Distribuire un cluster di Azure Service Fabric in zone di disponibilità
zone di disponibilità in Azure sono un'offerta a disponibilità elevata che protegge le applicazioni e i dati dagli errori del data center. Una zona di disponibilità è una posizione fisica univoca dotata di alimentazione, raffreddamento e rete indipendenti all'interno di un'area di Azure.
Per supportare i cluster che si estendono su zone di disponibilità, Azure Service Fabric fornisce i due metodi di configurazione, come descritto nell'articolo seguente. zone di disponibilità sono disponibili solo nelle aree selezionate. Per altre informazioni, vedere la panoramica zone di disponibilità.
I modelli di esempio sono disponibili in Modelli di zona tra disponibilità di Service Fabric.
Topologia per lo spanning di un tipo di nodo primario in zone di disponibilità
Nota
Il vantaggio dell'estensione del tipo di nodo primario tra le zone di disponibilità è in realtà visibile solo per tre zone e non solo per due.
- Livello di affidabilità del cluster impostato su
Platinum - Una singola risorsa IP pubblica con SKU Standard
- Una singola risorsa del servizio di bilanciamento del carico con SKU Standard
- Un gruppo di sicurezza di rete (NSG) a cui fa riferimento la subnet in cui si distribuiscono i set di scalabilità di macchine virtuali
Nota
La proprietà del gruppo di posizionamento singolo del set di scalabilità di macchine virtuali deve essere impostata su true.
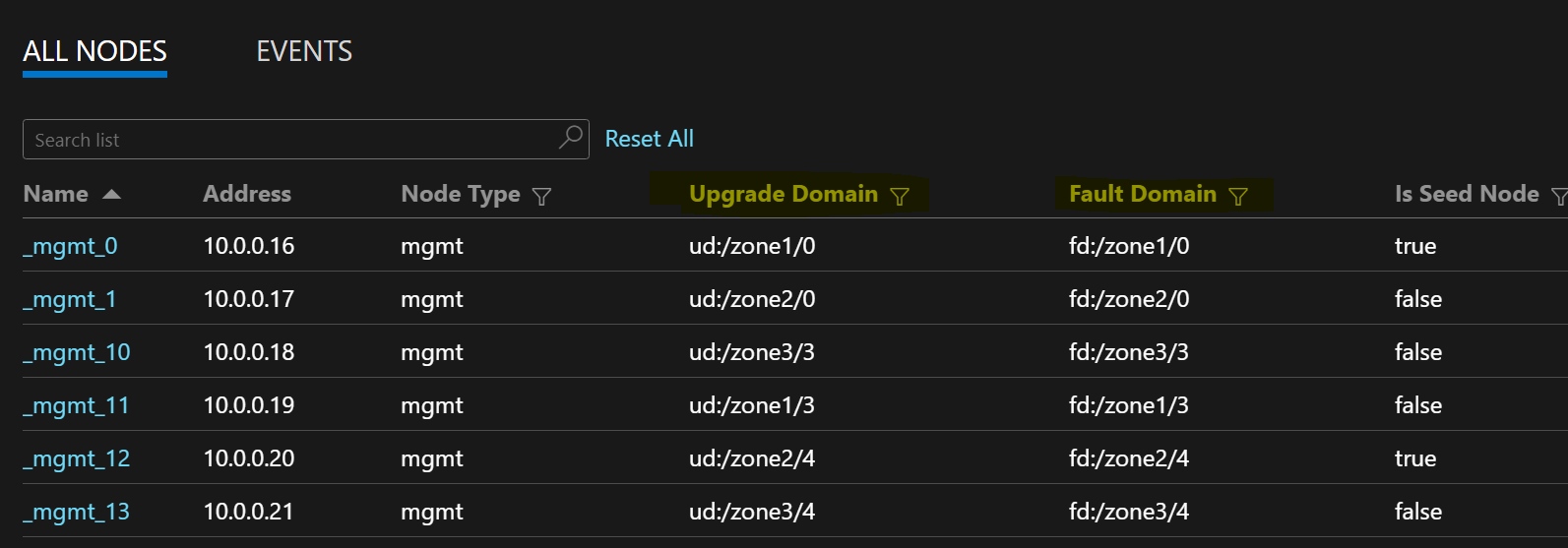
L'elenco di nodi di esempio seguente illustra i formati FD/UD in un set di scalabilità di macchine virtuali che si estende su zone:
Distribuzione delle repliche del servizio tra zone
Quando un servizio viene distribuito nei tipi di nodo che si estendono zone di disponibilità, le repliche vengono posizionate per assicurarsi che vengano posizionate in zone separate. I domini di errore nei nodi in ognuno di questi tipi di nodo vengono configurati con le informazioni sulla zona, ovvero FD = fd:/zone1/1 e così via. Ad esempio, per cinque repliche o istanze del servizio, la distribuzione è 2-2-1 e il runtime tenterà di garantire la stessa distribuzione tra le zone.
Configurazione della replica del servizio utente
I servizi utente con stato distribuiti nei tipi di nodo in zone di disponibilità devono essere configurati come segue: numero di repliche con destinazione = 9, min = 5. Questa configurazione consente il funzionamento del servizio anche quando una zona diventa inattiva perché le sei repliche saranno ancora in aumento nelle altre due zone. Anche un aggiornamento dell'applicazione in questo scenario avrà esito positivo.
Affidabilità clusterLevel
Questo valore definisce il numero di nodi di inizializzazione nel cluster e le dimensioni della replica dei servizi di sistema. Una configurazione tra zone di disponibilità ha un numero più elevato di nodi, distribuiti tra zone per abilitare la resilienza della zona.
Un valore superiore ReliabilityLevel garantisce che siano presenti più nodi di inizializzazione e repliche del servizio di sistema e distribuiti uniformemente tra le zone, in modo che se una zona ha esito negativo, il cluster e i servizi di sistema non sono interessati. ReliabilityLevel = Platinum (scelta consigliata) garantisce che siano presenti nove nodi di inizializzazione distribuiti tra le zone del cluster, con tre semi in ogni zona.
Scenario di zona verso il basso
Quando una zona diventa inattiva, tutti i nodi e le repliche del servizio per tale zona vengono visualizzati come inattivo. Poiché nelle altre zone sono presenti repliche, il servizio continua a rispondere. Le repliche primarie esezionano le zone funzionanti. I servizi sembrano essere in stati di avviso perché il numero di repliche di destinazione non è ancora raggiunto e il numero di macchine virtuali (VM) è ancora superiore alla dimensione minima della replica di destinazione.
Il servizio di bilanciamento del carico di Service Fabric consente di visualizzare le repliche nelle zone di lavoro in modo che corrispondano al numero di repliche di destinazione. A questo punto, i servizi appaiono integri. Quando la zona inattiva torna indietro, il servizio di bilanciamento del carico distribuirà in modo uniforme tutte le repliche del servizio tra le zone.
Ottimizzazioni imminenti
- Per fornire aggiornamenti affidabili dell'infrastruttura, Service Fabric richiede che la durabilità del set di scalabilità di macchine virtuali sia impostata almeno su Silver. Ciò consente al set di scalabilità di macchine virtuali sottostante e al runtime di Service Fabric di fornire aggiornamenti affidabili. Questa operazione richiede anche che ogni zona abbia almeno 5 macchine virtuali. Microsoft sta lavorando per ridurre questo requisito rispettivamente a 3 e 2 macchine virtuali per zona per i tipi di nodo primario e non primario.
- Tutte le configurazioni indicate di seguito e il lavoro successivo forniscono la migrazione sul posto ai clienti in cui è possibile aggiornare lo stesso cluster per usare la nuova configurazione aggiungendo nuovi nodeType e ritirando quelli precedenti.
Requisiti di rete
Ip pubblico e risorsa del servizio di bilanciamento del carico
Per abilitare la zones proprietà in una risorsa del set di scalabilità di macchine virtuali, il servizio di bilanciamento del carico e la risorsa IP a cui fa riferimento il set di scalabilità di macchine virtuali devono entrambi usare uno SKU Standard. La creazione di un servizio di bilanciamento del carico o una risorsa IP senza la proprietà SKU crea uno SKU Basic, che non supporta zone di disponibilità. Un servizio di bilanciamento del carico dello SKU Standard blocca tutto il traffico dall'esterno per impostazione predefinita. Per consentire il traffico esterno, distribuire un gruppo di sicurezza di rete nella subnet.
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/publicIPAddresses",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "Standard"
}
}
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/loadBalancers",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"dependsOn": [
"[concat('Microsoft.Network/networkSecurityGroups/', concat('nsg', parameters('subnet0Name')))]"
],
"properties": {
"addressSpace": {
"addressPrefixes": [
"[parameters('addressPrefix')]"
]
},
"subnets": [
{
"name": "[parameters('subnet0Name')]",
"properties": {
"addressPrefix": "[parameters('subnet0Prefix')]",
"networkSecurityGroup": {
"id": "[resourceId('Microsoft.Network/networkSecurityGroups', concat('nsg', parameters('subnet0Name')))]"
}
}
}
]
},
"sku": {
"name": "Standard"
}
}
Nota
Non è possibile eseguire una modifica sul posto dello SKU nell'indirizzo IP pubblico e nelle risorse del servizio di bilanciamento del carico. Se si esegue la migrazione da risorse esistenti con UNO SKU Basic, vedere la sezione relativa alla migrazione di questo articolo.
Regole NAT per i set di scalabilità di macchine virtuali
Le regole NAT (Network Address Translation) in ingresso per il servizio di bilanciamento del carico devono corrispondere ai pool NAT del set di scalabilità di macchine virtuali. Ogni set di scalabilità di macchine virtuali deve avere un pool NAT in ingresso univoco.
{
"inboundNatPools": [
{
"name": "LoadBalancerBEAddressNatPool0",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "50999",
"frontendPortRangeStart": "50000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool1",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "51999",
"frontendPortRangeStart": "51000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool2",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "52999",
"frontendPortRangeStart": "52000",
"protocol": "tcp"
}
}
]
}
Regole in uscita per un servizio di bilanciamento del carico dello SKU Standard
Il servizio di bilanciamento del carico dello SKU Standard e l'indirizzo IP pubblico introducono nuove capacità e comportamenti diversi per la connettività in uscita rispetto all'uso degli SKU Basic. Se si vuole la connettività in uscita quando si utilizzano SKU Standard, è necessario definirlo in modo esplicito con indirizzi IP pubblici dello SKU Standard o con un servizio di bilanciamento del carico dello SKU Standard. Per altre informazioni, vedere Connessioni in uscita e Informazioni su Azure Load Balancer.
Nota
Il modello standard fa riferimento a un gruppo di sicurezza di rete che consente tutto il traffico in uscita per impostazione predefinita. Il traffico in ingresso è limitato alle porte necessarie per le operazioni di gestione di Service Fabric. Le regole del gruppo di sicurezza di rete possono essere modificate per soddisfare i requisiti.
Importante
Ogni tipo di nodo in un cluster di Service Fabric che usa un servizio di bilanciamento del carico sku Standard richiede una regola che consenta il traffico in uscita sulla porta 443. Questa operazione è necessaria per completare la configurazione del cluster. Qualsiasi distribuzione senza questa regola avrà esito negativo.
1. Abilitare più zone di disponibilità in un singolo set di scalabilità di macchine virtuali
Questa soluzione consente agli utenti di estendersi su tre zone di disponibilità nello stesso tipo di nodo. Si tratta della topologia di distribuzione consigliata perché consente di distribuire tra zone di disponibilità mantenendo al tempo stesso un singolo set di scalabilità di macchine virtuali.
Un modello di esempio completo è disponibile in GitHub.
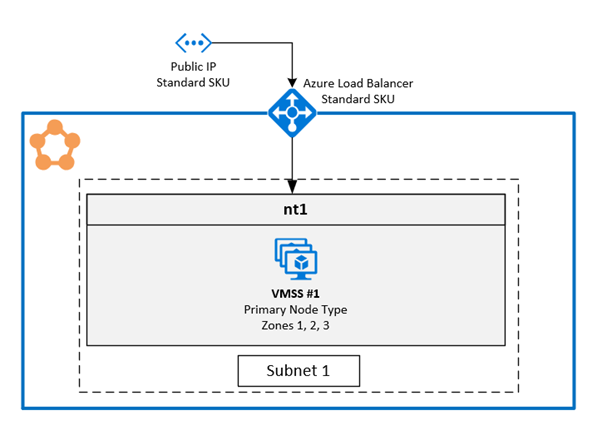
Configurazione delle zone in un set di scalabilità di macchine virtuali
Per abilitare le zone in un set di scalabilità di macchine virtuali, includere i tre valori seguenti nella risorsa del set di scalabilità di macchine virtuali:
Il primo valore è la
zonesproprietà , che specifica il zone di disponibilità presenti nel set di scalabilità di macchine virtuali.Il secondo valore è la
singlePlacementGroupproprietà , che deve essere impostata sutrue. Il set di scalabilità esteso tra tre zone di disponibilità può aumentare fino a 300 macchine virtuali anche consinglePlacementGroup = true.Il terzo valore è
zoneBalance, che garantisce un bilanciamento della zona rigoroso. Questo valore deve esseretrue. Ciò garantisce che le distribuzioni di macchine virtuali tra zone non siano sbilanciate, il che significa che quando una zona scende, le altre due zone hanno macchine virtuali sufficienti per mantenere il cluster in esecuzione.Un cluster con una distribuzione di macchine virtuali sbilanciata potrebbe non sopravvivere a uno scenario di zona inattivo perché tale zona potrebbe avere la maggior parte delle macchine virtuali. La distribuzione di macchine virtuali non bilanciate tra zone comporta anche problemi di posizionamento dei servizi e gli aggiornamenti dell'infrastruttura rimangono bloccati. Altre informazioni su zoneBalancing.
Non è necessario configurare le FaultDomain sostituzioni e UpgradeDomain .
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [ "1", "2", "3" ],
"properties": {
"singlePlacementGroup": true,
"zoneBalance": true
}
}
Nota
- I cluster di Service Fabric devono avere almeno un tipo di nodo primario. Il livello di durabilità dei tipi di nodo primario deve essere Silver o superiore.
- È necessario configurare un set di scalabilità di macchine virtuali con almeno tre zone di disponibilità, indipendentemente dal livello di durabilità.
- Un'area di disponibilità che si estende su un set di scalabilità di macchine virtuali con durabilità Silver o superiore deve avere almeno 15 macchine virtuali (5 per area).
- Un'area di disponibilità che si estende su un set di scalabilità di macchine virtuali con durabilità Bronze deve avere almeno sei macchine virtuali.
Abilitare il supporto per più zone nel tipo di nodo di Service Fabric
Il tipo di nodo di Service Fabric deve essere abilitato per supportare più zone di disponibilità.
Il primo valore è
multipleAvailabilityZones, che deve essere impostato sutrueper il tipo di nodo.Il secondo valore è e è
sfZonalUpgradeModefacoltativo. Questa proprietà non può essere modificata se un tipo di nodo con più zone di disponibilità è già presente nel cluster. Questa proprietà controlla il raggruppamento logico delle macchine virtuali nei domini di aggiornamento .This property controls the logical grouping of VMs in upgrade domains (UDS).- Se questo valore è impostato su
Parallel: le macchine virtuali nel tipo di nodo vengono raggruppate in ID e ignorano le informazioni sulla zona in cinque ID. Questa impostazione determina l'aggiornamento degli ID in tutte le zone contemporaneamente. Questa modalità di distribuzione è più veloce per gli aggiornamenti, non è consigliabile perché è in linea con le linee guida SDP, che indica che gli aggiornamenti devono essere applicati a un solo fuso alla volta. - Se questo valore viene omesso o impostato su
Hierarchical: le macchine virtuali vengono raggruppate per riflettere la distribuzione di zona in un massimo di 15 ID. Ognuna delle tre zone ha cinque ID. Ciò garantisce che le zone vengano aggiornate una alla volta, passando alla zona successiva solo dopo aver completato cinque ID all'interno della prima zona. Questo processo di aggiornamento è più sicuro per il cluster e l'applicazione utente.
Questa proprietà definisce solo il comportamento di aggiornamento per l'applicazione e gli aggiornamenti del codice di Service Fabric. Gli aggiornamenti del set di scalabilità di macchine virtuali sottostanti sono ancora paralleli in tutti i zone di disponibilità. Questa proprietà non influisce sulla distribuzione definita dall'utente per i tipi di nodo che non dispongono di più zone abilitate.
- Se questo valore è impostato su
Il terzo valore è
vmssZonalUpgradeMode, è facoltativo e può essere aggiornato in qualsiasi momento. Questa proprietà definisce lo schema di aggiornamento per il set di scalabilità di macchine virtuali in parallelo o sequenziale in zone di disponibilità.- Se questo valore è impostato su
Parallel: tutti gli aggiornamenti del set di scalabilità vengono eseguiti in parallelo in tutte le zone. Questa modalità di distribuzione è più veloce per gli aggiornamenti, non è consigliabile perché è in linea con le linee guida SDP, che indica che gli aggiornamenti devono essere applicati a un solo fuso alla volta. - Se questo valore viene omesso o impostato su
Hierarchical: in questo modo le zone vengono aggiornate una alla volta, passando alla zona successiva solo dopo aver completato cinque ID all'interno della prima zona. Questo processo di aggiornamento è più sicuro per il cluster e l'applicazione utente.
- Se questo valore è impostato su
Importante
La versione dell'API della risorsa cluster di Service Fabric deve essere 2020-12-01-preview o successiva.
La versione del codice del cluster deve essere atleast 8.1.321 o successiva.
{
"apiVersion": "2020-12-01-preview",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
"dependsOn": [
"[concat('Microsoft.Storage/storageAccounts/', parameters('supportLogStorageAccountName'))]"
],
"properties": {
"reliabilityLevel": "Platinum",
"sfZonalUpgradeMode": "Hierarchical",
"vmssZonalUpgradeMode": "Parallel",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"multipleAvailabilityZones": true
}
]
}
}
Nota
- Gli indirizzi IP pubblici e le risorse del servizio di bilanciamento del carico devono usare lo SKU Standard descritto in precedenza nell'articolo.
- La
multipleAvailabilityZonesproprietà nel tipo di nodo può essere definita solo quando viene creato il tipo di nodo e non può essere modificata in un secondo momento. I tipi di nodo esistenti non possono essere configurati con questa proprietà. - Quando
sfZonalUpgradeModeviene omesso o impostato suHierarchical, le distribuzioni di cluster e applicazioni saranno più lente perché nel cluster sono presenti più domini di aggiornamento. È importante modificare correttamente i timeout dei criteri di aggiornamento per tenere conto del tempo di aggiornamento necessario per 15 domini di aggiornamento. I criteri di aggiornamento per l'app e il cluster devono essere aggiornati per assicurarsi che la distribuzione non superi il limite di tempo di distribuzione del servizio risorse di Azure di 12 ore. Ciò significa che la distribuzione non deve richiedere più di 12 ore per 15 UD, ovvero non deve richiedere più di 40 minuti per ogni UD. - Impostare il livello di affidabilità del cluster per
Platinumassicurarsi che il cluster superi lo scenario di un'unica zona verso il basso. - L'aggiornamento di DurabilityLevel per un tipo di nodo con multipleAvailabilityZones non è supportato. Creare invece un nuovo tipo di nodo con maggiore durabilità.
- SF supporta solo 3 zone di disponibilità. Al momento non è supportato un numero più elevato.
Suggerimento
È consigliabile impostarla sfZonalUpgradeModeHierarchical su o ometterla. La distribuzione seguirà la distribuzione a livello di zona delle macchine virtuali e influirà su una quantità minore di repliche o istanze, rendendole più sicure.
Usare sfZonalUpgradeMode impostato su Parallel se la velocità di distribuzione è una priorità o solo i carichi di lavoro senza stato vengono eseguiti nel tipo di nodo con più zone di disponibilità. In questo modo, la procedura definita dall'utente viene eseguita in parallelo in tutte le zone di disponibilità.
Eseguire la migrazione al tipo di nodo con più zone di disponibilità
Per tutti gli scenari di migrazione, è necessario aggiungere un nuovo tipo di nodo che supporta più zone di disponibilità. Non è possibile eseguire la migrazione di un tipo di nodo esistente per supportare più zone. L'articolo Aumentare le prestazioni di un tipo di nodo primario del cluster di Service Fabric include passaggi dettagliati per aggiungere un nuovo tipo di nodo e le altre risorse necessarie per il nuovo tipo di nodo, ad esempio le risorse IP e di bilanciamento del carico. Questo articolo descrive anche come ritirare il tipo di nodo esistente dopo l'aggiunta di un nuovo tipo di nodo con più zone di disponibilità al cluster.
Migrazione da un tipo di nodo che usa il servizio di bilanciamento del carico di base e le risorse IP: questo processo è già descritto in una sezione secondaria seguente per la soluzione con un tipo di nodo per ogni zona di disponibilità.
Per il nuovo tipo di nodo, l'unica differenza è che è presente un solo set di scalabilità di macchine virtuali e un tipo di nodo per tutti i zone di disponibilità anziché uno per ogni zona di disponibilità.
Migrazione da un tipo di nodo che usa il servizio di bilanciamento del carico dello SKU Standard e le risorse IP con un gruppo di sicurezza di rete: seguire la stessa procedura descritta in precedenza. Non è tuttavia necessario aggiungere nuove risorse di bilanciamento del carico, IP e gruppo di sicurezza di rete. Le stesse risorse possono essere riutilizzate nel nuovo tipo di nodo.
2. Distribuire le zone aggiungendo un set di scalabilità di macchine virtuali a ogni zona
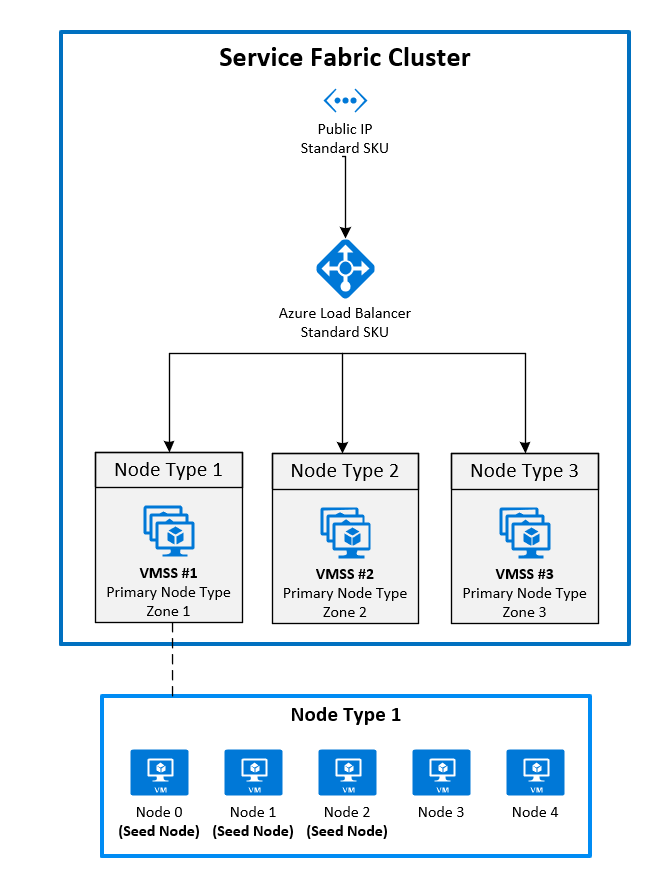
Questa è la configurazione disponibile a livello generale al momento. Per estendere un cluster di Service Fabric in zone di disponibilità, è necessario creare un tipo di nodo primario in ogni zona di disponibilità supportata dall'area. In questo modo i nodi di inizializzazione vengono distribuiti uniformemente in ogni tipo di nodo primario.
La topologia consigliata per il tipo di nodo primario richiede quanto segue:
- Tre tipi di nodo contrassegnati come primari
- Ogni tipo di nodo deve essere mappato al proprio set di scalabilità di macchine virtuali che si trova in una zona diversa.
- Ogni set di scalabilità di macchine virtuali deve avere almeno cinque nodi (durabilità Silver).
Il diagramma seguente illustra l'architettura della zona di disponibilità di Azure Service Fabric:
Abilitare le zone in un set di scalabilità di macchine virtuali
Per abilitare una zona in un set di scalabilità di macchine virtuali, includere i tre valori seguenti nella risorsa del set di scalabilità di macchine virtuali:
- Il primo valore è la
zonesproprietà , che specifica la zona di disponibilità in cui viene distribuito il set di scalabilità di macchine virtuali. - Il secondo valore è la
singlePlacementGroupproprietà , che deve essere impostata sutrue. - Il terzo valore è la
faultDomainOverrideproprietà nell'estensione del set di scalabilità di macchine virtuali di Service Fabric. Questa proprietà deve includere solo la zona in cui verrà inserito questo set di scalabilità di macchine virtuali. Esempio:"faultDomainOverride": "az1". Tutte le risorse del set di scalabilità di macchine virtuali devono essere inserite nella stessa area perché i cluster di Azure Service Fabric non dispongono del supporto tra aree.
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [
"1"
],
"properties": {
"singlePlacementGroup": true
},
"virtualMachineProfile": {
"extensionProfile": {
"extensions": [
{
"name": "[concat(parameters('vmNodeType1Name'),'_ServiceFabricNode')]",
"properties": {
"type": "ServiceFabricNode",
"autoUpgradeMinorVersion": false,
"publisher": "Microsoft.Azure.ServiceFabric",
"settings": {
"clusterEndpoint": "[reference(parameters('clusterName')).clusterEndpoint]",
"nodeTypeRef": "[parameters('vmNodeType1Name')]",
"dataPath": "D:\\\\SvcFab",
"durabilityLevel": "Silver",
"certificate": {
"thumbprint": "[parameters('certificateThumbprint')]",
"x509StoreName": "[parameters('certificateStoreValue')]"
},
"systemLogUploadSettings": {
"Enabled": true
},
"faultDomainOverride": "az1"
},
"typeHandlerVersion": "1.0"
}
}
]
}
}
}
Abilitare più tipi di nodo primario nella risorsa cluster di Service Fabric
Per impostare uno o più tipi di nodo come primario in una risorsa cluster, impostare la isPrimary proprietà su true. Quando si distribuisce un cluster di Service Fabric in zone di disponibilità, è necessario avere tre tipi di nodo in zone distinte.
{
"reliabilityLevel": "Platinum",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"applicationPorts": {
"endPort": "[parameters('nt0applicationEndPort')]",
"startPort": "[parameters('nt0applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt0fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt0ephemeralEndPort')]",
"startPort": "[parameters('nt0ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt0fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt0InstanceCount')]"
},
{
"name": "[parameters('vmNodeType1Name')]",
"applicationPorts": {
"endPort": "[parameters('nt1applicationEndPort')]",
"startPort": "[parameters('nt1applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt1fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt1ephemeralEndPort')]",
"startPort": "[parameters('nt1ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt1fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt1InstanceCount')]"
},
{
"name": "[parameters('vmNodeType2Name')]",
"applicationPorts": {
"endPort": "[parameters('nt2applicationEndPort')]",
"startPort": "[parameters('nt2applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt2fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt2ephemeralEndPort')]",
"startPort": "[parameters('nt2ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt2fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt2InstanceCount')]"
}
]
}
Eseguire la migrazione a zone di disponibilità da un cluster usando un servizio di bilanciamento del carico SKU Basic e un INDIRIZZO IP SKU Basic
Per eseguire la migrazione di un cluster che usa un servizio di bilanciamento del carico e un indirizzo IP con uno SKU di base, è prima necessario creare un servizio di bilanciamento del carico completamente nuovo e una risorsa IP usando lo SKU standard. Non è possibile aggiornare queste risorse.
Fare riferimento al nuovo servizio di bilanciamento del carico e all'indirizzo IP nei nuovi tipi di nodo zona tra disponibilità che si desidera usare. Nell'esempio precedente sono state aggiunte tre nuove risorse del set di scalabilità di macchine virtuali nelle zone 1, 2 e 3. Questi set di scalabilità di macchine virtuali fanno riferimento al servizio di bilanciamento del carico e all'INDIRIZZO IP appena creati e sono contrassegnati come tipi di nodo primari nella risorsa cluster di Service Fabric.
Per iniziare, aggiungere le nuove risorse al modello di Azure Resource Manager esistente. Tali risorse includono:
- Una risorsa IP pubblico con SKU Standard
- Una risorsa del servizio di bilanciamento del carico con SKU Standard
- Un gruppo di sicurezza di rete a cui fa riferimento la subnet in cui si distribuiscono i set di scalabilità di macchine virtuali
- Tre tipi di nodo contrassegnati come primari
- Ogni tipo di nodo deve essere mappato al proprio set di scalabilità di macchine virtuali che si trova in una zona diversa.
- Ogni set di scalabilità di macchine virtuali deve avere almeno cinque nodi (durabilità Silver).
Un esempio di queste risorse è disponibile nel modello di esempio.
New-AzureRmResourceGroupDeployment ` -ResourceGroupName $ResourceGroupName ` -TemplateFile $Template ` -TemplateParameterFile $ParametersAl termine della distribuzione delle risorse, è possibile disabilitare i nodi nel tipo di nodo primario dal cluster originale. Quando i nodi sono disabilitati, i servizi di sistema eseguono la migrazione al nuovo tipo di nodo primario distribuito in precedenza.
Connect-ServiceFabricCluster -ConnectionEndpoint $ClusterName ` -KeepAliveIntervalInSec 10 ` -X509Credential ` -ServerCertThumbprint $thumb ` -FindType FindByThumbprint ` -FindValue $thumb ` -StoreLocation CurrentUser ` -StoreName My Write-Host "Connected to cluster" $nodeNames = @("_nt0_0", "_nt0_1", "_nt0_2", "_nt0_3", "_nt0_4") Write-Host "Disabling nodes..." foreach($name in $nodeNames) { Disable-ServiceFabricNode -NodeName $name -Intent RemoveNode -Force }Dopo aver disabilitato tutti i nodi, i servizi di sistema verranno eseguiti nel tipo di nodo primario, che viene distribuito tra le zone. È quindi possibile rimuovere i nodi disabilitati dal cluster. Dopo aver rimosso i nodi, è possibile rimuovere l'INDIRIZZO IP, il servizio di bilanciamento del carico e le risorse del set di scalabilità di macchine virtuali originali.
foreach($name in $nodeNames){ # Remove the node from the cluster Remove-ServiceFabricNodeState -NodeName $name -TimeoutSec 300 -Force Write-Host "Removed node state for node $name" } $scaleSetName="nt0" Remove-AzureRmVmss -ResourceGroupName $groupname -VMScaleSetName $scaleSetName -Force $lbname="LB-cluster-nt0" $oldPublicIpName="LBIP-cluster-0" $newPublicIpName="LBIP-cluster-1" Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -ForceRimuovere quindi i riferimenti a queste risorse dal modello di Resource Manager distribuito.
Aggiornare infine il nome DNS e l'indirizzo IP pubblico.
$oldprimaryPublicIP = Get-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname
$primaryDNSName = $oldprimaryPublicIP.DnsSettings.DomainNameLabel
$primaryDNSFqdn = $oldprimaryPublicIP.DnsSettings.Fqdn
Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force
Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -Force
$PublicIP = Get-AzureRmPublicIpAddress -Name $newPublicIpName -ResourceGroupName $groupname
$PublicIP.DnsSettings.DomainNameLabel = $primaryDNSName
$PublicIP.DnsSettings.Fqdn = $primaryDNSFqdn
Set-AzureRmPublicIpAddress -PublicIpAddress $PublicIP