Preparare i dati per le attività di visione artificiale con Machine Learning automatizzato
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Importante
Il supporto per il training di modelli di visione artificiale con ML automatizzato in Azure Machine Learning è una funzionalità di anteprima pubblica sperimentale. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Questo articolo illustra come preparare i dati delle immagini per il training dei modelli di visione artificiale con ML automatizzato in Azure Machine Learning.
Per generare modelli per le attività di Visione artificiale con Machine Learning automatizzato, è necessario portare i dati dell'immagine etichettati come input per il training del modello sotto forma di .MLTable
È possibile creare un oggetto MLTable da dati di training etichettati in formato JSONL.
Se i dati di training etichettati sono in un formato diverso(ad esempio, pascal VOC o COCO), è possibile usare uno script di conversione per convertirli prima in JSONL e quindi creare un oggetto MLTable. In alternativa, è possibile usare lo strumento di etichettatura dati di Azure Machine Learning per etichettare manualmente le immagini ed esportare i dati etichettati da usare per il training del modello AutoML.
Prerequisiti
- Acquisire familiarità con gli schemi di accettati per i file JSONL per esperimenti di visione artificiale AutoML.
Ottenere dati etichettati
Per eseguire il training di modelli di visione artificiale usando AutoML, è necessario prima ottenere i dati di training etichettati. Le immagini devono essere caricate nel cloud e le annotazioni delle etichette devono essere in formato JSONL. È possibile usare lo strumento Di etichettatura dati di Azure Machine Learning per etichettare i dati oppure iniziare con i dati di immagine con etichetta predefinita.
Uso dello strumento di etichettatura dati di Azure Machine Learning per etichettare i dati di training
Se non si dispone di dati con etichetta predefinita, è possibile usare lo strumento di etichettatura dati di Azure Machine Learning per etichettare manualmente le immagini. Questo strumento genera automaticamente i dati necessari per il training nel formato accettato.
Consente di creare, gestire e monitorare le attività di etichettatura dei dati per
- Classificazione immagini (multiclasse e multietichetta)
- Rilevamento oggetti (rettangolo di selezione)
- Segmentazione istanza (poligono)
Se sono già stati etichettati dati da usare, è possibile esportare i dati etichettati come set di dati di Azure Machine Learning e quindi accedere al set di dati nella scheda "Set di dati" in studio di Azure Machine Learning. Questo set di dati esportato può quindi essere passato come input usando azureml:<tabulardataset_name>:<version> il formato . Ecco un esempio di come passare un set di dati esistente come input per i modelli di visione artificiale di training.
SI APPLICA A:Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
Uso dei dati di training pre-etichettati dal computer locale
Se sono stati etichettati dati da usare per eseguire il training del modello, è necessario caricare le immagini in Azure. È possibile caricare le immagini nella Archiviazione BLOB di Azure predefinita dell'area di lavoro di Azure Machine Learning e registrarla come asset di dati.
Lo script seguente carica i dati dell'immagine nel computer locale nel percorso "./data/odFridgeObjects" nell'archivio dati in Archiviazione BLOB di Azure. Crea quindi un nuovo asset di dati con il nome "refrigerator-items-images-object-detection" nell'area di lavoro di Azure Machine Learning.
Se esiste già un asset di dati con il nome "refrigerator-items-images-object-detection" nell'area di lavoro di Azure Machine Learning, aggiorna il numero di versione dell'asset di dati e lo punta alla nuova posizione in cui sono stati caricati i dati dell'immagine.
SI APPLICA A:Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)
Creare un file .yml con la configurazione seguente.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
Per caricare le immagini come asset di dati, eseguire il comando dell'interfaccia della riga di comando v2 seguente con il percorso del file .yml, il nome dell'area di lavoro, il gruppo di risorse e l'ID sottoscrizione.
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
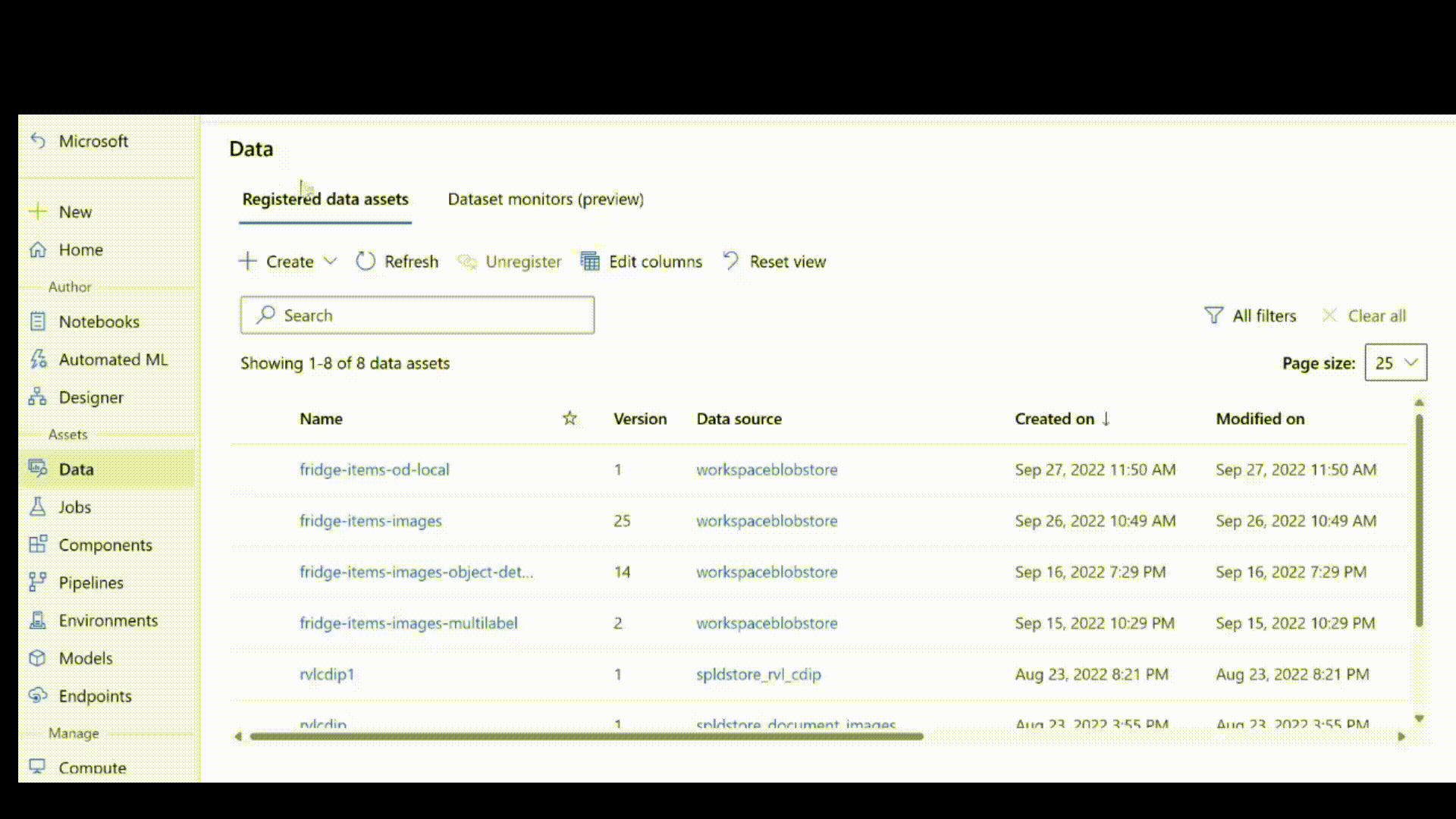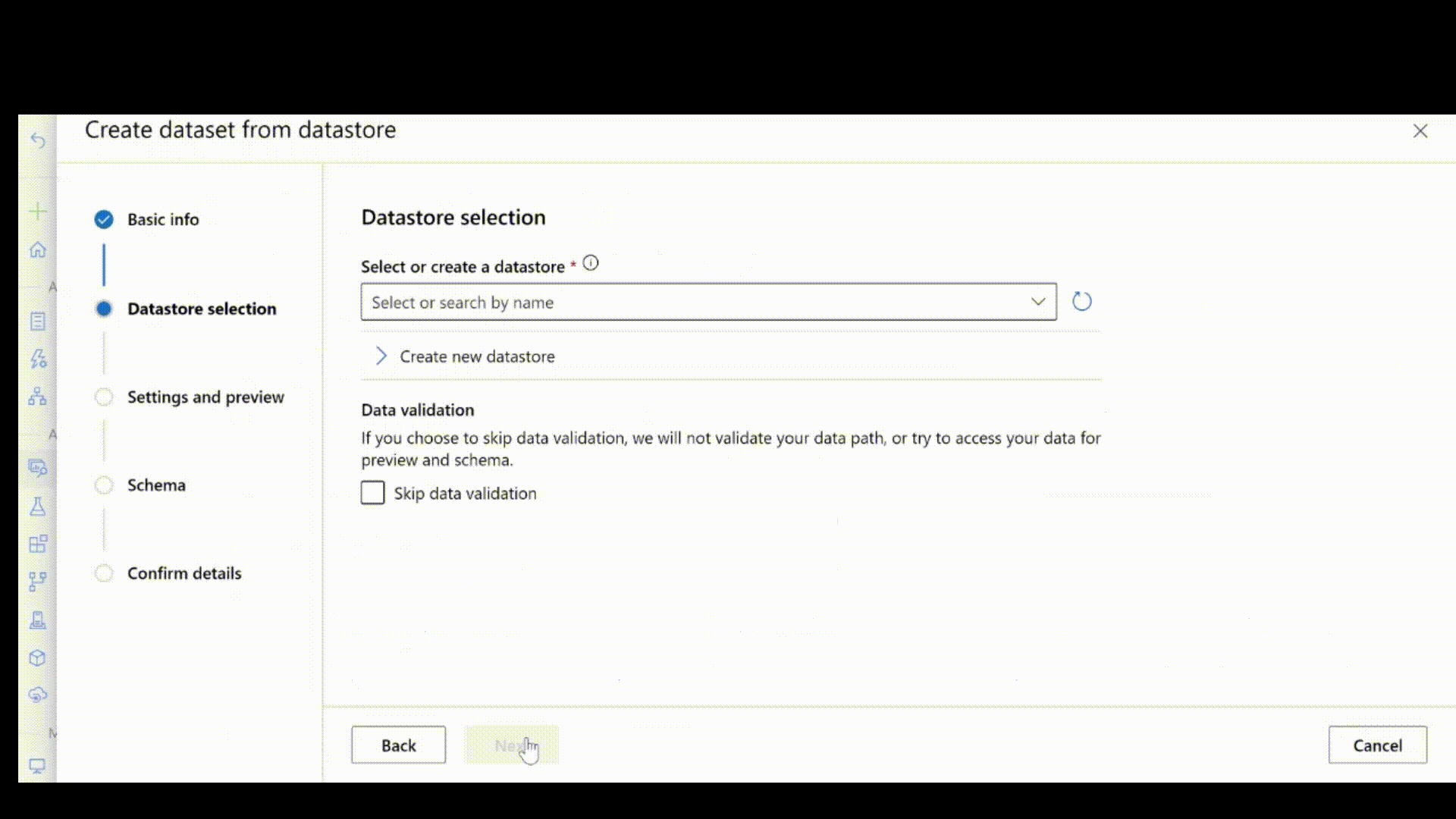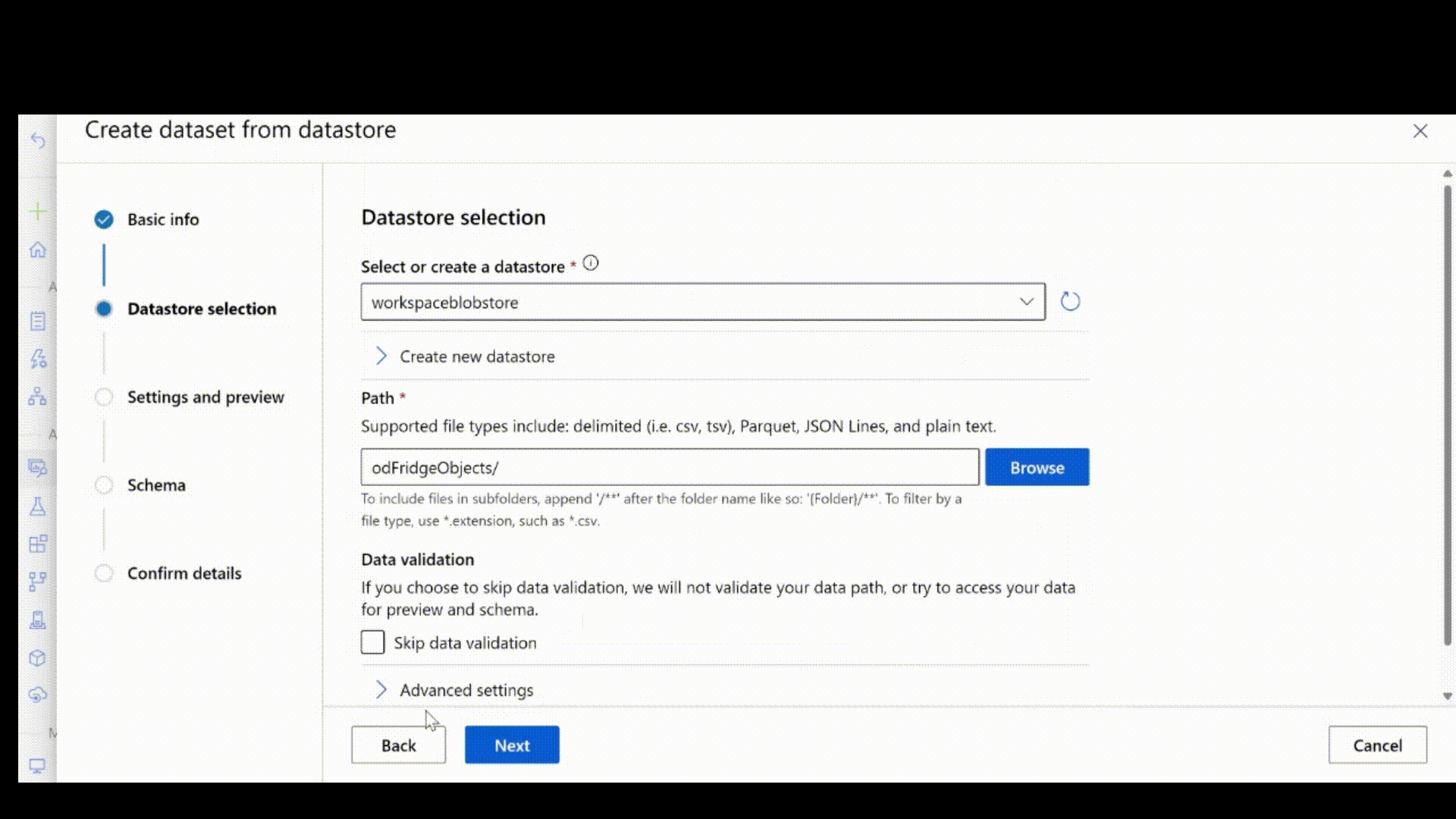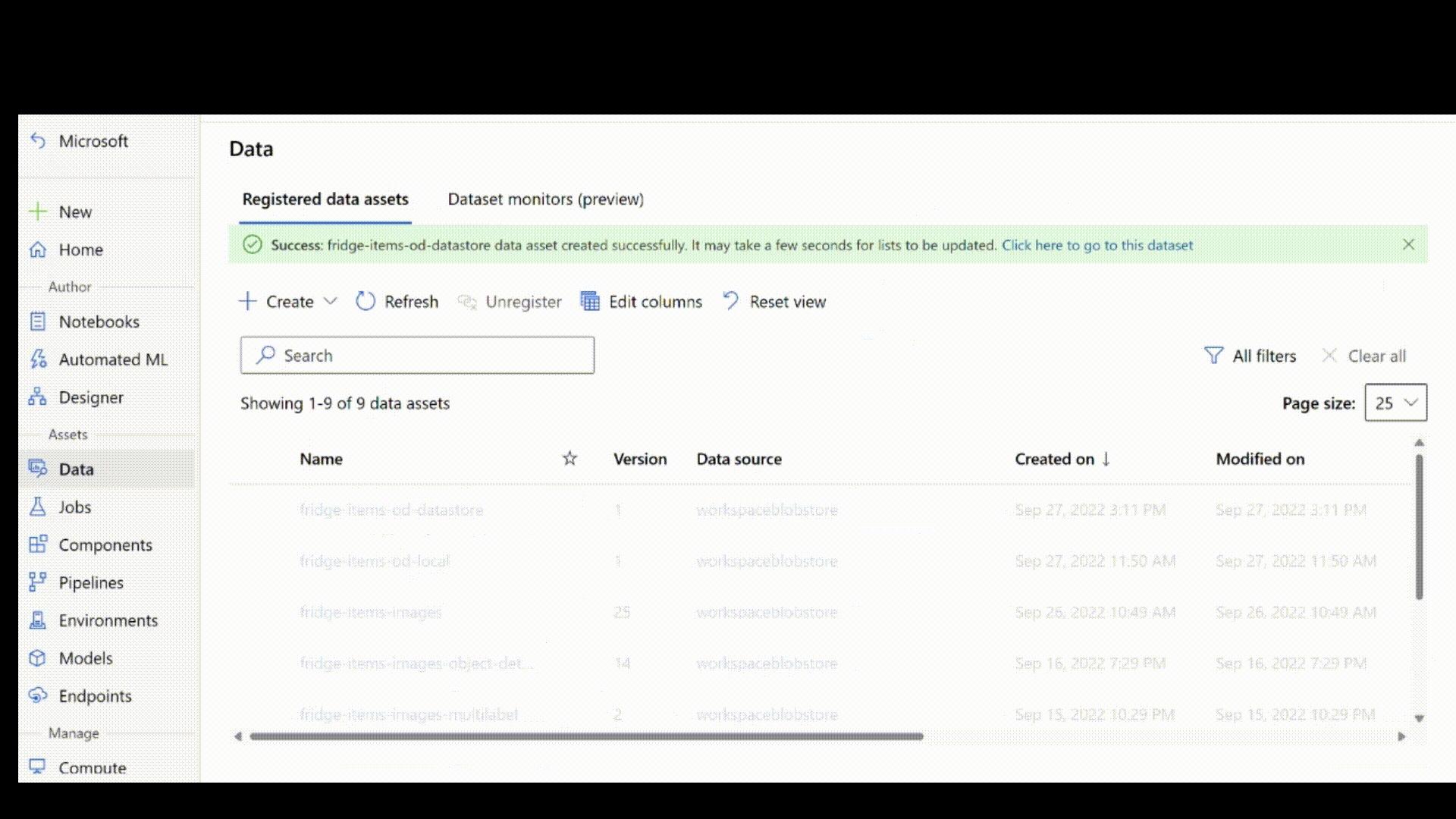
Se i dati sono già presenti in un archivio dati esistente e si vuole crearne uno esterno, è possibile farlo specificando il percorso dei dati nell'archivio dati, anziché specificare il percorso del computer locale. Aggiornare il codice precedente con il frammento di codice seguente.
SI APPLICA A:Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)
Creare un file .yml con la configurazione seguente.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
Successivamente, è necessario ottenere le annotazioni delle etichette in formato JSONL. Lo schema dei dati etichettati dipende dall'attività visione artificiale. Per altre informazioni sullo schema JSONL necessario per ogni tipo di attività, vedere Schemi JSONL per i file JSONL per gli esperimenti di Visione artificiale AutoML.
Se i dati di training sono in un formato diverso(ad esempio, pascal VOC o COCO), gli script helper per convertire i dati in JSONL sono disponibili negli esempi di notebook.
Dopo aver creato il file jsonl seguendo i passaggi precedenti, è possibile registrarlo come asset di dati usando l'interfaccia utente. Assicurarsi di selezionare stream il tipo nella sezione schema, come illustrato in questa animazione.
Uso dei dati di training pre-etichettati da Archiviazione BLOB di Azure
Se i dati di training etichettati sono presenti in un contenitore nell'archivio BLOB di Azure, è possibile accedervi direttamente da questa posizione creando un archivio dati che fa riferimento a tale contenitore.
Creare MLTable
Dopo aver etichettato i dati in formato JSONL, è possibile usarli per creare MLTable come illustrato in questo frammento yaml. MLtable inserisce i dati in un oggetto di consumo per il training.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
È quindi possibile passare come MLTableinput di dati per il processo di training AutoML.