Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo è una raccolta di suggerimenti e procedure consigliate per migliorare le prestazioni delle query e dell'indicizzazione per la ricerca di parole chiave. Conoscere quali fattori hanno maggiore probabilità di influire sulle prestazioni della ricerca può aiutare a evitare inefficienze e sfruttare al meglio il servizio di ricerca. Alcuni fattori chiave includono:
- Composizione dell'indice (schema e dimensioni)
- Struttura delle query
- Capacità del servizio (livello e numero di repliche e partizioni)
Nota
Si stanno cercando strategie per l'indicizzazione di volumi elevati? Vedere Indicizzare set di dati di grandi dimensioni in Azure AI Search.
Dimensioni e schema dell'indice
Le query vengono eseguite più velocemente su indici più piccoli. Si tratta in parte di una funzione che consente di avere meno campi da analizzare, ma anche del modo in cui il sistema memorizza nella cache il contenuto per le query future. Dopo la prima query, alcuni contenuti rimangono in memoria, dove la ricerca viene eseguita in modo più efficiente. Poiché le dimensioni degli indici tendono a crescere nel tempo, è consigliabile rivedere periodicamente la composizione degli indici, sia lo schema che i documenti, per cercare opportunità di riduzione del contenuto. Tuttavia, se l'indice è di dimensioni corrette, l'unica altra calibrazione che è possibile eseguire consiste nell'aumentare la capacità aggiornando il servizio, aggiungendo repliche o passando a un piano tariffario superiore. La sezione "Suggerimento: passare a un livello Standard S2" illustra la decisione di aumentare le prestazioni rispetto alla scalabilità orizzontale.
La complessità dello schema può anche influire negativamente sull'indicizzazione e sulle prestazioni delle query. L’attribuzione eccessiva dei campi si basa su limitazioni e requisiti di elaborazione. I tipi complessi richiedono più tempo per indicizzare ed eseguire query. Le sezioni successive esplorano ogni condizione.
Suggerimento: essere selettivi nell'attribuzione dei campi
Un errore comune che gli amministratori e gli sviluppatori commettono al momento di creare un indice di ricerca è quello di selezionare tutte le proprietà disponibili per i campi, invece di selezionare solo le proprietà necessarie. Ad esempio, se non è necessario che un campo sia ricercabile per testo completo, saltare tale campo quando si imposta l'attributo ricercabile.
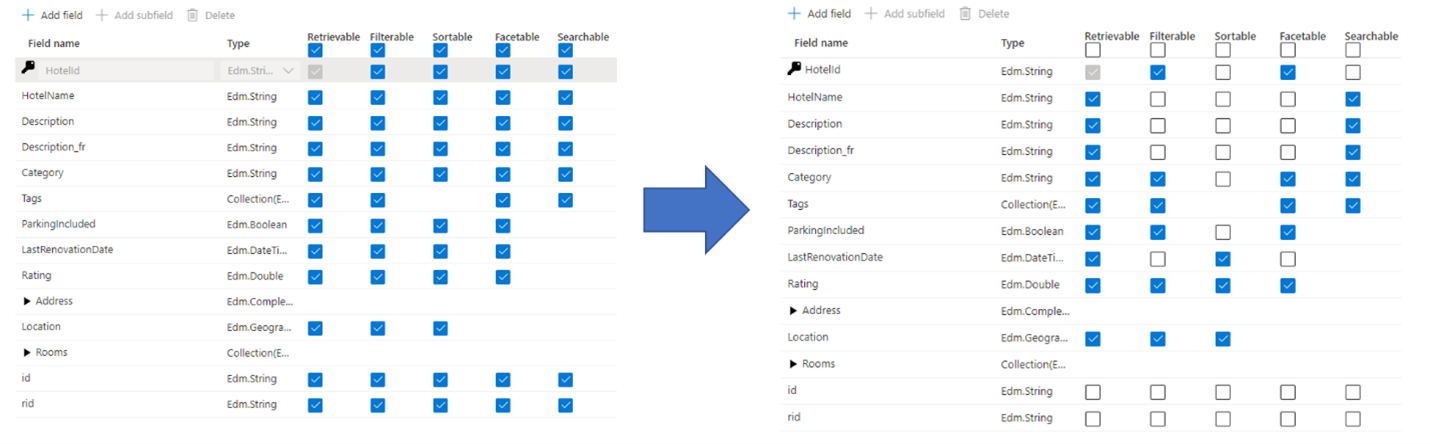
Il supporto per i filtri, i facet e l'ordinamento possono quadruplicare i requisiti di archiviazione. Se si aggiungono suggerimenti, i requisiti di archiviazione aumentano ancora di più. Per un'illustrazione dell'impatto degli attributi sull'archiviazione, vedere Attributi e dimensioni dell'indice.
Riepilogando, le ramificazioni dell'attribuzione eccessiva includono:
Riduzione delle prestazioni di indicizzazione a causa del lavoro aggiuntivo necessario per elaborare il contenuto nel campo, quindi archiviarlo all'interno dell'indice invertito di ricerca (impostare l'attributo "ricercabile" solo nei campi che contengono contenuto ricercabile).
Crea una superficie più grande che ogni query deve coprire. Tutti i campi contrassegnati come ricercabili vengono analizzati in una ricerca full-text.
Aumenta i costi operativi dovuti all'archiviazione aggiuntiva. Il filtro e l'ordinamento richiedono spazio aggiuntivo per l'archiviazione di stringhe originali (non analizzate). Evitare di impostare campi filtrabili o ordinabili dove non vi è necessità.
In molti casi, l'attribuzione eccessiva limita le funzionalità del campo. Ad esempio, se un campo è facettabile, filtrabile e ricercabile, è possibile archiviare solo 16 KB di testo all'interno di un campo, mentre un campo ricercabile può contenere fino a 16 MB di testo.
Nota
Nota
Evitare l'attribuzione di campi non necessari, ma non rimuovere funzionalità essenziali per l'esperienza di ricerca. I filtri e i facet sono spesso funzionalità principali e, quando si usa il filtro, l'ordinamento è in genere necessario per produrre risultati ordinati. Applicate gli attributi deliberatamente, solo quando sono necessari per soddisfare reali esigenze di query o dell'interfaccia utente.
Suggerimento: prendere in considerazione le alternative ai tipi complessi
I tipi di dati complessi sono utili quando i dati hanno una struttura annidata complessa, ad esempio gli elementi padre-figlio presenti nei documenti JSON. Lo svantaggio dei tipi complessi è costituito dai requisiti di archiviazione aggiuntivi e dalle risorse aggiuntive necessarie per indicizzare il contenuto, rispetto ai tipi di dati non complessi.
In alcuni casi, è possibile evitare questi compromessi eseguendo il mapping di una struttura di dati complessa a un tipo di campo più semplice, ad esempio una raccolta. In alternativa, è possibile scegliere di rendere bidimensionale una gerarchia di campi in singoli campi a livello radice.

Struttura delle query
La composizione e la complessità delle query sono tra i fattori più importanti per le prestazioni, e l'ottimizzazione delle query può migliorare drasticamente le prestazioni. Quando si progettano query, considerare i punti seguenti:
Numero di campi ricercabili. Ogni campo ricercabile aggiuntivo comporta lavoro aggiuntivo per il servizio di ricerca. È possibile limitare la ricerca dei campi in fase di query usando il parametro “searchFields”. È consigliabile specificare solo i campi a cui si è interessati per migliorare le prestazioni.
Quantità di dati restituiti. Il recupero di una grande quantità di contenuti può rallentare le query. Quando si struttura una query, restituire solo i campi di cui è necessario eseguire il rendering della pagina dei risultati, quindi recuperare i campi rimanenti usando l'API Ricerca dopo che un utente seleziona una corrispondenza.
Uso di ricerche di termini parziali. Le ricerche di termini parziali, ad esempio la ricerca con prefisso, la ricerca fuzzy e la ricerca di espressioni regolari, sono più costose in termini di calcolo rispetto alle ricerche di parole chiave, in quanto richiedono scansioni di indici completi per produrre i risultati.
Numero di facette. L'aggiunta di facet alle query richiede aggregazioni per ogni query. La richiesta di un "conteggio" più elevato per un facet richiede anche un lavoro aggiuntivo da parte del servizio. In generale, aggiungere solo i facet di cui si prevede di eseguire il rendering nell'app ed evitare di richiedere un conteggio elevato per i facet, a meno che non sia necessario.
Valori skip elevati. L'impostazione del parametro
$skipsu un valore elevato (ad esempio, in migliaia) aumenta la latenza di ricerca perché il motore recupera e classifica un volume superiore di documenti per ogni richiesta. Per motivi di prestazioni, è consigliabile evitare valori$skipelevati e usare invece altre tecniche, ad esempio filtri, per recuperare un numero elevato di documenti.Limitare i campi a cardinalità elevata. Un campo a cardinalità elevata si riferisce a un campo a cui è possibile applicare facet o filtri e che dispone di un numero significativo di valori univoci e, di conseguenza, richiede molte risorse per calcolare i risultati. Ad esempio, l'impostazione di un campo ID prodotto o la descrizione come facet e filtrabile rappresenterebbe un'elevata cardinalità perché la maggior parte dei valori dei documenti è univoca.
Suggerimento: usare le funzioni di ricerca anziché eseguire l'overload dei criteri di filtro
Poiché una query usa criteri di filtro sempre più complessi, le prestazioni della query di ricerca risulteranno ridotte. Si consideri l'esempio seguente che illustra l'uso dei filtri per tagliare i risultati in base a un'identità utente:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
In questo caso, le espressioni di filtro vengono usate per verificare se un singolo campo in ogni documento è uguale a uno dei molti valori possibili di un'identità utente. È molto probabile trovare questo modello nelle applicazioni che implementano la limitazione per motivi di sicurezza (verificando un campo contenente uno o più ID entità di sicurezza rispetto a un elenco di ID entità di sicurezza che rappresentano l'utente che esegue la query).
Un modo più efficiente per eseguire filtri che contengono un numero elevato di valori consiste nell'usare la funzionesearch.in, come illustrato in questo esempio:
search.in(userid, '123,234,345,456,567', ',')
Suggerimento: aggiungere partizioni per singole query lente
Quando le prestazioni delle query rallentano in generale, l'aggiunta di più repliche risolve spesso il problema. Ma cosa accade se il problema è una singola query che richiede troppo tempo per il completamento? In questo scenario, l'aggiunta di repliche non sarà utile, ma potrebbero esserlo più partizioni. Una partizione suddivide i dati tra risorse di calcolo aggiuntive. Due partizioni suddividono i dati a metà, una terza partizione li divide in terzi, e così via.
Un effetto secondario positivo dell'aggiunta di partizioni è che le query più lente a volte vengono eseguite più velocemente a causa del calcolo parallelo. È stata annotata la parallelizzazione su query a bassa selettività, ad esempio query che corrispondono a molti documenti o facet che forniscono conteggi su un numero elevato di documenti. Poiché sono necessari molti calcoli per valutare la rilevanza dei documenti o per calcolare il numero dei documenti, l'aggiunta di altre partizioni consente un completamento più rapido delle query.
Per aggiungere partizioni, usare il portale di Azure, PowerShell, l'interfaccia della riga di comando di Azure o un SDK di gestione.
Capacità del servizio
Un servizio viene sovraccaricato quando le query richiedono troppo tempo o quando il servizio avvia l'eliminazione delle richieste. In questo caso, è possibile risolvere il problema aggiornando il servizio o aggiungendo capacità.
Anche il livello del servizio di ricerca e il numero di repliche/partizioni hanno un impatto elevato sulle prestazioni di sistema. Ogni livello progressivamente superiore offre CPU più veloci e più memoria, entrambe con un impatto positivo sulle prestazioni.
Suggerimento: creare un nuovo servizio di ricerca ad alta capacità
I servizi Basic e Standard creati nelle aree supportate dopo il 3 aprile 2024 hanno più spazio di archiviazione per partizione rispetto ai servizi meno recenti. Se si dispone di un servizio meno recente, verificare se è possibile aggiornare il servizio per trarre vantaggio da una maggiore capacità con la stessa tariffa di fatturazione. Se non è disponibile un aggiornamento, esaminare i limiti del servizio di livello per verificare se lo stesso livello in un servizio più recente offre lo spazio di archiviazione necessario.
Suggerimento: passare a un livello Standard S2
Il livello di ricerca Standard S1 è spesso quello da cui i clienti iniziano. Un modello comune per i servizi S1 è che gli indici aumentano nel tempo, e ciò richiede più partizioni. Più partizioni comportano tempi di risposta più lenti, quindi vengono aggiunte più repliche per gestire il carico della query. Come si può immaginare, il costo di esecuzione di un servizio S1 è ora progredito a livelli superiori rispetto alla configurazione iniziale.
In questo momento, una domanda importante da porre è se sarebbe utile passare a un piano tariffario superiore, anziché aumentare progressivamente il numero di partizioni o repliche del servizio corrente.
Si consideri la topologia seguente come esempio di servizio che ha assunto livelli crescenti di capacità:
- Livello S1 Standard
- Le dimensioni dell'indice: 190 GB
- Conteggio partizioni: 8 (in S1, le dimensioni della partizione sono di 25 GB per partizione)
- Numero di repliche: 2
- Totale unità di ricerca: 16 (8 partizioni x 2 repliche)
- Ipotetico prezzo al dettaglio: circa 4.000 USD/mese (supponendo 250 USD x 16 unità di ricerca)
Si supponga che l'amministratore del servizio stia ancora riscontrando frequenze di latenza più elevate e stia valutando l'aggiunta di un'altra replica. In questo modo il numero di repliche verrebbe modificato da 2 a 3 e, di conseguenza, il conteggio delle unità di ricerca viene modificato in 24, con un prezzo risultante pari a 6.000 USD/mese.
Tuttavia, se l'amministratore ha scelto di passare a un livello Standard S2, la topologia sarà simile alla seguente:
- Livello Standard S2
- Le dimensioni dell'indice: 190 GB
- Conteggio partizioni: 2 (in S2, le dimensioni della partizione sono di 100 GB per partizione)
- Numero di repliche: 2
- Totale unità di ricerca: 4 (2 partizioni x 2 repliche)
- Ipotetico prezzo al dettaglio: circa 4.000 USD/mese (supponendo 1.000 USD x 4 unità di ricerca)
Come illustrato in questo scenario ipotetico, è possibile avere configurazioni su livelli inferiori che comportano costi simili, come se inizialmente si fosse scelto un livello superiore. Tuttavia, i livelli più elevati sono dotati di archiviazione Premium, che rende l'indicizzazione più veloce. I livelli più elevati hanno anche molta più potenza di calcolo, oltre a memoria aggiuntiva. Agli stessi costi, si potrebbe avere un'infrastruttura più potente che esegue il backup dello stesso indice.
Un vantaggio importante della memoria aggiunta è che è possibile memorizzare nella cache una parte maggiore dell’indice, con conseguente riduzione della latenza di ricerca e un numero maggiore di query al secondo. Con questa potenza aggiuntiva, l'amministratore potrebbe non dover aumentare il conteggio delle repliche e potrebbe pagare meno rispetto a rimanere nel servizio S1.
Suggerimento: prendere in considerazione le alternative alle query di espressioni regolari
Le query di espressioni regolari o regex possono essere particolarmente costose. Anche se possono essere molto utili per le ricerche avanzate, l'esecuzione può richiedere molta potenza di elaborazione, soprattutto se l'espressione regolare è complessa o se si esegue una ricerca in una grande quantità di dati. Tutti questi fattori contribuiscono a una latenza di ricerca elevata. Per la mitigazione, provare a semplificare l'espressione regolare o a suddividere la query complessa in query più piccole e gestibili.
Passaggi successivi
Esaminare questi altri articoli relativi alle prestazioni del servizio: