Questo articolo illustra come usare Open Neural Network Exchange (ONNX) per eseguire stime sui modelli di visione artificiale generati da Machine Learning automatizzato (AutoML) in Azure Machine Learning.
Per usare ONNX per le stime, è necessario:
Scaricare i file del modello ONNX da un'esecuzione di training autoML.
Comprendere gli input e gli output di un modello ONNX.
Pre-elaborare i dati in modo che siano nel formato richiesto per le immagini di input.
Eseguire l'inferenza con il runtime ONNX per Python.
Visualizzare le stime per attività di rilevamento oggetti e segmentazione istanza.
ONNX è uno standard aperto per i modelli di apprendimento automatico e Deep Learning. Consente l'importazione e l'esportazione di modelli (interoperabilità) tra i framework di intelligenza artificiale di uso comune. Per altre informazioni, vedere il progetto GitHub ONNX.
Il runtime ONNX è un progetto open source che supporta l'inferenza tra piattaforme. Il runtime ONNX fornisce API tra linguaggi di programmazione (inclusi Python, C++, C#, C, C, Java e JavaScript). È possibile usare queste API per eseguire l'inferenza nelle immagini di input. Dopo aver esportato il modello in formato ONNX, è possibile usare queste API in qualunque linguaggio di programmazione necessario per il progetto.
Questa guida spiega come usare le API di Python per il runtime ONNX per creare stime sulle immagini per attività di visione di uso comune. È possibile usare questi modelli ONNX esportati in vari linguaggi.
Installare il pacchetto onnxruntime. I metodi riportati in questo articolo sono stati testati con le versioni da 1.3.0 a 1.8.0.
Scaricare i file del modello ONNX
È possibile scaricare i file del modello ONNX da esecuzioni di AutoML usando l'interfaccia utente di Azure Machine Learning Studio o l’SDK Python di Azure Machine Learning. È consigliabile eseguire il download tramite l'SDK con il nome dell'esperimento e l'ID esecuzione padre.
Studio di Azure Machine Learning
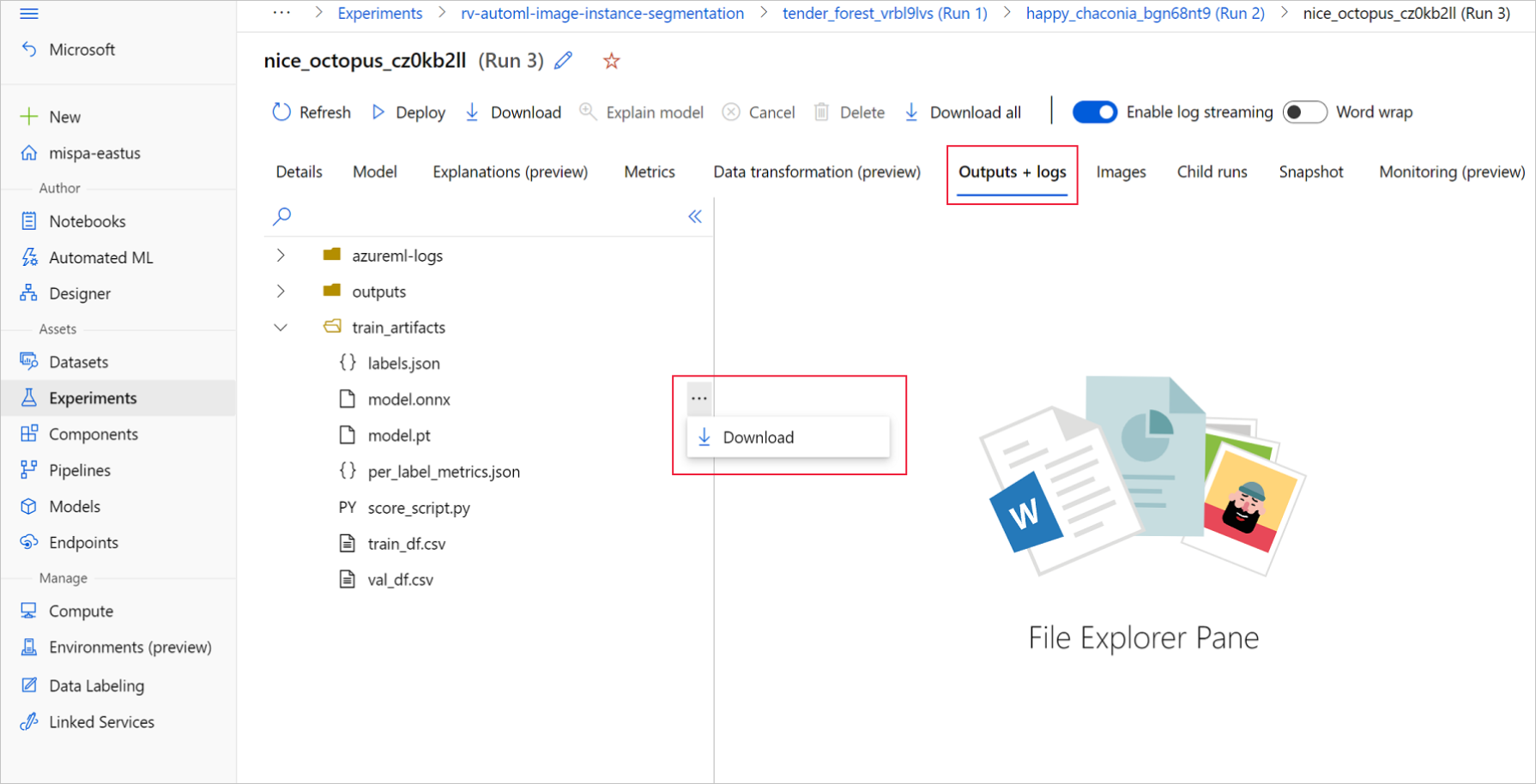
In Azure Machine Learning Studio, passare all'esperimento usando il collegamento ipertestuale all'esperimento generato nel notebook di training o selezionando il nome dell'esperimento nella scheda Esperimenti in Asset. Selezionare, quindi, la migliore esecuzione figlio.
All'interno della migliore esecuzione figlio, passare a Output + log>train_artifacts. Usare il pulsante Download per scaricare manualmente i file seguenti:
labels.json: file contenente tutte le classi o le etichette nel set di dati di training.
model.onnx: modello in formato ONNX.
Salvare i file del modello scaricati in una directory. Nell'esempio riportato in questo articolo viene usata la directory ./automl_models.
Python SDK di Azure Machine Learning
Con l'SDK è possibile selezionare la migliore esecuzione figlio (per metrica primaria) con il nome dell'esperimento e l'ID esecuzione padre. È possibile, quindi, scaricare i file labels.json e model.onnx.
Il codice seguente restituisce la migliore esecuzione figlio in base alla metrica primaria pertinente.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Scaricare il file labels.json, contenente tutte le classi o le etichette nel set di dati di training.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
Generazione di modelli per l'assegnazione dei punteggi in batch
Per impostazione predefinita, AutoML per le immagini supporta l'assegnazione dei punteggi in batch per la classificazione. I modelli ONNX di rilevamento oggetti e segmentazione istanza, però, non supportano l'inferenza batch. In caso di inferenza batch per rilevamento oggetti e segmentazione istanza, usare la procedura seguente per generare un modello ONNX per le dimensioni batch necessarie. I modelli generati per una dimensione batch specifica non funzionano per altre dimensioni batch.
Scaricare il file di ambiente conda e creare un oggetto ambiente da usare con il comando job.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Per ottenere i valori degli argomenti necessari per la creazione del modello di assegnazione dei punteggi in batch, vedere gli script di assegnazione dei punteggi generati nella cartella di output delle esecuzioni di training AutoML. Usare i valori degli iperparametri disponibili nella variabile delle impostazioni del modello all'interno del file di assegnazione dei punteggi per la migliore esecuzione figlio.
Per la classificazione di immagini multiclasse, il modello ONNX generato per la migliore esecuzione figlio supporta l'assegnazione dei punteggi in batch per impostazione predefinita. Di conseguenza, non sono necessari argomenti specifici del modello per questo tipo di attività ed è possibile passare alla sezione Caricare etichette e file del modello ONNX.
Per la classificazione di immagini multietichetta, il modello ONNX generato per la migliore esecuzione figlio supporta l'assegnazione dei punteggi in batch per impostazione predefinita. Di conseguenza, non sono necessari argomenti specifici del modello per questo tipo di attività ed è possibile passare alla sezione Caricare etichette e file del modello ONNX.
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Scaricare e mantenere il file ONNX_batch_model_generator_automl_for_images.py nella directory corrente per inviare lo script. Usare il comando job seguente per inviare lo script ONNX_batch_model_generator_automl_for_images.py disponibile nel repository GitHub azureml-examples per generare un modello ONNX con dimensioni batch specifiche. Nel codice seguente, l'ambiente del modello sottoposto a training viene usato per inviare questo script per la generazione e il salvataggio del modello ONNX nella directory di output.
Per la classificazione di immagini multiclasse, il modello ONNX generato per la migliore esecuzione figlio supporta l'assegnazione dei punteggi in batch per impostazione predefinita. Di conseguenza, non sono necessari argomenti specifici del modello per questo tipo di attività ed è possibile passare alla sezione Caricare etichette e file del modello ONNX.
Per la classificazione di immagini multietichetta, il modello ONNX generato per la migliore esecuzione figlio supporta l'assegnazione dei punteggi in batch per impostazione predefinita. Di conseguenza, non sono necessari argomenti specifici del modello per questo tipo di attività ed è possibile passare alla sezione Caricare etichette e file del modello ONNX.
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
Dopo aver generato il modello batch, scaricarlo manualmente da Output + log>output tramite l'interfaccia utente o usare il metodo seguente:
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
Dopo il passaggio di download del modello, usare il pacchetto Python del runtime ONNX per eseguire l'inferenza usando il file model.onnx. A scopo dimostrativo, questo articolo usa i set di dati della sezione Come preparare set di dati di immagini per ogni attività di visione.
Sono stati sottoposti a training i modelli per tutte le attività di visione con i rispettivi set di dati per dimostrare l'inferenza del modello ONNX.
Caricare le etichette e i file del modello ONNX
Il frammento di codice seguente carica labels.json, dove i nomi delle classi sono ordinati, vale a dire che se il modello ONNX stima un ID etichetta come 2, questo corrisponde al nome dell'etichetta specificato nel terzo indice nel file labels.json.
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Ottenere i dettagli di input e output previsti per un modello ONNX
Quando si dispone del modello, è importante conoscere alcuni dettagli specifici del modello e dell'attività. Questi dettagli includono il numero di input e il numero di output, la forma o il formato di input previsti per la pre-elaborazione dell'immagine e la forma di output, in modo da conoscere gli output specifici del modello o dell'attività.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Formati di input e output previsti per il modello ONNX
Ogni modello ONNX ha un set predefinito di formati di input e output.
Questo esempio applica il modello sottoposto a training sul set di dati fridgeObjects con 134 immagini e 4 classi/etichette per spiegare l'inferenza del modello ONNX. Per altre informazioni sul training di un'attività di classificazione delle immagini, vedere il notebook di classificazione di immagini multiclasse.
Formato di input
L'input è un'immagine pre-elaborata.
Nome input
Forma di input
Tipo di input
Descrizione
input1
(batch_size, num_channels, height, width)
ndarray(float)
L'input è un'immagine pre-elaborata, con la forma (1, 3, 224, 224) per dimensioni batch pari a 1 e un'altezza e una larghezza pari a 224. Questi numeri corrispondono ai valori usati per crop_size nell'esempio di training.
Formato di output
L'output è un array di logits per tutte le classi/etichette.
Nome output
Forma di output
Tipo di output
Descrizione
output1
(batch_size, num_classes)
ndarray(float)
Il modello restituisce logits (senza softmax). Ad esempio, per le dimensioni batch 1 e 4 classi, restituisce (1, 4).
L'input è un'immagine pre-elaborata, con la forma (1, 3, 224, 224) per dimensioni batch pari a 1 e un'altezza e una larghezza pari a 224. Questi numeri corrispondono ai valori usati per crop_size nell'esempio di training.
Formato di output
L'output è un array di logits per tutte le classi/etichette.
Nome output
Forma di output
Tipo di output
Descrizione
output1
(batch_size, num_classes)
ndarray(float)
Il modello restituisce logits (senza sigmoid). Ad esempio, per le dimensioni batch 1 e 4 classi, restituisce (1, 4).
Questo esempio di rilevamento oggetti usa il modello sottoposto a training sul set di dati di rilevamento fridgeObjects di 128 immagini e 4 classi/etichette per spiegare l'inferenza del modello ONNX. Questo esempio esegue il training di modelli Faster R-CNN per illustrare i passaggi di inferenza. Per altre informazioni sul training di modelli di rilevamento oggetti, vedere il notebook di rilevamento oggetti.
Formato di input
L'input è un'immagine pre-elaborata.
Nome input
Forma di input
Tipo di input
Descrizione
Input
(batch_size, num_channels, height, width)
ndarray(float)
L'input è un'immagine pre-elaborata, con la forma (1, 3, 600, 800) per dimensioni batch pari a 1 e un'altezza e una larghezza pari a 600.
Formato di output
L'output è una tupla di output_names e stime. In questo caso, output_names e predictions sono elenchi ciascuno con lunghezza 3*batch_size. Per Faster R-CNN gli output sono ordinati come caselle, etichette e punteggi, mentre per RetinaNet gli output sono ordinati come caselle, punteggi, etichette.
Nome output
Forma di output
Tipo di output
Descrizione
output_names
(3*batch_size)
Elenco di chiavi
Per dimensioni batch pari a 2, output_names è ['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Elenco di ndarray(float)
Per dimensioni batch pari a 2, predictions assume la forma di [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. In questo caso, i valori in ogni indice corrispondono allo stesso indice in output_names.
Nella tabella seguente vengono descritte le caselle, le etichette e i punteggi restituiti per ogni campione nel batch di immagini.
Nome
Forma
Tipo
Descrizione
Scatole
(n_boxes, 4), dove ogni casella ha x_min, y_min, x_max, y_max
ndarray(float)
Il modello restituisce n caselle con le relative coordinate in alto a sinistra e in basso a destra.
Etichette
(n_boxes)
ndarray(float)
Etichetta o ID classe di un oggetto in ogni casella.
Punteggi
(n_boxes)
ndarray(float)
Punteggio di confidenza di un oggetto in ogni casella.
Questo esempio di rilevamento oggetti usa il modello sottoposto a training sul set di dati di rilevamento fridgeObjects di 128 immagini e 4 classi/etichette per spiegare l'inferenza del modello ONNX. Questo esempio esegue il training di modelli YOLO per illustrare i passaggi di inferenza. Per altre informazioni sul training di modelli di rilevamento oggetti, vedere il notebook di rilevamento oggetti.
Formato di input
L'input è un'immagine pre-elaborata, con la forma (1, 3, 640, 640) per dimensioni batch pari a 1 e un'altezza e una larghezza pari a 640. Questi numeri corrispondono ai valori usati nell'esempio di training.
Nome input
Forma di input
Tipo di input
Descrizione
Input
(batch_size, num_channels, height, width)
ndarray(float)
L'input è un'immagine pre-elaborata, con la forma (1, 3, 640, 640) per dimensioni batch pari a 1 e un'altezza e una larghezza pari a 640.
Formato di output
Le stime del modello ONNX contengono più output. Il primo output è necessario per eseguire la soppressione non massimale per i rilevamenti. Per facilità d’uso, Machine Learning automatizzato visualizza il formato di output dopo il passaggio di post-elaborazione NMS. L'output dopo NMS è un elenco di caselle, etichette e punteggi per ogni campione nel batch.
Nome output
Forma di output
Tipo di output
Descrizione
Output
(batch_size)
Elenco di ndarray(float)
Il modello restituisce rilevamenti casella per ogni esempio nel batch
Ogni cella nell'elenco indica i rilevamenti casella di un campione con forma (n_boxes, 6), dove ogni casella ha x_min, y_min, x_max, y_max, confidence_score, class_id.
Per questo esempio di segmentazione istanza, si usa il modello Mask R-CNN sottoposto a training sul set di dati fridgeObjects con 128 immagini e 4 classi/etichette per spiegare l'inferenza del modello ONNX. Per altre informazioni sul training del modello di segmentazione istanza, vedere il notebook di segmentazione istanza.
Importante
Per le attività di segmentazione istanza è supportato solo Mask R-CNN. I formati di input e output sono basati solo su Mask R-CNN.
Formato di input
L'input è un'immagine pre-elaborata. Il modello ONNX per Mask R-CNN è stato esportato per l’uso di immagini di forme diverse. Per ottenere prestazioni migliori, è consigliabile ridimensionarle in base a dimensioni fisse coerenti con le dimensioni delle immagini di training.
Nome input
Forma di input
Tipo di input
Descrizione
Input
(batch_size, num_channels, height, width)
ndarray(float)
L'input è un'immagine pre-elaborata, con la forma (1, 3, input_image_height, input_image_width) per dimensioni batch pari a 1 e un'altezza e una larghezza simili a un’immagine di input.
Formato di output
L'output è una tupla di output_names e stime. In questo caso, output_names e predictions sono elenchi ciascuno con lunghezza 4*batch_size.
Nome output
Forma di output
Tipo di output
Descrizione
output_names
(4*batch_size)
Elenco di chiavi
Per dimensioni batch pari a 2, output_names è ['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Elenco di ndarray(float)
Per dimensioni batch pari a 2, predictions assume la forma di [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. In questo caso, i valori in ogni indice corrispondono allo stesso indice in output_names.
Nome
Forma
Tipo
Descrizione
Scatole
(n_boxes, 4), dove ogni casella ha x_min, y_min, x_max, y_max
ndarray(float)
Il modello restituisce n caselle con le relative coordinate in alto a sinistra e in basso a destra.
Etichette
(n_boxes)
ndarray(float)
Etichetta o ID classe di un oggetto in ogni casella.
Punteggi
(n_boxes)
ndarray(float)
Punteggio di confidenza di un oggetto in ogni casella.
Maschere
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Maschere (poligoni) di oggetti rilevati con l'altezza e la larghezza della forma di un'immagine di input.
Eseguire i passaggi di pre-elaborazione seguenti per l'inferenza del modello ONNX:
Convertire l'immagine in RGB.
Ridimensionare l'immagine su valori valid_resize_size e valid_resize_size corrispondenti a quelli usati nella trasformazione del set di dati di convalida durante il training. Il valore predefinito per valid_resize_size è 256.
Ritagliare al centro l'immagine su height_onnx_crop_size e width_onnx_crop_size. Corrisponde a valid_crop_size con il valore predefinito 224.
Cambia HxWxC in CxHxW.
Convertire in tipo float.
Normalizzare con i mean = [0.485, 0.456, 0.406] e std = [0.229, 0.224, 0.225] di ImageNet.
Se si scelgono valori diversi per gli iperparametrivalid_resize_size e valid_crop_size durante il training, usare tali valori.
Ottenere la forma di input necessaria per il modello ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Con PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Eseguire i passaggi di pre-elaborazione seguenti per l'inferenza del modello ONNX. Questi passaggi sono gli stessi per la classificazione di immagini multiclasse.
Convertire l'immagine in RGB.
Ridimensionare l'immagine su valori valid_resize_size e valid_resize_size corrispondenti a quelli usati nella trasformazione del set di dati di convalida durante il training. Il valore predefinito per valid_resize_size è 256.
Ritagliare al centro l'immagine su height_onnx_crop_size e width_onnx_crop_size. Corrisponde a valid_crop_size con il valore predefinito 224.
Cambia HxWxC in CxHxW.
Convertire in tipo float.
Normalizzare con i mean = [0.485, 0.456, 0.406] e std = [0.229, 0.224, 0.225] di ImageNet.
Se si scelgono valori diversi per gli iperparametrivalid_resize_size e valid_crop_size durante il training, usare tali valori.
Ottenere la forma di input necessaria per il modello ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Con PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Per il rilevamento degli oggetti con l'architettura Faster R-CNN, seguire gli stessi passaggi di pre-elaborazione eseguiti per la classificazione di immagini, ad eccezione del ritaglio delle immagini. È possibile ridimensionare l'immagine con altezza 600 e larghezza 800. È possibile ottenere l'altezza e la larghezza di input previste con il codice seguente.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Per il rilevamento oggetti con l'architettura YOLO, seguire gli stessi passaggi di pre-elaborazione eseguiti per la classificazione di immagini, ad eccezione del ritaglio delle immagini. È possibile ridimensionare l'immagine con altezza 600 e larghezza 800 e ottenere l'altezza e la larghezza di input previste con il codice seguente.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Importante
Per le attività di segmentazione istanza è supportato solo Mask R-CNN. I passaggi di pre-elaborazione sono basati solo su Mask R-CNN.
Eseguire i passaggi di pre-elaborazione seguenti per l'inferenza del modello ONNX:
Convertire l'immagine in RGB.
Ridimensionare l’immagine.
Cambia HxWxC in CxHxW.
Convertire in tipo float.
Normalizzare con i mean = [0.485, 0.456, 0.406] e std = [0.229, 0.224, 0.225] di ImageNet.
Per resize_height e resize_width, è anche possibile usare i valori usati durante il training, limitati da min_size e max_sizeiperparametri per Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Inferenza con il runtime ONNX
L'inferenza con il runtime ONNX è diversa per ogni attività di visione artificiale.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Il modello di segmentazione istanza prevede caselle, etichette, punteggi e maschere. ONNX restituisce come output una maschera stimata per ogni istanza, assieme al punteggio di confidenza della classe e ai rettangoli di selezione corrispondenti. Potrebbe essere necessario eseguire la conversione da maschera binaria a poligono.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Applicare softmax() sui valori stimati per ottenere i punteggi di confidenza della classificazione (probabilità) per ogni classe. La stima, quindi, sarà la classe con la probabilità più alta.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Questo passaggio è diverso dalla classificazione multiclasse. È necessario applicare sigmoid ai logits (output ONNX) per ottenere i punteggi di confidenza per la classificazione di immagini multietichetta.
Senza PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Con PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Per la classificazione multiclasse e multietichetta, è possibile seguire la stessa procedura citata in precedenza per tutte le architetture di modelli supportate in AutoML.
Per il rilevamento oggetti, le stime vengono eseguite automaticamente sulla scala di height_onnx, width_onnx. Per trasformare le coordinate della casella stimate nelle dimensioni originarie, è possibile implementare i calcoli seguenti.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Un'altra opzione consiste nell'uso del codice seguente per adeguare le dimensioni della casella in modo che siano incluse nell'intervallo [0, 1]. In questo modo le coordinate della casella possono essere moltiplicate con l’altezza e la larghezza delle immagini originarie con le rispettive coordinate (come descritto nella sezione sulla visualizzazione delle stime) per ottenere caselle nelle dimensioni originarie dell'immagine.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
Il codice seguente crea caselle, etichette e punteggi. Usare questi dettagli del rettangolo di selezione per eseguire gli stessi passaggi di post-elaborazione eseguiti per il modello Faster R-CNN.
È possibile usare i passaggi indicati per Faster R-CNN (nel caso di Mask R-CNN, ogni esempio ha quattro caselle di elementi, etichette, punteggi, maschere) oppure fare riferimento alla sezione sulla visualizzazione delle stime per la segmentazione istanza.
 Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)