Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
È consigliabile distribuire uno dei servizi NFS propri di Azure, NFS in File di Azure o volumi NFS ANF, per l'archiviazione di dati condivisi in un sistema SAP a disponibilità elevata. Tenere presente che vengono evidenziate le architetture di riferimento SAP tramite cluster NFS.
Questo articolo descrive come distribuire le macchine virtuali, configurare le macchine virtuali, installare il framework del cluster e installare un server NFS a disponibilità elevata che può essere usato per archiviare i dati condivisi di un sistema SAP a disponibilità elevata. Questa guida descrive come configurare un server NFS a disponibilità elevata usato da due sistemi SAP, NW1 e NW2. I nomi delle risorse, ad esempio delle macchine virtuali e delle reti virtuali, nell'esempio presuppongono che sia stato usato il modello di file server SAP con il prefisso di risorsa prod.
Nota
Questo articolo contiene riferimenti a termini che Microsoft non usa più. Quando i termini verranno rimossi dal software, verranno rimossi da questo articolo.
Leggere prima di tutto le note e i documenti seguenti relativi a SAP
Nota SAP 1928533, contenente:
- Elenco delle dimensioni delle VM di Azure supportate per la distribuzione di software SAP
- Importanti informazioni sulla capacità per le dimensioni delle VM di Azure
- Software SAP e combinazioni di sistemi operativi e database supportati
- Versione del kernel SAP richiesta per Windows e Linux in Microsoft Azure
La nota SAP 2015553 elenca i prerequisiti per le distribuzioni di software SAP supportate da SAP in Azure.
La nota SAP 2205917 contiene le impostazioni consigliate del sistema operativo per SUSE Linux Enterprise Server for SAP Applications
La nota SAP 1944799 contiene linee guida per SAP HANA per SUSE Linux Enterprise Server for SAP Applications
La nota SAP 2178632 contiene informazioni dettagliate su tutte le metriche di monitoraggio segnalate per SAP in Azure.
La nota SAP 2191498 contiene la versione dell'agente host SAP per Linux necessaria in Azure.
La nota SAP 2243692 contiene informazioni sulle licenze SAP in Linux in Azure.
La nota SAP 1984787 contiene informazioni generali su SUSE Linux Enterprise Server 12.
La nota SAP 1999351 contiene informazioni aggiuntive sulla risoluzione dei problemi per l'estensione di monitoraggio avanzato di Azure per SAP.
Community WIKI SAP contiene tutte le note su SAP necessarie per Linux.
Pianificazione e implementazione di Macchine virtuali di Azure per SAP in Linux
Distribuzione di Macchine virtuali di Microsoft Azure per SAP in Linux (questo articolo)
Distribuzione DBMS di Macchine virtuali di Azure per SAP in Linux
Archiviazione NFS a disponibilità elevata SUSE Linux Enterprise 12 SP5 con DRBD e Pacemaker
Guide alle procedure consigliate su SUSE Linux Enterprise Server for SAP Applications 12 SP5
Note sulla versione di SUSE Linux Enterprise Server for SAP Applications 12 SP5
Panoramica
Per ottenere la disponibilità elevata, SAP NetWeaver richiede un server NFS. Il server NFS viene configurato in un cluster separato e può essere usato da più sistemi SAP.
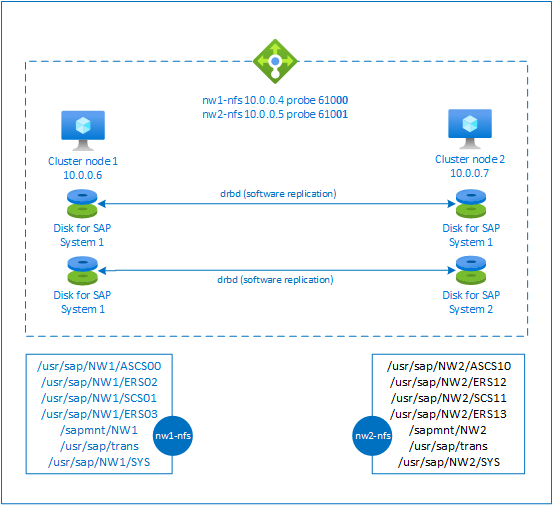
Il server NFS usa un nome host virtuale dedicato e indirizzi IP virtuali per ogni sistema SAP che usa questo server NFS. In Azure è necessario un servizio di bilanciamento del carico per usare un indirizzo IP virtuale. La configurazione presentata mostra un bilanciamento del carico con:
- Indirizzo IP front-end 10.0.0.4 per NW1
- Indirizzo IP front-end 10.0.0.5 per NW2
- Porta probe 61000 per NW1
- Porta probe 61001 per NW2
Configurare un server NFS a disponibilità elevata
Distribuire Linux manualmente tramite il portale di Azure
Questo documento presuppone che sia già stato distribuito un gruppo di risorse, una rete virtuale di Azure e una subnet.
Distribuire due macchine virtuali per i server NFS. Scegliere un'immagine SLES appropriata supportata nel sistema SAP. È possibile distribuire una macchina virtuale in una delle opzioni di disponibilità: set di scalabilità, zona di disponibilità o set di disponibilità.
Configurare il servizio di bilanciamento del carico di Azure
Seguire la guida Creare il servizio di bilanciamento del carico per configurare un servizio di bilanciamento del carico standard per una disponibilità elevata del server NFS. Durante la configurazione del servizio di bilanciamento del carico, prendere in considerazione i punti seguenti.
- Configurazione IP front-end: creare due IP front-end. Selezionare la stessa rete virtuale e la stessa subnet del server NFS.
- Pool back-end: creare un pool back-end e aggiungere macchine virtuali del server NFS.
- Regole in ingresso: creare due regole di bilanciamento del carico, una per NW1 e un'altra per NW2. Seguire la stessa procedura per entrambe le regole di bilanciamento del carico.
- Indirizzo IP front-end: selezionare IP front-end
- Pool back-end: selezionare il pool back-end
- Controllare "Porte a disponibilità elevata"
- Protocollo: TCP
- Probe di integrità: creare un probe di integrità con i dettagli seguenti (si applica sia per NW1 che per NW2)
- Protocollo: TCP
- Porta: [ad esempio: 61000 per NW1, 61001 per NW2]
- Intervallo: 5
- Soglia probe: 2
- Timeout di inattività (minuti): 30
- Selezionare "Abilita IP mobile"
Nota
La proprietà di configurazione del probe di integrità numberOfProbes, altrimenti nota nel portale come "Soglia non integra", non viene rispettata. Per controllare il numero di probe consecutivi riusciti o non riusciti, impostare la proprietà "probeThreshold" su 2. Non è attualmente possibile impostare questa proprietà usando il portale di Azure, quindi usare l'interfaccia della riga di comando di Azure o il comando di PowerShell.
Nota
Quando le macchine virtuali senza indirizzi IP pubblici vengono inserite nel pool back-end del Load Balancer interno standard di Azure (nessun indirizzo IP pubblico), non vi sarà connettività Internet in uscita, a meno che non venga eseguita una configurazione aggiuntiva per consentire il routing a endpoint pubblici. Per informazioni dettagliate su come ottenere la connettività in uscita, vedere Connettività degli endpoint pubblici per le macchine virtuali usando Load Balancer Standard di Azure negli scenari a disponibilità elevata SAP.
Importante
- Non abilitare i timestamp TCP nelle macchine virtuali di Azure che si trovano dietro Azure Load Balancer. Se si abilitano i timestamp TCP, i probe di integrità avranno esito negativo. Impostare il parametro
net.ipv4.tcp_timestampssu0. Per informazioni dettagliate, vedere Probe di integrità di Load Balancer. - Per impedire a saptune di modificare il valore
net.ipv4.tcp_timestampsimpostato manualmente da0a1, è consigliabile aggiornare la versione di saptune alla versione 3.1.1 o successiva. Per ulteriori dettagli, vedere saptune 3.1.1 – Devo fare l’aggiornamento?
Creare un cluster Pacemaker
Seguire i passaggi descritti in Setting up Pacemaker on SUSE Linux Enterprise Server in Azure (Configurazione di Pacemaker su SUSE Linux Enterprise Server in Azure) per creare un cluster Pacemaker di base per questo server NFS.
Configurare il server NFS
Gli elementi seguenti sono preceduti dall'indicazione [A] - applicabile a tutti i nodi, [1] - applicabile solo al nodo 1 o [2] - applicabile solo al nodo 2.
[A] Configurare la risoluzione dei nomi host
È possibile usare un server DNS o modificare /etc/hosts in tutti i nodi. Questo esempio mostra come usare il file /etc/hosts. Sostituire l'indirizzo IP e il nome host nei comandi seguenti
sudo vi /etc/hostsInserire le righe seguenti in /etc/hosts. Modificare l'indirizzo IP e il nome host in base all'ambiente
# IP address of the load balancer frontend configuration for NFS 10.0.0.4 nw1-nfs 10.0.0.5 nw2-nfs[A] Abilitare il server NFS
Creare la voce di esportazione NFS radice
sudo sh -c 'echo /srv/nfs/ *\(rw,no_root_squash,fsid=0\)>/etc/exports' sudo mkdir /srv/nfs/[A] Installare i componenti drbd
sudo zypper install drbd drbd-kmp-default drbd-utils[A] Creare una partizione per i dispositivi drbd
Elencare tutti i dischi dati disponibili
sudo ls /dev/disk/azure/scsi1/ # Example output # lun0 lun1Creare partizioni per ogni disco dati
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun1'[A] Creare le configurazioni LVM
Elencare tutte le partizioni disponibili
ls /dev/disk/azure/scsi1/lun*-part* # Example output # /dev/disk/azure/scsi1/lun0-part1 /dev/disk/azure/scsi1/lun1-part1Creare volumi LVM per ogni partizione
sudo pvcreate /dev/disk/azure/scsi1/lun0-part1 sudo vgcreate vg-NW1-NFS /dev/disk/azure/scsi1/lun0-part1 sudo lvcreate -l 100%FREE -n NW1 vg-NW1-NFS sudo pvcreate /dev/disk/azure/scsi1/lun1-part1 sudo vgcreate vg-NW2-NFS /dev/disk/azure/scsi1/lun1-part1 sudo lvcreate -l 100%FREE -n NW2 vg-NW2-NFS[A] Configurare drbd
sudo vi /etc/drbd.confAssicurarsi che il file drbd.conf contenga le due righe seguenti
include "drbd.d/global_common.conf"; include "drbd.d/*.res";Modificare la configurazione globale di drbd
sudo vi /etc/drbd.d/global_common.confAggiungere le voci seguenti al gestore e alla sezione net.
global { usage-count no; } common { handlers { fence-peer "/usr/lib/drbd/crm-fence-peer.9.sh"; after-resync-target "/usr/lib/drbd/crm-unfence-peer.9.sh"; split-brain "/usr/lib/drbd/notify-split-brain.sh root"; pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; } startup { wfc-timeout 0; } options { } disk { md-flushes yes; disk-flushes yes; c-plan-ahead 1; c-min-rate 100M; c-fill-target 20M; c-max-rate 4G; } net { after-sb-0pri discard-younger-primary; after-sb-1pri discard-secondary; after-sb-2pri call-pri-lost-after-sb; protocol C; tcp-cork yes; max-buffers 20000; max-epoch-size 20000; sndbuf-size 0; rcvbuf-size 0; } }[A] Creare i dispositivi drbd NFS
sudo vi /etc/drbd.d/NW1-nfs.resInserire la configurazione per il nuovo dispositivo drbd e uscire
resource NW1-nfs { protocol C; disk { on-io-error detach; } net { fencing resource-and-stonith; } on prod-nfs-0 { address 10.0.0.6:7790; device /dev/drbd0; disk /dev/vg-NW1-NFS/NW1; meta-disk internal; } on prod-nfs-1 { address 10.0.0.7:7790; device /dev/drbd0; disk /dev/vg-NW1-NFS/NW1; meta-disk internal; } }sudo vi /etc/drbd.d/NW2-nfs.resInserire la configurazione per il nuovo dispositivo drbd e uscire
resource NW2-nfs { protocol C; disk { on-io-error detach; } net { fencing resource-and-stonith; } on prod-nfs-0 { address 10.0.0.6:7791; device /dev/drbd1; disk /dev/vg-NW2-NFS/NW2; meta-disk internal; } on prod-nfs-1 { address 10.0.0.7:7791; device /dev/drbd1; disk /dev/vg-NW2-NFS/NW2; meta-disk internal; } }Creare il dispositivo drbd e avviarlo
sudo drbdadm create-md NW1-nfs sudo drbdadm create-md NW2-nfs sudo drbdadm up NW1-nfs sudo drbdadm up NW2-nfs[1] Saltare la sincronizzazione iniziale
sudo drbdadm new-current-uuid --clear-bitmap NW1-nfs sudo drbdadm new-current-uuid --clear-bitmap NW2-nfs[1] Impostare il nodo primario
sudo drbdadm primary --force NW1-nfs sudo drbdadm primary --force NW2-nfs[1] Attendere il completamento della sincronizzazione dei nuovi dispositivi drbd
sudo drbdsetup wait-sync-resource NW1-nfs sudo drbdsetup wait-sync-resource NW2-nfs[1] Creare i file system nei dispositivi drbd
sudo mkfs.xfs /dev/drbd0 sudo mkdir /srv/nfs/NW1 sudo chattr +i /srv/nfs/NW1 sudo mount -t xfs /dev/drbd0 /srv/nfs/NW1 sudo mkdir /srv/nfs/NW1/sidsys sudo mkdir /srv/nfs/NW1/sapmntsid sudo mkdir /srv/nfs/NW1/trans sudo mkdir /srv/nfs/NW1/ASCS sudo mkdir /srv/nfs/NW1/ASCSERS sudo mkdir /srv/nfs/NW1/SCS sudo mkdir /srv/nfs/NW1/SCSERS sudo umount /srv/nfs/NW1 sudo mkfs.xfs /dev/drbd1 sudo mkdir /srv/nfs/NW2 sudo chattr +i /srv/nfs/NW2 sudo mount -t xfs /dev/drbd1 /srv/nfs/NW2 sudo mkdir /srv/nfs/NW2/sidsys sudo mkdir /srv/nfs/NW2/sapmntsid sudo mkdir /srv/nfs/NW2/trans sudo mkdir /srv/nfs/NW2/ASCS sudo mkdir /srv/nfs/NW2/ASCSERS sudo mkdir /srv/nfs/NW2/SCS sudo mkdir /srv/nfs/NW2/SCSERS sudo umount /srv/nfs/NW2[A] Configurare il rilevamento di scenari split brain per drbd
Quando si usa drbd per sincronizzare i dati da un host a un altro, può verificarsi un fenomeno denominato split brain. Uno split brain è uno scenario in cui entrambi i nodi del cluster hanno innalzato di livello il dispositivo drbd come primario e non sono più sincronizzati. Questa situazione può essere rara, ma è comunque consigliabile essere preparati a gestire e risolvere uno scenario di split brain il più rapidamente possibile. Di conseguenza, è importante ricevere una notifica quando si verifica uno scenario di split brain.
Leggere la documentazione ufficiale di drbd su come configurare una notifica di split brain.
È anche possibile ripristinare automaticamente il sistema da uno scenario di split brain. Per altre informazioni, vedere Automatic split brain recovery policies (Criteri di ripristino automatico da scenari di split brain)
Configurare il framework del cluster
[1] Aggiungere i dispositivi drbd NFS per il sistema SAP NW1 alla configurazione del cluster
Importante
Sono state rilevate situazioni di test recenti, in cui netcat smette di rispondere alle richieste dovute al backlog e alla limitazione della gestione di una sola connessione. La risorsa netcat smette di essere in ascolto delle richieste del servizio di bilanciamento del carico di Azure e l'IP mobile diventa non disponibile.
Per i cluster Pacemaker esistenti, in passato era consigliabile sostituire netcat con socat. Attualmente è consigliabile usare l'agente di risorse azure-lb, che fa parte degli agenti di risorse del pacchetto, con i requisiti di versione del pacchetto seguenti:- Per SLES 12 SP4/SP5 la versione deve essere almeno resource-agents-4.3.018.a7fb5035-3.30.1.
- Per SLES 15/15 SP1 la versione deve essere almeno resource-agents-4.3.0184.6ee15eb2-4.13.1.
Si noti che la modifica richiederà un breve tempo di inattività.
Per i cluster Pacemaker esistenti, se la configurazione è stata già modificata per usare socat, come descritto in Azure Load-Balancer Detection Hardening (Protezione avanzata dei rilevamenti del servizio di bilanciamento del carico di Azure), non è necessario passare immediatamente all'agente delle risorse azure-lb.sudo crm configure rsc_defaults resource-stickiness="200" # Enable maintenance mode sudo crm configure property maintenance-mode=true sudo crm configure primitive drbd_NW1_nfs \ ocf:linbit:drbd \ params drbd_resource="NW1-nfs" \ op monitor interval="15" role="Master" \ op monitor interval="30" role="Slave" sudo crm configure ms ms-drbd_NW1_nfs drbd_NW1_nfs \ meta master-max="1" master-node-max="1" clone-max="2" \ clone-node-max="1" notify="true" interleave="true" sudo crm configure primitive fs_NW1_sapmnt \ ocf:heartbeat:Filesystem \ params device=/dev/drbd0 \ directory=/srv/nfs/NW1 \ fstype=xfs \ op monitor interval="10s" sudo crm configure primitive nfsserver systemd:nfs-server \ op monitor interval="30s" sudo crm configure clone cl-nfsserver nfsserver sudo crm configure primitive exportfs_NW1 \ ocf:heartbeat:exportfs \ params directory="/srv/nfs/NW1" \ options="rw,no_root_squash,crossmnt" clientspec="*" fsid=1 wait_for_leasetime_on_stop=true op monitor interval="30s" sudo crm configure primitive vip_NW1_nfs IPaddr2 \ params ip=10.0.0.4 op monitor interval=10 timeout=20 sudo crm configure primitive nc_NW1_nfs azure-lb port=61000 \ op monitor timeout=20s interval=10 sudo crm configure group g-NW1_nfs \ fs_NW1_sapmnt exportfs_NW1 nc_NW1_nfs vip_NW1_nfs sudo crm configure order o-NW1_drbd_before_nfs inf: \ ms-drbd_NW1_nfs:promote g-NW1_nfs:start sudo crm configure colocation col-NW1_nfs_on_drbd inf: \ g-NW1_nfs ms-drbd_NW1_nfs:Master[1] Aggiungere i dispositivi drbd NFS per il sistema SAP NW2 alla configurazione del cluster
# Enable maintenance mode sudo crm configure property maintenance-mode=true sudo crm configure primitive drbd_NW2_nfs \ ocf:linbit:drbd \ params drbd_resource="NW2-nfs" \ op monitor interval="15" role="Master" \ op monitor interval="30" role="Slave" sudo crm configure ms ms-drbd_NW2_nfs drbd_NW2_nfs \ meta master-max="1" master-node-max="1" clone-max="2" \ clone-node-max="1" notify="true" interleave="true" sudo crm configure primitive fs_NW2_sapmnt \ ocf:heartbeat:Filesystem \ params device=/dev/drbd1 \ directory=/srv/nfs/NW2 \ fstype=xfs \ op monitor interval="10s" sudo crm configure primitive exportfs_NW2 \ ocf:heartbeat:exportfs \ params directory="/srv/nfs/NW2" \ options="rw,no_root_squash,crossmnt" clientspec="*" fsid=2 wait_for_leasetime_on_stop=true op monitor interval="30s" sudo crm configure primitive vip_NW2_nfs IPaddr2 \ params ip=10.0.0.5 op monitor interval=10 timeout=20 sudo crm configure primitive nc_NW2_nfs azure-lb port=61001 \ op monitor timeout=20s interval=10 sudo crm configure group g-NW2_nfs \ fs_NW2_sapmnt exportfs_NW2 nc_NW2_nfs vip_NW2_nfs sudo crm configure order o-NW2_drbd_before_nfs inf: \ ms-drbd_NW2_nfs:promote g-NW2_nfs:start sudo crm configure colocation col-NW2_nfs_on_drbd inf: \ g-NW2_nfs ms-drbd_NW2_nfs:MasterL'opzione
crossmntnelle risorse clusterexportfsè presente nella documentazione per la compatibilità con le versioni precedenti di SLES.[1] Disabilitare la modalità manutenzione
sudo crm configure property maintenance-mode=false
Passaggi successivi
- Installare SAP ASCS e il database
- Pianificazione e implementazione di macchine virtuali di Azure per SAP
- Distribuzione di Macchine virtuali di Azure per SAP
- Distribuzione DBMS di macchine virtuali di Azure per SAP
- Per informazioni su come ottenere la disponibilità elevata e un piano di ripristino di emergenza di SAP HANA nelle macchine virtuali di Azure vedere Disponibilità elevata di SAP HANA nelle macchine virtuali di Azure (VM)