Creare processi e inserire dati negli endpoint batch
Quando si usano endpoint batch in Azure Machine Learning, è possibile eseguire operazioni batch lunghe su grandi quantità di dati di input. I dati possono trovarsi in posizioni diverse, ad esempio in aree diverse. Determinati tipi di endpoint batch possono anche ricevere parametri letterali come input.
Questo articolo descrive come specificare gli input dei parametri per gli endpoint batch e creare i processi di distribuzione. Il processo supporta l'uso di dati provenienti da varie origini, ad esempio asset di dati, archivi dati, account di archiviazione e file locali.
Prerequisiti
Endpoint e distribuzione batch. Per creare queste risorse, vedere Distribuire modelli MLflow nelle distribuzioni batch in Azure Machine Learning.
Autorizzazioni per eseguire una distribuzione di endpoint batch. È possibile usare i ruoli azureML Scienziato dei dati, collaboratore e proprietario per eseguire una distribuzione. Per esaminare le autorizzazioni specifiche necessarie per le definizioni di ruolo personalizzate, vedere Autorizzazione sugli endpoint batch.
Credenziali per richiamare un endpoint. Per altre informazioni, vedere Stabilire l'autenticazione.
Accesso in lettura ai dati di input dal cluster di calcolo in cui viene distribuito l'endpoint.
Suggerimento
Alcune situazioni richiedono l'uso di un archivio dati senza credenziali o di un account Archiviazione di Azure esterno come input di dati. In questi scenari assicurarsi di configurare i cluster di calcolo per l'accesso ai dati, perché l'identità gestita del cluster di calcolo viene usata per il montaggio dell'account di archiviazione. È ancora disponibile un controllo di accesso granulare, perché l'identità del processo (invoker) viene usata per leggere i dati sottostanti.
Stabilire l'autenticazione
Per richiamare un endpoint, è necessario un token Microsoft Entra valido. Quando si richiama un endpoint, Azure Machine Learning crea un processo di distribuzione batch con l'identità associata al token.
- Se si usa l'interfaccia della riga di comando di Azure Machine Learning (v2) o Azure Machine Learning SDK per Python (v2) per richiamare gli endpoint, non è necessario ottenere manualmente il token Microsoft Entra. Durante l'accesso, il sistema autentica l'identità dell'utente. Recupera e passa automaticamente il token.
- Se si usa l'API REST per richiamare gli endpoint, è necessario ottenere il token manualmente.
Per la chiamata è possibile usare le proprie credenziali, come descritto nelle procedure seguenti.
Usare l'interfaccia della riga di comando di Azure per accedere con autenticazione interattiva o con codice dispositivo:
az login
Per altre informazioni sui vari tipi di credenziali, vedere Come eseguire processi usando tipi diversi di credenziali.
Creare processi di base
Per creare un processo da un endpoint batch, richiamare l'endpoint. La chiamata può essere eseguita usando l'interfaccia della riga di comando di Azure Machine Learning, Azure Machine Learning SDK per Python o una chiamata API REST.
Gli esempi seguenti illustrano le nozioni di base sulla chiamata per un endpoint batch che riceve una singola cartella di dati di input per l'elaborazione. Per esempi che coinvolgono vari input e output, vedere Informazioni su input e output.
Usare l'operazione invoke negli endpoint batch:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Richiamare una distribuzione specifica
Gli endpoint batch possono ospitare più distribuzioni nello stesso endpoint. Viene usato l'endpoint predefinito, a meno che l'utente non specifichi diversamente. È possibile usare le procedure seguenti per modificare la distribuzione usata.
Usare l'argomento --deployment-name o -d per specificare il nome della distribuzione:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Configurare le proprietà del processo
È possibile configurare alcune proprietà del processo in fase di chiamata.
Nota
Attualmente, è possibile configurare le proprietà del processo solo negli endpoint batch con distribuzioni dei componenti della pipeline.
Configurare il nome dell'esperimento
Usare le procedure seguenti per configurare il nome dell'esperimento.
Usare l'argomento --experiment-name per specificare il nome dell'esperimento:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Spiegare input e output
Gli endpoint batch forniscono un'API durevole che i consumer possono usare per creare processi batch. La stessa interfaccia può essere usata per specificare gli input e gli output previsti dalla distribuzione. Usare gli input per passare all'endpoint le informazioni necessarie per eseguire il processo.
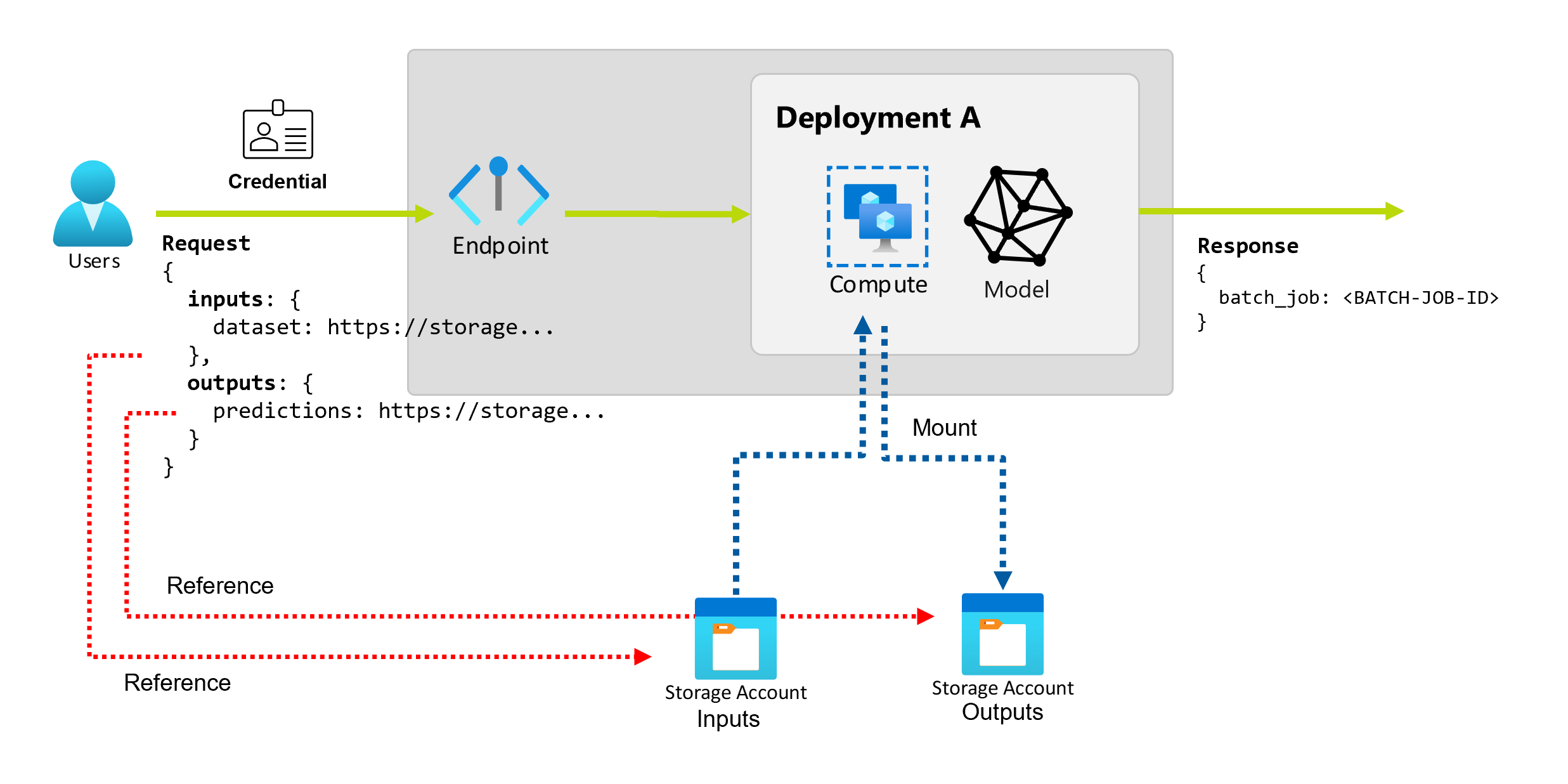
Gli endpoint batch supportano due tipi di input:
- Input di dati o puntatori a una posizione di archiviazione specifica o a un asset di Azure Machine Learning
- Input letterali o valori letterali come numeri o stringhe da passare al processo
Il numero e il tipo di input e output dipendono dal tipo di distribuzione batch. Le distribuzioni di modelli richiedono sempre un input di dati e producono un output dei dati. Gli input letterali non sono supportati nelle distribuzioni di modelli. Al contrario, le distribuzioni dei componenti della pipeline forniscono un costrutto più generale per la compilazione di endpoint. In una distribuzione dei componenti della pipeline è possibile specificare un numero qualsiasi di input di dati, input letterali e output.
La tabella seguente riepiloga gli input e gli output per le distribuzioni batch:
| Tipo di distribuzione | Numero di input | Tipi di input supportati | Numero di output | Tipi di output supportati |
|---|---|---|---|---|
| Distribuzione di modelli | 1 | Input dei dati | 1 | Output dei dati |
| Distribuzione di componenti della pipeline | 0-N | Input di dati e input letterali | 0-N | Output dei dati |
Suggerimento
Gli input e gli output sono sempre denominati. Ogni nome funge da chiave per identificare i dati e passare il valore durante la chiamata. Poiché le distribuzioni di modelli richiedono sempre un input e un output, i nomi vengono ignorati durante la chiamata nelle distribuzioni del modello. È possibile assegnare il nome che descrive meglio il caso d'uso, ad esempio sales_estimation.
Esplorare gli input dei dati
Gli input di dati fanno riferimento agli input che puntano a un percorso in cui vengono inseriti i dati. Poiché gli endpoint batch usano in genere grandi quantità di dati, non è possibile passare i dati di input come parte della richiesta di chiamata. Specificare invece il percorso in cui l'endpoint batch deve cercare i dati. I dati di input vengono montati e trasmessi nell'istanza di calcolo di destinazione per migliorare le prestazioni.
Gli endpoint batch possono leggere i file che si trovano nei tipi di archiviazione seguenti:
-
Asset di dati di Azure Machine Learning, inclusi i tipi di cartella (
uri_folder) e file (uri_file). - Archivi dati di Azure Machine Learning, tra cui Archiviazione BLOB di Azure, Azure Data Lake Storage Gen1 e Azure Data Lake Storage Gen2.
- Archiviazione di Azure account, tra cui Archiviazione BLOB, Data Lake Storage Gen1 e Data Lake Storage Gen2.
- Cartelle e file di dati locali, quando si usa l'interfaccia della riga di comando di Azure Machine Learning o Azure Machine Learning SDK per Python per richiamare gli endpoint. I dati locali vengono tuttavia caricati nell'archivio dati predefinito dell'area di lavoro di Azure Machine Learning.
Importante
Avviso di deprecazione: gli asset di dati di tipo FileDataset (V1) sono deprecati e verranno ritirati in futuro. Gli endpoint batch esistenti che si basano su questa funzionalità continueranno a funzionare. Tuttavia, non è disponibile alcun supporto per i set di dati V1 negli endpoint batch creati con:
- Versioni dell'interfaccia della riga di comando di Azure Machine Learning v2 disponibili a livello generale (2.4.0 e versioni successive).
- Versioni dell'API REST disponibili a livello generale (2022-05-01 e versioni successive).
Esplorare gli input letterali
Gli input letterali fanno riferimento a input che possono essere rappresentati e risolti in fase di chiamata, ad esempio stringhe, numeri e valori booleani. In genere, si usano input letterali per passare parametri all'endpoint come parte della distribuzione di un componente della pipeline. Gli endpoint batch supportano i tipi letterali seguenti:
stringbooleanfloatinteger
Gli input letterali sono supportati solo nelle distribuzioni dei componenti della pipeline. Per informazioni su come specificare endpoint letterali, vedere Creare processi con input letterali.
Esplorare gli output dei dati
Gli output dei dati fanno riferimento alla posizione in cui vengono inseriti i risultati di un processo batch. Ogni output ha un nome identificabile e Azure Machine Learning assegna automaticamente un percorso univoco a ciascun output denominato. Se necessario, è possibile specificare un altro percorso.
Importante
Gli endpoint batch supportano solo la scrittura di output negli archivi dati di archiviazione BLOB. Se è necessario scrivere in un account di archiviazione con spazi dei nomi gerarchici abilitati, ad esempio Data Lake Storage Gen2, è possibile registrare il servizio di archiviazione come archivio dati di archiviazione BLOB, perché i servizi sono completamente compatibili. In questo modo, è possibile scrivere output da endpoint batch in Data Lake Storage Gen2.
Creare processi con input di dati
Gli esempi seguenti illustrano come creare processi durante l'acquisizione di input di dati da asset di dati, archivi dati e account Archiviazione di Azure.
Usare i dati di input da un asset di dati
Gli asset di dati di Azure Machine Learning (noti in precedenza come set di dati) sono supportati come input per i processi. Seguire questa procedura per eseguire un processo di endpoint batch che usa i dati di input archiviati in un asset di dati registrato in Azure Machine Learning.
Avviso
Gli asset di dati della tabella di tipo (MLTable) non sono attualmente supportati.
Creare l'asset di dati. In questo esempio è costituita da una cartella che contiene più file CSV. Gli endpoint batch vengono usati per elaborare i file in parallelo. È possibile ignorare questo passaggio se i dati sono già registrati come asset di dati.
Creare una definizione di asset di dati in un file YAML denominato heart-data.yml:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataCreare l'asset di dati:
az ml data create -f heart-data.yml
Configurare l'input:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)L'ID asset di dati ha il formato
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Eseguire l'endpoint:
Utilizzare l'argomento
--setper specificare l'input. Sostituire prima qualsiasi trattino nel nome dell'asset di dati con caratteri di sottolineatura. Le chiavi possono contenere solo caratteri alfanumerici e caratteri di sottolineatura.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDPer un endpoint che gestisce una distribuzione del modello, è possibile usare l'argomento per specificare l'input
--inputdei dati, perché una distribuzione del modello richiede sempre un solo input di dati.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_IDL'argomento
--settende a produrre comandi lunghi quando si specificano più input. In questi casi, è possibile elencare gli input in un file e quindi fare riferimento al file quando si richiama l'endpoint. Ad esempio, è possibile creare un file YAML denominato inputs.yml che contiene le righe seguenti:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1È quindi possibile eseguire il comando seguente, che usa l'argomento
--fileper specificare gli input:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Usare i dati di input da un archivio dati
I processi di distribuzione batch possono fare riferimento direttamente ai dati presenti negli archivi dati registrati di Azure Machine Learning. In questo esempio si caricano prima alcuni dati in un archivio dati nell'area di lavoro di Azure Machine Learning. Quindi si esegue una distribuzione batch su tali dati.
Questo esempio usa l'archivio dati predefinito, ma è possibile usare un archivio dati diverso. In qualsiasi area di lavoro di Azure Machine Learning il nome dell'archivio dati BLOB predefinito è workspaceblobstore. Se si vuole usare un archivio dati diverso nei passaggi seguenti, sostituire workspaceblobstore con il nome dell'archivio dati preferito.
Caricare dati di esempio nell'archivio dati. I dati di esempio sono disponibili nel repository azureml-examples . È possibile trovare i dati nella cartella sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data del repository.
- In studio di Azure Machine Learning aprire la pagina degli asset di dati per l'archivio dati BLOB predefinito e quindi cercare il nome del contenitore BLOB.
- Usare uno strumento come Archiviazione di Azure Explorer o AzCopy per caricare i dati di esempio in una cartella denominata heart-disease-uci-unlabeled in tale contenitore.
Configurare le informazioni di input:
Posizionare il percorso del file nella variabile
INPUT_PATH:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Si noti che la
pathscartella fa parte del percorso di input. Questo formato indica che il valore che segue è un percorso.Eseguire l'endpoint:
Usare l'argomento
--setper specificare l'input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHPer un endpoint che gestisce una distribuzione del modello, è possibile usare l'argomento per specificare l'input
--inputdei dati, perché una distribuzione del modello richiede sempre un solo input di dati.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderL'argomento
--settende a produrre comandi lunghi quando si specificano più input. In questi casi, è possibile elencare gli input in un file e quindi fare riferimento al file quando si richiama l'endpoint. Ad esempio, è possibile creare un file YAML denominato inputs.yml che contiene le righe seguenti:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Se i dati si trovano in un file, usare invece il
uri_filetipo per l'input.È quindi possibile eseguire il comando seguente, che usa l'argomento
--fileper specificare gli input:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Usare i dati di input da un account Archiviazione di Azure
Gli endpoint batch di Azure Machine Learning possono leggere i dati dalle posizioni cloud in account Archiviazione di Azure, sia pubblici che privati. Usare la procedura seguente per eseguire un processo dell'endpoint batch con i dati in un account di archiviazione.
Per altre informazioni sulle configurazioni aggiuntive necessarie per la lettura dei dati dagli account di archiviazione, vedere Configurare i cluster di calcolo per l'accesso ai dati.
Configurare l'input:
Impostare la variabile
INPUT_DATA:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Se i dati si trovano in un file, usare un formato simile al seguente per definire il percorso di input:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Eseguire l'endpoint:
Usare l'argomento
--setper specificare l'input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAPer un endpoint che gestisce una distribuzione del modello, è possibile usare l'argomento per specificare l'input
--inputdei dati, perché una distribuzione del modello richiede sempre un solo input di dati.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderL'argomento
--settende a produrre comandi lunghi quando si specificano più input. In questi casi, è possibile elencare gli input in un file e quindi fare riferimento al file quando si richiama l'endpoint. Ad esempio, è possibile creare un file YAML denominato inputs.yml che contiene le righe seguenti:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataÈ quindi possibile eseguire il comando seguente, che usa l'argomento
--fileper specificare gli input:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlSe i dati si trovano in un file, usare il
uri_filetipo nel file inputs.yml per l'input dei dati.
Creare processi con input letterali
Le distribuzioni dei componenti della pipeline possono accettare input letterali. Per un esempio di distribuzione batch che contiene una pipeline di base, vedere Come distribuire pipeline con endpoint batch.
Nell'esempio seguente viene illustrato come specificare un input denominato score_mode, di tipo string, con un valore append:
Inserire gli input in un file YAML, ad esempio uno denominato inputs.yml:
inputs:
score_mode:
type: string
default: append
Eseguire il comando seguente, che usa l'argomento --file per specificare gli input.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
È anche possibile usare l'argomento --set per specificare il tipo e il valore predefinito. Tuttavia, questo approccio tende a produrre comandi lunghi quando si specificano più input:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Creare processi con output di dati
Nell'esempio seguente viene illustrato come modificare la posizione di un output denominato score. Per completezza, l'esempio configura anche un input denominato heart_data.
Questo esempio usa l'archivio dati predefinito, workspaceblobstore. Tuttavia, è possibile usare qualsiasi altro archivio dati nell'area di lavoro, purché si tratti di un account di archiviazione BLOB. Se si vuole usare un archivio dati diverso, sostituire workspaceblobstore nei passaggi seguenti con il nome dell'archivio dati preferito.
Ottenere l'ID dell'archivio dati.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')L'ID dell'archivio dati ha il formato
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Creare un output dei dati:
Definire i valori di input e output in un file denominato inputs-and-outputs.yml. Usare l'ID dell'archivio dati nel percorso di output. Per completezza, definire anche l'input dei dati.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathNota
Si noti che la
pathscartella fa parte del percorso di output. Questo formato indica che il valore che segue è un percorso.Eseguire la distribuzione:
Usare l'argomento
--fileper specificare i valori di input e output:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml