Stimare e gestire la capacità di un servizio di ricerca
In Azure AI Search la capacità è basata su repliche e partizioni che possono essere ridimensionate al carico di lavoro. Le repliche sono copie del motore di ricerca. Le partizioni sono unità di archiviazione. Ogni nuovo servizio di ricerca inizia con un'unità, ma è possibile aggiungere o rimuovere repliche e partizioni in modo indipendente per supportare carichi di lavoro fluttuanti. L'aggiunta di capacità aumenta il costo dell'esecuzione di un servizio di ricerca.
Le caratteristiche fisiche delle repliche e delle partizioni, ad esempio velocità di elaborazione e I/O del disco, variano in base al livello di servizio. In un servizio di ricerca standard, le repliche e le partizioni sono più veloci e più grandi di quelle di un servizio di base.
La modifica della capacità non è istantanea. Può essere necessaria fino a un'ora per commissionare o rimuovere le partizioni, in particolare per i servizi con grandi quantità di dati.
Quando si ridimensiona un servizio di ricerca, è possibile scegliere tra gli strumenti e gli approcci seguenti:
Nota
Le partizioni di capacità più elevate sono disponibili alla stessa tariffa di fatturazione per i servizi più recenti creati dopo aprile e maggio 2024. Per altre informazioni, vedere Limiti del servizio per gli aggiornamenti delle dimensioni della partizione.
Concetti: unità di ricerca, repliche, partizioni
La capacità è espressa in unità di ricerca che possono essere allocate in combinazioni di partizioni e repliche.
| Concetto | Definizione |
|---|---|
| Unità di ricerca | Un singolo incremento della capacità totale disponibile (36 unità). È anche l'unità di fatturazione per un servizio Azure AI Search. Per eseguire il servizio è necessaria almeno un'unità. |
| Replica | Istanze del servizio di ricerca, utilizzate principalmente per il bilanciamento di carico delle operazioni di query. Ogni replica ospita una copia di un indice. Se si allocano tre repliche, sono disponibili tre copie di un indice per le richieste di query di manutenzione. |
| Partizione | Archiviazione fisica degli indici e I/O per le operazioni di lettura e scrittura, ad esempio durante la compilazione o l'aggiornamento di un indice. Ogni partizione ha una sezione dell'indice totale. Se si allocano tre partizioni, l'indice viene diviso in terzi. |
Esaminare la tabella partizioni e repliche per le possibili combinazioni che rimangono al di sotto del limite di 36 unità.
Quando aggiungere capacità
Inizialmente, a un servizio viene allocato un livello minimo di risorse costituito da una partizione e una replica. Il livello scelto determina le dimensioni e la velocità della partizione e ogni livello è ottimizzato in base a un set di caratteristiche adatte a vari scenari. Se si sceglie un livello superiore, è possibile che siano necessarie meno partizioni rispetto all'uso di S1. Una delle domande a cui è necessario rispondere tramite test autonomi è se una partizione più grande e più costosa produrrà prestazioni migliori rispetto a due partizioni più economiche in un servizio di cui è stato effettuato il provisioning a un livello inferiore.
Un singolo servizio deve disporre di risorse sufficienti per gestire tutti i carichi di lavoro (indicizzazione e query). Nessuno dei due carichi di lavoro viene eseguito in background. È possibile pianificare l'indicizzazione per i tempi in cui le richieste di query sono naturalmente meno frequenti, ma il servizio non assegna in altro modo priorità a un'attività rispetto a un'altra. Inoltre, una certa quantità di ridondanza riduce le prestazioni delle query quando i servizi o i nodi vengono aggiornati internamente.
Alcune linee guida per determinare se aggiungere capacità includono:
- Soddisfare i criteri di disponibilità elevata per il contratto di servizio
- La frequenza degli errori HTTP 503 aumenta
- Sono previsti volumi di query di grandi dimensioni
Come regola generale, le applicazioni di ricerca tendono a richiedere più repliche che partizioni, in particolare quando fra le operazioni del servizio prevalgono i carichi di lavoro di query. Ogni replica è una copia dell'indice, che consente al servizio di bilanciare il carico delle richieste su più copie. Il bilanciamento del carico e la replica degli indici vengono gestiti da Azure AI Search ed è possibile modificare in qualsiasi momento il numero delle repliche allocate per il servizio. È possibile allocare fino a 12 repliche in un servizio di ricerca Standard e 3 repliche in un servizio di ricerca Basic. È possibile effettuare l'allocazione della replica dal portale di Azure o da una delle opzioni programmatiche.
Le partizioni aggiuntive sono utili per carichi di lavoro di indicizzazione intensivi. L'aggiunta di partizioni distribuisce le operazioni di lettura/scrittura su un numero più ampio di risorse di calcolo.
Infine, l'esecuzione di query su indici di dimensioni maggiori può richiedere tempi più lunghi. Di conseguenza, si noterà che ogni aumento incrementale delle partizioni richiede un aumento delle repliche proporzionale ma più limitato. La complessità e il volume delle query influiscono sulla rapidità di esecuzione delle stesse.
Nota
L'aggiunta di più repliche o partizioni aumenta il costo dell'esecuzione del servizio e può introdurre lievi variazioni nella modalità di ordinamento dei risultati. Assicurarsi di controllare il calcolatore prezzi per comprendere le implicazioni di fatturazione dell'aggiunta di altri nodi. Il grafico seguente consente di fare riferimento incrociato al numero di unità di ricerca necessarie per una configurazione specifica. Per altre informazioni sull'impatto delle repliche aggiuntive sull'elaborazione delle query, vedere Risultati dell'ordinamento.
Come modificare la capacità
Per aumentare o ridurre la capacità del servizio di ricerca, aggiungere o rimuovere partizioni e repliche.
Accedere al portale di Azure e selezionare il servizio di ricerca.
In Impostazioni aprire la pagina Scala per modificare repliche e partizioni.
Lo screenshot seguente mostra un servizio Standard di cui è stato effettuato il provisioning con una replica e una partizione. La formula nella parte inferiore indica il numero di unità di ricerca usate (1). Se il prezzo unitario era di $ 100 (solo come esempio), il costo mensile di esecuzione di questo servizio sarebbe di $ 100 in media.
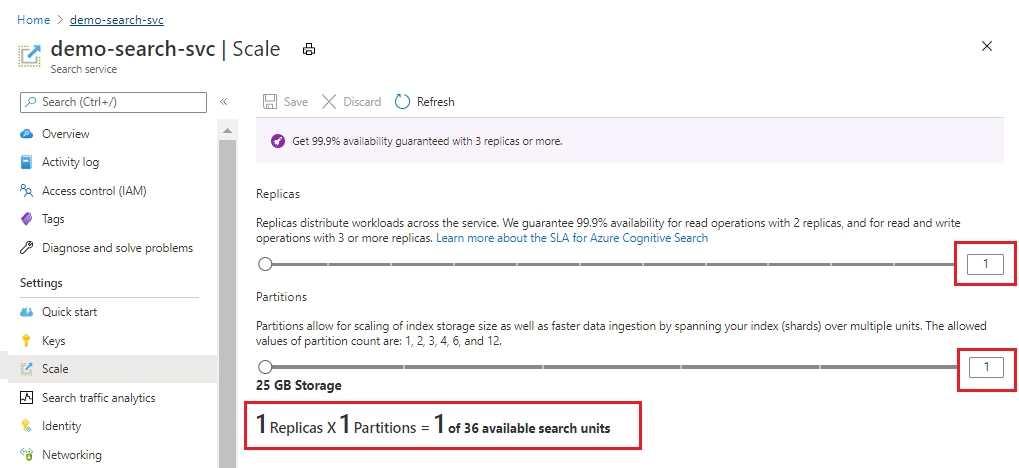
Usare il dispositivo di scorrimento per aumentare o diminuire il numero di partizioni. Seleziona Salva.
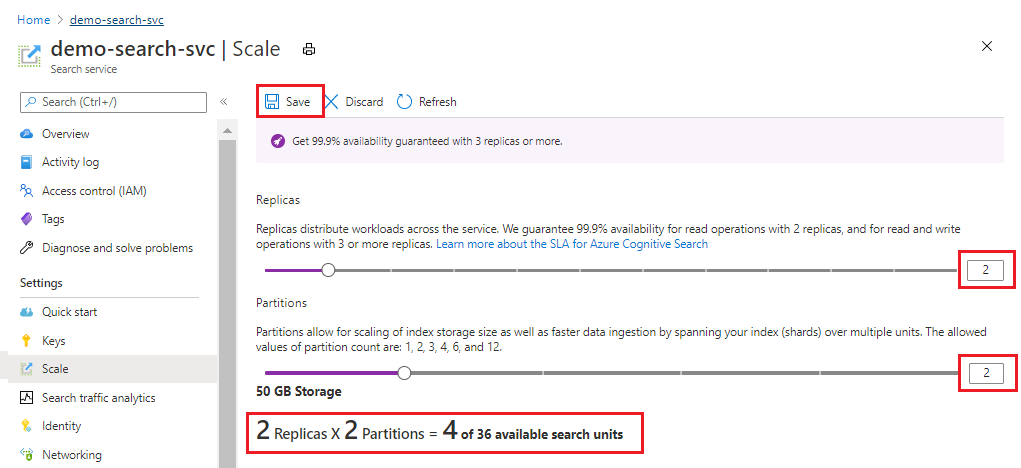
In questo esempio vengono aggiunte una seconda replica e una seconda partizione. Si noti il numero di unità di ricerca; ora sono quattro perché la formula di fatturazione consiste nelle repliche moltiplicate per le partizioni (2 x 2). Il raddoppio della capacità supera il doppio del costo di esecuzione del servizio. Se il costo unitario di ricerca era di $ 100, la nuova fattura mensile sarebbe ora di $ 400.
Per i costi correnti per unità di ogni livello, visitare la Pagina dei prezzi.
Dopo il salvataggio, è possibile controllare le notifiche per confermare che l'azione sia riuscita.
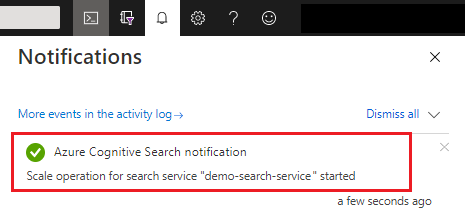
Il completamento delle modifiche alla capacità può richiedere da 15 minuti fino a diverse ore. Non è possibile annullare dopo l'avvio del processo e non è disponibile alcun monitoraggio in tempo reale per le modifiche di replica e partizione. Tuttavia, il messaggio seguente rimane visibile mentre sono in corso le modifiche.

Nota
Dopo aver effettuato il provisioning di un servizio, non è possibile aggiornarlo passando a un livello superiore. È necessario creare un servizio di ricerca a un nuovo livello e ricaricare gli indici. Per assistenza sul provisioning del servizio, vedere Creare un servizio Azure AI Search nel portale.
Modalità di gestione delle richieste di scalabilità
Dopo la ricezione di una richiesta di scalabilità, il servizio di ricerca:
- Verifica se la richiesta è valida.
- Avvia il backup dei dati e delle informazioni di sistema.
- Verifica se il servizio è già in stato di provisioning (ossia se sta attualmente aggiungendo o eliminando repliche o partizioni).
- Avvia il provisioning.
Il ridimensionamento di un servizio può richiedere fino a 15 minuti o oltre un'ora, a seconda delle dimensioni del servizio e dell'ambito della richiesta. Il backup può richiedere alcuni minuti, a seconda della quantità di dati e del numero di partizioni e repliche.
I passaggi precedenti non sono completamente consecutivi. Ad esempio, il sistema avvia il provisioning quando può farlo in modo sicuro, il che potrebbe essere mentre il backup è inattivo.
Errori durante il ridimensionamento
Il messaggio di errore "Le operazioni di aggiornamento del servizio non sono consentite in questo momento perché si sta elaborando una richiesta precedente" sono causate dalla ripetizione di una richiesta per ridurre o aumentare le prestazioni quando il servizio sta già elaborando una richiesta precedente.
Risolvere questo errore controllando lo stato del servizio per verificare lo stato del provisioning:
- Usare l'API REST di gestione, Azure PowerShello l'interfaccia della riga di comando di Azure per ottenere lo stato del servizio.
- Chiamare Servizio Get (REST) o equivalente per PowerShell o l'interfaccia della riga di comando.
- Controllare la risposta per "provisioningState": "provisioning"
Se lo stato è "Provisioning", attendere il completamento della richiesta. Lo stato deve essere "Operazione completata" o "Errore" prima che venga tentata un'altra richiesta. Non esiste alcuno stato per il backup. Il backup è un'operazione interna ed è improbabile che sia un fattore in qualsiasi interruzione di un esercizio di scalabilità.
Se il servizio di ricerca sembra essere bloccato in uno stato di provisioning, verificare la presenza di indici orfani inutilizzabili, senza volumi di query e senza aggiornamenti dell'indice. Un indice inutilizzabile può bloccare le modifiche apportate alla capacità del servizio. In particolare, cercare gli indici crittografati da CMK, le cui chiavi non sono più valide. È necessario eliminare l'indice o ripristinare le chiavi per riportare l'indice online e sbloccare l'operazione di scalabilità.
combinazioni di partizioni e repliche
Il grafico seguente si applica al livello Standard e superiore. Mostra tutte le possibili combinazioni di partizioni e repliche, soggette al massimo di 36 unità di ricerca per servizio.
| 1 partizione | 2 partizioni | 3 partizioni | 4 partizioni | 6 partizioni | 12 partizioni | |
|---|---|---|---|---|---|---|
| 1 replica. | 1 unità di archiviazione | 2 unità di ricerca | 3 unità di ricerca | 4 unità di ricerca | 6 unità di ricerca | 12 unità di ricerca |
| 2 repliche | 2 unità di ricerca | 4 unità di ricerca | 6 unità di ricerca | 8 unità di ricerca | 12 unità di ricerca | 24 unità di ricerca |
| 3 repliche | 3 unità di ricerca | 6 unità di ricerca | 9 unità di ricerca | 12 unità di ricerca | 18 unità di ricerca | 36 unità di ricerca |
| 4 repliche | 4 unità di ricerca | 8 unità di ricerca | 12 unità di ricerca | 16 unità di ricerca | 24 unità di ricerca | N/D |
| 5 repliche | 5 unità di ricerca | 10 unità di ricerca | 15 unità di ricerca | 20 unità di ricerca | 30 unità di ricerca | N/D |
| 6 repliche | 6 unità di ricerca | 12 unità di ricerca | 18 unità di ricerca | 24 unità di ricerca | 36 unità di ricerca | N/D |
| 12 repliche | 12 unità di ricerca | 24 unità di ricerca | 36 unità di ricerca | N/D | N/D | N/D |
I servizi di ricerca di base hanno un numero inferiore di unità di ricerca.
Nei servizi di ricerca creati prima del 3 aprile 2024, un servizio di ricerca di base può avere esattamente una partizione e fino a tre repliche, per un limite massimo di tre UR. Le repliche sono l'unica risorsa regolabile.
Nei servizi di ricerca creati dopo il 3 aprile 2024 in aree supportate, i servizi di base possono avere fino a tre partizioni e tre repliche. Il limite massimo di unità di streaming è nove per supportare un complemento pieno di partizioni e repliche.
Per i servizi di ricerca in qualsiasi livello fatturabile, indipendentemente dalla data di creazione, sono necessarie almeno due repliche per la disponibilità elevata nelle query.
Per le tariffe di fatturazione per livello e valuta, vedere la pagina dei prezzi di Azure AI Search.
Stimare la capacità usando un livello fatturabile
Le esigenze di archiviazione sono determinate dalle dimensioni degli indici che si prevede di compilare. Non ci sono solide informazioni euristiche o di generalità che possano aiutare con le stime. L'unico modo per determinare le dimensioni di un indice consiste nel compilarne uno. Le dimensioni sono basate sulla tokenizzazione e sugli incorporamenti e sull'abilitazione di suggerimenti, filtri e ordinamento oppure possono sfruttare la compressione vettoriale.
È consigliabile stimare in base a un livello fatturabile, Basic o superiore. Il livello Gratuito viene eseguito su risorse fisiche condivise da più clienti ed è soggetto a fattori oltre il controllo dell'utente. Solo le risorse dedicate di un servizio di ricerca fatturabile possono supportare tempi di campionamento ed elaborazione maggiori per stime più realistiche della quantità, delle dimensioni e dei volumi di query dell'indice durante lo sviluppo.
Rivedere i limiti di servizio di ogni livello per determinare se livelli inferiori possono supportare la quantità di indici necessaria. Valutare se sono necessarie più copie di un indice per lo sviluppo, il test e la produzione attivi.
Un servizio di ricerca è soggetto ai limiti degli oggetti (numero massimo di indici, indicizzatori, set di competenze e così via) e limiti di archiviazione. Il limite raggiunto per primo è il limite effettivo.
Creare un servizio a un livello fatturabile. I livelli sono ottimizzati per determinati carichi di lavoro. Ad esempio, il livello Ottimizzato per l'archiviazione ha un limite di 10 indici perché è progettato per supportare un numero ridotto di indici molto grandi.
Iniziare dal basso, dal livello Basic o S1, se non si è certi del caricamento proiettato.
Iniziare dall'alto, ai livelli S2 o anche S3, se il test include caricamenti di query e indicizzazione su larga scala.
Iniziare con Ottimizzazione archiviazione, in L1 o L2, se si indicizza una grande quantità di dati e il carico di query è relativamente basso, come con un'applicazione aziendale interna.
Generare un indice iniziale per determinare il modo in cui i dati di origine vengono convertiti in un indice. Questo è l'unico modo per stimare le dimensioni di un indice. Gli attributi nelle definizioni dei campi influiscono sui requisiti di archiviazione fisica:
Per la ricerca di parole chiave, contrassegnare i campi come filtrabili e ordinabili per aumentare le dimensioni dell'indice.
Per la ricerca vettoriale, è possibile impostare i parametri per ridurre l'archiviazione.
Monitorare l'archiviazione, i limiti del servizio, il volume di query e la latenza nel portale. Il portale mostra le query al secondo, le query limitate e la latenza di ricerca. Tutti questi valori aiutano a decidere se è stato selezionato il livello corretto.
Aggiungere repliche per la disponibilità elevata o ridurre il numero di query lente.
Non sono disponibili linee guida sul numero di repliche necessarie per supportare i carichi di query. Le prestazioni delle query dipendono dalla complessità delle query e dai carichi di lavoro concorrenti. Sebbene l'aggiunta di repliche consenta certamente di migliorare le prestazioni, il risultato non è strettamente lineare. L'aggiunta di tre repliche, infatti, non garantisce una velocità effettiva triplicata. Per indicazioni sulla stima di QPS per la soluzione, vedere Analizzare le prestazioni e Monitorare le query.
In un indice invertito le dimensioni e la complessità dipendono dal contenuto, non necessariamente dalla quantità di dati inseriti. Un'origine dati di grandi dimensioni con una ridondanza elevata può generare un indice più piccolo rispetto a un set di dati di dimensioni minori che include contenuto altamente variabile. Per questa ragione raramente è possibile dedurre le dimensioni dell'indice in base alle dimensioni del set di dati originale.
I requisiti di archiviazione possono aumentare se si includono dati che non verranno mai cercati. In teoria, i documenti contengono solo i dati necessari per l'esperienza di ricerca.
Considerazioni sul contratto di servizio
Le funzionalità di livello gratuito e anteprima non sono coperte dai contratti di servizio. Per tutti i livelli fatturabili, i contratti di servizio diventano effettivi quando viene effettuato il provisioning di una ridondanza sufficiente per il servizio.
Due o più repliche soddisfano i contratti di servizio di query (lettura).
Tre o più repliche soddisfano i contratti di servizio di query e indicizzazione (lettura/scrittura).
Il numero di partizioni non influisce sui contratti di servizio.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per