Accedere ai dati in un processo
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Contenuto dell'articolo:
- Come leggere i dati dall'archiviazione di Azure in un processo di Azure Machine Learning.
- Come scrivere dati dal processo di Azure Machine Learning ad Archiviazione di Azure.
- Differenza tra modalità montaggio e download.
- Come usare l'identità utente e l'identità gestita per accedere ai dati.
- Impostazioni di montaggio disponibili in un processo.
- Impostazioni di montaggio ottimali per scenari comuni.
- Come accedere agli asset di dati V1.
Prerequisiti
Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Area di lavoro di Azure Machine Learning
Avvio rapido
Prima di esplorare le opzioni dettagliate disponibili quando si accede ai dati, vengono descritti i frammenti di codice pertinenti per l'accesso ai dati.
Come leggere i dati dall'archiviazione di Azure in un processo di Azure Machine Learning
In questo esempio si invia un processo di Azure Machine Learning che accede ai dati da un account di archiviazione BLOB pubblico. È tuttavia possibile adattare il frammento di codice per accedere ai propri dati in un account di Archiviazione di Azure privato. Aggiornare il percorso come descritto qui. Azure Machine Learning gestisce facilmente l'autenticazione nell'archiviazione cloud, con il pass-through Microsoft Entra. Quando si invia un processo, è possibile scegliere:
- Identità utente: passthrough l'identità di Microsoft Entra per accedere ai dati
- Identità gestita: usare l'identità gestita della destinazione di calcolo per accedere ai dati
- Nessuno: non specificare un'identità per accedere ai dati. Usare None quando si usano archivi dati basati su credenziali (chiave/token SAS) o quando si accede ai dati pubblici
Suggerimento
Se si usano chiavi o token di firma di accesso condiviso per l'autenticazione, è consigliabile creare un archivio dati di Azure Machine Learning, perché il runtime si connetterà automaticamente all'archiviazione senza esposizione della chiave/token.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Scrivere dati dal processo di Azure Machine Learning in Archiviazione di Azure
In questo esempio si invia un processo di Azure Machine Learning che scrive i dati nell'archivio dati predefinito di Azure Machine Learning. Facoltativamente, è possibile impostare il valore name dell'asset di dati per creare un asset di dati nell'output.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Runtime dei dati di Azure Machine Learning
Quando si invia un processo, il runtime dei dati di Azure Machine Learning controlla il caricamento dei dati, dalla posizione di archiviazione alla destinazione di calcolo. Il runtime dei dati di Azure Machine Learning è ottimizzato per velocità ed efficienza per le attività di Machine Learning. I vantaggi principali includono:
- I caricamenti di dati scritti nel linguaggio Rust, un linguaggio noto per l'efficienza di memoria elevata e ad alta velocità. Per i download simultanei dei dati, Rust evita problemi di Python Global Interpreter Lock (GIL)
- Peso leggero; Rust non ha dipendenze da altre tecnologie, ad esempio JVM. Di conseguenza, il runtime viene installato rapidamente e non svuota risorse aggiuntive (CPU, memoria) nella destinazione di calcolo
- Caricamento di dati multiprocesso (parallelo)
- Prefetch dei dati come attività in background sulle CPU, per consentire un migliore utilizzo delle GPU durante l'apprendimento avanzato
- Gestione dell'autenticazione facile nell'archiviazione cloud
- Fornisce opzioni per montare i dati (flusso) o scaricare tutti i dati. Per altre informazioni, vedere le sezioni Mount (streaming) e Download.
- Integrazione senza problemi con fsspec: un'interfaccia pythonica unificata per file system locali, remoti e incorporati e l'archiviazione dei byte.
Suggerimento
È consigliabile sfruttare il runtime di dati di Azure Machine Learning, invece di creare una funzionalità di montaggio/download personalizzata nel codice di training (client). Sono stati osservati vincoli di velocità effettiva di archiviazione quando il codice client usa Python per scaricare i dati dall'archiviazione, a causa problemi di blocco dell'interprete globale (GIL).
Percorsi
Quando si specifica un input/output di dati per un processo, è necessario specificare un parametro path che punta alla posizione dei dati. Questa tabella mostra i diversi percorsi di dati supportati da Azure Machine Learning e mostra anche path esempi di parametri:
| Ufficio | Esempi | Input | Output |
|---|---|---|---|
| Un percorso nel computer locale | ./home/username/data/my_data |
Y | N |
| Percorso in un server HTTP pubblico | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Un percorso in Archiviazione di Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, solo per l'autenticazione basata su identità. | N |
| Un percorso in un archivio dati di Azure Machine Learning | azureml://datastores/<data_store_name>/paths/<path> |
S | S |
| Un percorso per un asset di dati | azureml:<my_data>:<version> |
Y | N, ma è possibile usare name e version per creare un asset di dati dall'output |
Modalità
Quando si esegue un processo con input/output di dati, è possibile selezionare tra queste opzioni di modalità:
ro_mount: percorso di archiviazione di montaggio, come di sola lettura nella destinazione di calcolo del disco locale (SSD).rw_mount: percorso di archiviazione di montaggio, come di sola lettura nella destinazione di calcolo del disco locale (SSD).download: scaricare i dati dal percorso di archiviazione alla destinazione di calcolo del disco locale (SSD).upload: caricare i dati dalla destinazione di calcolo alla posizione di archiviazione.eval_mount/eval_download:queste modalità sono univoche per MLTable. In alcuni scenari, un oggetto MLTable può restituire file che potrebbero trovarsi in un account di archiviazione diverso dall'account di archiviazione che ospita il file MLTable. In alternativa, una tabella MLTable può creare subset o riconfigurare i dati che si trovano nella risorsa di archiviazione. Tale vista del subset/shuffle diventa visibile solo se il runtime di dati di Azure Machine Learning valuta effettivamente il file MLTable. Ad esempio, questo diagramma mostra come una tabella MLTable usata coneval_mountoeval_downloadpuò acquisire immagini da due contenitori di archiviazione diversi e un file di annotazioni che si trova in un account di archiviazione diverso e quindi montare/scaricare nel file system della destinazione di calcolo remota.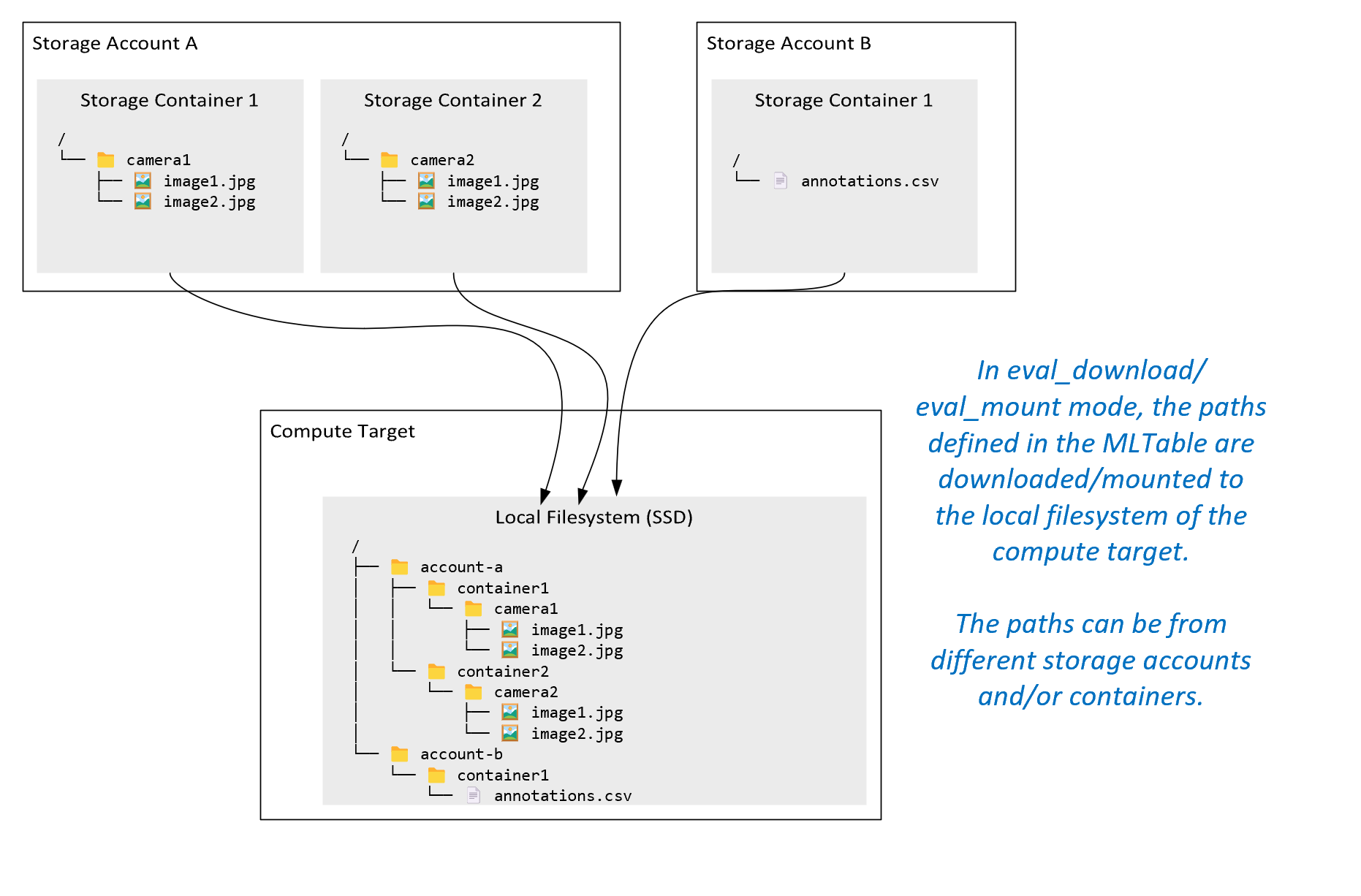
La cartella
camera1, la cartellacamera2e il fileannotations.csvsono quindi accessibili nel file system della destinazione di calcolo nella struttura di cartelle:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: è possibile leggere i dati direttamente da un URI tramite altre API, anziché passare attraverso il runtime dei dati di Azure Machine Learning. Ad esempio, è possibile accedere ai dati in un bucket s3 (con un URL virtual-hosted–style o path-stylehttps) usando il client boto s3. È possibile ottenere l'URI dell'input come stringa con la modalitàdirect. Viene visualizzato l'uso della modalità diretta nei processi Spark, perché i metodispark.read_*()sanno come elaborare gli URI. Per i processi di non Spark, è responsabilità dell'utente gestire le credenziali di accesso. Ad esempio, è necessario usare in modo esplicito l'identità del servizio gestito di calcolo o l'accesso broker.

La tabella illustra le modalità possibili per combinazioni diverse di tipo/modalità/input/output:
| Type | Input/Output | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Input | ✓ | ✓ | ✓ | ||||
uri_file |
Input | ✓ | ✓ | ✓ | ||||
mltable |
Input | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Output | ✓ | ✓ | |||||
uri_file |
Output | ✓ | ✓ | |||||
mltable |
Output | ✓ | ✓ | ✓ |
Scarica
In modalità download, tutti i dati di input vengono copiati nel disco locale (SSD) della destinazione di calcolo. Il runtime di dati di Azure Machine Learning avvia lo script di training dell'utente, una volta copiati tutti i dati. All'avvio dello script utente, legge i dati dal disco locale, esattamente come qualsiasi altro file. Al termine del processo, i dati vengono rimossi dal disco della destinazione di calcolo.
| Vantaggi | Svantaggi |
|---|---|
| All'avvio del training, tutti i dati sono disponibili nel disco locale (SSD) della destinazione di calcolo, per lo script di training. Non è necessaria alcuna interazione di archiviazione/rete di Azure. | Il set di dati deve adattarsi completamente a un disco di destinazione di calcolo. |
| Dopo l'avvio dello script utente, non ci sono dipendenze dall'affidabilità di archiviazione/rete. | L'intero set di dati viene scaricato (se il training deve selezionare in modo casuale solo una piccola parte di dati, la maggior parte del download viene quindi sprecato). |
| Il runtime dei dati di Azure Machine Learning può parallelizzare il download (differenza significativa in molti file di piccole dimensioni) e la velocità effettiva massima di rete/archiviazione. | Il processo attende fino a quando tutti i dati non vengono scaricati nel disco locale della destinazione di calcolo. Per un processo di Deep Learning inviato, le GPU sono inattive fino a quando i dati non sono pronti. |
| Nessun sovraccarico inevitabile aggiunto dal livello FUSE (round trip: chiamata dello spazio utente nello spazio utente del kernel dello → script → utente risposta del kernel → di fuse daemon → allo script utente nello spazio utente) | Le modifiche all'archiviazione non vengono riflesse sui dati dopo il download. |
Quando usare il download
- I dati sono sufficientemente piccoli da adattarsi al disco della destinazione di calcolo senza interferenze con altri training
- Il training usa la maggior parte o tutto il set di dati
- Il training legge i file da un set di dati più di una volta
- Il training deve passare a posizioni casuali di un file di grandi dimensioni
- È OK attendere che tutti i download di dati prima dell'avvio del training
Impostazioni di download disponibili
È possibile ottimizzare le impostazioni di download con queste variabili di ambiente nel processo:
| Nome di variabile di ambiente | Type | Valore predefinito | Descrizione |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Numero di download di thread simultanei che possono essere usati |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Numero di tentativi di prove di archiviazione / http richiesta di ripristino da errori temporanei. |
Nel processo è possibile modificare le impostazioni predefinite precedenti impostando le variabili di ambiente, ad esempio:
Per brevità, viene illustrato solo come definire le variabili di ambiente nel processo.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Scaricare le metriche delle prestazioni
Le dimensioni della macchina virtuale della destinazione di calcolo hanno un effetto sull'ora di download dei dati. In particolare:
- Numero di core. Più core sono disponibili, maggiore è la concorrenza e quindi una velocità di download più rapida.
- La larghezza di banda di rete prevista. Ogni macchina virtuale in Azure ha una velocità effettiva massima dalla scheda di interfaccia di rete.Each VM in Azure has a maximum throughput from the Network Interface Card (NIC).
Nota
Per le macchine virtuali GPU A100, il runtime di dati di Azure Machine Learning può saturare la scheda di interfaccia di rete (scheda di interfaccia di rete) durante il download dei dati nella destinazione di calcolo (~24 Gbit/s): La velocità effettiva massima teorica possibile.
Questa tabella illustra le prestazioni di download che il runtime di dati di Azure Machine Learning può gestire per un file da 100 GB in una macchina virtuale Standard_D15_v2 (20 core, velocità effettiva di rete da 25 Gbit/s):
| Struttura dei dati | Solo download (secs) | Scaricare e calcolare MD5 (secs) | Velocità effettiva ottenuta (Gbit/s) |
|---|---|---|---|
| 10 file x 10 GB | 55.74 | 260.97 | 14.35 Gbit/s |
| 100 file x 1 GB | 58.09 | 259.47 | 13.77 Gbit/s |
| 1 file x 100 GB | 96.13 | 300.61 | 8.32 Gbit/s |
È possibile notare che un file più grande, suddiviso in file più piccoli, può migliorare le prestazioni di download a causa del parallelismo. È consigliabile evitare che i file diventino troppo piccoli (meno di 4 MB) perché il tempo necessario per gli invii di richieste di archiviazione aumenta, in relazione al tempo impiegato per scaricare il payload. Per altre informazioni, leggere Problema di molti file di piccole dimensioni.
Montaggio (streaming)
In modalità di montaggio, la funzionalità dati di Azure Machine Learning usa la funzionalità FUSE (file system nello spazio utente) di Linux per creare un file system emulato. Anziché scaricare tutti i dati nel disco locale (SSD) della destinazione di calcolo, il runtime può reagire alle azioni script dell'utente in tempo reale. Ad esempio, "open file", "read 2-KB chunk from position X", "list directory content".
| Vantaggi | Svantaggi |
|---|---|
| I dati che superano la capacità del disco locale di destinazione di calcolo possono essere usati (non limitati dall'hardware di calcolo) | Aggiunta del sovraccarico del modulo Fuse linux. |
| Nessun ritardo all'inizio del training (a differenza della modalità di download). | Dipendenza dal comportamento del codice dell'utente’(se il codice di training che legge in sequenza file di piccole dimensioni in un montaggio a thread singolo richiede anche dati dall'archiviazione, potrebbe non ottimizzare la velocità effettiva di rete o archiviazione). |
| Altre impostazioni disponibili per ottimizzare uno scenario di utilizzo. | Nessun supporto Windows. |
| Solo i dati necessari al training vengono letti dall'archiviazione. |
Quando usare il montaggio
- I dati sono di grandi dimensioni e non rientrano nel disco locale di destinazione di calcolo.
- Ogni singolo nodo di calcolo in un cluster non deve leggere l'intero set di dati (file casuale o righe nella selezione di file CSV e così via).
- Ritardi nell'attesa del download di tutti i dati prima dell'avvio del training possono diventare un problema (tempo GPU inattiva).
Impostazioni di montaggio disponibili
È possibile ottimizzare le impostazioni di montaggio con queste variabili di ambiente nel processo:
| Nome della variabile Env | Type | Default value | Descrizione |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Non impostato (la cache non scade mai) | Tempo, in millisecondi, necessario per mantenere i risultati della chiamata getattr nella cache e per evitare richieste successive di queste informazioni dall'archiviazione. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Destinato a una configurazione di sistema, per mantenere integro il calcolo. Indipendentemente dai valori delle altre impostazioni, il runtime dei dati di Azure Machine Learning non usa gli ultimi RESERVED_FREE_DISK_SPACE byte di spazio su disco. |
DATASET_MOUNT_CACHE_SIZE |
usize | Nessun limite | Controlla la quantità di spazio su disco che può essere usata. Un valore positivo imposta il valore assoluto in byte. Il valore negativo imposta la quantità di spazio su disco da lasciare libero. Questa tabella offre altre opzioni della cache del disco. Supporta KB, MB e modificatori di GB per praticità. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Il montaggio del volume avvia l'eliminazione della cache quando la cache viene riempita fino a AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Deve essere compreso tra 0 e 1. Impostandolo < 1 attiva l'eliminazione della cache in background in precedenza. AVAILABLE_CACHE_SIZE non è una variabile di ambiente che è possibile modificare o visualizzare direttamente. In questo contesto, fa riferimento al "numero di byte calcolati dal sistema come disponibile per la memorizzazione nella cache". Questo valore dipende da fattori quali le dimensioni del disco, la quantità di spazio su disco necessaria per l'integrità del sistema e le configurazioni impostate nelle variabili di ambiente (ad esempio DATASET_RESERVED_FREE_DISK_SPACE e DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | L'eliminazione della cache tenta di liberare almeno (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) di spazio della cache. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Dimensioni del blocco di lettura di streaming. Quando il file è sufficientemente grande, richiedere almeno DATASET_MOUNT_READ_BLOCK_SIZE di dati dalla risorsa di archiviazione e memorizzare nella cache anche quando l'operazione di lettura richiesta da fuse era inferiore. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Il numero di blocchi da prefetch (blocco di lettura k attiva la prefetch in background dei blocchi k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Il numero di thread di prefetch in background. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | false | Abilitare la memorizzazione nella cache basata su blocchi. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Si applica solo a memorizzazione nella cache basata su blocchi. Le dimensioni della memorizzazione nella cache basata su blocchi di RAM possono essere usate. Il valore 0 disabilita completamente la memorizzazione nella cache della memoria. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | true | Si applica solo a memorizzazione nella cache basata su blocchi. Se impostato su True, la memorizzazione nella cache basata su blocchi usa il disco rigido locale per memorizzare nella cache i blocchi. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Si applica solo a memorizzazione nella cache basata su blocchi. La memorizzazione nella cache basata su blocchi scrive il blocco memorizzato nella cache in un disco locale in background. Questa impostazione controlla la quantità di montaggio della memoria utilizzabile per archiviare i blocchi in attesa dello scaricamento nella cache del disco locale. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Si applica solo a memorizzazione nella cache basata su blocchi. Numero di thread in background usati per la memorizzazione nella cache basata su blocchi per scrivere blocchi scaricati nel disco locale della destinazione di calcolo. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Tempo in secondi per unmount per completare (normalmente) tutte le operazioni in sospeso (ad esempio, scaricare le chiamate) prima di terminare forzatamente il ciclo di messaggi di montaggio. |
Nel processo è possibile modificare le impostazioni predefinite precedenti impostando le variabili di ambiente, ad esempio:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Modalità aperta basata su blocchi
La modalità aperta basata su blocchi suddivide ogni file in blocchi di dimensioni predefinite (ad eccezione dell'ultimo blocco). Una richiesta di lettura da una posizione specificata richiede un blocco corrispondente dall'archiviazione e restituisce immediatamente i dati richiesti. Una lettura attiva anche il prefetch in background di N blocchi successivi, usando più thread (ottimizzati per la lettura sequenziale). I blocchi scaricati vengono memorizzati nella cache a due livelli (RAM e disco locale).
| Vantaggi | Svantaggi |
|---|---|
| Recapito rapido dei dati allo script di training (meno blocco per blocchi non ancora richiesti). | Le letture casuali possono sprecare blocchi forward-prefetch. |
| Altri offload di lavoro nei thread in background (prefetch/memorizzazione nella cache). Il training può quindi continuare. | È stato aggiunto il sovraccarico per lo spostamento tra cache, rispetto alle letture dirette da un file in una cache del disco locale, ad esempio in modalità cache di file interi. |
| Solo i dati richiesti (più il prefetch) vengono letti dall'archiviazione. | |
| Per dati sufficienti, viene usata la cache basata su RAM veloce. |
Quando usare la modalità aperta basata su blocchi
Consigliato per la maggior parte degli scenari tranne quando sono necessarie letture rapide da percorsi di file casuali. In questi casi, usare la modalità aperta della cache di file interi.
Modalità di apertura della cache di file interi
Quando un file in una cartella di montaggio viene aperto (ad esempio, f = open(path, args)) in modalità file intero, la chiamata viene bloccata fino a quando l'intero file non viene scaricato in una cartella della cache di destinazione di calcolo sul disco. Tutte le chiamate di lettura successive reindirizzano al file memorizzato nella cache, quindi non è necessaria alcuna interazione di archiviazione. Se la cache non dispone di spazio sufficiente per adattarsi al file corrente, il montaggio tenta di eliminare il file usato meno di recente dalla cache. Nei casi in cui il file non può rientrare sul disco (rispetto alle impostazioni della cache), il runtime dei dati torna alla modalità di streaming.
| Vantaggi | Svantaggi |
|---|---|
| Nessuna dipendenza di affidabilità/velocità effettiva di archiviazione dopo l'apertura del file. | La chiamata aperta viene bloccata fino al download dell'intero file. |
| Letture casuali veloci (lettura di blocchi da posizioni casuali del file). | L'intero file viene letto dall'archiviazione, anche quando alcune parti del file potrebbero non essere necessarie. |
Quando usarlo
Quando sono necessarie letture casuali per file di dimensioni relativamente grandi che superano 128 MB.
Utilizzo
Impostare la variabile di ambiente DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED su false nel processo:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Montaggio: elenco di file
Quando si lavora con milioni di file, evitare un elenco ricorsivo, ad esempio ls -R /mnt/dataset/folder/. Un elenco ricorsivo attiva molte chiamate per elencare il contenuto della directory padre. Richiede quindi una chiamata ricorsiva separata per ogni directory all'interno, a tutti i livelli figlio. In genere, Archiviazione di Azure consente di restituire solo 5000 elementi per ogni singola richiesta di elenco. Di conseguenza, un elenco ricorsivo di 1 milione di cartelle contenenti 10 file richiede 1,000,000 / 5000 + 1,000,000 = 1,000,200 richieste di archiviazione. In confronto, 1.000 cartelle con 10.000 file richiederebbero solo 1001 richieste di archiviazione per un elenco ricorsivo.
Gli handle di montaggio di Azure Machine Learning vengono elencati in modo differito. Pertanto, per elencare molti file di piccole dimensioni, è preferibile usare una chiamata iterativa della libreria client (ad esempio, os.scandir() in Python) anziché una chiamata di libreria client che restituisce l'elenco completo (ad esempio, os.listdir() in Python). Una chiamata iterativa della libreria client restituisce un generatore, vale a dire che non è necessario attendere il caricamento dell'intero elenco. Può quindi procedere più velocemente.
Questa tabella confronta il tempo necessario per le funzioni di os.scandir() Python e os.listdir() per elencare una cartella contenente circa 4 milioni si file in una struttura flat:
| Metric | os.scandir() |
os.listdir() |
|---|---|---|
| Tempo per ottenere la prima voce (secs) | 0.67 | 553,79 |
| Tempo per ottenere le prime 50.000 voci (secs) | 9,56 | 562,73 |
| Tempo per ottenere tutte le voci (secs) | 558,35 | 582,14 |
Impostazioni di montaggio ottimali per scenari comuni
Per alcuni scenari comuni, vengono visualizzate le impostazioni di montaggio ottimali che è necessario impostare nel processo di Azure Machine Learning.
Lettura sequenziale di file di grandi dimensioni (righe di elaborazione nel file CSV)
Includere queste impostazioni di montaggio nella sezione environment_variables del processo di Azure Machine Learning:
Nota
Per usare il calcolo serverless, eliminare compute="cpu-cluster", in questo codice.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Lettura di file di grandi dimensioni una volta da più thread (elaborazione di file CSV partizionati in più thread)
Includere queste impostazioni di montaggio nella sezione environment_variables del processo di Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Lettura di milioni di file di piccole dimensioni (immagini) da più thread una sola volta (training di un singolo periodo sulle immagini)
Includere queste impostazioni di montaggio nella sezione environment_variables del processo di Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Lettura di milioni di file di piccole dimensioni (immagini) da più thread più volte (training di più periodi sulle immagini)
Includere queste impostazioni di montaggio nella sezione environment_variables del processo di Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Lettura di file di grandi dimensioni con ricerche casuali (ad esempio la gestione del database di file dalla cartella montata)
Includere queste impostazioni di montaggio nella sezione environment_variables del processo di Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Diagnosi e risoluzione dei colli di bottiglia per il caricamento dei dati
Quando un processo di Azure Machine Learning viene eseguito con i dati, il mode di un input determina il modo in cui i byte vengono letti dall'archiviazione e memorizzati nella cache nel disco SSD locale della destinazione di calcolo. Per la modalità di download, tutte le cache dei dati su disco, prima che il codice utente avvii l'esecuzione. Di conseguenza, fattori come
- numero di thread paralleli
- numero di file
- dimensione del file
hanno un effetto sulla velocità massima di download. Per il montaggio, il codice utente deve iniziare ad aprire i file prima che i dati inizino a memorizzare nella cache. Impostazioni di montaggio diverse comportano un comportamento di lettura e memorizzazione nella cache diverso. Vari fattori hanno un effetto sulla velocità di caricamento dei dati dall'archiviazione:
- Località dei dati per calcolare: le posizioni di archiviazione e di destinazione di calcolo devono essere uguali. Se la destinazione di archiviazione e di calcolo si trova in aree diverse, le prestazioni diminuiscono perché i dati devono essere trasferiti tra aree. Per altre informazioni su come assicurarsi che i dati si concatenino con il calcolo, vedere Collocare i dati con il calcolo.
- Le dimensioni della destinazione di calcolo: i calcoli di piccole dimensioni hanno un numero di core inferiore (minore parallelismo) e una larghezza di banda di rete inferiore rispetto alle dimensioni di calcolo maggiori, entrambi i fattori influiscono sulle prestazioni di caricamento dei dati.
- Ad esempio, se si usano dimensioni di macchina virtuale di piccole dimensioni, ad esempio
Standard_D2_v2(2 core, 1500 Mbps NIC) e si tenta di caricare 50.000 MB (50 GB) di dati, il tempo di caricamento dei dati più ottenibile sarà di circa 270 sec (presupponendo che si saturazione la scheda di interfaccia di rete a una velocità effettiva di 187,5 MB/s). Al contrario, unStandard_D5_v2(16 core, 12.000 Mbps) caricherà gli stessi dati in ~33 sec (presupponendo la saturazione della scheda di interfaccia di rete a 1500 MB/s di velocità effettiva).
- Ad esempio, se si usano dimensioni di macchina virtuale di piccole dimensioni, ad esempio
- Livello di archiviazione: per la maggior parte degli scenari, inclusi i modelli di linguaggio di grandi dimensioni (LLM), l'archiviazione standard offre il miglior profilo costo/prestazioni. Tuttavia, se si dispone di molti file di piccole dimensioni, archiviazione premium offre un profilo costo/prestazioni migliore. Per altre informazioni, vedere opzioni di Archiviazione di Azure.
- Carico di archiviazione: se l'account di archiviazione è sottoposto a carico elevato, ad esempio molti nodi GPU in un cluster che richiedono dati, si rischia di raggiungere la capacità di archiviazione in uscita. Per altre informazioni, vedere Caricamento archiviazione. Se si dispone di molti file di piccole dimensioni che richiedono l'accesso in parallelo, è possibile raggiungere i limiti di richiesta di archiviazione. Leggere informazioni aggiornate sui limiti per la capacità in uscita e le richieste di archiviazione nelle destinazioni di scalabilità per gli account di archiviazione standard.
- Modello di accesso ai dati nel codice utente: quando si usa la modalità di montaggio, i dati vengono recuperati in base alle azioni aperte/lette nel codice. Ad esempio, quando si leggono sezioni casuali di un file di grandi dimensioni, le impostazioni predefinite di prefetch dei dati dei montaggi possono causare download di blocchi che non verranno letti. Potrebbe essere necessario ottimizzare alcune impostazioni per raggiungere la velocità effettiva massima. Per altre informazioni, vedere Impostazioni di montaggio ottimali per scenari comuni.
Uso dei log per diagnosticare i problemi
Per accedere ai log del runtime di dati dal processo:
- Selezionare la scheda Output + log nella pagina del processo.
- Selezionare la cartella system_logs, quindi la cartella data_capability.
- Verranno visualizzati due file di log:
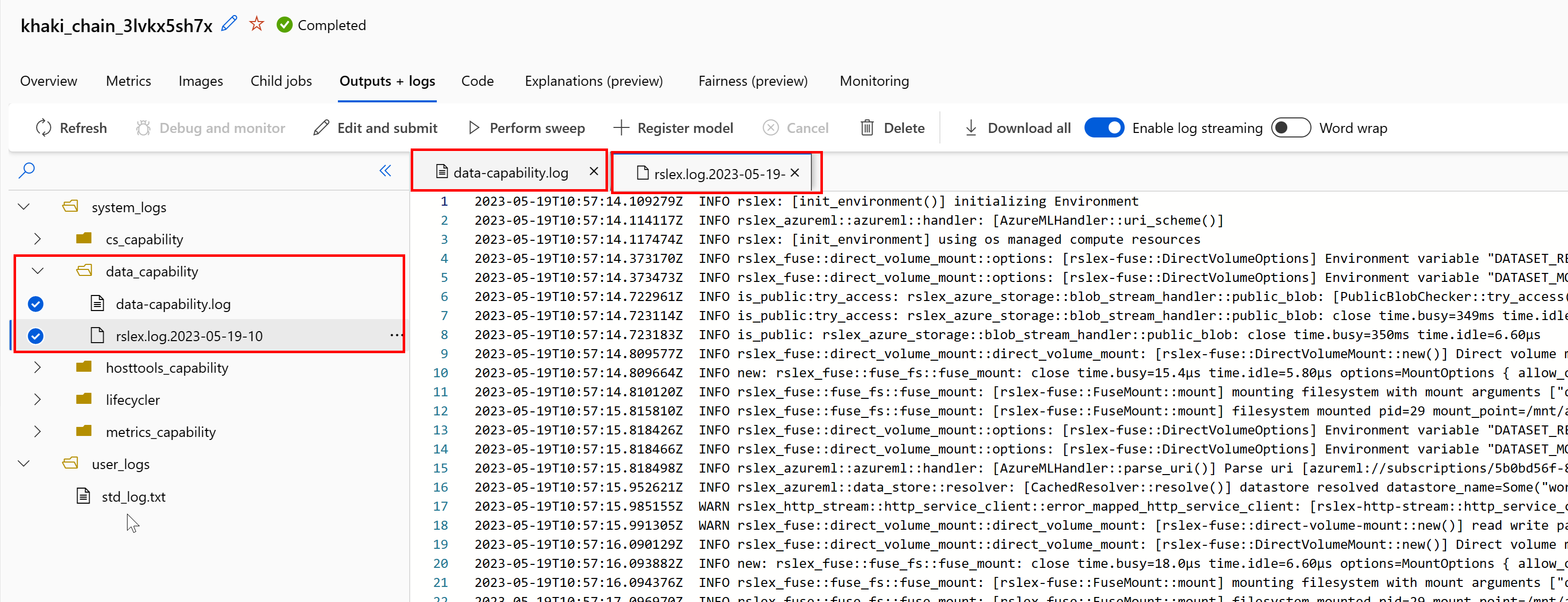

Il file di log data-capability.log mostra le informazioni generali sul tempo dedicato alle attività di caricamento dei dati chiave. Ad esempio, quando si scaricano dati, il runtime registra l'ora di inizio e fine dell'attività di download:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Se la velocità effettiva del download è una frazione della larghezza di banda di rete prevista per le dimensioni della macchina virtuale, è possibile esaminare il file di log rslex.log.<TIMESTAMP>. Questo file contiene tutte le registrazioni con granularità fine dal runtime basato su Rust; ad esempio, parallelizzazione:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
Il file rslex.log fornisce informazioni dettagliate su tutte le operazioni di copia del file, indipendentemente dal fatto che si abbia scelto o meno le modalità di montaggio o download. Descrive anche le impostazioni (variabili di ambiente) usate. Per avviare il debug, verificare se si impostano le Impostazioni di montaggio ottimali per scenari comuni.
Monitoraggio Archiviazione di Azure
Nel portale di Azure, è possibile selezionare l'account di archiviazione e quindi Metriche per visualizzare le metriche di archiviazione:

È quindi possibile tracciare SuccessE2ELatency con SuccessServerLatency. Se le metriche mostrano un numero elevato di SuccessE2ELatency e uno basso di SuccessServerLatency, sono presenti thread disponibili limitati oppure se si esegue un numero ridotto di risorse, ad esempio CPU, memoria o larghezza di banda di rete, è necessario:
- Usare visualizzazione di monitoraggio in studio di Azure Machine Learning per controllare l'utilizzo della CPU e della memoria del processo. Se la CPU e la memoria sono scarse, è consigliabile aumentare le dimensioni della macchina virtuale di destinazione del calcolo.
- Prendere in considerazione l'aumento di
RSLEX_DOWNLOADER_THREADSse si sta scaricando e non si usa la CPU e la memoria. Se si usa il montaggio, è consigliabile aumentareDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTper eseguire più prefetch e aumentareDATASET_MOUNT_READ_THREADSper altri thread di lettura.
Se le metriche mostrano una bassa SuccessE2ELatency e una bassa SuccessServerLatency, ma il client riscontra una latenza elevata, si verifica un ritardo nella richiesta di archiviazione che raggiunge il servizio. È necessario controllare:
- Indica se il numero di thread usati per il montaggio/download (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) è impostato su un valore troppo basso rispetto al numero di core disponibili nella destinazione di calcolo. Se l'impostazione è troppo bassa, aumentare il numero di thread. - Indica se il numero di tentativi per il download (
AZUREML_DATASET_HTTP_RETRY_COUNT) è impostato su un valore troppo elevato. In tal caso, ridurre il numero di tentativi.
Monitorare l'utilizzo del disco durante un processo
Da studio di Azure Machine Learning è anche possibile monitorare l'I/O del disco di destinazione di calcolo e l'utilizzo durante l'esecuzione del processo. Passare al processo e selezionare la scheda Monitoraggio. Questa scheda fornisce informazioni dettagliate sulle risorse del processo, in sequenza di 30 giorni. Ad esempio:

Nota
Il monitoraggio dei processi supporta solo le risorse di calcolo gestite da Azure Machine Learning. I processi con runtime inferiore a 5 minuti non avranno dati sufficienti per popolare questa visualizzazione.
Il runtime di dati di Azure Machine Learning non usa gli ultimi RESERVED_FREE_DISK_SPACE byte di spazio su disco per mantenere integro il calcolo (il valore predefinito è 150MB). Se il disco è pieno, il codice scrive i file su disco senza dichiarare i file come output. Controllare quindi il codice per assicurarsi che i dati non vengano scritti erroneamente sul disco temporaneo. Se è necessario scrivere file sul disco temporaneo e tale risorsa sta diventando piena, prendere in considerazione quanto segue:
- aumentare le dimensioni della macchina virtuale a uno con un disco temporaneo più grande
- impostare una durata (TTL) nei dati memorizzati nella cache (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL), per eliminare i dati dal disco
Collocare i dati con il calcolo
Attenzione
Se l'archiviazione e il calcolo si trovano in aree diverse, le prestazioni diminuiscono perché i dati devono essere trasferiti tra aree. Questo aumenta i costi. Assicurarsi che l'account di archiviazione e le risorse di calcolo si trovino nella stessa area.
Se i dati e l'area di lavoro di Azure Machine Learning vengono archiviati in aree diverse, è consigliabile copiare i dati in un account di archiviazione nella stessa area con l'utilità azcopy. AzCopy usa API da server a server, in modo che i dati copiano direttamente tra i server di archiviazione. Queste operazioni di copia non usano la larghezza di banda di rete del computer. È possibile aumentare la velocità effettiva di queste operazioni con la variabile di ambiente AZCOPY_CONCURRENCY_VALUE. Per altre informazioni, vedere Aumentare la concorrenza.
Carico di archiviazione
Un singolo account di archiviazione può diventare limitato quando si tratta di un carico elevato, quando:
- Il processo usa molti nodi GPU
- L'account di archiviazione ha molti utenti/app simultanei che accedono ai dati durante l'esecuzione del processo
Questa sezione illustra i calcoli per determinare se la limitazione potrebbe diventare un problema per il carico di lavoro e come affrontare le riduzioni della limitazione.
Larghezza di banda della rete
Un account di Archiviazione di Azure ha un limite di uscita predefinito di 120 Gbit/s. Le macchine virtuali di Azure hanno larghezze di banda di rete diverse, che hanno un effetto sul numero teorico di nodi di calcolo necessari per raggiungere il massimo di capacità predefinita in uscita dell'archiviazione:
| Dimensione | Scheda GPU | vCPU | Memoria: GiB | GiB di archiviazione temp (unità SSD) | Numero di schede GPU | Memoria GPU: GiB | Larghezza di banda di rete prevista (Gbit/s) | Valore massimo predefinito in uscita dell'account di archiviazione (Gbit/s)* | Numero di nodi per raggiungere la capacità in uscita predefinita |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Entrambi gli SKU A100/V100 hanno una larghezza di banda di rete massima per nodo di 24 Gbit/s. Se ogni nodo che legge i dati da un singolo account può leggere vicino al massimo teorico di 24 Gbit/s, la capacità in uscita si verifica con cinque nodi. L'uso di sei o più nodi di calcolo inizierebbe a ridurre la velocità effettiva dei dati in tutti i nodi.
Importante
Se il carico di lavoro richiede più di 6 nodi di A100/V100 o si ritiene che si superi la capacità di uscita predefinita di archiviazione (120Gbit/s), contattare il supporto tecnico (tramite il portale di Azure) e richiedere un aumento del limite di uscita di archiviazione.
Ridimensionamento tra più account di archiviazione
È possibile superare la capacità massima in uscita dello spazio di archiviazione e/o di raggiungere i limiti di frequenza delle richieste. Se si verificano questi problemi, è consigliabile contattare il supporto tecnico prima, per aumentare questi limiti per l'account di archiviazione.
Se non è possibile aumentare la capacità massima in uscita o il limite di frequenza delle richieste, è consigliabile prendere in considerazione la replica dei dati tra più account di archiviazione. Copiare i dati in più account con Azure Data Factory, Azure Storage Explorer o azcopy e montare tutti gli account nel processo di training. Vengono scaricati solo i dati a cui si accede in un montaggio. Pertanto, il codice di training può leggere il RANK dalla variabile di ambiente, per selezionare quale dei più input monta da cui leggere. La definizione del processo passa in un elenco di account di archiviazione:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Il codice Python di training può quindi usare RANK per ottenere l'account di archiviazione specifico per tale nodo:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Problemi di molti file di piccole dimensioni
La lettura dei file dall'archiviazione comporta l'esecuzione di richieste per ogni file. Il numero di richieste per file varia in base alle dimensioni dei file e alle impostazioni del software che gestisce le letture del file.
I file vengono in genere letti in blocchi di dimensioni pari a 1-4 MB. I file più piccoli di un blocco vengono letti con una singola richiesta (GET file.jpg 0-4 MB) e i file più grandi di un blocco hanno una richiesta effettuata per blocco (GET file.jpg 0-4 MB, GET file.jpg 4-8 MB). Questa tabella mostra che i file di dimensioni inferiori a un blocco di 4 MB generano più richieste di archiviazione rispetto ai file di dimensioni maggiori:
| # file | Dimensione file | Dimensioni totali dei dati | Dimensioni blocco | # richieste di archiviazione |
|---|---|---|---|---|
| 2.000.000 | 500 kB | 1 TB | 4 MB | 2.000.000 |
| 1.000 | 1 GB | 1 TB | 4 MB | 256.000 |
Per i file di piccole dimensioni, l'intervallo di latenza prevede principalmente la gestione delle richieste di archiviazione, anziché i trasferimenti di dati. Di conseguenza, offriamo questi consigli per aumentare le dimensioni del file:
- Per i dati non strutturati (immagini, testo, video e così via), archiviare file di piccole dimensioni (zip/tar) insieme, per archiviarli come file di dimensioni maggiori che possono essere letti in più blocchi. Questi file archiviati di dimensioni maggiori possono essere aperti nella risorsa di calcolo e PyTorch Archive DataPipes possono estrarre i file più piccoli.
- Per i dati strutturati (CSV, parquet e così via), esaminare il processo ETL per assicurarsi che i file vengano uniti per aumentare le dimensioni. Spark include metodi
repartition()ecoalesce()per aumentare le dimensioni dei file.
Se non è possibile aumentare le dimensioni dei file, esplorare le opzioni di Archiviazione di Azure.
Opzioni di Archiviazione di Azure
Archiviazione di Azure offre due livelli: standard e premium:
| Storage | Scenario |
|---|---|
| BLOB di Azure - Standard (HDD) | I dati sono strutturati in BLOB di dimensioni maggiori: immagini, video e così via. |
| BLOB di Azure - Premium (SSD) | Velocità delle transazioni elevate, oggetti più piccoli o requisiti di latenza di archiviazione costantemente bassi |
Suggerimento
Per "molti" file di piccole dimensioni (grandezza in KB), è consigliabile usare premium (SSD) perché il costo dell'archiviazione è inferiore ai costi di esecuzione del calcolo GPU.
Leggere asset di dati V1
Questa sezione illustra come leggere le entità dati FileDataset V1 e TabularDataset in un processo V2.
Leggere un FileDataset
Nell'oggetto Input specificare il type come AssetTypes.MLTABLE e mode come InputOutputModes.EVAL_MOUNT:
Nota
Per usare il calcolo serverless, eliminare compute="cpu-cluster", in questo codice.
Per altre informazioni sull'oggetto MLClient, sulle opzioni di inizializzazione degli oggetti MLClient e su come connettersi a un'area di lavoro, visitare Connettersi a un'area di lavoro.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Leggere un TabularDataset
Nell'oggetto Input specificare il type come AssetTypes.MLTABLE e mode come InputOutputModes.DIRECT:
Nota
Per usare il calcolo serverless, eliminare compute="cpu-cluster", in questo codice.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint
Passaggi successivi
- Eseguire il training dei modelli
- Esercitazione: Creare pipeline di Machine Learning di produzione con Python SDK v2
- Altre informazioni sui Dati in Azure Machine Learning