Distribuire un flusso come endpoint online gestito per l'inferenza in tempo reale
Dopo aver creato un flusso e averlo testato correttamente, è possibile distribuirlo come endpoint in modo da poter richiamare l'endpoint per l'inferenza in tempo reale.
Questo articolo illustra come distribuire un flusso come endpoint online gestito per l'inferenza in tempo reale. I passaggi da eseguire sono:
- Testare il flusso e prepararlo per la distribuzione
- Creare una distribuzione online
- Concedere le autorizzazioni all'endpoint
- Testare l'endpoint
- Utilizzare l'endpoint
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. La versione di anteprima viene messa a disposizione senza contratto di servizio e non è consigliata per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Prerequisiti
Informazioni su come creare e testare un flusso nel prompt flow.
Avere una conoscenza di base sugli endpoint online gestiti. Gli endpoint online gestiti funzionano con potenti macchine CPU e GPU in Azure in modo scalabile e completamente gestito librando l'utente dalle attività di configurazione e gestione dell'infrastruttura di distribuzione sottostante. Per altre informazioni sugli endpoint online gestiti, vedere Endpoint e distribuzioni online per l'inferenza in tempo reale.
I controlli degli accessi in base al ruolo di Azure vengono usati per concedere l'accesso alle operazioni in Azure Machine Learning. Per poter distribuire un endpoint nel prompt flow, all'account utente deve essere assegnato il ruolo Scienziato dei dati di AzureML o un ruolo con più privilegi per l'area di lavoro di Azure Machine Learning.
Avere una conoscenza di base delle identità gestite. Altre informazioni sulle identità gestite.
Nota
L'endpoint online gestito supporta solo la rete virtuale gestita. Se l'area di lavoro si trova nella rete virtuale personalizzata, è necessario provare altre opzioni di distribuzione, ad esempio la distribuzione nell'endpoint online Kubernetes usando l'interfaccia della riga di comando/SDK o la distribuzione in altre piattaforme, ad esempio Docker.
Creare il flusso e prepararlo per la distribuzione
Se è già stata completata l'esercitazione introduttiva, il flusso è già stato testato correttamente inviando l'esecuzione batch e valutando i risultati.
Se l'esercitazione non è stata completata, è necessario creare un flusso. Testare correttamente il flusso con un'esecuzione batch e una valutazione prima della distribuzione è una procedura consigliata.
Si userà il flusso di esempio Classificazione Web per illustrare come distribuire il flusso. Questo flusso di esempio è un flusso standard. La distribuzione dei flussi di chat è simile. Il flusso di valutazione non supporta la distribuzione.
Definire l'ambiente usato dalla distribuzione
Quando si distribuisce il prompt flow all'endpoint online gestito nell'interfaccia utente, per impostazione predefinita la distribuzione userà l'ambiente creato in base all'immagine del prompt flow più recente e alle dipendenze specificate nel file requirements.txt del flusso. È possibile specificare pacchetti aggiuntivi necessari in requirements.txt. È possibile trovare il file requirements.txt nella cartella radice della cartella del flusso.

Nota
Se si usano feed privati in Azure DevOps, è necessario prima creare l'immagine con feed privati e selezionare l'ambiente personalizzato da distribuire nell'interfaccia utente.
Creare una distribuzione online
Dopo aver creato un flusso e averlo testato correttamente, è possibile creare l'endpoint online per l'inferenza in tempo reale.
Il prompt flow supporta la distribuzione degli endpoint da un flusso o da un'esecuzione batch. È consigliabile testare il flusso prima della distribuzione.
Nella pagina di creazione del flusso o nella pagina dei dettagli dell'esecuzione selezionare Distribuisci.
Pagina di creazione del flusso:

Pagina dei dettagli dell'esecuzione:

Viene eseguita una procedura guidata per la configurazione dell'endpoint che include i passaggi seguenti.
Impostazioni di base

Questo passaggio consente di configurare le impostazioni di base della distribuzione.
| Proprietà | Descrizione |
|---|---|
| Endpoint | È possibile scegliere se si vuole distribuire un nuovo endpoint o aggiornare un endpoint esistente. Se si seleziona Nuovo, è necessario specificare il nome dell'endpoint. |
| Nome distribuzione | - All'interno dello stesso endpoint, il nome della distribuzione deve essere univoco. - Se si seleziona un endpoint esistente e si immette un nome di distribuzione esistente, tale distribuzione verrà sovrascritta con le nuove configurazioni. |
| Macchina virtuale | Dimensioni della macchina virtuale da usare per la distribuzione. Per l'elenco delle dimensioni supportate, vedere Elenco di SKU degli endpoint online gestiti. |
| Numero di istanze | Numero di istanze da usare per la distribuzione. Specificare il valore del carico di lavoro previsto. Per la disponibilità elevata, è consigliabile impostare il valore almeno su 3. Si riserva un ulteriore 20% per l'esecuzione degli aggiornamenti. Per altre informazioni, vedere Quote degli endpoint online gestiti. |
| Raccolta dati di inferenza | Se si abilita questa opzione, gli input e gli output del flusso verranno raccolti automaticamente in un asset di dati di Azure Machine Learning e potranno essere usati per il monitoraggio successivo. Per altre informazioni, vedere Come monitorare le applicazioni di intelligenza artificiale generativa. |
Dopo aver completato le impostazioni di base, è possibile selezionare direttamente Rivedi e crea per completare la creazione oppure selezionare Avanti per configurare le Impostazioni avanzate.
Impostazioni avanzate - Endpoint
È possibile specificare le impostazioni seguenti per l'endpoint.

Tipo di autenticazione
Metodo di autenticazione per l'endpoint. L'autenticazione basata su chiave fornisce una chiave primaria e secondaria che non scade. L'autenticazione basata su token di Azure Machine Learning fornisce un token che viene aggiornato periodicamente. Per altre informazioni sull'autenticazione, vedere Eseguire l'autenticazione a un endpoint online.
Tipo di identità
L'endpoint deve accedere alle risorse di Azure, ad esempio Registro Azure Container o le connessioni dell'area di lavoro per l'inferenza. È possibile consentire all'endpoint di accedere alle risorse di Azure concedendo l'autorizzazione alla relativa identità gestita.
L'identità assegnata dal sistema verrà creata automaticamente dopo la creazione dell'endpoint, mentre l'identità assegnata dall'utente viene creata dall'utente. Vedere altre informazioni sulle identità gestite.
Assegnata dal sistema
Si noterà che è disponibile un'opzione che indica se Imporre l'accesso ai segreti di connessione (anteprima). Se il flusso usa le connessioni, l'endpoint deve accedere alle connessioni per eseguire l'inferenza. L'opzione è abilitata per impostazione predefinita; all'endpoint verrà concesso il ruolo Lettore di segreti di connessione dell'area di lavoro di Azure Machine Learning per accedere automaticamente alle connessioni se si dispone dell'autorizzazione di lettura dei segreti di connessione. Se si disabilita questa opzione, è necessario concedere manualmente questo ruolo all'identità assegnata dal sistema o chiedere assistenza all'amministratore. Altre informazioni su come concedere l'autorizzazione all'identità dell'endpoint.
Assegnata dall'utente
Quando si crea la distribuzione, Azure tenta di eseguire il pull dell'immagine del contenitore utente dal servizio Registro Azure Container dell'area di lavoro e di montare il modello utente e gli artefatti di codice nel contenitore utente dall'account di archiviazione dell'area di lavoro.
Se è stato creato l'endpoint associato con l'identità assegnata dall'utente, è necessario concedere all'identità assegnata dall'utente i ruoli seguenti prima della creazione della distribuzione; in caso contrario, la creazione della distribuzione avrà esito negativo.
| Ambito | Ruolo | Perché è necessario |
|---|---|---|
| Area di lavoro di Azure Machine Learning | Il ruolo Lettore segreti della connessione area di lavori di Azure Machine Learning OPPURE un ruolo personalizzato con "Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action" | Ottenere le connessioni all'area di lavoro |
| Registro contenitori dell'area di lavoro | Pull record di controllo di accesso | Eseguire il pull dell'immagine del contenitore |
| Archiviazione predefinita dell'area di lavoro | Lettore dei dati del BLOB di archiviazione | Caricare il modello dall'archiviazione |
| (Facoltativo) Area di lavoro di Azure Machine Learning | Writer delle metriche dell'area di lavoro | Dopo aver distribuito l'endpoint, se si desidera monitorare le metriche correlate all'endpoint, ad esempio utilizzo CPU/GPU/Disco/Memoria, è necessario concedere questa autorizzazione all'identità. |
Vedere le indicazioni dettagliate su come concedere le autorizzazioni all'identità dell'endpoint in Concedere le autorizzazioni all'endpoint.
Importante
Se il flusso usa connessioni di autenticazione basate su ID Entra di Microsoft, indipendentemente dall'uso dell'identità assegnata dal sistema o dell'identità assegnata dall'utente, è sempre necessario concedere all'identità gestita i ruoli appropriati delle risorse corrispondenti in modo che possa effettuare chiamate API a tale risorsa. Ad esempio, se la connessione Azure OpenAI usa l'autenticazione basata su ID Entra di Microsoft, è necessario concedere all'identità gestita dall'endpoint il ruolo di Utente OpenAI OpenAI di Servizi cognitivi o Collaboratore OpenAI di Servizi cognitivi delle risorse Azure OpenAI corrispondenti.
Impostazioni avanzate - Distribuzione
In questo passaggio, ad eccezione dei tag, è anche possibile specificare l'ambiente usato dalla distribuzione.

Usare l'ambiente della definizione del flusso corrente
Per impostazione predefinita, la distribuzione userà l'ambiente creato in base all'immagine di base specificata nel file flow.dag.yaml e alle dipendenze specificate nel file requirements.txt.
È possibile specificare l'immagine di base nel file
flow.dag.yamlselezionando l'opzioneRaw file modedel flusso. Se non è specificata alcuna immagine, l'immagine di base predefinita è l'immagine di base del prompt flow più recente.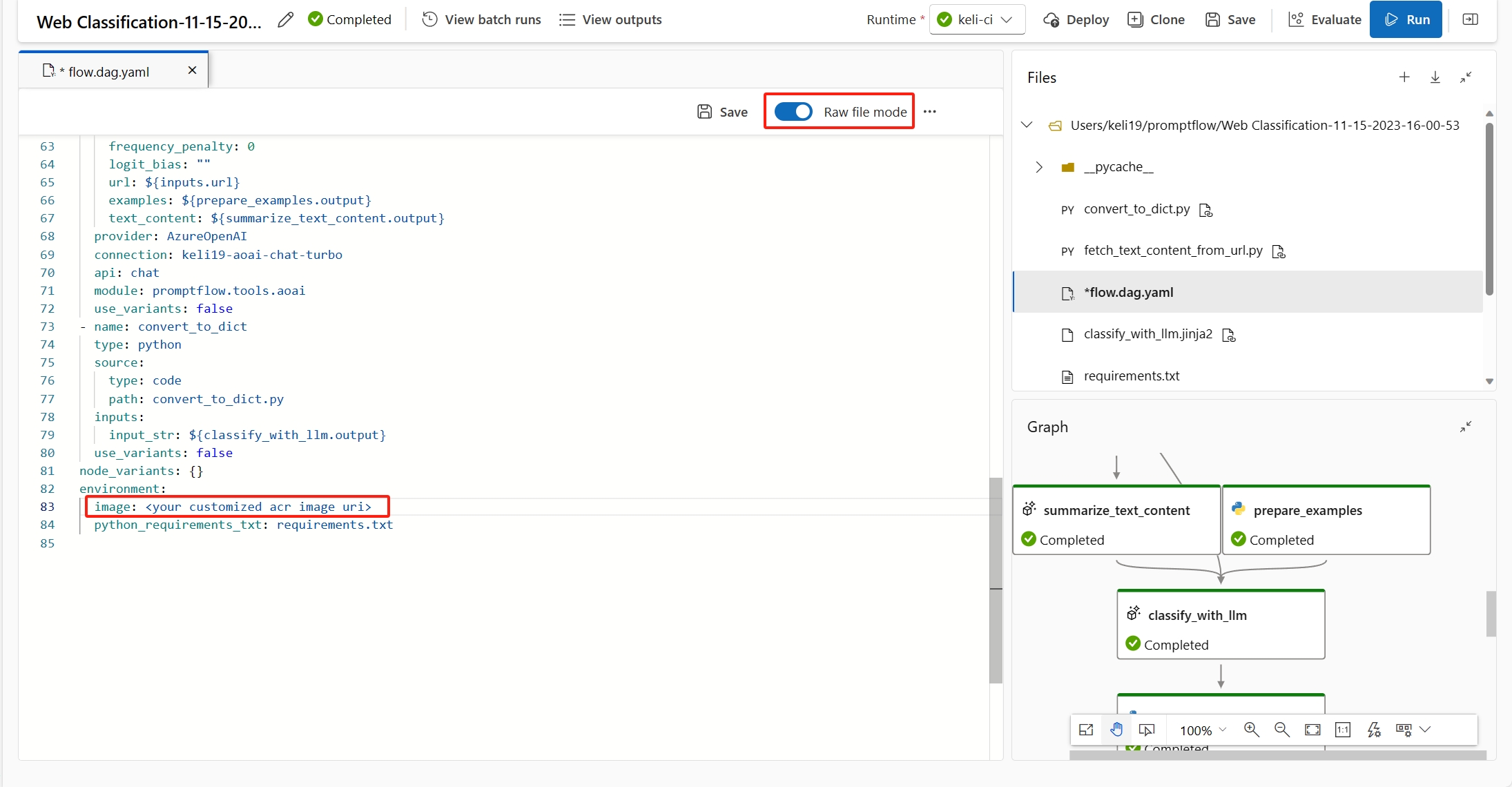
È possibile trovare il file
requirements.txtnella cartella radice della cartella del flusso e aggiungere le dipendenze all'interno del file stesso.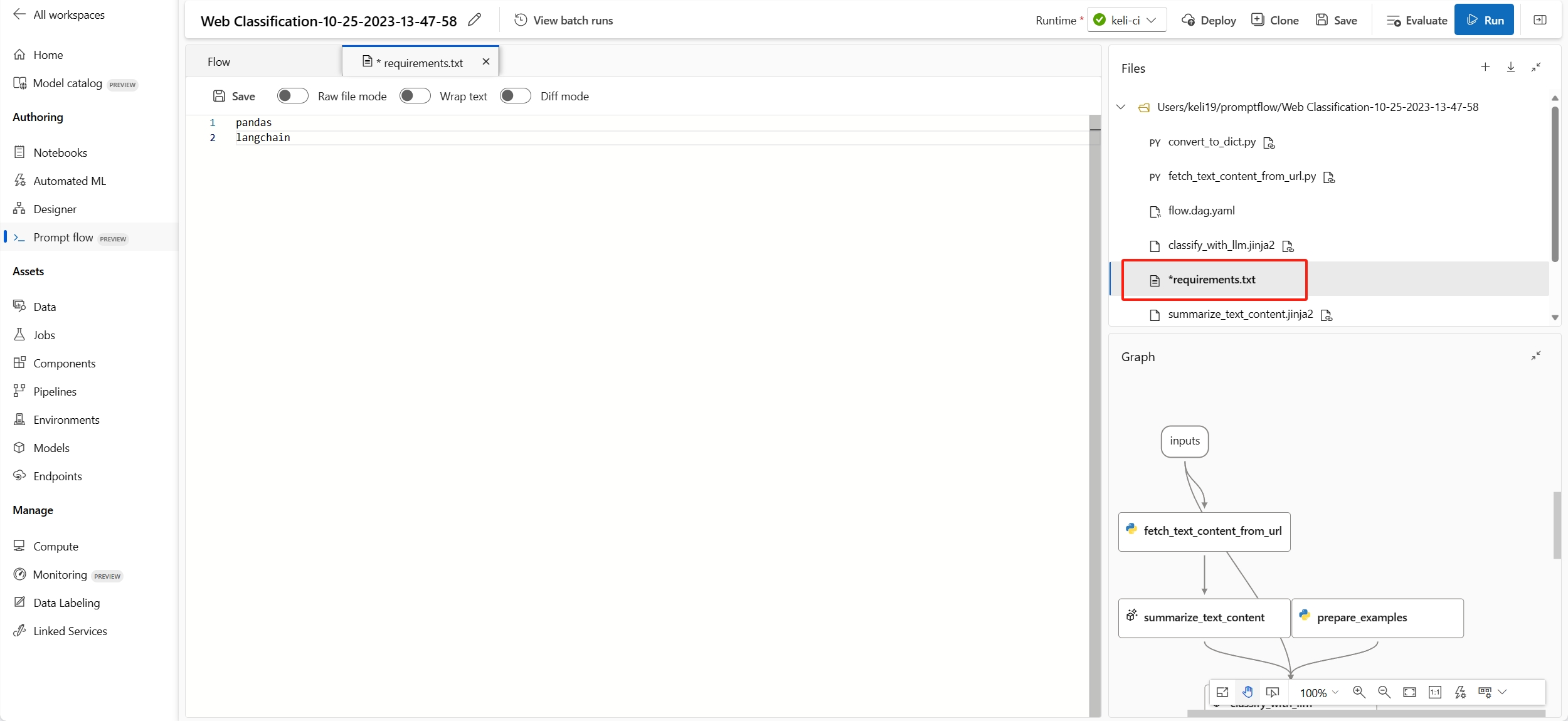

Usare un ambiente personalizzato
È anche possibile creare un ambiente personalizzato e usarlo per la distribuzione.
Nota
L'ambiente personalizzato deve soddisfare i requisiti seguenti:
- L'immagine docker deve essere creata in base all'immagine di base del prompt flow,
mcr.microsoft.com/azureml/promptflow/promptflow-runtime-stable:<newest_version>. La versione più recente è disponibile qui. - La definizione dell'ambiente deve includere
inference_config.
Di seguito è riportato un esempio di definizione di un ambiente personalizzato.
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
Abilitare la traccia attivando la diagnostica di Application Insights (anteprima)
Se si abilita questa opzione, i dati di tracciamento e le metriche di sistema durante il tempo di inferenza (come numero di token, latenza del flusso, richiesta di flusso e così via) verranno raccolte nell'istanza di Application Insights dell'area di lavoro. Per ulteriori informazioni, vedere Prompt flow che gestisce i dati e le metriche di tracciamento.
Se si desidera specificare un Application Insights diverso da quello collegato all'area di lavoro, è possibile configurare tramite l'interfaccia della riga di comando.
Impostazioni avanzate - Output e connessioni
In questo passaggio è possibile visualizzare tutti gli output del flusso e specificare quali output verranno inclusi nella risposta dell'endpoint distribuito. Per impostazione predefinita, vengono selezionati tutti gli output del flusso.
È anche possibile specificare le connessioni usate dall'endpoint quando esegue l'inferenza. Per impostazione predefinita, vengono ereditate dal flusso.
Dopo aver configurato e rivisto tutti i passaggi precedenti, è possibile selezionare Rivedi e crea per completare la creazione.
Nota
Si prevede che la creazione dell'endpoint richieda all'incirca più di 15 minuti, perché contiene diverse fasi, tra cui la creazione dell'endpoint, la registrazione del modello, la creazione della distribuzione e così via.
È possibile comprendere lo stato di avanzamento della creazione della distribuzione tramite la notifica avviata da Distribuzione del prompt flow.

Concedere le autorizzazioni all'endpoint
Importante
La concessione delle autorizzazioni (aggiunta dell'assegnazione di ruolo) è abilitata solo per il proprietario delle risorse di Azure specifiche. Potrebbe essere necessario chiedere assistenza all'amministratore IT. È consigliabile concedere ruoli all'identità assegnata dall'utenteprima della creazione della distribuzione. Per rendere effettiva l'autorizzazione concessa, potrebbero essere necessari più di 15 minuti.
È possibile concedere tutte le autorizzazioni nell'interfaccia utente del portale di Azure seguendo questa procedura.
Passare alla pagina di panoramica dell'area di lavoro di Azure Machine Learning nel portale di Azure.
Selezionare Controllo di accesso e quindi Aggiungi assegnazione di ruolo.
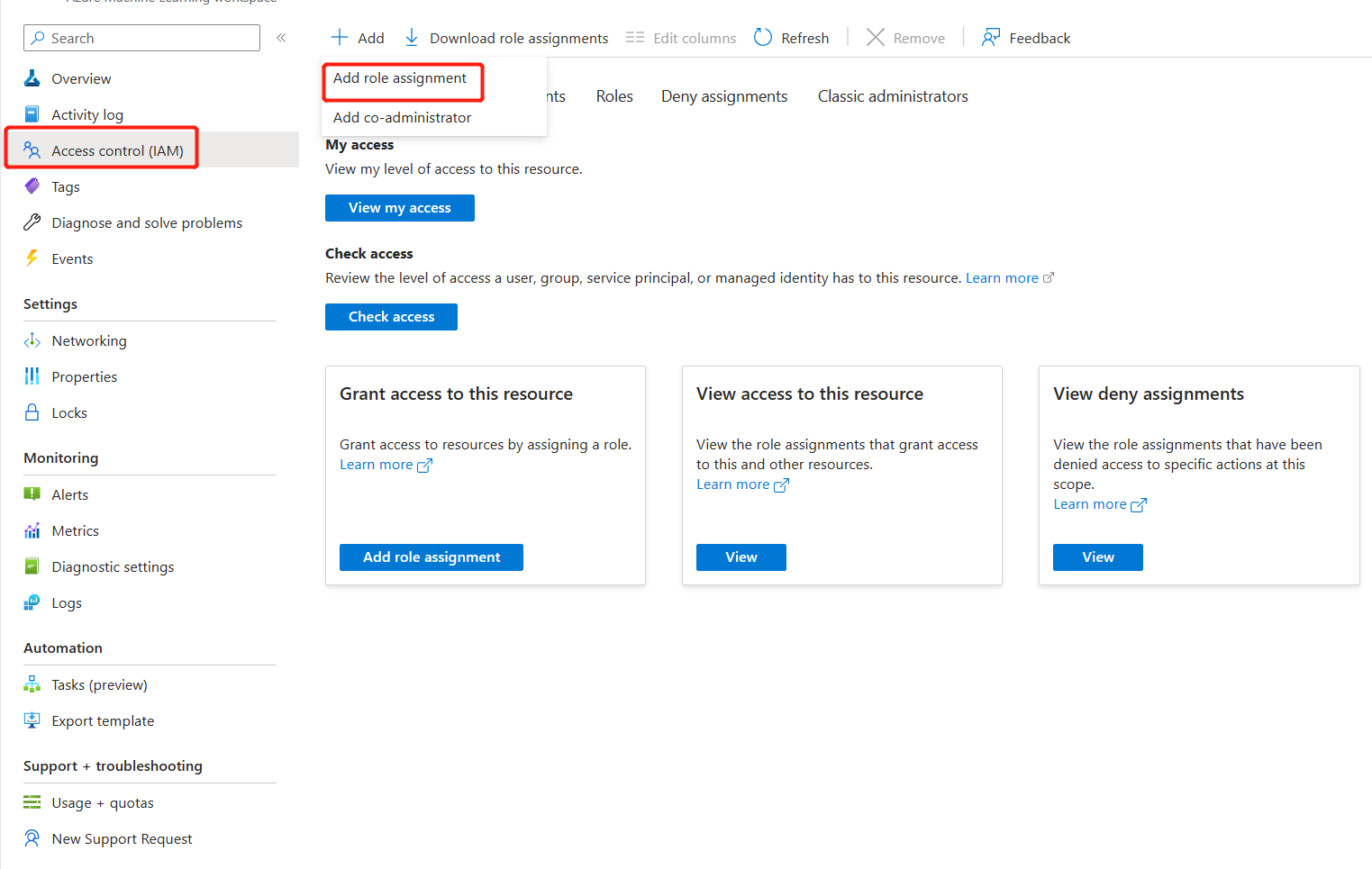
Selezionare Lettore di segreti di connessione dell'area di lavoro di Azure Machine Learning, quindi scegliere Avanti.
Nota
Lettore di segreti di connessione dell'area di lavoro di Azure Machine Learning è un ruolo predefinito che dispone dell'autorizzazione per ottenere le connessioni all'area di lavoro.
Per usare un ruolo personalizzato, assicurarsi che il ruolo personalizzato disponga dell'autorizzazione "Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action". Altre informazioni su Come creare ruoli personalizzati.
Selezionare Identità gestita e selezionare i membri.
Per l'identità assegnata dal sistema, selezionare Endpoint online di Machine Learning in Identità gestita assegnata dal sistema ed eseguire la ricerca in base al nome dell'endpoint.
Per l'identità assegnata dall'utente, selezionare Identità gestita assegnata dall'utente ed eseguire la ricerca in base al nome dell'identità.
Per l'identità assegnata dall'utente, è necessario concedere le autorizzazioni anche al registro contenitori e all'account di archiviazione dell'area di lavoro. È possibile trovare il registro contenitori e l'account di archiviazione nella pagina di panoramica dell'area di lavoro nel portale di Azure.
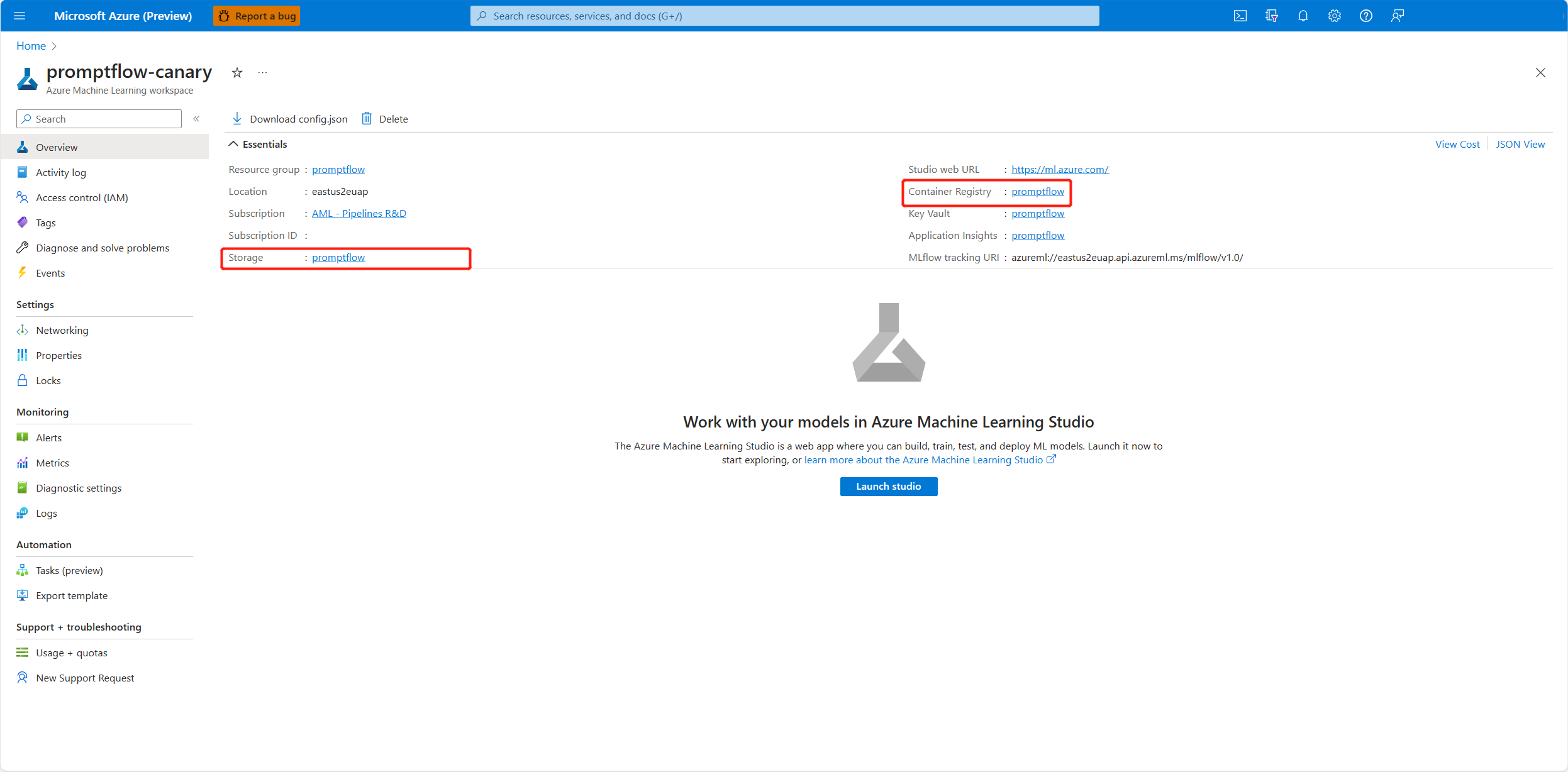
Passare alla pagina di panoramica del registro contenitori dell'area di lavoro, selezionare Controllo di accesso, quindi selezionare Aggiungi assegnazione di ruolo e assegnare Pull Registro Azure Container |Eseguire il pull dell'immagine del contenitore all'identità dell'endpoint.
Passare alla pagina di panoramica dell'archiviazione predefinita dell'area di lavoro, selezionare Controllo di accesso, quindi selezionare Aggiungi assegnazione di ruolo e assegnare Ruolo con autorizzazioni di lettura per i dati dei BLOB di archiviazione all'identità dell'endpoint.
(Facoltativo) Per l'identità assegnata dall'utente, se si vuole monitorare le metriche correlate all'endpoint, come l'utilizzo di CPU/GPU/disco/memoria, è necessario concedere all'identità anche il ruolo Writer delle metriche dell'area di lavoro.


Controllare lo stato dell'endpoint
Dopo aver completato la distribuzione guidata, verranno visualizzate alcune notifiche. Dopo aver creato correttamente l'endpoint e la distribuzione, è possibile selezionare Distribuisci dettagli nella pagina dei dettagli della notifica all'endpoint.
È anche possibile passare direttamente alla pagina Endpoint nello studio e controllare lo stato dell'endpoint distribuito.

Testare l'endpoint con dati di esempio
Nella pagina dei dettagli dell'endpoint passare alla scheda Test.
È possibile immettere i valori e selezionare il pulsante Test.
Il Risultato del test è il seguente:

Testare l'endpoint distribuito da un flusso di chat
Per gli endpoint distribuiti dal flusso di chat, è possibile testarli in una finestra di chat immersiva.

chat_input è stato impostato durante lo sviluppo del flusso di chat. È possibile immettere il messaggio chat_input nella casella di input. Il pannello Input sul lato destro consente di specificare i valori per gli altri input oltre a chat_input. Altre informazioni su Come sviluppare un flusso di chat.
Utilizzare l'endpoint
Nella pagina dei dettagli dell'endpoint passare alla scheda Utilizzo. È possibile trovare l'endpoint REST e la chiave/token per usare l'endpoint. È anche disponibile un codice di esempio per usare l'endpoint in diverse lingue.
Si noti che è necessario compilare i valori dei dati in base agli input del flusso. Prendendo come esempio il flusso di esempio usato in questo articolo Classificazione Web, è necessario specificare data = {"url": "<the_url_to_be_classified>"} e inserire la chiave o il token nel codice di utilizzo di esempio.

Monitorare gli endpoint
Visualizzare le metriche comuni degli endpoint online gestiti con Monitoraggio di Azure (facoltativo)
È possibile visualizzare varie metriche (numeri di richiesta, latenza delle richieste, byte di rete, utilizzo di CPU/GPU/disco/memoria e altro ancora) per un endpoint online e le relative distribuzioni seguendo i collegamenti della pagina Dettagli dell'endpoint nello studio. Questi collegamenti consentono di passare alla pagina esatta delle metriche nel portale di Azure per l'endpoint o la distribuzione.
Nota
Se si specifica l'identità assegnata dall'utente per l'endpoint, assicurarsi di aver assegnato il ruolo Writer delle metriche dell'area di lavoro dell'Area di lavoro di Azure Machine Learning all'identità assegnata dall'utente. In caso contrario, l'endpoint non sarà in grado di registrare le metriche.

Per altre informazioni su come visualizzare le metriche degli endpoint online, vedere Monitorare gli endpoint online.
Visualizzare metriche e dati di tracciamento specifici di endpoint del prompt flow (facoltativo)
Se si abilita diagnostica di Application Insights nella distribuzione guidata dell'interfaccia utente, i dati di tracciamento e le metriche specifici del prompt flow verranno raccolti nell'area di lavoro collegata ad Application Insights. Vedere i dettagli sull'abilitazione del tracciamento per la distribuzione.
Risolvere i problemi relativi agli endpoint distribuiti dal flusso immediato
Non si dispone dell'autorizzazione a eseguire l'azione "Microsoft.MachineLearningService/workspaces/datastores/read"
Se il flusso contiene lo strumento Ricerca indice, dopo la distribuzione del flusso l'endpoint deve accedere all'archivio dati dell'area di lavoro per leggere il file YAML MLIndex o la cartella FAISS contenente blocchi e incorporamenti. È quindi necessario concedere manualmente l'autorizzazione a farlo all'identità dell'endpoint.
È possibile concedere l'identità dell'endpoint AzureML Data Scientist nell'ambito dell'area di lavoro o un ruolo personalizzato contenente l'azione "MachineLearningService/workspace/datastore/reader".
Errore MissingDriverProgram
Se si distribuisce il flusso con un ambiente personalizzato e si verifica l'errore seguente, è possibile che non sia stato specificato inference_config nella definizione dell'ambiente personalizzato.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Esistono 2 modi per correggere questo errore.
(Scelta consigliata) È possibile trovare l'URI dell'immagine del contenitore nella pagina dei dettagli dell'ambiente personalizzato e impostarlo come immagine di base del flusso nel file flow.dag.yaml. Quando si distribuisce il flusso nell'interfaccia utente, è sufficiente selezionare Usare l'ambiente della definizione del flusso corrente e il servizio back-end creerà l'ambiente personalizzato in base a questa immagine di base e al file
requirement.txtper la distribuzione. Altre informazioni sull'ambiente specificato nella definizione del flusso.
È possibile correggere questo errore aggiungendo
inference_confignella definizione dell'ambiente personalizzato. Altre informazioni su Come usare l'ambiente personalizzato.Di seguito è riportato un esempio di definizione di un ambiente personalizzato.

$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
La risposta del modello richiede troppo tempo
In alcuni casi, si può notare che la distribuzione richiede troppo tempo per rispondere. Ci sono diversi fattori potenziali che possono causare questo problema.
- Il modello non è abbastanza potente (ad esempio, usare gpt su text-ada)
- La query dell'indice non è ottimizzata e richiede troppo tempo
- Il flusso ha molti passaggi da elaborare
Provare a ottimizzare l'endpoint con le considerazioni precedenti per migliorare le prestazioni del modello.
Impossibile recuperare lo schema di distribuzione
Dopo aver distribuito l'endpoint e averlo testato nella scheda Test della pagina dei dettagli dell'endpoint, se la scheda Test mostra Non è possibile recuperare lo schema di distribuzione come indicato di seguito, è possibile provare i 2 metodi seguenti per attenuare questo problema:

- Assicurarsi di avere concesso l'autorizzazione corretta all'identità dell'endpoint. Altre informazioni su come concedere l'autorizzazione all'identità dell'endpoint.
Accesso negato all'elenco dei segreti dell'area di lavoro
Se si verifica un errore simile ad "Accesso negato all'elenco dei segreti dell'area di lavoro", verificare se è stata concessa l'autorizzazione corretta all'identità dell'endpoint. Altre informazioni su come concedere l'autorizzazione all'identità dell'endpoint.
Pulire le risorse
Se non si intende usare l'endpoint dopo aver completato questa esercitazione, è necessario eliminarlo.
Nota
L'eliminazione completa può richiedere circa 20 minuti.
Passaggi successivi
- Eseguire l'iterazione e ottimizzare il flusso ottimizzando i prompt usando varianti
- Abilitare il tracciamento e raccogliere feedback per la distribuzione
- Visualizzare i costi per un endpoint online gestito di Azure Machine Learning
- Risoluzione dei problemi relativi alle distribuzioni del prompt flow.