SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)SDK Python azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)SDK Python azure-ai-ml v2 (corrente)
Questo articolo illustra come distribuire il modello in un endpoint online per l'inferenza in tempo reale. Per iniziare, distribuire un modello nel computer locale per eseguire il debug di eventuali errori. Distribuire e testare quindi il modello in Azure, visualizzare i log di distribuzione e monitorare il contratto di servizio. Al termine di questo articolo, si dispone di un endpoint HTTPS/REST scalabile che è possibile usare per l'inferenza in tempo reale.
Gli endpoint online sono endpoint usati per l'inferenza (in tempo reale). Esistono due tipi di endpoint online: endpoint online gestiti e endpoint online Kubernetes. Per ulteriori informazioni sulle differenze, vedere Endpoint online gestiti rispetto a Endpoint online Kubernetes.
Gli endpoint online gestiti consentono di distribuire i modelli di apprendimento automatico in modo pronto all'uso. Funzionano con computer CPU e GPU potenti in Azure in modo scalabile e completamente gestito. Gli endpoint online gestiti si occupano di gestire, ridimensionare, proteggere e monitorare i modelli. Questa assistenza consente di liberare dall'overhead di configurazione e gestione dell'infrastruttura sottostante.
L'esempio principale in questo articolo usa endpoint online gestiti per la distribuzione. Per usare Kubernetes, invece, vedere le note contenute in questo documento che sono inline con la discussione sugli endpoint online gestiti.
Prerequisiti
SI APPLICA A:Estensione ml della CLI di Azure v2 (corrente)
Il controllo degli accessi in base al ruolo di Azure viene usato per concedere l'accesso alle operazioni in Azure Machine Learning. Per eseguire la procedura descritta in questo articolo, all'account utente deve essere assegnato il ruolo Proprietario o Collaboratore per l'area di lavoro di Azure Machine Learning oppure un ruolo personalizzato deve consentire Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Se si usa Azure Machine Learning Studio per creare e gestire endpoint o distribuzioni online, è necessaria l'autorizzazione Microsoft.Resources/deployments/write aggiuntiva del proprietario del gruppo di risorse. Per altre informazioni, vedere Gestire l'accesso alle aree di lavoro di Azure Machine Learning.
(Facoltativo) Per eseguire la distribuzione in locale, è necessario installare il motore Docker nel computer locale. Si consiglia vivamente questa opzione, che semplifica il debug dei problemi.
SI APPLICA A: SDK Python azure-ai-ml v2 (corrente)
Azure RBAC viene utilizzato per concedere l'accesso alle operazioni in Azure Machine Learning. Per eseguire la procedura descritta in questo articolo, all'account utente deve essere assegnato il ruolo Proprietario o Collaboratore per l'area di lavoro di Azure Machine Learning oppure un ruolo personalizzato deve consentire Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Per altre informazioni, vedere Gestire l'accesso alle aree di lavoro di Azure Machine Learning.
(Facoltativo) Per eseguire la distribuzione in locale, è necessario installare il motore Docker nel computer locale. Si consiglia vivamente questa opzione, che semplifica il debug dei problemi.
Prima di seguire la procedura descritta in questo articolo, assicurarsi di disporre dei prerequisiti seguenti:
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
- Un'area di lavoro di Azure Machine Learning e un'istanza di ambiente di calcolo. Se queste risorse non sono disponibili, vedere Creare risorse necessarie per iniziare.
- Azure RBAC viene utilizzato per concedere l'accesso alle operazioni in Azure Machine Learning. Per eseguire la procedura descritta in questo articolo, all'account utente deve essere assegnato il ruolo Proprietario o Collaboratore per l'area di lavoro di Azure Machine Learning oppure un ruolo personalizzato deve consentire
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Per altre informazioni, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning.
L'interfaccia della riga di comando di Azure e l'estensione dell'interfaccia della riga di comando per Machine Learning vengono usate in questi passaggi, ma non sono l'obiettivo principale. Vengono usati più come utilità per passare modelli ad Azure e controllare lo stato delle distribuzioni di modelli.
- Azure RBAC viene utilizzato per concedere l'accesso alle operazioni in Azure Machine Learning. Per eseguire la procedura descritta in questo articolo, all'account utente deve essere assegnato il ruolo Proprietario o Collaboratore per l'area di lavoro di Azure Machine Learning oppure un ruolo personalizzato deve consentire
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Per altre informazioni, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning.
Assicurarsi di avere una quota di macchina virtuale (VM) sufficiente allocata per la distribuzione. Azure Machine Learning riserva il 20% delle risorse di calcolo per l'esecuzione degli aggiornamenti in alcune versioni di VM. Ad esempio, se si richiedono 10 istanze in una distribuzione, è necessario avere una quota di 12 per ogni numero di core per la versione della macchina virtuale. Se non si tiene conto delle risorse di calcolo aggiuntive, viene generato un errore. Alcune versioni delle macchine virtuali sono escluse dalla prenotazione di quota aggiuntiva. Per altre informazioni sull'allocazione delle quote, vedere Allocazione della quota di macchine virtuali per la distribuzione.
In alternativa, è possibile usare la quota dal pool di quote condivise di Azure Machine Learning per un periodo di tempo limitato. Azure Machine Learning offre un pool di quote condivise da cui gli utenti in diverse aree possono accedere alla quota per eseguire test per un periodo di tempo limitato, a seconda della disponibilità.
Quando si usa Studio per distribuire modelli Llama-2, Phi, Nemotron, Mistral, Dolly e Deci-DeciLM dal catalogo dei modelli a un endpoint online gestito, Azure Machine Learning consente di accedere al proprio pool di quote condivise per un breve periodo di tempo, in modo da poter eseguire la verifica. Per altre informazioni sul pool di quote condivise, vedere Quota condivisa di Azure Machine Learning.
Preparare il sistema
Impostare le variabili di ambiente
Se le impostazioni predefinite per l'interfaccia della riga di comando di Azure non sono già state impostate, salvare le proprie impostazioni predefinite. Per evitare di passare più volte i valori per la sottoscrizione, l'area di lavoro e il gruppo di risorse, eseguire questo codice:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Clonare il repository di esempi
Per seguire questo articolo, clonare prima il repository azureml-examples e quindi passare alla directory azureml-examples/cli del repository:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
Usare --depth 1 per clonare solo il commit più recente nel repository, riducendo il tempo necessario per completare l'operazione.
I comandi di questa esercitazione si trovano nei file deploy-local-endpoint.sh e deploy-managed-online-endpoint.sh nella directory CLI. I file di configurazione YAML si trovano nella sottodirectory endpoints/online/managed/sample/ .
Note
I file di configurazione YAML per gli endpoint online Kubernetes si trovano nella sottodirectory endpoints/online/kubernetes/ .
Clonare il repository di esempi
Per eseguire gli esempi di training, clonare prima il repository azureml-examples e quindi passare alla directory azureml-examples/sdk/python/endpoints/online/managed :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Usare --depth 1 per clonare solo il commit più recente nel repository, riducendo il tempo necessario per completare l'operazione.
Le informazioni contenute in questo articolo si basano sul notebook online-endpoints-simple-deployment.ipynb . Include lo stesso contenuto di questo articolo, anche se l'ordine dei codici è lievemente differente.
Connettersi all'area di lavoro di Azure Machine Learning
L'area di lavoro è la risorsa di primo livello per Azure Machine Learning. Offre una posizione centralizzata per lavorare con tutti gli artefatti creati quando si usa Azure Machine Learning. In questa sezione, ci si connetterà all'area di lavoro in cui vengono eseguite le attività di distribuzione. Per seguire, aprire il notebook online-endpoints-simple-deployment.ipynb.
Importare le librerie necessarie:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
Note
Se si usa l'endpoint online Kubernetes, importare la classe KubernetesOnlineEndpoint e la classe KubernetesOnlineDeployment dalla libreria azure.ai.ml.entities.
Configurare i dettagli e ottenere un handle per l'area di lavoro.
Per connettersi a un'area di lavoro, sono necessari questi parametri di identificatore: una sottoscrizione, un gruppo di risorse e un nome dell'area di lavoro. Questi dettagli verranno usati in MLClient da azure.ai.ml per ottenere un handle per l'area di lavoro di Azure Machine Learning necessaria. Questo esempio usa l'autenticazione di Azure predefinita.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Se Git è installato nel computer locale, è possibile seguire le istruzioni per clonare il repository degli esempi. In caso contrario, seguire le istruzioni per scaricare i file dal repository degli esempi.
Clonare il repository di esempi
Per seguire questo articolo, clonare prima il repository azureml-examples e quindi passare alla directory azureml-examples/cli/endpoints/online/model-1.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Usare --depth 1 per clonare solo il commit più recente nel repository, riducendo il tempo necessario per completare l'operazione.
Scaricare i file dal repository degli esempi
Se è stato clonato il repository di esempi, il computer locale dispone già di copie dei file per questo esempio ed è possibile passare alla sezione successiva. Se il repository non è stato clonato, scaricarlo nel computer locale.
- Passare al repository di esempi (azureml-examples).
- Passare al <> pulsante Codice nella pagina e quindi nella scheda Locale selezionare Scarica ZIP.
- Individuare la cartella /cli/endpoints/online/model-1/model e il file /cli/endpoints/online/model-1/onlinescoring/score.py.
Impostare le variabili di ambiente
Impostare le variabili di ambiente seguenti in modo che sia possibile usarle negli esempi di questo articolo. Sostituire i valori con l'ID sottoscrizione di Azure, l'area di Azure in cui si trova l'area di lavoro, il gruppo di risorse che contiene l'area di lavoro e il nome dell'area di lavoro:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
Un paio di esempi di modello richiedono di caricare i file nell'Archiviazione BLOB di Azure per l'area di lavoro. La procedura seguente esegue una query sull'area di lavoro e archivia queste informazioni nelle variabili di ambiente usate negli esempi:
Ottenere un token di accesso:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
Impostare la versione dell'API REST:
API_VERSION="2022-05-01"
Ottenere le informazioni di archiviazione:
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
Clonare il repository di esempi
Per seguire questo articolo, clonare prima il repository azureml-examples e quindi passare alla directory azureml-examples :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
Usare --depth 1 per clonare solo il commit più recente nel repository, riducendo il tempo necessario per completare l'operazione.
Definire l'endpoint
Per definire un endpoint online, specificare il nome dell'endpoint e la modalità di autenticazione. Per altre informazioni sugli endpoint online gestiti, vedere Endpoint online.
Impostare il nome di un endpoint
Per impostare il nome dell'endpoint eseguire il comando seguente. Sostituire <YOUR_ENDPOINT_NAME> con un nome univoco nell'area di Azure. Per altre informazioni sulle regole di denominazione, vedere Limiti degli endpoint.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
Il frammento di codice seguente mostra il file endpoints/online/managed/sample/endpoint.yml :
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
Il riferimento per il formato YAML dell'endpoint è descritto nella tabella seguente. Per informazioni su come specificare questi attributi, vedere le informazioni di riferimento sull'endpoint YAML online. Per informazioni sui limiti correlati agli endpoint gestiti, vedere Endpoint online e endpoint batch di Azure Machine Learning.
| Chiave |
Descrizione |
$schema |
(Facoltativo) Schema YAML. Per vedere tutte le opzioni disponibili nel file YAML, è possibile visualizzare in un browser lo schema incluso nel frammento di codice precedente. |
name |
Nome dell'endpoint. |
auth_mode |
Usare key per l'autenticazione basata su chiave.
Usare aml_token per l'autenticazione basata su token di Azure Machine Learning.
Usare aad_token per l'autenticazione basata su token di Microsoft Entra (anteprima).
Per altre informazioni sull'autenticazione, vedere Autenticare i client per gli endpoint online. |
Definire prima di tutto il nome dell'endpoint online e quindi configurare l'endpoint.
Sostituire <YOUR_ENDPOINT_NAME> con un nome univoco nell'area di Azure o usare il metodo di esempio per definire un nome casuale. Assicurarsi di eliminare il metodo che non si usa. Per altre informazioni sulle regole di denominazione, vedere Limiti degli endpoint.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
Il codice precedente usa key per l'autenticazione basata su chiave. Per usare l'autenticazione basata su token di Azure Machine Learning, usare aml_token. Usare aad_token per l'autenticazione basata su token di Microsoft Entra (anteprima). Per altre informazioni sull'autenticazione, vedere Autenticare i client per gli endpoint online.
Quando si esegue la distribuzione in Azure dallo studio, si crea un endpoint e una distribuzione da aggiungere. In tale occasione, viene richiesto di specificare i nomi per l'endpoint e la distribuzione.
Impostare il nome di un endpoint
Per impostare il nome dell'endpoint, eseguire il comando seguente per generare un nome casuale. Deve essere univoco nell'area di Azure. Per altre informazioni sulle regole di denominazione, vedere Limiti degli endpoint.
export ENDPOINT_NAME=endpoint-`echo $RANDOM`
Per definire l'endpoint e la distribuzione, questo articolo usa i modelli di Azure Resource Manager (modelli arm) online-endpoint.json e online-endpoint-deployment.json. Per usare i modelli per definire un endpoint e una distribuzione online, vedere la sezione Distribuire in Azure .
Definire la distribuzione
Una distribuzione è un set di risorse necessarie per ospitare il modello che esegue effettivamente l'inferenza. Per questo esempio si distribuisce un scikit-learn modello che esegue la regressione e si usa uno script di assegnazione dei punteggi score.py per eseguire il modello in una richiesta di input specifica.
Per informazioni sugli attributi chiave di una distribuzione, vedere Distribuzioni online.
La configurazione della distribuzione utilizza la posizione del modello che si desidera distribuire.
Il frammento di codice seguente mostra il file endpoints/online/managed/sample/blue-deployment.yml , con tutti gli input necessari per configurare una distribuzione:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Il file blue-deployment.yml specifica gli attributi di distribuzione seguenti:
-
model: specifica le proprietà del modello inline usando il path parametro (da cui caricare i file). L'interfaccia della riga di comando carica automaticamente i file del modello e registra il modello con un nome generato automaticamente.
-
environment: usa definizioni inline che includono da dove caricare i file. L'interfaccia della riga di comando carica automaticamente il file conda.yaml e registra l'ambiente. Successivamente, per compilare l'ambiente, la distribuzione usa il image parametro per l'immagine di base. In questo esempio è mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Le conda_file dipendenze vengono installate sopra l'immagine di base.
-
code_configuration: carica i file locali, ad esempio l'origine Python per il modello di assegnazione dei punteggi, dall'ambiente di sviluppo durante la distribuzione.
Per altre informazioni sullo schema YAML, vedere le informazioni di riferimento sull'endpoint YAML online.
Note
Per usare gli endpoint Kubernetes anziché gli endpoint online gestiti come destinazione di calcolo:
- Creare e collegare il cluster Kubernetes come destinazione di calcolo all'area di lavoro di Azure Machine Learning usando Azure Machine Learning Studio.
- Usare l'endpoint YAML per specificare come destinazione Kubernetes anziché l'endpoint gestito YAML. È necessario modificare YAML per modificare il valore di
compute con il nome della destinazione di calcolo registrata. È possibile usare questo file deployment.yaml con altre proprietà applicabili a una distribuzione Kubernetes.
Tutti i comandi usati in questo articolo per gli endpoint online gestiti si applicano anche agli endpoint Kubernetes, ad eccezione delle funzionalità seguenti che non si applicano agli endpoint Kubernetes:
- Il monitoraggio SLA facoltativo e l'integrazione di Azure Log Analytics tramite Azure Monitor.
- Uso dei token di Microsoft Entra.
- Scalabilità automatica come descritto nella sezione facoltativa Configurare la scalabilità automatica .
Usare il codice seguente per configurare una distribuzione:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model: specifica le proprietà del modello inline usando il path parametro (da cui caricare i file). L'SDK carica automaticamente i file del modello e registra il modello con un nome generato automaticamente.
-
Environment: usa definizioni inline che includono da dove caricare i file. L'SDK carica automaticamente il file conda.yaml e registra l'ambiente. Successivamente, per compilare l'ambiente, la distribuzione usa il image parametro per l'immagine di base. In questo esempio è mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Le conda_file dipendenze vengono installate sopra l'immagine di base.
-
CodeConfiguration: carica i file locali, ad esempio l'origine Python per il modello di assegnazione dei punteggi, dall'ambiente di sviluppo durante la distribuzione.
Per altre informazioni sulla definizione di distribuzione online, vedere Classe OnlineDeployment.
Quando si esegue la distribuzione in Azure, si crea un endpoint e una distribuzione da aggiungere. In tale occasione, viene richiesto di specificare i nomi per l'endpoint e la distribuzione.
Informazioni sullo script di assegnazione dei punteggi
Il formato dello script di assegnazione dei punteggi per gli endpoint online è lo stesso di quello usato nella versione precedente dell'interfaccia della riga di comando e in Python SDK.
Lo script di assegnazione dei punteggi specificato in code_configuration.scoring_script deve avere una funzione init() e una run().
Lo script di assegnazione dei punteggi deve avere una funzione init() e una run().
Lo script di assegnazione dei punteggi deve avere una funzione init() e una run().
Lo script di assegnazione dei punteggi deve avere una funzione init() e una run(). Questo articolo usa il file di score.py.
Quando si usa un modello per la distribuzione, è prima necessario caricare il file di assegnazione dei punteggi in Archiviazione BLOB e quindi registrarlo:
Il codice seguente usa il comando dell'interfaccia della riga di comando az storage blob upload-batch di Azure per caricare il file di assegnazione dei punteggi:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
Il codice seguente usa un modello per registrare il codice:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
In questo esempio viene usato il file score.py dal repository clonato o scaricato in precedenza:
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
La funzione init() viene chiamata quando il contenitore viene inizializzato o avviato. L'inizializzazione si verifica in genere poco dopo la creazione o l'aggiornamento della distribuzione. La init funzione è la posizione in cui scrivere la logica per operazioni di inizializzazione globali, ad esempio la memorizzazione nella cache del modello in memoria (come illustrato in questo file score.py ).
La run() funzione viene chiamata ogni volta che viene richiamato l'endpoint. Esegue il punteggio effettivo e la predizione. In questo file score.py la run() funzione estrae i dati da un input JSON, chiama il metodo del predict() modello scikit-learn e quindi restituisce il risultato della stima.
Distribuire ed eseguire il debug in locale usando un endpoint locale
È consigliabile testare l'esecuzione dell'endpoint in locale per convalidare ed eseguire il debug del codice e della configurazione prima di eseguire la distribuzione in Azure. L'interfaccia della riga di comando di Azure e Python SDK supportano endpoint e distribuzioni locali, ma i modelli di Azure Machine Learning Studio e ARM non lo fanno.
Per eseguire la distribuzione in locale, è necessario installare ed eseguire il motore Docker . Docker Engine viene in genere avviato all'avvio del computer. In caso contrario, è possibile eseguire la risoluzione dei problemi relativi a Docker Engine.
È possibile usare il pacchetto Python del server HTTP di inferenza di Azure Machine Learning per eseguire il debug dello script di assegnazione dei punteggi in locale senza il motore Docker. Il debug con il server di inferenza consente di eseguire il debug dello script di assegnazione dei punteggi prima di eseguire la distribuzione negli endpoint locali in modo da poter eseguire il debug senza influire sulle configurazioni del contenitore di distribuzione.
Per altre informazioni sul debug degli endpoint online in locale prima della distribuzione in Azure, vedere Debug degli endpoint online.
Distribuire il modello in locale
Creare prima di tutto un endpoint. Facoltativamente, per un endpoint locale, è possibile ignorare questo passaggio. È possibile creare la distribuzione direttamente (passaggio successivo), che a sua volta crea i metadati necessari. La distribuzione dei modelli in locale è utile a scopo di sviluppo e test.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
Studio non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Il modello non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Creare ora una distribuzione denominata blue nell'endpoint.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
Il flag --local indirizza l'interfaccia della riga di comando a distribuire l'endpoint nell'ambiente Docker.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
Il flag local=True indirizza l'SDK a distribuire l'endpoint nell'ambiente Docker.
Studio non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Il modello non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Verificare la corretta esecuzione della distribuzione locale
Controllare lo stato della distribuzione per verificare se il modello è stato distribuito senza errori:
az ml online-endpoint show -n $ENDPOINT_NAME --local
L'output sarà simile al seguente JSON. Il provisioning_state parametro è Succeeded.
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
Il metodo restituisce ManagedOnlineEndpoint l'entità . Il provisioning_state parametro è Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
Studio non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Il modello non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Nella tabella seguente sono elencati i possibili valori di provisioning_state:
| valore |
Descrizione |
Creating |
La risorsa è in fase di creazione. |
Updating |
La risorsa è in fase di aggiornamento. |
Deleting |
La risorsa è in fase di eliminazione. |
Succeeded |
Operazione di creazione o aggiornamento completata. |
Failed |
Operazione di creazione, aggiornamento o eliminazione non riuscita. |
Richiamare l'endpoint locale per assegnare un punteggio ai dati usando il modello
Richiamare l'endpoint per assegnare un punteggio al modello usando l'utile comando invoke e passando i parametri di query archiviati in un file JSON:
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Se si desidera usare un client REST (ad esempio curl), è necessario disporre dell'URI di assegnazione dei punteggi. Per ottenere l'URI di assegnazione dei punteggi, eseguire az ml online-endpoint show --local -n $ENDPOINT_NAME. Nei dati restituiti trovare l'attributo scoring_uri.
Richiamare l'endpoint per assegnare un punteggio al modello usando l'utile comando invoke e passando i parametri di query archiviati in un file JSON.
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
Se si desidera usare un client REST (ad esempio curl), è necessario disporre dell'URI di assegnazione dei punteggi. Per ottenere l'URI di assegnazione dei punteggi, eseguire il codice seguente. Nei dati restituiti trovare l'attributo scoring_uri.
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
Studio non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Il modello non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Esaminare i log per l'output dell'operazione di chiamata
Nell'esempio score.py file il run() metodo registra un output nella console.
È possibile visualizzare questo output usando il comando get-logs:
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
È possibile visualizzare questo output usando il metodo get_logs:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
Studio non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Il modello non supporta gli endpoint locali. Per testare l'endpoint localmente, consultare le schede CLI di Azure o Python.
Distribuire l'endpoint online in Azure
A questo punto, distribuire l'endpoint online in Azure. Come procedura consigliata per la produzione, è consigliabile registrare il modello e l'ambiente usati nella distribuzione.
Registrare il modello e l'ambiente
È consigliabile registrare il modello e l'ambiente prima della distribuzione in Azure in modo da poter specificare i nomi e le versioni registrati durante la distribuzione. Dopo aver registrato gli asset, è possibile riutilizzarli senza dover caricarli ogni volta che si creano distribuzioni. Questa pratica aumenta la riproducibilità e la tracciabilità.
A differenza della distribuzione in Azure, la distribuzione locale non supporta l'uso di modelli e ambienti registrati. La distribuzione locale usa invece file di modello locali e usa ambienti solo con file locali.
Per la distribuzione in Azure, è possibile usare asset locali o registrati (modelli e ambienti). In questa sezione dell'articolo la distribuzione in Azure usa gli asset registrati, ma è possibile usare gli asset locali. Per un esempio di configurazione di distribuzione che carica i file locali da usare per la distribuzione locale, vedere Configurare una distribuzione.
Per registrare il modello e l'ambiente, usare il modulo model: azureml:my-model:1 o environment: azureml:my-env:1.
Per la registrazione, è possibile estrarre le definizioni YAML di model e environment in file YAML separati nella cartella endpoints/online/managed/sample e usare i az ml model create comandi e az ml environment create. Per altre informazioni su questi comandi, eseguire az ml model create -h e az ml environment create -h.
Creare una definizione YAML per il modello. Assegnare al file il nome model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
Registrare il modello:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
Creare una definizione YAML per l'ambiente. Assegnare al file il nome environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
Registrare l'ambiente:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
Per altre informazioni su come registrare il modello come asset, vedere Registrare un modello usando l'interfaccia della riga di comando di Azure o Python SDK. Per altre informazioni sulla creazione di un ambiente, vedere Creare un ambiente personalizzato.
Registrare un modello:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
Registrare l'ambiente:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
Per informazioni su come registrare il modello come asset in modo da poter specificare il nome registrato e la versione durante la distribuzione, vedere Registrare un modello usando l'interfaccia della riga di comando di Azure o Python SDK.
Per altre informazioni sulla creazione di un ambiente, vedere Creare un ambiente personalizzato.
Registrare il modello
Una registrazione del modello è un'entità logica nell'area di lavoro che può contenere un singolo file di modello o una directory costituita da più file. Come procedura consigliata per la produzione, registrare il modello e l'ambiente. Prima di creare l'endpoint e la distribuzione in questo articolo, registrare la cartella del modello che contiene il modello.
Procedere come segue per registrare il modello di esempio:
Passare ad Azure Machine Learning Studio.
Nel riquadro sinistro selezionare la pagina Modelli .
Selezionare Registra e quindi scegliere Da file locali.
Selezionare Tipo non specificato per Tipo di modello.
Selezionare Sfoglia e scegliere Sfoglia cartella.
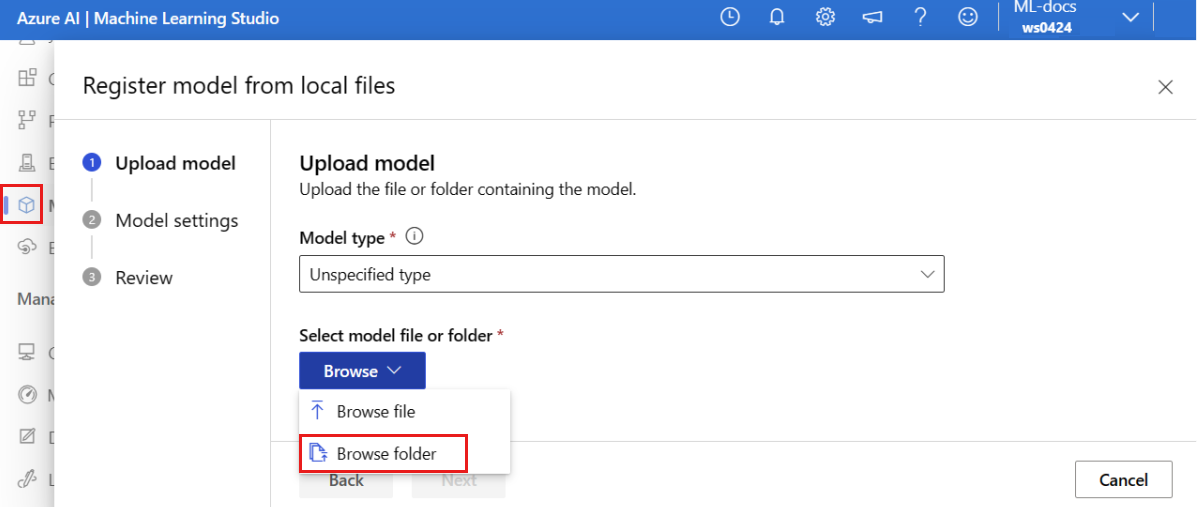
Selezionare la cartella \azureml-examples\cli\endpoints\online\model-1\model dalla copia locale del repository clonato o scaricato in precedenza. Quando viene richiesto, selezionare Carica e attendere il completamento del caricamento.
Selezionare Avanti.
Immettere un nome amichevole per il modello. I passaggi descritti in questo articolo presuppongono che il modello sia denominato model-1.
Selezionare Avanti e quindi Registra per completare la registrazione.
Per altre informazioni su come usare i modelli registrati, vedere Usare i modelli registrati.
Creare e registrare l'ambiente
Nel riquadro sinistro selezionare la pagina Ambienti .
Selezionare la scheda Ambienti personalizzati e quindi scegliere Crea.
Nella pagina Impostazioni immettere un nome, ad esempio my-env per l'ambiente.
Per Seleziona origine ambiente, scegliere Usa immagine Docker esistente con origine Conda facoltativa.
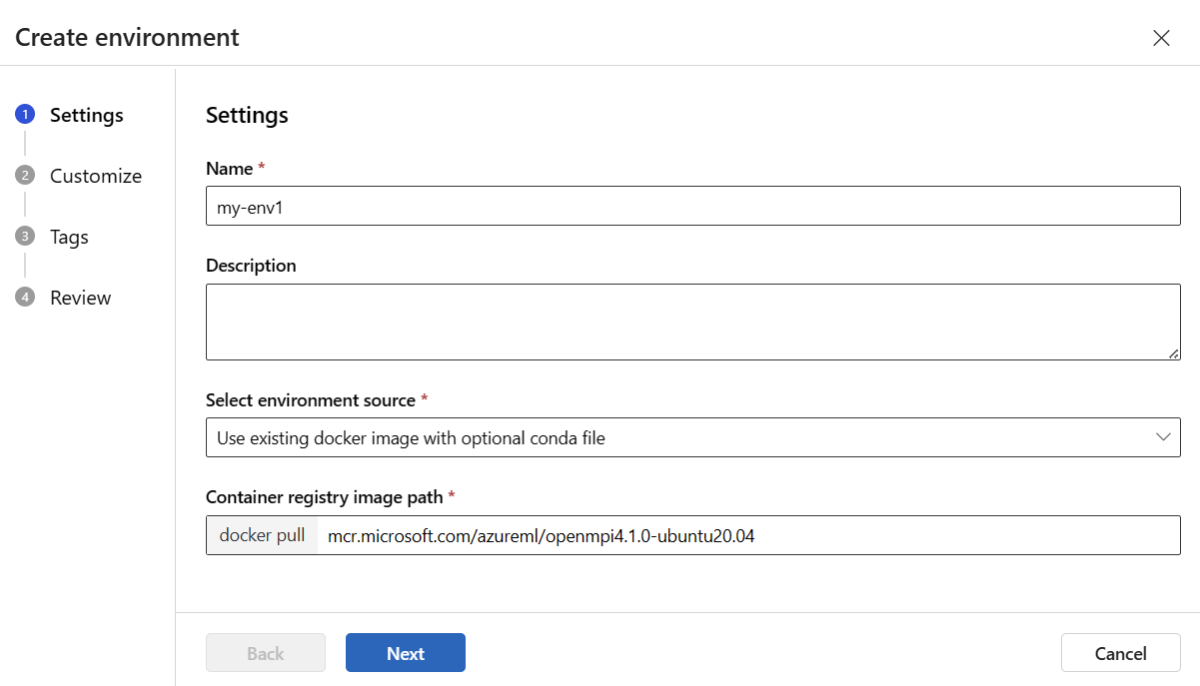
Selezionare Avanti per passare alla pagina Personalizza .
Copiare il contenuto del file \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml dal repository clonato o scaricato in precedenza.
Incollare il contenuto nella casella di testo.
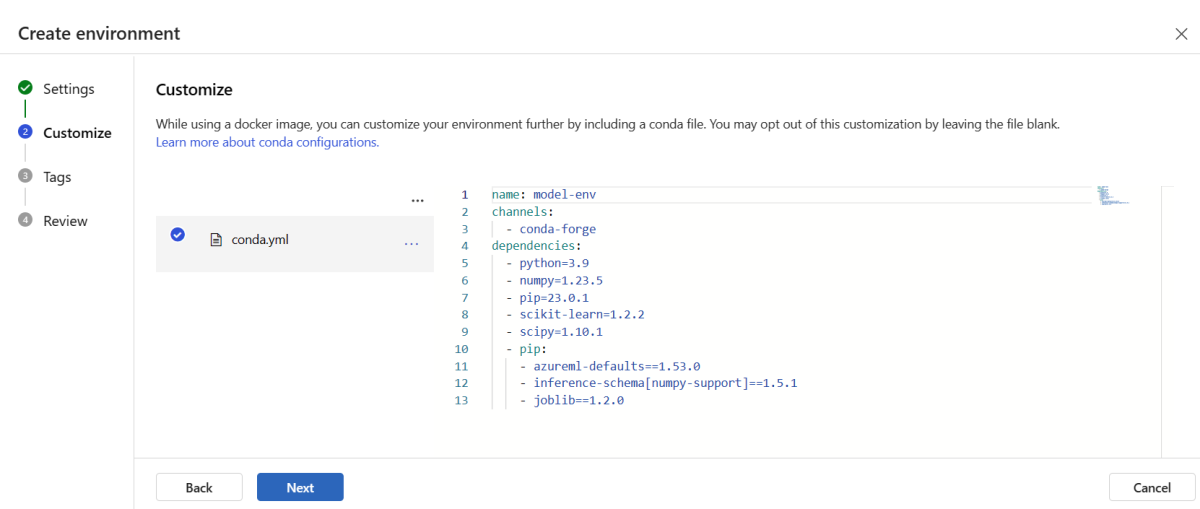
Selezionare Avanti fino a visualizzare la pagina Crea e quindi selezionare Crea.
Per altre informazioni su come creare un ambiente in studio, vedere Creare un ambiente.
Per registrare il modello usando un modello, è prima necessario caricare il file del modello in Archiviazione BLOB. L'esempio seguente usa il comando az storage blob upload-batch per caricare un file nella risorsa di archiviazione predefinita per l'area di lavoro:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
Dopo aver caricato il file, usare il modello per creare una registrazione del modello. Nell'esempio seguente il parametro modelUri contiene il percorso del modello:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
Parte dell'ambiente è un file conda che specifica le dipendenze del modello necessarie per ospitare il modello. Nell'esempio seguente viene illustrato come leggere il contenuto del file conda in variabili di ambiente:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
Nell'esempio seguente viene illustrato come usare il modello per registrare l'ambiente. Il contenuto del file conda del passaggio precedente viene passato al modello usando il condaFile parametro :
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
Importante
Quando si definisce un ambiente personalizzato per la distribuzione, assicurarsi che il azureml-inference-server-http pacchetto sia incluso nel file conda. Questo pacchetto è essenziale per il corretto funzionamento del server di inferenza. Se non si ha familiarità con il processo di creazione di un ambiente personalizzato, usare uno degli ambienti curati, come minimal-py-inference (per i modelli personalizzati che non usano mlflow) o mlflow-py-inference (per i modelli che usano mlflow). Questi ambienti curati sono disponibili nella scheda Ambienti dell'istanza di Azure Machine Learning Studio.
La configurazione della distribuzione usa il modello registrato che si vuole distribuire e l'ambiente registrato.
Usare gli asset registrati (modello e ambiente) nella definizione di distribuzione. Il frammento di codice seguente mostra il file endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml, con tutti gli input necessari per configurare una distribuzione:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
Per configurare una distribuzione, usare il modello e l'ambiente registrati:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Quando si esegue la distribuzione dallo studio, si crea un endpoint e una distribuzione da aggiungere al suddetto. In tale occasione, viene richiesto di immettere i nomi per l'endpoint e la distribuzione.
Usare tipi e immagini di istanze di CPU e GPU differenti
È possibile specificare i tipi di istanza CPU o GPU e le immagini nella definizione di distribuzione per la distribuzione locale e la distribuzione in Azure.
La definizione della distribuzione nel file blue-deployment-with-registered-assets.yml usa un'istanza Standard_DS3_v2di tipo generico e l'immagine Docker non GPU mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Per il calcolo GPU, scegliere una versione del tipo di calcolo GPU e un'immagine Docker GPU.
Per i tipi di istanza per utilizzo generico e GPU supportati, vedere l'elenco degli SKU degli endpoint online gestiti. Per un elenco delle immagini di base della CPU e della GPU di Azure Machine Learning, vedere Immagini di base di Azure Machine Learning.
È possibile specificare i tipi di istanza CPU o GPU e le immagini nella configurazione della distribuzione sia per la distribuzione locale che per la distribuzione in Azure.
In precedenza è stata configurata una distribuzione che usava un'istanza Standard_DS3_v2 di tipo generico e un'immagine Docker non GPU mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Per il calcolo GPU, scegliere una versione del tipo di calcolo GPU e un'immagine Docker GPU.
Per i tipi di istanza per utilizzo generico e GPU supportati, vedere l'elenco degli SKU degli endpoint online gestiti. Per un elenco delle immagini di base della CPU e della GPU di Azure Machine Learning, vedere Immagini di base di Azure Machine Learning.
La precedente registrazione dell'ambiente specifica un'immagine Docker non-GPU mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 passando il valore al modello environment-version.json tramite il parametro dockerImage. Per un calcolo GPU, fornire un valore per un'immagine Docker GPU al modello (usare il dockerImage parametro ) e fornire una versione del tipo di calcolo GPU al online-endpoint-deployment.json modello (usare il skuName parametro ).
Per i tipi di istanza per utilizzo generico e GPU supportati, vedere l'elenco degli SKU degli endpoint online gestiti. Per un elenco delle immagini di base della CPU e della GPU di Azure Machine Learning, vedere Immagini di base di Azure Machine Learning.
A questo punto, distribuire l'endpoint online in Azure.
Distribuisci in Azure
Creare l'endpoint nel cloud di Azure:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Creare la distribuzione denominata blue nell'endpoint:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
La creazione della distribuzione può richiedere fino a 15 minuti a seconda che l'ambiente o l'immagine sottostante venga compilata per la prima volta. Le distribuzioni successive che usano lo stesso ambiente vengono elaborate più velocemente.
Se si preferisce non bloccare la console dell'interfaccia della riga di comando, è possibile aggiungere il flag --no-wait al comando. Tuttavia, questa opzione arresta la visualizzazione interattiva dello stato della distribuzione.
Il flag --all-traffic usato in az ml online-deployment create usato per creare la distribuzione alloca il 100% del traffico dell'endpoint alla distribuzione blu appena creata. L'uso di questo flag è utile a scopo di sviluppo e test, ma per l'ambiente di produzione potrebbe essere necessario instradare il traffico alla nuova distribuzione tramite un comando esplicito. Ad esempio, usare az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100".
Creare l'endpoint:
Usando il endpoint parametro definito in precedenza e il MLClient parametro creato in precedenza, è ora possibile creare l'endpoint nell'area di lavoro. Questo comando avvia la creazione dell'endpoint e restituisce una risposta di conferma mentre la procedura è ancora in corso.
ml_client.online_endpoints.begin_create_or_update(endpoint)
Creare la distribuzione:
Usando il blue_deployment_with_registered_assets parametro definito in precedenza e il MLClient parametro creato in precedenza, è ora possibile creare la distribuzione nell'area di lavoro. Questo comando avvia la creazione della distribuzione e restituisce una risposta di conferma mentre la creazione della distribuzione è ancora in corso.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Se si preferisce non bloccare la console Python, è possibile aggiungere il flag no_wait=True ai parametri. Tuttavia, questa opzione arresta la visualizzazione interattiva dello stato della distribuzione.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
Creare un endpoint e una distribuzione online gestiti
Usare Studio per creare un endpoint online gestito direttamente nel browser. Quando si crea un endpoint online gestito in Studio, è necessario definire una distribuzione iniziale. Non è possibile creare un endpoint online gestito vuoto.
Un modo per creare un endpoint online gestito nello studio è dalla pagina Modelli . Questo metodo offre anche un modo semplice per aggiungere un modello a una distribuzione online gestita esistente. Per distribuire il modello denominato model-1 registrato in precedenza nella sezione Registrare il modello e l'ambiente :
Passare ad Azure Machine Learning Studio.
Nel riquadro sinistro selezionare la pagina Modelli .
Selezionare il modello denominato model-1.
Selezionare Distribuisci>Endpoint in tempo reale.
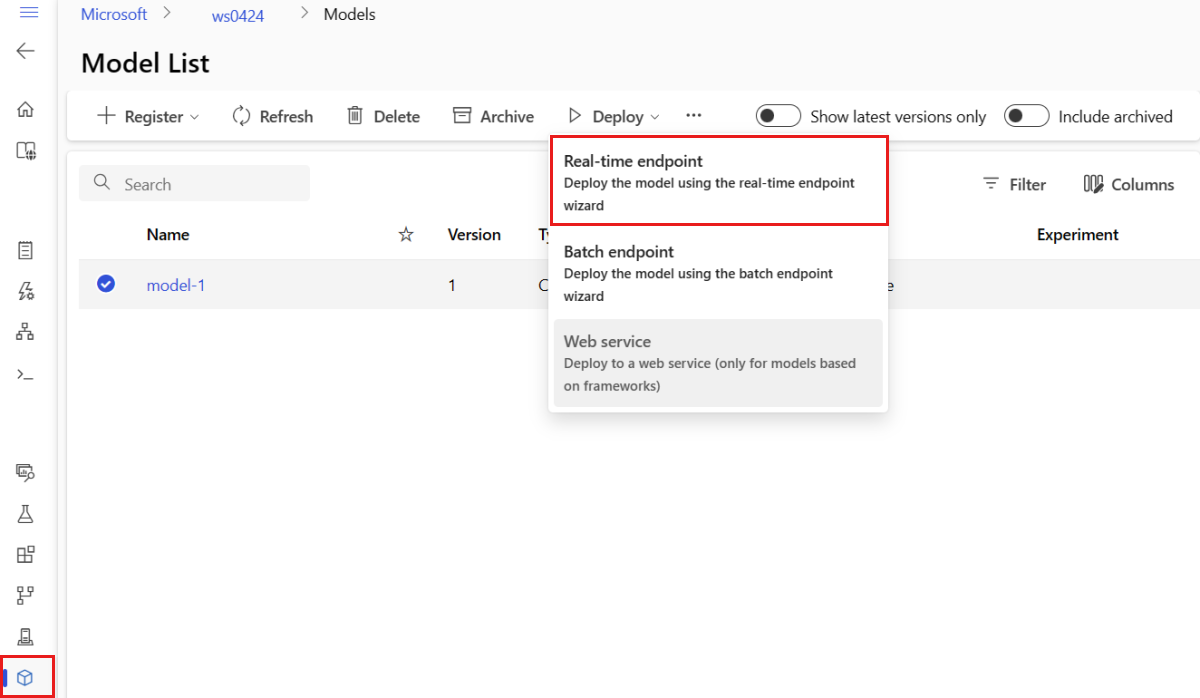
Questa azione apre una finestra in cui è possibile specificare i dettagli sull'endpoint.
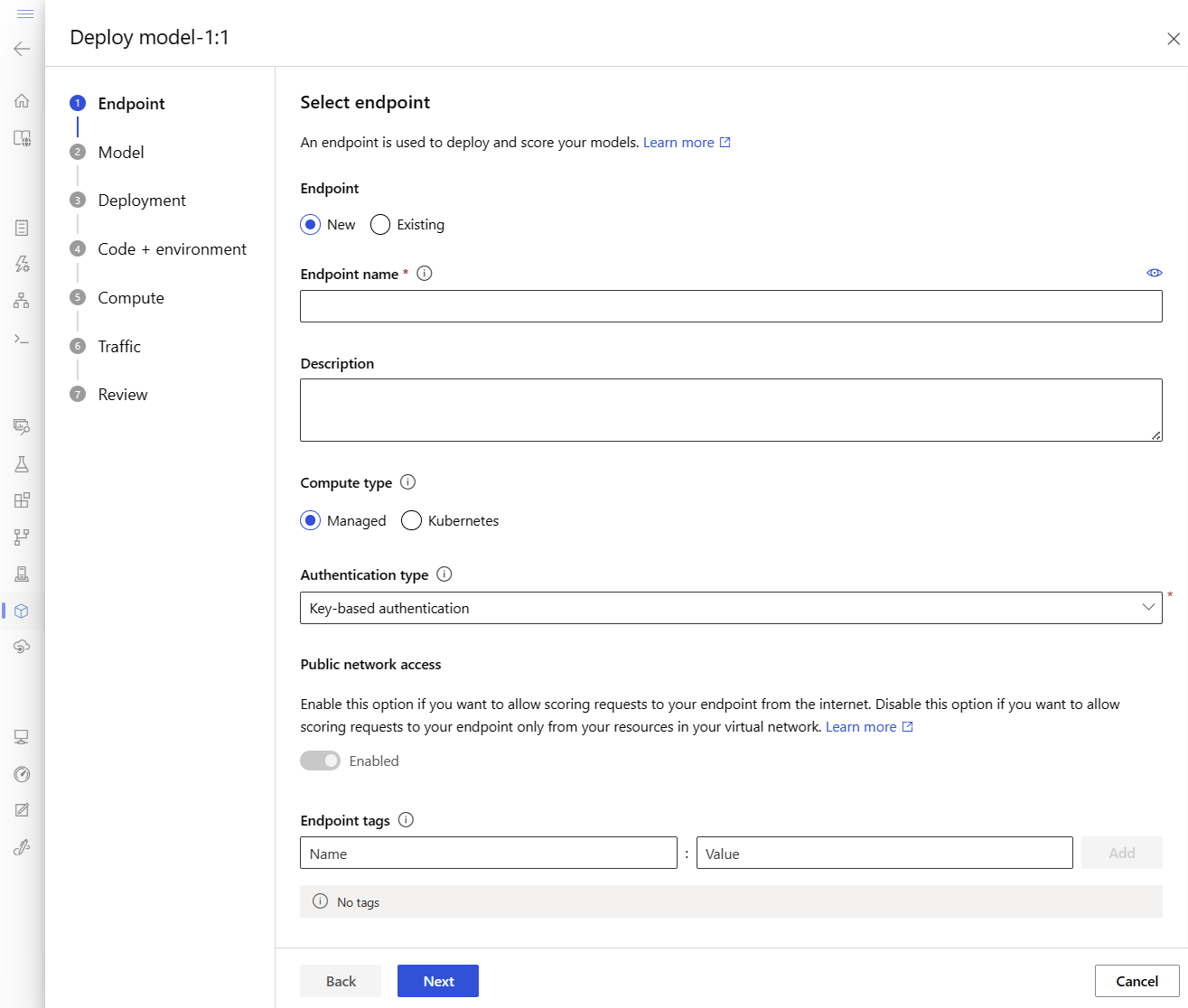
Immettere un nome di endpoint univoco nell'area di Azure. Per altre informazioni sulle regole di denominazione, vedere Limiti degli endpoint.
Mantenere la selezione predefinita: gestita per il tipo di calcolo.
Mantenere la selezione predefinita: autenticazione basata su chiave per il tipo di autenticazione. Per altre informazioni sull'autenticazione, vedere Autenticare i client per gli endpoint online.
Selezionare Avanti finché non si arriva alla pagina Distribuzione . Attivare o disattivare la diagnostica di Application Insights su Abilitato in modo che sia possibile visualizzare i grafici delle attività dell'endpoint in studio in un secondo momento e analizzare metriche e log usando Application Insights.
Selezionare Avanti per passare alla pagina Codice e ambiente . Selezionare le opzioni seguenti:
-
Selezionare uno script di assegnazione dei punteggi per l'inferenza: Sfoglia e seleziona il file \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py dal repository clonato o scaricato in precedenza.
-
Selezionare la sezione Ambiente: selezionareAmbienti personalizzati e quindi selezionare l'ambiente my-env:1 creato in precedenza.
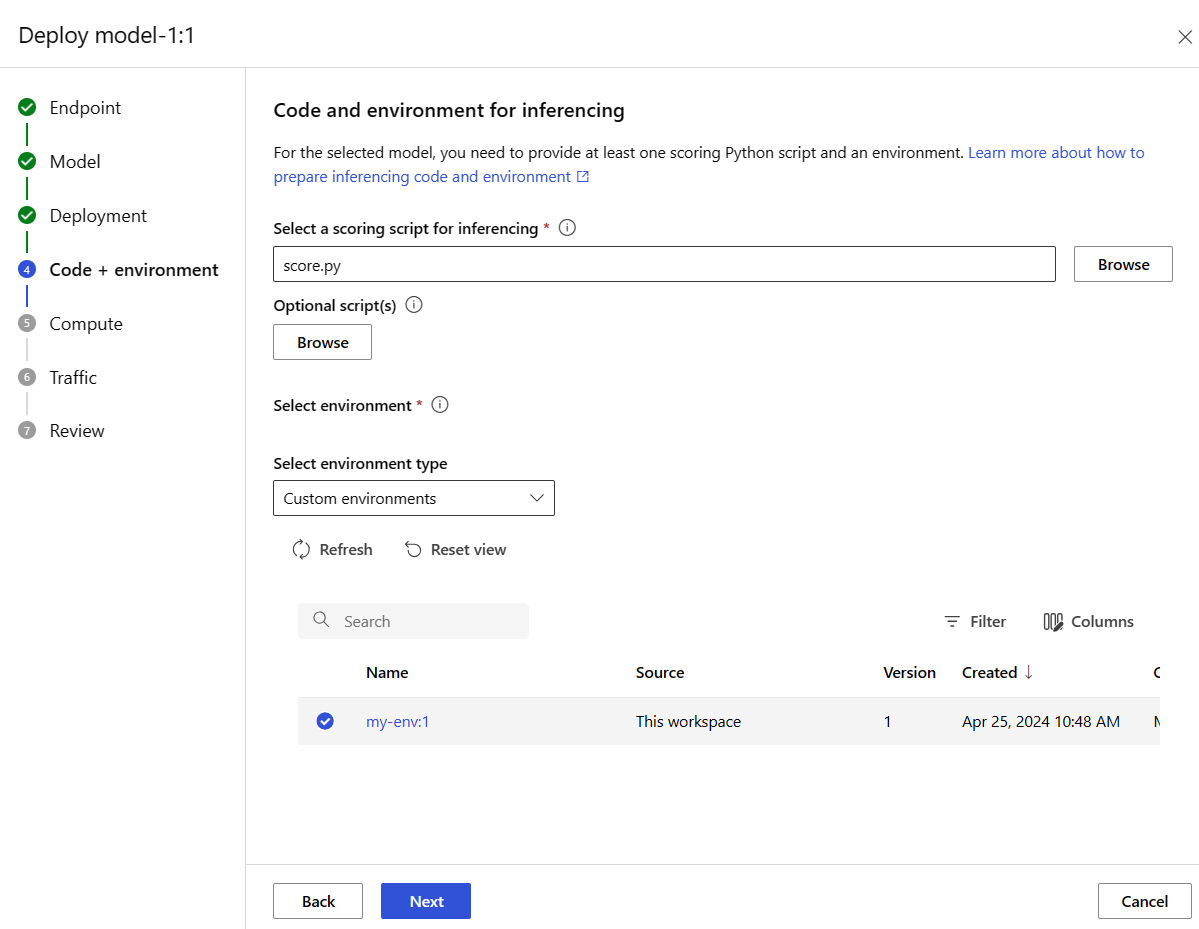
Selezionare Avanti e accettare le impostazioni predefinite fino a quando non viene richiesto di creare la distribuzione.
Esaminare le impostazioni di distribuzione e selezionare Crea.
In alternativa, è possibile creare un endpoint online gestito dalla pagina Endpoint in studio.
Passare ad Azure Machine Learning Studio.
Nel riquadro sinistro selezionare la pagina Endpoints.
Selezionare + Crea.
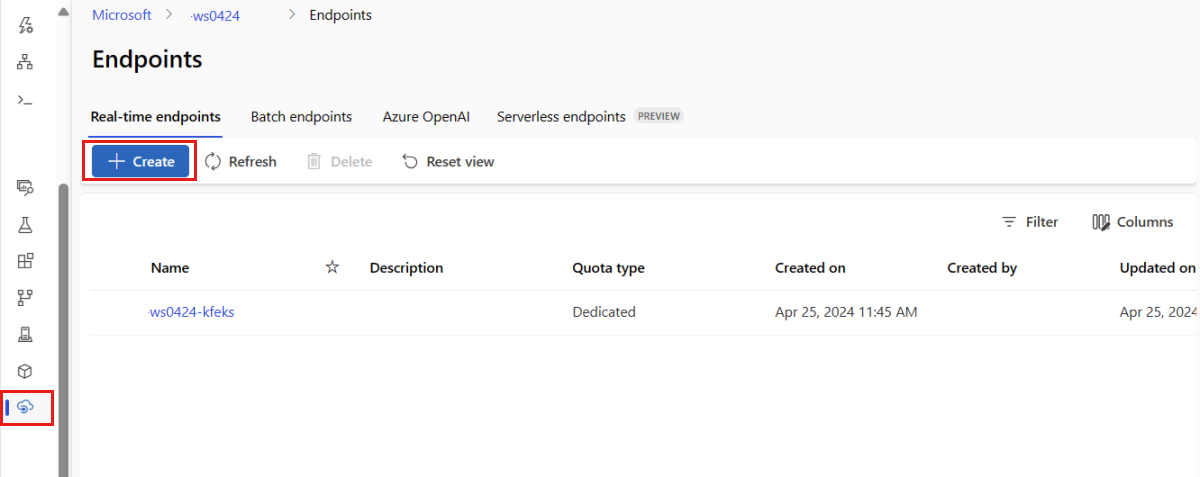
Questa azione apre una finestra in cui selezionare il modello e specificare i dettagli relativi all'endpoint e alla distribuzione. Immettere le impostazioni per l'endpoint e la distribuzione come descritto in precedenza e quindi selezionare Crea per creare la distribuzione.
Usare il modello per creare un endpoint online:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
Distribuire il modello nell'endpoint dopo la creazione dell'endpoint:
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
Per eseguire il debug degli errori nella distribuzione, vedere Risoluzione dei problemi relativi alle distribuzioni degli endpoint online.
Controllare lo stato dell'endpoint online
Usare il comando show per visualizzare le informazioni in provisioning_state per l'endpoint e la distribuzione:
az ml online-endpoint show -n $ENDPOINT_NAME
Elencare tutti gli endpoint nell'area di lavoro in un formato di tabella usando il comando list:
az ml online-endpoint list --output table
Controllare lo stato dell'endpoint per verificare se il modello è stato distribuito senza errori:
ml_client.online_endpoints.get(name=endpoint_name)
Elencare tutti gli endpoint nell'area di lavoro in un formato di tabella usando il metodo list:
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
Il metodo restituisce un elenco (iteratore) di ManagedOnlineEndpoint entità.
Per ottenere altre informazioni, è possibile specificare più parametri. Ad esempio, emettere l'elenco di endpoint come una tabella:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
Visualizzare gli endpoint online gestiti
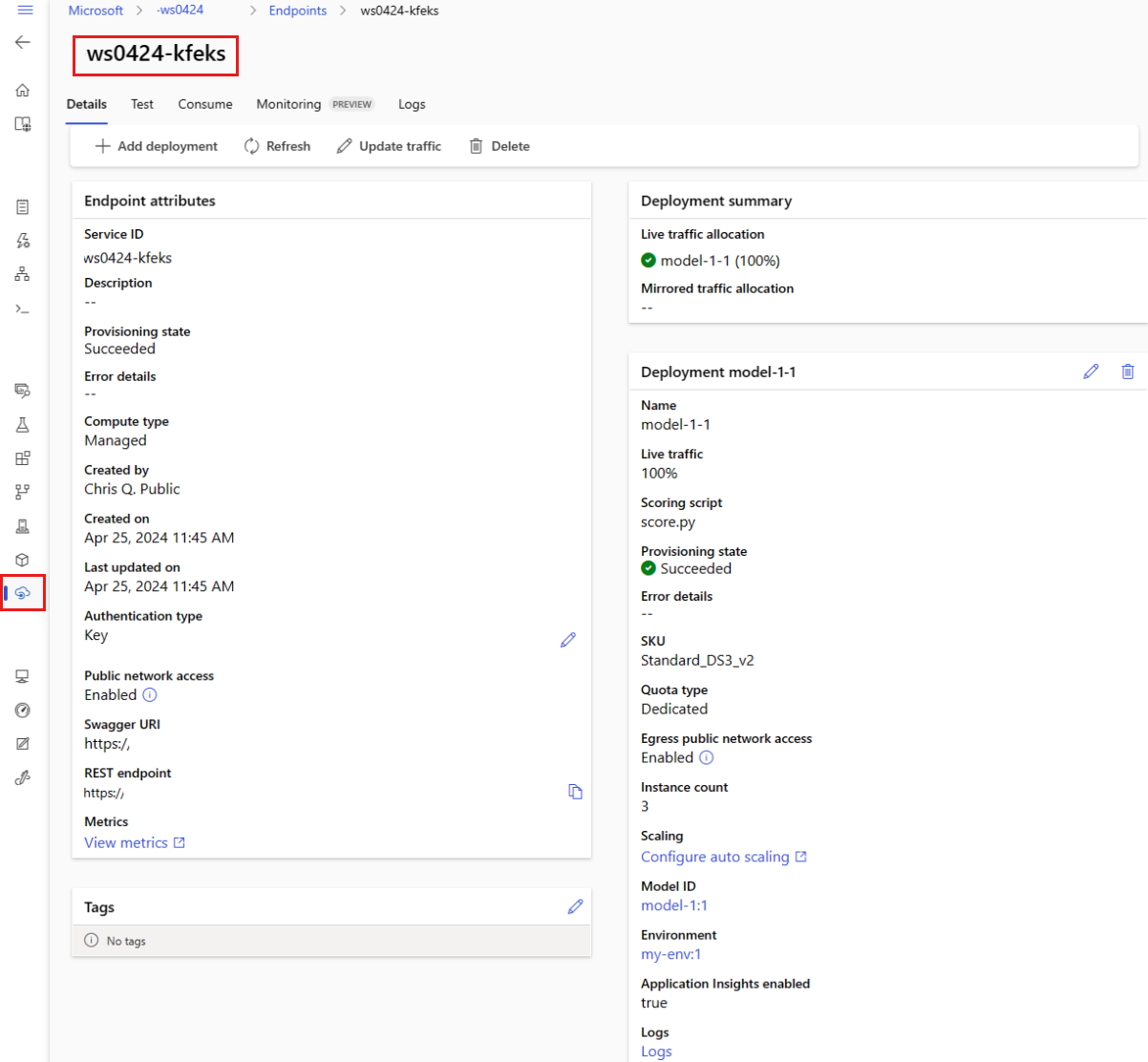
È possibile visualizzare tutti gli endpoint online gestiti nella pagina Endpoint . Passare alla pagina Dettagli dell'endpoint per trovare informazioni critiche, ad esempio l'URI dell'endpoint, lo stato, gli strumenti di test, i monitoraggi attività, i log di distribuzione e il codice di consumo di esempio.
Nel riquadro sinistro selezionare Endpoint per visualizzare un elenco di tutti gli endpoint nell'area di lavoro.
(Facoltativo) Creare un filtro per il tipo di calcolo per visualizzare solo i tipi di calcolo gestiti .
Selezionare un nome endpoint per visualizzare la pagina Dettagli dell'endpoint.
I modelli sono utili per la distribuzione delle risorse, ma non è possibile usarli per elencare, visualizzare o richiamare le risorse. Usare l'interfaccia della riga di comando di Azure, Python SDK o Studio per eseguire queste operazioni. Il codice seguente usa l'interfaccia della riga di comando di Azure.
Usare il show comando per visualizzare le informazioni nel provisioning_state parametro per l'endpoint e la distribuzione:
az ml online-endpoint show -n $ENDPOINT_NAME
Elencare tutti gli endpoint nell'area di lavoro in un formato di tabella usando il comando list:
az ml online-endpoint list --output table
Verificare lo stato della distribuzione online
Controllare i log per verificare se il modello è stato distribuito senza errori.
Per visualizzare l'output del log da un contenitore, usare il seguente comando dell'interfaccia della riga di comando:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Per impostazione predefinita, i log vengono estratti dal contenitore del server di inferenza. Per visualizzare i log dal contenitore dell'inizializzatore di archiviazione, aggiungere il flag --container storage-initializer. Per altre informazioni sui log di distribuzione, vedere Ottenere i log dei contenitori.
È possibile visualizzare questo output di log usando il metodo get_logs:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Per impostazione predefinita, i log vengono estratti dal contenitore del server di inferenza. Per visualizzare i log dal contenitore dell'inizializzatore di archiviazione, aggiungere l'opzione container_type="storage-initializer". Per altre informazioni sui log di distribuzione, vedere Ottenere i log dei contenitori.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
Per visualizzare l'output del log, selezionare la scheda Log nella pagina dell'endpoint. Se nell'endpoint sono presenti più distribuzioni, usare l'elenco a discesa per selezionare la distribuzione con il log che si vuole visualizzare.
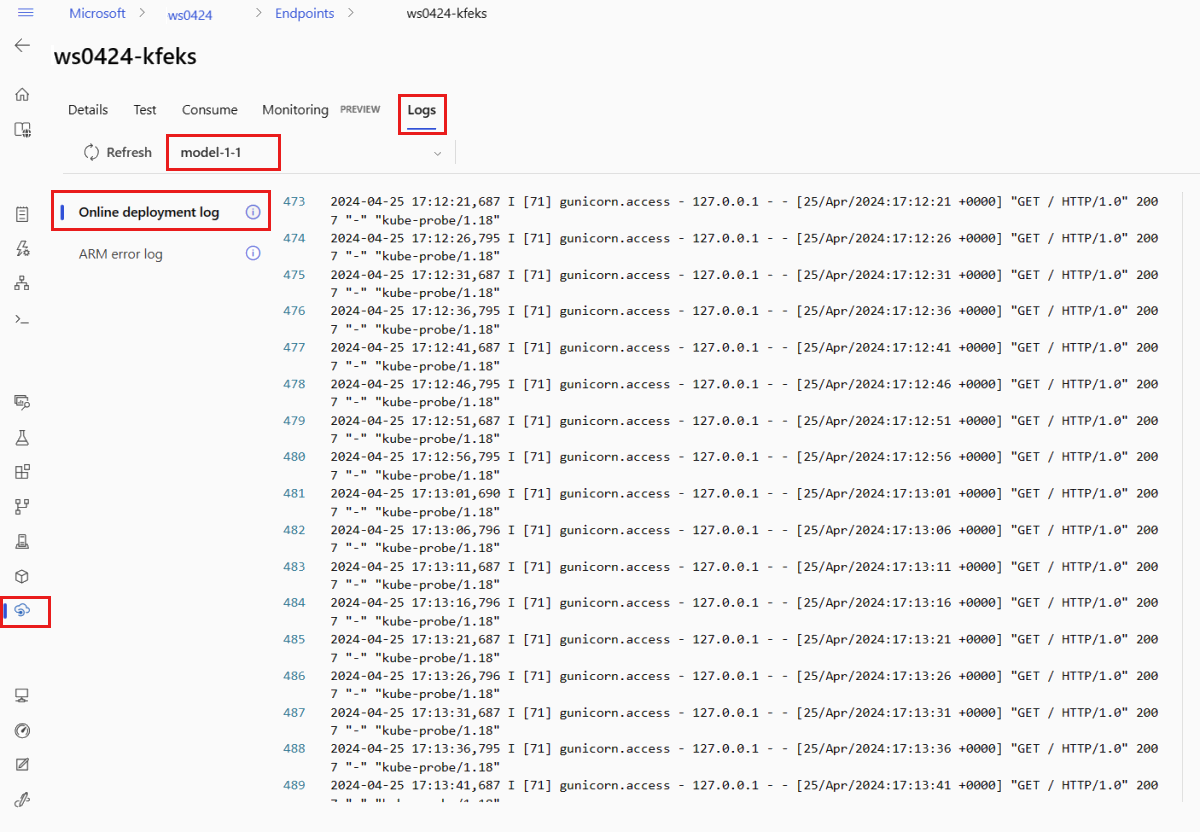
Per impostazione predefinita, i log vengono estratti dal server di inferenza. Per visualizzare i log estratti dal contenitore dell'inizializzatore di archiviazione, usare l'interfaccia della riga di comando di Azure o Python SDK (per informazioni dettagliate vedere le singole schede). I log estratti dal contenitore dell'inizializzatore di archiviazione forniscono informazioni sul fatto che il codice e i dati del modello siano stati o meno scaricati correttamente nel contenitore. Per altre informazioni sui log di distribuzione, vedere Ottenere i log dei contenitori.
I modelli sono utili per la distribuzione delle risorse, ma non è possibile usarli per elencare, visualizzare o richiamare le risorse. Usare l'interfaccia della riga di comando di Azure, Python SDK o Studio per eseguire queste operazioni. Il codice seguente usa l'interfaccia della riga di comando di Azure.
Per visualizzare l'output del log da un contenitore, usare il seguente comando dell'interfaccia della riga di comando:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Per impostazione predefinita, i log vengono estratti dal contenitore del server di inferenza. Per visualizzare i log dal contenitore dell'inizializzatore di archiviazione, aggiungere il flag --container storage-initializer. Per altre informazioni sui log di distribuzione, vedere Ottenere i log dei contenitori.
Richiamare l'endpoint per assegnare un punteggio ai dati usando il modello
Usare il comando invoke o un client REST di propria scelta per richiamare l'endpoint e assegnare un punteggio ad alcuni dati:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Ottenere la chiave usata per l'autenticazione all'endpoint:
È possibile controllare quali entità di sicurezza di Microsoft Entra possono ottenere la chiave di autenticazione assegnandole a un ruolo personalizzato che consente Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action e Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action. Per altre informazioni su come gestire l'autorizzazione per le aree di lavoro, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
Usare curl per assegnare punteggi ai dati.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
Si noti che si utilizzano i comandi show e get-credentials per ottenere le credenziali di autenticazione. Si noti anche che si usa il --query flag per filtrare solo gli attributi necessari. Per altre informazioni sul flag --query, vedere Eseguire query sull'output dei comandi dell'interfaccia della riga di comando di Azure.
Per visualizzare i log delle chiamate, eseguire nuovamente get-logs.
Usando il MLClient parametro creato in precedenza, si ottiene un handle per l'endpoint. È quindi possibile richiamare l'endpoint usando il invoke comando con i parametri seguenti:
-
endpoint_name: nome dell'endpoint.
-
request_file: file con i dati della richiesta.
-
deployment_name: nome della distribuzione specifica da testare in un endpoint.
Inviare una richiesta di esempio usando un file JSON .
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
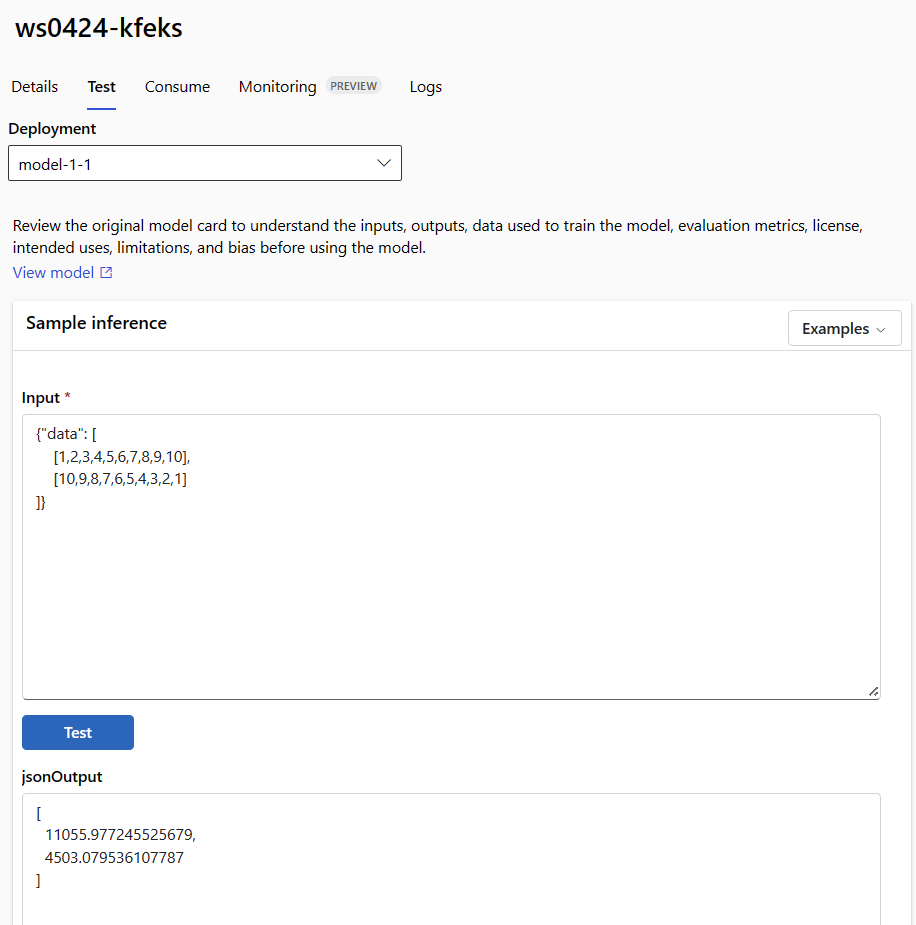
Usare la scheda Test nella pagina dei dettagli dell'endpoint per testare la distribuzione online gestita. Immettere l'input di esempio e visualizzare i risultati.
Selezionare la scheda Test nella pagina dei dettagli dell'endpoint.
Usare l'elenco a discesa per selezionare la distribuzione da testare.
Immettere l'input di esempio.
Selezionare Test.
I modelli sono utili per la distribuzione delle risorse, ma non è possibile usarli per elencare, visualizzare o richiamare le risorse. Usare l'interfaccia della riga di comando di Azure, Python SDK o Studio per eseguire queste operazioni. Il codice seguente usa l'interfaccia della riga di comando di Azure.
Usare il comando invoke o un client REST di propria scelta per richiamare l'endpoint e assegnare un punteggio ad alcuni dati:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(Facoltativo) Aggiornare la distribuzione
Se si vuole aggiornare il codice, il modello o l'ambiente, aggiornare il file YAML. Eseguire quindi il az ml online-endpoint update comando .
Se si aggiorna il numero di istanze (per ridimensionare la distribuzione) insieme ad altre impostazioni del modello (ad esempio codice, modello o ambiente) in un singolo update comando, l'operazione di ridimensionamento viene eseguita per prima. Gli altri aggiornamenti vengono applicati successivamente. È consigliabile eseguire queste operazioni separatamente in un ambiente di produzione.
Per comprendere il funzionamento di update:
Aprire il file online/model-1/onlinescoring/score.py.
Modificare l'ultima riga della funzione init(): dopo logging.info("Init complete"), aggiungere logging.info("Updated successfully").
Salvare il file.
Eseguire questo comando:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
L'aggiornamento tramite YAML è dichiarativo. Ciò significa che le modifiche apportate al file YAML si riflettono nelle risorse di Resource Manager sottostanti (endpoint e distribuzioni). Un approccio dichiarativo facilita GitOps: tutte le modifiche apportate agli endpoint e alle distribuzioni (anche instance_count) passano attraverso YAML.
È possibile usare parametri di aggiornamento generici, ad esempio il --set parametro , con il comando dell'interfaccia update della riga di comando per eseguire l'override degli attributi nel file YAML o per impostare attributi specifici senza passarli nel file YAML. L'uso di --set per attributi singoli è particolarmente utile negli scenari di sviluppo e test. Ad esempio, per aumentare il valore instance_count per la prima distribuzione, è possibile usare il flag --set instance_count=2. Tuttavia, poiché YAML non viene aggiornato, questa tecnica non facilita GitOps.
Specificare il file YAML non è obbligatorio. Ad esempio, se si vuole testare impostazioni di concorrenza diverse per una distribuzione specifica, è possibile provare qualcosa come az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4. Questo approccio mantiene tutta la configurazione esistente, ma aggiorna solo i parametri specificati.
Poiché la init() funzione è stata modificata, che viene eseguita quando l'endpoint viene creato o aggiornato, il messaggio Updated successfully viene visualizzato nei log. Recuperare i log eseguendo:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Il comando update funziona anche con le distribuzioni locali. Usare lo stesso comando az ml online-deployment update con il flag --local.
Se si vuole aggiornare il codice, il modello o l'ambiente, aggiornare la configurazione e quindi eseguire il MLClientmetodo di online_deployments.begin_create_or_update per creare o aggiornare una distribuzione.
Se si aggiorna il numero di istanze (per ridimensionare la distribuzione) insieme ad altre impostazioni del modello (ad esempio codice, modello o ambiente) in un singolo begin_create_or_update metodo, l'operazione di ridimensionamento viene eseguita per prima. Vengono quindi applicati gli altri aggiornamenti. È consigliabile eseguire queste operazioni separatamente in un ambiente di produzione.
Per comprendere il funzionamento di begin_create_or_update:
Aprire il file online/model-1/onlinescoring/score.py.
Modificare l'ultima riga della funzione init(): dopo logging.info("Init complete"), aggiungere logging.info("Updated successfully").
Salvare il file.
Eseguire il metodo:
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Poiché la init() funzione è stata modificata, che viene eseguita quando l'endpoint viene creato o aggiornato, il messaggio Updated successfully viene visualizzato nei log. Recuperare i log eseguendo:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Il metodo begin_create_or_update funziona anche con le distribuzioni locali. Usare lo stesso metodo con il flag local=True.
Attualmente, è possibile apportare aggiornamenti solo al numero di istanze di una distribuzione. Usare le istruzioni seguenti per aumentare o ridurre le prestazioni di una singola distribuzione modificando il numero di istanze:
- Apri la pagina Dettagli dell'endpoint e individua la scheda per la distribuzione che si vuole aggiornare.
- Selezionare l'icona di modifica (icona a forma di matita) accanto al nome della distribuzione.
- Aggiornare il numero di istanze associato alla distribuzione. Scegli tra Predefinito o Utilizzo mirato per Tipo di scalabilità di distribuzione.
- Se si seleziona Predefinito, è anche possibile specificare un valore numerico per Numero di istanze.
- Se si seleziona Utilizzo destinazione, è possibile specificare i valori da usare per i parametri quando si ridimensiona automaticamente la distribuzione.
- Selezionare Aggiorna per completare l'aggiornamento dei conteggi delle istanze per la distribuzione.
Attualmente non è disponibile un'opzione per aggiornare la distribuzione utilizzando un modello di Resource Manager.
Note
L'aggiornamento della distribuzione in questa sezione è un esempio di aggiornamento in sequenza sul posto.
- Per un endpoint online gestito, la distribuzione viene aggiornata alla nuova configurazione con il 20% dei nodi alla volta. Ciò significa, che se la distribuzione ha 10 nodi, sono aggiornati 2 nodi alla volta.
- Per un endpoint online Kubernetes, il sistema crea in modo iterativo una nuova istanza di distribuzione con la nuova configurazione ed eliminerà quella precedente.
- Per l'utilizzo di produzione, prendere in considerazione la distribuzione blu-verde, che offre un'alternativa più sicura per l'aggiornamento di un servizio Web.
La scalabilità automatica usa automaticamente la quantità corretta di risorse per gestire il carico dell'applicazione. Gli endpoint online gestiti supportano la scalabilità automatica tramite l'integrazione con la funzionalità di scalabilità automatica di Monitoraggio di Azure. Per configurare la scalabilità automatica, vedere Ridimensionare automaticamente gli endpoint online.
(Facoltativo) Monitorare il contratto di servizio usando Monitoraggio di Azure
Per visualizzare le metriche e impostare gli avvisi in base al contratto di servizio, seguire i passaggi descritti in Monitorare gli endpoint online.
(Facoltativo) Eseguire l'integrazione con Log Analytics
Il get-logs comando per l'interfaccia della riga di comando o il get_logs metodo per l'SDK fornisce solo le ultime centinaia di righe di log da un'istanza selezionata automaticamente. Tuttavia, Log Analytics consente di archiviare e analizzare i log in modo durevole. Per altre informazioni su come usare la registrazione, vedere Usare i log.
Eliminare l'endpoint e la distribuzione
Usare il comando seguente per eliminare l'endpoint e tutte le distribuzioni sottostanti:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Usare il comando seguente per eliminare l'endpoint e tutte le distribuzioni sottostanti:
ml_client.online_endpoints.begin_delete(name=endpoint_name)
Se non si intende usare l'endpoint e la distribuzione, eliminarli. Eliminando l'endpoint, vengono eliminate anche tutte le distribuzioni sottostanti.
- Passare ad Azure Machine Learning Studio.
- Nel riquadro sinistro selezionare la pagina Endpoints.
- Selezionare un endpoint.
- Selezionare Elimina.
In alternativa, è possibile eliminare direttamente un endpoint online gestito selezionando l'icona Elimina nella pagina dei dettagli dell'endpoint.
Usare il comando seguente per eliminare l'endpoint e tutte le distribuzioni sottostanti:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Contenuti correlati









