Esercitazione: Indicizzare dati di grandi dimensioni da Apache Spark usando SynapseML e Azure AI Search
Questa esercitazione su Azure AI Search illustra come indicizzare ed eseguire query su dati di grandi dimensioni caricati da un cluster Spark. Configurare un Jupyter Notebook che esegue le azioni seguenti:
- Caricare vari moduli (fatture) in un frame di dati in una sessione di Apache Spark
- Analizzarli per determinarne le funzionalità
- Assemblare l'output risultante in una struttura dati tabulare
- Scrivere l'output in un indice di ricerca ospitato in Azure AI Search
- Esplorare ed eseguire le query sul contenuto creato
Questa esercitazione usa una dipendenza da SynapseML, una libreria open source che supporta l'apprendimento automatico in parallelo massiccio su Big Data. In SynapseML, l'indicizzazione della ricerca e l'apprendimento automatico vengono esposti tramite trasformatori che eseguono attività specializzate. I trasformatori sfruttano un'ampia gamma di funzionalità di IA. In questo esercizio usare le API AzureSearchWriter per l'analisi e l'arricchimento tramite intelligenza artificiale.
Anche se Azure AI Search include l'arricchimento tramite intelligenza artificiale nativo, questa esercitazione illustra come accedere alle funzionalità di IA all'esterno di Azure AI Search. Usando SynapseML invece di indicizzatori o capacità, non si è soggetti ai limiti dei dati o ad altri vincoli associati a tali oggetti.
Suggerimento
Guardare un video breve di questa demo all'indirizzo https://www.youtube.com/watch?v=iXnBLwp7f88. In questa esercitazione il video si amplia con altri passaggi e oggetti visivi.
Prerequisiti
Sono necessarie la libreria synapseml e diverse risorse di Azure. Se possibile, usare la stessa sottoscrizione e la stessa area per le risorse di Azure e inserire tutto in un unico gruppo di risorse per una pulizia semplice in un secondo momento. I collegamenti seguenti sono relativi alle installazioni del portale. I dati campione sono importati da un sito pubblico.
- Pacchetto SynapseML 1
- Azure AI Search (qualsiasi livello) 2
- Servizi di Azure AI (qualsiasi livello) 3
- Azure Databricks (qualsiasi livello) 4
1 Questo collegamento si risolve in un'esercitazione per il caricamento del pacchetto.
2 È possibile usare il livello di ricerca gratuito per indicizzare i dati campione, ma se i volumi di dati sono di grandi dimensioni, scegliere un livello superiore. Per i livelli fatturabili, specificare la chiave API di ricerca nel passaggio Configurare le dipendenze.
3 Questa esercitazione usa Informazioni sui documenti di Azure AI e Traduttore per Azure AI. Nelle istruzioni seguenti specificare una chiave multiservizio e l'area. La stessa chiave funziona per entrambi i servizi.
4 In questa esercitazione Azure Databricks offre la piattaforma di calcolo Spark. Sono state usate le istruzioni del portale per configurare l'area di lavoro.
Nota
Tutte le risorse di Azure superiori supportano le funzionalità di sicurezza in Microsoft Identity Platform. Per semplicità, questa esercitazione presuppone l'autenticazione basata su chiave, usando endpoint e chiavi copiati dalle pagine del portale di ciascun servizio. Se si implementa questo flusso di lavoro in un ambiente di produzione, o se si condivide la soluzione con altri utenti, ricordarsi di sostituire le chiavi hardcoded con sicurezza integrata o chiavi crittografate.
Passaggio 1: Creare un cluster Spark e un notebook
In questa sezione creare un cluster, installare la libreria synapseml e creare un notebook per eseguire il codice.
Nel portale di Azure, individuare l'area di lavoro di Azure Databricks e selezionare Avvia area di lavoro.
Nel menu a sinistra selezionare Calcolo.
Selezionare Crea calcolo.
Accettare la configurazione predefinita. La creazione del cluster richiede alcuni minuti.
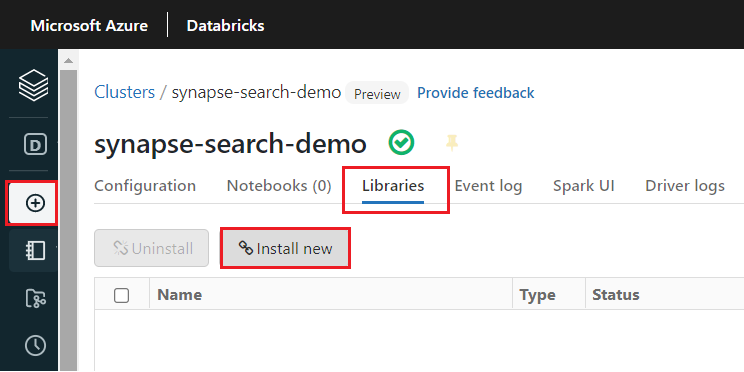
Dopo la creazione del cluster, installare la libreria
synapseml:Selezionare Librerie nelle schede nella parte superiore della pagina del cluster.
Selezionare Installa nuovo.
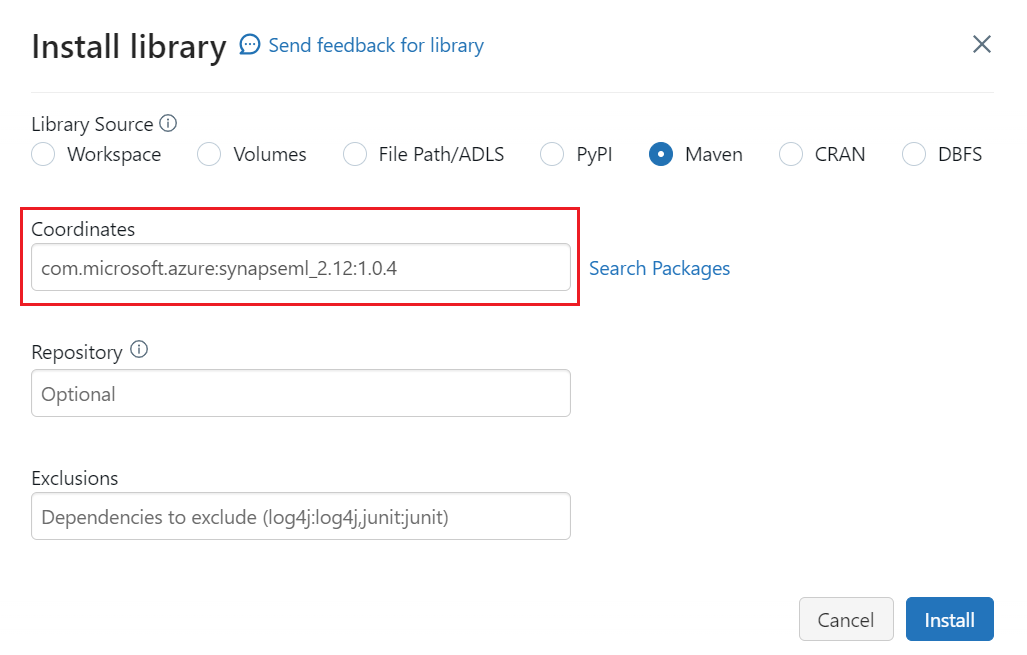
Selezionare Maven.
In Coordinate, immettere
com.microsoft.azure:synapseml_2.12:1.0.4Selezionare Installa.
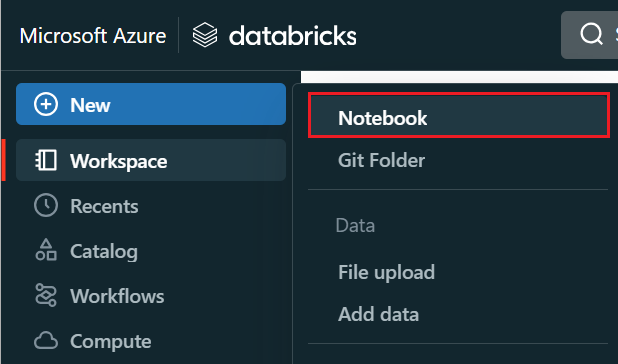
Nel menu a sinistra selezionare Crea>Notebook.
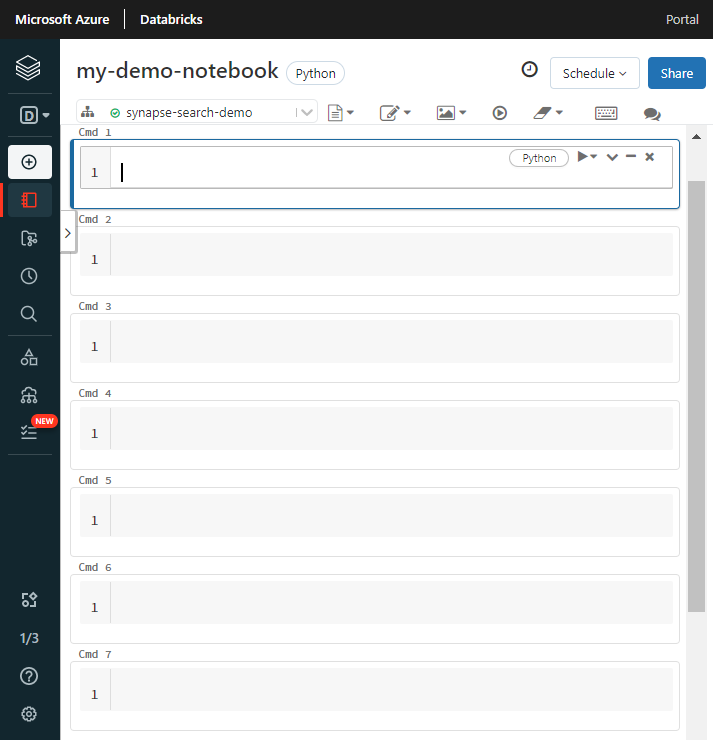
Assegnare un nome al notebook, selezionare Python come linguaggio predefinito e selezionare il cluster che ha la libreria
synapseml.Creare sette celle consecutive. Incollare il codice in ciascuna.
Passaggio 2: Configurare le dipendenze
Incollare il codice seguente nella prima cella del notebook.
Sostituire i segnaposto con endpoint e chiavi di accesso per ciascuna risorsa. Specificare un nome il nuovo indice di ricerca. Non sono necessarie altre modifiche, quindi se tutto pronto, eseguire il codice.
Questo codice importa più pacchetti e configura l'accesso alle risorse di Azure usate in questo flusso di lavoro.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Passaggio 3: Caricare i dati in Spark
Incollare il codice seguente nella seconda cella. Non sono necessarie modifiche, quindi se tutto pronto, eseguire il codice.
Questo codice carica alcuni file esterni da un account di archiviazione di Azure. I file sono diverse fatture e sono letti in un frame di dati.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Passaggio 4: Aggiungere le funzionalità di informazioni sui documenti
Incollare il codice seguente nella terza cella. Non sono necessarie modifiche, quindi se tutto pronto, eseguire il codice.
Questo codice carica il trasformatore AnalyzeInvoices e passa un riferimento al frame di dati contenente le fatture. Chiama il modello di fattura predefinito di Informazioni sui documenti di Azure AI per estrarre le informazioni dalle fatture.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
L'output di questo passaggio dovrebbe essere simile a quello nello screenshot successivo. Si noti che l'analisi dei moduli viene compressa in una colonna densamente strutturata che non agevola il lavoro. La trasformazione successiva risolve il problema analizzando la colonna in righe e colonne.
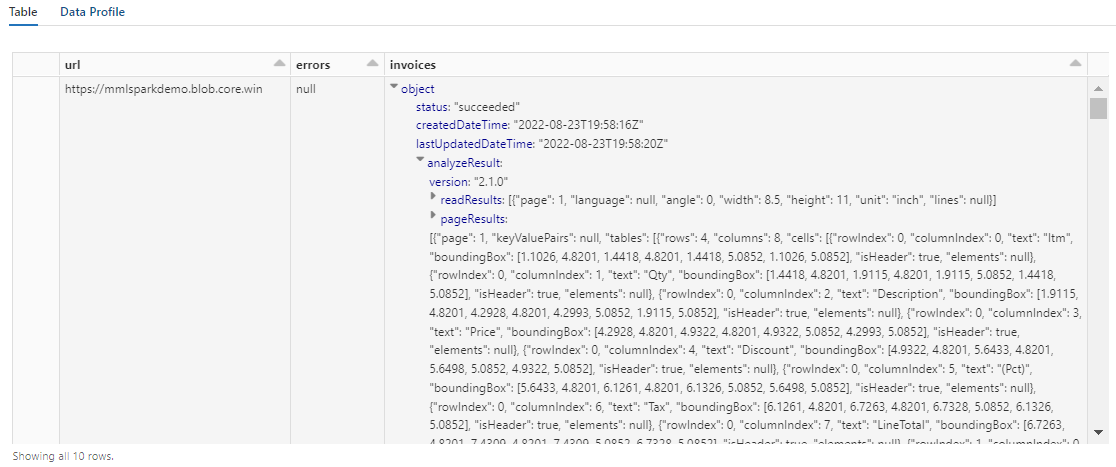
Passaggio 5: Ristrutturare l'output di informazioni sui documenti
Incollare il codice seguente nella quarta cella ed eseguirlo. Non sono necessarie modifiche.
Questo codice carica FormOntologyLearner, un trasformatore che analizza l'output dei trasformatori di Informazioni sui documenti e deduce una struttura dati tabulare. L'output di AnalyzeInvoices è dinamico e varia in base alle funzionalità rilevate nel contenuto. Inoltre, il trasformatore consolida l'output in una colonna singola. Poiché l'output è dinamico e consolidato, è difficile da usare nelle trasformazioni downstream che richiedono una struttura maggiore.
FormOntologyLearner estende l'utilità del trasformatore AnalyzeInvoices cercando modelli che possono essere usati per creare una struttura dati tabulare. L'organizzazione dell'output in più colonne e righe rende il contenuto utilizzabile per altri trasformatori, ad esempio AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Si noti che questa trasformazione esegue un nuovo casting dei campi annidati in una tabella, che consente le due trasformazioni successive. Questo screenshot viene troncato per brevità. Se si sta seguendo tutto nel proprio notebook, sono presenti 19 colonne e 26 righe.
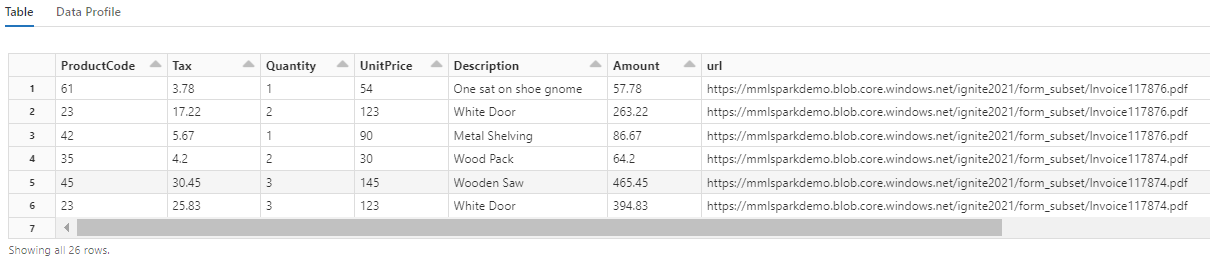
Passaggio 6: Aggiungere le traduzioni
Incollare il codice seguente nella quinta cella. Non sono necessarie modifiche, quindi se tutto pronto, eseguire il codice.
Questo codice carica Traduci, un trasformatore che chiama il servizio Traduttore per Azure AI nei Servizi di Azure AI. Il testo originale, in inglese si trova nella colonna "Descrizione", viene tradotto in varie lingue. L’intero output è consolidato nella matrice "output.translations".
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Suggerimento
Per verificare la presenza di stringhe tradotte, scorrere fino al termine delle righe.
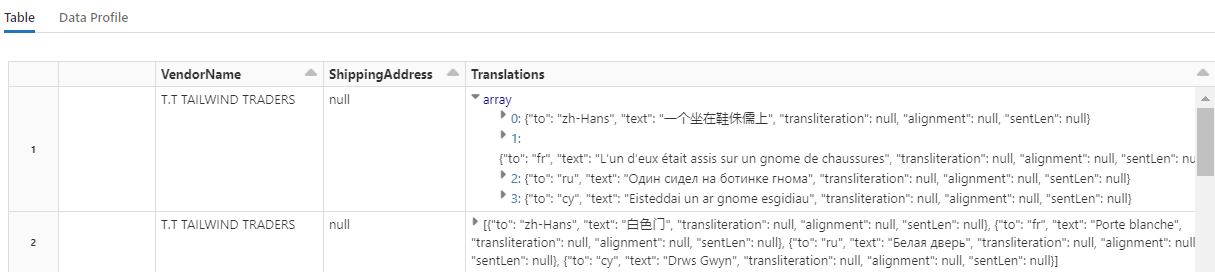
Passaggio 7: Aggiungere un indice di ricerca con AzureSearchWriter
Incollare il codice seguente nella sesta cella ed eseguirlo. Non sono necessarie modifiche.
Questo codice carica AzureSearchWriter. Usa un set di dati tabulare e deduce uno schema dell'indice di ricerca che definisce un campo per ciascuna colonna. Poiché la struttura delle traduzioni è una matrice, è articolata nell'indice come raccolta complessa con i sottocampi per ogni traduzione linguistica. L'indice generato ha una chiave del documento e usa i valori predefiniti per i campi creati usando API REST Creare indice.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
È possibile controllare le pagine del servizio di ricerca nel portale di Azure per esplorare la definizione di indice creata da AzureSearchWriter.
Nota
Se non è possibile usare l'indice di ricerca predefinito, fornire una definizione personalizzata esterna in JSON, passandone l'URI come stringa nella proprietà "indexJson". Generare prima l'indice predefinito, così da conoscere i campi da specificare, quindi seguire con le proprietà personalizzate, ad esempio se sono necessari analizzatori specifici.
Passaggio 8: Eseguire una query sull'indice
Incollare il codice seguente nella settima cella ed eseguirlo. Non sono necessarie modifiche, ad eccezione del fatto che si potrebbe voler variare la sintassi o provare altri esempi per esplorare ulteriormente il contenuto:
Non vi sono trasformatori o moduli che generano query. Questa cella è una semplice chiamata a API REST Cercare documenti.
Questo particolare esempio rappresenta la ricerca della parola "porta" ("search": "door"). Inoltre restituisce un "conteggio" del numero di documenti corrispondenti, e per i risultati seleziona solo il contenuto dei campi "Descrizione" e "Traduzioni". Per visualizzare l'elenco completo dei campi, rimuovere il parametro "select".
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
Lo screenshot seguente mostra l'output della cella per lo script campione.
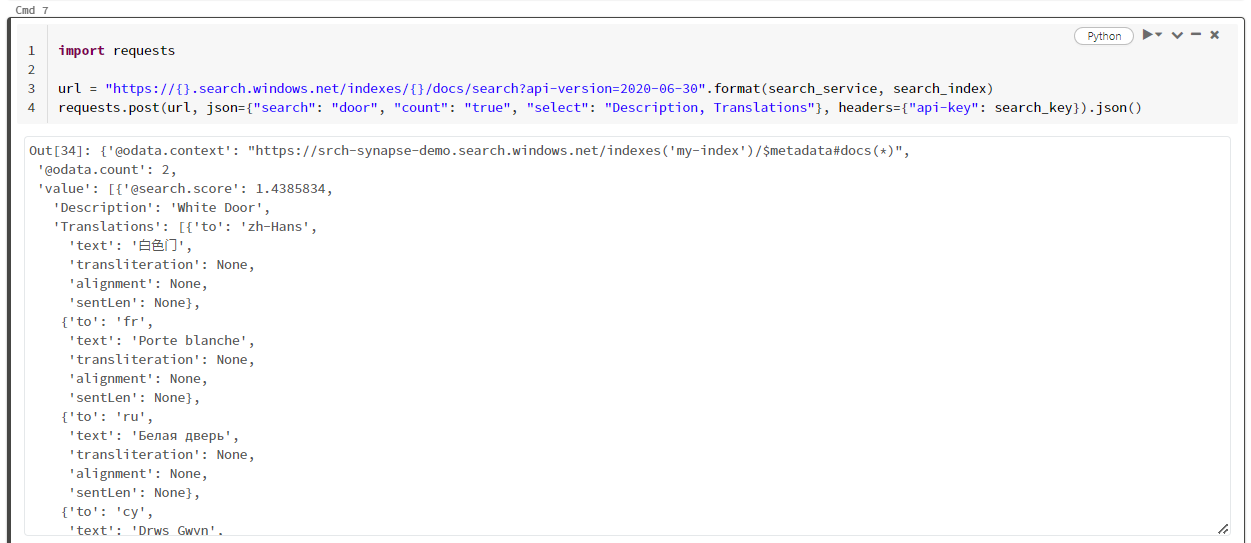
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
Per trovare e gestire le risorse nel portale, usare il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Passaggi successivi
In questa esercitazione è stato illustrato il trasformatore AzureSearchWriter in SynapseML, un nuovo modo per creare e caricare indici di ricerca in Azure AI Search. Il trasformatore accetta JSON strutturato come input. FormOntologyLearner può fornire la struttura necessaria per l'output prodotto dai trasformatori di Informazioni sui documenti in SynapseML.
Come passaggio successivo, esaminare le altre esercitazioni di SynapseML che producono contenuto trasformato da esplorare tramite Azure AI Search: