Attivare le pipeline di apprendimento automatico
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Questo articolo illustra come pianificare in modo programmatico l'esecuzione di una pipeline in Azure. È possibile creare una pianificazione in base al tempo trascorso o alle modifiche del file system. Le pianificazioni basate sul tempo possono essere usate per occuparsi delle attività di routine, ad esempio il monitoraggio della deriva dei dati. Le pianificazioni basate sulle modifiche possono essere usate per reagire a modifiche irregolari o imprevedibili, ad esempio i nuovi dati caricati o quelli obsoleti modificati. Dopo aver appreso come creare pianificazioni, si apprenderà come recuperarli e disattivarli. Infine, si apprenderà come usare altri servizi di Azure, App per la logica di Azure e Azure Data Factory per eseguire pipeline. Un'app per la logica di Azure consente di attivare una logica o un comportamento più complessi. Le pipeline di Azure Data Factory consentono di chiamare una pipeline di Machine Learning come parte di una pipeline di orchestrazione dei dati più grande.
Prerequisiti
Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito.
Un ambiente Python in cui è installato Azure Machine Learning SDK per Python. Per altre informazioni, vedere Creare e gestire ambienti riutilizzabili per il training e la distribuzione con Azure Machine Learning.
Un'area di lavoro di Machine Learning con una pipeline pubblicata. È possibile utilizzare quello integrato in Creare ed eseguire le pipeline di Machine Learning con Azure Machine Learning SDK.
Attivare pipeline con Azure Machine Learning SDK per Python
Per pianificare una pipeline, è necessario un riferimento all'area di lavoro, all'identificatore della pipeline pubblicata e al nome dell'esperimento in cui si vuole creare la pianificazione. È possibile ottenere questi valori con il codice seguente:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Creare una programmazione
Per eseguire una pipeline su base ricorrente, si creerà una pianificazione. Un Schedule associa una pipeline, un esperimento e un trigger. Il trigger può essere un ScheduleRecurrence che descrive l'attesa tra processi o un percorso dell'archivio dati che specifica una directory da controllare per le modifiche. In entrambi i casi, è necessario l'identificatore della pipeline e il nome dell'esperimento in cui creare la pianificazione.
Nella parte superiore del file Python importare le classi Schedule e ScheduleRecurrence:
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Creare una pianificazione basata sul tempo
Il costruttore ScheduleRecurrence ha un argomento frequency obbligatorio che deve essere una delle stringhe seguenti: "Minute", "Hour", "Day", "Week" o "Month". Richiede anche un argomento interval intero che specifica il numero di unità di frequency che devono trascorrere tra gli avvii della pianificazione. Gli argomenti facoltativi consentono di essere più specifici sull'ora di inizio, come descritto in dettaglio nella documentazione di ScheduleRecurrence SDK.
Creare un Schedule che avvia un processo ogni 15 minuti:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Creare una pianificazione basata su modifiche
Le pipeline attivate dalle modifiche ai file possono essere più efficienti rispetto alle pianificazioni basate sul tempo. Quando si desidera eseguire un'operazione prima della modifica di un file o quando un nuovo file viene aggiunto a una directory di dati, è possibile pre-elaborare tale file. È possibile monitorare le modifiche apportate a un archivio dati o all'interno di una directory specifica nell'archivio dati. Se si monitora una directory specifica, le modifiche all'interno di sottodirectory di tale directory non attivano un processo.
Nota
Le pianificazioni basate sulle modifiche supportano solo il monitoraggio dell'archiviazione BLOB di Azure.
Per creare un Schedule file-reattivo, è necessario impostare il parametro datastore nella chiamata a Schedule.create. Per monitorare una cartella, impostare l'argomento path_on_datastore.
L'argomento polling_interval consente di specificare, in minuti, la frequenza con cui l'archivio dati viene controllato per eventuali modifiche.
Se la pipeline è stata costruita con un DataPathPipelineParameter, è possibile impostare tale variabile sul nome del file modificato impostando l'argomento data_path_parameter_name.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Argomenti facoltativi durante la creazione di una pianificazione
Oltre agli argomenti illustrati in precedenza, è possibile impostare l'argomento status su "Disabled" per creare una pianificazione inattiva. Infine, il continue_on_step_failure consente di passare un valore booleano che sostituirà il comportamento di errore predefinito della pipeline.
Visualizzare le pipeline pianificate
Nel Web browser passare ad Azure Machine Learning. Nella sezione Endpoint del pannello di navigazione scegliere Endpoint pipeline. Verrà visualizzato un elenco delle pipeline pubblicate nell'area di lavoro.
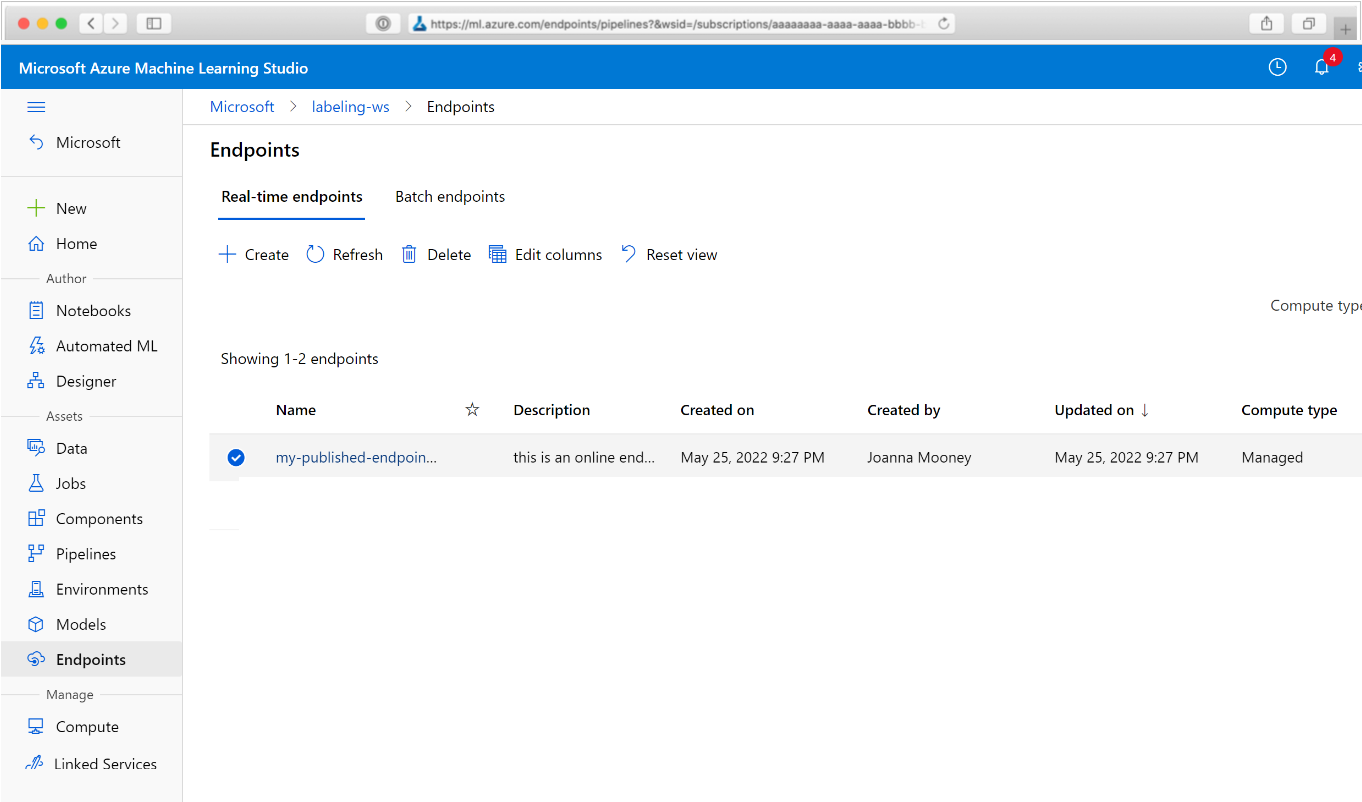
In questa pagina è possibile visualizzare informazioni di riepilogo su tutte le pipeline nell'area di lavoro: nomi, descrizioni, stato e così via. Eseguire il drill-in facendo clic sulla pipeline. Nella pagina risultante sono disponibili altri dettagli sulla pipeline ed è possibile eseguire il drill-down in singoli processi.
Disattivare la pipeline
Se si dispone di un Pipeline pubblicato, ma non pianificato, è possibile disabilitarlo con:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Se la pipeline è pianificata, è necessario annullare prima la pianificazione. Recuperare l'identificatore della pianificazione dal portale o eseguendo:
ss = Schedule.list(ws)
for s in ss:
print(s)
Dopo aver ottenuto il schedule_id che si vuole disabilitare, eseguire:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Se si esegue di nuovo Schedule.list(ws), si dovrebbe ottenere un elenco vuoto.
Usare App per la logica di Azure per trigger complessi
È possibile creare regole o comportamenti di trigger più complessi usando un’app per la logica di Azure.
Per usare un'app per la logica di Azure al fine di attivare una pipeline di Machine Learning, è necessario l'endpoint REST per una pipeline di Machine Learning pubblicata. Creare e pubblicare la pipeline. Individuare quindi l'endpoint REST del PublishedPipeline usando l'ID della pipeline:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Creare un'app per la logica in Azure
Creare ora un'istanza di app per la logica di Azure. Dopo il provisioning dell'app per la logica, seguire questa procedura per configurare un trigger per la pipeline:
Creare un'identità gestita assegnata dal sistema per fornire all'app l'accesso all'area di lavoro di Azure Machine Learning.
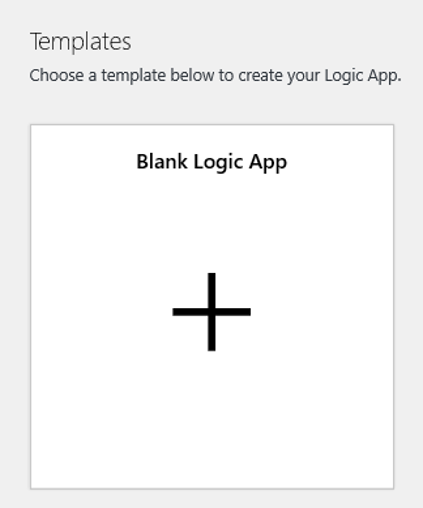
Passare alla visualizzazione Progettazione dell’app per la logica e selezionare il modello dell’app per la logica vuota.
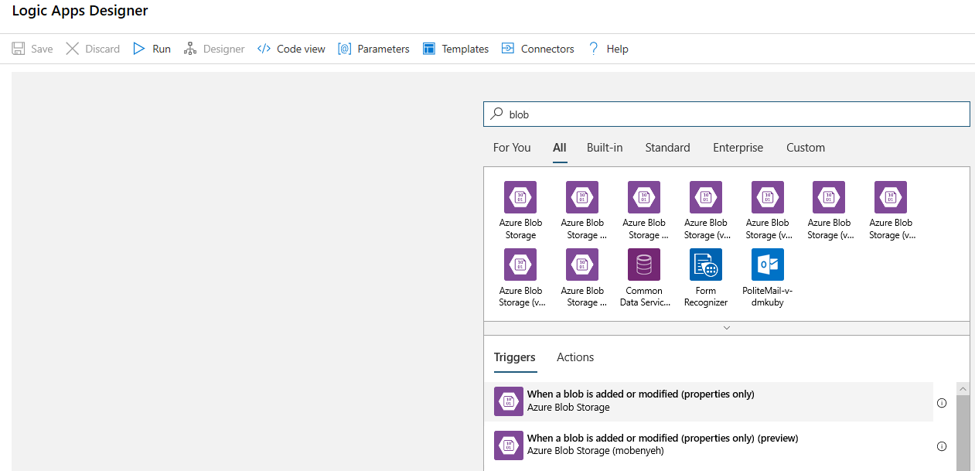
Nella finestra di progettazione, cercare BLOB. Selezionare il trigger Quando un BLOB viene aggiunto o modificato (solo proprietà) e aggiungere questo trigger all'app per la logica.
Immettere le informazioni di connessione per l'account di archiviazione BLOB che si vuole monitorare per individuare le aggiunte o le modifiche dei BLOB. Selezionare il contenitore da monitorare.
Scegliere Intervallo e Frequenza per eseguire il polling degli aggiornamenti che funzionano automaticamente.
Nota
Questo trigger monitorerà il contenitore selezionato, ma non le sottocartelle.
Aggiungere un'azione HTTP che verrà eseguita quando viene rilevato un BLOB nuovo o modificato. Selezionare + Nuovo passaggio, quindi cercare e selezionare l'azione HTTP.
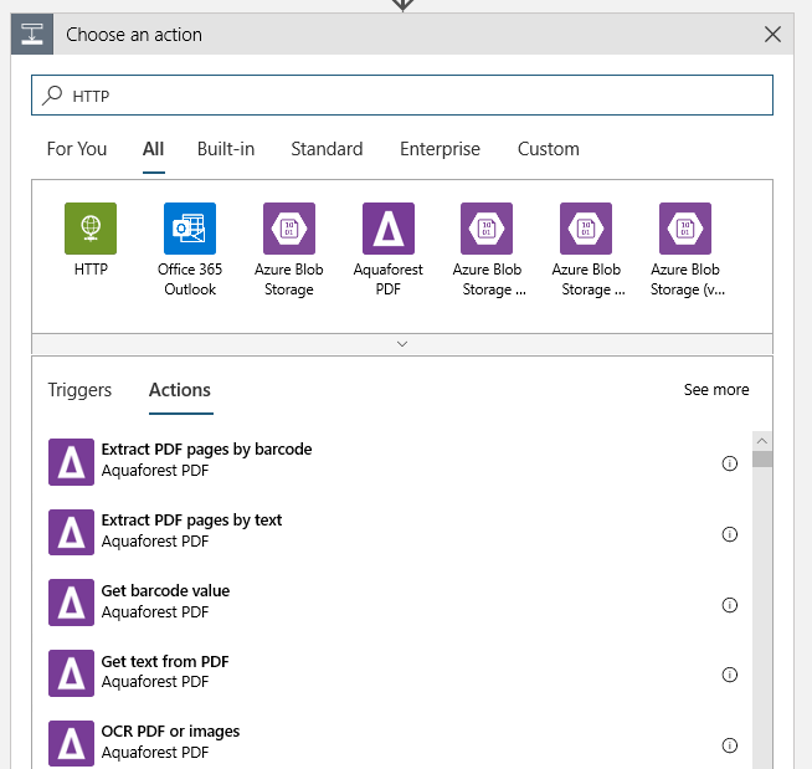
Usare le impostazioni seguenti per configurare l'azione:
| Impostazione | Valore |
|---|---|
| Azione HTTP | POST |
| URI | l'endpoint della pipeline pubblicata trovata come Prerequisito |
| Modalità di autenticazione | Identità gestita |
Configurare la pianificazione per impostare il valore di qualsiasi DataPath PipelineParameters possibile:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Usare il
DataStoreNameaggiunto all'area di lavoro come Prerequisito.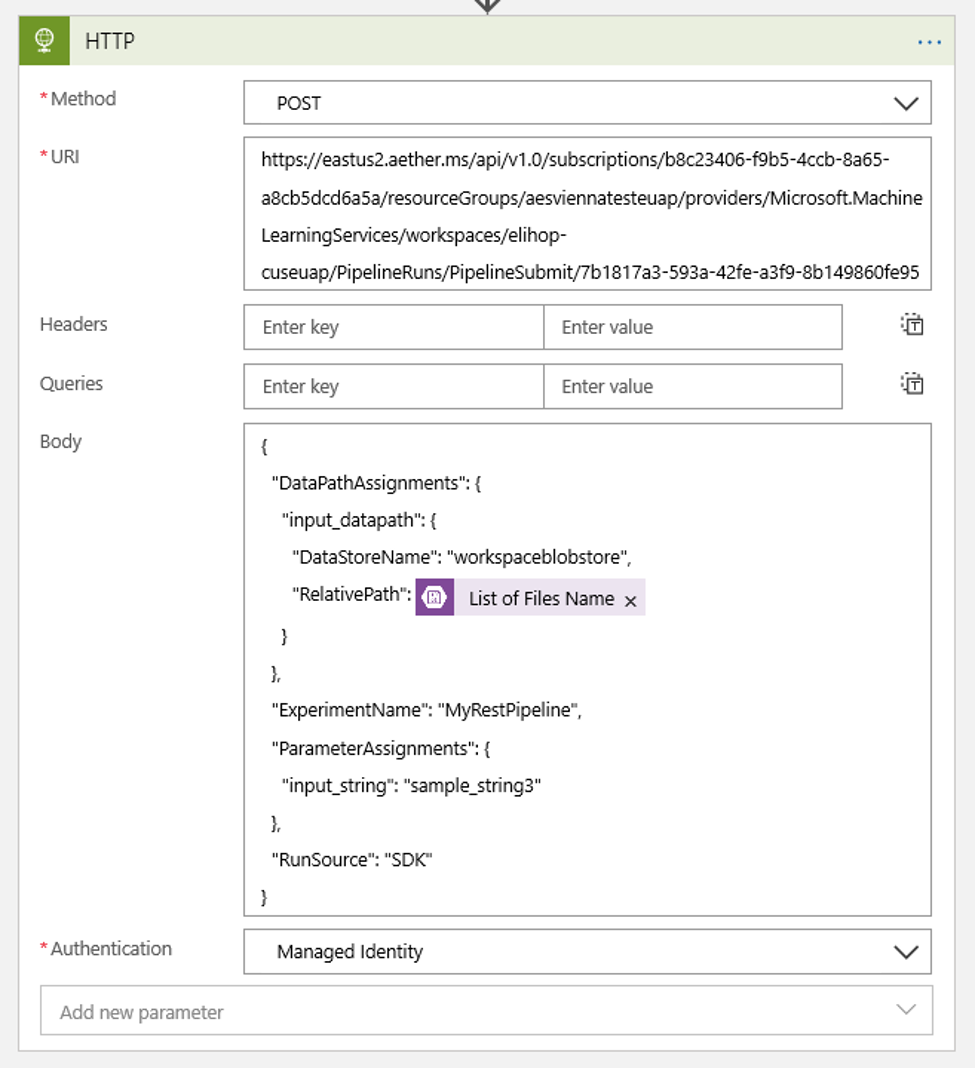
Selezionare Salva e la pianificazione è ora pronta.
Importante
Se, per gestire l'accesso alla pipeline, si usa il controllo degli accessi in base al ruolo di Azure, impostare le autorizzazioni per lo scenario della pipeline (training o punteggio).
Chiamare pipeline di Machine Learning da pipeline di Azure Data Factory
In una pipeline di Azure Data Factory l'attività di esecuzione della pipeline di Machine Learning esegue una pipeline di Azure Machine Learning. È possibile trovare questa attività nella pagina di creazione di Data Factory nella categoria Machine Learning:
Passaggi successivi
In questo articolo è stato usato Azure Machine Learning SDK per Python per pianificare una pipeline in due modi diversi. Una pianificazione si ripete in base all'ora trascorsa. Gli altri processi di pianificazione se un file viene modificato in un Datastore specificato o all'interno di una directory in tale archivio. È stato illustrato come usare il portale per esaminare la pipeline e i singoli processi. Si è appreso come disabilitare una pianificazione in modo che la pipeline arresti l'esecuzione. Infine, è stata creata un'app per la logica di Azure per attivare una pipeline.
Per altre informazioni, vedi:
- Altre informazioni sulle pipeline
- Altre informazioni sull’esplorazione di Azure Machine Learning con Jupyter