Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le pipeline di Azure Machine Learning supportano input e output sia a livello di componente che di pipeline. Questo articolo descrive gli input e output di pipeline e componenti e come gestirli.
A livello di componente, gli input e gli output definiscono l'interfaccia di un componente. È possibile usare l'output di un componente come input per un altro componente nella stessa pipeline padre, consentendo il passaggio di dati o modelli tra i componenti. Questa interconnettività rappresenta il flusso di dati all'interno della pipeline.
A livello di pipeline, è possibile usare input e output per inviare processi della pipeline con input o parametri di dati variabili, ad esempio learning_rate. Gli input e gli output sono particolarmente utili quando si richiama una pipeline tramite un endpoint REST. È possibile assegnare valori diversi all'input della pipeline o accedere all'output di processi della pipeline diversi. Per altre informazioni, vedere Creare processi e dati di input per gli endpoint batch.
Tipi di input e output
I tipi seguenti sono supportati sia come input che output di componenti o pipeline:
Tipi di dati. Per ulteriori informazioni, vedi Tipi di dati.
uri_fileuri_foldermltable
Tipi di modello.
mlflow_modelcustom_model
Per gli input sono supportati anche i tipi primitivi seguenti:
- Tipi primitivi
stringnumberintegerboolean
L'output del tipo primitivo non è supportato.
Input e output di esempio
Questi esempi provengono dalla pipeline NYC Taxi Data Regression nel repository GitHub di esempi di Azure Machine Learning :
- Il componente train ha un input
numberdenominatotest_split_ratio. - Il componente prep ha un output di tipo
uri_folder. Nel codice sorgente del componente, legge i file CSV dalla cartella di input, elabora i file e scrive i file CSV elaborati nella cartella di output. - Il componente train ha un output di tipo
mlflow_model. Il codice sorgente del componente salva il modello sottoposto a training usando il metodomlflow.sklearn.save_model.
Serializzazione dell'output
L'uso di output di dati o modelli serializza gli output e li salva come file in un percorso di archiviazione. I passaggi successivi possono accedere ai file durante l'esecuzione del processo montando questo percorso di archiviazione o scaricando o caricando i file nel file system di calcolo.
Il codice sorgente del componente deve serializzare l'oggetto di output, in genere archiviato in memoria, in file. Ad esempio, è possibile serializzare un dataframe Pandas in un file CSV. Azure Machine Learning non definisce metodi standardizzati per la serializzazione degli oggetti. Gli utenti hanno la flessibilità di scegliere i metodi preferiti per serializzare gli oggetti in file. Nel componente downstream è possibile scegliere come deserializzare e leggere questi file.
Percorsi di input e output del tipo di dati
Per l'input e output dell'asset di dati, è necessario specificare un parametro percorso che punta alla posizione dei dati. La tabella seguente illustra i percorsi dei dati supportati per gli input e gli output della pipeline di Azure Machine Learning, con path esempi di parametri:
| Location | Input | Risultato | Esempio |
|---|---|---|---|
| Un percorso nel computer locale | ✓ | ./home/<username>/data/my_data |
|
| Percorso in un server http/s pubblico | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Un percorso in Archiviazione di Azure | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>o abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Percorso in un archivio dati di Azure Machine Learning | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Percorso per un asset di dati | ✓ | ✓ | azureml:my_data:<version> |
Suggerimento
* L'uso diretto di Archiviazione di Azure non è consigliato per l'input, perché può essere necessaria una configurazione di identità aggiuntiva per leggere i dati. È preferibile usare i percorsi dell'archivio dati di Azure Machine Learning, supportati in vari tipi di processi della pipeline.
Modalità di input e output del tipo di dati
Per gli input e gli output dei tipi di dati, è possibile scegliere tra diverse modalità di download, caricamento e montaggio per definire il modo in cui la destinazione di calcolo accede ai dati. La tabella seguente illustra le modalità supportate per diversi tipi di input e output.
| TIPO | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
Input uri_folder |
✓ | ✓ | ✓ | ||||
Input uri_file |
✓ | ✓ | ✓ | ||||
Input mltable |
✓ | ✓ | ✓ | ✓ | ✓ | ||
Output uri_folder |
✓ | ✓ | |||||
Output uri_file |
✓ | ✓ | |||||
Output mltable |
✓ | ✓ | ✓ |
È consigliabile usare la modalità ro_mount o rw_mount per la maggior parte dei casi. Per altre informazioni, vedere Modalità.
Input e output nei grafici della pipeline
Nella pagina del processo della pipeline in Studio di Azure Machine Learning gli input e gli output dei componenti vengono visualizzati come piccoli cerchi denominati porte di input/output. Queste porte rappresentano il flusso di dati nella pipeline. L'output a livello di pipeline viene visualizzato in caselle viola per facilitare l'identificazione.
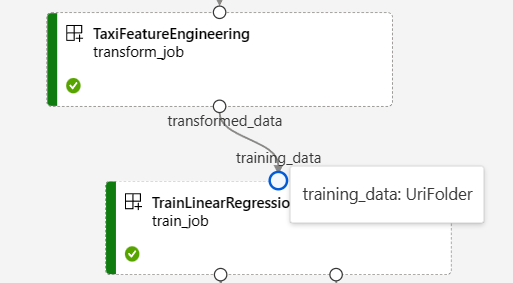
Lo screenshot seguente del grafico della pipeline NYC Taxi Data Regression mostra molti input e output di componenti e pipeline.

Quando si passa il mouse su una porta di input/output, viene visualizzato il tipo.
Il grafico della pipeline non visualizza input di tipo primitivo. Questi input sono visualizzati nella scheda Impostazioni del pannello di Panoramica del processo della pipeline (per gli input a livello di pipeline) o nel pannello dei componenti (per gli input a livello di componente). Per aprire il pannello dei componenti, fare doppio clic sul componente nel grafico.

Quando si modifica una pipeline in Progettazione studio, gli input e gli output della pipeline si trovano nel pannello Interfaccia pipeline e gli input e gli output dei componenti si trovano nel pannello dei componenti.

Alzare di livello di input/output dei componenti ai livelli della pipeline
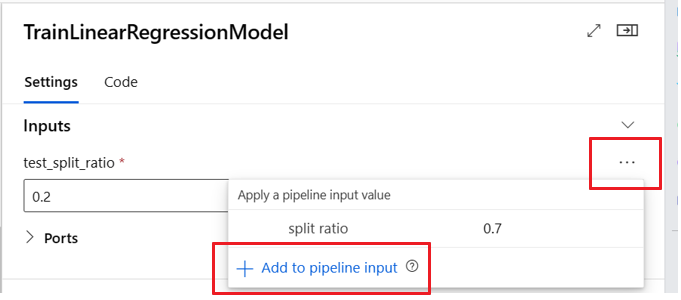
La promozione dell'input/output di un componente a livello di pipeline consente di sovrascrivere l'input/output del componente durante l'invio di un processo della pipeline. Questa funzionalità è particolarmente utile per l'attivazione di pipeline tramite endpoint REST.
Negli esempi seguenti viene illustrato come promuovere input/output a livello di componente in input/output a livello di pipeline.
La pipeline seguente promuove tre input e tre output a livello di pipeline. Ad esempio, pipeline_job_training_max_epocs è l'input a livello di pipeline perché è dichiarato nella sezione inputs a livello radice.
In train_job nella sezione jobs, l'input denominato max_epocs viene riferito come ${{parent.inputs.pipeline_job_training_max_epocs}}, che indica che l’input train_job di max_epocs fa riferimento all'input a livello di pipeline pipeline_job_training_max_epocs. L'output della pipeline viene alzato di livello usando lo stesso schema.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
È possibile trovare l'esempio completo nella pipeline train-score-eval con componenti registrati nel repository di esempi di Azure Machine Learning.
Definire gli input facoltativi
Per impostazione predefinita, tutti gli input sono necessari e devono avere un valore predefinito oppure devono essere assegnati a un valore ogni volta che si invia un processo della pipeline. Tuttavia, è possibile definire un input facoltativo.
Note
Gli output facoltativi non sono supportati.
L'impostazione di input facoltativi può essere utile in due scenari:
Se si definisce un input facoltativo di dati/modello e non si assegna un valore quando si invia il processo della pipeline, il componente della pipeline non dispone della dipendenza dei dati. Se la porta di input del componente non è collegata ad alcun nodo di componente o di dati/modello, la pipeline richiama direttamente il componente anziché attendere una dipendenza precedente.
Se si imposta
continue_on_step_failure = Trueper la pipeline manode2usa l'input richiesto danode1,node2non viene eseguito senode1ha esito negativo. Se l'inputnode1è facoltativo,node2viene eseguito anche senode1ha esito negativo. Il grafico seguente illustra questo scenario.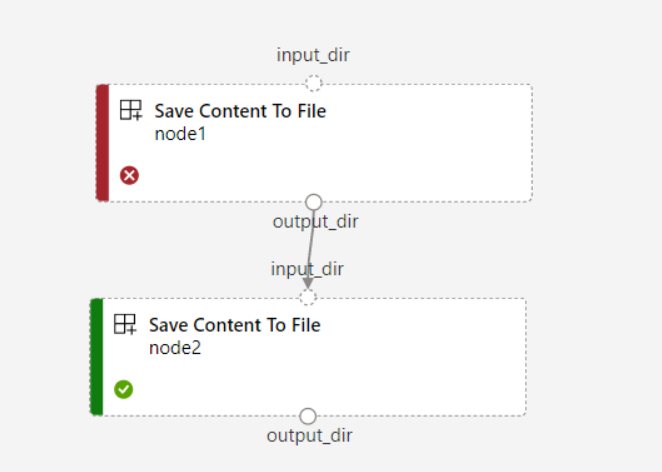
Nell'esempio di codice seguente viene illustrato come definire l'input facoltativo. Quando l'input è impostato su optional = true, è necessario usare $[[]] per accettare gli input della riga di comando, come nelle righe evidenziate dell'esempio.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Personalizzare i percorsi di output
Per impostazione predefinita, l'output del componente viene archiviato nell'oggetto {default_datastore} impostato per la pipeline, azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}. Se non è impostato, il valore predefinito è l'archiviazione BLOB dell'area di lavoro.
Il processo {name} viene risolto in fase di esecuzione del processo e {output_name} è il nome definito nel YAML del componente. È possibile personalizzare la posizione in cui archiviare l'output definendo un percorso di output.
Il file pipeline.yml nella pipeline train-score-eval con componenti registrati di esempio definisce una pipeline con tre output a livello di pipeline. Usare il comando seguente per impostare percorsi di output personalizzati per l'output pipeline_job_trained_model :
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Scaricare gli output
È possibile scaricare gli output a livello di pipeline o componente.
Scaricare gli output a livello di pipeline
È possibile scaricare tutti gli output di un processo o scaricare un output specifico.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

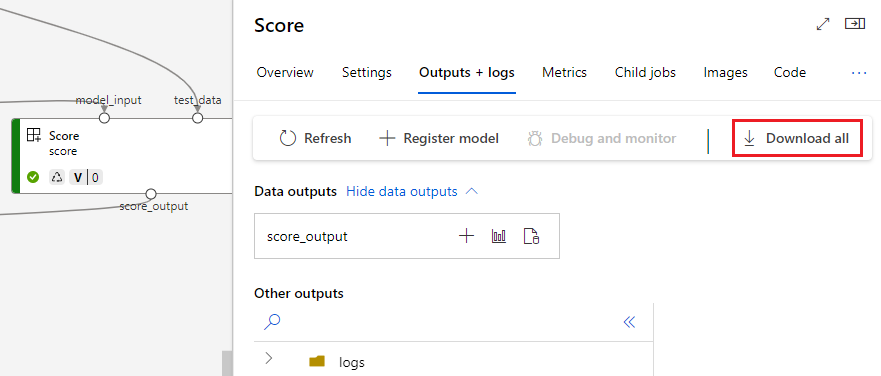
Scaricare gli output dei componenti
Per scaricare gli output di un componente figlio, elencare prima tutti i processi figlio di un processo della pipeline quindi usare codice simile per scaricare gli output.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
Registrare l'output come asset denominato
È possibile registrare l'output di un componente o di una pipeline come asset denominato assegnando name e version all'output. L'asset registrato può essere elencato nell'area di lavoro tramite l'interfaccia utente, l'interfaccia della riga di comando o l'SDK di Studio e può essere fatto riferimento nei processi futuri dell'area di lavoro.
Registrare l'output a livello di pipeline
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster