Eseguire stime batch tramite la finestra di progettazione di Azure Machine Learning
In questo articolo viene descritto come usare la finestra di progettazione per creare una pipeline di stima in batch. La stima in batch consente di assegnare in modo continuo un punteggio a set di dati di grandi dimensioni su richiesta usando un servizio Web che può essere attivato da qualsiasi libreria HTTP.
In questa guida pratica si apprenderà come eseguire queste attività:
- Creare e pubblicare una pipeline di inferenza batch
- Utilizzo di un endpoint della pipeline
- Gestire le versioni degli endpoint
Per informazioni su come configurare i servizi di assegnazione dei punteggi batch con l'SDK, vedere l'esercitazione associata sull'assegnazione dei punteggi batch alla pipeline.
Prerequisiti
In questa guida pratica si presuppone che sia già presente una pipeline di training. Per un'introduzione guidata alla finestra di progettazione, eseguire la prima parte dell'esercitazione relativa alla finestra di progettazione.
Importante
Se gli elementi grafici citati in questo documento non vengono visualizzati, ad esempio i pulsanti di Studio o della finestra di progettazione, è possibile che non si abbia il livello di autorizzazioni appropriato per l'area di lavoro. Contattare l'amministratore della sottoscrizione di Azure per verificare che sia stato concesso il livello di accesso corretto. Per altre informazioni, vedere Gestire utenti e ruoli.
Creare una pipeline di inferenza batch
La pipeline di training deve essere eseguita almeno una volta per poter creare una pipeline di inferenza.
Passare alla scheda Finestra di progettazione nell'area di lavoro.
Selezionare la pipeline di training che esegue il training del modello che si desidera usare per la stima.
Inviare la pipeline.
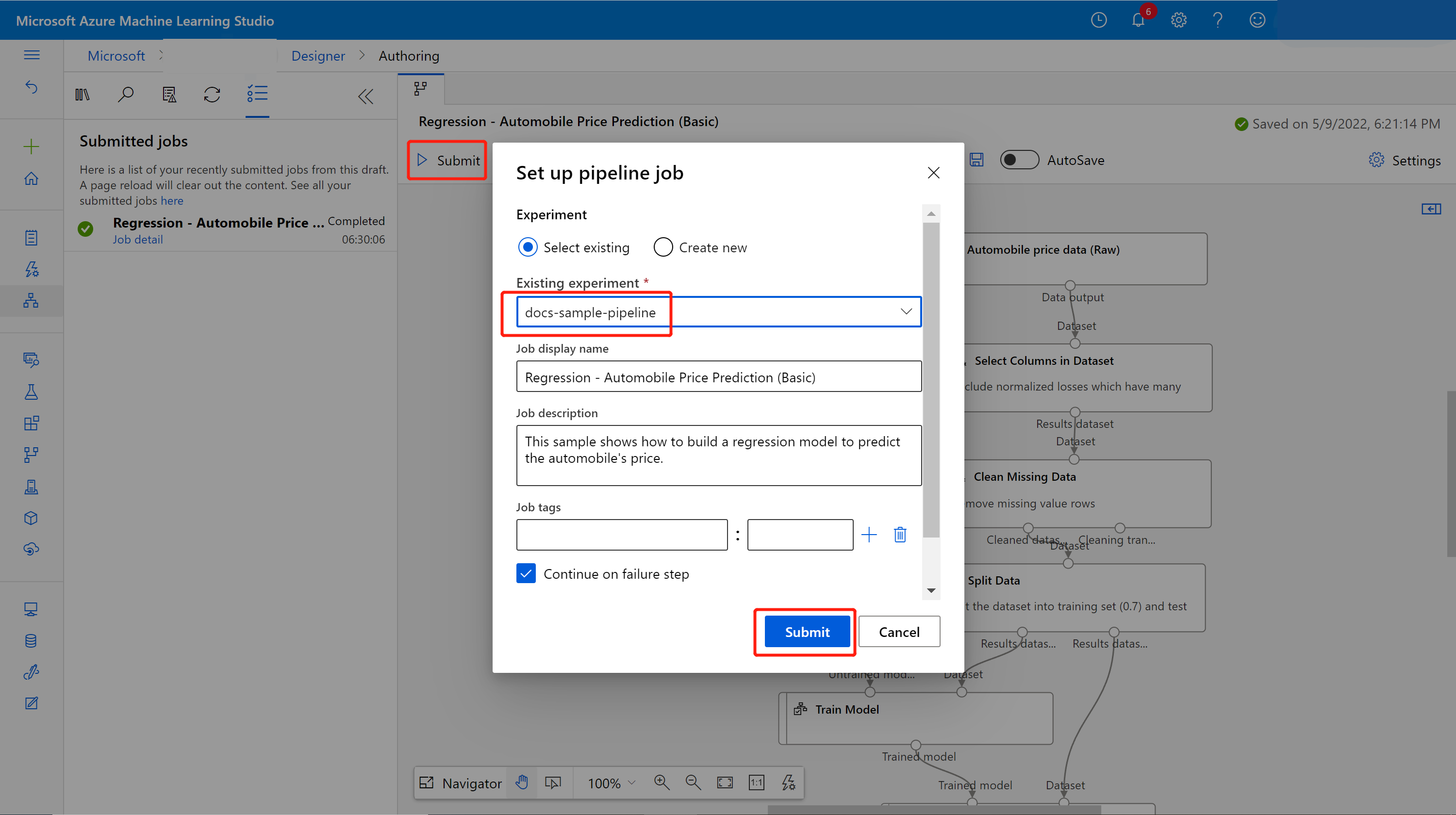

Verrà visualizzato un elenco di invii a sinistra del canvas. È possibile selezionare il collegamento dei dettagli del processo per passare alla pagina dei dettagli del processo e, al termine del processo della pipeline di training, è possibile creare una pipeline di inferenza batch.

Nella pagina dei dettagli del processo, sull’area canvas, selezionare l'elenco a discesa Crea pipeline di inferenza. Selezionare Batch inference pipeline (Pipeline inferenza batch).
Nota
Attualmente la pipeline di inferenza generata automaticamente funziona solo per la pipeline di training compilata esclusivamente dai componenti integrati della finestra di progettazione.
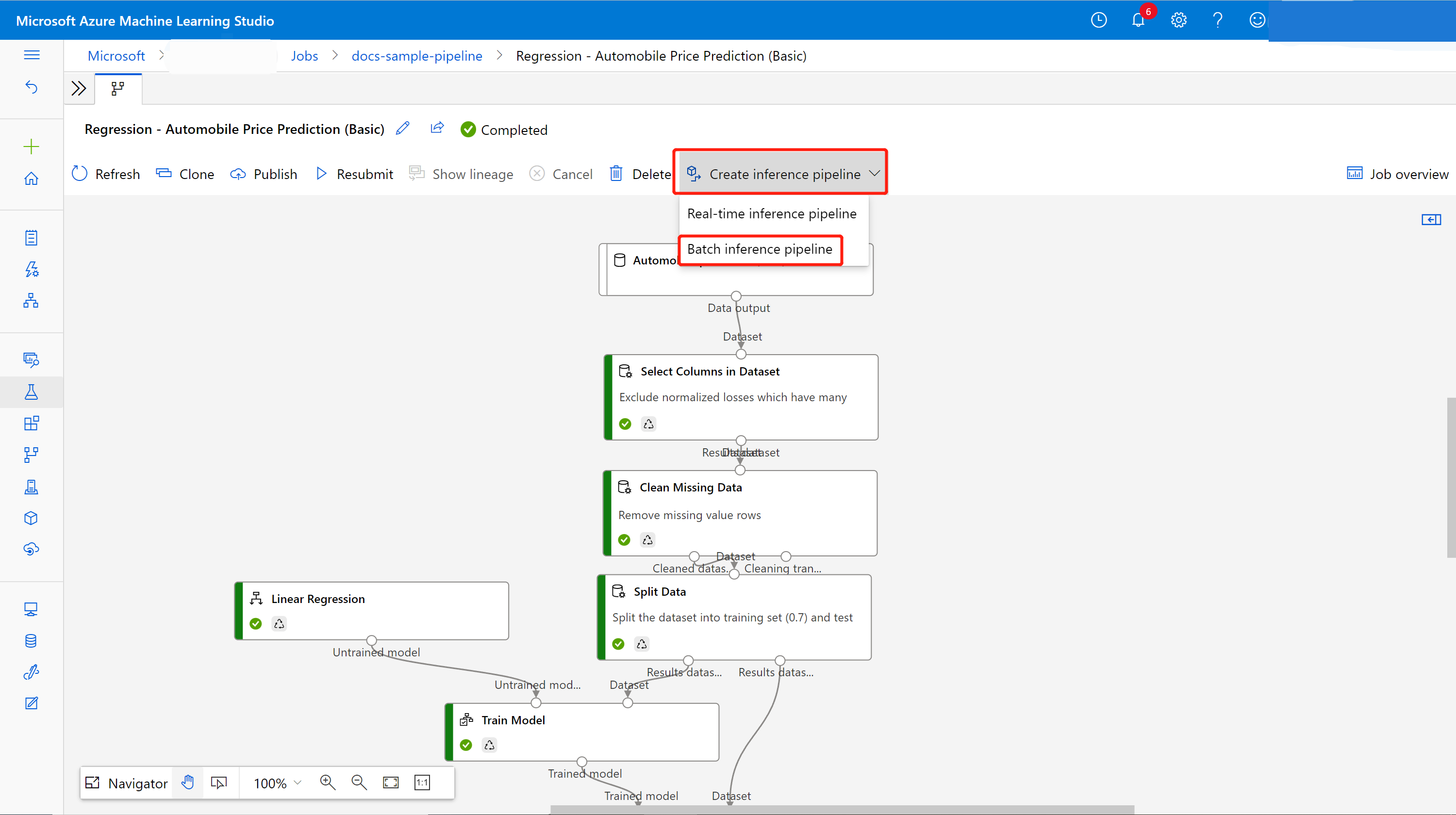
Creerà automaticamente una bozza di pipeline di inferenza batch. La bozza di pipeline di inferenza batch usa il modello sottoposto a training come nodo MD- e la trasformazione come nodo TD- dal processo della pipeline di training.
È anche possibile modificare questa bozza di pipeline di inferenza per gestire meglio i dati di input per l'inferenza batch.
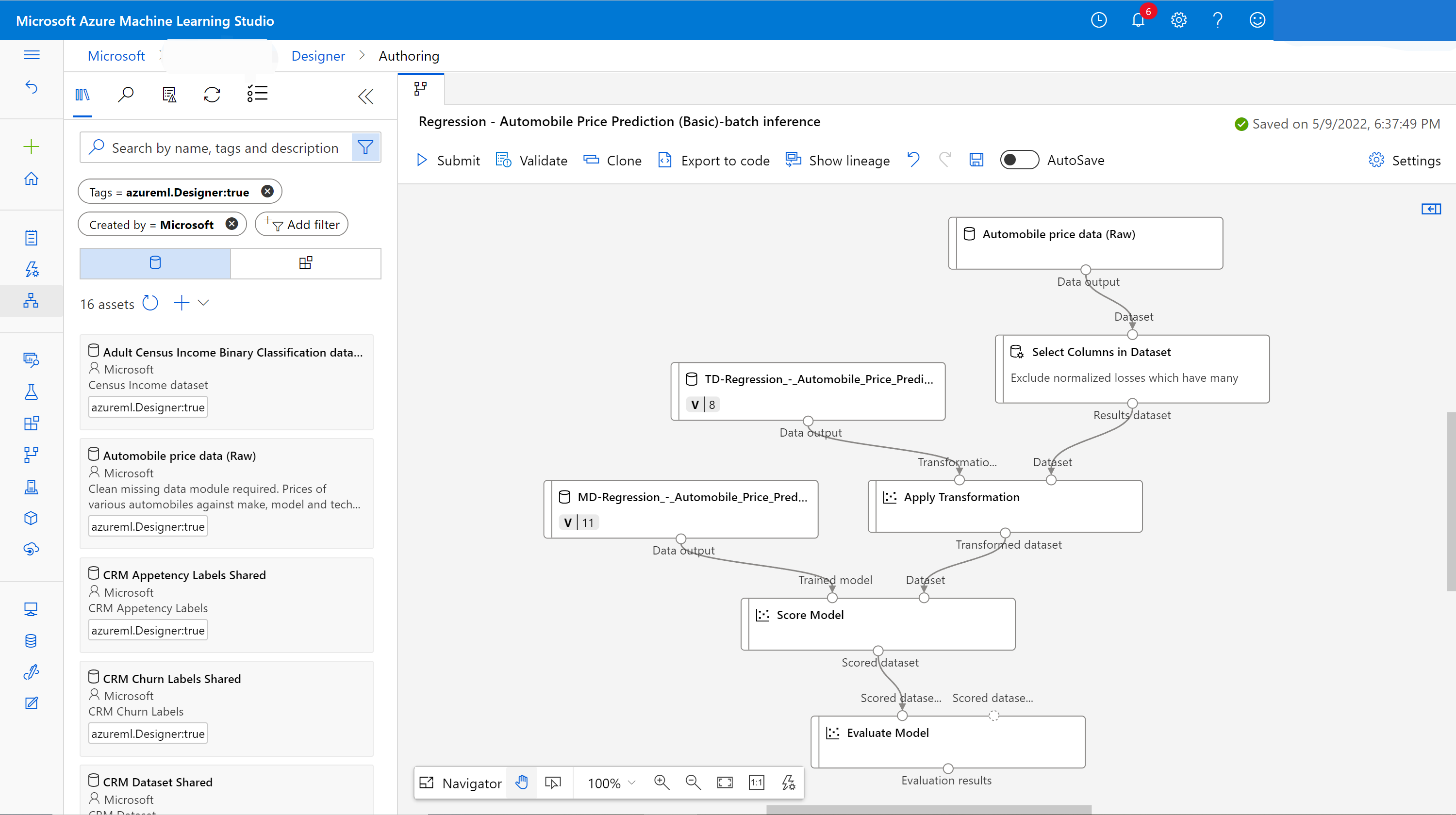


Aggiungere un parametro della pipeline
Per creare stime sui nuovi dati, è possibile connettere manualmente un set di dati diverso nella visualizzazione bozza della pipeline o creare un parametro per il set di dati. I parametri consentono di modificare il comportamento del processo di inferenza batch durante il runtime.
In questa sezione viene creato un parametro del set di dati per specificare un set di dati diverso per cui eseguire stime.
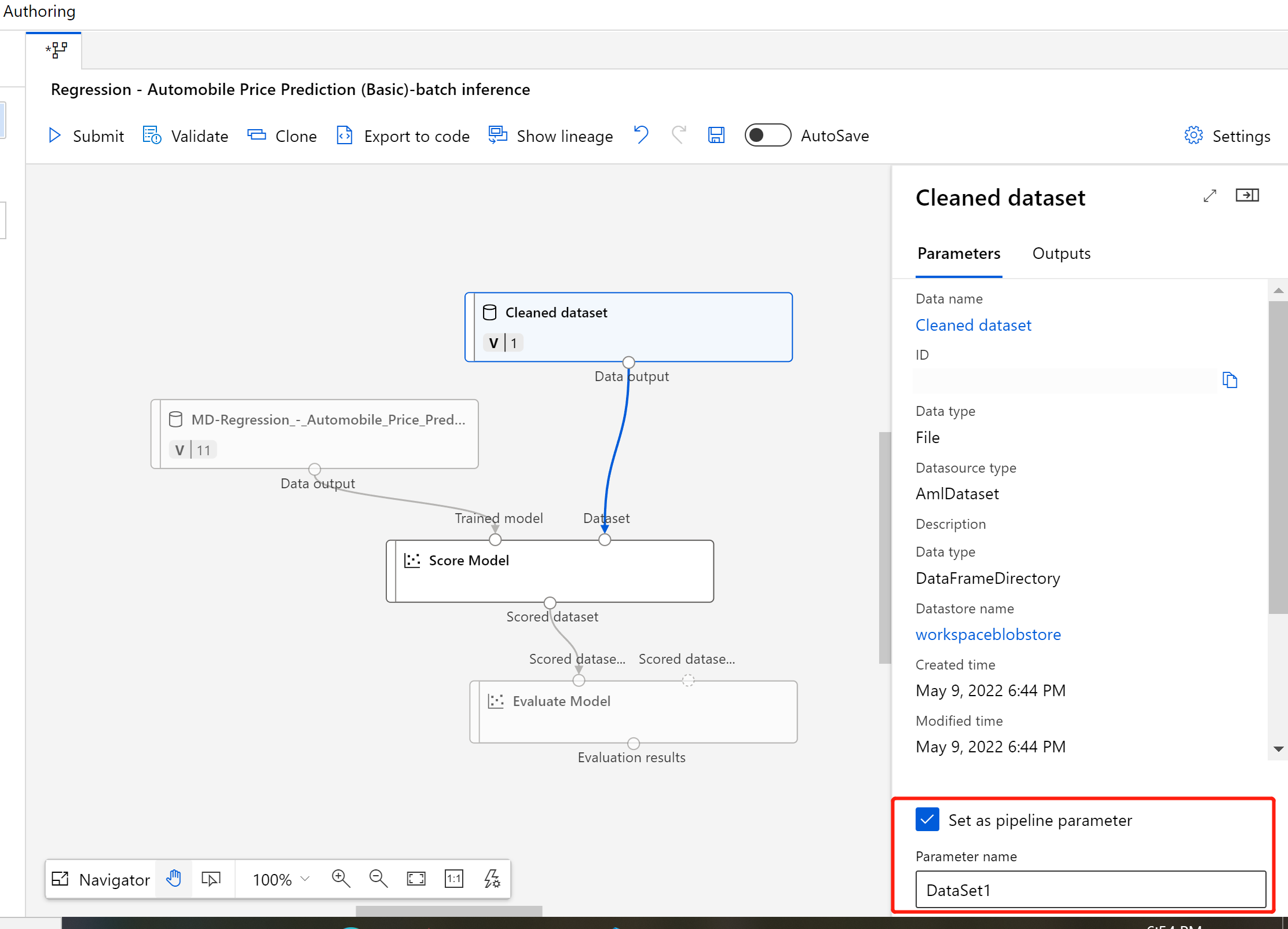
Selezionare il componente di set di dati.
Viene visualizzato un riquadro a destra dell'area di disegno. Nella parte inferiore del riquadro selezionare Set as pipeline parameter (Imposta come parametro pipeline).
Immettere un nome per il parametro o accettare il valore predefinito.
Inviare la pipeline di inferenza batch e passare alla pagina dei dettagli del processo selezionando il collegamento al processo nel riquadro sinistro.

Pubblicare la pipeline di inferenza batch
A questo punto è possibile distribuire la pipeline di inferenza. La pipeline verrà distribuita e resa disponibile per l'uso da parte di altri utenti.
Selezionare il pulsante Pubblica.
Nella finestra di dialogo visualizzata espandere l'elenco a discesa di PipelineEndpoint e selezionare New PipelineEndpoint (Nuovo PipelineEndpoint).
Specificare un nome e una descrizione facoltativa per l'endpoint.
Nella parte inferiore della finestra di dialogo è possibile visualizzare il parametro configurato con un valore predefinito dell'ID set di dati usato durante il training.
Selezionare Pubblica.

Utilizzare un endpoint
A questo punto è disponibile una pipeline pubblicata con un parametro del set di dati. La pipeline userà il modello di cui è stato eseguito il training creato nella pipeline di training per assegnare un punteggio al set di dati specificato come parametro.
Inviare il processo della pipeline
In questa sezione verrà configurato un processo manuale della pipeline e verrà modificato il parametro della pipeline per assegnare un punteggio ai nuovi dati.
Al termine della distribuzione, passare alla sezione Endpoints (Endpoint).
Selezionare Pipeline endpoints (Endpoint pipeline).
Selezionare il nome dell'endpoint creato.
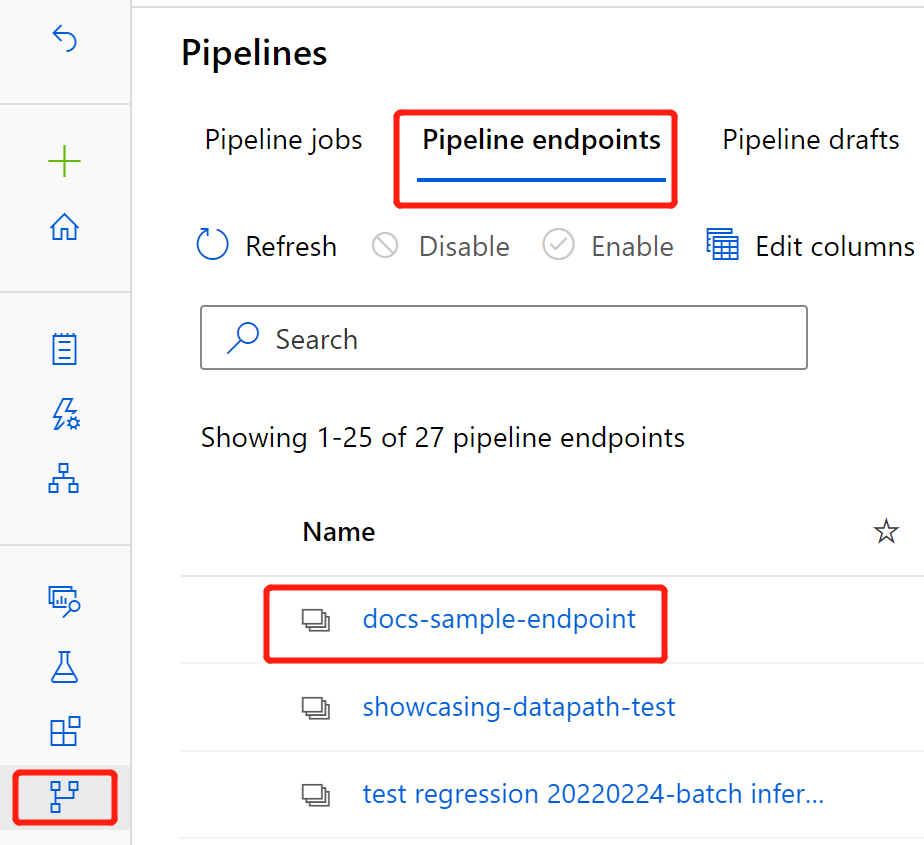
Selezionare Published pipelines (Pipeline pubblicate).
Questa schermata mostra tutte le pipeline pubblicate nell'endpoint.
Selezionare la pipeline pubblicata.
La pagina dei dettagli della pipeline mostra una cronologia processo dettagliata e le informazioni della stringa di connessione per la pipeline.
Selezionare Submit (Invia) per creare un'esecuzione manuale della pipeline.
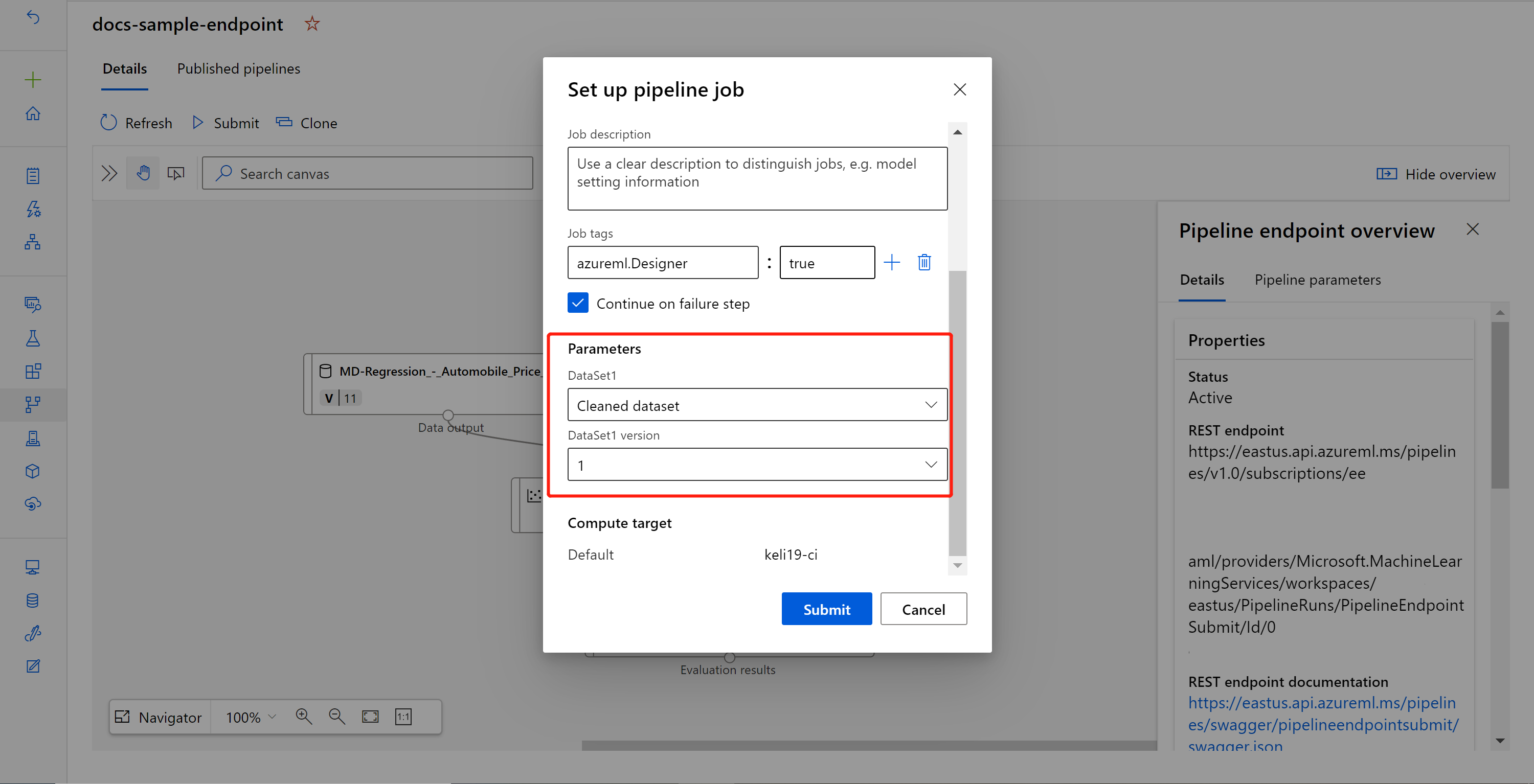
Modificare il parametro per usare un set di dati diverso.
Selezionare Submit (Invia) per eseguire la pipeline.

Usare l'endpoint REST
Per informazioni su come utilizzare gli endpoint della pipeline e la pipeline pubblicata, vedere la sezione Endpoints (Endpoint).
È possibile trovare l'endpoint REST di un endpoint della pipeline nel pannello di panoramica del processo. Chiamando l'endpoint, si utilizza la pipeline pubblicata predefinita.
È anche possibile utilizzare una pipeline pubblicata nella pagina Published pipelines (Pipeline pubblicate). Selezionare una pipeline pubblicata ed è possibile trovarne l'endpoint REST nel pannello Panoramica della pipeline pubblicata a destra del grafo.
Per eseguire una chiamata REST sarà necessaria un'intestazione di autenticazione di tipo bearer token OAuth 2.0. Vedere la sezione dell'esercitazione seguente per informazioni più dettagliate sulla configurazione dell'autenticazione per l'area di lavoro e l'esecuzione di una chiamata REST con parametri.
Controllo delle versioni degli endpoint
La finestra di progettazione assegna una versione a ogni pipeline successiva pubblicata in un endpoint. È possibile specificare la versione della pipeline che si vuole eseguire come parametro nella chiamata REST. Se non si specifica un numero di versione, la finestra di progettazione userà la pipeline predefinita.
Quando si pubblica una pipeline, è possibile scegliere di impostarla come nuova pipeline predefinita per l'endpoint.
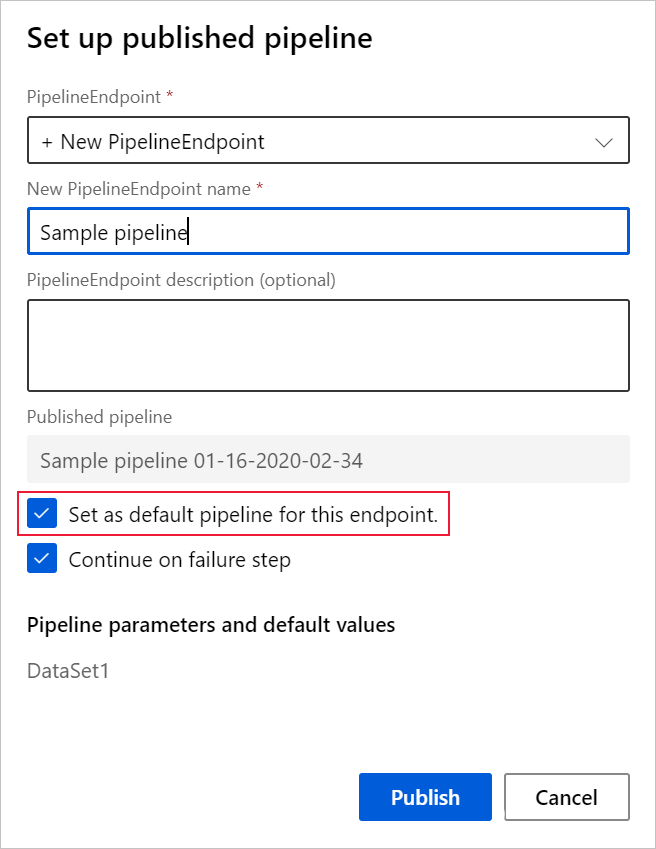
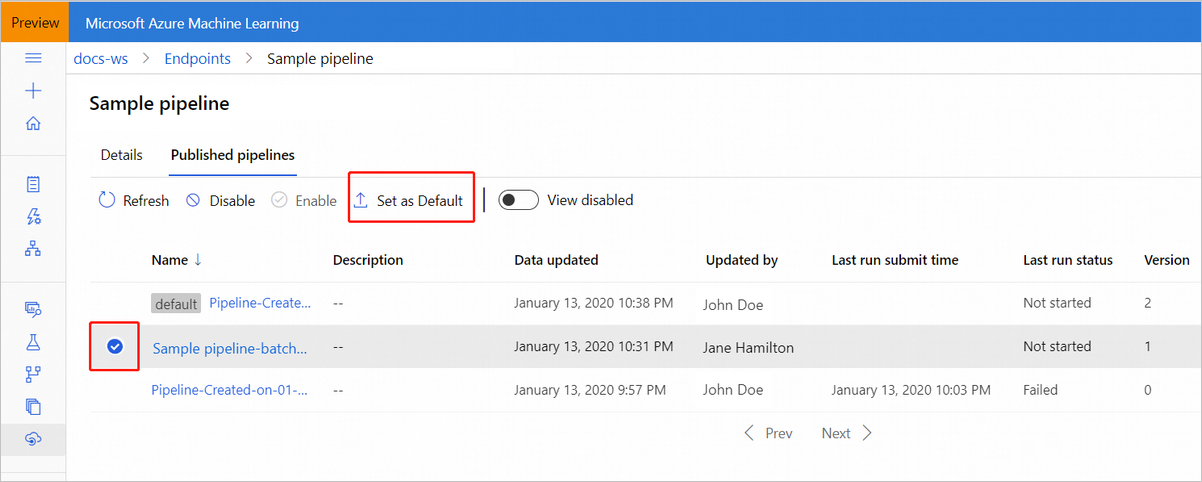
È anche possibile impostare una nuova pipeline predefinita nella scheda Published pipelines (Pipeline pubblicate) dell'endpoint.
Aggiorna l’endpoint della pipeline
Se si apportano alcune modifiche nella pipeline di training, è possibile aggiornare il modello appena sottoposto a training all'endpoint della pipeline.
Al termine della modifica della pipeline di training, passare alla pagina dei dettagli del processo.
Fare clic con il pulsante destro del mouse sul componente Eseguire il training del modello e selezionare Registra data
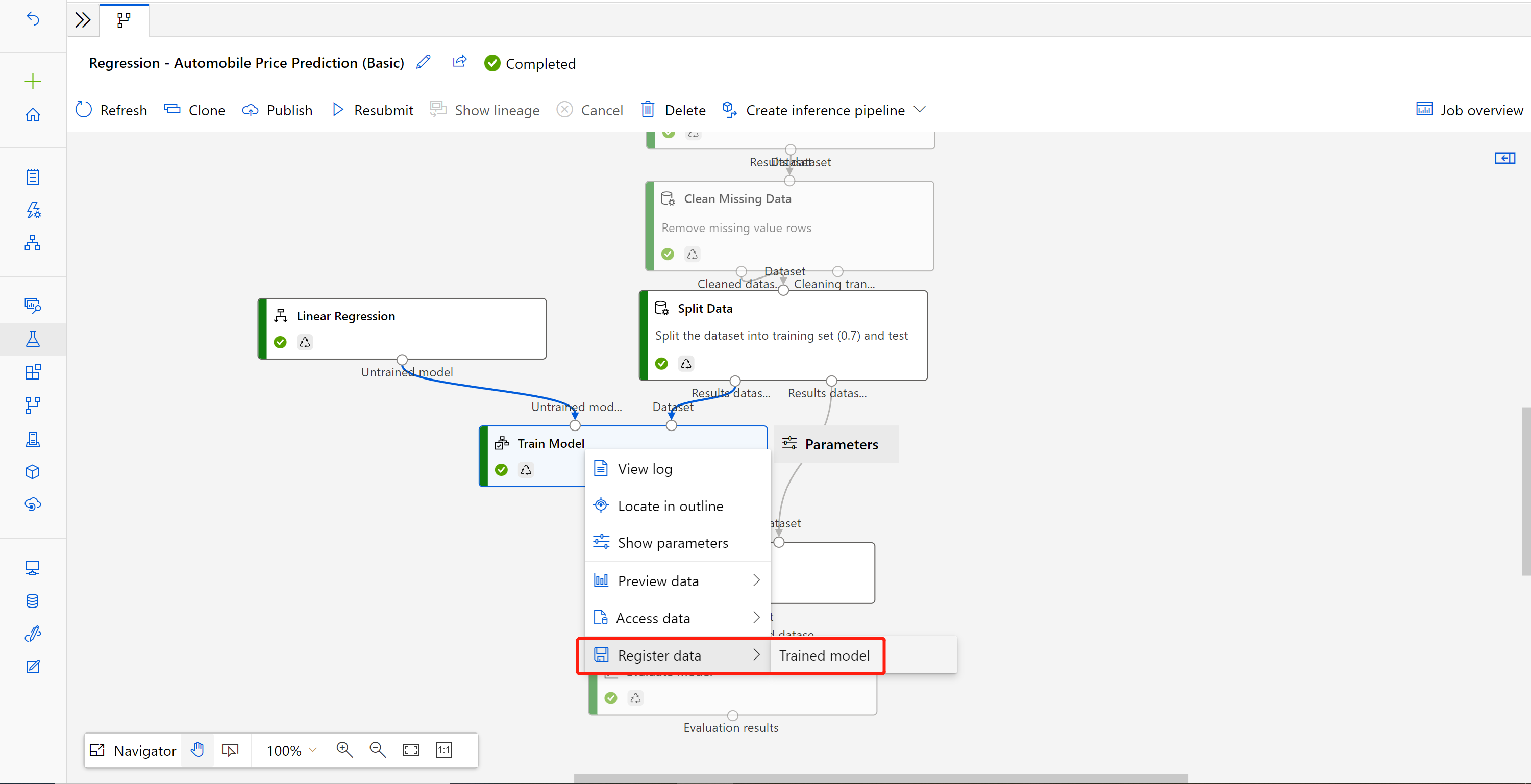
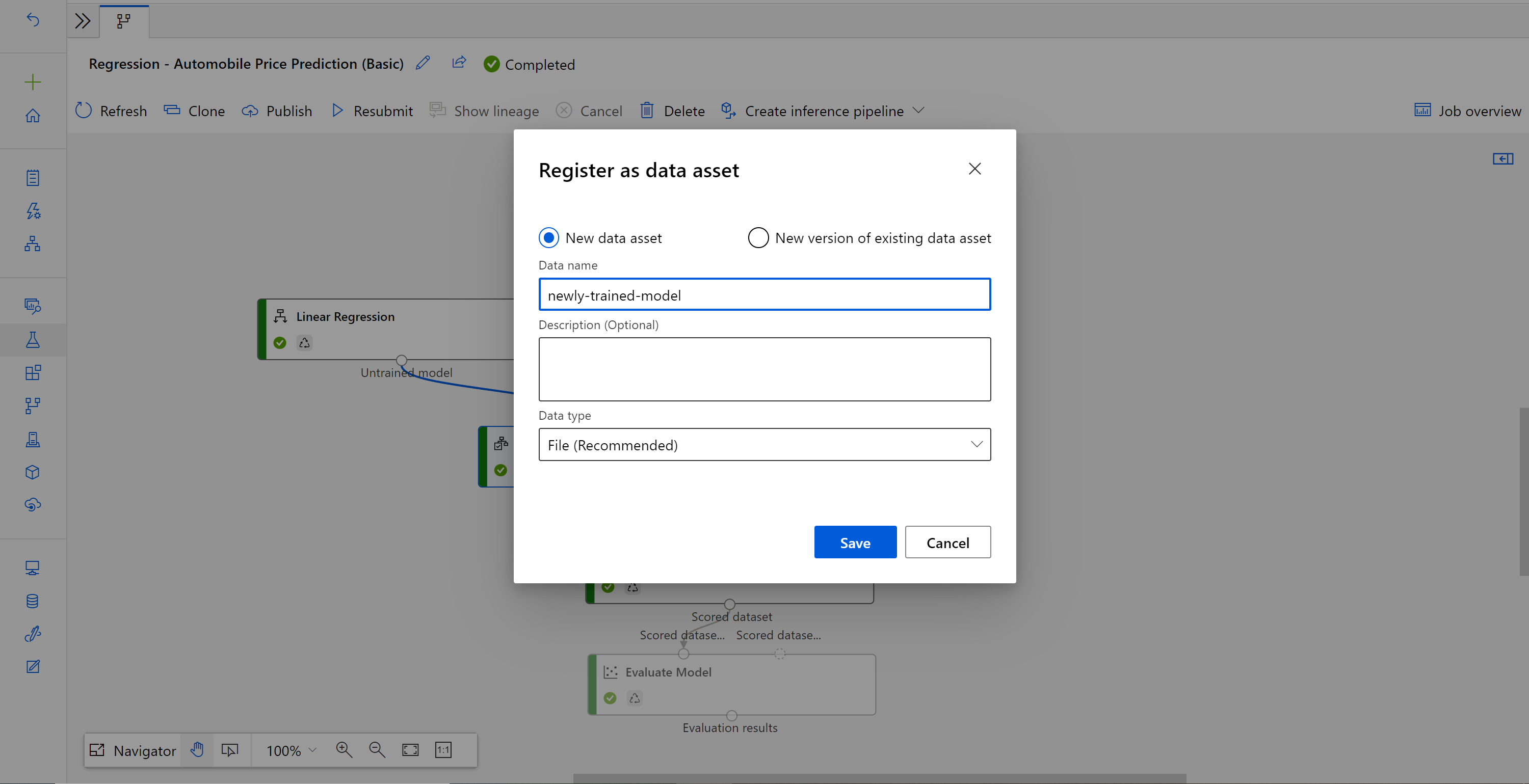
Immettere il nome e selezionare il tipo di File.
Trovare la bozza di pipeline di inferenza batch precedente oppure è Clonare la pipeline pubblicata in una nuova bozza.
Sostituire il nodo MD- nella bozza di pipeline di inferenza con i dati registrati nel passaggio precedente.
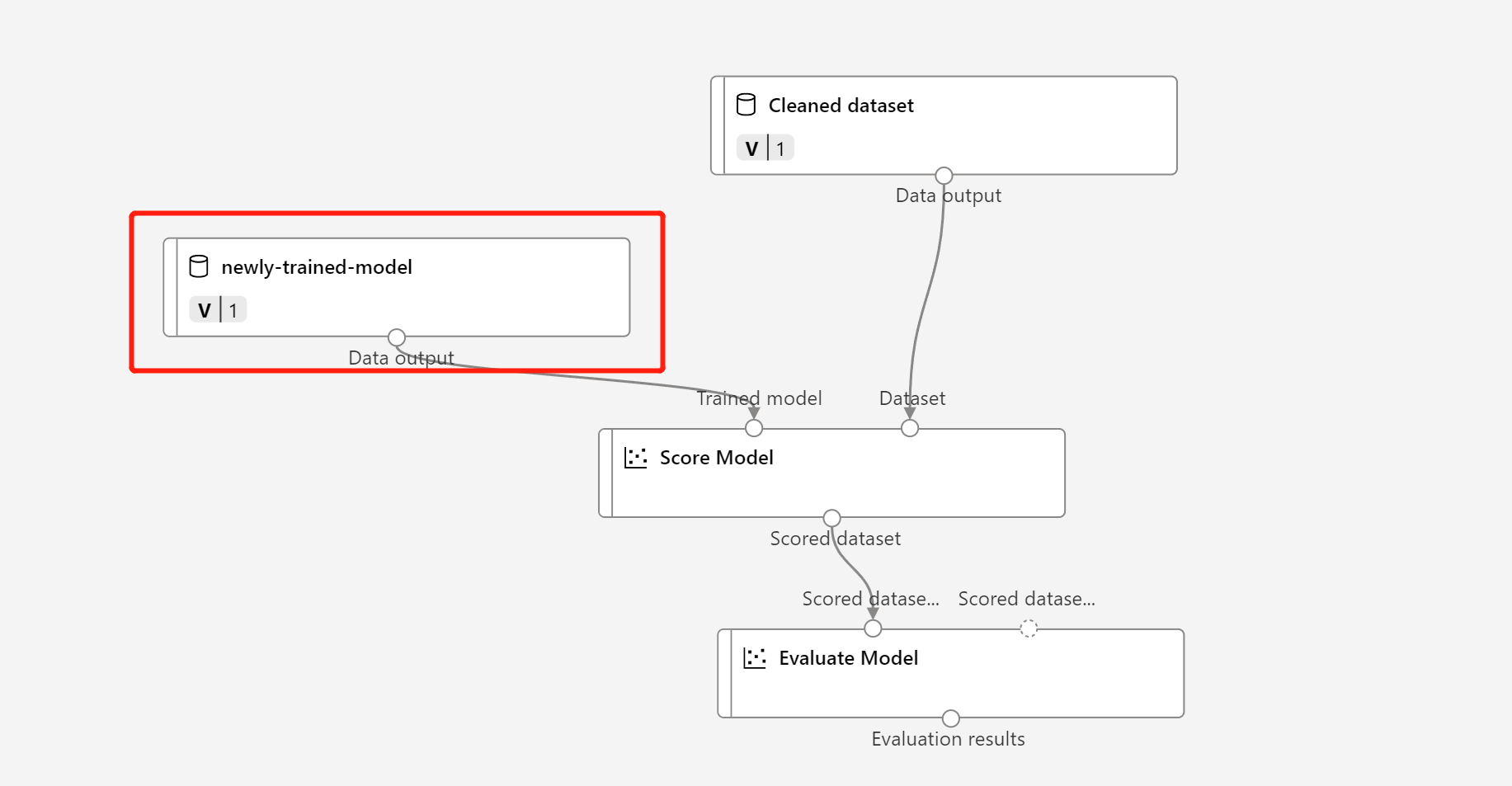
L'aggiornamento del nodo di trasformazione dati TD- corrisponde al modello sottoposto a training.
È quindi possibile inviare la pipeline di inferenza con il modello e la trasformazione aggiornati e pubblicare nuovamente.


Passaggi successivi
- Seguire l'esercitazione relativa alla finestra di progettazione per eseguire il training e la distribuzione di un modello di regressione.
- Per informazioni su come pubblicare ed eseguire una pipeline pubblicata usando l'SDK v1, vedere l'articolo Come distribuire pipeline.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per