Come usare i modelli di base open source curati da Azure Machine Learning
Questo articolo illustra come ottimizzare, valutare e distribuire i modelli di base nel catalogo modelli.
È possibile testare rapidamente qualsiasi modello già sottoposto a training usando il modulo dell'esempio di inferenza nella scheda del modello, che fornisce input di esempio personalizzato per testare il risultato. Inoltre, la scheda del modello per ogni modello include una breve descrizione del modello e collegamenti a esempi per l'inferenza basata sul codice, l'ottimizzazione e la valutazione del modello.
Come valutare i modelli di base usando dati di test personalizzati
È possibile valutare un modello di base in base al set di dati di test usando il modulo di valutazione dell'interfaccia utente o gli esempi basati sul codice, di cui è disponibile un collegamento nella scheda del modello.
Valutazione con lo studio
È possibile richiamare il modulo di valutazione del modello selezionando il pulsante Valuta nella scheda del modello per qualsiasi modello di base.
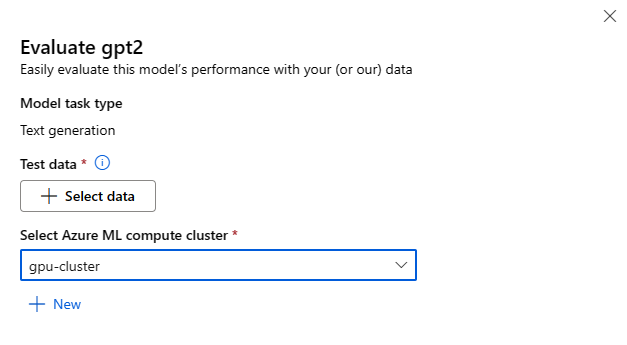
Ogni modello può essere valutato per l'attività di inferenza specifica per cui verrà usato.
Dati di test:
- Passare i dati di test da usare per valutare il modello. È possibile scegliere di caricare un file locale (in formato JSONL) o di selezionare un set di dati registrato esistente dall'area di lavoro.
- Dopo aver selezionato il set di dati, è necessario eseguire il mapping delle colonne dei dati di input, in base allo schema necessario per l'attività. Ad esempio, eseguire il mapping dei nomi di colonna corrispondenti alle chiavi 'frase' ed 'etichetta' per la classificazione del testo.

Calcolo:
Specificare il cluster di elaborazione di Azure Machine Learning che si vuole usare per ottimizzare il modello. La valutazione deve essere eseguita nell'ambiente di calcolo GPU. Assicurarsi di disporre di una quota di calcolo sufficiente per gli SKU di calcolo da usare.
Selezionare Fine nel modulo di valutazione per inviare il processo di valutazione. Al termine del processo, è possibile visualizzare le metriche di valutazione per il modello. In base alle metriche di valutazione, è possibile decidere se ottimizzare il modello usando dati di training personalizzati. È inoltre possibile decidere se registrare il modello e distribuirlo in un endpoint.
Valutazione con esempi basati sul codice
Per consentire agli utenti di iniziare a usare la valutazione del modello, sono stati pubblicati esempi (sia notebook Python che esempi dell'interfaccia della riga di comando) negli esempi di valutazione nel repository git azureml-examples. Ogni scheda del modello include i collegamenti anche a esempi di valutazione per le attività corrispondenti.
Come ottimizzare i modelli di base con dati di training personalizzati
Per migliorare le prestazioni del modello nel carico di lavoro, è possibile ottimizzare un modello base utilizzando i propri dati di training. È possibile ottimizzare facilmente questi modelli di base usando le impostazioni di ottimizzazione nello studio o gli esempi basati sul codice per cui è disponibile il collegamento nella scheda del modello.
Ottimizzare con lo studio
È possibile richiamare il modulo delle impostazioni di ottimizzazione selezionando il pulsante Ottimizza nella scheda del modello per qualsiasi modello di base.
Impostazioni di ottimizzazione:
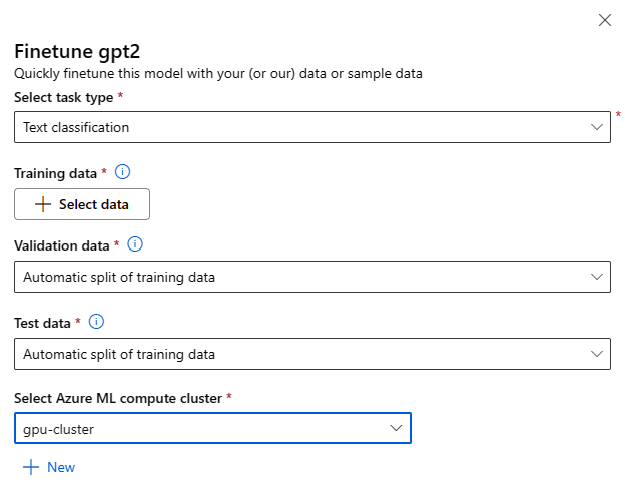
Tipo di attività di ottimizzazione
- Ogni modello già sottoposto a training dal catalogo modelli può essere ottimizzato per un set specifico di attività, ad esempio classificazione del testo, classificazione dei token e risposta alla domanda. Selezionare l'attività da usare nell'elenco a discesa.
Dati di training
Passare i dati di training da usare per ottimizzare il modello. È possibile scegliere di caricare un file locale (in formato JSONL, CSV o TSV) oppure selezionare un set di dati registrato esistente dall'area di lavoro.
Dopo aver selezionato il set di dati, è necessario eseguire il mapping delle colonne dai dati di input in base allo schema necessario per l'attività. Ad esempio, eseguire il mapping dei nomi di colonna corrispondenti alle chiavi 'frase' ed 'etichetta' per la classificazione del testo.

- Dati di convalida: passare i dati da usare per convalidare il modello. Selezionando Automatic split (Suddivisione automatica) viene prenotata una suddivisione automatica dei dati di training per la convalida. In alternativa, è possibile fornire un set di dati di convalida diverso.
- Dati di test: passare i dati di test da usare per valutare il modello ottimizzato. Selezionando Automatic split (Suddivisione automatica) viene prenotata una suddivisione automatica dei dati di training per il test.
- Ambiente di calcolo: specificare il cluster di elaborazione di Azure Machine Learning che si vuole usare per ottimizzare il modello. L'ottimizzazione deve essere eseguita nell'ambiente di calcolo GPU. Per l'ottimizzazione è consigliabile usare SKU di calcolo con GPU A100/V100. Assicurarsi di disporre di una quota di calcolo sufficiente per gli SKU di calcolo da usare.
- Selezionare Fine nel modulo di ottimizzazione per inviare il processo di ottimizzazione. Al termine del processo, è possibile visualizzare le metriche di valutazione per il modello ottimizzato. È quindi possibile registrare l'output del modello ottimizzato dal processo di ottimizzazione e distribuire questo modello in un endpoint per l'inferenza.
Ottimizzazione con esempi basati sul codice
Attualmente, Azure Machine Learning supporta modelli di ottimizzazione per le attività di linguaggio seguenti:
- Classificazione testo
- Classificazione dei token
- Risposta alle domande
- Riepilogo
- Traduzione
Per consentire agli utenti di iniziare rapidamente a usare l'ottimizzazione, sono stati pubblicati esempi (sia notebook Python che esempi dell'interfaccia della riga di comando) per ogni attività negli esempi di ottimizzazione nel repository git azureml-examples. Ogni scheda del modello è collegata anche a esempi di ottimizzazione per le attività di ottimizzazione supportate.
Distribuzione di modelli di base in endpoint per l'inferenza
È possibile distribuire modelli di base (sia modelli già sottoposti a training dal catalogo modelli che modelli ottimizzati, una volta registrati nell'area di lavoro) in un endpoint che può quindi essere usato per l'inferenza. La distribuzione in endpoint in tempo reale ed endpoint batch è supportata. È possibile distribuire questi modelli usando la procedura guidata di distribuzione di interfaccia utente o usando gli esempi basati sul codice per cui è presente un collegamento nella scheda del modello.
Distribuzione con lo studio
È possibile richiamare il modulo di distribuzione di interfaccia utente selezionando il pulsante Distribuisci nella scheda del modello per qualsiasi modello di base e selezionando l'endpoint in tempo reale o l'endpoint batch.

Impostazioni di distribuzione
Dal momento che lo script di assegnazione dei punteggi e l'ambiente vengono inclusi automaticamente nel modello di base, è sufficiente specificare lo SKU della macchina virtuale da usare, il numero di istanze e il nome dell'endpoint da usare per la distribuzione.
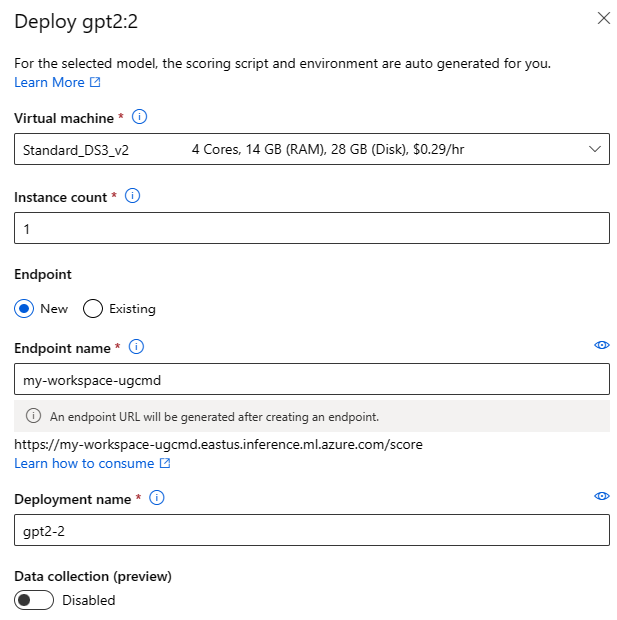
Quota condivisa
Se si distribuisce un modello Llama-2, Phi, Nemotron, Mistral, Dolly o Deci-DeciLM dal catalogo modelli, ma non è disponibile una quota sufficiente per la distribuzione, Azure Machine Learning consente di usare la quota da un pool di quote condivise per un periodo di tempo limitato. Per altre informazioni sulla quota condivisa, vedere Quota condivisa di Azure Machine Learning.

Distribuzione tramite esempi basati su codice
Per consentire agli utenti di iniziare rapidamente a usare la distribuzione e l'inferenza, sono stati pubblicati esempi negli esempi di inferenza nel repository git azureml-examples. Gli esempi pubblicati includono notebook Python ed esempi dell'interfaccia della riga di comando. Ogni scheda del modello include anche collegamenti a esempi di inferenza per l'inferenza in tempo reale e l'inferenza batch.
Importare modelli di base
Se si vuole usare un modello open source che non è incluso nel catalogo modelli, è possibile importare il modello da Hugging Face nell'area di lavoro di Azure Machine Learning. Hugging Face è una libreria open source per l'elaborazione del linguaggio naturale (NLP) che fornisce modelli con training preliminare per le attività NLP più comuni. Attualmente, l'importazione di modelli supporta l'importazione di modelli per le attività seguenti, purché il modello soddisfi i requisiti elencati nel notebook di importazione del modello:
- fill-mask
- token-classification
- question-answering
- summarization
- text-generation
- text-classification
- Traduzione
- image-classification
- text-to-image
Nota
I modelli di Hugging Face sono soggetti a condizioni di licenza di terze parti disponibili nella pagina dei dettagli del modello Hugging Face. È responsabilità dell'utente rispettare le condizioni di licenza del modello.
È possibile selezionare il pulsante Importa in alto a destra del catalogo modelli per usare il notebook di importazione del modello.
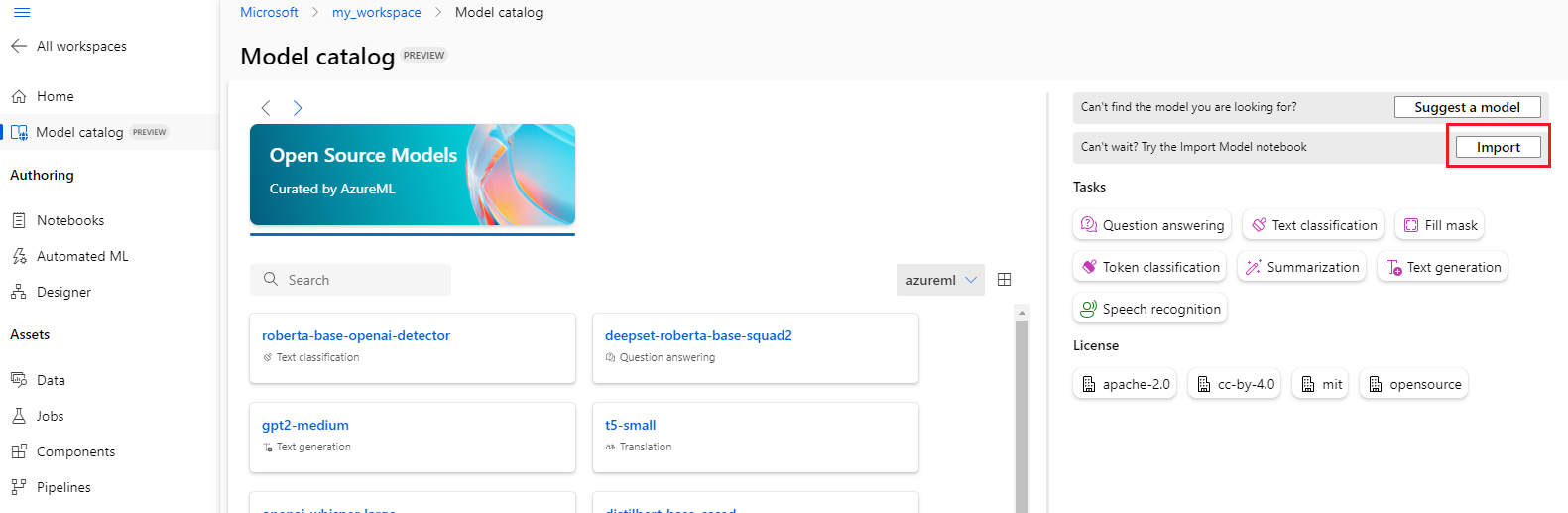
Il notebook di importazione del modello è incluso anche nel repository git azureml-examples disponibile qui.
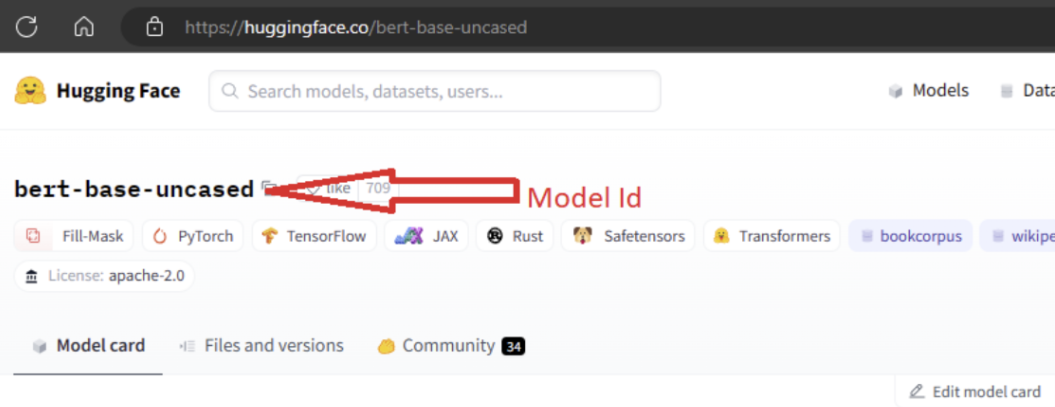
Per importare il modello, è necessario passare la variabile MODEL_ID del modello da importare da Hugging Face. Sfogliare i modelli nell'hub di Hugging Face e identificare il modello da importare. Assicurarsi che il tipo di attività del modello sia tra i tipi di attività supportati. Copiare l'ID modello, disponibile nell'URI della pagina o copiarlo usando l'icona di copia accanto al nome del modello. Assegnarlo alla variabile 'MODEL_ID' nel notebook di importazione del modello. Ad esempio:
È necessario fornire l'ambiente di calcolo per l'esecuzione dell'importazione del modello. Tale operazione comporta l'importazione del modello specificato da Hugging Face e la registrazione nell'area di lavoro di Azure Machine Learning. È quindi possibile ottimizzare questo modello o distribuirlo in un endpoint per l'inferenza.
Altre informazioni
- Esplorare il catalogo modelli nello studio di Azure Machine Learning. Per esplorare il catalogo, è necessaria un'area di lavoro di Azure Machine Learning.
- Esplorare il catalogo e le raccolte di modelli