Esercitazione: Caricare dati e eseguire il training di un modello (SDK v1, parte 3 di 3)
SI APPLICA A: Azureml di Python SDK v1
Azureml di Python SDK v1
Questa esercitazione illustra come caricare e usare i propri dati per eseguire il training dei modelli di Machine Learning in Azure Machine Learning. Questa esercitazione fa parte 3 di una serie di esercitazioni in tre parti.
Nella parte 2: Eseguire il training di un modello, è stato eseguito il training di un modello nel cloud usando i dati di esempio da PyTorch. Sono stati scaricati anche i dati tramite il metodo nell'API torchvision.datasets.CIFAR10 PyTorch. In questa esercitazione si useranno i dati scaricati per apprendere il flusso di lavoro per l'uso dei propri dati in Azure Machine Learning.
In questa esercitazione:
- Caricare i dati in Azure.
- Creare uno script di controllo.
- Acquisire i nuovi concetti di Azure Machine Learning (passaggio di parametri, set di dati, archivi dati).
- Inviare ed eseguire lo script di training.
- Visualizzare l'output del codice nel cloud.
Prerequisiti
Sono necessari i dati scaricati nell'esercitazione precedente. Assicurarsi di aver completato questi passaggi:
Modificare lo script di training
A questo momento è disponibile lo script di training (get-started/src/training.py) in esecuzione in Azure Machine Learning e è possibile monitorare le prestazioni del modello. Ora lo script di training verrà parametrizzato introducendo gli argomenti. L'uso degli argomenti consente di confrontare facilmente iperparametri diversi.
Lo script di training è attualmente impostato per scaricare il set di dati CIFAR10 in ogni esecuzione. Il codice di Python seguente è stato modificato per leggere i dati da una directory.
Nota
L'uso di argparse parametrizza lo script.
Aprire train.py e sostituirlo con questo codice:
import os import argparse import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run run = Run.get_context() if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_path', type=str, help='Path to the training data' ) parser.add_argument( '--learning_rate', type=float, default=0.001, help='Learning rate for SGD' ) parser.add_argument( '--momentum', type=float, default=0.9, help='Momentum for SGD' ) args = parser.parse_args() print("===== DATA =====") print("DATA PATH: " + args.data_path) print("LIST FILES IN DATA PATH...") print(os.listdir(args.data_path)) print("================") # prepare DataLoader for CIFAR10 data transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) trainset = torchvision.datasets.CIFAR10( root=args.data_path, train=True, download=False, transform=transform, ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD( net.parameters(), lr=args.learning_rate, momentum=args.momentum, ) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 run.log('loss', loss) # log loss metric to AML print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Salvare il file. Chiudere la scheda se si desidera.
Informazioni sulle modifiche al codice
Il codice in train.py ha usato la libreria argparse per configurare data_path, learning_rate e momentum.
# .... other code
parser = argparse.ArgumentParser()
parser.add_argument('--data_path', type=str, help='Path to the training data')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Learning rate for SGD')
parser.add_argument('--momentum', type=float, default=0.9, help='Momentum for SGD')
args = parser.parse_args()
# ... other code
Lo script train.py è stato anche adattato per aggiornare l'utilità di ottimizzazione per l'uso di parametri definiti dall'utente:
optimizer = optim.SGD(
net.parameters(),
lr=args.learning_rate, # get learning rate from command-line argument
momentum=args.momentum, # get momentum from command-line argument
)
Caricare i dati in Azure
Per eseguire questo script in Azure Machine Learning, è necessario rendere i dati di training disponibili in Azure. L'area di lavoro di Azure Machine Learning include un archivio dati predefinito. Si tratta di un account di archiviazione BLOB di Azure in cui è possibile archiviare i dati di training.
Nota
Azure Machine Learning consente di connettere altri archivi dati basati sul cloud in cui vengono archiviati i dati. Per altri dettagli, vedere la documentazione degli archivi dati.
Creare un nuovo script di controllo Python nella cartella get-started (assicurarsi che sia avviato, non nella cartella /src). Assegnare allo script upload-data.py e copiare questo codice nel file:
# upload-data.py from azureml.core import Workspace from azureml.core import Dataset from azureml.data.datapath import DataPath ws = Workspace.from_config() datastore = ws.get_default_datastore() Dataset.File.upload_directory(src_dir='data', target=DataPath(datastore, "datasets/cifar10") )Il valore
target_pathspecifica il percorso dell'archivio dati in cui verranno caricati i dati CIFAR10.Suggerimento
Anche se si usa Azure Machine Learning per caricare i dati, è possibile usare Azure Storage Explorer per caricare file ad hoc. Se è necessario uno strumento di estrazione, trasformazione e caricamento, è possibile usare Azure Data Factory per inserire i dati in Azure.
Selezionare Salva ed eseguire script nel terminale per eseguire lo script upload-data.py .
Verrà visualizzato l'output standard seguente:
Uploading ./data\cifar-10-batches-py\data_batch_2 Uploaded ./data\cifar-10-batches-py\data_batch_2, 4 files out of an estimated total of 9 . . Uploading ./data\cifar-10-batches-py\data_batch_5 Uploaded ./data\cifar-10-batches-py\data_batch_5, 9 files out of an estimated total of 9 Uploaded 9 files
Creare uno script di controllo
Come è stato fatto in precedenza, creare un nuovo script di controllo Python denominato run-pytorch-data.py nella cartella get-started :
# run-pytorch-data.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
from azureml.core import Dataset
if __name__ == "__main__":
ws = Workspace.from_config()
datastore = ws.get_default_datastore()
dataset = Dataset.File.from_files(path=(datastore, 'datasets/cifar10'))
experiment = Experiment(workspace=ws, name='day1-experiment-data')
config = ScriptRunConfig(
source_directory='./src',
script='train.py',
compute_target='cpu-cluster',
arguments=[
'--data_path', dataset.as_named_input('input').as_mount(),
'--learning_rate', 0.003,
'--momentum', 0.92],
)
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print("Submitted to compute cluster. Click link below")
print("")
print(aml_url)
Suggerimento
Se è stato usato un nome diverso quando è stato creato il cluster di calcolo, assicurarsi di modificare anche il nome nel codice compute_target='cpu-cluster' .
Informazioni sulle modifiche al codice
Lo script di controllo è simile a quello della terza parte di questa serie, con le nuove righe seguenti:
dataset = Dataset.File.from_files( ... )
Un set di dati viene usato per fare riferimento ai dati caricati in archiviazione BLOB di Azure. I set di dati sono un livello di astrazione superiore a quello dei dati e sono progettati per migliorare l'affidabilità e l'attendibilità.
config = ScriptRunConfig(...)
ScriptRunConfig è stato modificato in modo da includere un elenco di argomenti che verranno passati in train.py. L'argomento dataset.as_named_input('input').as_mount() indica che la directory specificata verrà montata nella destinazione di calcolo.
Inviare l'esecuzione ad Azure Machine Learning
Selezionare Salva ed eseguire script nel terminale per eseguire lo script di run-pytorch-data.py . Questa esecuzione eseguirà il training del modello nel cluster di calcolo usando i dati caricati.
Questo codice stamperà un URL nell'esperimento in Azure Machine Learning Studio. Passando a tale collegamento, sarà possibile vedere il codice in esecuzione.
Nota
È possibile che vengano visualizzati alcuni avvisi che iniziano con Errore durante il caricamento di azureml_run_type_providers.... È possibile ignorare questi avvisi. Usare il collegamento nella parte inferiore di questi avvisi per visualizzare l'output.
Esaminare il file di log
In studio passare al processo di esperimento (selezionando l'output dell'URL precedente) seguito da Output e log. Selezionare il file std_log.txt. Scorrere verso il basso il file di log fino a visualizzare l'output seguente:
Processing 'input'.
Processing dataset FileDataset
{
"source": [
"('workspaceblobstore', 'datasets/cifar10')"
],
"definition": [
"GetDatastoreFiles"
],
"registration": {
"id": "XXXXX",
"name": null,
"version": null,
"workspace": "Workspace.create(name='XXXX', subscription_id='XXXX', resource_group='X')"
}
}
Mounting input to /tmp/tmp9kituvp3.
Mounted input to /tmp/tmp9kituvp3 as folder.
Exit __enter__ of DatasetContextManager
Entering Job History Context Manager.
Current directory: /mnt/batch/tasks/shared/LS_root/jobs/dsvm-aml/azureml/tutorial-session-3_1600171983_763c5381/mounts/workspaceblobstore/azureml/tutorial-session-3_1600171983_763c5381
Preparing to call script [ train.py ] with arguments: ['--data_path', '$input', '--learning_rate', '0.003', '--momentum', '0.92']
After variable expansion, calling script [ train.py ] with arguments: ['--data_path', '/tmp/tmp9kituvp3', '--learning_rate', '0.003', '--momentum', '0.92']
Script type = None
===== DATA =====
DATA PATH: /tmp/tmp9kituvp3
LIST FILES IN DATA PATH...
['cifar-10-batches-py', 'cifar-10-python.tar.gz']
Notare:
- Azure Machine Learning ha montato automaticamente l'archiviazione BLOB nel cluster di calcolo.
dataset.as_named_input('input').as_mount()usato nello script di controllo viene risolto nel punto di montaggio.
Pulire le risorse
Se si prevede di continuare ora a un'altra esercitazione o di avviare i propri processi di training, passare a Passaggi successivi.
Arrestare l'istanza di calcolo
Se non lo si userà ora, arrestare l'istanza di calcolo:
- In studio selezionare Calcolo a sinistra.
- Nelle schede principali selezionare Istanze di calcolo
- Selezionare l'istanza di calcolo nell'elenco.
- Nella barra degli strumenti superiore selezionare Arresta.
Eliminare tutte le risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se non si prevede di usare alcuna delle risorse create, eliminarle in modo da non comportare addebiti:
Nel portale di Azure fare clic su Gruppi di risorse all'estrema sinistra.
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
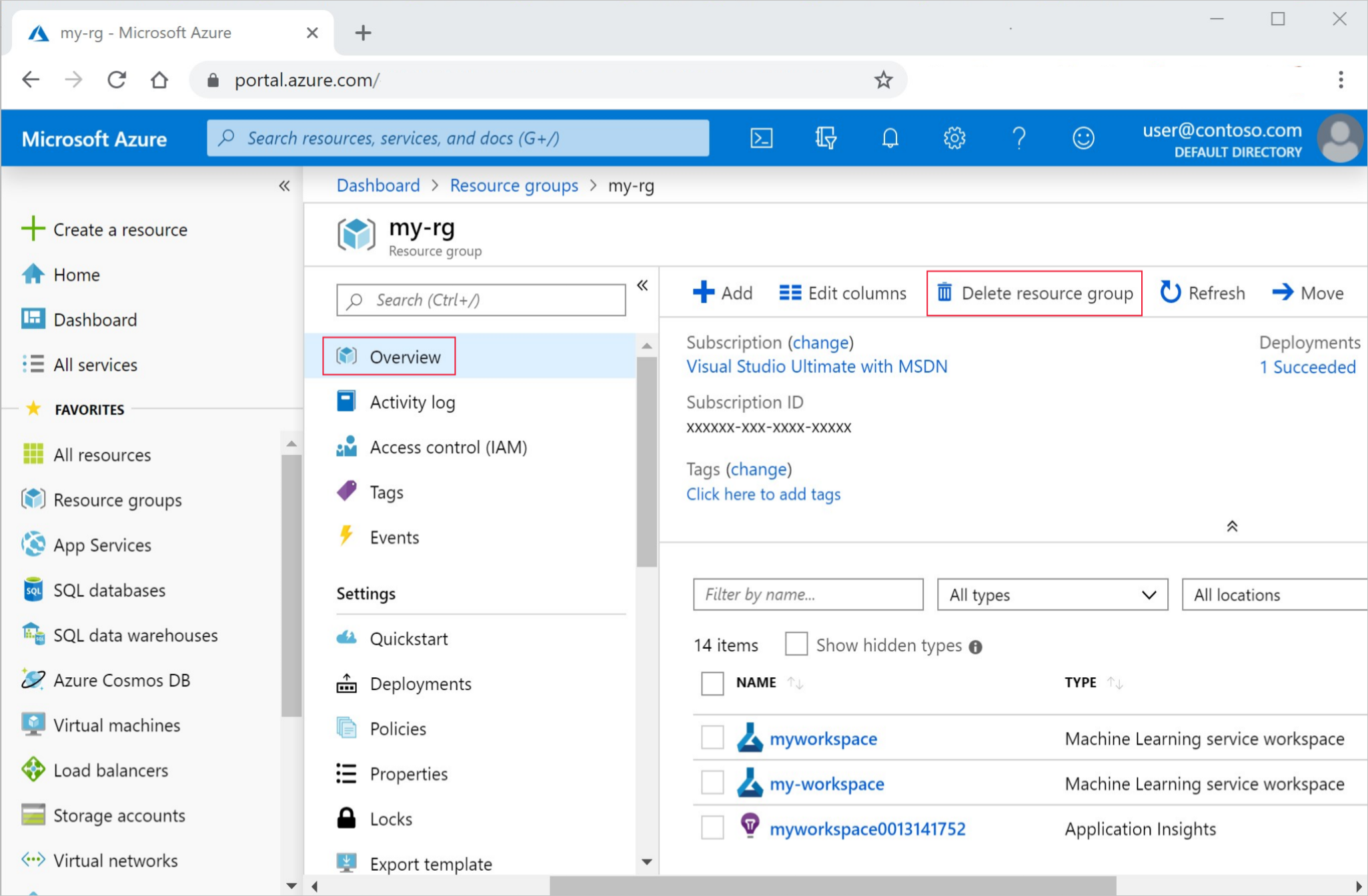
Immettere il nome del gruppo di risorse. Selezionare Elimina.
È anche possibile mantenere il gruppo di risorse ma eliminare una singola area di lavoro. Visualizzare le proprietà dell'area di lavoro e selezionare Elimina.
Passaggi successivi
In questa esercitazione si è visto come caricare i dati in Azure usando Datastore. L'archivio dati è stato usato come risorsa di archiviazione nel cloud per l'area di lavoro, fornendo uno spazio di archiviazione permanente e flessibile in cui conservare i dati.
È stato illustrato come modificare lo script di training per accettare un percorso dati tramite la riga di comando. DatasetUsando , è stato possibile montare una directory nel processo remoto.
Ora che è stato creato un modello, vedere: