Come distribuire modelli Cohere Command con lo studio di Azure Machine Learning
Cohere offre due modelli Command nello studio di Azure Machine Learning. Questi modelli sono disponibili come API serverless con la fatturazione basata su token con pagamento in base al consumo.
- Cohere Command R
- Cohere Command R+
È possibile esplorare la famiglia di modelli Cohere nel catalogo dei modelli filtrando in base alla raccolta Cohere.
Modelli
Questo articolo illustra come usare studio di Azure Machine Learning per distribuire i modelli di comando Cohere come API serverless con pagamento in base al consumo.
Cohere Command R
Command R è un modello LLM (Large Language Model) generativo ad alte prestazioni, ottimizzato per un'ampia gamma di casi d'uso, tra cui motivazione, riepilogo e risposta alla domanda.
Architettura del modello: si tratta di un modello linguistico autoregressivo che usa l'architettura di un trasformatore ottimizzata. Dopo il training preliminare, questo modello usa il processo SFT (Supervised Fine-Tuning) e il training delle preferenze per allineare il comportamento del modello alle preferenze umane a vantaggio dell'utilità e della sicurezza.
Lingue supportate: Il modello è ottimizzato per conseguire ottime prestazioni nelle lingue seguenti: inglese, francese, spagnolo, italiano, tedesco, portoghese brasiliano, giapponese, coreano, cinese semplificato e arabo.
I dati di training preliminare includono anche le 13 lingue seguenti: russo, polacco, turco, vietnamita, olandese, ceco, indonesiano, ucraino, romeno, greco, hindi, ebraico, persiano.
Lunghezza del contesto: Command R supporta una lunghezza del contesto di 128K.
Input: nei modelli viene inserito solo testo.
Output: i modelli generano solo testo.
Cohere Command R+
Command R+ è un modello LLM (Large Language Model) generativo ad alte prestazioni, ottimizzato per un'ampia gamma di casi d'uso, tra cui motivazione, riepilogo e risposta alla domanda.
Architettura del modello: si tratta di un modello linguistico autoregressivo che usa l'architettura di un trasformatore ottimizzata. Dopo il training preliminare, questo modello usa il processo SFT (Supervised Fine-Tuning) e il training delle preferenze per allineare il comportamento del modello alle preferenze umane a vantaggio dell'utilità e della sicurezza.
Lingue supportate: Il modello è ottimizzato per conseguire ottime prestazioni nelle lingue seguenti: inglese, francese, spagnolo, italiano, tedesco, portoghese brasiliano, giapponese, coreano, cinese semplificato e arabo.
I dati di training preliminare includono anche le 13 lingue seguenti: russo, polacco, turco, vietnamita, olandese, ceco, indonesiano, ucraino, romeno, greco, hindi, ebraico, persiano.
Lunghezza del contesto: Command R+ supporta una lunghezza del contesto di 128K.
Input: nei modelli viene inserito solo testo.
Output: i modelli generano solo testo.
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Distribuire come API serverless
Alcuni modelli nel catalogo modelli possono essere distribuiti come API serverless con la fatturazione di pagamenti in base al consumo. Questo metodo di distribuzione consente di usare i modelli come API senza ospitarli nella sottoscrizione, mantenendo al tempo stesso le organizzazioni di sicurezza e conformità aziendali necessarie. Questa opzione di distribuzione non richiede la quota dalla sottoscrizione.
I modelli Cohere indicati in precedenza possono essere distribuiti come API serverless con pagamento in base al consumo e sono offerti da Cohere tramite Microsoft Azure Marketplace. Cohere può modificare o aggiornare le condizioni per l'utilizzo e i prezzi di questo modello.
Prerequisiti
Una sottoscrizione di Azure con un metodo di pagamento valido. Le sottoscrizioni di Azure gratuite o di valutazione non funzioneranno. Se non si dispone di una sottoscrizione di Azure, è possibile creare un account Azure gratuito per iniziare.
Un'area di lavoro di Azure Machine Learning. Se non sono disponibili, seguire la procedura descritta nell'articolo Avvio rapido: Creare risorse dell'area di lavoro per crearle.
Importante
L'offerta di distribuzione di modelli con pagamento in base al consumo è disponibile solo nelle aree di lavoro create all'interno delle aree Stati Uniti orientali 2 e Svezia centrale.
I controlli degli accessi in base al ruolo di Azure vengono usati per concedere l'accesso alle operazioni. Per eseguire la procedura descritta in questo articolo, all'account utente deve essere assegnato il ruolo di sviluppatore di Azure per intelligenza artificiale nel gruppo di risorse.
Per altre informazioni sulle autorizzazioni, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning.
Creare una nuova distribuzione
Per creare una distribuzione:
Passare ad Azure Machine Learning Studio.
Selezionare l'area di lavoro in cui distribuire i modelli. Per usare l'offerta di distribuzione api serverless, l'area di lavoro deve appartenere all'area EastUS2 o Svezia centrale.
Scegliere il modello da distribuire dal catalogo modelli.
In alternativa, è possibile avviare la distribuzione passando all'area di lavoro e selezionando Endpoint>Endpoint serverless>Crea.
Nella pagina di panoramica del modello nel catalogo dei modelli selezionare Distribuisci.

Nella distribuzione guidata selezionare il collegamento a Condizioni di Azure Marketplace per altre informazioni sulle condizioni per l'utilizzo.
È anche possibile selezionare la scheda Dettagli sull'offerta in Marketplace per informazioni sui prezzi per il modello selezionato.
Se è la prima volta che si distribuisce il modello nell'area di lavoro, è necessario sottoscrivere l'area di lavoro per l'offerta specifica del modello. Questo passaggio richiede che l'account disponga delle autorizzazioni associate al ruolo di sviluppatore di Azure per intelligenza artificiale per il gruppo di risorse, come indicato nei prerequisiti. Ogni area di lavoro ha una propria sottoscrizione per l'offerta specifica di Azure Marketplace, che consente di controllare e monitorare la spesa. Selezionare Sottoscrivi e distribuisci. Attualmente è possibile avere una sola distribuzione per ogni modello all'interno di un'area di lavoro.
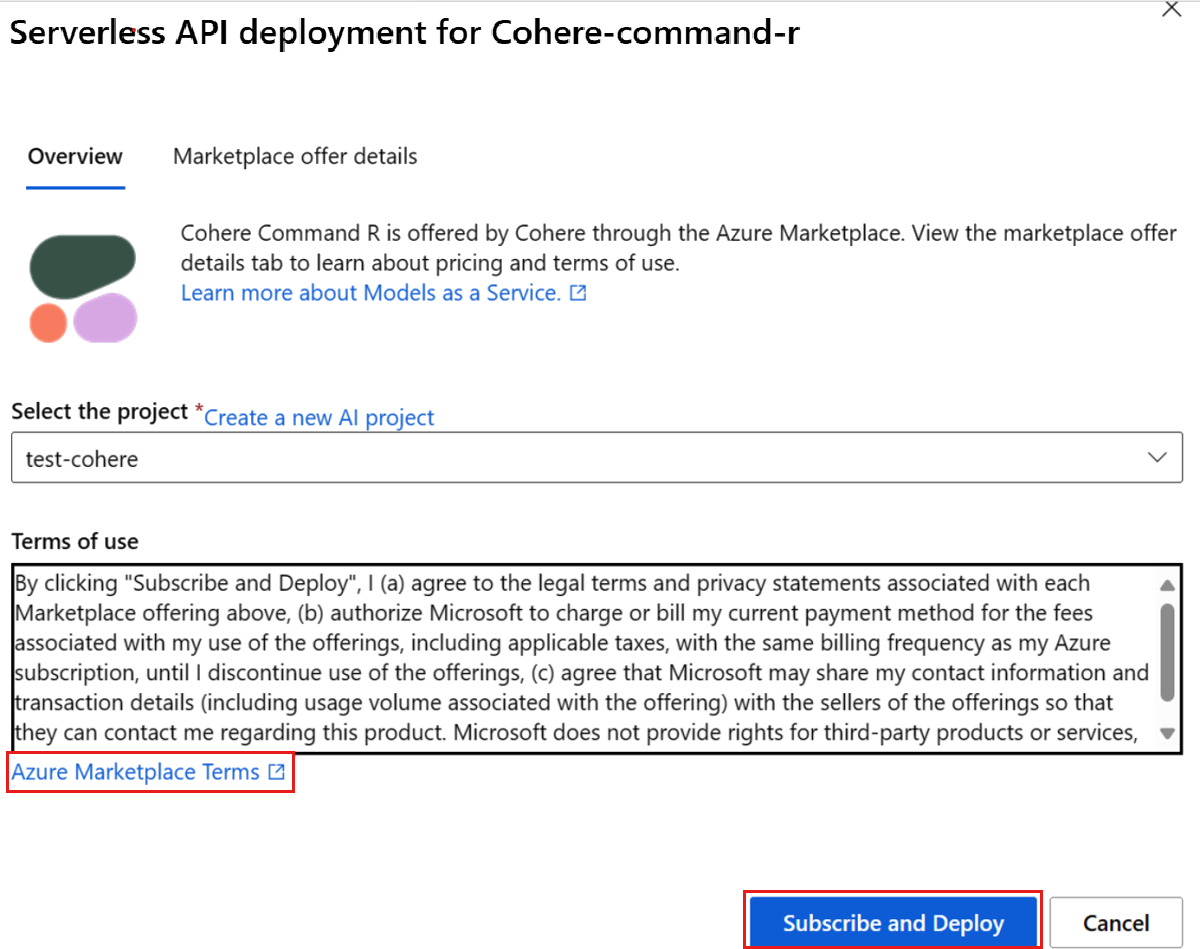
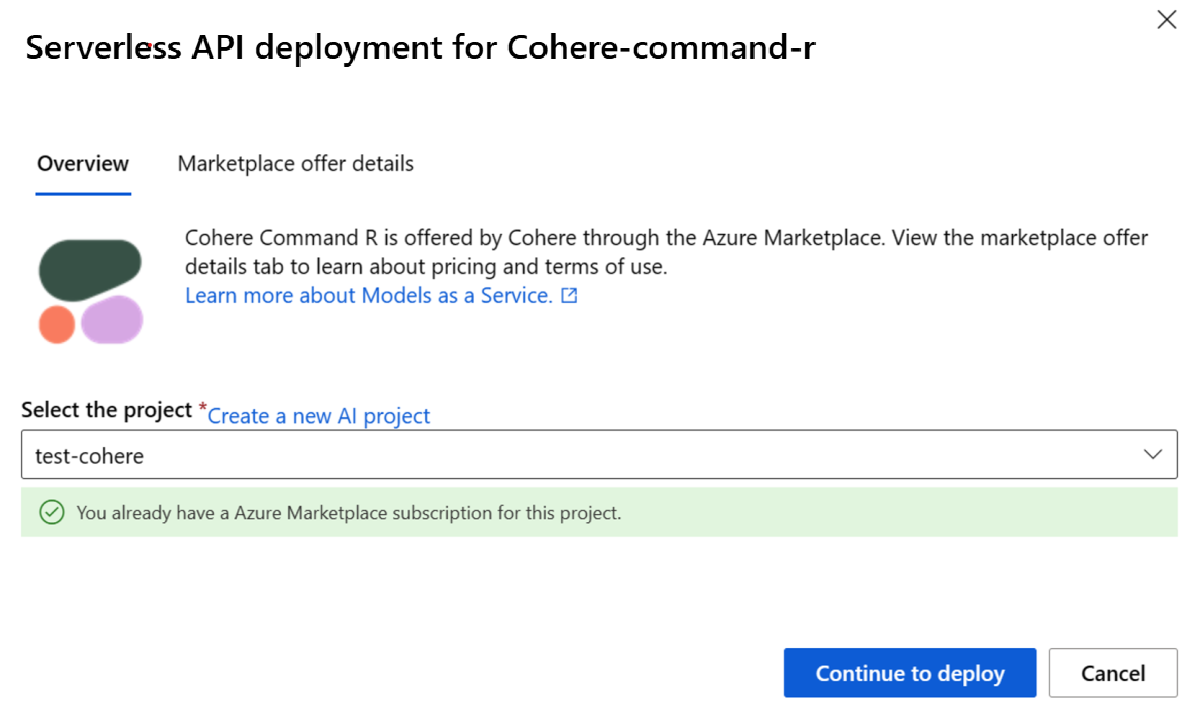
Dopo la sottoscrizione dell’area di lavoro a una determinata offerta di Azure Marketplace, le distribuzioni successive della stessa offerta nello stesso progetto non richiedono una nuova sottoscrizione. Se questo scenario si applica all'utente, verrà visualizzata un'opzione Continua a distribuire da selezionare.
Assegnare un nome alla distribuzione. Questo nome diventa parte dell'URL dell'API di distribuzione. Questo URL deve essere univoco in ogni area di Azure.
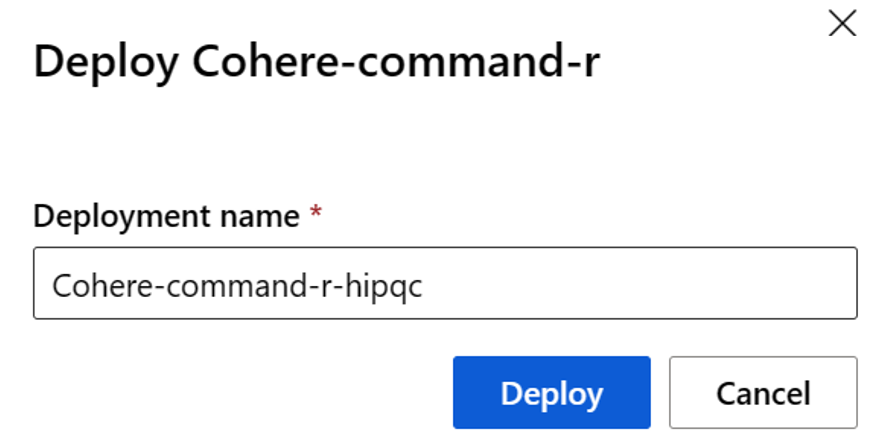
Seleziona Distribuisci. Attendere il completamento della distribuzione e si viene reindirizzati alla pagina endpoint serverless.
Selezionare l'endpoint per aprire la relativa pagina Dettagli.
Selezionare la scheda Test per iniziare a interagire con il modello.
È sempre possibile trovare i dettagli, l'URL e le chiavi di accesso dell'endpoint passando a Area di lavoro>Endpoint>Endpoint serverless.
Prendere nota dell'URL di Destinazione e della Chiave privata. Per altre informazioni sull'uso delle API, vedere la sezione di riferimento.




Per informazioni sulla fatturazione per i modelli distribuiti con pagamento in base al consumo, vedere Considerazioni sui costi e sulle quote per i modelli Cohere distribuiti come servizio.
Usare i modelli Cohere come servizio
I modelli Cohere indicati in precedenza possono essere usati tramite l'API Chat.
- Nell'area di lavoro, selezionare Endpoint>Endpoint serverless.
- Trovare e selezionare la distribuzione creata.
- Copiare l'URL Target e i valori del token Chiave.
- Cohere espone due route per l'inferenza con i modelli Command R e Command R+. L'API di inferenza del modello di Azure per intelligenza artificiale sulla route
/chat/completionse l'API Cohere nativa.
Per altre informazioni sull'uso delle API, vedere la sezione di riferimento.
Informazioni di riferimento per i modelli Cohere distribuiti come API serverless
I modelli Cohere Command R e Command R+ accettano sia l'API di inferenza del modello di Azure per intelligenza artificiale sulla route /chat/completions sia l'API Cohere Chat nativa in /v1/chat.
API di inferenza del modello di Azure per intelligenza artificiale
Lo schema dell'API di inferenza del modello di Azure per intelligenza artificiale è disponibile nell'articolo di riferimento sui completamenti delle chat. È inoltre possibile ottenere una specifica OpenAPI dall'endpoint stesso.
API Cohere Chat
Di seguito sono riportati alcuni dettagli sull'API Cohere Chat.
Richiedi
POST /v1/chat HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Schema della richiesta v1/chat
Cohere Command R e Command R+ accettano i parametri seguenti per una chiamata di inferenza della risposta v1/chat:
| Chiave | Type | Default | Descrizione |
|---|---|---|---|
message |
string |
Richiesto | Input di testo per il modello a cui rispondere. |
chat_history |
array of messages |
None |
Elenco dei messaggi precedenti tra l'utente e il modello, finalizzato a fornire il contesto di conversazione del modello per rispondere al messaggio dell'utente. |
documents |
array |
None |
Elenco dei documenti pertinenti che il modello può indicare per generare una risposta più accurata. Ogni documento è un dizionario stringa-stringa. Le chiavi e i valori di ogni documento vengono serializzati in una stringa e passati al modello. Il risultato è la generazione di citazioni che fanno riferimento ad alcuni di questi documenti. Possibili chiavi includono: "text", "author" e "date". Per una qualità di generazione migliore, mantenere il numero totale di parole delle stringhe nel dizionario sotto 300. Facoltativamente, è possibile specificare un campo _excludes (matrice di stringhe) per escludere alcune coppie chiave-valore dalla visualizzazione nel modello. I campi esclusi vengono comunque visualizzati nell'oggetto citazione. Il campo "_excludes" non viene passato al modello. Vedere la guida alla Modalità documento nella documentazione di Cohere. |
search_queries_only |
boolean |
false |
Se true, la risposta contiene solo un elenco delle query di ricerca generate, ma non viene eseguita alcuna ricerca e dal modello non viene generata alcuna risposta all'oggetto message dell'utente. |
stream |
boolean |
false |
Se true, la risposta è un flusso di eventi JSON. L'evento finale contiene la risposta completa e ha un event_type corrispondente a "stream-end". Lo streaming è utile per le interfacce utente che eseguono il rendering del contenuto della risposta, sezione per sezione, mentre viene generata. |
max_tokens |
integer |
None | Numero massimo di token generati dal modello nell'ambito della risposta. Nota: l'impostazione di un valore basso potrebbe determinare generazioni incomplete. Se questo valore non viene specificato, vengono generati token fino alla fine della sequenza. |
temperature |
float |
0.3 |
Usare un valore inferiore per ridurre la casualità nella risposta, che può essere invece accresciuta aumentando il valore del parametro p. Il valore minimo è 0, il valore massimo 2. |
p |
float |
0.75 |
Usare un valore inferiore per ignorare le opzioni meno probabili. Impostarlo su 0 o 1.0 per disabilitare questo parametro. Se sono abilitati sia p che k, p entra in azione dopo k. Il valore minimo è 0,01, il valore massimo 0,99. |
k |
float |
0 |
Specificare il numero di token tra cui sceglie il modello per generare il token successivo. Se sono abilitati sia p che k, p entra in azione dopo k. Il valore minimo è 0, il valore massimo 500. |
prompt_truncation |
enum string |
OFF |
Accetta AUTO_PRESERVE_ORDER, AUTO e OFF. Determina il modo in cui viene costruita la richiesta. Con prompt_truncation impostato su AUTO_PRESERVE_ORDER, alcuni elementi di chat_history e documents vengono rimossi per costruire una richiesta che soddisfi i limiti di lunghezza del contesto specificati per il modello. Durante questo processo, viene mantenuto l'ordine dei documenti e della cronologia della chat. Con prompt_truncation impostato su "OFF", non viene rimosso alcun elemento. |
stop_sequences |
array of strings |
None |
Il testo generato viene tagliato alla fine della prima occorrenza di una sequenza di arresto. La sequenza è inclusa nel testo. |
frequency_penalty |
float |
0 |
Consente di ridurre la ripetitività dei token generati. Maggiore è il valore, più alta sarà la penalità applicata ai token presenti in precedenza, proporzionalmente al numero di volte in cui sono già apparsi nella richiesta o nella generazione precedente. Il valore minimo è 0,0, il valore massimo 1,0. |
presence_penalty |
float |
0 |
Consente di ridurre la ripetitività dei token generati. Simile a frequency_penalty, tranne per il fatto che questa penalità viene applicata equamente a tutti i token già apparsi, indipendentemente dalle relative frequenze esatte. Il valore minimo è 0,0, il valore massimo 1,0. |
seed |
integer |
None |
Se specificato, il back-end effettua tutti i tentativi possibili per campionare i token in modo deterministico, in modo che le richieste ripetute con lo stesso valore di inizializzazione e gli stessi parametri restituiscano lo stesso risultato. Il determinismo, tuttavia, non può essere garantito. |
return_prompt |
boolean |
false |
Restituisce la risposta completo inviato al modello se true. |
tools |
array of objects |
None |
Il campo è soggetto a variazioni. Elenco degli strumenti (funzioni) disponibili che il modello può suggerire di richiamare prima di produrre una risposta testuale. Se viene passato tools (senza tool_results), il campo text della risposta è "", mentre nel campo tool_calls della risposta viene inserito un elenco di chiamate di strumenti da effettuare. Se non è necessario effettuare alcuna chiamata, la matrice tool_calls è vuota. |
tool_results |
array of objects |
None |
Il campo è soggetto a variazioni. Elenco dei risultati ottenuti chiamando gli strumenti consigliati dal modello nel turno precedente della chat. I risultati vengono usati per produrre una risposta testuale; ad essi viene inoltre fatto riferimento nelle citazioni. Se si usa tool_results, deve essere passato anche tools. Ogni voce tool_result contiene informazioni su come è stata richiamata e un elenco di output sotto forma di dizionari. L'esclusiva logica di citazione con granularità fine di Cohere richiede che l'output sia costituito da un elenco. Nel caso in cui l'output sia composto invece da un solo elemento, ad esempio, {"status": 200}, eseguirne il wrapping all'interno di un elenco. |
L'oggetto chat_history richiede i campi seguenti:
| Chiave | Type | Descrizione |
|---|---|---|
role |
enum string |
Accetta USER, SYSTEM o CHATBOT. |
message |
string |
Contenuto del testo del messaggio. |
L'oggetto documents include i campi opzionali seguenti:
| Chiave | Type | Default | Descrizione |
|---|---|---|---|
id |
string |
None |
Può essere specificato per identificare il documento nelle citazioni. Questo campo non viene passato al modello. |
_excludes |
array of strings |
None |
È possibile specificarlo (facoltativamente) per escludere alcune coppie chiave-valore dalla visualizzazione nel modello. I campi esclusi vengono comunque visualizzati nell'oggetto citazione. Il campo _excludes non viene passato al modello. |
Schema di risposta v1/chat
I campi di risposta sono completamente documentati nell'articolo di riferimento sull'API Chat di Cohere. L'oggetto della risposta contiene sempre gli elementi seguenti:
| Chiave | Type | Descrizione |
|---|---|---|
response_id |
string |
Identificatore univoco per il completamento della chat. |
generation_id |
string |
Identificatore univoco per il completamento della chat, usato con l'endpoint Feedback nella piattaforma di Cohere. |
text |
string |
Risposta del modello all'input del messaggio di chat. |
finish_reason |
enum string |
Motivo per cui la generazione è stata completata. Può essere uno dei valori seguenti: COMPLETE, ERROR, ERROR_TOXIC, ERROR_LIMIT, USER_CANCEL o MAX_TOKENS |
token_count |
integer |
Numero di token usati. |
meta |
string |
Dati di utilizzo dell'API, inclusi la versione corrente e i token fatturabili. |
Documenti
Se nella richiesta vengono specificati oggetti documents, nella risposta saranno presenti altri due campi:
| Chiave | Type | Descrizione |
|---|---|---|
documents |
array of objects |
Elenca i documenti citati nella risposta. |
citations |
array of objects |
Specifica quale parte della risposta è stata trovata in un determinato documento. |
citations è una matrice di oggetti con i campi obbligatori seguenti:
| Chiave | Type | Descrizione |
|---|---|---|
start |
integer |
Indice di testo da cui inizia la citazione, contando da zero. Una generazione di Hello, world! con una citazione su world, ad esempio, avrà un valore iniziale pari a 7. La citazione, infatti, inizia da w, che è il settimo carattere. |
end |
integer |
Indice di testo in seguito al quale finisce la citazione, contando da zero. Una generazione di Hello, world! con una citazione su world, ad esempio, avrà un valore finale pari a 11. La citazione, infatti, finisce dopo d, che è l'undicesimo carattere. |
text |
string |
Testo della citazione. Una generazione di Hello, world! con una citazione su world, ad esempio, avrà il valore di testo world. |
document_ids |
array of strings |
Identificatori dei documenti citati da questa sezione della risposta generata. |
Strumenti
Se vengono specificati e richiamati dal modello oggetti tools, nella risposta sarà presente un altro campo:
| Chiave | Type | Descrizione |
|---|---|---|
tool_calls |
array of objects |
Contiene le chiamate di strumenti generate dal modello. Deve essere usato per richiamare i propri strumenti. |
tool_calls è una matrice di oggetti con i campi seguenti:
| Chiave | Type | Descrizione |
|---|---|---|
name |
string |
Nome dello strumento da chiamare. |
parameters |
object |
Nome e valore dei parametri da usare quando si richiama uno strumento. |
Search_queries_only
Se nella richiesta viene specificato search_queries_only=TRUE, nella risposta saranno presenti altri due campi:
| Chiave | Type | Descrizione |
|---|---|---|
is_search_required |
boolean |
Indica al modello di generare una query di ricerca. |
search_queries |
array of objects |
Oggetto contenente un elenco di query di ricerca. |
search_queries è una matrice di oggetti con i campi seguenti:
| Chiave | Type | Descrizione |
|---|---|---|
text |
string |
Testo della query di ricerca. |
generation_id |
string |
Identificatore univoco per la query di ricerca generata. Utile per l'invio di un feedback. |
Esempi
Chat - Completamenti
Il testo seguente costituisce una chiamata di richiesta di esempio per ottenere i completamenti della chat da un modello Cohere Command. Deve essere quindi usato quando si genera il completamento di una chat.
Richiesta:
{
"chat_history": [
{"role":"USER", "message": "What is an interesting new role in AI if I don't have an ML background"},
{"role":"CHATBOT", "message": "You could explore being a prompt engineer!"}
],
"message": "What are some skills I should have"
}
Risposta:
{
"response_id": "09613f65-c603-41e6-94b3-a7484571ac30",
"text": "Writing skills are very important for prompt engineering. Some other key skills are:\n- Creativity\n- Awareness of biases\n- Knowledge of how NLP models work\n- Debugging skills\n\nYou can also have some fun with it and try to create some interesting, innovative prompts to train an AI model that can then be used to create various applications.",
"generation_id": "6d31a57f-4d94-4b05-874d-36d0d78c9549",
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 99,
"response_tokens": 70,
"total_tokens": 169,
"billed_tokens": 151
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 81,
"output_tokens": 70
}
}
}
Chat - Generazione fondata e funzionalità RAG
Il training di Command R e Command R+ per RAG viene eseguito combinando il processo SFT (Supervised Fine-Tuning) con l'ottimizzazione delle preferenze in un modello di richiesta specifico, che verrà introdotto tramite il parametro documents. I frammenti del documento devono essere piccoli blocchi, non lunghi documenti, generalmente composti da circa 100-400 parole. I frammenti di documento sono costituiti da coppie chiave-valore. Le chiavi devono essere brevi stringhe descrittive. I valori possono essere di testo o semistrutturati.
Richiesta:
{
"message": "Where do the tallest penguins live?",
"documents": [
{
"title": "Tall penguins",
"snippet": "Emperor penguins are the tallest."
},
{
"title": "Penguin habitats",
"snippet": "Emperor penguins only live in Antarctica."
}
]
}
Risposta:
{
"response_id": "d7e72d2e-06c0-469f-8072-a3aa6bd2e3b2",
"text": "Emperor penguins are the tallest species of penguin and they live in Antarctica.",
"generation_id": "b5685d8d-00b4-48f1-b32f-baebabb563d8",
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 615,
"response_tokens": 15,
"total_tokens": 630,
"billed_tokens": 22
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 7,
"output_tokens": 15
}
},
"citations": [
{
"start": 0,
"end": 16,
"text": "Emperor penguins",
"document_ids": [
"doc_0"
]
},
{
"start": 69,
"end": 80,
"text": "Antarctica.",
"document_ids": [
"doc_1"
]
}
],
"documents": [
{
"id": "doc_0",
"snippet": "Emperor penguins are the tallest.",
"title": "Tall penguins"
},
{
"id": "doc_1",
"snippet": "Emperor penguins only live in Antarctica.",
"title": "Penguin habitats"
}
]
}
Chat - Uso dello strumento
Se si richiamano strumenti o si genera una risposta in base ai risultati di uno strumento, usare i parametri seguenti.
Richiesta:
{
"message":"I'd like 4 apples and a fish please",
"tools":[
{
"name":"personal_shopper",
"description":"Returns items and requested volumes to purchase",
"parameter_definitions":{
"item":{
"description":"the item requested to be purchased, in all caps eg. Bananas should be BANANAS",
"type": "str",
"required": true
},
"quantity":{
"description": "how many of the items should be purchased",
"type": "int",
"required": true
}
}
}
],
"tool_results": [
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Apples",
"quantity": 4
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale completed"
}
]
},
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Fish",
"quantity": 1
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale not completed"
}
]
}
]
}
Risposta:
{
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"text": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"chat_history": [
{
"message": "I'd like 4 apples and a fish please",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "a4c5da95-b370-47a4-9ad3-cbf304749c04",
"role": "User"
},
{
"message": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"role": "Chatbot"
}
],
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 644,
"response_tokens": 31,
"total_tokens": 675,
"billed_tokens": 41
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 10,
"output_tokens": 31
}
},
"citations": [
{
"start": 5,
"end": 23,
"text": "completed the sale",
"document_ids": [
""
]
},
{
"start": 113,
"end": 132,
"text": "currently no stock.",
"document_ids": [
""
]
}
],
"documents": [
{
"response": "Sale completed"
}
]
}
Dopo aver eseguito la funzione e aver ricevuto gli output dagli strumenti, è possibile passarli nuovamente al modello per generare una risposta per l'utente.
Richiesta:
{
"message":"I'd like 4 apples and a fish please",
"tools":[
{
"name":"personal_shopper",
"description":"Returns items and requested volumes to purchase",
"parameter_definitions":{
"item":{
"description":"the item requested to be purchased, in all caps eg. Bananas should be BANANAS",
"type": "str",
"required": true
},
"quantity":{
"description": "how many of the items should be purchased",
"type": "int",
"required": true
}
}
}
],
"tool_results": [
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Apples",
"quantity": 4
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale completed"
}
]
},
{
"call": {
"name": "personal_shopper",
"parameters": {
"item": "Fish",
"quantity": 1
},
"generation_id": "cb3a6e8b-6448-4642-b3cd-b1cc08f7360d"
},
"outputs": [
{
"response": "Sale not completed"
}
]
}
]
}
Risposta:
{
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"text": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"chat_history": [
{
"message": "I'd like 4 apples and a fish please",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "a4c5da95-b370-47a4-9ad3-cbf304749c04",
"role": "User"
},
{
"message": "I've completed the sale for 4 apples. \n\nHowever, there was an error regarding the fish; it appears that there is currently no stock.",
"response_id": "fa634da2-ccd1-4b56-8308-058a35daa100",
"generation_id": "f567e78c-9172-4cfa-beba-ee3c330f781a",
"role": "Chatbot"
}
],
"finish_reason": "COMPLETE",
"token_count": {
"prompt_tokens": 644,
"response_tokens": 31,
"total_tokens": 675,
"billed_tokens": 41
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 10,
"output_tokens": 31
}
},
"citations": [
{
"start": 5,
"end": 23,
"text": "completed the sale",
"document_ids": [
""
]
},
{
"start": 113,
"end": 132,
"text": "currently no stock.",
"document_ids": [
""
]
}
],
"documents": [
{
"response": "Sale completed"
}
]
}
Chat - Query di ricerca
Se si sta creando un'agente RAG, è anche possibile usare l'API Chat di Cohere per ottenere query di ricerca da Command. Specificare search_queries_only=TRUE nella richiesta.
Richiesta:
{
"message": "Which lego set has the greatest number of pieces?",
"search_queries_only": true
}
Risposta:
{
"response_id": "5e795fe5-24b7-47b4-a8bc-b58a68c7c676",
"text": "",
"finish_reason": "COMPLETE",
"meta": {
"api_version": {
"version": "1"
}
},
"is_search_required": true,
"search_queries": [
{
"text": "lego set with most pieces",
"generation_id": "a086696b-ad8e-4d15-92e2-1c57a3526e1c"
}
]
}
Altri esempi di inferenza
| Pacchetto | Notebook di esempio |
|---|---|
| Interfaccia della riga di comando che usa richieste Web CURL e Python - Command R | command-r.ipynb |
| Interfaccia della riga di comando che usa richieste Web CURL e Python - Command R+ | command-r-plus.ipynb |
| SDK di OpenAI (sperimentale) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Cohere SDK | cohere-sdk.ipynb |
| LiteLLM SDK | litellm.ipynb |
RAG (Retrieval Augmented Generation) ed esempi d'uso dello strumento
| Descrizione | Pacchetto | Notebook di esempio |
|---|---|---|
| Creare un indice vettoriale FAISS (Facebook AI Similarity Search) locale usando incorporamenti Cohere - Langchain | langchain, langchain_cohere |
cohere_faiss_langchain_embed.ipynb |
| Usare Cohere Command R/R+ per rispondere alle domande dai dati presenti nell'indice vettoriale FAISS locale - Langchain | langchain, langchain_cohere |
command_faiss_langchain.ipynb |
| Usare Cohere Command R/R+ per rispondere alle domande dai dati presenti nell'indice vettoriale di AI Search - Langchain | langchain, langchain_cohere |
cohere-aisearch-langchain-rag.ipynb |
| Usare Cohere Command R/R+ per rispondere alle domande dai dati presenti nell'indice vettoriale di AI Search - Cohere SDK | cohere, azure_search_documents |
cohere-aisearch-rag.ipynb |
| Chiamata di uno strumento/funzione Command R+ con LangChain | cohere, langchain, langchain_cohere |
command_tools-langchain.ipynb |
Costi e quote
Considerazioni su costi e quote per i modelli distribuiti come servizio
I modelli Cohere distribuiti come servizio vengono offerti da Cohere tramite Azure Marketplace e integrati con studio di Azure Machine Learning. È possibile trovare i prezzi di Azure Marketplace durante la distribuzione dei modelli.
Ogni volta che un'area di lavoro sottoscrive un'offerta di modello specifica da Azure Marketplace, viene creata una nuova risorsa per tenere traccia dei costi associati al consumo. La stessa risorsa viene usata per tenere traccia dei costi associati all'inferenza; Tuttavia, sono disponibili più contatori per tenere traccia di ogni scenario in modo indipendente.
Per altre informazioni su come tenere traccia dei costi, vedere Monitorare i costi per i modelli offerti tramite Azure Marketplace.
La quota viene gestita per distribuzione. Ogni distribuzione ha un limite di frequenza di 200.000 token al minuto e 1.000 richieste API al minuto. Tuttavia, c’è attualmente un limite di una distribuzione per ogni modello per ogni area di lavoro. Contattare il supporto tecnico di Microsoft Azure se i limiti di frequenza correnti non sono sufficienti per gli scenari in uso.
Filtri dei contenuti
I modelli distribuiti come servizio con pagamento in base al consumo sono protetti dalla sicurezza dei contenuti di Intelligenza artificiale di Azure. Con la sicurezza dei contenuti di Intelligenza artificiale di Azure abilitata, sia il prompt che il completamento passano attraverso un insieme di modelli di classificazione volti a rilevare e impedire l'output di contenuto dannoso. Il sistema di filtro del contenuto rileva e agisce su categorie specifiche di contenuto potenzialmente dannoso sia nelle richieste di input che nei completamenti di output. Altre informazioni su Sicurezza dei contenuti di Azure per intelligenza artificiale.
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per