Che cos'è la finestra di progettazione (v1) in Azure Machine Learning?
La finestra di progettazione di Azure Machine Learning è un'interfaccia basata su trascinamento della selezione usata per eseguire il training e la distribuzione dei modelli nello studio di Azure Machine Learning. Questo articolo descrive le attività che è possibile eseguire nella finestra di progettazione.
Importante
La finestra di progettazione in Azure Machine Learning supporta due tipi di pipeline che usano componenti predefiniti classici (v1) o personalizzati (v2). I due tipi di componenti non sono compatibili all'interno delle pipeline e la finestra di progettazione v1 non è compatibile con l'interfaccia della riga di comando v2 e l'SDK v2. Questo articolo si applica alle pipeline che usano componenti predefiniti classici (v1).
I componenti predefiniti classici (v1) includono attività tipiche di elaborazione dei dati e apprendimento automatico, tra cui regressione e classificazione. Azure Machine Learning continua a supportare i componenti predefiniti classici esistenti, ma non vengono aggiunti nuovi componenti predefiniti. La distribuzione di componenti predefiniti classici (v1) non supporta inoltre gli endpoint online gestiti (v2).
I componenti personalizzati (v2) consentono di eseguire il wrapping del codice come componenti, abilitando quindi la condivisione tra aree di lavoro e la creazione senza problemi tra le interfacce di studio di Azure Machine Learning, l'interfaccia della riga di comando v2 e l'interfaccia di SDK v2. È consigliabile usare componenti personalizzati per i nuovi progetti, perché sono compatibili con Azure Machine Learning v2 e continuano a ricevere nuovi aggiornamenti. Per altre informazioni sui componenti personalizzati e sulla finestra di progettazione (v2), vedere Finestra di progettazione di Azure Machine Learning (v2).
La GIF animata seguente illustra come creare visivamente una pipeline nella finestra di progettazione trascinando e rilasciando gli asset e collegandoli.

Per informazioni sui componenti disponibili nella finestra di progettazione, vedere Informazioni di riferimento sull'algoritmo e sui componenti. Per iniziare a usare la finestra di progettazione, vedere Esercitazione: eseguire il training di un modello di regressione senza codice.
Training e distribuzione dei modelli
La finestra di progettazione usa l'area di lavoro di Azure Machine Learning per organizzare le risorse condivise, ad esempio:
- Pipeline
- Dati
- Risorse di calcolo
- Modelli registrati
- Processi della pipeline pubblicati
- Endpoint in tempo reale
Il diagramma seguente illustra come usare la finestra di progettazione per creare un flusso di lavoro di apprendimento automatico end-to-end. È possibile eseguire il training, testare e distribuire modelli, tutti nell'interfaccia della finestra di progettazione.
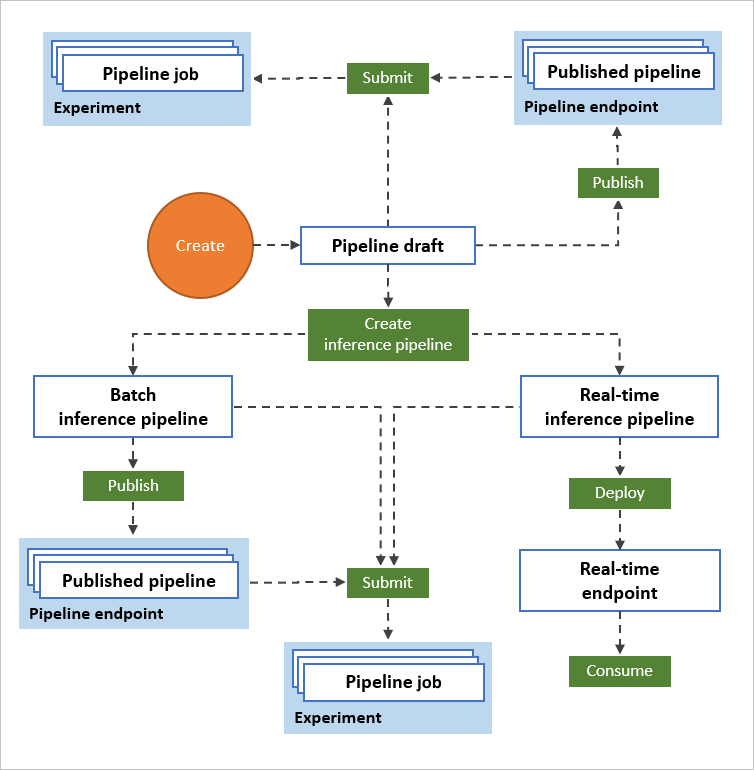
- Trascinare e rilasciare asset di dati e componenti nell'area di disegno visiva della finestra di progettazione e connettere i componenti per creare una bozza di pipeline.
- Inviare un processo della pipeline che usa le risorse di calcolo nell'area di lavoro Azure Machine Learning.
- Convertire le pipeline di training in pipeline di inferenza.
- Pubblicare le pipeline in un endpoint di pipeline REST per inviare nuove pipeline eseguite con parametri e asset di dati diversi.
- Pubblicare una pipeline di training per riusare una singola pipeline per il training di più modelli durante la modifica di parametri e asset di dati.
- Pubblicare una pipeline di inferenza batch per eseguire stime sui nuovi dati usando un modello precedentemente sottoposto a training.
- Distribuire una pipeline di inferenza in tempo reale in un endpoint online per eseguire stime sui nuovi dati in tempo reale.
Dati
Un asset di dati di Machine Learning semplifica l'accesso e l'uso dei dati. La finestra di progettazione include diversi asset di dati di esempio per consentire la sperimentazione. È possibile registrare più asset di dati in base alle necessità.
Componenti
Un componente è un algoritmo che è possibile eseguire sui dati. La finestra di progettazione include numerosi componenti, dalle funzioni di ingresso dei dati ai processi di training, assegnazione punteggio e convalida.
Un componente può avere parametri usati per configurare gli algoritmi interni del componente. Quando si seleziona un componente nell'area di disegno, i parametri del componente e altre impostazioni vengono visualizzati in un riquadro delle proprietà a destra dell'area di disegno. È possibile modificare i parametri e impostare le risorse di calcolo per i singoli componenti in tale riquadro.
Per altre informazioni sulla libreria degli algoritmi di Machine Learning disponibili, vedere Informazioni di riferimento su algoritmi e componenti. Per informazioni sulla scelta di un algoritmo, vedere la Scheda di riferimento rapido sull'algoritmo di Azure Machine Learning.
Pipelines
Una pipeline è costituita da asset di dati e componenti analitici che vengono connessi. Le pipeline consentono di riutilizzare il lavoro e organizzare i progetti.
Le pipeline hanno molti usi. È possibile creare pipeline che consentono di:
- Eseguire il training di un singolo modello.
- Eseguire il training di più modelli.
- Generare stime in tempo reale o in batch.
- Pulire solo i dati.
Bozze della pipeline
Quando si modifica una pipeline nella finestra di progettazione, lo stato viene salvato come bozza di pipeline. È possibile modificare una bozza di pipeline in qualsiasi momento aggiungendo o rimuovendo moduli, configurando le destinazioni di calcolo o configurando i parametri.
Una pipeline valida presenta le caratteristiche seguenti:
- Gli asset di dati possono connettersi solo ai componenti.
- I componenti possono connettersi solo agli asset di dati o ad altri componenti.
- Tutte le porte di input per i componenti devono avere una connessione al flusso di dati.
- Tutti i parametri necessari per ogni componente devono essere impostati.
Quando si è pronti per eseguire la bozza di pipeline, salvare la pipeline e inviare un processo della pipeline.
Processi della pipeline
Ogni volta che si esegue una pipeline, la configurazione della pipeline e i relativi risultati vengono archiviati nell'area di lavoro come processo della pipeline. I processi della pipeline vengono raggruppati in esperimenti per organizzare la cronologia dei processi.
È possibile tornare a un processo della pipeline per esaminarlo a scopo di risoluzione dei problemi o di controllo. Clonare un processo della pipeline per creare una nuova bozza di pipeline da modificare.
Risorse di calcolo
Le destinazioni di calcolo sono collegate all'area di lavoro di Azure Machine Learning in Studio di Azure Machine Learning. Usare le risorse di calcolo dall'area di lavoro per eseguire la pipeline e ospitare i modelli distribuiti come endpoint online o endpoint della pipeline (per l'inferenza batch). Le destinazioni di calcolo supportate sono le seguenti:
| Destinazione del calcolo | Formazione | Distribuzione |
|---|---|---|
| Ambiente di calcolo di Azure Machine Learning | ✓ | |
| Servizio Azure Kubernetes (AKS) | ✓ |
Distribuzione
Per eseguire l'inferenza in tempo reale, è necessario distribuire una pipeline come endpoint online. L'endpoint online crea un'interfaccia tra un'applicazione esterna e il modello di punteggio. Un endpoint è basato su REST, un'opzione di architettura diffusa per progetti di programmazione Web. Una chiamata a un endpoint online restituisce i risultati della stima all'applicazione in tempo reale.
Per effettuare una chiamata a un endpoint online, passare una chiave API creata al momento della distribuzione dell'endpoint. Gli endpoint online devono essere distribuiti in un cluster del servizio Azure Kubernetes. Per informazioni su come distribuire il proprio modello, vedere Esercitazione: distribuire un modello di Machine Learning con la finestra di progettazione.
Pagina
È anche possibile pubblicare una pipeline in un endpoint della pipeline. Analogamente a un endpoint online, un endpoint della pipeline consente di inviare i nuovi processi delle pipeline da applicazioni esterne usando le chiamate REST. Non è tuttavia possibile inviare o ricevere dati in tempo reale tramite un endpoint della pipeline.
Gli endpoint della pipeline pubblicati sono flessibili e possono essere usati per eseguire il training o ripetere il training dei modelli, eseguire l'inferenza batch o elaborare nuovi dati. È possibile pubblicare più pipeline in un singolo endpoint della pipeline e specificare quale versione della pipeline eseguire.
Una pipeline pubblicata viene eseguita nelle risorse di calcolo definite nella bozza di pipeline per ogni componente. La finestra di progettazione crea lo stesso oggetto PublishedPipeline dell'SDK.
Contenuto correlato
- Per informazioni sui concetti fondamentali dell'analisi predittiva e dell'apprendimento automatico, vedere l'Esercitazione: Stimare il prezzo delle automobili con la finestra di progettazione.
- Informazioni su come modificare gli esempi della finestra di progettazione esistenti per adattarli alle proprie esigenze.