Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questo articolo fornisce informazioni sull'uso di Azure Machine Learning SDK v1. L'SDK v1 è deprecato a partire dal 31 marzo 2025 e il supporto per questo terminerà il 30 giugno 2026. È possibile installare e usare l'SDK v1 fino a tale data.
È consigliabile passare all'SDK v2 prima del 30 giugno 2026. Per altre informazioni sull'SDK v2, vedere Informazioni su Azure Machine Learning Python SDK v2 e informazioni di riferimento sull'SDK v2.
Questo articolo illustra come usare la finestra di progettazione di Azure Machine Learning per eseguire il training di un modello di regressione lineare che stima i prezzi delle automobili. Questa esercitazione è la prima di una serie in due parti.
Per altre informazioni sulla finestra di progettazione, vedere Che cos'è la finestra di progettazione di Azure Machine Learning?
Nota
Designer supporta due tipi di componenti: componenti classici predefiniti (v1) e componenti personalizzati (v2). Questi due tipi di componenti NON sono compatibili.
I componenti predefiniti classici sono destinati principalmente all'elaborazione dei dati e alle attività tradizionali di Machine Learning, come la regressione e la classificazione. Questo tipo di componente continua a essere supportato, ma non avrà nuove aggiunte future.
I componenti personalizzati consentono di eseguire il wrapping del codice personalizzato come componente. Questa opzione supporta la condivisione di componenti tra aree di lavoro e la creazione senza interruzioni nelle interfacce di Studio, CLI v2 e SDK v2.
Per i nuovi progetti, è consigliabile usare componenti personalizzati compatibili con Azure Machine Learning V2 e continuare a ricevere nuovi aggiornamenti.
Questo articolo si applica ai componenti predefiniti classici e non è compatibile con CLI v2 e SDK v2.
In questa esercitazione si apprenderà come:
- Crea una nuova pipeline.
- Importa dati.
- Preparare i dati.
- Eseguire il training di un modello di Machine Learning.
- Valutare un modello di Machine Learning.
Nella seconda parte dell'esercitazione si distribuisce il modello come endpoint di inferenza in tempo reale per stimare il prezzo di qualsiasi automobile in base alle specifiche tecniche inviate.
Nota
Per visualizzare una versione completa di questa esercitazione come pipeline di esempio, vedere Usare la regressione per stimare i prezzi delle automobili con la finestra di progettazione di Azure Machine Learning.
Importante
Se gli elementi grafici citati in questo documento (ad esempio i pulsanti di Studio o della finestra di progettazione) non vengono visualizzati, è possibile che non si disponga del livello di autorizzazioni appropriato per l'area di lavoro. Contattare l'amministratore della sottoscrizione di Azure per verificare che sia stato concesso il livello di accesso corretto. Per altre informazioni, vedere Gestire utenti e ruoli.
Crea una nuova pipeline
Le pipeline di Azure Machine Learning organizzano più passaggi di Machine Learning ed elaborazione dati in un'unica risorsa. Le pipeline consentono di organizzare, gestire e riutilizzare flussi di lavoro di Machine Learning complessi in più progetti e utenti.
Per creare una pipeline di Azure Machine Learning, è necessaria un'area di lavoro di Azure Machine Learning. In questa sezione viene descritto come creare entrambe queste risorse.
Creazione di una nuova area di lavoro
Per usare la finestra di progettazione, è necessaria un'area di lavoro di Azure Machine Learning. L'area di lavoro è la risorsa di primo livello per Azure Machine Learning. Offre una posizione centralizzata per lavorare con tutti gli artefatti creati in Azure Machine Learning. Per informazioni su come creare un'area di lavoro, vedere Creare risorse dell'area di lavoro.
Nota
Se l'area di lavoro usa una rete virtuale, sono necessari passaggi di configurazione aggiuntivi per usare la finestra di progettazione. Per altre informazioni, vedere Usare studio di Azure Machine Learning in una rete virtuale di Azure.
Creare la pipeline
Accedere ad Azure Machine Learning Studio e selezionare l'area di lavoro da usare.
Selezionare Progettazione dal menu della barra laterale. In Predefinito classico scegliere Crea una nuova pipeline usando i componenti predefiniti classici.
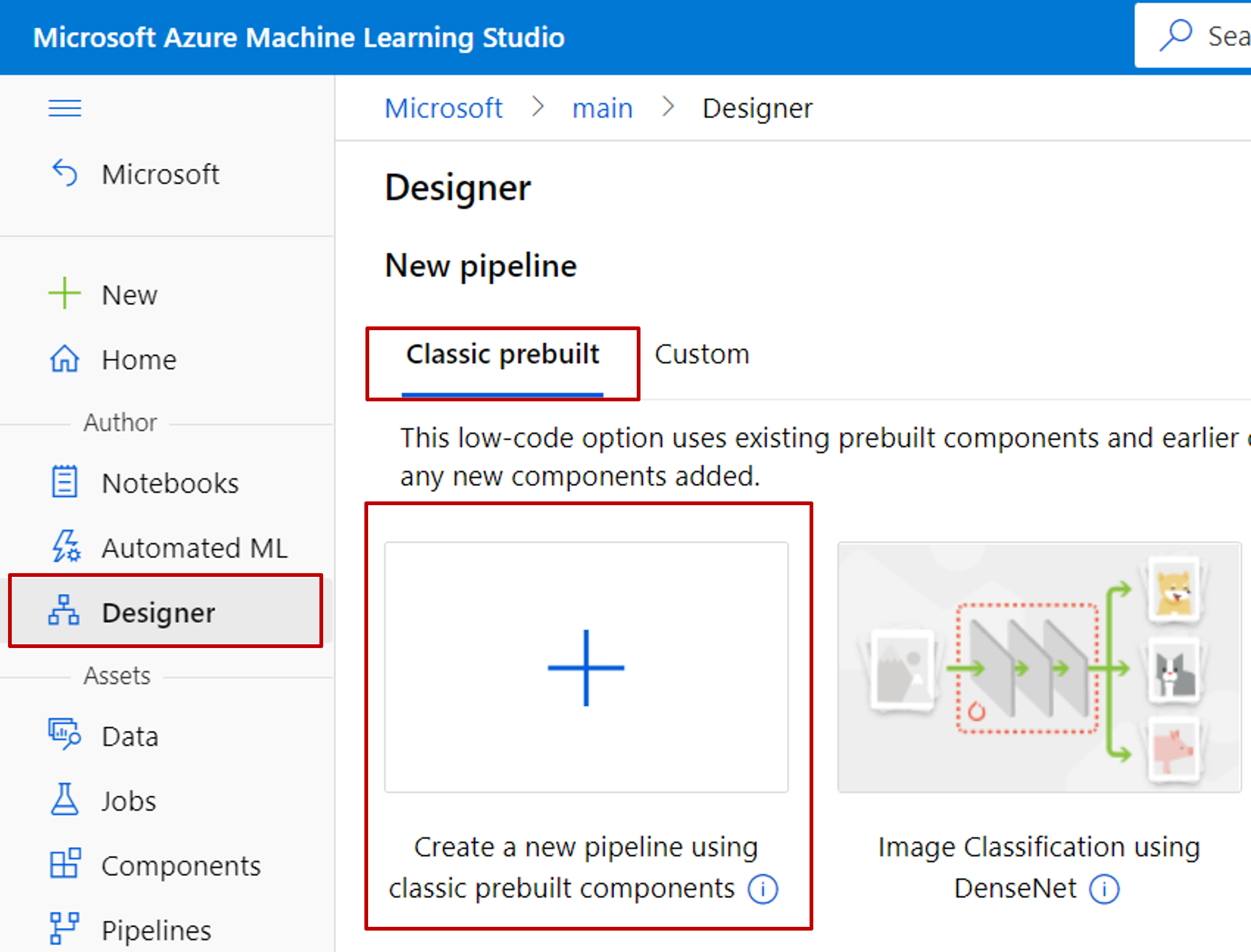
Seleziona l'icona a forma di matita accanto al nome della linea di processo generata automaticamente e rinominala in Automobile price prediction. Il nome non deve essere univoco.

Importare i dati
Nella finestra di progettazione sono disponibili diversi set di dati di esempio con cui sperimentare. Per questa esercitazione, usare Automobile price data (Raw).
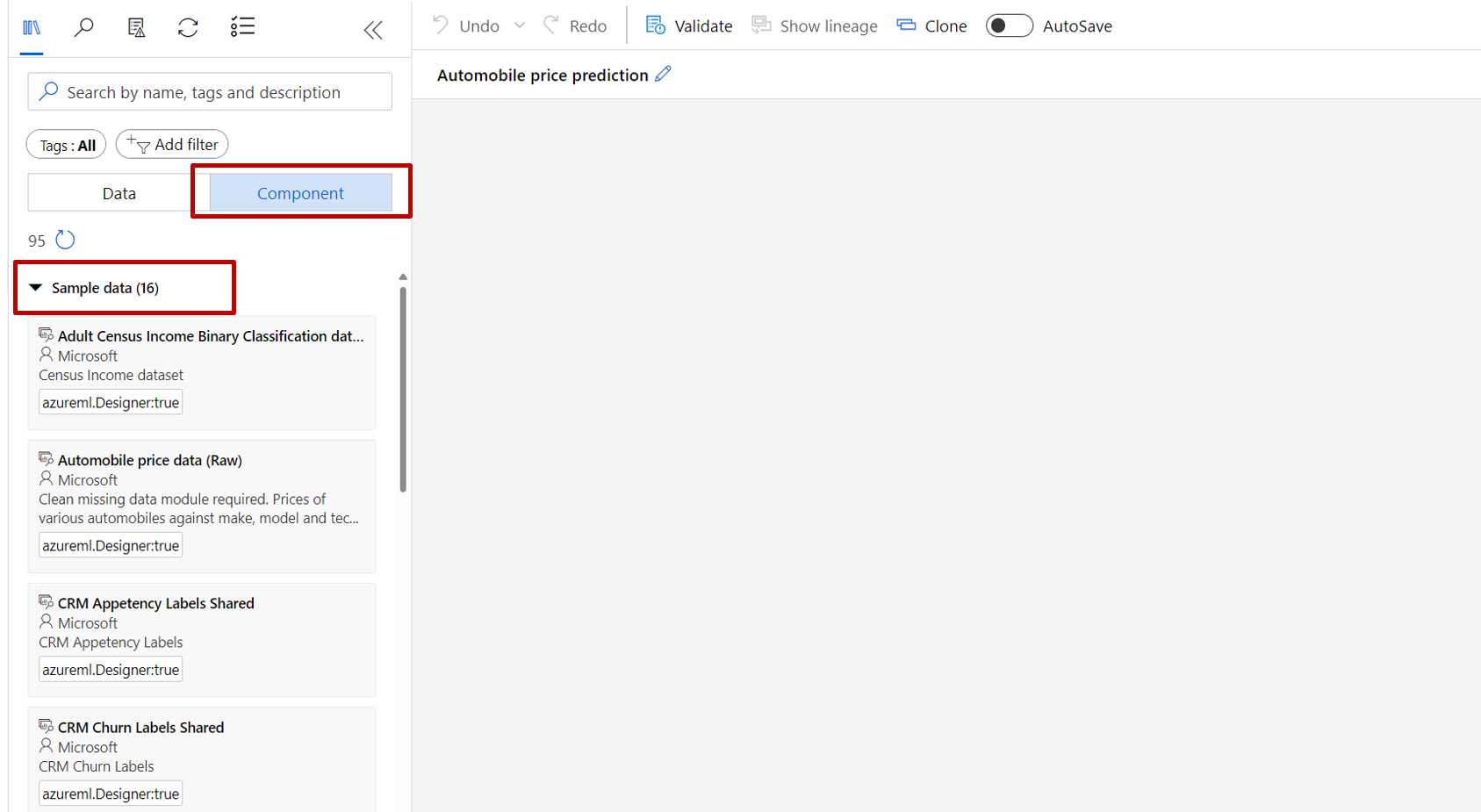
A sinistra del canvas della pipeline è presente un riquadro di set di dati e componenti. Selezionare Componente>Dati di esempio.
Selezionare il set di dati Automobile price data (Raw) e trascinarlo nel canvas.

Visualizzare i dati
È possibile visualizzare i dati per comprendere il set di dati che verrà usato.
Fare clic con il pulsante destro del mouse su Dati prezzi automobili (Raw) e selezionare Visualizza in anteprima i dati.
Selezionare le diverse colonne nella finestra dei dati per visualizzare le informazioni relative a ciascuna.
Ogni riga rappresenta un'automobile e le variabili associate a ogni automobile sono rappresentate da colonne. In questo set di dati sono presenti 205 righe e 26 colonne.
Preparazione dei dati
I set di dati in genere richiedono una pre-elaborazione prima dell'analisi. Durante l'ispezione del set di dati si potrebbe aver notato che mancano alcuni valori. Per consentire al modello di analizzare correttamente i dati, è necessario eseguire la pulizia di questi valori mancanti.
Rimuovere una colonna
Quando si esegue il training di un modello, è necessario eseguire operazioni sui dati mancanti. In questo set di dati la colonna normalized-losses manca molti valori, quindi si esclude completamente tale colonna dal modello.
Nel riquadro dei set di dati e dei componenti a sinistra dell'area di disegno selezionare Componente e cercare il componente Seleziona colonne nel set di dati .
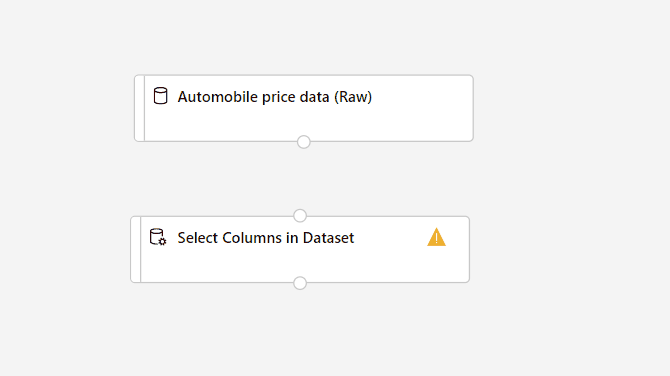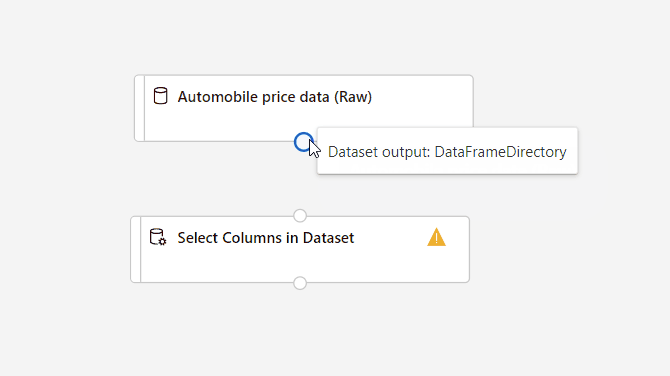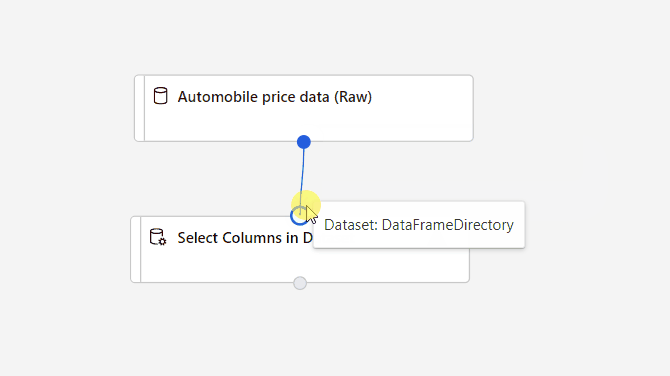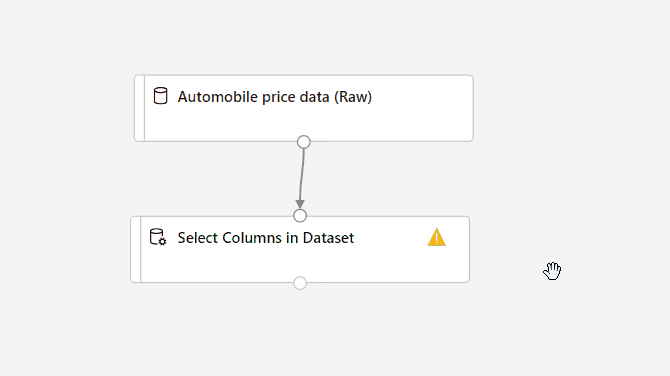
Trascinare il componente Seleziona colonne nel set di dati nel canvas. Eliminare il componente sotto il componente del set di dati.
Connettere il set di dati Dati prezzi automobili (Raw) al componente Seleziona colonne nel set di dati. Trascinare dalla porta di output del set di dati, ovvero il piccolo cerchio nella parte inferiore del set di dati nel canvas, alla porta di input di Seleziona colonne nel set di dati, ovvero il piccolo cerchio nella parte superiore del componente.
Suggerimento
Viene creato un flusso di dati attraverso la pipeline quando si connette la porta di output di un componente a una porta di input di un'altra.
Selezionare il componente Seleziona colonne nel set di dati.
Selezionare l'icona a forma di freccia in Interfaccia pipeline a destra dell'area di disegno per aprire il riquadro dei dettagli del componente. In alternativa, è possibile fare doppio clic sul componente Seleziona colonne nel set di dati per aprire il riquadro dei dettagli.
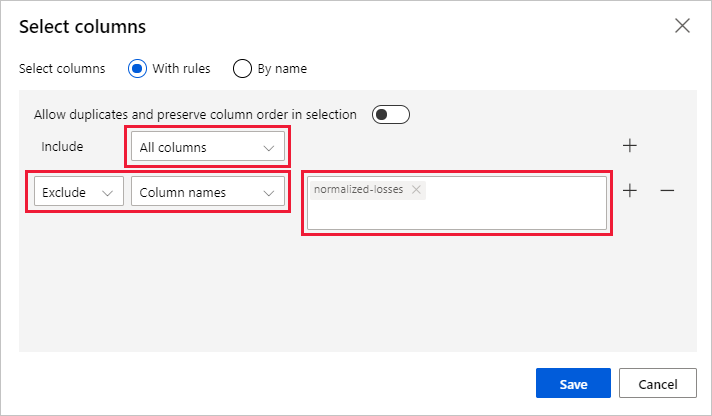
Selezionare Modifica colonna a destra del riquadro.
Espandere l'elenco a discesa Nomi colonne accanto a Includi e selezionare Tutte le colonne.
Selezionare il segno + per aggiungere una nuova regola.
Nel menu a discesa selezionare Escludi e Nomi colonne.
Immettere normalized-losses nella casella di testo.
Nell'angolo in basso a destra selezionare Save (Salva) per chiudere il selettore di colonne.
Nel riquadro dei dettagli del componente Seleziona colonne nel set di dati, espandere informazioni sul nodo.
Selezionare la casella di testo Commento e immettere Escludi perdite normalizzate.
I commenti vengono visualizzati nel grafico per aiutarvi a organizzare la pipeline.
Pulire i dati mancanti
Dopo la rimozione della colonna normalized-losses, il set di dati contiene ancora colonne con valori mancanti. È possibile rimuovere i dati mancanti rimanenti usando il componente Pulisci dati mancanti.
Suggerimento
La pulizia dei valori mancanti dai dati di input è un prerequisito per l'uso della maggior parte dei componenti nella finestra di progettazione.
Nei set di dati e nella tavolozza dei componenti a sinistra dell'area di disegno selezionare Componente e cercare il componente Pulisci dati mancanti .
Trascinare il componente Pulisci dati mancanti nel canvas della pipeline. Connetterlo al componente Seleziona colonne nel set di dati.
Selezionare il componente Pulisci dati mancanti.
Selezionare l'icona a forma di freccia in Interfaccia pipeline a destra dell'area di disegno per aprire il riquadro dei dettagli del componente. In alternativa, è possibile fare doppio clic sul componente Pulisci dati mancanti per aprire il riquadro dei dettagli.
Selezionare Modifica colonna a destra del riquadro.
Nella finestra Columns to be cleaned (Colonne da pulire) visualizzata espandere il menu a discesa accanto a Include (Includi). Selezionare Tutte le colonne.
Seleziona Salva.
Nel riquadro dei dettagli del componente Pulisci dati mancanti in Modalità pulizia, selezionare Rimuovi riga intera.
Nel riquadro dei dettagli del componente Pulisci dati mancanti, espandi Informazioni sul nodo.
Selezionare la casella di testo Commento e immettere Rimuovi righe di valori mancanti.
La pipeline avrà ora un aspetto analogo al seguente:
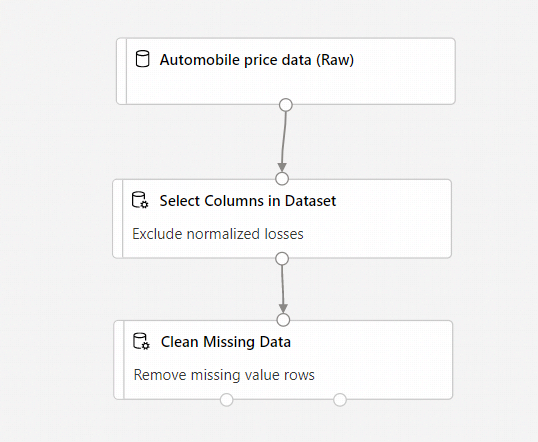
Eseguire il training di un modello di Machine Learning
Dopo aver creato i componenti per elaborare i dati, è possibile configurare i componenti di training.
Poiché si vuole stimare il prezzo, ovvero un numero, è possibile usare un algoritmo di regressione. Per questo esempio si userà un modello di regressione lineare.
Suddividere i dati
La divisione dei dati è un'attività comune in Machine Learning. I dati dovranno essere divisi in due set di dati separati. Un set di dati esegue il training del modello e l'altro verifica il livello di esecuzione del modello.
Nei set di dati e nella tavolozza dei componenti a sinistra dell'area di disegno selezionare Componente e cercare il componente Divisione dati .
Trascinare il componente Dividi dati nel canvas della pipeline.
Connettere la porta sinistra del componente Pulisci dati mancanti al componente Dividi dati.
Importante
Assicurarsi che la porta di output sinistra di Pulisci dati mancanti si connetta a Dividi dati. La porta sinistra contiene i dati puliti. La porta destra contiene i dati rimossi.
Selezionare il componente Dividi dati.
Selezionare l'icona a forma di freccia in Interfaccia pipeline a destra dell'area di disegno per aprire il riquadro dei dettagli del componente. In alternativa, è possibile fare doppio clic sul componente Dividi dati per aprire il riquadro dei dettagli.
Nel riquadro Dettagli divisione dati impostare Frazione di righe nel primo set di dati di output su 0,7.
Con questa opzione, per il training del modello verrà usato il 70% dei dati, mentre il restante 30% verrà usato per i test. Il set di dati del 70% è disponibile tramite la porta di uscita sinistra. I dati rimanenti saranno disponibili tramite la porta di output destra.
Nel riquadro Dettagli divisione dati, espandi le Informazioni sul nodo.
Selezionare la casella di testo Commento e immettere Dividi il set di dati in set di training (0,7) e set di test (0,3).
Eseguire il training del modello
Eseguire il training del modello assegnando un set di dati che include il prezzo. L'algoritmo crea un modello che spiega la relazione tra le caratteristiche e il prezzo come presentato dai dati di training.
Nei set di dati e nella tavolozza dei componenti a sinistra dell'area di disegno selezionare Componente e cercare il componente Regressione lineare .
Trascinare il componente Regressione lineare nel canvas della pipeline.
Nei dataset e nella tavolozza dei componenti a sinistra dell'area di disegno, selezionare Componente e cercare il componente Train Model (Esegui training modello).
Trascinare il componente Esegui il training del modello nel canvas della pipeline.
Connettere l'output del componente Regressione lineare all'input sinistro del componente Esegui il training del modello.
Connettere l'output dei dati di training (porta sinistra) del componente Dividi dati all'input destro del componente Esegui il training del modello.
Importante
Assicurarsi che la porta di output sinistra di Dividi dati si connetta a Esegui il training del modello. La porta sinistra contiene il set di training. La porta destra contiene il set di test.
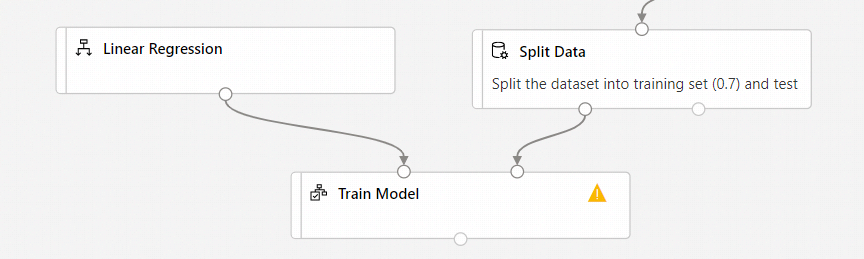
Selezionare il componente Esegui il training del modello.
Selezionare l'icona a forma di freccia in Impostazioni pipeline a destra dell'area di disegno per aprire il riquadro dei dettagli del componente. In alternativa, è possibile fare doppio clic sul componente Esegui il training del modello per aprire il riquadro dei dettagli.
Selezionare Modifica colonna a destra del riquadro.
Nella finestra Etichetta colonna visualizzata, espandere il menu a discesa e selezionare Nomi di colonna.
Nella casella di testo immettere price per specificare il valore che verrà previsto dal modello.
Importante
Assicurarsi di immettere esattamente il nome della colonna. Non capitalizzare il prezzo.
La pipeline dovrebbe avere un aspetto simile al seguente:
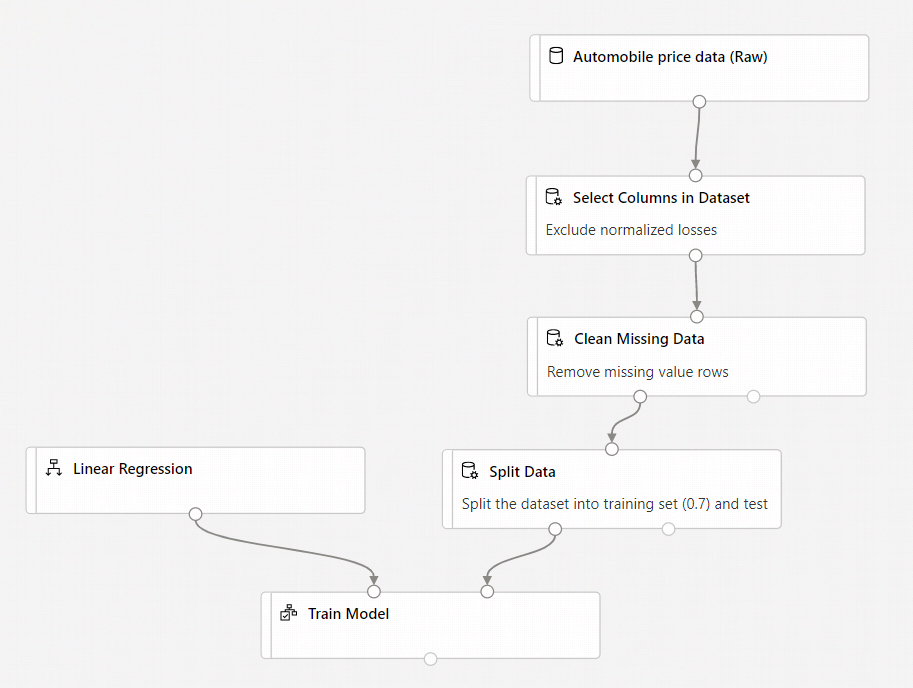

Aggiungere il componente Assegna un punteggio al modello
Dopo aver eseguito il training del modello usando il 70% dei dati, è possibile usarlo per assegnare punteggi al restante 30% e verificarne il funzionamento.
Nei set di dati e nella tavolozza dei componenti, a sinistra dell'area di disegno, selezionare Componente e cercare il componente Score Model (Punteggio modello).
Trascinare il componente Assegna un punteggio al modello nel canvas della pipeline.
Connettere l'output del componente Esegui il training del modello alla porta di input sinistra di Assegna un punteggio al modello. Connetti l'output dei dati di test (porta destra) del componente Dividi dati alla porta di input destra di Assegna un punteggio al modello.
Aggiungere il componente Valuta modello
Usare il componente Valuta modello per valutare il punteggio del modello con il set di dati di test.
Nei set di dati e nella tavolozza dei componenti a sinistra dell'area di disegno selezionare Componente e cercare il componente Evaluate Model (Valuta modello ).
Trascinare il componente Valuta modello nel canvas della pipeline.
Connettere l'output del componente Assegna un punteggio al modello all'input sinistro di Valuta modello.
La pipeline finale avrà un aspetto analogo al seguente:
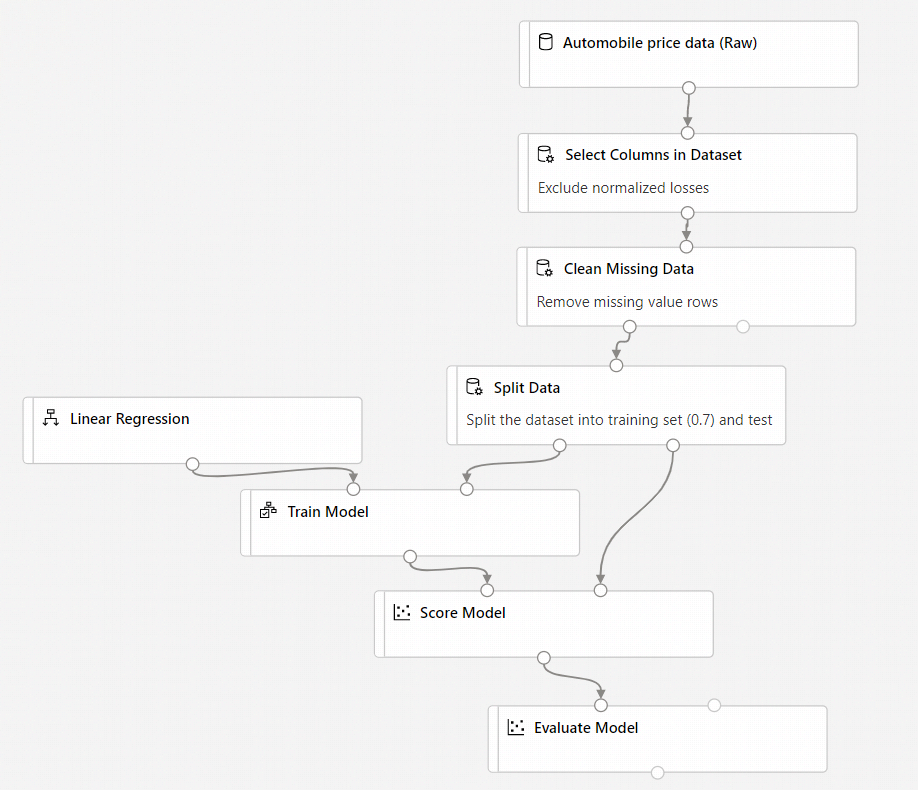

Inviare la pipeline
Selezionare Configura e invia nell'angolo superiore per inviare la pipeline.
Dopo aver visualizzato la procedura guidata dettagliata, seguire la procedura guidata per inviare il processo della pipeline.
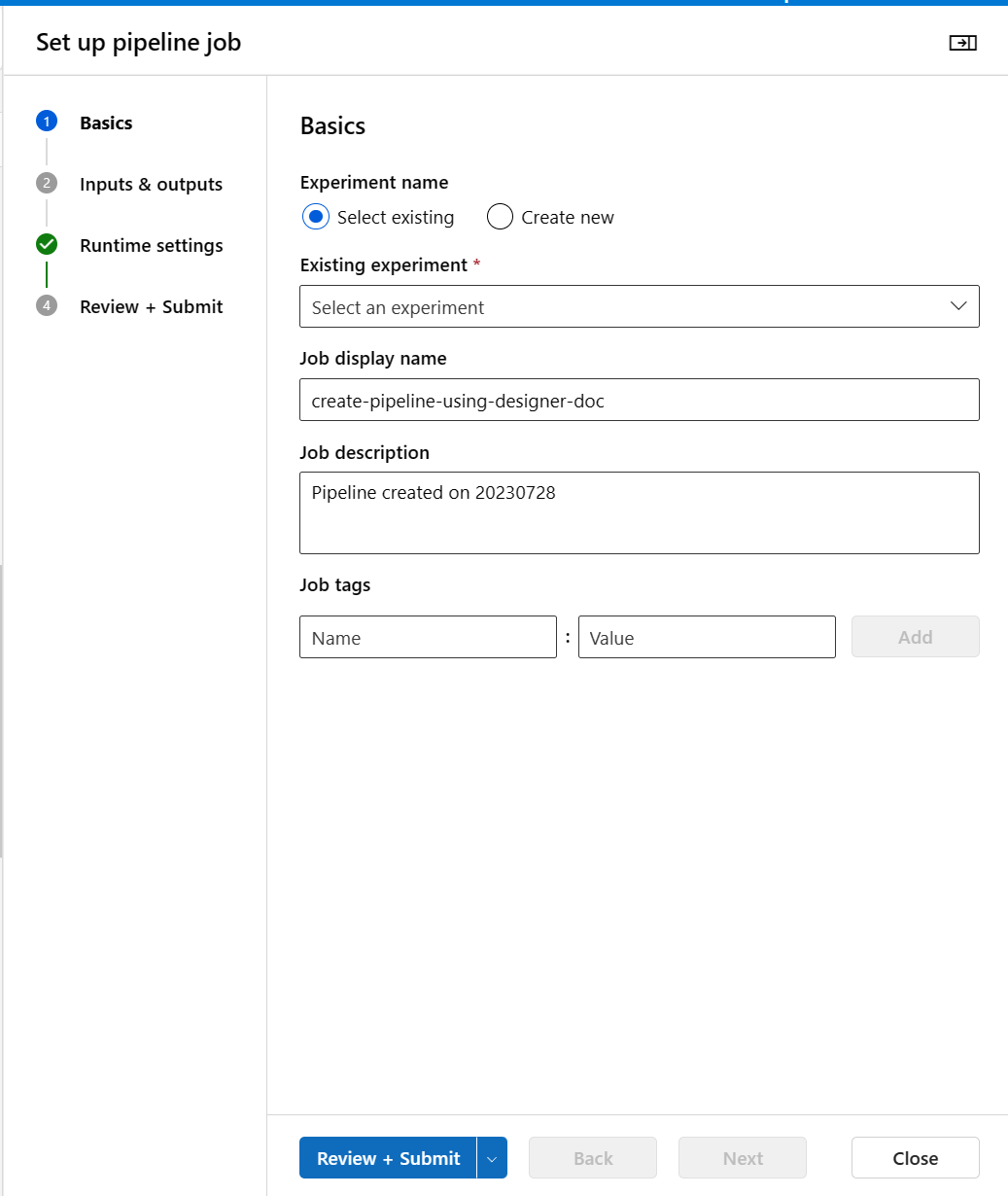
In Informazioni di base è possibile configurare l'esperimento, il nome visualizzato del processo, la descrizione del processo e così via.
In Input e output è possibile assegnare valore agli input e agli output promossi al livello della pipeline. In questo esempio è vuoto perché non è stato promosso alcun input o output a livello di pipeline.
In Impostazioni di runtimeè possibile configurare l'archivio dati predefinito e l'ambiente di calcolo predefinito della pipeline. Si tratta dell'archivio dati predefinito e del calcolo per tutti i componenti della pipeline. Tuttavia, se si imposta un archivio dati o di calcolo diverso per un componente in modo esplicito, il sistema rispetta l'impostazione a livello di componente. In caso contrario, usa l'impostazione predefinita.
Il passaggio Rivedi e invia è l'ultimo passaggio per esaminare tutte le configurazioni prima dell'invio. Se mai invii la pipeline, la procedura guidata memorizza la tua ultima configurazione.

Dopo l'invio del processo della pipeline, viene visualizzato un messaggio nella parte superiore con un collegamento al dettaglio del processo. È possibile selezionare questo collegamento per esaminare i dettagli del processo.

Visualizzare le etichette dei punteggi
Nella pagina dei dettagli del processo è possibile controllare lo stato, i risultati e i log del processo della pipeline.
Al termine del processo, è possibile visualizzare i risultati del processo della pipeline. Prima di tutto, esaminare le previsioni generate dal modello di regressione.
Fare clic con il pulsante destro del mouse sul componente Assegna un punteggio al modello e selezionare Visualizza in anteprima i dati>Set di dati con punteggio assegnato per visualizzarne l'output.
Qui è possibile visualizzare i prezzi stimati e i prezzi effettivi dai dati di test.
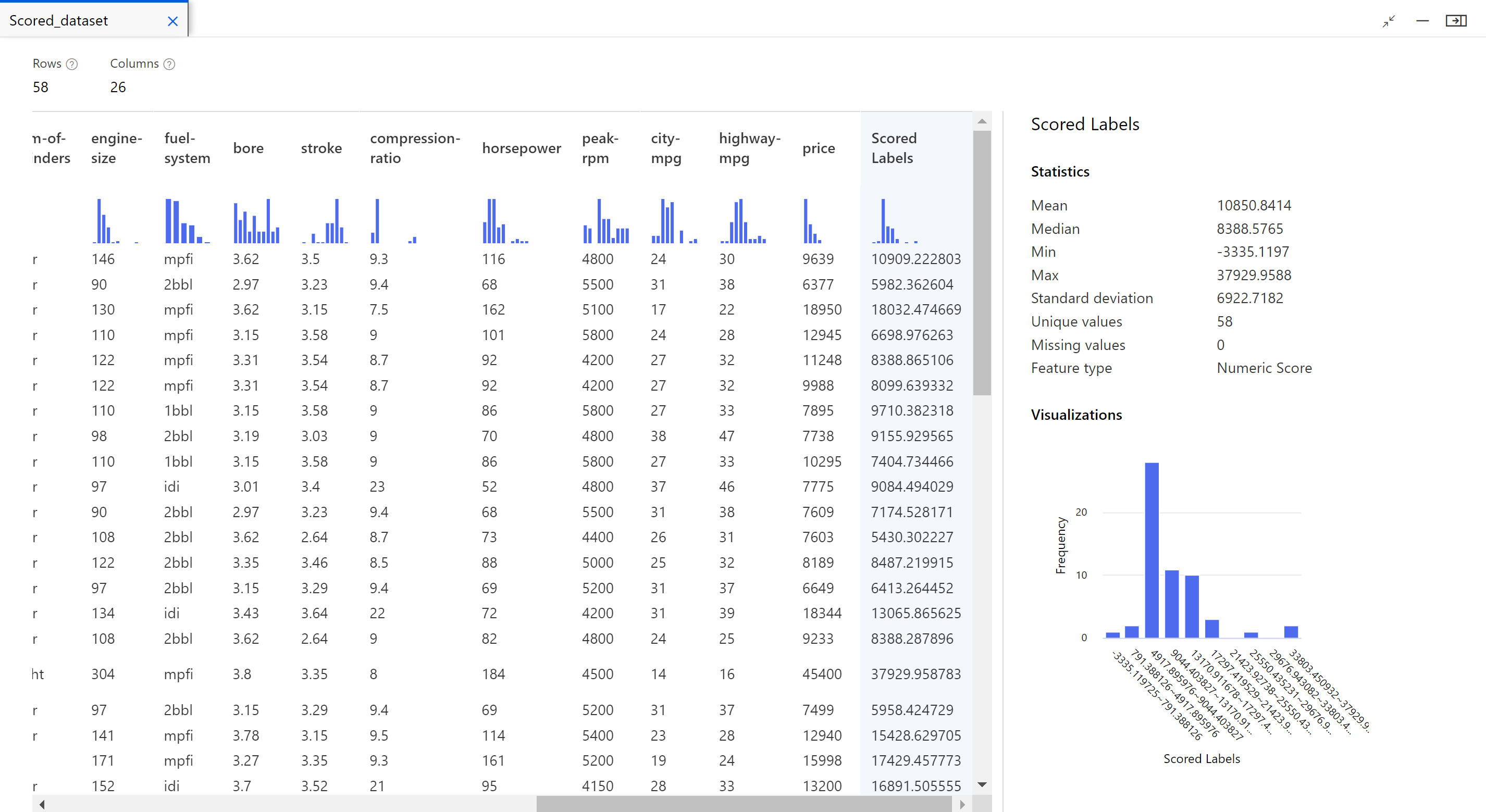

Valutare i modelli
Usare Evaluate Model (Valutazione modello) per verificare le prestazioni del modello sottoposto a training nel set di dati di test.
- Fare clic con il pulsante destro del mouse sul componente Valuta modello e selezionare Visualizza in anteprima i dati>Risultati della valutazione per visualizzarne l'output.
Per il modello vengono visualizzate le seguenti statistiche:
- Errore assoluto medio (MAE): media degli errori assoluti. Un errore è la differenza tra il valore stimato e il valore effettivo .
- Root Mean Squared Error (RMSE, radice errore quadratico medio): radice quadrata della media degli errori quadratici delle stime effettuate sul set di dati di test.
- Relative Absolute Error(errore assoluto relativo): media degli errori assoluti relativamente alla differenza assoluta tra i valori effettivi e la media di tutti i valori effettivi.
- Relative Squared Error(errore quadratico relativo): media degli errori quadratici relativamente alla differenza quadratica tra i valori effettivi e la media di tutti i valori effettivi.
- Coefficiente di determinazione: noto anche come valore R quadro, questa metrica statistica indica il grado di adattamento dei dati a un modello.
Per ogni statistica di errore, sono preferibili i valori più piccoli. Un valore più piccolo indica che le stime sono più vicine ai valori effettivi. Per il coefficiente di determinazione, più il valore si avvicina a uno (1,0) più le stime sono precise.
Pulire le risorse
Saltare questa sezione se si vuole continuare con la parte 2 dell'esercitazione relativa alla distribuzione di modelli.
Importante
È possibile usare le risorse create come prerequisiti per altre esercitazioni e procedure dettagliate relative ad Azure Machine Learning.
Eliminare tutto
Se non si prevede di usare le risorse create, eliminare l'intero gruppo di risorse per evitare addebiti.
Nel portale di Azure, selezionare Gruppi di risorse nella parte sinistra della finestra.
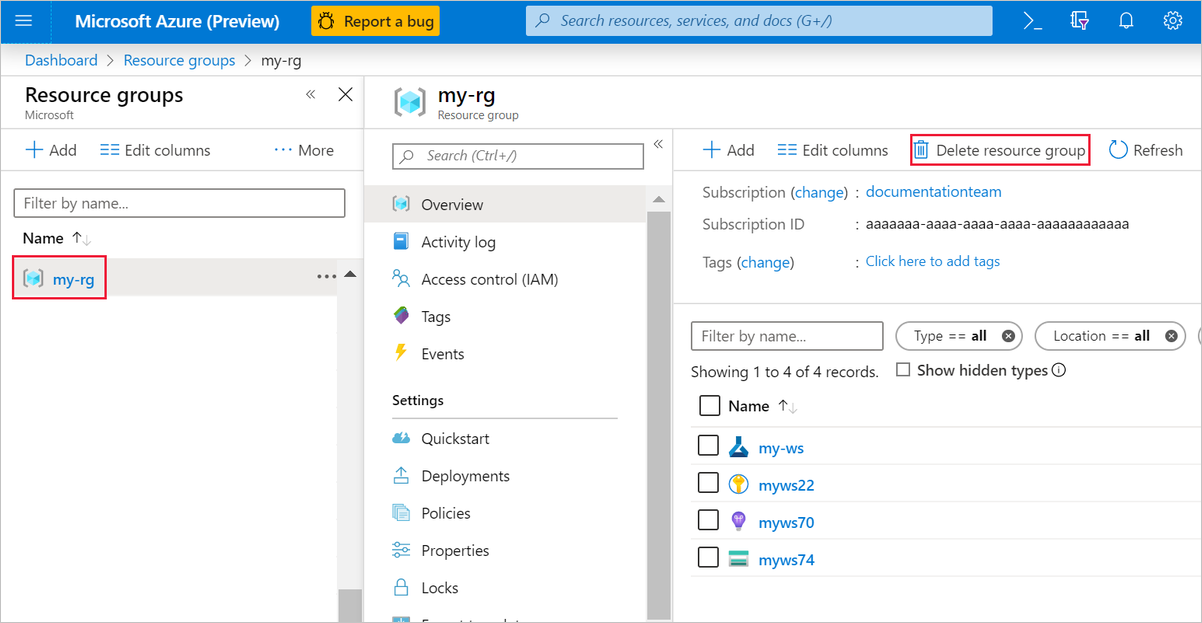
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
Se si elimina il gruppo di risorse, vengono eliminate anche tutte le risorse create nella finestra di progettazione.
Eliminare singole risorse
Nella finestra di progettazione in cui è stato creato l'esperimento eliminare le singole risorse selezionandole e quindi selezionando il pulsante Elimina.
La destinazione di calcolo creata qui viene ridimensionata automaticamente a zero nodi quando non viene usata, Questa azione viene intrapresa per ridurre al minimo gli addebiti. Se si vuole eliminare la destinazione di calcolo, eseguire le operazioni seguenti:
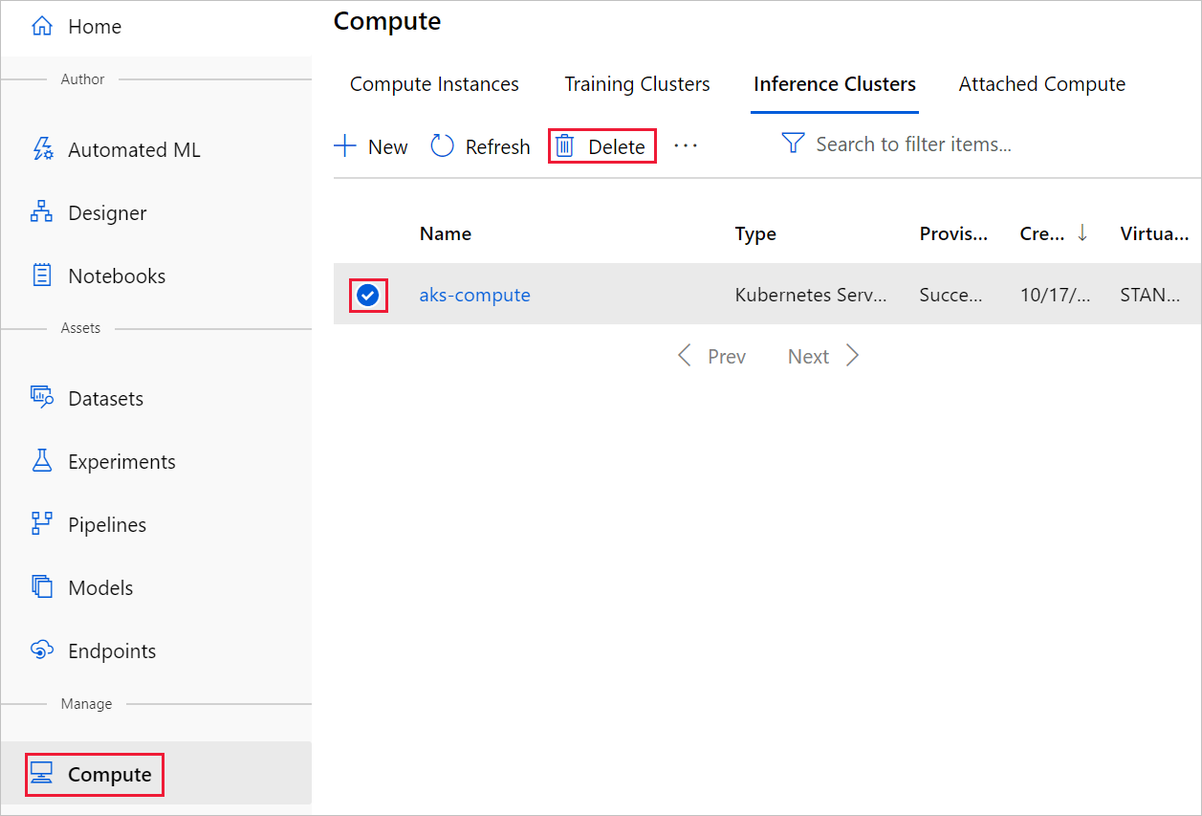
La registrazione dei set di dati nell'area di lavoro può essere annullata selezionando ogni set di dati e quindi Annulla registrazione.
Per eliminare un set di dati, passare all'account di archiviazione tramite il portale di Azure o Azure Storage Explorer ed eliminare manualmente tali asset.
Passo successivo
Nella seconda parte si apprenderà come distribuire il modello come endpoint in tempo reale.