Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La ricerca full-text è un approccio al recupero delle informazioni che individua corrispondenze con testo normale archiviato in un indice. Ad esempio, data una stringa di query "hotels in San Diego on the beach", il motore di ricerca cerca stringhe con token in base a tali termini. Per rendere le analisi più efficienti, le stringhe di query vengono sottoposte ad analisi lessicali: l'uso di minuscole per tutti i termini, la rimozione di parole non significative come "the" e la riduzione dei termini alle forme radice primitive. Quando vengono trovati termini corrispondenti, il motore di ricerca recupera i documenti, li classifica in ordine di pertinenza e restituisce i risultati principali.
L'esecuzione di query può essere complessa. Questo articolo si rivolge agli sviluppatori che hanno bisogno di una conoscenza più approfondita circa il funzionamento della ricerca full-text in Azure AI Search. Per le query di testo, Azure AI Search fornisce i risultati previsti nella maggior parte degli scenari, ma in alcuni casi è possibile ottenere un risultato che sembrerà in qualche modo "strano". In questi casi la presenza di uno sfondo nelle quattro fasi dell'esecuzione di query di Lucene (analisi delle query, analisi lessicale, abbinamento dei documenti, assegnazione dei punteggi) consente di identificare le modifiche specifiche per i parametri di query o per la configurazione di indice che garantisce il risultato desiderato.
Nota
Azure AI Search usa Apache Lucene per la ricerca full-text, ma l'integrazione con Lucene non è completa. Le funzionalità Lucene vengono esposte ed estese in modo selettivo per abilitare gli scenari importanti per Azure AI Search.
Panoramica e diagramma dell'architettura
L'esecuzione di query presenta quattro fasi:
- Analisi della query
- Analisi lessicale
- Recupero dei documenti
- Punteggio
Una query di ricerca full-text inizia con l'analisi del testo della query per estrarre i termini di ricerca e gli operatori. Sono disponibili due parser in modo da poter scegliere tra velocità e complessità. La fase successiva è l'analisi, in cui i singoli termini di query vengono talvolta suddivisi e ricostituiti in nuove forme. Questo passaggio consente di eseguire il cast di una rete più ampia su ciò che può essere considerato come una potenziale corrispondenza. Il motore di ricerca analizza quindi l'indice per trovare documenti con termini corrispondenti e assegna un punteggio a ogni corrispondenza. Un set di risultati viene quindi ordinato sulla base di un punteggio di pertinenza assegnato a ogni singolo documento corrispondente. Quelli nella parte superiore dell'elenco di pertinenza vengono restituiti all'applicazione chiamante.
Il diagramma seguente illustra i componenti usati per elaborare una richiesta di ricerca.
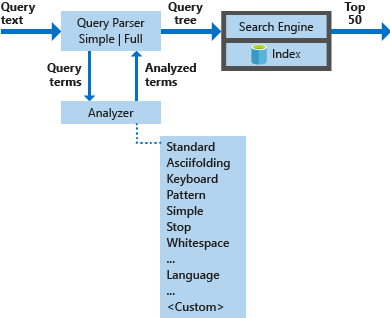
| Componenti principali | Descrizione funzionale |
|---|---|
| Parser della query | Separare i termini della query dagli operatori della query e creare la struttura della query (un albero di query) da inviare al motore di ricerca. |
| Analizzatori | Eseguire l'analisi lessicale sui termini della query. Questo processo può implicare la trasformazione, la rimozione o l'espansione dei termini della query. |
| Indice | Una struttura efficiente dei dati usata per archiviare e organizzare i termini ricercabili estratti da documenti indicizzati. |
| Motore di ricerca | Recupera e assegna i punteggi di documenti corrispondenti in base al contenuto dell'indice invertito. |
Anatomia di una richiesta di ricerca
Una richiesta di ricerca è una specifica completa di ciò che deve essere restituito in un set di risultati. Nella forma più semplice, è una query vuota senza alcun tipo di criterio. Un esempio più realistico include parametri, termini di query diversi, forse con ambito in determinati campi, con eventualmente un'espressione filtro e regole di ordinamento.
L'esempio seguente è una richiesta di ricerca che è possibile inviare ad Azure AI Search tramite l'API REST.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Per questa richiesta, il motore di ricerca esegue le operazioni seguenti:
Trova i documenti in cui il prezzo è almeno 60 USD e meno di 300 USD.
Esegue la query. In questo esempio la query di ricerca è costituita da frasi e termini:
"Spacious, air-condition* +\"Ocean view\""(gli utenti in genere non immettono segni di punteggiatura, ma includerli nell'esempio consente di spiegare come la gestiscono gli analizzatori).Per questa query, il motore di ricerca esegue la scansione della descrizione e dei campi del titolo specificati in "searchFields" per i documenti che contengono
"Ocean view"e anche il termine"spacious"o i termini che iniziano con il prefisso"air-condition". Il parametro "searchMode" viene usato per l'abbinamento con qualsiasi termine (impostazione predefinita) o con tutti i termini, per i casi in cui un termine non è esplicitamente richiesto (+).Ordina il set risultante degli hotel in prossimità di una posizione geografica specificata e quindi restituisce i risultati all'applicazione chiamante.
La maggior parte di questo articolo riguarda l'elaborazione di query di ricerca: "Spacious, air-condition* +\"Ocean view\"". Il filtro e l'ordinamento non appartengono all'ambito. Per altre informazioni, vedere la Documentazione di riferimento dell'API di Ricerca.
Fase 1: Analisi della query
Come accennato, la stringa della query è la prima riga della richiesta:
"search": "Spacious, air-condition* +\"Ocean view\"",
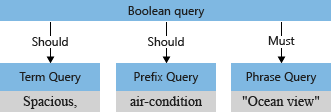
Il parser della query separa gli operatori (ad esempio * e + nell'esempio) dalla ricerca di termini e annulla la costruzione della query di ricerca in sottoquery di un tipo supportato:
- query del termine per i termini singoli (ad esempio spazioso)
- query della frase per i termini tra virgolette (ad esempio vista oceano)
-
query del prefisso per i termini seguiti da un operatore prefisso
*(ad esempio, aria condizionata)
Per un elenco completo dei tipi di query supportati vedere Sintassi di query Lucene
Gli operatori associati a una sottoquery determinano se la query "deve essere" o "dovrebbe essere" soddisfatta al fine di considerare un documento come corrispondenza. Ad esempio, +"Ocean view" è "deve" in virtù dell'operatore +.
Il parser della query ristruttura le sottoquery in un albero della query (una struttura interna che rappresenta la query) e la trasmette al motore di ricerca. Nella prima fase di analisi della query, l'albero della query appare come segue.
Parser supportati: Lucene semplice e completa
Azure AI Search espone due diversi linguaggi di query, simple (impostazione predefinita) e full. Impostando il parametro queryType con la richiesta di ricerca, si indica al parser della query quale linguaggio di query si sceglie in modo che sappia come interpretare gli operatori e la sintassi.
Il linguaggio semplice della query è intuitivo e potente, spesso adatto a interpretare l'input dell'utente così come si presenta, senza elaborazione dal lato client. Supporta operatori di query familiari dai motori di ricerca Web.
Il Linguaggio di query Lucene Full, che si ottiene impostando
queryType=full, estende il linguaggio di query semplice di impostazione predefinita aggiungendo il supporto per più operatori e tipi di query quali carattere jolly, fuzzy, regex e query con ambito campo. Ad esempio, un'espressione regolare inviata nella sintassi di query semplice verrebbe interpretata come una stringa di query e non come un'espressione. La richiesta di esempio in questo articolo usa il linguaggio di query Lucene Full.
Impatto di searchMode sul parser
Un altro parametro di richiesta di ricerca che influisce sull'analisi è il parametro "searchMode". Questo parametro controlla l'operatore predefinito per le query booleane: qualsiasi (predefinita) o tutte.
Quando "searchMode=any", ovvero il valore predefinito, il delimitatore tra spacious e air-condition è OR (||) e il testo di query di esempio è quindi equivalente a:
Spacious,||air-condition*+"Ocean view"
Gli operatori espliciti, ad esempio + in +"Ocean view", non sono ambigui nella costruzione di query booleana (il termine deve corrispondere). Come interpretare i termini rimanenti è meno ovvio: spazioso e aria condizionata. Il motore di ricerca dovrebbe trovare corrispondenze su vista sull'oceano and spazioso and aria condizionata? O dovrebbe trovare vista sull'oceano più uno dei termini rimanenti?
Per impostazione predefinita ("searchMode=any"). Il motore di ricerca presuppone l'interpretazione più ampia. Uno dei campi dovrebbe essere associato, riflettendo la semantica di "or". L'albero della query iniziale illustrato in precedenza, con due operazioni "should", mostra il valore predefinito.
Si supponga di impostare "searchMode=all". In questo caso, lo spazio viene interpretato come un'operazione "and". Ciascuno dei termini rimanenti deve essere presente nel documento per essere considerato come corrispondenza. La query di esempio risultante verrebbe interpretata nel modo seguente:
+Spacious,+air-condition*+"Ocean view"
Un albero di query modificato per questa query sarà come segue, se un documento corrispondente è l'intersezione di tutte e tre le sottoquery:

Nota
È consigliabile decidere di scegliere "searchMode=any" rispetto a "searchMode=all" dopo l'esecuzione di query rappresentative. Gli utenti che molto probabilmente includono operatori (comune quando si eseguono ricerche nell'archivio dei documenti) potrebbero trovare risultati più intuitivi se "searchMode=all" informa i costrutti della query booleana. Per altre informazioni sull'interazione tra "searchMode" e gli operatori, vedere Sintassi di query semplice.
Fase 2: Analisi lessicale
Gli analizzatori lessicali elaborano le query del termine e le query della frase dopo aver strutturato l'albero della query. Un analizzatore accetta gli input di testo assegnati dal parser, elabora il testo e quindi invia nuovamente in formato token i termini da incorporare nell'albero della query.
La forma più comune di analisi lessicale è l'*analisi linguistica che trasforma i termini della query in base a regole specifiche per un determinato linguaggio:
- Riduzione di un termine della query nella forma radice di una parola
- Rimozione di parole non essenziali (parole non significative, ad esempio "the" o "and" in inglese)
- Suddivisione di una parola composta nelle parti che la compongono
- Trasformazione in lettere minuscole di una parola in lettere maiuscole
Tutte queste operazioni tendono a cancellare le differenze tra l'input del testo fornito dall'utente e i termini archiviati nell'indice. Tali operazioni vanno oltre l'elaborazione del testo e richiedono una conoscenza approfondita del linguaggio. Per aggiungere questo livello di consapevolezza linguistica, Azure AI Search supporta un lungo elenco di analizzatori della lingua di Microsoft e Lucene.
Nota
I requisiti per l'analisi possono variare da minimi a elaborati a seconda dello scenario. È possibile controllare la complessità dell'analisi lessicale quando si seleziona uno degli analizzatori predefiniti o creando il proprio analizzatore personalizzato. Gli analizzatori sono limitati a campi ricercabili e vengono specificati come parte di una definizione di campo. Ciò consente di variare l'analisi lessicale in base al campo. Se non è specificato, viene usato l'analizzatore Lucene standard.
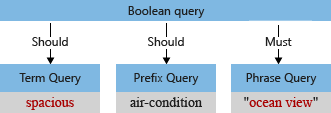
Nel nostro esempio prima dell'analisi l'albero della query iniziale contiene il termine "Spacious,", con una "S" maiuscola e una virgola, che il parser della query interpreta come parte del termine della query (la virgola non viene considerata come operatore di linguaggio della query).
Quando l'analizzatore predefinito elabora il termine, renderà con lettere minuscole "vista sull'oceano" e "spazioso" e rimuoverà il carattere di virgola. L'albero delle query modificato è simile al seguente:
Comportamenti dell'analizzatore del test
Il comportamento di un analizzatore può essere testato usando l'API Analyze. Fornire il testo da analizzare per vedere quali termini specificati vengono generati dall'analizzatore. Ad esempio, per visualizzare il modo in cui l'analizzatore standard elabora il testo "aria condizionata", è possibile eseguire la richiesta seguente:
{
"text": "air-condition",
"analyzer": "standard"
}
L'analizzatore standard suddivide il testo di input nei due token seguenti, annotandoli con attributi quali offset iniziale e finale (usati per l'evidenziazione dei risultati), nonché con la loro posizione (usata per la corrispondenza di una frase):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Eccezioni all'analisi lessicale
L'analisi lessicale si applica solo ai tipi di query che richiedono termini completi, una query di termine o una query di frase. Non si applica ai tipi di query con termini incompleti: query di prefisso, query con caratteri jolly, query regex o query fuzzy. Questi tipi di query, tra cui la query di prefisso con il termine air-condition* nel nostro esempio, vengono aggiunti direttamente all'albero della query, ignorando la fase di analisi. L'unica trasformazione eseguita per i termini della query di queste tipologie è la conversione in lettere minuscole.
Fase 3: Recupero dei documenti
Il recupero dei documenti fa riferimento alla ricerca di documenti con termini corrispondenti all'indice. Questa fase viene spiegata meglio attraverso un esempio. Iniziamo con un indice degli hotel che presenta il seguente schema semplice:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Si supponga anche che l'indice contenga i seguenti quattro documenti:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Come vengono indicizzati termini
Comprendere il recupero è utile per conoscere alcune nozioni di base sull'indicizzazione. L'unità di archiviazione è un indice invertito, uno per ogni campo ricercabile. In un indice invertito è presente un elenco ordinato di tutti i termini derivanti da tutti i documenti. Ogni termine esegue il mapping nell'elenco di termini in cui si verifica, come si evince nell'esempio seguente.
Per produrre i termini in un indice inverso, il motore di ricerca esegue l'analisi lessicale del contenuto dei documenti, analogamente a quanto accade durante l'elaborazione delle query:
- Gli input di testo vengono passati a un analizzatore, in lettere minuscole, prive di punteggiatura e così via, a seconda della configurazione dell'analizzatore.
- I token sono l'output dell'analisi lessicale.
- I termini vengono aggiunti all'indice.
È comune, ma non obbligatorio, usare gli stessi analizzatori per la ricerca e le operazioni di indicizzazione in modo che i termini di query assomiglino di più ai termini contenuti nell'indice.
Nota
Azure AI Search consente di specificare diversi analizzatori per l'indicizzazione e la ricerca tramite parametri di campo aggiuntivi indexAnalyzer e searchAnalyzer. Se non è specificato, l'analizzatore impostato con la proprietà analyzer viene usato per l'indicizzazione e la ricerca.
Indice invertito per i documenti di esempio
Ritornando all'esempio precedente, per il campo titolo, l'indice invertito è simile al seguente:
| Termine | Elenco di documenti |
|---|---|
| atman | 1 |
| spiaggia | 2 |
| hotel | 1, 3 |
| oceano | 4 |
| playa | 3 |
| resort | 3 |
| rifugio | 4 |
Nel campo del titolo, solo hotel viene visualizzato in due documenti: 1, 3.
Per il campo descrizione, l'indice è il seguente:
| Termine | Elenco di documenti |
|---|---|
| air | 3 |
| e | 4 |
| spiaggia | 1 |
| condizionata | 3 |
| comodo | 3 |
| distance | 1 |
| isola | 2 |
| kauaʻi | 2 |
| posizionato | 2 |
| nord | 2 |
| oceano | 1, 2, 3 |
| di | 2 |
| on | 2 |
| quiet | 4 |
| camere | 1, 3 |
| appartato | 4 |
| costa | 2 |
| spazioso | 1 |
| il | 1, 2 |
| to | 1 |
| view | 1, 2, 3 |
| passeggiata | 1 |
| con | 3 |
Corrispondenza dei termini di query con i termini indicizzati
Dati gli indici invertiti precedenti, tornare alla query di esempio e vedere come si trovano i documenti corrispondenti per la query di esempio. Tenere presente che l'albero della query finale ha il seguente aspetto:
Durante l'esecuzione delle query, le singole query vengono eseguite sulla base dei campi ricercabili in modo indipendente.
Il TermQuery "spazioso" corrisponde al documento 1 (Hotel Atman).
Il PrefixQuery "aria-condizionata*" non corrisponde a nessun documento.
Si tratta di un comportamento che a volte confonde gli sviluppatori. Sebbene il termine air-conditioned esista nel documento, è suddiviso in due termini dall'analizzatore predefinito. È importante ricordare che le query di prefisso, che contengono termini parziali, non vengono analizzate. Di conseguenza termini con prefisso "aria condizionata" vengono cercati nell'indice invertito e non trovati.
La PhraseQuery "vista sull'oceano" cerca i termini "oceano" e "vista" e controlla la prossimità dei termini nel documento originale. I documenti 1, 2 e 3 abbinano questa query nel campo della descrizione. Si noti che il documento 4 contiene il termine oceano, ma non è considerata una corrispondenza poiché stiamo cercando la frase "vista sull'oceano" e non le singole parole.
Nota
Viene eseguita una query di ricerca in modo indipendente in tutti i campi disponibili per la ricerca nell'indice di Azure AI Search, a meno che non si superino i campi impostati con il parametro searchFields, come illustrato nella richiesta di ricerca di esempio. Vengono restituiti i documenti corrispondenti in uno dei campi selezionati.
Nel complesso, per la query in questione, i documenti corrispondenti sono 1, 2, 3.
Fase 4: Assegnazione dei punteggi
Ad ogni documento in un set di risultati di ricerca viene assegnato un punteggio di pertinenza. La funzione del punteggio di pertinenza è di posizionare in alto in classifica quei documenti che meglio rispondono a una domanda utente espressa dalla query di ricerca. Il punteggio viene calcolato in base alle proprietà statistiche dei termini che corrispondono. Alla base della formula del punteggio è presente la ponderazione TF/IDF (frequenza del termine - frequenza inversa del documento). Nelle query che contengono termini rari e comuni, il TF/IDF promuove i risultati contenenti il termine raro. Ad esempio, in un indice ipotetico con tutti gli articoli di Wikipedia, dai documenti che corrispondono alla query il presidente, i documenti che corrispondono a presidente sono considerati più pertinenti dei documenti corrispondenti con il.
Esempio di assegnazione dei punteggi
Richiamare i tre documenti che corrispondono alla query di esempio:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Il documento 1 corrisponde alla query migliore poiché sia il termine spazioso sia la frase richiesta vista sull'oceano si verificano nel campo descrizione. I due documenti successivi corrispondono solo per la frase vista sull'oceano. È sorprendente constatare che il punteggio di pertinenza per i documenti 2 e 3 è diverso, anche se essi corrispondono alla query nello stesso modo. Ciò avviene perché la formula di assegnazione del punteggio include più componenti rispetto a TF/IDF. In questo caso al documento 3 è stato assegnato un punteggio leggermente maggiore perché la sua descrizione è più breve. Informazioni sulla formula Lucene per il punteggio pratico per comprendere in che modo la lunghezza del campo e altri fattori possono influenzare il punteggio di pertinenza.
Alcuni tipi di query (carattere jolly, prefisso, regex) contribuiscono sempre con un punteggio costante al punteggio complessivo del documento. Questo permette alle corrispondenze trovate tramite l'espansione della query di essere incluse nei risultati, ma senza modificare la classifica.
Un esempio illustra il motivo per cui questo risulta importante. Le ricerche con caratteri jolly, tra cui le ricerche con prefisso, sono ambigue per definizione poiché l'input è una stringa parziale con potenziali corrispondenze in un numero molto elevato di termini diversi (si consideri un input di "tour*", con corrispondenze trovate in "tour", "tourettes" e "tourmaline"). Data la natura di questi risultati, non è possibile dedurre ragionevolmente quali termini risultino più utili rispetto ad altri. Per questo motivo, verranno ignorate le frequenze di termini durante l'assegnazione dei punteggi dei risultati nelle query di tipo con caratteri jolly, prefisso e regex. In una richiesta di ricerca a più parti che comprende termini parziali e completi, i risultati dall'input parziale sono incorporati con un punteggio costante per evitare la distorsione verso risultati potenzialmente imprevisti.
Ottimizzazione della pertinenza
Esistono due modi per ottimizzare i punteggi di pertinenza in Azure AI Search:
I profili di punteggio promuovono i documenti nell'elenco di pertinenza dei risultati in base a un set di regole. Nel nostro esempio è possibile considerare i documenti che corrispondono al campo del titolo più rilevanti rispetto ai documenti corrispondenti al campo della descrizione. In aggiunta, se l'indice dispone di un campo prezzo per ogni albergo, è possibile promuovere i documenti con prezzo inferiore. Altre informazioni sull'aggiunta di profili di punteggio a un indice di ricerca.
Aumento priorità dei termini (disponibile solo nella sintassi di query Lucene Full) offre un aumento della priorità dell'operatore
^che può essere applicato a qualsiasi parte dell'albero della query. Nell'esempio anziché cercare il prefisso air-condition*, è possibile cercare il termine esatto air-condition o il prefisso, ma i documenti che corrispondono al termine esatto si trovano in una posizione più alta applicando l'aumento della priorità alla query del termine: air-condition^2||air-condition*. Altre informazioni sull'aumento della priorità dei termini in una query.
Assegnazione dei punteggi in un indice distribuito
Tutti gli indici in Azure AI Search sono automaticamente suddivisi in più partizioni, consentendo di distribuire rapidamente l'indice tra più nodi durante l'aumento o la riduzione delle prestazioni del servizio. Quando viene eseguita una richiesta di ricerca, viene generata in ogni partizione in modo indipendente. I risultati di ogni partizione vengono uniti e ordinati in base al punteggio (se non è definito nessun altro ordine). È importante sapere che la funzione di assegnazione dei punteggi pesa la frequenza del termine della query rispetto alla frequenza inversa del documento in tutti i documenti all'interno della partizione, non in tutte le partizioni.
Ciò significa che un punteggio di pertinenza potrebbe essere diverso per documenti identici se si trovano in partizioni diverse. Fortunatamente, queste differenze tendono a scomparire man mano che aumenta il numero di documenti nell'indice a causa anche di altre distribuzioni del termine. Non è possibile presumere in quale partizione verrà inserito un documento specifico. Tuttavia, dando per assunto che una chiave del documento non cambia, verrà sempre assegnata alla stessa partizione.
In genere, il punteggio del documento non è l'attributo migliore per l'ordinamento dei documenti se la stabilità dell'ordine è importante. Ad esempio, dati due documenti con un punteggio identico, non vi sono garanzie circa quale sarà visualizzato per primo in esecuzioni successive della stessa query. Il punteggio del documento deve solo dare un'idea generale della pertinenza del documento relativo ad altri documenti nel set di risultati.
Conclusione
Il successo dei motori di ricerca commerciali ha generato aspettative per la ricerca full-text su dati privati. Per quasi tutti i tipi di esperienza di ricerca, è ora previsto che il motore comprenda il nostro obiettivo, anche quando i termini sono errati o incompleti. Ci si potrebbero anche aspettare corrispondenze basate su termini quasi equivalenti o sinonimi mai specificati.
Dal punto di vista tecnico, la ricerca full-text è estremamente complessa, richiede un'analisi linguistica sofisticata e un approccio sistematico all'elaborazione in modo tale da filtrare, espandere e trasformare i termini della query per fornire un risultato pertinente. Date le complessità intrinseche, esistono molti fattori che possono influire sul risultato di una query. Per questo motivo, investire del tempo per comprendere i meccanismi della ricerca full-text offre dei vantaggi tangibili quando si prova a lavorare con risultati imprevisti.
In questo articolo è stata illustrata la ricerca full-text nel contesto di Azure AI Search. Ci auguriamo che questo argomento offra un background sufficiente per riconoscere possibili cause e soluzioni per affrontare i problemi comuni della query.
Passaggi successivi
Compilare l'indice di esempio, provare diverse query ed esaminare i risultati. Per istruzioni, vedere Compilare ed eseguire query su un indice nel portale di Azure.
Provare un'altra sintassi di query dalla sezione Cerca documenti di esempio o dalla sintassi di query semplice in Esplora ricerche nella portale di Azure.
Rivedere i profili di punteggio se si desidera ottimizzare la classificazione nell'applicazione di ricerca.
Informazioni su come applicare analizzatori lessicali specifici della lingua.
Configurare gli analizzatori personalizzati per un'elaborazione minima o specializzati per settori specifici.
Vedi anche
Search Documents REST API (API REST di Ricerca di documenti)
Full Lucene query syntax (Sintassi di query completa Lucene)