Gestione dell'utilizzo delle risorse e del carico in Service Fabric con le metriche
Con metriche si intendono le risorse rilevanti per i servizi, che sono fornite dai nodi nel cluster. Una metrica è un qualsiasi elemento che si vuole gestire per controllare o migliorare le prestazioni dei servizi. Ad esempio, è possibile osservare il consumo di memoria per capire se il servizio è sovraccarico. Le metriche possono essere usate per determinare se il servizio può essere spostato in un'altra posizione con memoria meno vincolata, per ottenere prestazioni migliori.
Sono metriche, ad esempio, l'utilizzo della CPU, della memoria e dei dischi. In questo caso si tratta di metriche fisiche, ovvero risorse che corrispondono alle risorse fisiche nel nodo e che devono essere gestite. Le metriche possono anche essere logiche e in genere sono di questo tipo. Sono metriche logiche, ad esempio, "MyWorkQueueDepth", "MessagesToProcess" e "TotalRecords". Le metriche logiche sono definite dall'applicazione e corrispondono indirettamente al consumo di alcune risorse fisiche. Sono comuni in quanto può essere difficile misurare e creare report sul consumo delle risorse fisiche per ogni servizio. La complessità della misurazione e della creazione di report delle metriche è anche il motivo per cui in Service Fabric vengono fornite alcune metriche predefinite.
Metriche predefinite
Si supponga che si desideri iniziare a scrivere e a distribuire il servizio. Ancora non si conoscono le risorse fisiche o logiche che il servizio consuma. Questo approccio non presenta problemi. Cluster Resource Manager di Service Fabric usa alcune metriche predefinite quando non vengono specificate altre metriche. Sono:
- PrimaryCount - Numero di repliche primarie nel nodo
- ReplicaCount - Numero di repliche con stato totali nel nodo
- Count - Numero di oggetti servizio (con e senza stato) nel nodo
| Metric | Carico di istanza senza stato | Carico secondario con stato | Carico primario con stato | Weight |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Alto |
| ReplicaCount | 0 | 1 | 1 | Medio |
| Count | 1 | 1 | 1 | Basso |
Per i carichi di lavoro di base, le metriche predefinite forniscono una distribuzione ragionevole del lavoro nel cluster. L'esempio seguente illustra che cosa accade quando si creano due servizi e ci si affida alle metriche predefinite per il bilanciamento. Il primo è un servizio con stato con tre partizioni e dimensioni del set di repliche di destinazione pari a tre. Il secondo è un servizio senza stato con una partizione e un numero di istanze pari a tre.
Ecco cosa si ottiene:
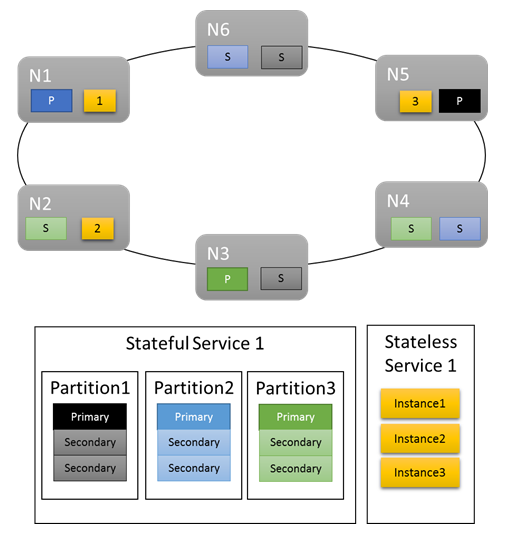
Ci sono alcuni aspetti da considerare:
- Le repliche primarie per il servizio con stato vengono distribuite tra più nodi.
- Le repliche della stessa partizione si trovano su nodi differenti.
- Il numero totale di elementi primari e secondari è distribuito nel cluster.
- Il numero totale di oggetti di servizio è allocato in modo uniforme in ogni nodo.
Bene,
Le metriche predefinite sono un punto di partenza ideale, ma non consentono di andare troppo oltre. Sono infatti un approccio efficace fino a quando non si prende in considerazione l'effettiva probabilità che lo schema di partizionamento selezionato produca un consumo perfettamente uniforme in tutte le partizioni, e che il carico per un determinato servizio sia costante nel tempo o resti invariato.
È possibile operare solo con le metriche predefinite, tuttavia, in genere ciò significa che il consumo del cluster è inferiore e non uniforme come desiderato. Ciò è dovuto al fatto che le metriche predefinite non sono adattive e presuppongono che tutti gli elementi siano equivalenti. Ad esempio, una replica primaria e una che non lo è contribuiscono entrambe con "1" alla metrica PrimaryCount. Nel peggiore dei casi, l'uso delle sole metriche predefinite può determinare anche la sovrapianificazione dei nodi e di conseguenza problemi di prestazioni. Se si è interessati a sfruttare al meglio il cluster e a evitare problemi di prestazioni, è opportuno prendere in considerazione metriche personalizzate e creazione di report sul carico dinamico.
Metriche personalizzate
Le metriche sono configurate in base alle singole istanze del servizio durante la creazione del servizio.
Qualsiasi metrica è descritta da alcune proprietà: nome, carico predefinito e peso.
- Nome della metrica: il nome della metrica, che è un identificatore univoco della metrica nel cluster dal punto di vista di Resource Manager.
Nota
Il nome della metrica personalizzata non deve essere uno dei nomi delle metriche di sistema, ad esempio servicefabric:/_CpuCores o servicefabric:/_MemoryInMB perché può causare un comportamento non definito. A partire da Service Fabric versione 9.1, per i servizi esistenti con questi nomi di metriche personalizzati viene generato un avviso di integrità per indicare che il nome della metrica non è corretto.
- Peso: il peso della metrica ne definisce l'importanza rispetto alle altre metriche per il servizio.
- Default Load: il carico predefinito è rappresentato in modo diverso a seconda che il servizio sia con o senza stato.
- Per i servizi senza stato, ogni metrica ha un'unica proprietà denominata DefaultLoad
- Per i servizi con stato definiti:
- PrimaryDefaultLoad: quantità predefinita della metrica utilizzata dal servizio quando è primario
- SecondaryDefaultLoad: quantità predefinita della metrica utilizzata dal servizio quando è secondario
Nota
Se si definiscono metriche personalizzate e si vogliono usare anche le metriche predefinite, è necessario aggiungerle esplicitamente, e definire per queste pesi e valori, così da stabilire la relazione tra le metriche predefinite e quelle personalizzate. Ad esempio, si può essere più interessati a una metrico di tipo ConnectionCount o WorkQueueDepth che alla distribuzione della metrica primaria. Per impostazione predefinita il peso della metrica PrimaryCount è elevato, pertanto si desidera ridurlo a medio se si aggiungono altre metriche, per garantire che abbiano la precedenza.
Definizione delle metriche per il servizio: esempio
Si supponga di voler ottenere la configurazione seguente:
- Il servizio segnala una metrica denominata "ConnectionCount".
- Si desidera usare anche le metriche predefinite.
- Sono state eseguite alcune misurazioni rilevando che normalmente per una replica primaria del servizio sono necessarie 20 unità di "ConnectionCount",
- mentre per quelle secondarie ne sono necessarie cinque.
- Si è consapevoli del fatto che "ConnectionCount" è la metrica più importante in termini di gestione delle prestazioni del servizio specifico,
- ma si vuole comunque che le repliche primarie siano bilanciate. Il bilanciamento delle repliche primarie è comunque un approccio consigliabile. Consente infatti di evitare che la perdita di alcuni nodi o domini di errore abbia conseguenze anche su un gran numero di repliche primarie.
- Altrimenti, le metriche predefinite sono comunque una scelta valida.
Di seguito è riportato il codice da scrivere per creare un servizio con tale configurazione delle metriche:
Codice:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Nota
Gli esempi precedenti e ciò che segue in questo documento illustrano come gestire le metriche di gestione di ogni specifico servizio. È anche possibile definire le metriche per i servizi a livello di tipo del servizio. A tal fine, specificarle nei manifesti del servizio. La definizione delle metriche a livello di tipo non è consigliata per diversi motivi. Il primo è che i nomi delle metriche sono spesso specifici dell'ambiente. A meno che non sia disponibile un contratto aziendale, non è possibile assicurarsi che la metrica "Cores" in un ambiente non sia "MiliCores" o "CoRes" in altri. Se le metriche vengono definite nel manifesto è necessario creare nuovi manifesti per ogni ambiente. Questo comporta in genere una proliferazione di manifesti diversi che presentano solo piccole differenze, e ciò può implicare difficoltà di gestione.
I carichi delle metriche vengono in genere assegnati in base a determinate istanze del servizio. Si supponga, ad esempio, di creare un'istanza del servizio per ClienteA, che ne prevede un utilizzo saltuario. Si supponga quindi di crearne un'altra per ClienteB, che ha un carico di lavoro maggiore. In questo caso probabilmente si desidera ottimizzare i carichi predefiniti per tali servizi. In presenza di metriche e carichi definiti tramite i manifesti e si desidera supportare questo scenario, sono necessari tipi di servizio e applicazione diversi per ogni cliente. I valori definiti al momento della creazione del servizio sostituiscono quelli definiti nel manifesto, ed è pertanto possibile usarli per impostare valori predefiniti specifici. Tuttavia, questa operazione determina che i valori dichiarati nei manifesti non corrispondano a quelli con i quali viene eseguito il servizio. Ciò può causare confusione.
Promemoria: se si vogliono usare solo le metriche predefinite, non è necessario modificare in alcun modo la raccolta di metriche né eseguire operazioni speciali durante la creazione del servizio. Le metriche predefinite vengono usate automaticamente quando non ne sono definite altre.
Di seguito ognuna di queste impostazioni viene esaminata in modo più dettagliato; viene inoltre descritto il comportamento sul quale essa agisce.
Load
La definizione di metriche consiste essenzialmente nella rappresentazione di un carico. Il carico è la quantità di una determinata metrica che viene consumata da una replica o un'istanza del servizio in un nodo specifico. Il carico può essere configurato in qualsiasi momento, Ad esempio:
- Può essere definito quando viene creato un servizio. Questo tipo di configurazione del carico è denominato caricamento predefinito.
- Le informazioni sulle metriche, inclusi i caricamenti predefiniti, per un servizio possono essere aggiornate dopo la creazione del servizio. Questo aggiornamento delle metriche viene eseguito aggiornando un servizio.
- Il carico di una determinata partizione può essere reimpostato sui valori predefiniti per il servizio. Questo aggiornamento delle metriche è denominato reimpostazione del carico della partizione.
- Il caricamento può essere segnalato per ogni oggetto servizio, in modo dinamico durante il runtime. Questo aggiornamento delle metriche è denominato caricamento dei report.
- Il carico per le repliche o le istanze della partizione può anche essere aggiornato tramite la creazione di report sui valori di caricamento tramite una chiamata API di Infrastruttura. Questo aggiornamento delle metriche viene chiamato carico di report per una partizione.
Tutte queste strategie possono essere usate nello stesso servizio per tutta la relativa durata.
Carico predefinito
Il carico predefinito è la quantità di metrica consumata da ogni oggetto servizio (istanza senza stato o replica con stato) del servizio specifico. Cluster Resource Manager usa questo numero per il carico dell'oggetto servizio finché non riceve altre informazioni, ad esempio un report del carico dinamico. Per i servizi più semplici, il carico predefinito è una definizione statica. Non viene mai aggiornato e viene usato per tutta la durata del servizio. I carichi predefiniti funzionano in modo ottimale per scenari di pianificazione della capacità semplice in cui determinate quantità di risorse sono dedicate a carichi di lavoro diversi e non cambiano.
Nota
Per altre informazioni sulla gestione della capacità e su come definire le capacità dei nodi del cluster, vedere questo articolo.
Cluster Resource Manager consente ai servizi con stato di definire un carico predefinito diverso per le repliche primarie e quelle secondarie, mentre per i servizi senza stato può essere specificato un solo valore, applicato a tutte le istanze. Per i servizi con stato, il carico predefinito per le repliche primarie e secondarie è in genere diverso perché le repliche eseguono diverse tipologie di lavoro nel rispettivo ruolo. A differenza delle repliche secondarie, ad esempio, le repliche primarie gestiscono in genere operazioni sia di lettura che di scrittura, oltre alla maggior parte delle operazioni di calcolo. In genere il carico predefinito di una replica primaria è superiore rispetto al carico predefinito delle repliche secondarie. I valori effettivi dipendono dalle proprie misurazioni.
Carico dinamico
Si supponga di aver eseguito un servizio per un determinato periodo di tempo e di aver rilevato, con alcune attività di monitoraggio, quanto segue:
- Alcune partizioni o istanze di un determinato servizio utilizzano più risorse di altre.
- Il carico di alcuni servizi varia nel tempo.
Fluttuazioni del carico di questo tipo possono avere diverse cause. Ad esempio, servizi o partizioni diversi sono associati a clienti diversi con esigenze differenti. Il carico può anche cambiare, perché la quantità di lavoro svolto dal servizio varia nel corso della giornata. Indipendentemente dal motivo, non esiste un singolo numero che possa essere usato come valore predefinito. Ciò vale soprattutto se si desidera ottimizzare al massimo il consumo del cluster. Qualsiasi valore selezionato come carico predefinito risulterà errato in determinati momenti. Carichi predefiniti non corretti causano un'allocazione eccessiva o insufficiente di risorse per il servizio da parte di Cluster Resource Manager. Di conseguenza, i nodi saranno sovrautilizzati o sottoutilizzati nonostante Cluster Resource Manager ritenga che il cluster sia bilanciato. I carichi predefiniti sono comunque validi perché forniscono alcune informazioni, ma non rappresentano interamente i carichi di lavoro reali. È possibile acquisire in modo preciso le variazioni dei requisiti delle risorse. Cluster Resource Manager consente a ogni oggetto servizio di aggiornare il proprio carico in fase di esecuzione, con la creazione di report di carico dinamici.
I report di carico dinamici consentono alle repliche o alle istanze di modificare l'allocazione o il carico segnalato delle metriche nel corso della propria durata. Una replica o un'istanza del servizio che è inattiva e non esegue alcuna operazione segnalerà in genere un uso ridotto di una determinata metrica, mentre una replica o un'istanza occupata segnalerà un uso superiore.
La creazione di report per ogni replica o istanza consente a Cluster Resource Manager di riorganizzare i singoli oggetti di servizio nel cluster, in modo da garantire che i servizi ottengano le risorse necessarie. I servizi occupati riescono effettivamente a "recuperare" le risorse da altre repliche o istanze attualmente inattive o meno occupate.
In Reliable Services, il codice per la creazione di report di carico dinamici si presenterà come riportato di seguito.
Codice:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Un servizio può segnalare in un report una qualsiasi delle metriche definite al momento della creazione. Se un servizio segnala il carico per una metrica non configurata per l'utilizzo, Service Fabric ignora il report. Se nello stesso momento vengono segnalate altre metriche valide, i report vengono accettati. Il codice del servizio può eseguire la misurazione e la creazione di report per tutte le metriche configurate e gli operatori possono specificare la configurazione delle metriche da usare senza dover modificare il codice.
Segnalazione del carico per una partizione
La sezione precedente descrive il caricamento delle repliche o delle istanze del servizio stesso. È disponibile un'opzione aggiuntiva per segnalare dinamicamente il carico per le repliche o le istanze di una partizione tramite l'API di Service Fabric. Quando si segnala il carico per una partizione, è possibile segnalare più partizioni contemporaneamente.
Tali report verranno usati esattamente come i report di caricamento provenienti dalle repliche o dalle istanze stesse. I valori segnalati saranno validi fino a quando non vengono segnalati nuovi valori di carico, dalla replica o dall'istanza o segnalando un nuovo valore di carico per una partizione.
Con questa API sono disponibili diversi modi per aggiornare il carico nel cluster:
- Una partizione del servizio con stato può aggiornare il carico della replica primaria.
- Entrambi i servizi senza stato e con stato possono aggiornare il carico di tutte le repliche o istanze secondarie.
- Entrambi i servizi senza stato e con stato possono aggiornare il carico di una replica o di un'istanza specifica in un nodo.
È anche possibile combinare uno di questi aggiornamenti per partizione contemporaneamente. È necessario specificare la combinazione di aggiornamenti di carico per una determinata partizione tramite l'oggetto PartitionMetricLoadDescription, che può contenere l'elenco corrispondente di aggiornamenti di caricamento, come illustrato nell'esempio seguente. Gli aggiornamenti del carico vengono rappresentati tramite l'oggetto MetricLoadDescription, che può contenere il valore di carico corrente o stimato per una metrica, specificato con un nome di metrica.
Nota
I valori di carico delle metriche stimati sono attualmente una funzionalità di anteprima. Consente di segnalare e usare i valori di carico stimati sul lato Service Fabric, ma questa funzionalità non è attualmente abilitata.
L'aggiornamento dei carichi per più partizioni è possibile con una singola chiamata API, nel qual caso l'output conterrà una risposta per partizione. Nel caso in cui l'aggiornamento della partizione non venga applicato correttamente per qualsiasi motivo, gli aggiornamenti per tale partizione verranno ignorati e verrà fornito il codice di errore corrispondente per una partizione di destinazione:
- PartitionNotFound: l'ID di partizione specificato non esiste.
- Riconfigurazione In sospeso: la partizione è attualmente riconfigurazione.
- InvalidForStatelessServices: è stato effettuato un tentativo di modificare il carico di una replica primaria per una partizione appartenente a un servizio senza stato.
- ReplicaDoesNotExist: la replica o l'istanza secondaria non esiste in un nodo specificato.
- InvalidOperation: può verificarsi in due casi: l'aggiornamento del carico per una partizione appartenente all'applicazione di sistema o l'aggiornamento del carico stimato non è abilitato.
Se vengono restituiti alcuni di questi errori, è possibile aggiornare l'input per una partizione specifica e riprovare l'aggiornamento.
Codice:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
Con questo esempio si eseguirà un aggiornamento dell'ultimo carico segnalato per una partizione 53df3d7f-5471-403b-b736-bde6ad584f42. Il carico della replica primaria per una metrica CustomMetricName0 verrà aggiornato con il valore 100. Allo stesso tempo, il caricamento per la stessa metrica per una replica secondaria specifica situata nel nodo NodeName0 verrà aggiornato con il valore 200.
Aggiornamento della configurazione delle metriche di un servizio
È possibile aggiornare in modo dinamico e in tempo reale l'elenco delle metriche associate al servizio e le proprietà di tali metriche. Questo approccio consente di sperimentare con flessibilità. Di seguito alcuni esempi che mostrano l'utilità di questo tipo di aggiornamento:
- disabilitazione di una metrica con un report anomalo per un determinato servizio;
- riconfigurazione dei pesi di metriche in base al comportamento desiderato;
- abilitazione di una nuova metrica solo dopo che il codice è stato distribuito e convalidato tramite altri meccanismi;
- modifica del carico predefinito per un servizio in base al consumo e al comportamento osservato.
Le principali API per modificare la configurazione della metrica sono disponibili FabricClient.ServiceManagementClient.UpdateServiceAsync in C# e Update-ServiceFabricService in PowerShell. Tutte le informazioni specificate con queste API sostituiscono immediatamente le informazioni sulla metrica esistenti relative al servizio.
Combinazione di valori di carico predefiniti e report sul carico dinamico
È possibile usare per lo stesso servizio il carico predefinito e carichi dinamici. Quando un servizio usa sia il carico predefinito sia i report di carico dinamici, il carico predefinito funge da stima finché non sono disponibili i report dinamici. Il carico predefinito è efficace perché offre a Cluster Resource Manager elementi su cui lavorare. Consente anche di posizionare in modo ottimale gli oggetti servizio quando vengono creati. Se non vengono specificate informazione sul carico predefinito, i servizi vengono posizionati in modo casuale. Quando i report di carico vengono ricevuti in un secondo momento, il posizionamento casuale iniziale è spesso errato e Cluster Resource Manager deve spostare i servizi.
Partendo dall'esempio precedente, è possibile verificare le conseguenze dell'aggiunta di alcune metriche personalizzate e dei report di carico dinamici. In questo esempio verrà usata la metrica "MemoryInMb".
Nota
La memoria è una delle metriche di sistema che Service Fabric è in grado di controllare come risorsa; la creazione manuale dei relativi report in genere è difficile. In realtà non si prevede che l'utente crei report sul consumo di memoria; la memoria viene usata come supporto per comprendere le funzionalità di Cluster Resource Manager,
e si presuppone che il servizio con stato sia stato inizialmente creato con il comando riportato di seguito.
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Si ricordi che la sintassi è ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad").
Un layout di cluster può avere un aspetto analogo al seguente:
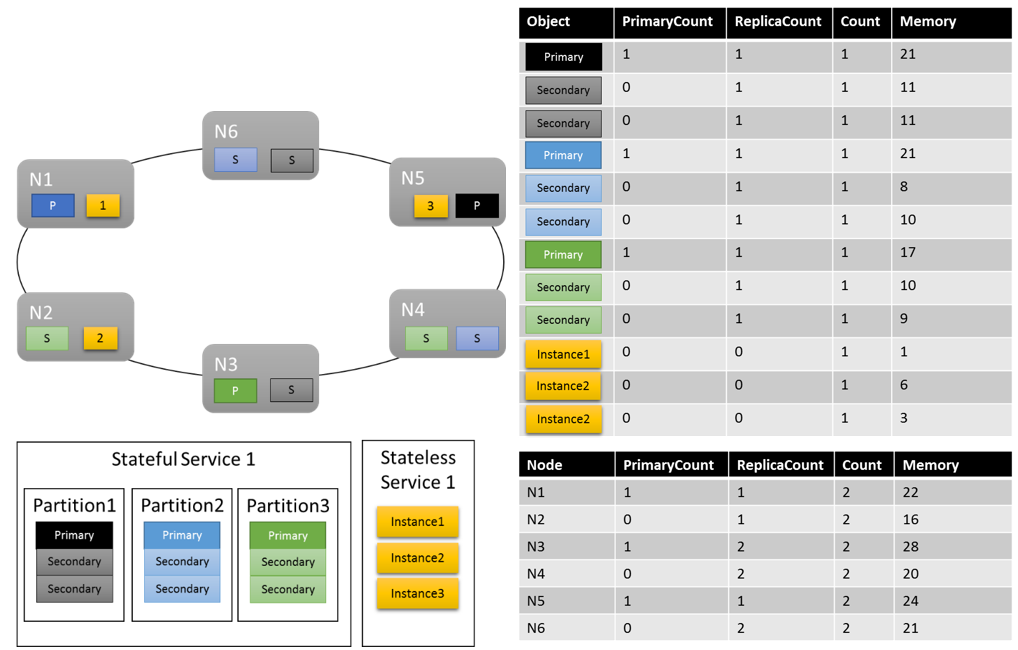
Occorre notare alcuni aspetti:
- Le repliche secondarie in una partizione possono avere un carico specifico.
- Complessivamente, le metriche appaiono bilanciate. Per la memoria, il rapporto tra carico massimo e minimo è 1,75. Il nodo con il carico maggiore è N3, quello con il carico minore è N2 e 28/16 = 1,75.
Restano ancora da spiegare alcuni aspetti:
- In che modo è stato stabilito se un rapporto di 1,75 è ragionevole? Come determina Cluster Resource Manager se la configurazione è ottimale o deve essere modificata?
- Quando viene applicato il bilanciamento?
- Cosa significa che il peso di Memory è "High"?
Pesi metrici
La possibilità di tenere traccia delle stesse metriche in diversi servizi è importante, perché consente a Cluster Resource Manager di tenere traccia del consumo nel cluster, bilanciare il consumo tra i nodi e garantire che non ne venga superata la capacità. La stessa metrica, tuttavia, può assumere una diversa importanza per i diversi servizi. In un cluster con molte metriche e numerosi servizi, inoltre, potrebbero non esistere soluzioni perfettamente bilanciate per tutte le metriche. Come devono essere gestite queste situazioni in Cluster Resource Manager?
I pesi delle metriche consentono a Cluster Resource Manager di decidere come bilanciare il cluster quando non esiste una risposta perfetta, nonché di bilanciare in modo diverso servizi specifici. Le metriche possono avere quattro livelli di peso diversi: Zero, Low, Medium e High. Una metrica con peso zero non ha impatto quando si valuta se gli elementi sono bilanciati o meno, ma il suo carico ha conseguenze sulla gestione della capacità. Le metriche con peso zero sono comunque utili e vengono spesso usate come componenti del comportamento del servizio e del monitoraggio delle prestazioni. Questo articolo offre altre informazioni sull'uso delle metriche per il monitoraggio e la diagnostica dei servizi.
L'impatto effettivo di pesi delle metriche diversi nel cluster consiste nel fatto che Cluster Resource Manager genera soluzioni diverse. I pesi indicano a Cluster Resource Manager che determinate metriche sono più importanti di altre. Quando non esiste una soluzione perfetta, Cluster Resource Manager può preferire soluzioni con un migliore bilanciamento delle metriche con peso superiore. Se una particolare metrica non è importante per un servizio, potrebbe sbilanciarne l'uso in modo da garantire a un altro servizio, per cui è importante, una distribuzione uniforme.
L'esempio seguente illustra alcuni report di carico e come pesi diversi delle metriche possono determinare allocazioni diverse nel cluster. In questo esempio si può notare che la modifica del peso relativo delle metriche fa sì che Cluster Resource Manager crei disposizioni diverse dei servizi.
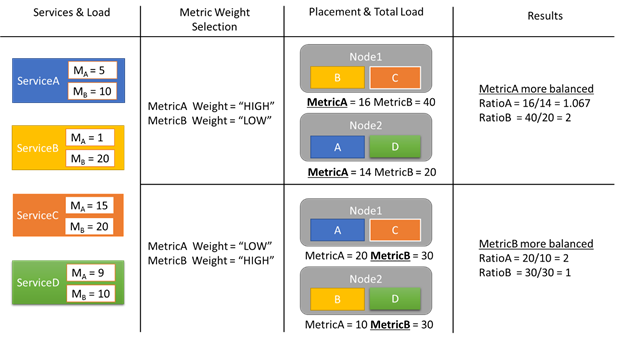
In questo esempio sono presenti quattro diversi servizi, tutti con valori diversi nei report di due diverse metriche, MetricA e MetricB. In un caso, tutti i servizi definiscono MetricA come la più importante (Peso = High) e MetricB come non importante (Peso = Low). Di conseguenza, Cluster Resource Manager posiziona i servizi in modo da ottenere per MetricA un bilanciamento migliore rispetto a MetricB. "Bilanciamento migliore" significa che MetricA presenta una deviazione standard inferiore rispetto a MetricB. Nel secondo caso, i pesi delle metriche sono invertiti. Di conseguenza, Cluster Resource Manager scambia i servizi A e B in modo da ottenere un'allocazione in cui il bilanciamento di MetricB è migliore rispetto a MetricA.
Nota
I pesi della metrica determinano il modo in cui Cluster Resource Manager esegue il bilanciamento, ma non quando questo debba verificarsi. Per altre informazioni sul bilanciamento, vedere questo articolo.
Pesi metrici globali
Si supponga che ServiceA definisca il peso di MetricA come High e ServiceB imposta il peso di MetricA su Low o Zero. Qual è il peso che verrà effettivamente usato?
Per ogni metrica esistono più pesi di cui tenere traccia. Il primo peso è quello definito per la metrica al momento della creazione del servizio. L'altro è un peso globale, che viene calcolato automaticamente. Cluster Resource Manager usa entrambi questi pesi per calcolare i punteggi delle soluzioni. Considerare entrambi i pesi è importante. Ciò consente a Cluster Resource Manager di bilanciare ogni servizio in base alle relative priorità e di verificare anche che il cluster nel suo complesso sia stato allocato correttamente.
Se Cluster Resource Manager non tiene conto del bilanciamento globale e locale, si possono avere soluzioni bilanciate a livello globale, ma che determinano allocazioni inefficienti delle risorse per i singoli servizi. L'esempio seguente illustra un servizio configurato esclusivamente con le metriche predefinite e mostra cosa accade se viene considerato solo il bilanciamento globale:
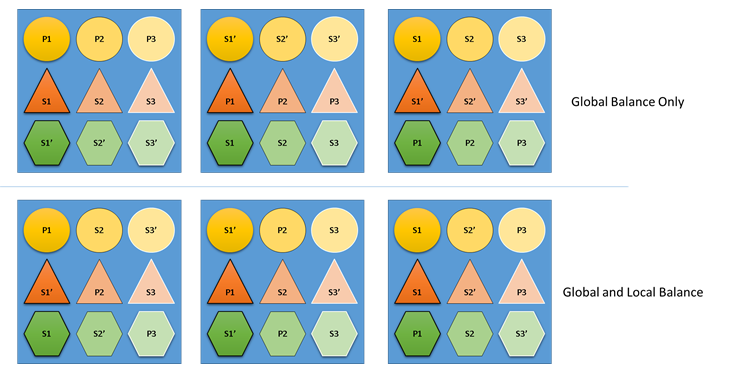
Nell'esempio in alto, basato solo sul bilanciamento globale, il cluster nel suo complesso è effettivamente bilanciato. Tutti i nodi hanno lo stesso numero di repliche primarie e di repliche totali. Se tuttavia si esamina l'impatto effettivo di questa allocazione, si notano alcuni problemi. La perdita di un nodo influisce in modo sproporzionato su un carico di lavoro specifico, perché rende inattive tutte le repliche primarie. In caso di errore nel primo nodo, ad esempio, tutte e tre le repliche primarie per le tre diverse partizioni del servizio rappresentato con il cerchio andrebbero perse. Le partizioni dei servizi rappresentati con il triangolo e con l'esagono perdono invece una replica. L'unica interruzione di servizio, in questo caso, consiste nel ripristinare la replica perduta.
Nell'esempio in basso, Cluster Resource Manager ha distribuito le repliche in base al bilanciamento globale e per i singoli servizi. Quando calcola il punteggio della soluzione, assegna la maggior parte del peso alla soluzione globale e una parte (configurabile) ai singoli servizi. Il bilanciamento globale della metrica viene calcolato in base alla media dei pesi delle metriche per ogni servizio. Ogni servizio viene bilanciato in base ai pesi delle metriche specificamente definiti. In questo modo, i servizi sono bilanciati internamente in base alle specifiche esigenze. In caso di errore nel primo nodo, quindi, la perdita viene distribuita in tutte le partizioni di tutti i servizi. L'impatto su ogni elemento è uguale.
Passaggi successivi
- Per altre informazioni sulla configurazione dei servizi vedere Informazioni sulla configurazione dei servizi(service-fabric-cluster-resource-manager-configure-services.md)
- La definizione delle metriche di deframmentazione è un modo per consolidare il carico sui nodi anziché distribuirlo. Per informazioni su come configurare la deframmentazione, vedere questo articolo
- Per informazioni sul modo in cui Cluster Resource Manager gestisce e bilancia il carico nel cluster, vedere l'articolo relativo al bilanciamento del carico
- Partire dall'inizio e vedere l' introduzione a Cluster Resource Manager di Service Fabric
- Il costo dello spostamento è un modo per segnalare a Cluster Resource Manager che alcuni servizi sono più costosi da spostare rispetto ad altri. Per altre informazioni sui costi di spostamento, vedere questo articolo