Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Gli agenti di intelligenza artificiale stanno trasformando il modo in cui le applicazioni interagiscono con i dati combinando modelli di linguaggio di grandi dimensioni con strumenti e database esterni. Gli agenti consentono l'automazione di flussi di lavoro complessi, migliorano l'accuratezza del recupero delle informazioni e facilitano le interfacce del linguaggio naturale ai database.
Questo articolo illustra come creare agenti di intelligenza artificiale intelligenti in grado di cercare e analizzare i dati in Database di Azure per PostgreSQL. Illustra la configurazione, l'implementazione e il test usando un assistente alla ricerca legale come esempio.
Che cosa sono gli agenti di intelligenza artificiale
Gli agenti IA vanno oltre i semplici chatbot in quanto combinano i modelli linguistici di grandi dimensioni (LLM) con strumenti e database esterni. A differenza dei sistemi LLM autonomi o di generazione aumentata del recupero (RAG) standard, gli agenti IA possono:
- Piano: suddividere le attività complesse in passaggi più piccoli e sequenziali.
- Usare gli strumenti: usare API, esecuzione del codice e sistemi di ricerca per raccogliere informazioni o eseguire azioni.
- Percezione: comprendere ed elaborare gli input da varie origini dati.
- Ricorda: archiviare e richiamare le interazioni precedenti per un processo decisionale migliore.
Connettendo gli agenti di intelligenza artificiale ai database come Database di Azure per PostgreSQL, gli agenti possono fornire risposte più accurate e con riconoscimento del contesto in base ai dati. Gli agenti di intelligenza artificiale si estendono oltre la conversazione umana di base per eseguire attività basate sul linguaggio naturale. Queste attività richiedono tradizionalmente la logica codificata. Tuttavia, gli agenti possono pianificare le attività necessarie per l'esecuzione in base al contesto fornito dall'utente.
Implementazione degli agenti IA
L'implementazione degli agenti di intelligenza artificiale con Database di Azure per PostgreSQL prevede l'integrazione di funzionalità avanzate di intelligenza artificiale con funzionalità di database affidabili per creare sistemi intelligenti e con riconoscimento del contesto. Usando strumenti come la ricerca vettoriale, gli incorporamenti e il servizio agente Foundry, gli sviluppatori possono creare agenti che comprendano le query in linguaggio naturale, recuperano i dati pertinenti e forniscono informazioni dettagliate interattive.
Le sezioni seguenti illustrano il processo dettagliato per configurare, configurare e distribuire gli agenti di intelligenza artificiale. Questo processo consente un'interazione senza problemi tra i modelli di intelligenza artificiale e il database PostgreSQL.
Framework
Vari framework e strumenti possono facilitare lo sviluppo e la distribuzione degli agenti IA. Tutti questi framework supportano l'uso di Database di Azure per PostgreSQL come strumento:
Esempio di implementazione
L'esempio di questo articolo usa il servizio Agent per la pianificazione, l'utilizzo degli strumenti e la percezione degli agenti. Usa Database di Azure per PostgreSQL come strumento per le funzionalità di ricerca semantica e di database vettoriali.
Le sezioni seguenti illustrano la creazione di un agente di intelligenza artificiale che aiuta i team legali a cercare casi rilevanti per supportare i clienti nello stato di Washington. Agente:
- Accetta query in linguaggio naturale su situazioni legali.
- Usa la ricerca vettoriale in Database di Azure per PostgreSQL per trovare precedenti del caso pertinenti.
- Analizza e riepiloga i risultati in un formato utile per i professionisti legali.
Prerequisiti
Abilitare e configurare le estensioni
azure_aiepg_vector.Distribuire modelli
gpt-4o-minietext-embedding-small.Installare Visual Studio Code.
Installare l'estensione Python .
Installare Python 3.11.x.
Installare l'interfaccia della riga di comando di Azure (versione più recente).
Annotazioni
Ti servono la chiave e l'endpoint dei modelli distribuiti che hai creato per l'agente.
Come iniziare
Tutti i set di dati di codice e di esempio sono disponibili in questo repository GitHub.
Passaggio 1: Configurare la ricerca vettoriale in Database di Azure per PostgreSQL
Prima di tutto, preparare il database per archiviare e cercare i dati dei casi legali usando incorporamenti vettoriali.
Configurare l'ambiente
Se si usa macOS e Bash, eseguire questi comandi:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Se si usa Windows e PowerShell, eseguire questi comandi:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Se si usa Windows e cmd.exe, eseguire questi comandi:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
Configurare le variabili di ambiente
Creare un .env file con le credenziali:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
Caricare documenti e vettori
Il file Python load_data/main.py funge da punto di ingresso centrale per il caricamento dei dati in Database di Azure per PostgreSQL. Il codice elabora i dati per i casi di esempio, incluse le informazioni sui casi in Washington.
Ecco il file main.py:
- Crea le estensioni necessarie, configura le impostazioni dell'API OpenAI e gestisce le tabelle di database eliminando quelle esistenti e creando nuove per l'archiviazione dei dati del case.
- Legge i dati da un file CSV e lo inserisce in una tabella temporanea e quindi lo elabora e lo trasferisce nella tabella del case principale.
- Aggiunge una nuova colonna per gli embeddings nella tabella dei casi e genera embeddings per le opinioni dei casi usando l'API di OpenAI. Archivia gli incorporamenti nella nuova colonna. Il processo di incorporamento richiede da circa 3 a 5 minuti.
Per avviare il processo di caricamento dei dati, eseguire il comando seguente dalla load_data directory :
python main.py
Ecco l'output di main.py:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
Passaggio 2: Creare uno strumento Postgres per l'agente
Configurare quindi gli strumenti dell'agente di intelligenza artificiale per recuperare i dati da Postgres. Usare quindi Agent Service SDK per connettere l'agente di intelligenza artificiale al database Postgres.
Definire una funzione che l'agente deve chiamare
Iniziare con la definizione di una funzione che l'agente deve chiamare descrivendone la struttura e tutti i parametri necessari in una docstring. Includere tutte le definizioni di funzione in un singolo file , legal_agent_tools.py. È quindi possibile importare il file nello script principale.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
Passaggio 3: Creare e configurare l'agente di intelligenza artificiale con Postgres
Configurare ora l'agente di intelligenza artificiale e integrarlo con lo strumento Postgres. Il file Python src/simple_postgres_and_ai_agent.py funge da punto di ingresso centrale per la creazione e l'uso dell'agente.
Ecco il file simple_postgres_and_ai_agent.py:
- Inizializza l'agente nel progetto Foundry con un modello specifico.
- Aggiunge lo strumento Postgres per la ricerca vettoriale nel database durante l'inizializzazione dell'agente.
- Configura un thread di comunicazione. Questo thread viene usato per inviare messaggi all'agente per l'elaborazione.
- Elabora la query dell'utente usando l'agente e gli strumenti. L'agente può pianificare con gli strumenti per ottenere la risposta corretta. In questo caso d'uso, l'agente chiama lo strumento Postgres in base alla firma della funzione e alla docstring per eseguire una ricerca vettoriale e recuperare i dati pertinenti per rispondere alla domanda.
- Visualizza la risposta dell'agente alla query dell'utente.
Trovare la stringa di connessione del progetto in Foundry
Nel tuo progetto Foundry, trovi la stringa di connessione del progetto dalla pagina di panoramica del progetto. Usare questa stringa per connettere il progetto all'SDK del servizio Agent. Aggiungere questa stringa al .env file.
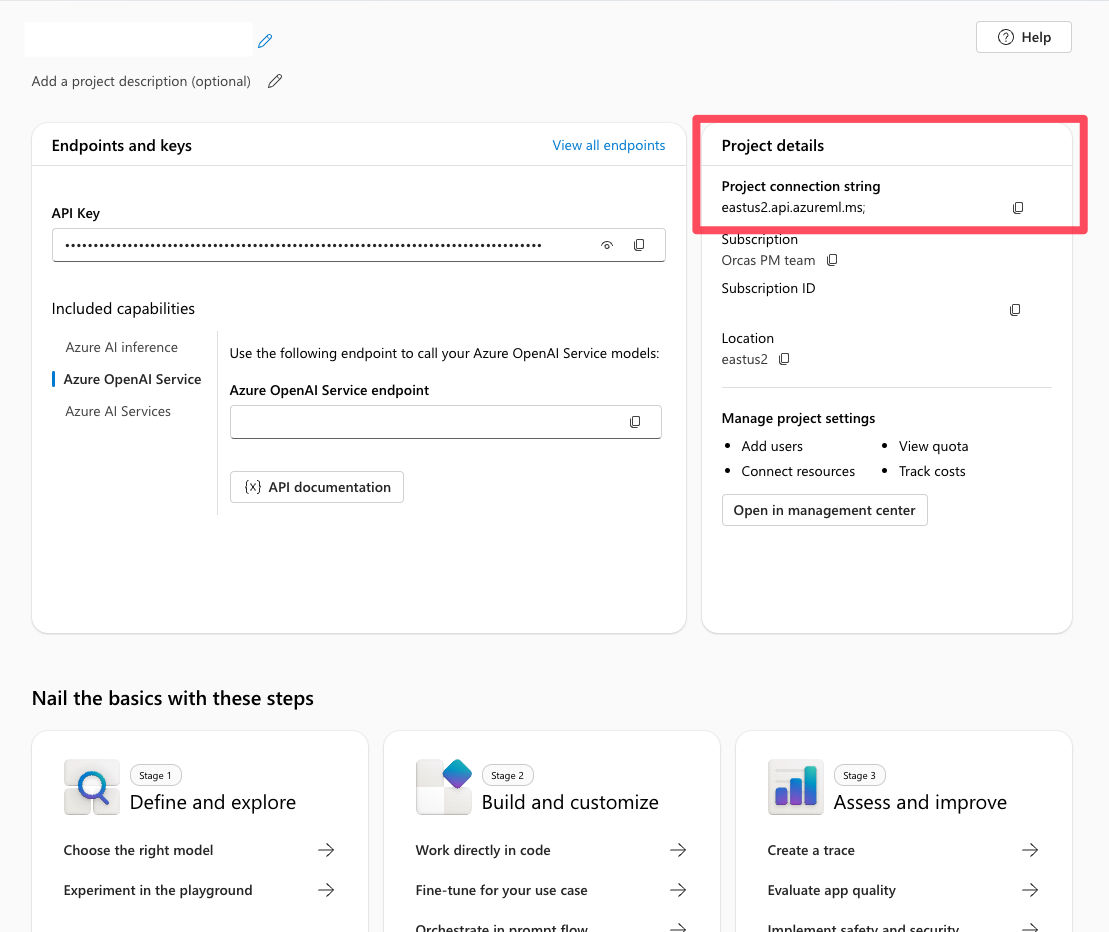
Configurare la connessione
Aggiungere queste variabili al file .env nella directory radice:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create a Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
Creare un thread di comunicazione
Questo frammento di codice illustra come creare un thread e un messaggio dell'agente, che l'agente elabora in un'esecuzione:
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
Elaborare la richiesta
Il frammento di codice seguente crea un'esecuzione per l'agente per elaborare il messaggio e usare gli strumenti appropriati per fornire il risultato migliore.
Usando gli strumenti, l'agente può chiamare Postgres e la ricerca vettoriale sulla query "Perdita di acqua nell'appartamento dall'alto" per recuperare i dati necessari per rispondere meglio alla domanda.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
Eseguire l'agente
Per eseguire l'agente, eseguire il comando seguente dalla src directory :
python simple_postgres_and_ai_agent.py
L'agente produce un risultato simile usando lo strumento Database di Azure per PostgreSQL per accedere ai dati del caso salvati nel database Postgres.
Ecco un frammento di output dell'agente:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
Passaggio 4: Testare ed eseguire il debug con l'ambiente di prova dell'agente
Dopo aver eseguito l'agente usando Agent Service SDK, l'agente viene archiviato nel progetto. È possibile provare l'agente nell'area di prova dell'agente:
In Foundry passare alla sezione Agenti .
Trovare l'agente nell'elenco e selezionarlo per aprirlo.
Utilizzare l'interfaccia del playground per testare varie query legali.
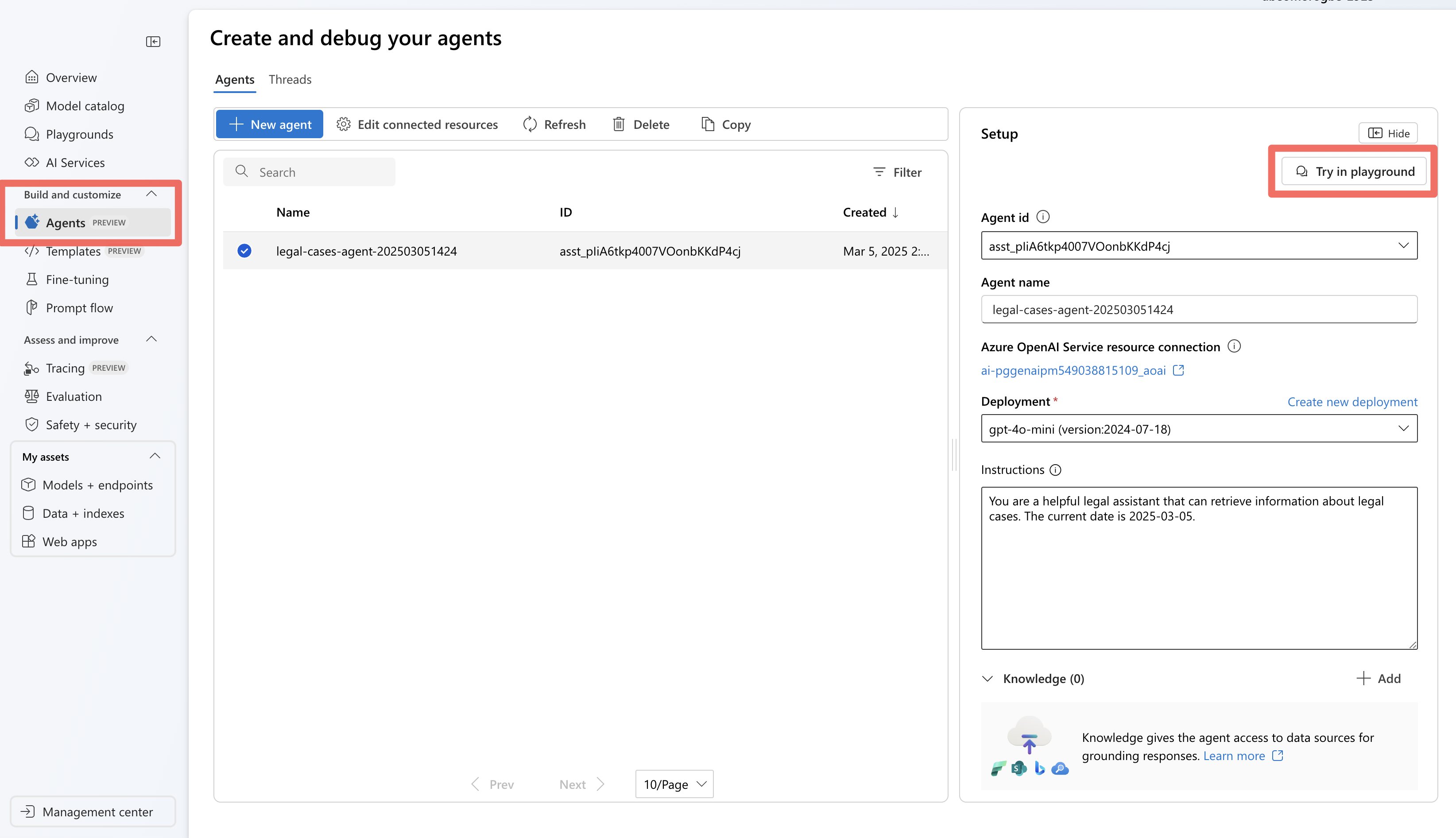
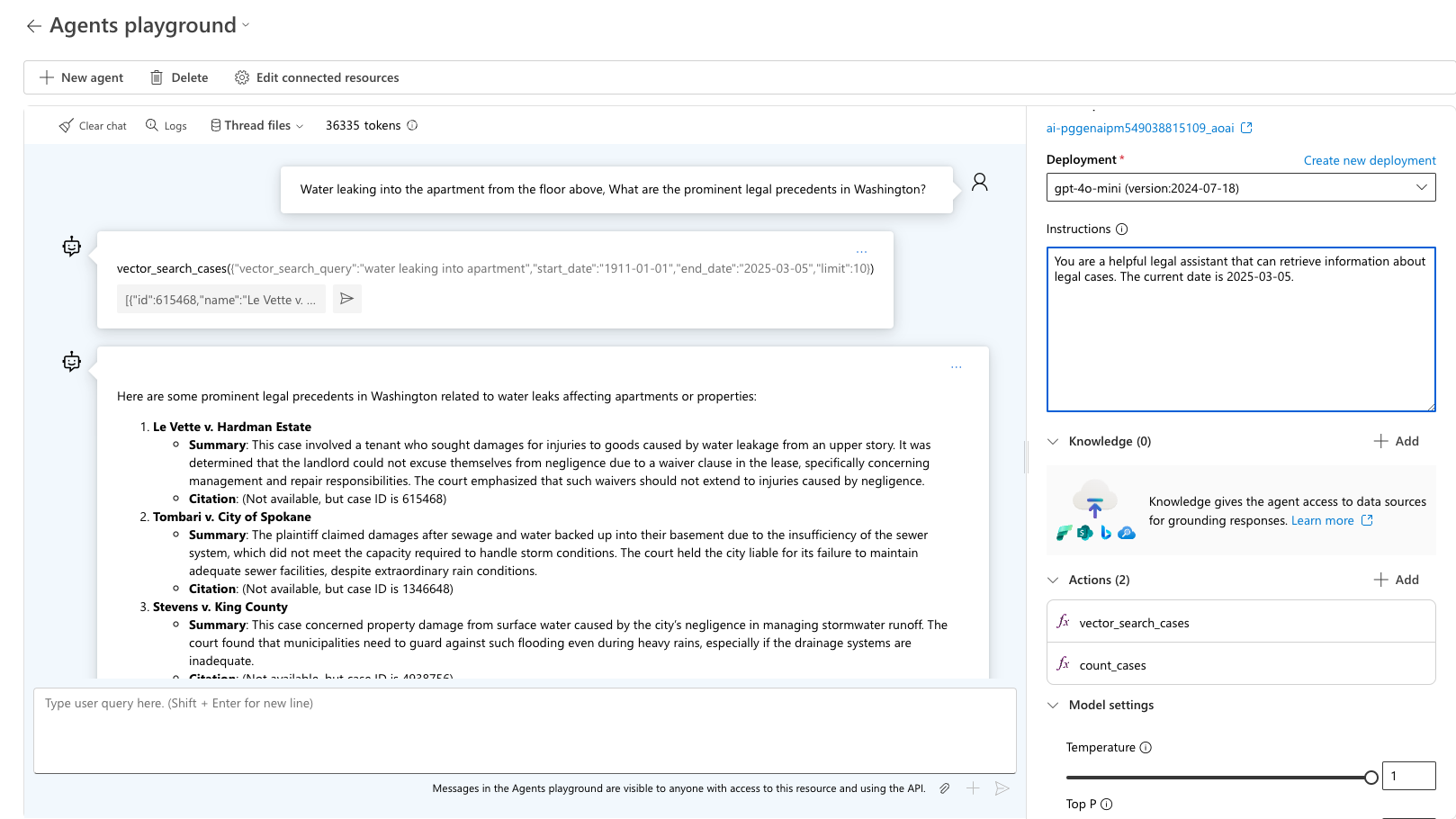
Testare la query "Infiltrazioni di acqua nell'appartamento dovute a perdite dall'appartamento del piano di sopra. Quali sono i precedenti più importanti nello stato di Washington?" L'agente seleziona lo strumento corretto da utilizzare e chiede l'output previsto per la query. Usare sample_vector_search_cases_output.json come output di esempio.
Passaggio 5: Debug con il tracciamento di Foundry
Quando si sviluppa l'agente usando Agent Service SDK, è possibile eseguire il debug dell'agente con la tracciatura. La traccia consente di eseguire il debug delle chiamate a strumenti come Postgres e vedere come l'agente orchestra ogni attività.
In Foundry passare a Tracciamento.
Per creare una nuova risorsa di Application Insights, selezionare Crea nuovo. Per connettere una risorsa esistente, selezionare una nella casella Nome risorsa di Application Insights e quindi selezionare Connetti.
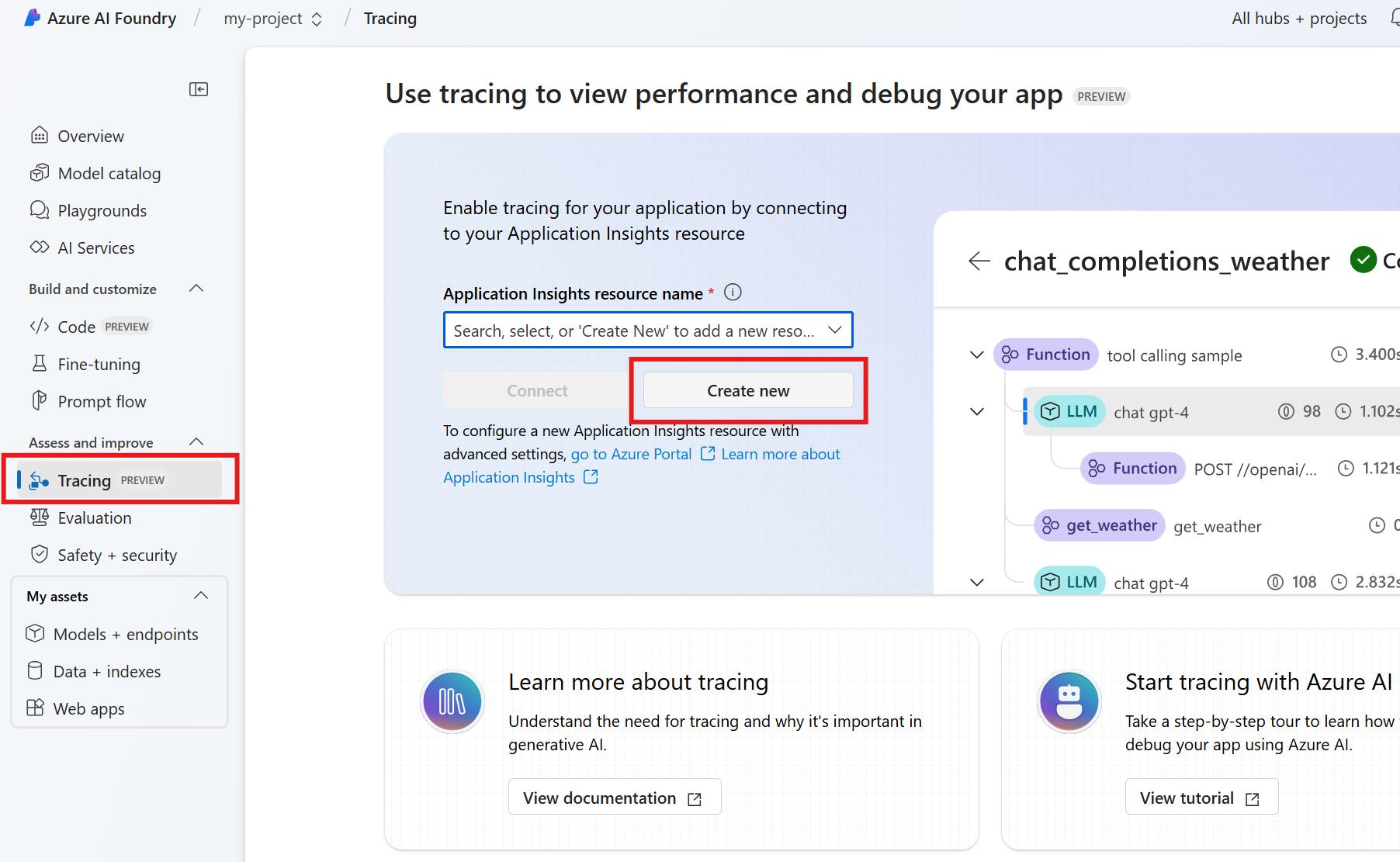
Visualizzare tracce dettagliate delle operazioni dell'agente.
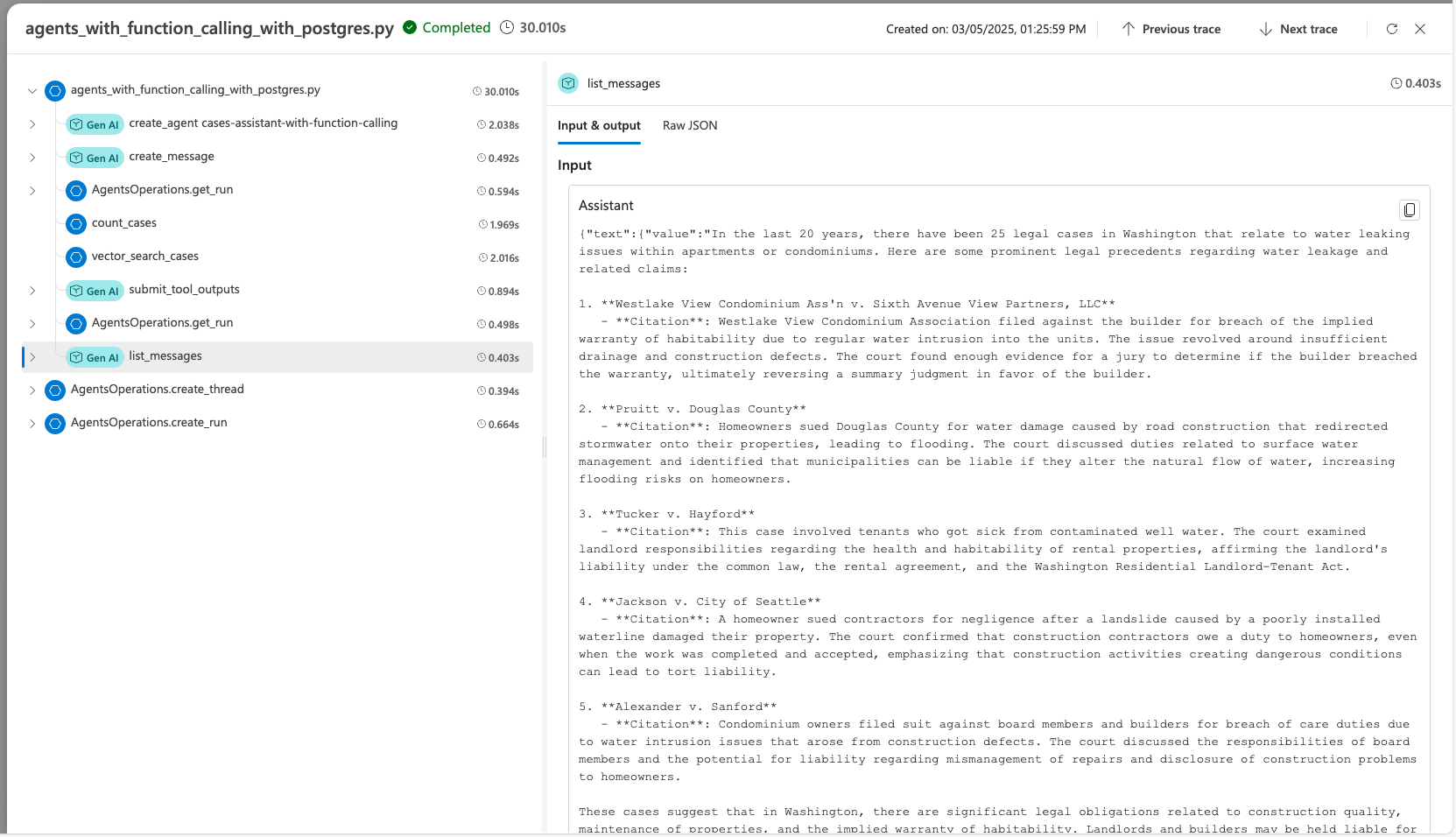
Altre informazioni su come configurare la traccia con l'agente di intelligenza artificiale e Postgres nel file advanced_postgres_and_ai_agent_with_tracing.py su GitHub.
Contenuti correlati
- Integrazioni di Database di Azure per PostgreSQL per le applicazioni di intelligenza artificiale
- Usare LangChain con Database di Azure per PostgreSQL
- Generare incorporamenti vettoriali con OpenAI di Azure in Database di Azure per PostgreSQL
- Estensione di Azure AI nel database di Azure per PostgreSQL
- Creare una ricerca semantica con Database di Azure per PostgreSQL e Azure OpenAI
- Abilitare e usare pgvector in Database di Azure per PostgreSQL