configure Liveness, Readiness and Startup Probes.For more information about liveness and readiness probes, see Configure Liveness, Readiness and Startup Probes.
Il server API scelto determina le route di attività e conformità. Il server viene identificato in un passaggio precedente quando si testa il contenitore in locale. In questo articolo, la distribuzione di esempio usa lo stesso percorso per le route di liveness e readiness, perché TF Serving definisce solo una route di liveness. Per altri modi per definire le route, vedere altri esempi.
Route di assegnazione dei punteggi
Il server API usato offre un modo per ricevere il payload su cui lavorare. Nel contesto dell'inferenza di Machine Learning, un server riceve i dati di input tramite una route specifica. Identificare la route per il server API quando si testa il contenitore in locale in un passaggio precedente. Specificare quel percorso come percorso di assegnazione dei punteggi quando si definisce la distribuzione da creare.
La creazione corretta della distribuzione aggiorna anche il scoring_uri parametro dell'endpoint. È possibile verificare questo fatto eseguendo il comando seguente: az ml online-endpoint show -n <endpoint-name> --query scoring_uri.
Individuare il modello montato
Quando si distribuisce un modello come endpoint online, Azure Machine Learning monta il modello nell'endpoint. Quando il modello viene montato, è possibile distribuire nuove versioni del modello senza dover creare una nuova immagine Docker. Per impostazione predefinita, un modello registrato con il nome my-model e la versione 1 si trova nel percorso seguente all'interno del contenitore distribuito: /var/azureml-app/azureml-models/my-model/1.
Si consideri ad esempio la configurazione seguente:
- Una struttura di directory sul tuo computer locale di /azureml-examples/cli/endpoints/online/custom-container
- Nome del modello di
half_plus_two
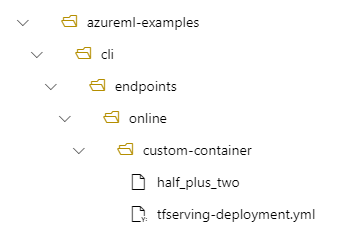
Si supponga che il file tfserving-deployment.yml contenga le righe seguenti nella relativa model sezione. In questa sezione il name valore fa riferimento al nome usato per registrare il modello in Azure Machine Learning.
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
In questo caso, quando si crea una distribuzione, il modello si trova nella cartella seguente: /var/azureml-app/azureml-models/tfserving-mounted/1.
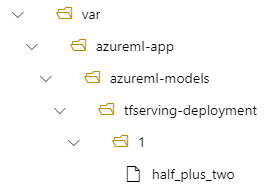
È possibile configurare facoltativamente il valore model_mount_path. Modificando questa impostazione, è possibile modificare il percorso in cui è montato il modello.
Importante
Il model_mount_path valore deve essere un percorso assoluto valido in Linux (sistema operativo dell'immagine del contenitore).
Quando si modifica il valore di , è necessario aggiornare anche la MODEL_BASE_PATH variabile di model_mount_pathambiente. Impostare MODEL_BASE_PATH sullo stesso valore di model_mount_path per evitare una distribuzione non riuscita a causa di un errore relativo al percorso di base non trovato.
Ad esempio, è possibile aggiungere il model_mount_path parametro al file tfserving-deployment.yml. È anche possibile aggiornare il MODEL_BASE_PATH valore in tale file:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
Nella distribuzione il modello si trova quindi in /var/tfserving-model-mount/tfserving-mounted/1. Non è più in azureml-app/azureml-models, ma nel percorso di montaggio specificato:
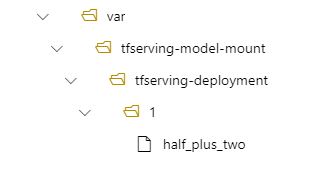
Creare l'endpoint e la distribuzione
Dopo aver costruito il file YAML, usare il comando seguente per creare l'endpoint:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
Usare il comando seguente per creare la distribuzione. Questo passaggio potrebbe essere eseguito per alcuni minuti.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
Richiamare l'endpoint
Al termine della distribuzione, effettuare una richiesta di assegnazione dei punteggi all'endpoint distribuito.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Eliminare l'endpoint
Se l'endpoint non è più necessario, eseguire il comando seguente per eliminarlo:
az ml online-endpoint delete --name tfserving-endpoint