Linguaggio di query Kusto in Microsoft Sentinel
Linguaggio di query Kusto è il linguaggio che verrà usato per usare e modificare i dati in Microsoft Sentinel. I log inseriti nell'area di lavoro non valgono molto se non è possibile analizzarli e ottenere le informazioni importanti nascoste in tutti i dati. Linguaggio di query Kusto non solo la potenza e la flessibilità per ottenere tali informazioni, ma la semplicità per iniziare rapidamente. Se si ha uno sfondo nello scripting o nell'uso dei database, molti dei contenuti di questo articolo saranno molto familiari. In caso contrario, non preoccuparti, poiché la natura intuitiva del linguaggio consente di iniziare rapidamente a scrivere query personalizzate e a promuovere il valore per l'organizzazione.
Questo articolo presenta le nozioni di base di Linguaggio di query Kusto, che illustra alcune delle funzioni e degli operatori più usati, che devono indirizzare il 75 all'80% delle query che verranno scritte giorno dopo giorno. Quando è necessaria maggiore profondità o per eseguire query più avanzate, è possibile sfruttare la nuova cartella di lavoro avanzata KQL per Microsoft Sentinel (vedere questo post di blog introduttivo). Vedere anche la documentazione ufficiale Linguaggio di query Kusto e una varietà di corsi online (ad esempio Pluralsight).
Background - Perché Linguaggio di query Kusto?
Microsoft Sentinel si basa sul servizio Monitoraggio di Azure e usa le aree di lavoro Log Analytics di Monitoraggio di Azure per archiviare tutti i dati. Questi dati includono uno dei seguenti:
- dati inseriti da origini esterne in tabelle predefinite usando i connettori dati di Microsoft Sentinel.
- dati inseriti da origini esterne in tabelle personalizzate definite dall'utente, usando connettori dati creati in modo personalizzato, nonché alcuni tipi di connettori predefiniti.
- dati creati da Microsoft Sentinel stesso, risultanti dalle analisi create ed eseguite, ad esempio avvisi, eventi imprevisti e informazioni correlate all'UEBA.
- dati caricati in Microsoft Sentinel per facilitare il rilevamento e l'analisi, ad esempio feed di intelligence sulle minacce e watchlist.
Linguaggio di query Kusto è stato sviluppato come parte del servizio Azure Esplora dati ed è quindi ottimizzato per la ricerca in archivi Big Data in un ambiente cloud. Ispirato dal famoso esploratore sottomarino Jacques Cousteau (e pronunciato di conseguenza "koo-STOH"), è progettato per aiutarti a immergerti in profondità nei tuoi oceani di dati ed esplorare i loro tesori nascosti.
Linguaggio di query Kusto viene usato anche in Monitoraggio di Azure (e quindi in Microsoft Sentinel), incluse alcune funzionalità aggiuntive di Monitoraggio di Azure, che consentono di recuperare, visualizzare, analizzare e analizzare i dati negli archivi dati di Log Analytics. In Microsoft Sentinel si usano strumenti basati su Linguaggio di query Kusto ogni volta che si stanno visualizzando e analizzando i dati e la ricerca di minacce, sia nelle regole esistenti che nelle cartelle di lavoro o nella creazione di cartelle di lavoro personalizzate.
Poiché Linguaggio di query Kusto fa parte di quasi tutto ciò che si fa in Microsoft Sentinel, una chiara comprensione del funzionamento consente di ottenere molto di più dal siem.
Che cos'è una query?
Una query Linguaggio di query Kusto è una richiesta di sola lettura per elaborare i dati e restituire i risultati. Non scrive dati. Le query operano su dati organizzati in una gerarchia di database, tabelle e colonne, simili a SQL.
Le richieste vengono dichiarate in linguaggio normale e usano un modello di flusso di dati progettato per semplificare la lettura, la scrittura e l'automazione della sintassi. Questo verrà visualizzato in dettaglio.
Linguaggio di query Kusto query sono costituite da istruzioni separate da punti e virgola. Esistono molti tipi di istruzioni, ma solo due tipi ampiamente usati di seguito:
Le istruzioni di espressione tabulare sono ciò che in genere si intende quando si parla di query, ovvero il corpo effettivo della query. La cosa importante da sapere sulle istruzioni di espressione tabulare è che accettano un input tabulare (una tabella o un'altra espressione tabulare) e producono un output tabulare. Almeno uno di questi è obbligatorio. La maggior parte del resto di questo articolo illustra questo tipo di istruzione.
Le istruzioni let consentono di creare e definire variabili e costanti al di fuori del corpo della query, per semplificare la leggibilità e la versatilità. Questi sono facoltativi e dipendono dalle esigenze specifiche. Questo tipo di dichiarazione verrà affrontato alla fine dell'articolo.
Ambiente demo
È possibile praticare Linguaggio di query Kusto istruzioni, incluse quelle contenute in questo articolo, in un ambiente demo di Log Analytics nel portale di Azure. Non è previsto alcun addebito per l'uso di questo ambiente di pratica, ma è necessario un account Azure per accedervi.
Esplorare l'ambiente demo. Come Log Analytics nell'ambiente di produzione, può essere usato in diversi modi:
Scegliere una tabella in cui compilare una query. Nella scheda Tabelle predefinite (visualizzata nel rettangolo rosso in alto a sinistra), selezionare una tabella dall'elenco di tabelle raggruppate in base agli argomenti (mostrati in basso a sinistra). Espandere gli argomenti per visualizzare le singole tabelle ed espandere ulteriormente ogni tabella per visualizzare tutti i relativi campi (colonne). Se si fa doppio clic su una tabella o un nome di campo, il cursore verrà inserito nel punto del cursore nella finestra di query. Digitare il resto della query seguendo il nome della tabella, come indicato di seguito.
Trovare una query esistente da studiare o modificare. Selezionare la scheda Query (mostrata nel rettangolo rosso in alto a sinistra) per visualizzare un elenco di query disponibili nella casella predefinita. In alternativa, selezionare Query dalla barra dei pulsanti in alto a destra. È possibile esplorare le query fornite con Microsoft Sentinel predefinite. Facendo doppio clic su una query, l'intera query verrà inserita nella finestra della query al punto del cursore.
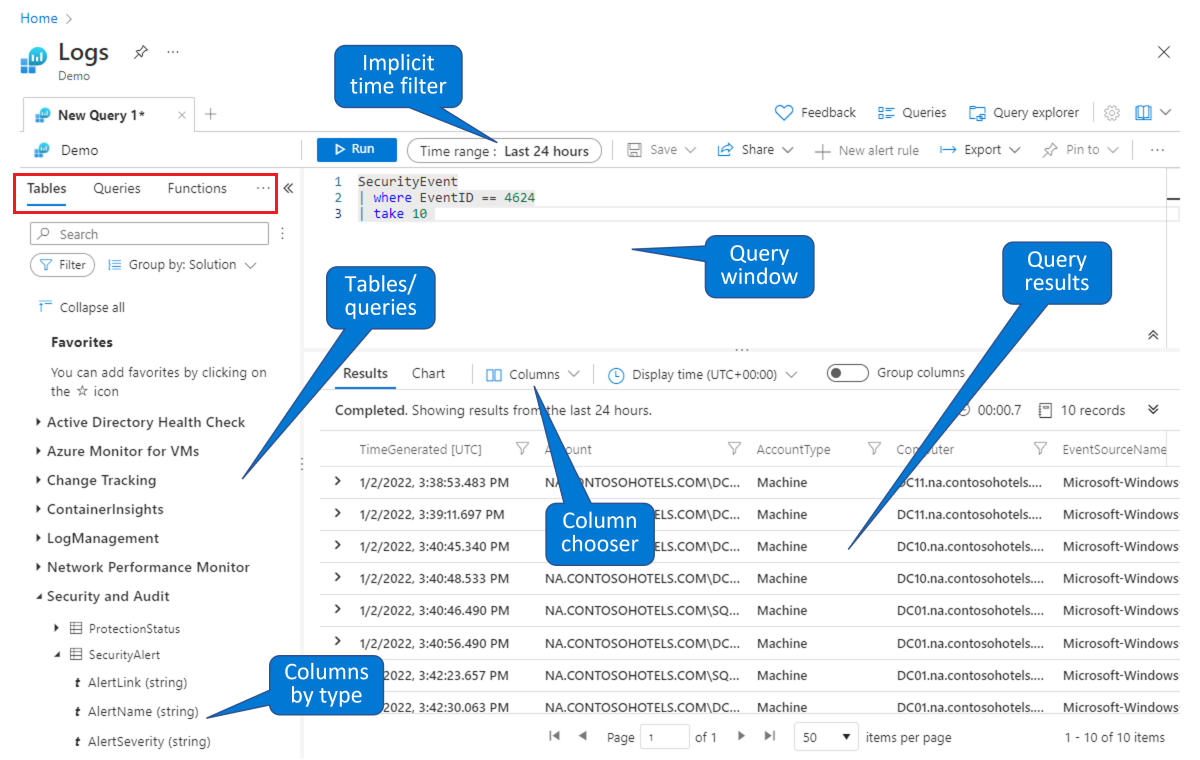
Come in questo ambiente demo, è possibile eseguire query e filtrare i dati nella pagina Log di Microsoft Sentinel. È possibile selezionare una tabella ed eseguire il drill-down per visualizzare le colonne. È possibile modificare le colonne predefinite visualizzate usando il chooser colonna ed è possibile impostare l'intervallo di tempo predefinito per le query. Se l'intervallo di tempo è definito in modo esplicito nella query, il filtro temporale non sarà disponibile (disattivato).
Struttura di query
Un buon punto di partenza per iniziare a imparare Linguaggio di query Kusto consiste nel comprendere la struttura complessiva delle query. La prima cosa che si noterà quando si esamina una query Kusto è l'uso del simbolo di pipe (|). La struttura di una query Kusto inizia con il recupero dei dati da un'origine dati e quindi il passaggio dei dati in una "pipeline" e ogni passaggio fornisce un certo livello di elaborazione e quindi passa i dati al passaggio successivo. Alla fine della pipeline si otterrà il risultato finale. In effetti, questa è la pipeline:
Get Data | Filter | Summarize | Sort | Select
Questo concetto di passaggio dei dati nella pipeline rende una struttura molto intuitiva, in quanto è facile creare un'immagine mentale dei dati in ogni passaggio.
Per illustrare questo aspetto, si esaminerà la query seguente, che esamina i log di accesso di Microsoft Entra. Durante la lettura di ogni riga, è possibile visualizzare le parole chiave che indicano cosa accade ai dati. La fase pertinente nella pipeline è stata inclusa come commento in ogni riga.
Nota
È possibile aggiungere commenti a qualsiasi riga in una query precedendoli con una doppia barra (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Poiché l'output di ogni passaggio funge da input per il passaggio seguente, l'ordine dei passaggi può determinare i risultati della query e influire sulle prestazioni. È fondamentale ordinare i passaggi in base a ciò che si vuole uscire dalla query.
Suggerimento
- Una buona regola generale consiste nel filtrare i dati in anticipo, quindi si passano solo i dati pertinenti verso il basso nella pipeline. In questo modo si aumentano notevolmente le prestazioni e si garantisce che non si includano accidentalmente dati irrilevanti nei passaggi di riepilogo.
- Questo articolo illustra alcune altre procedure consigliate da tenere presente. Per un elenco più completo, vedere Procedure consigliate per le query.
Si spera che ora si abbia un apprezzamento per la struttura complessiva di una query in Linguaggio di query Kusto. Verranno ora esaminati gli operatori di query effettivi, che vengono usati per creare una query.
Tipo di dati
Prima di accedere agli operatori di query, si esaminerà prima di tutto i tipi di dati. Come nella maggior parte dei linguaggi, il tipo di dati determina quali calcoli e manipolazioni possono essere eseguiti su un valore. Ad esempio, se si dispone di un valore di tipo string, non sarà possibile eseguire calcoli aritmetici su di esso.
In Linguaggio di query Kusto, la maggior parte dei tipi di dati segue le convenzioni standard e ha nomi probabilmente visti in precedenza. La tabella seguente mostra l'elenco completo:
Tabella dei tipi di dati
| Tipo | Nome/i aggiuntivo/i | Tipo .NET equivalente |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Anche se la maggior parte dei tipi di dati è standard, è possibile che si abbia meno familiarità con tipi come dynamic, timespan e GUID.
Dynamic ha una struttura molto simile a JSON, ma con una differenza chiave: può archiviare Linguaggio di query Kusto tipi di dati specifici che json tradizionale non può, ad esempio un valore dinamico annidato o un intervallo di tempo. Ecco un esempio di tipo dinamico:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Timespan è un tipo di dati che fa riferimento a una misura di tempo, ad esempio ore, giorni o secondi. Non confondere timespan con datetime, che restituisce una data e un'ora effettive, non una misura di ora. La tabella seguente mostra un elenco di suffissi timespan .
Suffissi timespan
| Funzione | Descrizione |
|---|---|
D |
giorni |
H |
ore |
M |
minutes |
S |
seconds |
Ms |
milliseconds |
Microsecond |
Microsecondi |
Tick |
Nanosecondi |
Guid è un tipo di dati che rappresenta un identificatore univoco globale a 128 bit, che segue il formato standard [8]-[4]-[4]-[4]-[12], dove ogni [numero] rappresenta il numero di caratteri e ogni carattere può variare da 0 a 9 o a-f.
Nota
Linguaggio di query Kusto dispone di operatori tabulari e scalari. Nel resto di questo articolo, se si visualizza semplicemente la parola "operator", è possibile presupporre che significa operatore tabulare, a meno che non diversamente specificato.
Recupero, limitazione, ordinamento e filtro dei dati
Il vocabolario principale di Linguaggio di query Kusto, la base che consente di eseguire la maggior parte delle attività, è una raccolta di operatori per filtrare, ordinare e selezionare i dati. Le attività rimanenti che dovrai eseguire richiederanno di estendere la tua conoscenza del linguaggio per soddisfare le tue esigenze più avanzate. Si esaminerà ora alcuni dei comandi usati nell'esempio precedente e si esaminerà take, sorte where.
Per ognuno di questi operatori, verrà esaminato l'uso nell'esempio precedente di SigninLogs e verrà illustrato un suggerimento utile o una procedura consigliata.
Recupero di dati
La prima riga di qualsiasi query di base specifica la tabella da utilizzare. Nel caso di Microsoft Sentinel, questo sarà probabilmente il nome di un tipo di log nell'area di lavoro, ad esempio SigninLogs, SecurityAlert o CommonSecurityLog. Ad esempio:
SigninLogs
Si noti che in Linguaggio di query Kusto i nomi di log fanno distinzione tra maiuscole e minuscole, signinLogs quindi SigninLogs verranno interpretati in modo diverso. Prestare attenzione quando si scelgono i nomi per i log personalizzati, in modo che siano facilmente identificabili e non troppo simili a un altro log.
Limitazione dei dati: prendere / il limite
L'operatore take (e l'operatore limite identico) viene usato per limitare i risultati restituendo solo un determinato numero di righe. È seguito da un numero intero che specifica il numero di righe da restituire. In genere, viene usato alla fine di una query dopo aver determinato l'ordinamento e, in questo caso, restituirà il numero specificato di righe all'inizio dell'ordinamento.
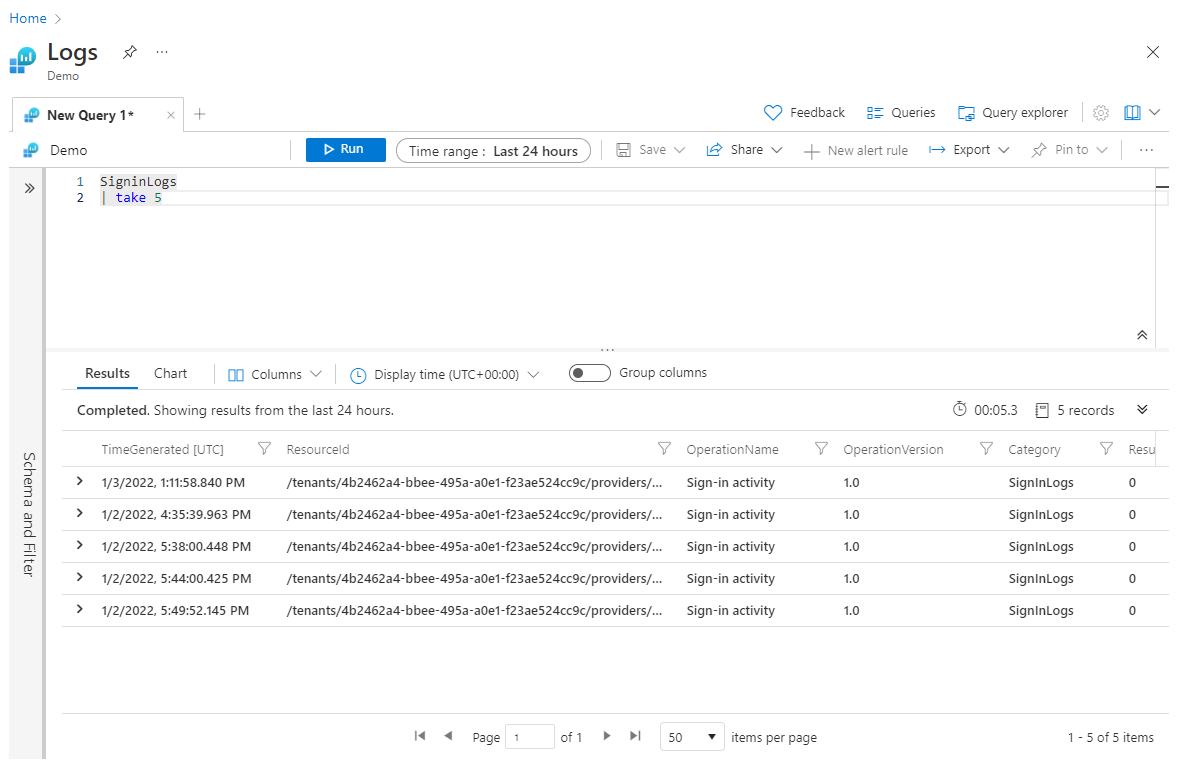
L'uso take precedente della query può essere utile per testare una query, quando non si vogliono restituire set di dati di grandi dimensioni. Tuttavia, se si inserisce l'operazione take prima di qualsiasi sort operazione, take restituirà le righe selezionate in modo casuale e possibilmente un set diverso di righe ogni volta che viene eseguita la query. Ecco un esempio di uso di take:
SigninLogs
| take 5
Suggerimento
Quando si lavora su una query completamente nuova in cui non si conosce l'aspetto della query, può essere utile inserire un'istruzione take all'inizio per limitare artificialmente il set di dati per un'elaborazione e una sperimentazione più veloci. Dopo aver soddisfatto la query completa, è possibile rimuovere il passaggio iniziale take .
Ordinamento dei dati: ordinamento /
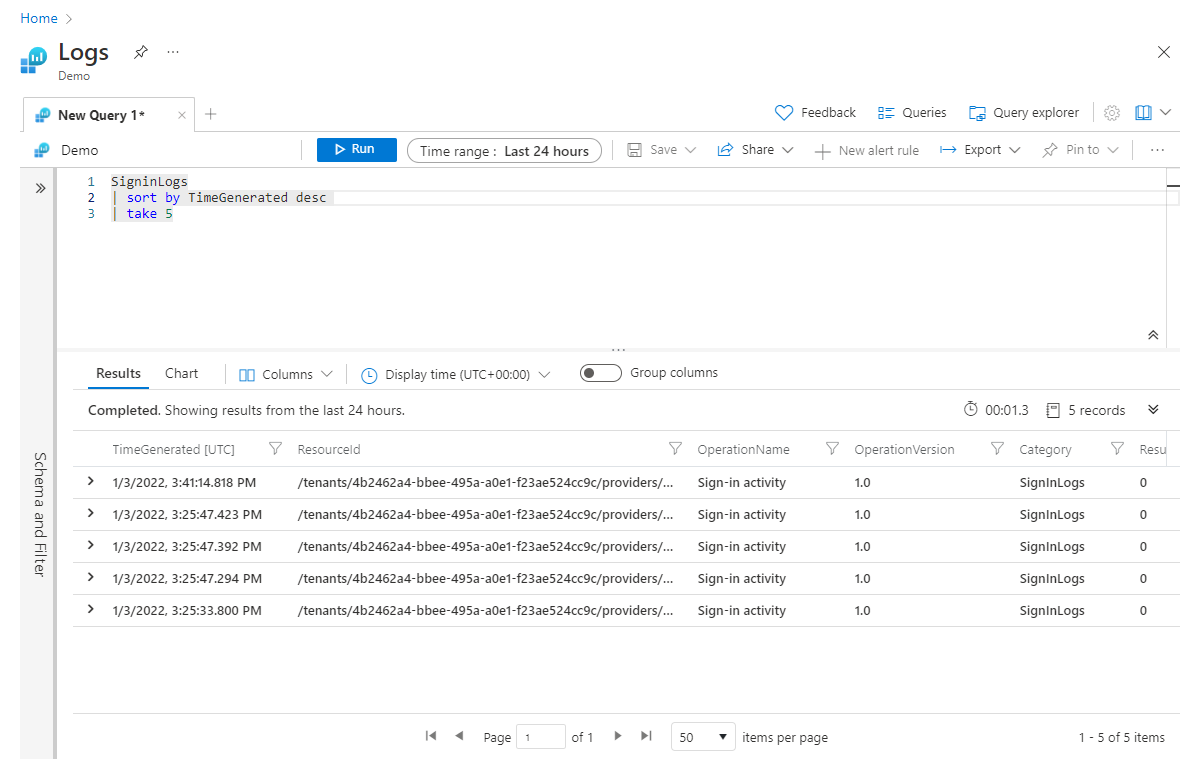
L'operatore sort (e l'operatore di ordinamento identico) viene usato per ordinare i dati in base a una colonna specificata. Nell'esempio seguente i risultati sono stati ordinati in base a TimeGenerated e si imposta la direzione dell'ordine in ordine decrescente con il parametro desc , inserendo i valori più alti per primi. Per un ordine crescente, si userà asc.
Nota
La direzione predefinita per gli ordinamenti è decrescente, quindi tecnicamente è necessario specificare solo se si desidera ordinare in ordine crescente. Tuttavia, specificando la direzione di ordinamento in qualsiasi caso, la query sarà più leggibile.
SigninLogs
| sort by TimeGenerated desc
| take 5
Come accennato, l'operatore sort viene inserito prima dell'operatore take . È necessario ordinare prima di tutto per assicurarsi di ottenere i cinque record appropriati.
Top
L'operatore top consente di combinare le sort operazioni e take in un singolo operatore:
SigninLogs
| top 5 by TimeGenerated desc
Nei casi in cui due o più record hanno lo stesso valore nella colonna in base alla quale si esegue l'ordinamento, è possibile aggiungere altre colonne per l'ordinamento. Aggiungere colonne di ordinamento aggiuntive in un elenco delimitato da virgole, che si trova dopo la prima colonna di ordinamento, ma prima della parola chiave sort order. Ad esempio:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Ora, se TimeGenerated è lo stesso tra più record, tenterà di ordinare in base al valore nella colonna Identity .
Nota
Quando usare sort e takee quando usare top
Se si esegue l'ordinamento solo in un campo, usare
top, perché offre prestazioni migliori rispetto alla combinazione disortetake.Se è necessario ordinare più campi (come nell'ultimo esempio precedente),
topnon è possibile eseguire questa operazione, quindi è necessario usaresortetake.
Filtro dei dati: dove
L'operatore where è probabilmente l'operatore più importante, perché è la chiave per assicurarsi di usare solo il subset di dati rilevanti per lo scenario. È consigliabile filtrare i dati il prima possibile nella query perché in questo modo si miglioreranno le prestazioni delle query riducendo la quantità di dati che devono essere elaborati nei passaggi successivi; garantisce inoltre di eseguire calcoli solo sui dati desiderati. Vedere questo esempio:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
L'operatore where specifica una variabile, un operatore di confronto (scalare) e un valore. In questo caso, è stato usato >= per indicare che il valore nella colonna TimeGenerated deve essere maggiore di (ovvero successivo a) o uguale a sette giorni fa.
Esistono due tipi di operatori di confronto in Linguaggio di query Kusto: stringa e numerica. La tabella seguente mostra l'elenco completo degli operatori numerici:
Operatori numerici
| Operator | Descrizione |
|---|---|
+ |
Aggiunta |
- |
Sottrazione |
* |
Moltiplicazione |
/ |
Divisione |
% |
Modulo |
< |
Minore di |
> |
Maggiore di |
== |
Uguale a |
!= |
Diverso da |
<= |
Minore di o uguale a |
>= |
Maggiore di o uguale a |
in |
Uguale a uno degli elementi |
!in |
Non uguale a uno degli elementi |
L'elenco degli operatori stringa è un elenco molto più lungo perché include permutazioni per la distinzione tra maiuscole e minuscole, posizioni di sottostringa, prefissi, suffissi e molto altro ancora. L'operatore == è sia un operatore numerico che un operatore stringa, ovvero può essere usato sia per i numeri che per il testo. Ad esempio, entrambe le istruzioni seguenti sono valide dove le istruzioni:
| where ResultType == 0| where Category == 'SignInLogs'
Suggerimento
Procedura consigliata: nella maggior parte dei casi, è probabile che si voglia filtrare i dati in base a più colonne o filtrare la stessa colonna in più modi. In questi casi, è consigliabile tenere presenti due procedure consigliate.
È possibile combinare più where istruzioni in un singolo passaggio usando la parola chiave e . Ad esempio:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Quando si dispone di più filtri uniti in un'unica where istruzione usando la parola chiave e , come sopra, si otterranno prestazioni migliori inserendo i filtri che fanno riferimento solo a una singola colonna. Quindi, un modo migliore per scrivere la query precedente sarebbe:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
In questo esempio il primo filtro menziona una singola colonna (TimeGenerated), mentre la seconda fa riferimento a due colonne (Resource e ResourceGroup).
Riepilogo dei dati
Summarize è uno degli operatori tabulari più importanti in Linguaggio di query Kusto, ma è anche uno degli operatori più complessi per imparare se non si ha familiarità con i linguaggi di query in generale. Il processo di summarize consiste nell'acquisire una tabella di dati e restituire una nuova tabella aggregata da una o più colonne.
Struttura dell'istruzione summarize
La struttura di base di un'istruzione summarize è la seguente:
| summarize <aggregation> by <column>
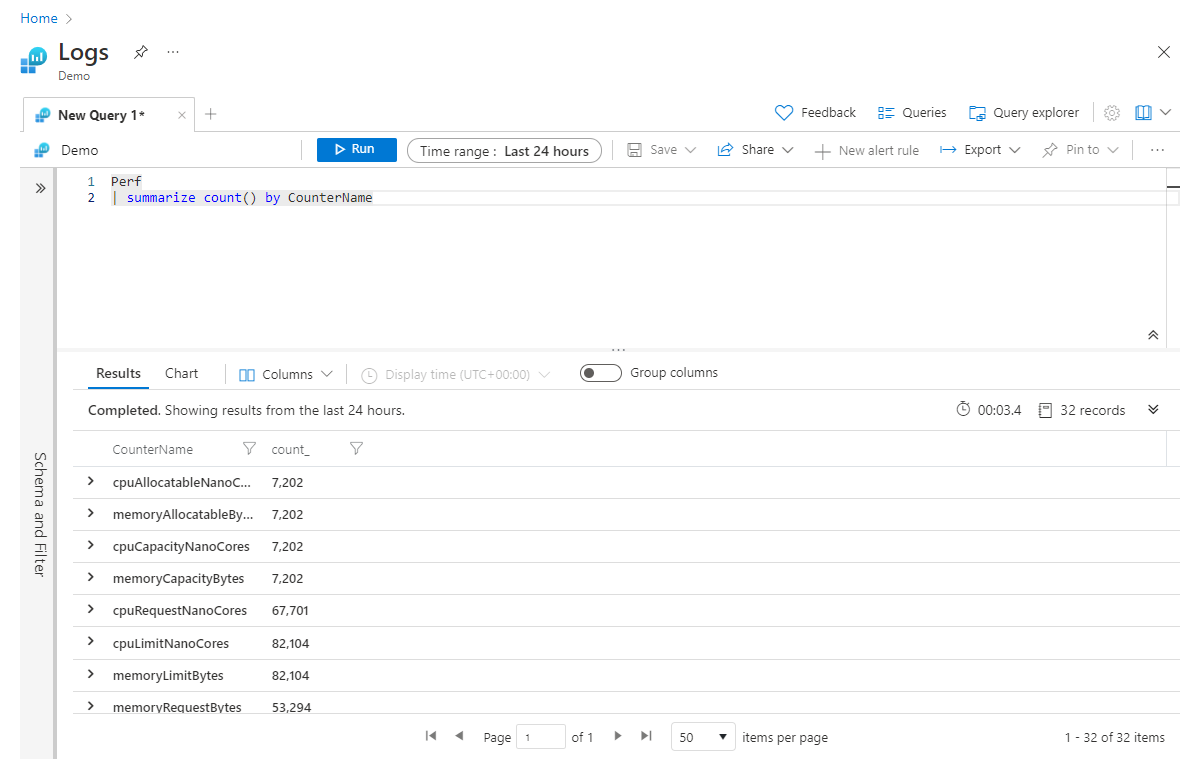
Ad esempio, quanto segue restituisce il numero di record per ogni valore CounterName nella tabella Perf :
Perf
| summarize count() by CounterName
Poiché l'output di summarize è una nuova tabella, tutte le colonne non specificate in modo esplicito nell'istruzione summarize non verranno passate alla pipeline. Per illustrare questo concetto, considerare questo esempio:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
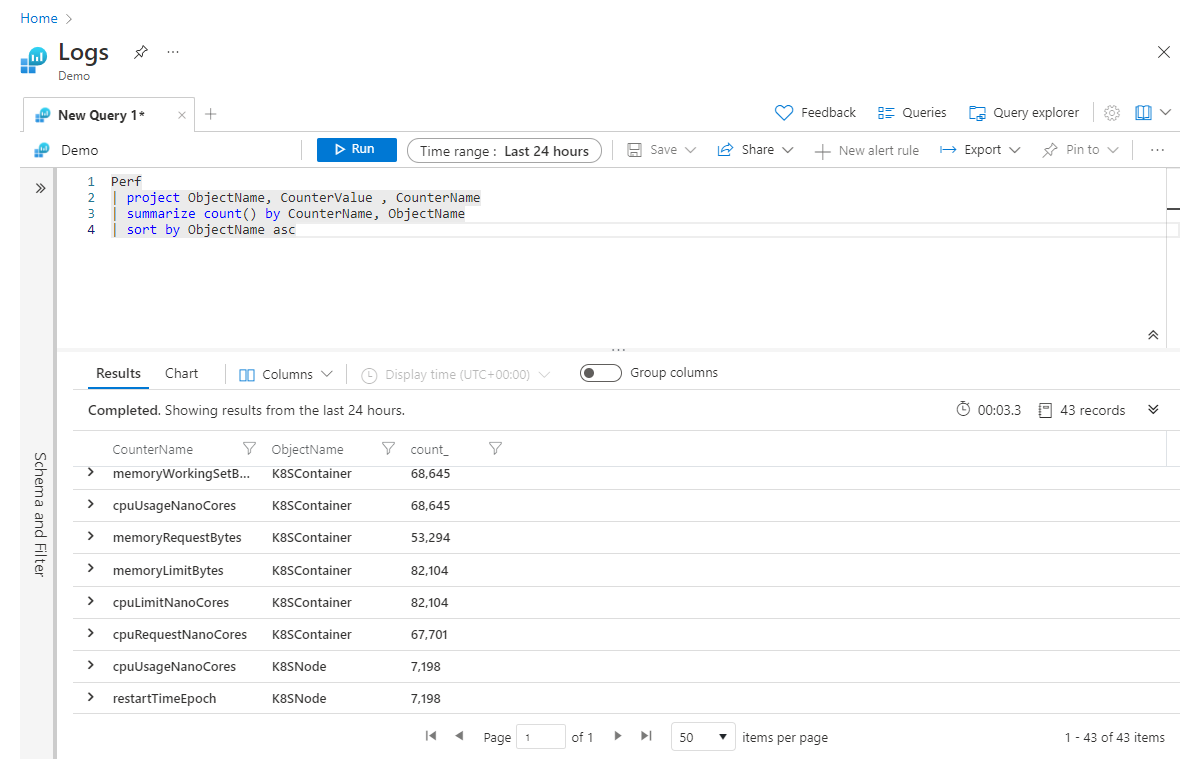
Nella seconda riga si specifica che le colonne NomeOggetto, CounterValue e CounterName vengono solo specificate. È stato quindi riepilogato per ottenere il conteggio dei record per CounterName e infine si tenta di ordinare i dati in ordine crescente in base alla colonna ObjectName . Sfortunatamente, questa query avrà esito negativo con un errore (a indicare che ObjectName è sconosciuto) perché, quando è stato riepilogato, sono state incluse solo le colonne Count e CounterName nella nuova tabella. Per evitare questo errore, è sufficiente aggiungere ObjectName alla fine del summarize passaggio, come illustrato di seguito:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
Il modo per leggere la summarize riga nella testa sarebbe: "riepilogare il conteggio dei record per CounterName e raggruppare per ObjectName". È possibile continuare ad aggiungere colonne, separate da virgole, alla fine dell'istruzione summarize .
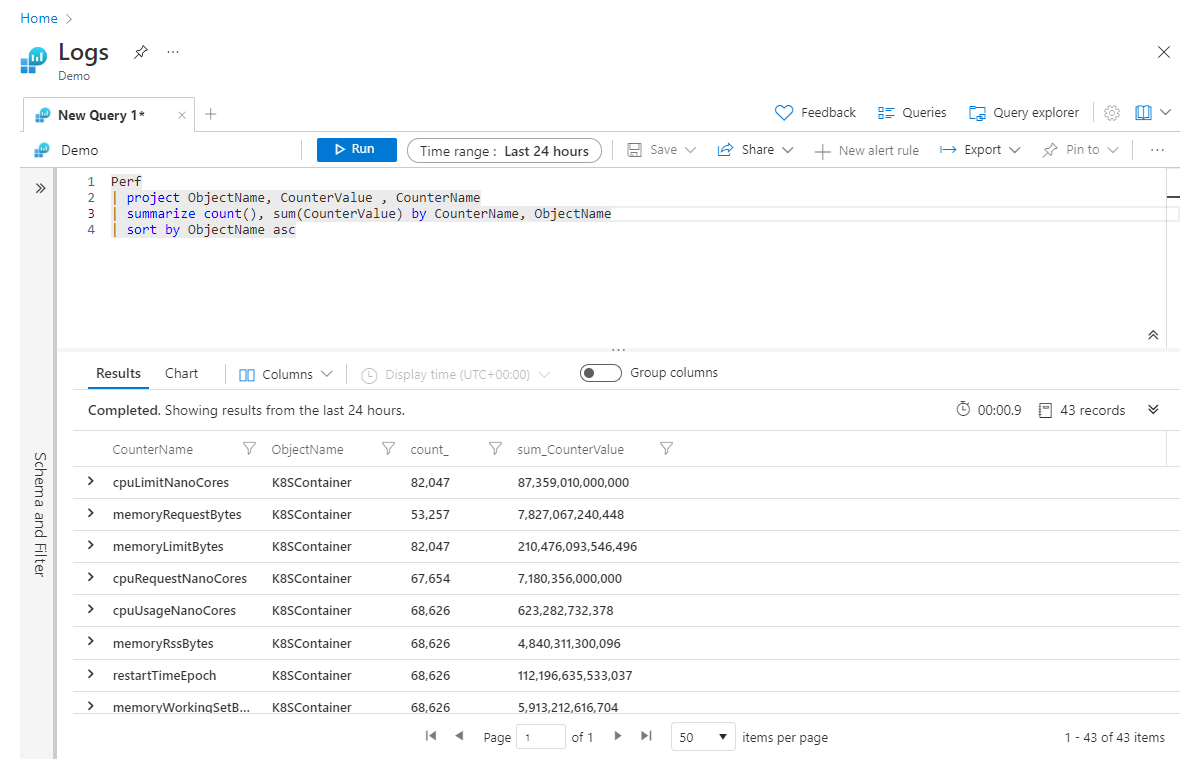
Basandosi sull'esempio precedente, se si vogliono aggregare più colonne contemporaneamente, è possibile ottenere questo risultato aggiungendo aggregazioni all'operatore summarize , separate da virgole. Nell'esempio seguente viene ottenuto non solo un conteggio di tutti i record, ma anche una somma dei valori nella colonna CounterValue in tutti i record (che corrispondono a tutti i filtri nella query):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
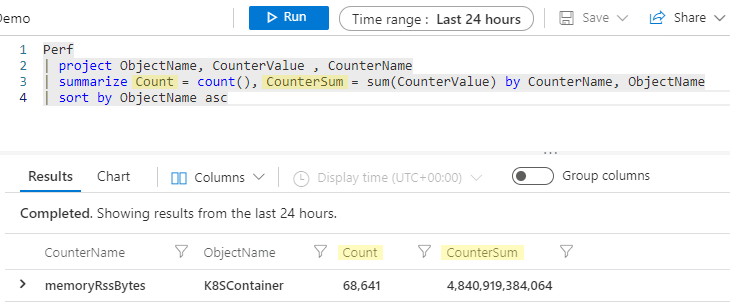
Ridenominazione delle colonne aggregate
Questo sembra un buon momento per parlare dei nomi di colonna per queste colonne aggregate. All'inizio di questa sezione, si è detto che l'operatore summarize accetta una tabella di dati e produce una nuova tabella e solo le colonne specificate nell'istruzione summarize continueranno a scorrere la pipeline. Pertanto, se si esegue l'esempio precedente, le colonne risultanti per l'aggregazione saranno count_ e sum_CounterValue.
Il motore Kusto creerà automaticamente un nome di colonna senza che sia necessario essere espliciti, ma spesso si scopre che si preferisce che la nuova colonna abbia un nome più descrittivo. È possibile rinominare facilmente la colonna nell'istruzione summarize specificando un nuovo nome, seguito da = e l'aggregazione, come indicato di seguito:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Le colonne riepilogate verranno ora denominate Count e CounterSum.
C'è molto di più per l'operatore summarize che possiamo coprire qui, ma è consigliabile investire il tempo per apprenderlo perché è un componente chiave per qualsiasi analisi dei dati che si prevede di eseguire sui dati di Microsoft Sentinel.
Informazioni di riferimento sulle aggregazioni
Sono molte funzioni di aggregazione, ma alcune delle più comunemente usate sono sum(), count()e avg(). Ecco un elenco parziale (vedere l'elenco completo):
Funzione di aggregazione
| Funzione | Descrizione |
|---|---|
arg_max() |
Restituisce una o più espressioni quando l'argomento è ingrandita |
arg_min() |
Restituisce una o più espressioni quando l'argomento viene ridotto a icona |
avg() |
Restituisce un valore medio nel gruppo |
buildschema() |
Restituisce lo schema minimo che ammette tutti i valori dell'input dinamico |
count() |
Restituisce il conteggio del gruppo |
countif() |
Restituisce il conteggio con il predicato del gruppo |
dcount() |
Restituisce un conteggio distinto approssimativo degli elementi del gruppo |
make_bag() |
Restituisce un contenitore di proprietà di valori dinamici all'interno del gruppo |
make_list() |
Restituisce un elenco di tutti i valori contenuti nel gruppo |
make_set() |
Restituisce un set di valori distinti contenuti nel gruppo |
max() |
Restituisce il valore massimo nel gruppo |
min() |
Restituisce il valore minimo nel gruppo |
percentiles() |
Restituisce il percentile approssimativo del gruppo |
stdev() |
Restituisce la deviazione standard del gruppo |
sum() |
Restituisce la somma degli elementi all'interno del gruppo |
take_any() |
Restituisce un valore casuale non vuoto per il gruppo |
variance() |
Restituisce la varianza del gruppo |
Selezione: aggiunta e rimozione di colonne
Quando si inizia a lavorare più con le query, è possibile che siano presenti più informazioni di quelle necessarie per gli argomenti, ovvero troppe colonne nella tabella. Oppure potrebbero essere necessarie più informazioni di quelle disponibili, ovvero è necessario aggiungere una nuova colonna che conterrà i risultati dell'analisi di altre colonne. Verranno ora esaminati alcuni degli operatori chiave per la manipolazione delle colonne.
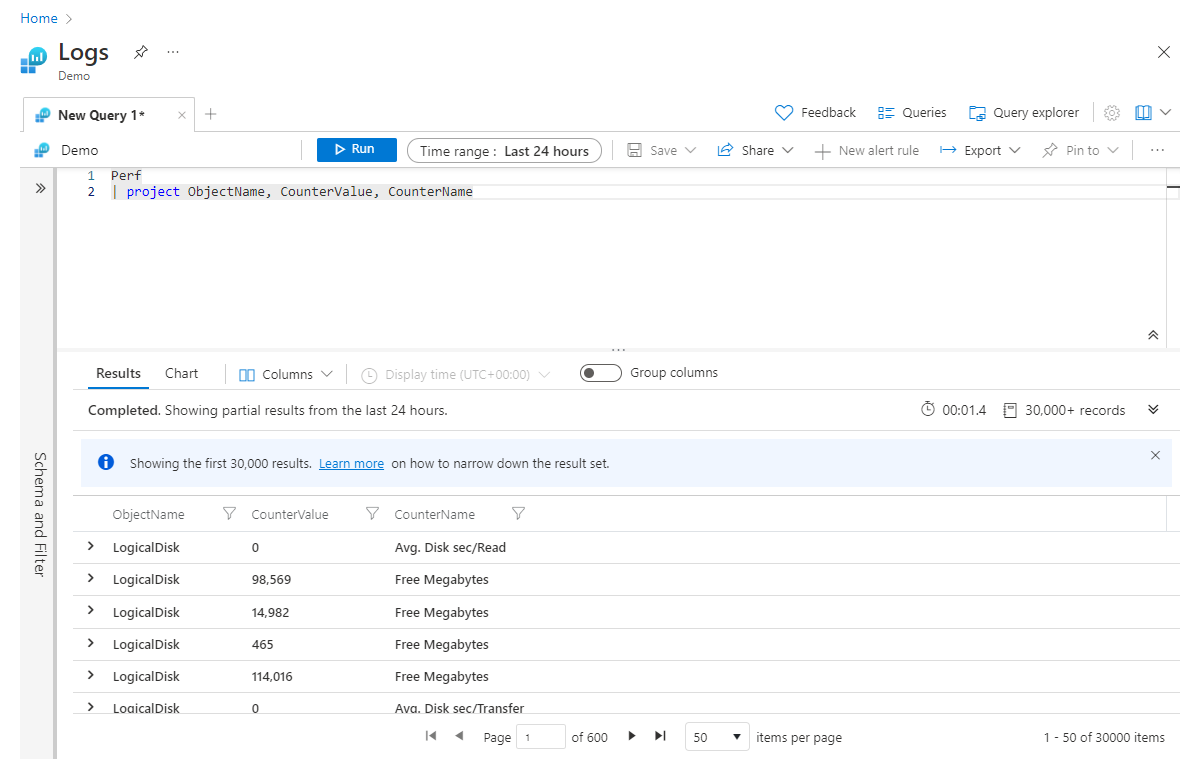
Project and project-away
Project equivale approssimativamente alle istruzioni select di molti linguaggi. Consente di scegliere le colonne da mantenere. L'ordine delle colonne restituite corrisponderà all'ordine delle colonne elencate nell'istruzione project , come illustrato in questo esempio:
Perf
| project ObjectName, CounterValue, CounterName
Come si può immaginare, quando si lavora con set di dati molto ampi, potrebbero essere presenti molte colonne da mantenere e specificarle tutte in base al nome richiederebbero molta digitazione. Per questi casi, si dispone di project-away, che consente di specificare quali colonne rimuovere, anziché quelle da conservare, come illustrato di seguito:
Perf
| project-away MG, _ResourceId, Type
Suggerimento
Può essere utile usare project in due posizioni nelle query, all'inizio e di nuovo alla fine. L'uso project nelle prime fasi della query consente di migliorare le prestazioni rimuovendo blocchi di dati di grandi dimensioni che non è necessario passare alla pipeline. Usandolo di nuovo alla fine, è possibile eliminare tutte le colonne che potrebbero essere state create nei passaggi precedenti e non sono necessarie nell'output finale.
Estendi
L'estensione viene utilizzata per creare una nuova colonna calcolata. Ciò può essere utile quando si desidera eseguire un calcolo su colonne esistenti e visualizzare l'output per ogni riga. Si esaminerà un semplice esempio in cui si calcola una nuova colonna denominata Kbytes, che è possibile calcolare moltiplicando il valore MB (nella colonna Quantity esistente) per 1.024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
Nella riga finale dell'istruzione project è stata rinominata la colonna Quantity in Mbytes, in modo da poter indicare facilmente quale unità di misura è rilevante per ogni colonna.
Vale la pena notare che extend funziona anche con colonne già calcolate. Ad esempio, è possibile aggiungere un'altra colonna denominata Byte calcolata da Kbytes:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Join di tabelle
Gran parte del lavoro in Microsoft Sentinel può essere eseguita usando un singolo tipo di log, ma in alcuni casi è necessario correlare i dati insieme o eseguire una ricerca su un altro set di dati. Come la maggior parte dei linguaggi di query, Linguaggio di query Kusto offre alcuni operatori usati per eseguire vari tipi di join. In questa sezione verranno esaminati gli operatori union più usati e join.
Union
Union accetta semplicemente due o più tabelle e restituisce tutte le righe. Ad esempio:
OfficeActivity
| union SecurityEvent
Verranno restituite tutte le righe dalle tabelle OfficeActivity e SecurityEvent . Union offre alcuni parametri che possono essere usati per regolare il comportamento dell'unione. Due delle più utili sono consource e tipo:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Il parametro withsource consente di specificare il nome di una nuova colonna il cui valore in una determinata riga sarà il nome della tabella da cui proviene la riga. Nell'esempio precedente è stata denominata la colonna SourceTable e, a seconda della riga, il valore sarà OfficeActivity o SecurityEvent.
L'altro parametro specificato è stato tipo, che ha due opzioni: interno o esterno. Nell'esempio precedente è stato specificato inner, ovvero le uniche colonne che verranno mantenute durante l'unione sono quelle presenti in entrambe le tabelle. In alternativa, se fosse stato specificato outer (ovvero il valore predefinito), verranno restituite tutte le colonne di entrambe le tabelle.
Join.
Il join funziona in modo analogo a union, ad eccezione del fatto che invece di unire tabelle per creare una nuova tabella, vengono unite righe per creare una nuova tabella. Analogamente alla maggior parte dei linguaggi di database, è possibile eseguire più tipi di join. La sintassi generale per un join è:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Dopo l'operatore join , si specifica il tipo di join da eseguire seguito da una parentesi aperta. All'interno delle parentesi è possibile specificare la tabella da unire, nonché qualsiasi altra istruzione di query nella tabella da aggiungere. Dopo la parentesi di chiusura, viene usata la parola chiave on seguita da sinistra ($left.<columnName> keyword) e right ($right.<colonne columnName>) separate con l'operatore ==. Ecco un esempio di inner join:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Nota
Se entrambe le tabelle hanno lo stesso nome per le colonne in cui si esegue un join, non è necessario usare $left e $right. È invece possibile specificare solo il nome della colonna. L'uso di $left e $right, tuttavia, è più esplicito e generalmente considerato una procedura consigliata.
Per riferimento, la tabella seguente mostra un elenco dei tipi di join disponibili.
Tipi di join
| Tipo di join | Descrizione |
|---|---|
inner |
Restituisce un singolo oggetto per ogni combinazione di righe corrispondenti di entrambe le tabelle. |
innerunique |
Restituisce righe dalla tabella a sinistra con valori distinti nel campo collegato che hanno una corrispondenza nella tabella a destra. Si tratta del tipo di join non specificato predefinito. |
leftsemi |
Restituisce tutti i record della tabella a sinistra che hanno una corrispondenza nella tabella a destra. Verranno restituite solo le colonne della tabella sinistra. |
rightsemi |
Restituisce tutti i record della tabella a destra che hanno una corrispondenza nella tabella a sinistra. Verranno restituite solo le colonne della tabella destra. |
leftanti/leftantisemi |
Restituisce tutti i record della tabella a sinistra che non hanno una corrispondenza nella tabella a destra. Verranno restituite solo le colonne della tabella sinistra. |
rightanti/rightantisemi |
Restituisce tutti i record della tabella a destra che non hanno una corrispondenza nella tabella a sinistra. Verranno restituite solo le colonne della tabella destra. |
leftouter |
Restituisce tutti i record della tabella sinistra. Per i record che non hanno corrispondenze nella tabella corretta, i valori delle celle saranno Null. |
rightouter |
Restituisce tutti i record della tabella corretta. Per i record che non hanno corrispondenze nella tabella sinistra, i valori delle celle saranno Null. |
fullouter |
Restituisce tutti i record delle tabelle sia a sinistra che a destra, corrispondenti o meno. I valori non corrispondenti saranno Null. |
Suggerimento
È consigliabile avere la tabella più piccola a sinistra. In alcuni casi, seguendo questa regola è possibile ottenere enormi vantaggi in termini di prestazioni, a seconda dei tipi di join sufficienti e delle dimensioni delle tabelle.
Evaluate
È possibile ricordare che nel primo esempio è stato visto l'operatore evaluate su una delle righe. L'operatore evaluate è meno comunemente usato di quelli che abbiamo toccato in precedenza. Tuttavia, sapere come funziona l'operatore evaluate vale la pena il vostro tempo. Ancora una volta, ecco la prima query, in cui verrà visualizzata evaluate nella seconda riga.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Questo operatore consente di richiamare i plug-in disponibili (fondamentalmente funzioni predefinite). Molti di questi plug-in sono incentrati sulla data science, ad esempio autocluster, diffpattern e sequence_detect, consentendo di eseguire analisi avanzate e individuare anomalie statistiche e outlier.
Il plug-in usato nell'esempio precedente è stato chiamato bag_unpack e rende molto semplice prendere un blocco di dati dinamici e convertirlo in colonne. Tenere presente che i dati dinamici sono un tipo di dati molto simile a JSON, come illustrato in questo esempio:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
In questo caso, si desidera riepilogare i dati in base alla città, ma la città è contenuta come proprietà all'interno della colonna LocationDetails . Per usare la proprietà city nella query, è necessario prima convertirla in una colonna usando bag_unpack.
Tornando ai passaggi originali della pipeline, è stato illustrato quanto segue:
Get Data | Filter | Summarize | Sort | Select
Ora che l'operatore evaluate è stato considerato, è possibile vedere che rappresenta una nuova fase nella pipeline, che ora ha un aspetto simile al seguente:
Get Data | Parse | Filter | Summarize | Sort | Select
Esistono molti altri esempi di operatori e funzioni che possono essere usati per analizzare le origini dati in un formato più leggibile e modificabile. È possibile ottenere informazioni su di essi, e il resto del Linguaggio di query Kusto, nella documentazione completa e nella cartella di lavoro.
Istruzioni "let"
Ora che sono stati trattati molti dei principali operatori e tipi di dati, si esaminerà l'istruzione let, che è un ottimo modo per semplificare la lettura, la modifica e la gestione delle query.
Let consente di creare e impostare una variabile o di assegnare un nome a un'espressione. Questa espressione può essere un singolo valore, ma potrebbe anche essere un'intera query. Ecco un semplice esempio:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
In questo caso è stato specificato un nome di aWeekAgo e lo si imposta come uguale all'output di una funzione timespan, che restituisce un valore datetime. Terminare quindi l'istruzione let con un punto e virgola. Ora è disponibile una nuova variabile denominata aWeekAgo che può essere usata in qualsiasi punto della query.
Come appena accennato, è possibile usare un'istruzione let per eseguire un'intera query e assegnare un nome al risultato. Poiché i risultati delle query, essendo espressioni tabulari, possono essere usati come input di query, è possibile trattare questo risultato denominato come tabella ai fini dell'esecuzione di un'altra query su di essa. Ecco una leggera modifica all'esempio precedente:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
In questo caso è stata creata una seconda istruzione let , in cui è stato eseguito il wrapping dell'intera query in una nuova variabile denominata getSignins. Proprio come in precedenza, viene terminata la seconda istruzione let con un punto e virgola. Viene quindi chiamata la variabile nella riga finale, che eseguirà la query. Si noti che è stato possibile usare aWeekAgo nella seconda istruzione let . Ciò è dovuto al fatto che è stato specificato nella riga precedente; se fosse necessario scambiare le istruzioni let in modo che getSignins sia arrivato per primo, si otterrebbe un errore.
È ora possibile usare getSignins come base di un'altra query (nella stessa finestra):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Le istruzioni let offrono maggiore potenza e flessibilità per organizzare le query. È possibile definire valori scalari e tabulari, nonché creare funzioni definite dall'utente. Sono davvero utili quando si organizzano query più complesse che potrebbero eseguire più join.
Passaggi successivi
Anche se questo articolo ha appena graffiato la superficie, ora hai le basi necessarie e abbiamo trattato le parti che userai più spesso per svolgere il tuo lavoro in Microsoft Sentinel.
Cartella di lavoro avanzata KQL per Microsoft Sentinel
Sfruttare una cartella di lavoro Linguaggio di query Kusto direttamente in Microsoft Sentinel, ovvero la cartella di lavoro avanzata KQL per Microsoft Sentinel. Offre informazioni dettagliate ed esempi per molte delle situazioni che è probabile riscontrare durante le operazioni di sicurezza quotidiane, oltre a fornire numerosi esempi predefiniti di regole di analisi, cartelle di lavoro, regole di ricerca e altri elementi che usano query Kusto. Avviare questa cartella di lavoro dal pannello Cartelle di lavoro in Microsoft Sentinel.
Cartella di lavoro avanzata di KQL Framework: consente di diventare esperti di KQL è un eccellente post di blog che illustra come usare questa cartella di lavoro.
Altre risorse
Vedere questa raccolta di risorse di apprendimento, formazione e competenze per ampliare e approfondire la conoscenza di Linguaggio di query Kusto.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per