Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)SDK Python azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)SDK Python azure-ai-ml v2 (corrente)
In questo articolo viene illustrato come distribuire una nuova versione di un modello di Machine Learning nell'ambiente di produzione senza causare interruzioni. Si usa una strategia di distribuzione blu-verde, nota anche come strategia di implementazione sicura, per introdurre una nuova versione di un servizio Web nell'ambiente di produzione. Quando si usa questa strategia, è possibile implementare la nuova versione del servizio Web in un piccolo subset di utenti o richieste prima di implementarla completamente.
In questo articolo si presuppone che vengano usati endpoint online o endpoint usati per l'inferenza online (in tempo reale). Esistono due tipi di endpoint online: endpoint online gestiti ed endpoint online Kubernetes. Per altre informazioni sugli endpoint e sulle differenze tra i tipi di endpoint, vedere Endpoint online gestiti e endpoint online Kubernetes.
Questo articolo usa endpoint online gestiti per la distribuzione. Ma include anche note che spiegano come usare gli endpoint Kubernetes anziché gli endpoint online gestiti.
In questo articolo viene illustrato come:
- Definire un endpoint online con una distribuzione denominata
blueper gestire la prima versione di un modello. - Ridimensionare la
bluedistribuzione in modo che possa gestire più richieste. - Distribuire la seconda versione del modello, denominata distribuzione
green, nell'endpoint, ma non inviare alcun traffico attivo alla distribuzione. - Testare la distribuzione
greenin isolamento. - Eseguire il mirroring di una percentuale di traffico attivo verso la distribuzione
greenper convalidarla. - Inviare una piccola percentuale di traffico attivo alla distribuzione
green. - Inviare tutto il traffico in diretta alla distribuzione
green. - Eliminare la distribuzione inutilizzata
blue.
Prerequisiti
L'interfaccia della riga di comando di Azure e l'estensione
mlper l'interfaccia della riga di comando di Azure, installate e configurate. Per altre informazioni, vedere Installare e configurare l'interfaccia della riga di comando (v2).Una shell Bash o una shell compatibile, ad esempio una shell in un sistema Linux o un sottosistema Windows per Linux. Gli esempi dell'interfaccia della riga di comando di Azure in questo articolo presuppongono l'uso di questo tipo di shell.
Un'area di lavoro di Azure Machine Learning. Per istruzioni su come creare un'area di lavoro, vedere Configurare.
Un account utente che possiede almeno uno dei ruoli di controllo degli accessi in base al ruolo di Azure (Azure RBAC) seguenti:
- Ruolo proprietario per l'area di lavoro di Azure Machine Learning
- Ruolo Collaboratore per l'area di lavoro di Azure Machine Learning
- Ruolo personalizzato con
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*autorizzazioni
Per altre informazioni, vedere Gestire l'accesso alle aree di lavoro di Azure Machine Learning.
Facoltativamente, motore Docker, installato ed in esecuzione in locale. Questo prerequisito è altamente consigliato. È necessario per distribuire un modello in locale ed è utile per il debug.
Preparare il sistema
Impostare le variabili di ambiente
È possibile configurare i valori predefiniti da usare con l'interfaccia della riga di comando di Azure. Per evitare di passare più volte valori per la sottoscrizione, l'area di lavoro e il gruppo di risorse, eseguire il codice seguente:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<Azure-Machine-Learning-workspace-name> group=<resource-group-name>
Clonare il repository di esempi
Per seguire questo articolo, clonare prima di tutto il repository degli esempi (azureml-examples). Passare quindi alla directory cli/ del repository:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Suggerimento
Usare --depth 1 per clonare solo il commit più recente nel repository, riducendo il tempo necessario per completare l'operazione.
I comandi di questa esercitazione si trovano nel file deploy-safe-rollout-online-endpoints.sh nella directory cli, e i file di configurazione YAML si trovano nella sottodirectory endpoints/online/managed/sample/.
Note
I file di configurazione YAML per gli endpoint online Kubernetes si trovano nella sottodirectory endpoints/online/kubernetes/.
Definire l'endpoint e la distribuzione
Gli endpoint online sono usati per l'inferenza online (in tempo reale). Gli endpoint online contengono distribuzioni pronte a ricevere dati dai client e in grado di inviare risposte in tempo reale.
Definire un endpoint
Nella tabella seguente sono elencati gli attributi chiave da specificare quando si definisce un endpoint.
| Attributo | Obbligatorio o facoltativo | Descrizione |
|---|---|---|
| Nome | Obbligatorio | Nome dell'endpoint. Deve essere univoco nella propria area di Azure. Per altre informazioni sulle regole di denominazione, vedere Endpoint online e endpoint batch di Azure Machine Learning. |
| Modalità di autenticazione | Opzionale | Metodo di autenticazione per l'endpoint. È possibile scegliere tra l'autenticazione basata su chiave, keye l'autenticazione basata su token di Azure Machine Learning, aml_token. Una chiave non scade, a differenza di un token. Per altre informazioni sull'autenticazione, vedere Autenticare i client per gli endpoint online. |
| Descrizione | Opzionale | La descrizione dell'endpoint. |
| Tag | Opzionale | Dizionario di tag per l'endpoint. |
| Traffico | Opzionale | Regole su come instradare il traffico tra le distribuzioni. Il traffico viene rappresentato come dizionario di coppie chiave-valore, in cui la chiave rappresenta il nome della distribuzione e il valore rappresenta la percentuale di traffico verso tale distribuzione. È possibile impostare il traffico solo dopo la creazione delle distribuzioni in un endpoint. È anche possibile aggiornare il traffico per un endpoint online dopo la creazione delle distribuzioni. Per ulteriori informazioni su come utilizzare il traffico duplicato, consultare Allocare una piccola percentuale di traffico attivo alla nuova distribuzione. |
| Mirroring del traffico | Opzionale | La percentuale di traffico live di cui eseguire il mirroring in una distribuzione. Per ulteriori informazioni su come utilizzare il traffico replicato, consulta Testare la distribuzione con il traffico replicato. |
Per visualizzare un elenco completo degli attributi che è possibile specificare quando si crea un endpoint, vedere Schema YAML dell'endpoint online dell'interfaccia della riga di comando (v2). Per la versione 2 di Azure Machine Learning SDK per Python, vedere Classe ManagedOnlineEndpoint.
Definire una distribuzione
Un'implementazione è un insieme di risorse necessarie per ospitare il modello che esegue la deduzione effettiva. Nella tabella seguente vengono descritti gli attributi chiave da specificare quando si definisce una distribuzione.
| Attributo | Obbligatorio o facoltativo | Descrizione |
|---|---|---|
| Nome | Obbligatorio | Nome della distribuzione. |
| Nome dell'endpoint | Obbligatorio | Nome dell'endpoint in cui creare la distribuzione. |
| Modello | Opzionale | Modello da usare per la distribuzione. Questo valore può essere un riferimento a un modello con controllo delle versioni esistente nell'area di lavoro o a una specifica del modello inline. Negli esempi di questo articolo, un modello scikit-learn esegue la regressione. |
| Percorso del codice | Opzionale | Percorso della cartella nell'ambiente di sviluppo locale che contiene tutto il codice sorgente Python per l'assegnazione del punteggio al modello. È possibile usare directory e pacchetti annidati. |
| Scoring script (Script di assegnazione punteggi) | Opzionale | Codice Python che esegue il modello in una determinata richiesta di input. Questo valore può essere il percorso relativo del file di assegnazione dei punteggi nella cartella del codice sorgente. Lo script di assegnazione dei punteggi riceve i dati inviati a un servizio Web distribuito e lo passa al modello. Quindi, lo script esegue il modello e restituisce la risposta al client. Lo script di assegnazione dei punteggi è specifico del modello e deve comprendere i dati che il modello prevede come input e restituisce come output. Gli esempi di questo articolo usano un file score.py. Questo codice Python deve avere una funzione init e una funzione run. La init funzione viene chiamata dopo la creazione o l'aggiornamento del modello. È possibile utilizzarlo, ad esempio, per memorizzare il modello nella cache in memoria. La funzione run viene chiamata a ogni chiamata dell'endpoint per eseguire l'assegnazione del punteggio e la stima effettive. |
| Environment | Obbligatorio | Ambiente in cui ospitare il modello e il codice. Questo valore può essere un riferimento a un ambiente con controllo delle versioni esistente nell'area di lavoro o a una specifica dell'ambiente inline. L'ambiente può essere un'immagine Docker con dipendenze Conda, un Dockerfile o un ambiente registrato. |
| Tipo di istanza | Obbligatorio | Dimensioni della macchina virtuale da usare per la distribuzione. Per un elenco delle dimensioni supportate, vedere Elenco di SKU degli endpoint online gestiti. |
| Numero di istanze | Obbligatorio | Numero di istanze da usare per la distribuzione. Si basa il valore sul carico di lavoro previsto. Per l'alta disponibilità, raccomandiamo di utilizzare almeno tre istanze. Azure Machine Learning riserva un ulteriore 20% per l'esecuzione degli aggiornamenti. Per ulteriori informazioni, consultare gli endpoint online e gli endpoint batch di Azure Machine Learning. |
Per visualizzare un elenco completo degli attributi che è possibile specificare quando si crea una distribuzione, vedere Schema YAML della distribuzione online gestita dell'interfaccia della riga di comando (v2). Per la versione 2 di Python SDK, vedere Classe ManagedOnlineDeployment.
Creare un endpoint online
Impostare prima il nome dell'endpoint e quindi configurarlo. In questo articolo si usa il file endpoints/online/managed/sample/endpoint.yml per configurare l'endpoint. Il file contiene le righe seguenti:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
Nella tabella seguente vengono descritte le chiavi usate dal formato YAML dell'endpoint. Per informazioni su come specificare questi attributi, vedere lo schema YAML dell'endpoint online per la CLI (v2). Per informazioni sui limiti correlati agli endpoint online gestiti, vedere Endpoint online e endpoint batch di Azure Machine Learning.
| Chiave | Descrizione |
|---|---|
$schema |
(Facoltativo) Schema YAML. Per visualizzare tutte le opzioni disponibili nel file YAML, è possibile visualizzare lo schema nel blocco di codice precedente in un browser. |
name |
Nome dell'endpoint. |
auth_mode |
Modalità di autenticazione. Usare key per l'autenticazione basata su chiave. Usare aml_token per l'autenticazione basata su token di Azure Machine Learning. Per ottenere il token più recente, usare il comando az ml online-endpoint get-credentials. |
Per creare un endpoint online:
Impostare il nome dell'endpoint eseguendo il comando Unix seguente. Sostituire
YOUR_ENDPOINT_NAMEcon un nome univoco.export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Importante
I nomi degli endpoint devono essere univoci nell’area di Azure. Ad esempio, nell’area di Azure
westus2può esistere un solo endpoint denominatomy-endpoint.Creare l'endpoint nel cloud eseguendo il codice seguente. Questo codice usa il file endpoint.yml per configurare l'endpoint:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Creare la distribuzione blu
È possibile usare il file endpoints/online/managed/sample/blue-deployment.yml per configurare gli aspetti chiave di una distribuzione denominata blue. Il file contiene le righe seguenti:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Per utilizzare il file blue-deployment.yml per creare la distribuzione per l'endpoint blue, eseguire il comando seguente:
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Importante
Il flag --all-traffic nel comando az ml online-deployment create alloca il 100 percento del traffico dell'endpoint alla distribuzione blue appena creata.
Nel file blue-deployment.yaml la path riga specifica da dove caricare i file. L'interfaccia della riga di comando di Azure Machine Learning usa queste informazioni per caricare i file e registrare il modello e l'ambiente. Come procedura consigliata per l'ambiente di produzione, è necessario registrare il modello e l'ambiente e specificare il nome e la versione registrati separatamente nel codice YAML. Usare il formato model: azureml:<model-name>:<model-version> per il modello, model: azureml:my-model:1ad esempio . Per l'ambiente, usare il formato environment: azureml:<environment-name>:<environment-version>, ad esempio environment: azureml:my-env:1.
Per la registrazione, è possibile estrarre le definizioni YAML di model e environment in file YAML separati e usare i comandi az ml model create e az ml environment create. Per altre informazioni su questi comandi, eseguire az ml model create -h e az ml environment create -h.
Per altre informazioni sulla registrazione del modello come asset, vedere Registrare un modello usando l'interfaccia della riga di comando di Azure o Python SDK. Per altre informazioni sulla creazione di un ambiente, vedere Creare un ambiente personalizzato.





Confermare la distribuzione esistente
Un modo per confermare la distribuzione esistente consiste nel richiamare l'endpoint in modo che possa assegnare un punteggio al modello per una determinata richiesta di input. Quando si richiama l'endpoint tramite l'interfaccia della riga di comando di Azure o Python SDK, è possibile scegliere di specificare il nome della distribuzione per ricevere il traffico in ingresso.
Note
A differenza dell'interfaccia della riga di comando di Azure o di Python SDK, Azure Machine Learning Studio richiede di specificare una distribuzione quando si richiama un endpoint.
Richiamare un endpoint con un nome di distribuzione
Quando si richiama un endpoint, è possibile specificare il nome di un'implementazione a cui si desidera indirizzare il traffico. In questo caso, Azure Machine Learning instrada il traffico dell'endpoint direttamente alla distribuzione specificata e ne restituisce l'output. È possibile usare l'opzione --deployment-nameper l'interfaccia della riga di comando di Azure Machine Learning v2 o l'opzione deployment_nameper Python SDK v2 per specificare la distribuzione.
Richiamare l'endpoint senza specificare una distribuzione
Se si richiama l'endpoint senza specificare la distribuzione a cui si desidera inviare traffico, Azure Machine Learning instrada il traffico in ingresso dell'endpoint verso le distribuzioni presenti nell'endpoint in base alle impostazioni di controllo del traffico.
Le impostazioni di controllo del traffico allocano le percentuali di traffico in ingresso a ogni distribuzione nell'endpoint. Ad esempio, se le regole di traffico specificano che una particolare distribuzione nell'endpoint deve ricevere il traffico in ingresso il 40% del tempo, Azure Machine Learning instrada il 40% del traffico dell'endpoint a tale distribuzione.
Per visualizzare lo stato dell'endpoint e della distribuzione esistenti, eseguire i comandi seguenti:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
L'output elenca le informazioni sull'endpoint $ENDPOINT_NAME e sulla blue distribuzione.
Testare l'endpoint usando dati di esempio
È possibile richiamare l'endpoint usando il invoke comando . Il comando seguente usa il file JSONsample-request.json per inviare una richiesta di esempio:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json


Ridimensionare una distribuzione esistente per gestire più traffico
Nella distribuzione descritta in Distribuire e assegnare un punteggio a un modello di Machine Learning usando un endpoint online, impostare il instance_count valore su 1 nel file YAML di distribuzione. È possibile aumentare il numero di istanze usando il comando update:
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Note
Nel comando precedente, l'opzione --set esegue l'override della configurazione di distribuzione. In alternativa, è possibile aggiornare il file YAML e passarlo come input al update comando usando l'opzione --file .

Distribuire un nuovo modello ma non gestire il traffico verso di esso
Creare una nuova distribuzione denominata green:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Poiché non viene esplicitamente allocato alcun traffico alla distribuzione green, a questa non è allocato alcun traffico. È possibile verificare il fatto usando il comando seguente:
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
Testare la nuova distribuzione
Anche se alla distribuzione green è allocato lo 0% del traffico, è possibile richiamarla direttamente usando l'opzione --deployment:
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
Per usare un client REST per richiamare la distribuzione direttamente, senza passare attraverso le regole del traffico, impostare l'intestazione HTTP seguente: azureml-model-deployment: <deployment-name>. Il codice seguente usa Client per URL (cURL) per richiamare direttamente la distribuzione. È possibile eseguire il codice in un ambiente Unix o Sottosistema Windows per Linux (WSL). Per istruzioni sul recupero del valore, vedere $ENDPOINT_KEY del piano dati.
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json


Testare la distribuzione con il traffico con mirroring
Dopo aver testato la green distribuzione, è possibile eseguire il mirroring di una percentuale del traffico attivo verso l'endpoint copiando tale percentuale di traffico e inviandola alla green distribuzione. Il mirroring del traffico, detto anche shadowing, non modifica i risultati restituiti ai client: il 100% delle richieste continua a fluire verso la distribuzione blue. La percentuale del traffico con mirroring viene copiata e anche inviata alla distribuzione green in modo da poter raccogliere metriche e registrazioni senza impatto sui client.
Il mirroring è utile per convalidare una nuova distribuzione senza impatto sui client. Ad esempio, è possibile usare il mirroring per verificare se la latenza si trova all'interno di limiti accettabili o per verificare che non siano presenti errori HTTP. L'uso del mirroring del traffico, o shadowing, per testare una nuova distribuzione è noto anche come shadow testing. La distribuzione che riceve il traffico con mirroring, in questo caso, la distribuzione green, può anche essere chiamata distribuzione shadow.
Il mirroring presenta le limitazioni seguenti:
- Il mirroring è supportato per le versioni 2.4.0 e successive dell'interfaccia della riga di comando di Azure Machine Learning e delle versioni 1.0.0 e successive di Python SDK. Se si usa una versione precedente dell'interfaccia della riga di comando di Azure Machine Learning o Python SDK per aggiornare un endpoint, si perde l'impostazione del traffico mirror.
- Il mirroring non è attualmente supportato per gli endpoint online kubernetes.
- È possibile eseguire il mirroring del traffico a una sola distribuzione in un endpoint.
- La percentuale massima di traffico che è possibile eseguire il mirroring è del 50%. Questo limite limita l'effetto sulla quota di larghezza di banda dell'endpoint, che ha un valore predefinito di 5 MBps. La larghezza di banda dell'endpoint viene limitata se si supera la quota allocata. Per informazioni sul monitoraggio della limitazione della larghezza di banda, vedere Limitazione della larghezza di banda.
Si noti anche il comportamento seguente:
- È possibile configurare una distribuzione per ricevere solo traffico live o traffico con mirroring, non entrambi.
- Quando si richiama un endpoint, è possibile specificare il nome di una delle relative distribuzioni, anche una distribuzione shadow, per restituire la stima.
- Quando si richiama un endpoint e si specifica il nome di una distribuzione per ricevere il traffico in ingresso, Azure Machine Learning non esegue il mirroring del traffico verso la distribuzione shadow. Azure Machine Learning esegue il mirroring del traffico verso la distribuzione shadow dal traffico inviato all'endpoint quando non si specifica una distribuzione.
Se si imposta la distribuzione green per ricevere il 10% del traffico con mirroring, i client ricevono comunque stime solo dalla distribuzione blue.
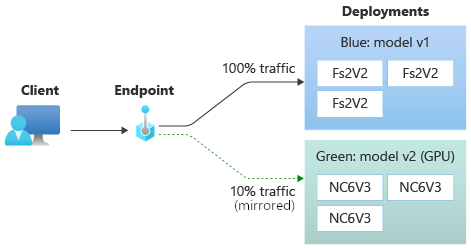
Usare il comando seguente per eseguire il mirroring del 10% del traffico e inviarlo alla green distribuzione:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
È possibile testare il traffico con mirroring richiamando l'endpoint più volte senza specificare una distribuzione per ricevere il traffico in ingresso:
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
È possibile confermare che la percentuale di traffico specificata venga inviata all'implementazione green controllando i log della stessa implementazione.
az ml online-deployment get-logs --name green --endpoint $ENDPOINT_NAME
Dopo il test, è possibile impostare il traffico con mirroring su zero per disabilitare il mirroring:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"



Allocare una piccola percentuale di traffico live alla nuova distribuzione
Dopo aver testato la distribuzione green, allocate una piccola percentuale di traffico ad essa.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
Suggerimento
La percentuale di traffico totale deve essere pari al 0% per disabilitare il traffico o il 100% per abilitare il traffico.
Ora la distribuzione green riceve il 10% del traffico attivo totale. I clienti ricevono previsioni sia dalle implementazioni blue che green.
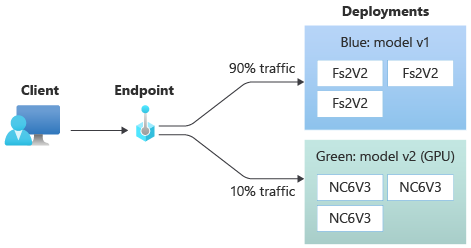
Inviare tutto il traffico alla nuova distribuzione
Quando si è completamente soddisfatti della distribuzione green, reindirizzare tutto il traffico verso di essa.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
Rimuovere la distribuzione precedente
Seguire questa procedura per eliminare una singola distribuzione da un endpoint online gestito. L'eliminazione di una singola distribuzione non influisce sulle altre distribuzioni nell'endpoint online gestito:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
Eliminare l'endpoint e la distribuzione
Se non si intende usare l'endpoint e la distribuzione, è necessario eliminarli. Quando si elimina un endpoint, vengono eliminate anche tutte le distribuzioni sottostanti.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait