Pipeline e set di dati di esempio per la finestra di progettazione di Azure Machine Learning
Usare gli esempi incorporati nella finestra di progettazione di Azure Machine Learning per iniziare rapidamente a creare le proprie pipeline di Machine Learning. Il repository GitHub della finestra di progettazione di Azure Machine Learning contiene la documentazione dettagliata per comprendere alcuni scenari comuni di Machine Learning.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito.
- Area di lavoro di Azure Machine Learning
Importante
Se gli elementi grafici citati in questo documento non vengono visualizzati, ad esempio i pulsanti di Studio o della finestra di progettazione, è possibile che non si abbia il livello di autorizzazioni appropriato per l'area di lavoro. Contattare l'amministratore della sottoscrizione di Azure per verificare che sia stato concesso il livello di accesso corretto. Per altre informazioni, vedere Gestire utenti e ruoli.
Usare le pipeline di esempio
La finestra di progettazione salva una copia delle pipeline di esempio nell'area di lavoro dello studio. È possibile modificare la pipeline per adattarla alle proprie esigenze e salvarla come pipeline personalizzata. È possibile usarla come punto di partenza per avviare rapidamente i progetti.
Di seguito viene illustrato come usare un esempio di finestra di progettazione:
Accedere a ml.azure.com e selezionare l'area di lavoro che si vuole usare.
Selezionare Progettazione.
Selezionare una pipeline di esempio nella sezione Nuova pipeline.
Selezionare Mostra più esempi per un elenco completo di esempi.
Per eseguire una pipeline, è necessario prima di tutto impostare la destinazione di calcolo predefinita in cui eseguirla.
Nel riquadro Impostazioni a destra dell'area di disegno selezionare Seleziona destinazione di calcolo.
Nella finestra di dialogo visualizzata selezionare una destinazione di calcolo esistente o crearne una nuova. Seleziona Salva.
Selezionare Invia nella parte superiore del canvas per avviare un processo della pipeline.
A seconda della pipeline di esempio e delle impostazioni di calcolo, il completamento dei processi potrebbe richiedere del tempo. Le impostazioni di calcolo predefinite prevedono una dimensione minima del nodo pari a 0, il che significa che la finestra di progettazione deve allocare risorse dopo l'inattività. I processi ripetuti della pipeline richiederanno meno tempo, perché le risorse di calcolo sono già allocate. Inoltre, la finestra di progettazione usa i risultati memorizzati nella cache per ogni componente per migliorare ulteriormente l'efficienza.
Al termine dell'esecuzione, è possibile esaminare la pipeline e visualizzare l'output di ogni componente per acquisire altre informazioni. Per visualizzare l'output dei componenti, procedere come segue:
- Fare clic con il pulsante destro del mouse sul componente nel canvas di cui si vuole visualizzare l'output.
- Selezionare Visualize (Visualizza).
Usare gli esempi come punti di partenza per alcuni scenari più comuni di Machine Learning.
Regressione
Esplorare questi esempi di regressione incorporati.
| Titolo di esempio | Descrizione |
|---|---|
| Regressione - Previsione dei prezzi delle automobili (base) | Stimare i prezzi delle automobili usando la regressione lineare. |
| Regressione - Previsione dei prezzi delle automobili (avanzata) | Stimare i prezzi delle automobili usando la foresta delle decisioni e i regressori degli alberi delle decisioni con boosting. Confrontare i modelli per trovare l'algoritmo migliore. |
Classificazione
Esplorare questi esempi di classificazione incorporati. Per altre informazioni, aprire gli esempi e visualizzare i commenti del componente nella finestra di progettazione.
| Titolo di esempio | Descrizione |
|---|---|
| Classificazione binaria con selezione delle funzionalità - Stima del reddito | Stimare il reddito come alto o basso, usando un albero delle decisioni con boosting a due classi. Usare la correlazione di Pearson per selezionare le funzionalità. |
| Classificazione binaria con script di Python personalizzato - Stima del rischio di credito | Classificare le applicazioni di credito come ad alto o basso rischio. Usare il componente di esecuzione dello script Python per ponderare i dati. |
| Classificazione binaria - Stima delle relazioni con i clienti | Stimare l'abbandono dei clienti usando alberi delle decisioni con boosting a due classi. Usare SMOTE per campionare i dati distorti. |
| Classificazione del testo - Set di dati Wikipedia SP 500 | Classificare i tipi di aziende da articoli Wikipedia con regressione logistica multiclasse. |
| Classificazione multiclasse - Riconoscimento delle lettere | Creare un insieme di classificatori binari per classificare le lettere scritte. |
Visione artificiale
Esplorare questi esempi di visione artificiale predefiniti. Per altre informazioni, aprire gli esempi e visualizzare i commenti del componente nella finestra di progettazione.
| Titolo di esempio | Descrizione |
|---|---|
| Classificazione delle immagini con DenseNet | Usare i componenti di visione artificiale per creare un modello di classificazione delle immagini basato su PyTorch DenseNet. |
Moduli di raccomandazione
Esplorare questi esempi di raccomandazione incorporati. Per altre informazioni, aprire gli esempi e visualizzare i commenti del componente nella finestra di progettazione.
| Titolo di esempio | Descrizione |
|---|---|
| Raccomandazione basata su Wide & Deep - Stima della valutazione dei ristoranti | Creare un motore di raccomandazione dei ristoranti dalle funzionalità e dalle valutazioni di ristoranti/utenti. |
| Raccomandazione - Tweet sulla classificazione dei film | Creare un motore di raccomandazione di film da presentazioni e valutazioni di utenti/film. |
Utilità
Altre informazioni sugli esempi che illustrano le utilità e le funzionalità di Machine Learning. Per altre informazioni, aprire gli esempi e visualizzare i commenti del componente nella finestra di progettazione.
| Titolo di esempio | Descrizione |
|---|---|
| Classificazione binaria tramite il modello Vowpal Wabbit - Stima del reddito degli adulti | Vowpal Wabbit è un sistema di Machine Learning che supera i limiti di Machine Learning con tecniche come hash, allreduce, reduction, learning2search, nonché apprendimento online, attivo e interattivo. Questo esempio illustra come usare il modello di Vowpal Wabbit per creare il modello di classificazione binaria. |
| Usare uno script R personalizzato - Stima dei ritardi dei voli | Usare lo script R personalizzato per stimare se un volo passeggeri pianificato subirà un ritardo di oltre 15 minuti. |
| Convalida incrociata per la classificazione binaria - Stima del reddito per adulti | Usare la convalida incrociata per creare un classificatore binario per il reddito degli adulti. |
| Permutation Feature Importance (Importanza caratteristica permutazione) | Usare l'importanza della caratteristica di permutazione per calcolare i punteggi di importanza per il set di dati di test. |
| Ottimizzare i parametri per la classificazione binaria - Stima del reddito per adulti | Usare gli iperparametri del modello di ottimizzazione per trovare iperparametri ottimali per creare un classificatore binario. |
Set di dati
Quando si crea una nuova pipeline nella finestra di progettazione di Azure Machine Learning, per impostazione predefinita è inclusa una serie di set di dati di esempio. Questi set di dati di esempio vengono usati dalle pipeline di esempio nella home page della finestra di progettazione.
I set di dati di esempio sono disponibili nella categoria Set di dati-Esempi. In particolare, è possibile trovarli nella tavolozza dei componenti a sinistra dell'area di disegno della finestra di progettazione. Per usare uno qualsiasi di questi set di dati in una pipeline personalizzata, trascinarlo nell'area di disegno.
| Nome del set di dati | Descrizione del set di dati |
|---|---|
| Adult Census Income Binary Classification dataset | Subset del database relativo al censimento del 1994, che usa adulti lavoratori di età superiore ai 16 anni con un indice di reddito adeguato di > 100. Utilizzo: classificare le persone usando i dati demografici per prevedere se una persona ha un guadagno superiore a 50.000 dollari all'anno. Ricerca correlata: Kohavi, R., Becker, B., (1996). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science |
| Automobile price data (Raw) | Informazioni sulle automobili in base a marchio e modello, inclusi il prezzo, funzionalità quali il numero di cilindri e il consumo di carburante, oltre a un punteggio relativo al rischio assicurativo. Il punteggio di rischio viene inizialmente associato al prezzo dell'automobile e quindi adeguato in base al rischio effettivo in un processo noto agli attuari come simbolizzazione. Un valore pari a +3 indica che l'automobile è rischiosa e un valore pari a -3 indica che è probabilmente sicura. Utilizzo: prevedere il punteggio di rischio in base alle funzionalità, usando la regressione o la classificazione multivariata. Ricerca correlata: Schlimmer, J.C. (1987). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science. |
| CRM Appetency Labels Shared | Etichette dalla competizione KDD Cup 2009 di previsione delle relazioni con i clienti (orange_small_train_appetency.labels). |
| CRM Churn Labels Shared | Etichette dalla competizione KDD Cup 2009 di previsione delle relazioni con i clienti (orange_small_train_churn.labels). |
| CRM Dataset Shared | Questi dati vengono dalla competizione KDD Cup 2009 di previsione delle relazioni con i clienti (orange_small_train.data.zip). Il set di dati contiene 50.000 clienti della società di telecomunicazioni francese Orange. Ogni cliente dispone di 230 elementi resi anonimi, 190 dei quali numerici e 40 categorici. Gli elementi sono molto sparsi. |
| CRM Upselling Labels Shared | Etichette dalla competizione KDD Cup 2009 di previsione delle relazioni con i clienti (orange_large_train_upselling.labels |
| Flight Delays Data | Dati relativi alle prestazioni nel tempo dei voli passeggeri ottenuti dalla raccolta dati TranStats del Dipartimento dei trasporti degli Stati Uniti (On-Time). Il set di dati copre il periodo aprile-ottobre 2013. Prima del caricamento nella finestra di progettazione, il set di dati è stato elaborato come segue: - Il set di dati è stato filtrato in modo da coprire solo i 70 aeroporti più trafficati degli Stati Uniti continentali - I voli cancellati sono stati etichettati in modo da indicare un ritardo superiore a 15 minuti - I voli deviati sono stati esclusi - Sono state selezionate le colonne seguenti: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| German Credit Card UCI dataset | Set di dati UCI Statlog (German Credit Card) (Statlog+German+Credit+Data), con l'uso del file german.data. Il set di dati classifica le persone, descritte da un set di attributi, come rischi di credito alti o bassi. Ogni esempio rappresenta una persona. Sono presenti 20 variabili, sia numeriche che relative alle categorie, nonché un'etichetta binaria (il valore del rischio di credito). Le voci che rappresentano un rischio di credito elevato hanno l'etichetta 2, quelle che rappresentano un rischio di credito hanno l'etichetta 1. Classificare erroneamente un cliente come a basso rischio mentre è ad alto rischio implica costi cinque volte più alti. |
| IMDB Movie Titles | Il set di dati contiene informazioni sui film che sono stati valutati nei tweet di Twitter: ID del film nel database IMDB, nome, genere e anno di produzione del film. Il set di dati contiene 17.000 film. Il set di dati è stato introdotto nel documento di S. Dooms, T. De Pessemier e L. Martens. "MovieTweetings: a Movie Rating Dataset Collected From Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013." |
| Classificazioni film | Il set di dati è una versione estesa di quello relativo ai tweet sui film. Il set di dati contiene 170.000 valutazioni di film, estratti da tweet ben strutturati pubblicati su Twitter. Ogni istanza rappresenta un tweet ed è una tupla: ID utente, ID del film nel database IMDB, valutazione, data e ora, numero di preferenze per questo tweet e numero di retweet. Il set di dati è stato messo a disposizione da A. Said, S. Dooms, B. Loni e D. Tikk per Recommender Systems Challenge 2014. |
| Weather Dataset | Le osservazioni meteo sono su base oraria e al suolo e vengono fornite dalla NOAA (dati uniti dal mese di aprile al mese di ottobre 2013). I dati relativi al meteo riguardano le osservazioni effettuate dalle stazioni meteo degli aeroporti nel periodo aprile-ottobre 2013. Prima del caricamento nella finestra di progettazione, il set di dati è stato elaborato come segue: - Gli ID delle stazioni meteo sono stati mappati agli ID degli aeroporti corrispondenti - Le stazioni meteo non associate ai 70 aeroporti più trafficati sono state escluse - La colonna Date è stata suddivisa in colonne Year, Month e Day distinte - Sono state selezionate le seguenti colonne: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Set di dati SP 500 di Wikipedia | I dati sono tratti da articoli di Wikipedia (https://www.wikipedia.org/) su ognuna delle società incluse nell'indice S&P 500 e sono archiviati come dati XML. Prima del caricamento nella finestra di progettazione, il set di dati è stato elaborato come segue: - Estrazione del contenuto di testo per ogni specifica società - Rimozione della formattazione wiki - Rimozione dei caratteri non alfanumerici - Conversione di tutto il testo in minuscolo - Aggiunta delle categorie di società note Tenere presente che per alcune società non sono stati trovati articoli, dunque il numero dei record è inferiore a 500. |
| Restaurant Feature Data | Set di metadati relativi ai ristoranti e alle rispettive caratteristiche, ad esempio tipo di cibo, stile del ristorante e ubicazione. Utilizzo: usare questo set di dati, con altri due set di dati relativi ai ristoranti, per il training e il test di un sistema di raccomandazione. Ricerca correlata: Bache, K. e Lichman, M. (2013). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science. |
| Restaurant Ratings | Include le valutazioni assegnate dagli utenti ai ristoranti in una scala da 0 a 2. Utilizzo: usare questo set di dati, con altri due set di dati relativi ai ristoranti, per il training e il test di un sistema di raccomandazione. Ricerca correlata: Bache, K. e Lichman, M. (2013). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science. |
| Restaurant Customer Data | Set di metadati relativi ai clienti, inclusi dati demografici e preferenze. Utilizzo: usare questo set di dati, con altri due set di dati relativi ai ristoranti, per il training e il test di un sistema di raccomandazione. Ricerca correlata: Bache, K. e Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science. |
Pulire le risorse
Importante
È possibile usare le risorse create come prerequisiti per altre esercitazioni e procedure dettagliate relative ad Azure Machine Learning.
Eliminare tutto
Se non si prevede di usare le risorse create, eliminare l'intero gruppo di risorse per evitare addebiti.
Nel portale di Azure, selezionare Gruppi di risorse nella parte sinistra della finestra.
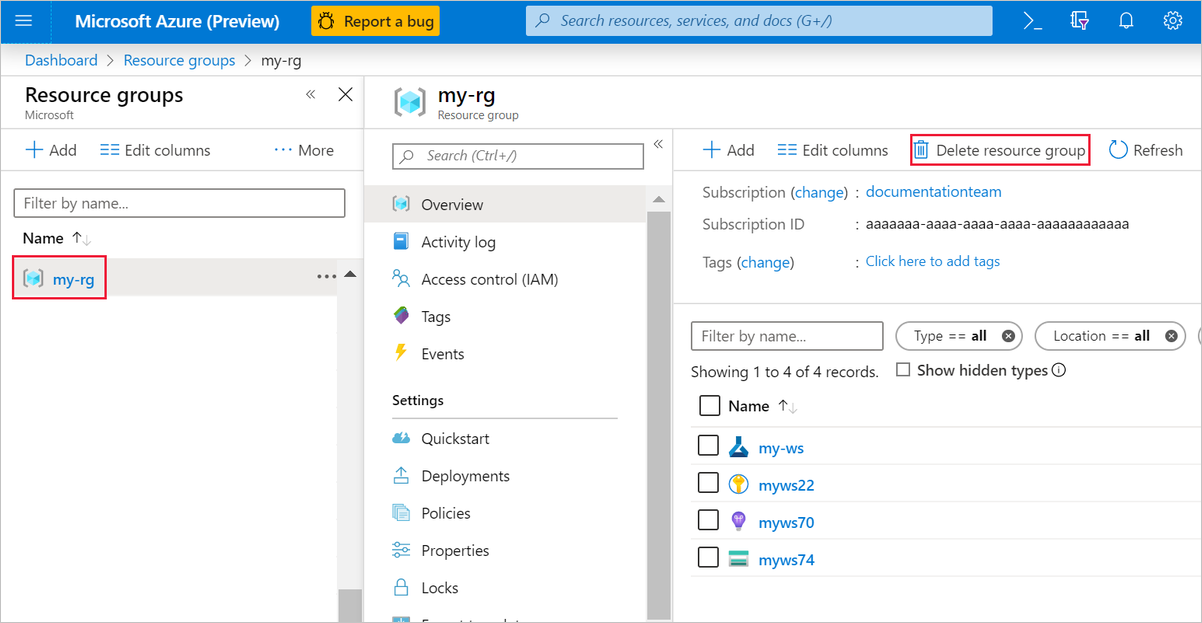
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
Se si elimina il gruppo di risorse, vengono eliminate anche tutte le risorse create nella finestra di progettazione.
Eliminare singole risorse
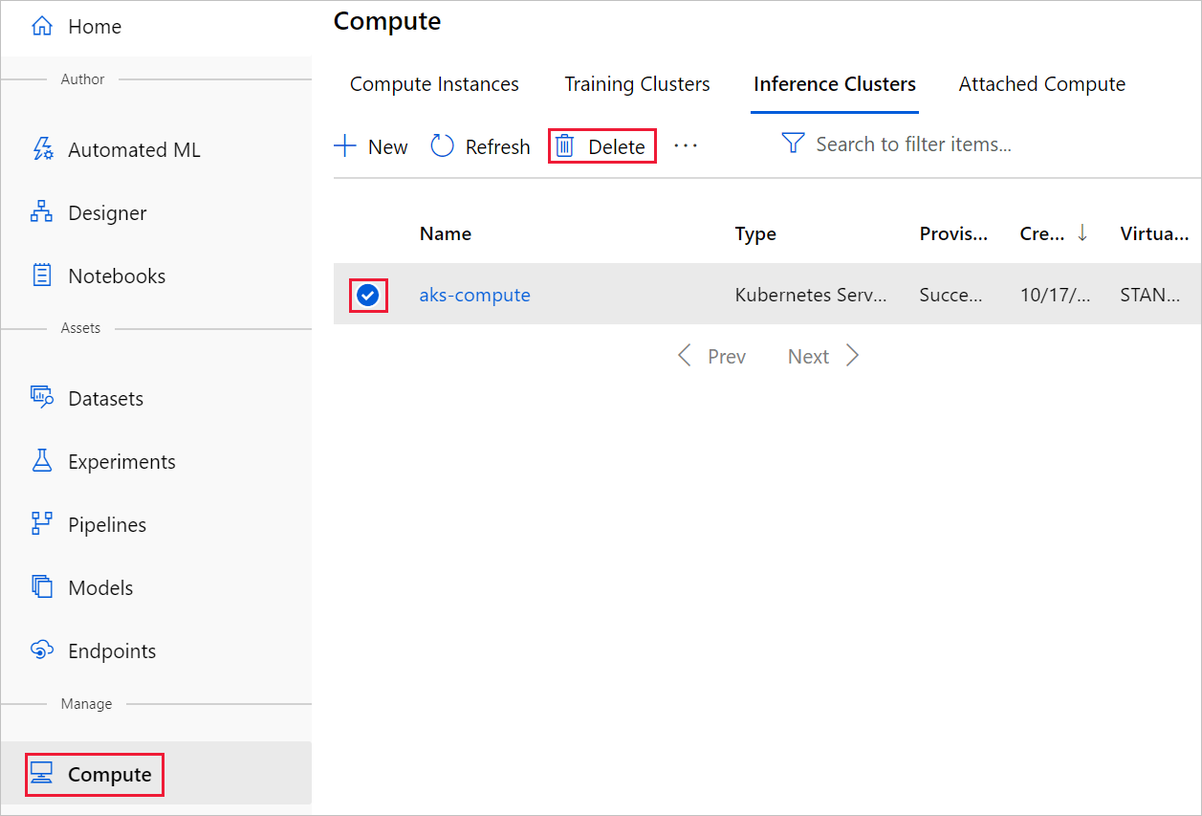
Nella finestra di progettazione in cui è stato creato l'esperimento eliminare le singole risorse selezionandole e quindi selezionando il pulsante Elimina.
La destinazione di calcolo creata qui viene ridimensionata automaticamente a zero nodi quando non viene usata, Questa azione viene intrapresa per ridurre al minimo gli addebiti. Se si vuole eliminare la destinazione di calcolo, eseguire le operazioni seguenti:
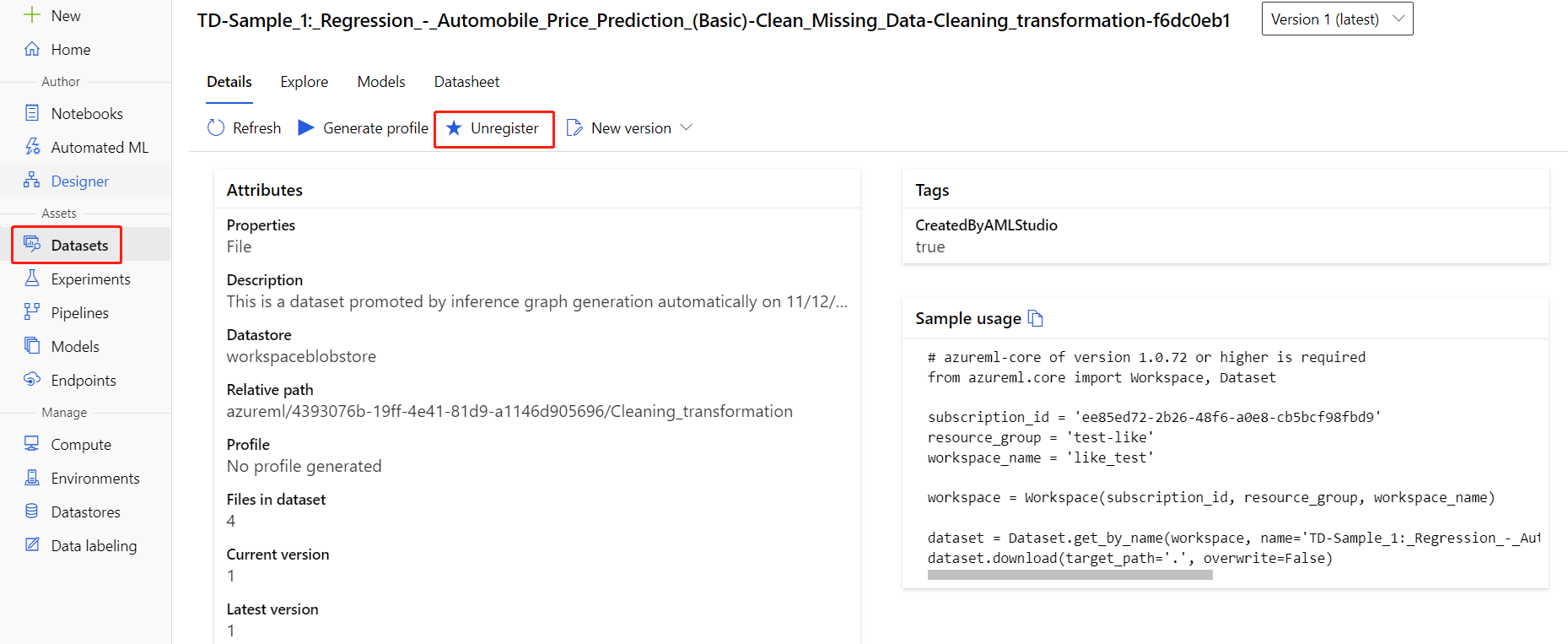
La registrazione dei set di dati nell'area di lavoro può essere annullata selezionando ogni set di dati e quindi Annulla registrazione.
Per eliminare un set di dati, passare all'account di archiviazione tramite il portale di Azure o Azure Storage Explorer ed eliminare manualmente tali asset.
Passaggi successivi
Informazioni sui concetti fondamentali dell'analisi predittiva e dell'apprendimento automatico con l'Esercitazione: stimare il prezzo delle automobili con la finestra di progettazione
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per