Esercitazione 1: Prevedere il rischio di credito - Machine Learning Studio (versione classica)
SI APPLICA A: Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  Azure Machine Learning
Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere leinformazioni sullo spostamento di progetti di Machine Learning da ML Studio (versione classica) ad Azure Machine Learning.
- Scoprire di più su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
In questa esercitazione si esamina il processo di sviluppo di una soluzione di analisi predittiva. Si svilupperà un modello semplice in Machine Learning Studio (versione classica). Si distribuisce quindi il modello come servizio Web di Machine Learning. Questo modello distribuito può creare previsioni usando nuovi dati. Questa esercitazione è la prima di una serie in tre parti.
Si supponga di dover prevedere il rischio di credito di un soggetto in base alle informazioni fornite in una richiesta di credito.
La valutazione del rischio di credito è un problema complesso che verrà tuttavia semplificato con questa esercitazione. Verrà usato come esempio di come creare una soluzione di analisi predittiva usando Machine Learning Studio (versione classica). Per questa soluzione si userà unMachine Learning Studio (versione classica) e un servizio Web di Machine Learning.
In questa esercitazione in tre parti si inizia con dati sul rischio di credito disponibili pubblicamente. Verrà quindi sviluppato e sottoposto a training un modello predittivo. Il modello verrà infine distribuito come servizio Web.
In questa parte dell'esercitazione verranno eseguite queste operazioni:
- Creare un'area di lavoro di Machine Learning Studio (versione classica)
- Caricare i dati esistenti
- Creare un esperimento
È quindi possibile usare questo esperimento per eseguire il training dei modelli nella seconda parte e quindi distribuirli nella terza parte.
Prerequisiti
Questa esercitazione presuppone che Machine Learning Studio (versione classica) sia già stato usato almeno una volta e che alcuni concetti di Machine Learning siano noti, ma non si dà per scontato che l'utente sia un esperto.
Se in precedenza non è mai stato usato Machine Learning Studio (versione classica), è consigliabile iniziare con la guida introduttiva Creare il primo esperimento di data science in Machine Learning Studio (versione classica). Tale esercitazione guida l'utente nel primo utilizzo di Machine Learning Studio (versione classica), offre le nozioni di base su come trascinare moduli nell'esperimento, connetterli, eseguire l'esperimento ed esaminare i risultati.
Suggerimento
È possibile trovare una copia di lavoro dell'esperimento sviluppato in questa esercitazione nella raccolta per intelligenza artificiale di Azure. Passare a Tutorial - Predict credit risk (Esercitazione: prevedere il rischio di credito) e fare clic su Open in Studio (Apri in Studio) per scaricare una copia dell'esperimento nell'area di lavoro di Machine Learning Studio (versione classica).
Creare un'area di lavoro di Machine Learning Studio (versione classica)
Per usare Machine Learning Studio (versione classica), è necessario avere un'area di lavoro di Machine Learning Studio (versione classica). Quest'area di lavoro contiene tutti gli strumenti necessari per la creazione, la gestione e la pubblicazione di esperimenti.
Per creare un'area di lavoro, vedere Creare e condividere un'area di lavoro di Machine Learning Studio (versione classica).
Dopo aver creato l'area di lavoro, aprire Machine Learning Studio (versione classica) (https://studio.azureml.net/Home). Se sono disponibili più aree di lavoro, è possibile selezionare l'area di lavoro nella barra degli strumenti nell'angolo superiore destro della finestra.
Suggerimento
Se si è proprietari dell'area di lavoro, è possibile condividere gli esperimenti su cui si sta lavorando invitando altri utenti nell'area di lavoro. Questa operazione può essere eseguita nella pagina SETTINGS (Impostazioni) di Machine Learning Studio (versione classica). È sufficiente conoscere l'account Microsoft o l'account aziendale di ogni utente.
Nella pagina SETTINGS fare clic su USERS e quindi su INVITE MORE USERS nella parte inferiore della finestra.
Caricare i dati esistenti
Per sviluppare un modello predittivo per il rischio di credito, sono necessari dati che è possibile usare per eseguire il training e quindi testare il modello. Per questa esercitazione verrà usato il set di dati "UCI Statlog (German Credit Data)" del repository di apprendimento automatico della UC Irvine, disponibile al seguente indirizzo:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Verrà usato il file denominato german.data. Scaricare questo file nel disco rigido locale.
Il set di dati german.data contiene le righe di 20 variabili per 1000 clienti che in passato hanno fatto richiesta di un credito. Queste 20 variabili rappresentano l'insieme di funzionalità del set di dati (vettore delle funzionalità) che fornisce le caratteristiche di identificazione di ogni richiedente credito. Una colonna aggiuntiva in ogni riga rappresenta il rischio di credito calcolato del richiedente. In questa colonna 700 richiedenti sono identificati come a basso rischio e 300 ad alto rischio.
Il sito Web UCI presenta una descrizione degli attributi del vettore delle funzionalità per i dati. Questi dati includono informazioni finanziarie, cronologia del credito, stato di occupazione e dati personali. Per ogni richiedente è stata assegnata una valutazione in formato binario per indicare se è a basso o ad alto rischio.
Questi dati verranno usati per eseguire il training di un modello di analisi predittiva. Dopo aver completato questa operazione, il modello potrà accettare un vettore delle funzionalità per un nuovo cliente e prevedere se tale cliente è a basso o ad alto rischio.
Ma ecco un'interessante svolta.
La descrizione del set di dati sul sito Web di UCI include i possibili costi in caso di errata classificazione del rischio di credito di un utente. Se il modello stima un elevato rischio di credito per un utente che è effettivamente a basso rischio, il modello ha eseguito una errata classificazione.
Tuttavia, la classificazione errata inversa è cinque volte più costosa per l'istituto finanziario, ovvero se il modello stima un basso rischio di credito per un utente che in realtà è a elevato rischio di credito.
L'obiettivo è quindi eseguire il training del modello in modo che il costo di quest'ultimo tipo di errata classificazione sia cinque volte superiore rispetto all'altro tipo di errata classificazione.
Un modo semplice per raggiungere questo obiettivo durante il training del modello nell'esperimento consiste nel duplicare (cinque volte) le voci che rappresentano un utente a elevato rischio di credito.
Se il modello classifica un utente erroneamente a basso rischio quando è in realtà a rischio elevato, il modello ripete la stessa errata classificazione cinque volte, una volta per ogni duplicato. e il costo di questo errore aumenterà nei risultati.
Convertire il formato del set di dati
Nel set di dati originale viene usato un formato con valori delimitati da spazi vuoti. Per il funzionamento ottimale di Machine Learning Studio (versione classica) è preferibile usare un file con valori delimitati da virgole (CSV), di conseguenza il set di dati verrà convertito sostituendo gli spazi con le virgole.
Esistono diversi modi per convertire questi dati. Un'opzione consiste nell'usare il comando di Windows PowerShell seguente:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Un'altra opzione consiste nell'usare il comando sed di Unix:
sed 's/ /,/g' german.data > german.csv
In entrambi i casi è stata creata una versione delimitata da virgole dei dati in un file denominato german.csv che è possibile usare nell'esperimento.
Caricare il set di dati in Machine Learning Studio (versione classica)
Dopo aver convertito i dati in formato CSV è necessario caricarli in Machine Learning Studio (versione classica).
Aprire la home page di Machine Learning Studio (versione classica) (https://studio.azureml.net).
Fare clic sul menu
 Nell'angolo superiore sinistro della finestra fare clic su Azure Machine Learning, selezionare Studio e accedere.
Nell'angolo superiore sinistro della finestra fare clic su Azure Machine Learning, selezionare Studio e accedere.Fare clic su +NEW nella parte inferiore della finestra.
Selezionare DATASET.
Selezionare FROM LOCAL FILE.
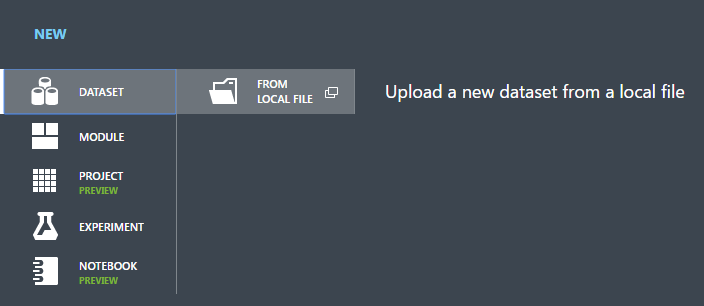
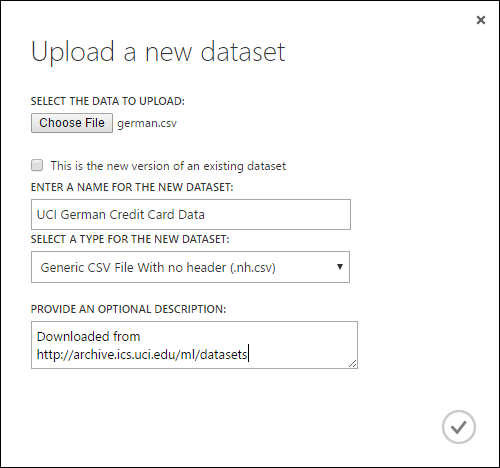
Nella finestra di dialogo Upload a new dataset (Carica un nuovo set di dati) fare clic su Browse (Sfoglia) e trovare il file german.csv creato.
Immettere un nome per il set di dati. Per questa esercitazione, il nome sarà "UCI German Credit Card Data".
Come tipo di dati selezionare Generic CSV File With no header (.nh.csv) .
Aggiungere un'eventuale descrizione.
Fare clic sul segno di spunta OK.
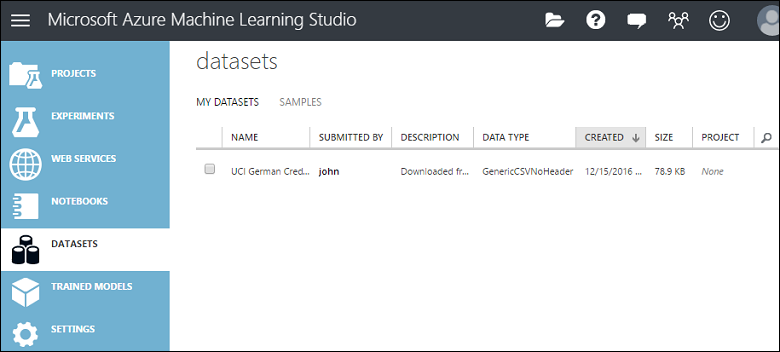
I dati vengono caricati in un modulo del set di dati che è possibile usare in un esperimento.
È possibile gestire i set di dati caricati in Studio (versione classica) facendo clic su sulla scheda DATASETS (Set di dati) a sinistra della finestra di Studio (versione classica).
Per altre informazioni sull'importazione di altri tipi di dati in un esperimento, vedere Importare i dati di training in Machine Learning Studio (versione classica) .
Creare un esperimento
Il passaggio successivo di questa esercitazione consiste nel creare un esperimento in Machine Learning Studio (versione classica) che usa il set di dati caricato.
In Studio (versione classica) fare clic su +NEW (Nuovo) nella parte inferiore della finestra.
Selezionare EXPERIMENTe quindi selezionare "Blank Experiment".
Selezionare il nome dell'esperimento predefinito nella parte superiore dell'area di disegno e denominarlo in modo significativo.

Suggerimento
È buona abitudine completare i campi Summary (Riepilogo) e Description (Descrizione) per l'esperimento nel riquadro Properties (Proprietà). Queste proprietà offrono la possibilità di documentare l'esperimento, in modo che chiunque in seguito lo esamini sia in grado di comprendere gli obiettivi e la metodologia.

Nella tavolozza dei moduli a sinistra dell'area di disegno dell'esperimento, espandere Set di dati salvati.
Trovare il set di dati creato in My Datasets e trascinarlo nell'area di disegno. È possibile trovare il set di dati anche immettendone il nome nella casella Cerca sopra alla tavolozza.
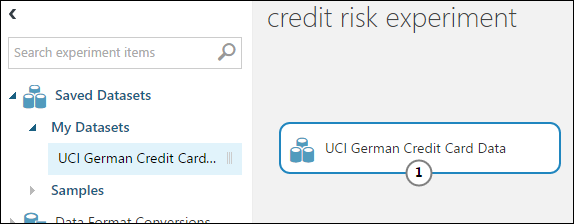
Preparare i dati
È possibile visualizzare le prime 100 righe di dati e alcune informazioni statistiche per l'intero set di dati: fare clic sulla porta di output del set di dati (il circoletto in basso) e selezionare Visualize (Visualizza).
Poiché il file di dati non presentava intestazioni di colonna, Studio (versione classica) ha assegnato intestazioni generiche (Col1, Col2, e così via). Anche se per la creazione di un modello non sono indispensabili intestazioni di colonna precise, queste semplificano l'uso dei dati nell'esperimento. Quando il modello verrà pubblicato in un servizio Web, le intestazioni aiuteranno gli utenti del servizio a identificare le varie colonne.
È possibile aggiungere intestazioni di colonna usando il modulo Edit Metadata (Modifica metadati).
Si usa il modulo Edit Metadata per modificare i metadati associati a un set di dati. In questo caso verrà usato per immettere nomi più descrittivi per le intestazioni di colonna.
Per usare Edit Metadata (Modifica metadati), è necessario specificare prima di tutto le colonne da modificare, in questo caso tutte. Quindi, è necessario specificare l'azione da eseguire su queste colonne, in questo caso la modifica delle intestazioni di colonna.
Nella tavolozza dei moduli digitare "metadati" nella casella Cerca . Nell'elenco dei moduli viene visualizzato il modulo Edit Metadata (Modifica metadati).
Trascinare il modulo Edit Metadata (Modifica metadati) nel canvas e rilasciarlo sotto il set di dati aggiunto in precedenza.
Connettere il set di dati a Edit Metadata (Modifica metadati): fare clic sulla porta di output del set di dati (il circoletto in fondo al set di dati), trascinarla sulla porta di input di Edit Metadata (Modifica metadati) (il circoletto nella parte superiore del modulo), quindi rilasciare il pulsante del mouse. Il set di dati e il modulo resteranno connessi anche se vengono spostati in un'altra posizione nell'area di disegno.
L'esperimento avrà ora un aspetto analogo al seguente:
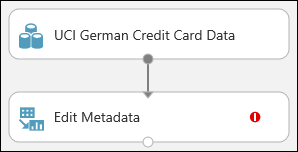
Il punto esclamativo rosso indica che le proprietà di questo modulo non sono ancora state impostate. Questa operazione verrà eseguita più avanti.
Suggerimento
È possibile aggiungere un commento a un modulo facendo doppio clic sul modulo e immettendo del testo. In tal modo sarà possibile individuare subito l'operazione eseguita dal modulo nell'esperimento. In questo caso, fare doppio clic sul modulo Edit Metadata (Modifica metadati) e digitare il commento "Add column headings" (Aggiungere intestazioni di colonna). Fare clic in un punto qualsiasi dell'area di disegno per chiudere la casella di testo. Per visualizzare il commento, fare clic sulla freccia rivolta verso il basso nel modulo.
Selezionare Edit Metadata (Modifica metadati) e nel riquadro Properties (Proprietà) a destra del canvas fare clic su Launch column selector (Avvia selettore colonne).
Nella finestra di dialogo Seleziona colonne selezionare tutte le righe in Colonne disponibili e fare clic > per spostarle in Colonne selezionate. La finestra di dialogo dovrebbe essere simile alla seguente:
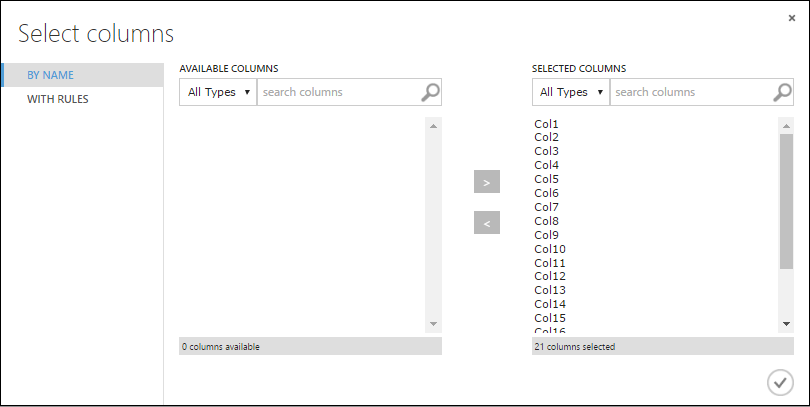
Fare clic sul segno di spunta OK.
Di nuovo nel riquadro Properties (Proprietà) cercare il parametro New column names (Nuovi nomi di colonna). In questo campo immettere un elenco di nomi per le 21 colonne nel set di dati, separati da virgole e nell'ordine delle colonne. È possibile ottenere i nomi di colonna dalla documentazione relativa ai set di dati disponibile sul sito Web UCI, oppure, per praticità, è possibile copiare e incollare l'elenco seguente:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskIl riquadro Proprietà (Proprietà) ha l'aspetto seguente:
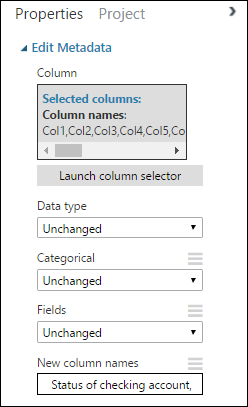
Suggerimento
Se si vuole verificare le intestazioni di colonna, eseguire l'esperimento (fare clic su RUN (ESEGUI) sotto l'area di disegno dell'esperimento). Al termine dell'esecuzione, ovvero quando viene visualizzato un segno di spunta in Edit Metadata (Modifica metadati), fare clic sulla porta di output del modulo Edit Metadata (Modifica metadati) e selezionare Visualize (Visualizza). È possibile visualizzare l'output di ogni modulo nello stesso modo in cui si visualizza lo stato dei dati nel corso dell'esperimento.
Creazione di set di dati di training e di test
Sono necessari alcuni dati per il training e alcuni dati per il test del modello. Nel passaggio successivo dell'esperimento, il set di dati viene suddiviso in due set di dati separati: uno per il training e uno per il test del modello.
A questo scopo viene usato il modulo Split Data (Divisione dati).
Trovare il modulo Split Data (Divisione dati), trascinarlo nel canvas, quindi connetterlo al modulo Edit Metadata (Modifica metadati).
Per impostazione predefinita, il rapporto di suddivisione è impostato su 0,5 e il parametro Suddivisione casuale è impostato. Questo significa che una metà casuale dei dati verrà inviata come output attraverso una porta del modulo Split Data (Divisione dati) e l'altra metà attraverso l'altra. È possibile regolare queste parametri, così come il parametro Random seed (Valore di inizializzazione casuale), per modificare la divisione tra dati di training e dati di test. Per questo esempio, i parametri vengono lasciati invariati.
Suggerimento
La proprietà Fraction of rows in the first output dataset determina la quantità di dati da inviare alla porta di output sinistra. Se ad esempio si imposta il rapporto su 0,7, il 70% dei dati verrà inviato alla porta sinistra e il 30% alla porta destra.
Fare doppio clic sul modulo Split Data (Divisione dati) e immettere il commento, "Training/testing data split 50%" (Divisione dati training/test 50%).
È possibile usare gli output del modulo Split Data (Divisione dati) nel modo preferito, ma in questo caso si sceglie di usare l'output sinistro per i dati di training e quello destro per i dati di test.
Come indicato nel passaggio precedente, il costo di un'errata classificazione come basso di un rischio di credito elevato è cinque volte maggiore del costo di un'errata classificazione come alto di un rischio di credito basso. Tenendo conto di questa indicazione, viene generato un nuovo set di dati che rifletta questa funzione di costo. Nel nuovo set di dati ogni esempio a rischio elevato viene replicato cinque volte, mentre ogni esempio a basso rischio non viene replicato.
Ciò è ottenibile usando il codice R:
Trovare e trascinare il modulo Execute R Script (Esecuzione script R) nel canvas dell'esperimento.
Connettere la porta di output sinistra del modulo Split Data (Divisione dati) alla prima porta di input ("Dataset1") del modulo Execute R Script (Esecuzione script R).
Fare doppio clic sul modulo Execute R Script (Esecuzione script R) e immettere il commento "Set cost adjustment" (Impostare rettifica costo).
Nel riquadro Properties (Proprietà) eliminare il testo predefinito nel parametro R Script (Script R) e immettere questo script:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")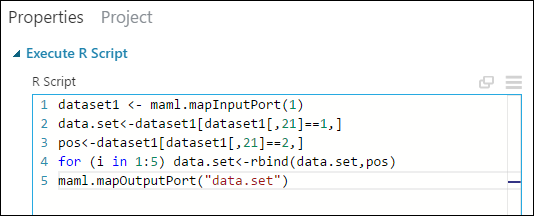
È necessario eseguire la stessa operazione di replica per ogni output del modulo Split Data (Divisione dati) in modo che i dati di training e di test abbiano la stessa rettifica del costo. A questo scopo, il modulo Execute R Script (Esecuzione script R) appena creato verrà duplicato e connesso all'altra porta di output del modulo Split Data (Divisione dati).
Fare clic con il pulsante destro del mouse sul modulo Execute R Script (Esecuzione script R) e scegliere Copy (Copia).
Fare clic con il pulsante destro del mouse nell'area di disegno dell'esperimento, quindi selezionare Incolla.
Trascinare il nuovo modulo nella posizione scelta e quindi connettere la porta di output destra del modulo Split Data (Divisione dati) alla prima porta di input di questo nuovo modulo Execute R Script (Esecuzione script R).
Fare clic su Run (Esegui) nella parte inferiore dell'area di disegno.
Suggerimento
La copia del modulo Esecuzione script R contiene lo stesso script contenuto nel modulo originale. Quando si copia e incolla un modulo sull'area di disegno, la copia conserva tutte le proprietà dell'originale.
L'esperimento avrà ora un aspetto analogo al seguente:
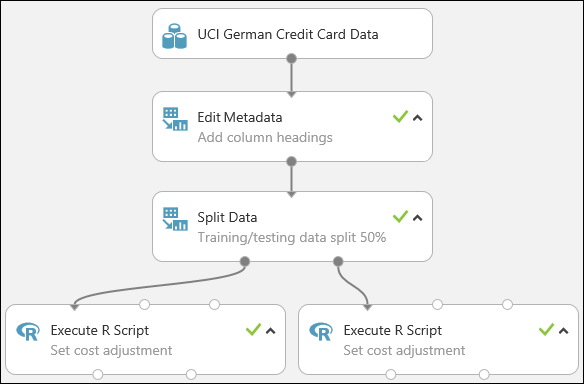
Per altre informazioni sull'uso di script R negli esperimenti, vedere Estendere l'esperimento con R.
Pulire le risorse
Se le risorse create in questo articolo non sono più necessarie, eliminarle per evitare di incorrere in eventuali addebiti. Per altre informazioni, vedere l'articolo Esportare ed eliminare i dati utente interni al prodotto.
Passaggi successivi
In questa esercitazione sono stati completati i passaggi seguenti:
- Creare un'area di lavoro di Machine Learning Studio (versione classica)
- Caricare i dati esistenti nell'area di lavoro
- Creare un esperimento
A questo punto si è pronti per il training e la valutazione dei modelli per questi dati.