Migrazione di StorSimple 1200 a Sincronizzazione file di Azure
StorSimple serie 1200 è un'appliance virtuale che viene eseguita in un data center locale. È possibile eseguire la migrazione dei dati da questa appliance a un ambiente Sincronizzazione file di Azure. Sincronizzazione file di Azure è il servizio di Azure predefinito e strategico a lungo termine in cui è possibile eseguire la migrazione delle appliance StorSimple. Questo articolo fornisce le informazioni generali e i passaggi relativi alle migrazioni per una corretta migrazione a Sincronizzazione file di Azure.
Nota
Il servizio StorSimple (incluso Gestione dispositivi StorSimple per serie 8000 e 1200 e StorSimple Data Manager) ha raggiunto la fine del supporto. La fine del supporto per StorSimple è stata pubblicata nel 2019 nelle pagine Criteri del ciclo di vita Microsoft e Comunicazioni di Azure. Alcune notifiche aggiuntive sono state inviate tramite posta elettronica e pubblicate nel portale di Azure e nella panoramica di StorSimple. Per altri dettagli, contattare il supporto tecnico Microsoft.
Si applica a
| Tipo di condivisione file | SMB | NFS |
|---|---|---|
| Condivisioni file Standard (GPv2), archiviazione con ridondanza locale/archiviazione con ridondanza della zona | ||
| Condivisioni file Standard (GPv2), archiviazione con ridondanza geografica/archiviazione con ridondanza geografica della zona | ||
| Condivisioni file Premium (FileStorage), archiviazione con ridondanza locale/archiviazione con ridondanza della zona |
Sincronizzazione file di Azure
Sincronizzazione file di Azure è un servizio cloud Microsoft basato su due componenti principali:
- Sincronizzazione dei file e suddivisione in livelli cloud.
- Condivisioni file come archiviazione nativa in Azure a cui è possibile accedere tramite più protocolli, ad esempio SMB e FileREST. Una condivisione file di Azure è paragonabile a una condivisione file in Windows Server che è possibile montare in modo nativo come unità di rete. Supporta aspetti importanti della fedeltà dei file, ad esempio attributi, autorizzazioni e timestamp. A differenza di StorSimple, non è necessario alcun servizio/applicazione per interpretare i file e le cartelle archiviati nel cloud. L'approccio ideale e più flessibile consiste nell'archiviare i dati del file server per utilizzo generico e alcuni dati dell'applicazione nel cloud.
Questo articolo è incentrato sui passaggi di migrazione. Per altre informazioni su Sincronizzazione file di Azure, è consigliabile consultare gli articoli seguenti:
- Sincronizzazione file di Azure - Panoramica
- Sincronizzazione file di Azure - Guida alla distribuzione
Obiettivi della migrazione
L'obiettivo è garantire l'integrità dei dati di produzione e garantire la disponibilità. Quest'ultimo aspetto richiede un tempo di inattività minimo, in modo da poter rientrare o superare leggermente le normali finestre di manutenzione.
Percorso di migrazione di StorSimple 1200 a Sincronizzazione file di Azure
Per eseguire un agente sincronizzazione file di Azure, è necessario un server Windows locale. Windows Server può essere come minimo un server 2012R2, ma idealmente deve essere un Windows Server 2019.
I percorsi di migrazione alternativi sono numerosi e sarebbe necessario un articolo troppo lungo per documentarli tutti e illustrare il motivo per cui presentano rischi o svantaggi rispetto alla route consigliata in questo articolo.
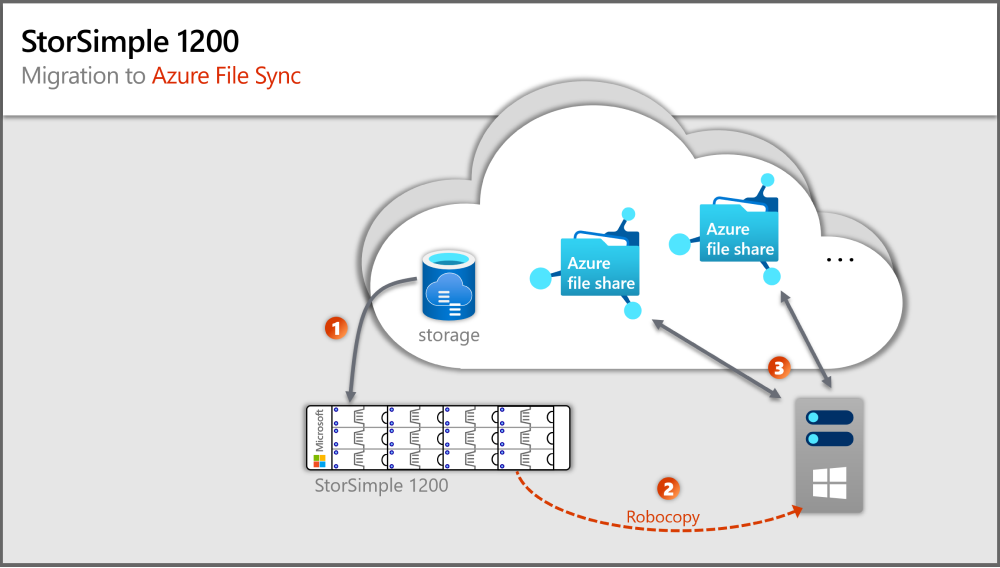
L'immagine precedente illustra i passaggi che corrispondono alle sezioni di questo articolo.
Passaggio 1: Provisioning di Windows Server e archiviazione locali
- Creare un server Windows Server 2019, almeno 2012R2, come macchina virtuale o server fisico. È supportato anche un cluster di failover di Windows Server.
- Effettuare il provisioning o aggiungere l'archiviazione con collegamento diretto (DAS rispetto a NAS, che non è supportata). Le dimensioni dell'archiviazione di Windows Server devono essere uguali o superiori alle dimensioni della capacità disponibile dell'appliance StorSimple 1200 virtuale.
Passaggio 2: Configurare l'archiviazione di Windows Server
In questo passaggio si esegue il mapping della struttura di archiviazione StorSimple (volumi e condivisioni) alla struttura di archiviazione di Windows Server. Se si prevede di apportare modifiche alla struttura di archiviazione, ovvero il numero di volumi, l'associazione di cartelle di dati ai volumi o la struttura delle sottocartelle al di sopra o al di sotto delle condivisioni SMB/NFS correnti, è il momento di prendere in considerazione queste modifiche. La modifica della struttura di file e cartelle dopo la configurazione di Sincronizzazione file di Azure è complessa e deve essere evitata. Questo articolo presuppone che si stia eseguendo il mapping 1:1, pertanto è necessario prendere in considerazione le modifiche di mapping quando si seguono i passaggi descritti in questo articolo.
- Nessuno dei dati di produzione dovrebbe terminare nel volume di sistema di Windows Server. Il cloud a livelli non è supportato nei volumi di sistema. Questa funzionalità, tuttavia, è necessaria per la migrazione e per le operazioni continue come sostituzione di StorSimple.
- Effettuare il provisioning dello stesso numero di volumi in Windows Server nell'appliance virtuale StorSimple 1200.
- Configurare i ruoli, le funzionalità e le impostazioni di Windows Server necessari. È consigliabile acconsentire esplicitamente agli aggiornamenti di Windows Server per mantenere il sistema operativo sicuro e aggiornato. Analogamente, è consigliabile acconsentire esplicitamente a Microsoft Update per mantenere aggiornate le applicazioni Microsoft, incluso l'agente di Sincronizzazione file di Azure.
- Non configurare cartelle o condivisioni prima di leggere i passaggi seguenti.
Passaggio 3: Distribuire la prima risorsa cloud di Sincronizzazione file di Azure
Per completare questo passaggio, sono necessarie le credenziali della sottoscrizione di Azure.
La risorsa principale da configurare per Sincronizzazione file di Azure è denominata Servizio di sincronizzazione archiviazione. È consigliabile una sola distribuzione per tutti i server che sincronizzano lo stesso set di file ora o in futuro. Creare più servizi di sincronizzazione archiviazione solo se esistono set distinti di server che non devono mai scambiare dati. Ad esempio, potrebbero esistere server che non devono mai sincronizzare la stessa condivisione file di Azure. In caso contrario, l'uso di un singolo Servizio di sincronizzazione archiviazione è la procedura consigliata.
Scegliere un'area di Azure per il Servizio di sincronizzazione archiviazione vicino alla propria località. Tutte le altre risorse cloud devono essere distribuite nella stessa area. Per semplificare la gestione, creare un nuovo gruppo di risorse nella sottoscrizione che ospita risorse di sincronizzazione e archiviazione.
Per altre informazioni, vedere la sezione sulla distribuzione del Servizio di sincronizzazione archiviazione nell'articolo sulla distribuzione di Sincronizzazione file di Azure. Seguire solo questa sezione dell'articolo. Nei passaggi successivi saranno disponibili collegamenti ad altre sezioni dell'articolo.
Passaggio 4: Associare il volume locale e la struttura di cartelle alle risorse di Sincronizzazione file di Azure e condivisione file di Azure
In questo passaggio verrà determinato il numero di condivisioni file di Azure necessarie. Una singola istanza di Windows Server (o cluster) può sincronizzare fino a 30 condivisioni file di Azure.
Potrebbero essere presenti più cartelle nei volumi attualmente condivisi in locale come condivisioni SMB per gli utenti e le app. Il modo più semplice per eseguire l'immagine di questo scenario consiste nell'immaginare una condivisione locale che esegue il mapping 1:1 a una condivisione file di Azure. Se si dispone di un numero sufficientemente piccolo di condivisioni, inferiore a 30 per una singola istanza di Windows Server, è consigliabile eseguire un mapping 1:1.
Se sono presenti più di 30 condivisioni, il mapping di una condivisione locale 1:1 a una condivisione file di Azure spesso non è necessario. Valutare le opzioni seguenti.
Raggruppamento di condivisioni
Ad esempio, se il reparto risorse umane (HR) ha 15 condivisioni, valutare l’archiviazione di tutti i dati delle risorse umane in una singola condivisione file di Azure. L'archiviazione di più condivisioni locali in un’unica condivisione file di Azure non impedisce di creare le 15 condivisioni SMB normali nell'istanza locale di Windows Server. Significa solo che si organizzano le cartelle radice di queste 15 condivisioni come sottocartelle in una cartella comune. Si sincronizza, quindi, questa cartella comune con una condivisione file di Azure. In questo modo, è necessaria solo una singola condivisione file di Azure nel cloud per questo gruppo di condivisioni locali.
Sincronizzazione di volumi
Sincronizzazione file di Azure supporta la sincronizzazione della radice di un volume con una condivisione file di Azure. Se si sincronizza la radice del volume, tutte le sottocartelle e i file passeranno nella stessa condivisione file di Azure.
La sincronizzazione della radice del volume non è sempre l'opzione migliore. La sincronizzazione di più posizioni offre alcuni vantaggi. In questo modo, ad esempio, è possibile mantenere inferiore il numero di elementi per ambito di sincronizzazione. Vengono testate le condivisioni file di Azure e Sincronizzazione file di Azure con 100 milioni di elementi (file e cartelle) per condivisione. Ma una procedura consigliata consiste nel cercare di mantenere il numero inferiore a 20 milioni o 30 milioni in una singola quota. La configurazione di Sincronizzazione file di Azure con un numero inferiore di elementi non è utile solo per la sincronizzazione file. Un numero inferiore di elementi offre benefici anche in scenari come i seguenti:
- L'analisi iniziale del contenuto cloud può essere completata più rapidamente, riducendo a sua volta l'attesa della visualizzazione dello spazio dei nomi in un server abilitato per Sincronizzazione file di Azure.
- Il ripristino lato cloud da uno snapshot di condivisione file di Azure sarà più veloce.
- Il ripristino di emergenza di un server locale può accelerare notevolmente.
- Le modifiche apportate direttamente in una condivisione file di Azure (al di fuori della sincronizzazione) possono essere rilevate e sincronizzate più velocemente.
Suggerimento
Se non si conosce il numero di file e cartelle esistenti, consultare lo strumento TreeSize di JAM Software GmbH.
Approccio strutturato a una mappa di distribuzione
Prima di distribuire l'archiviazione nel cloud in un passaggio successivo, è importante creare una mappa tra le cartelle locali e le condivisioni file di Azure. Questo mapping consentirà di appurare quante e quali risorse del gruppo di sincronizzazione di Sincronizzazione file di Azure verranno sottoposte a provisioning. Un gruppo di sincronizzazione collega la condivisione file di Azure e la cartella nel server e stabilisce una connessione di sincronizzazione.
Per decidere il numero di condivisioni file di Azure necessarie, esaminare i limiti e le procedure consigliate seguenti. In questo modo, sarà possibile ottimizzare la mappa.
Un server in cui è installato l'agente di Sincronizzazione file di Azure può eseguire la sincronizzazione con un massimo di 30 condivisioni file di Azure.
Una condivisione file di Azure viene distribuita in un account di archiviazione. Questa disposizione rende l'account di archiviazione una destinazione di scalabilità per i numeri correlati alle prestazioni come operazioni di I/O al secondo e velocità effettiva.
Quando si distribuiscono condivisioni file di Azure, prestare attenzione alle limitazioni di un account di archiviazione in termini di operazioni di I/O al secondo. L’ideale sarebbe eseguire il mapping 1:1 delle condivisioni file con gli account di archiviazione. Tuttavia, ciò non sempre è possibile, a causa dei diversi limiti e restrizioni imposti dalla propria organizzazione e da Azure. Quando non è possibile distribuire una sola condivisione file per account di archiviazione, valutare quali condivisioni saranno particolarmente attive e quali lo saranno meno, in modo da non inserire le condivisioni file più utilizzate nello stesso account di archiviazione.
Se si prevede di trasferire un'app in Azure che userà la condivisione file di Azure in modo nativo, potrebbe essere necessario ottenere prestazioni più elevate dalla condivisione file di Azure. Se questo tipo di uso è una possibilità, anche in futuro, è consigliabile creare una singola condivisione file standard di Azure nel proprio account di archiviazione.
Esiste un limite di 250 account di archiviazione per sottoscrizione e area di Azure.
Suggerimento
Alla luce di queste informazioni, spesso diventa necessario raggruppare più cartelle di primo livello nei volumi in una nuova directory radice comune. Si sincronizza, quindi, questa nuova directory radice e tutte le cartelle in essa raggruppate in una singola condivisione file di Azure. Questa tecnica consente di rimanere entro il limite di 30 sincronizzazioni di condivisioni file di Azure per server.
Questo raggruppamento in una radice comune non influisce sull'accesso ai dati. Gli ACL non vengono modificati. È sufficiente modificare i percorsi di condivisione (come condivisioni SMB o NFS) nelle cartelle del server locale che ora sono state modificate in una radice comune. Non occorrono altre modifiche.
Importante
Il vettore di scala più importante per Sincronizzazione file di Azure è il numero di elementi (file e cartelle) che devono essere sincronizzati. Per informazioni più dettagliate, esaminare Obiettivi di scalabilità di Sincronizzazione file di Azure.
È consigliabile mantenere basso il numero di elementi per ambito di sincronizzazione. Questo è un fattore importante da considerare nel mapping delle cartelle alle condivisioni file di Azure. Sincronizzazione file di Azure è testato con 100 milioni di elementi (file e cartelle) per condivisione. Molte volte, tuttavia, è preferibile cercare di mantenere il numero di elementi al di sotto di 20 milioni o 30 milioni in una singola quota. Suddividere lo spazio dei nomi in più condivisioni se si inizia a superare questi numeri. È possibile continuare a raggruppare più condivisioni locali nella stessa condivisione file di Azure se si rimane approssimativamente al di sotto di questi numeri. Questa pratica fornirà spazio per la crescita.
È possibile che, nella propria situazione, un set di cartelle possa essere sincronizzato logicamente con la stessa condivisione file di Azure (usando il nuovo approccio comune alle cartelle radice menzionato in precedenza). Potrebbe essere preferibile, tuttavia, raggruppare le cartelle in modo che vengano sincronizzate con due condivisioni file di Azure anziché una sola. È possibile usare questo approccio per mantenere bilanciato il numero di file e cartelle per condivisione file nel server. È anche possibile suddividere le condivisioni locali e la sincronizzazione tra più server locali, aggiungendo la possibilità di eseguire la sincronizzazione con altre 30 condivisioni file di Azure per ogni server aggiuntivo.
Scenari e considerazioni comuni di sincronizzazione dei file
| # | Scenario di sincronizzazione | Supportata | Considerazioni (o limitazioni) | Soluzione (soluzione alternativa) |
|---|---|---|---|---|
| 1 | File server con più dischi/volumi e più condivisioni nella stessa condivisione file di Azure di destinazione (consolidamento) | No | Una condivisione file di Azure di destinazione (endpoint cloud) supporta la sincronizzazione con un solo gruppo di sincronizzazione. Un gruppo di sincronizzazione supporta un solo endpoint server per ogni server registrato. |
1) Iniziare con la sincronizzazione di un solo disco (relativo volume radice) alla condivisione file di Azure di destinazione. Cominciare dal disco/volume più grande sarà utile per i requisiti di archiviazione locale. Configurare il cloud a livelli per suddividere in livelli tutti i dati nel cloud, liberando spazio sul disco del file server. Spostare i dati da altri volumi/condivisioni nel volume corrente che esegue la sincronizzazione. Continuare i passaggi uno per uno fino a quando tutti i dati vengono suddivisi in livelli nel cloud o nella migrazione. 2) Specificare come destinazione un solo volume radice (disco) alla volta. Usare il cloud a livelli per suddividere in livelli tutti i dati per la condivisione file di Azure di destinazione. Rimuovere l'endpoint server dal gruppo di sincronizzazione, ricreare l'endpoint con il volume/disco radice successivo, sincronizzare e ripetere il processo. Nota: potrebbe essere necessario reinstallare l'agente. 3) Consigliare l'uso di più condivisioni file di Azure di destinazione (account di archiviazione identico o diverso in base ai requisiti di prestazioni) |
| 2 | File server con singolo volume e più condivisioni nella stessa condivisione file di Azure di destinazione (consolidamento) | Sì | Non è possibile avere più endpoint server per ogni server registrato che esegue la sincronizzazione con la stessa condivisione file di Azure di destinazione (uguale a quella precedente) | Sincronizzare la radice del volume che contiene più condivisioni o cartelle di primo livello. Per altre informazioni, fare riferimento a Concetto di raggruppamento delle condivisioni e Sincronizzazione di volumi. |
| 3 | File server con più condivisioni e/o volumi in più condivisioni file di Azure con un singolo account di archiviazione (mapping 1:1 della condivisione) | Sì | Una singola istanza di Windows Server (o cluster) può sincronizzare fino a 30 condivisioni file di Azure. Un account di archiviazione è una destinazione di scalabilità per le prestazioni. Le operazioni di I/O al secondo e la velocità effettiva vengono condivise tra le condivisioni file. Mantenere il numero di elementi per gruppo di sincronizzazione entro 100 milioni di elementi (file e cartelle) per condivisione. L’ideale sarebbe rimanere al di sotto di 20 o 30 milioni di elementi per condivisione. |
1) Usare più gruppi di sincronizzazione (numero di gruppi di sincronizzazione = numero di condivisioni file di Azure da sincronizzare). 2) In questo scenario è possibile sincronizzare solo 30 condivisioni alla volta. Se esistono più di 30 condivisioni in tale file server, usare il Concetto di raggruppamento delle condivisioni e Sincronizzazione di volumi per ridurre il numero di cartelle radice o di primo livello nell'origine. 3) Usare server di Sincronizzazione file aggiuntivi in locale e dividere/spostare i dati in questi server per aggirare le limitazioni nel server Windows di origine. |
| 4 | File server con più condivisioni e/o volumi in più condivisioni file di Azure con un account di archiviazione differente (mapping 1:1 della condivisione) | Sì | Una singola istanza di Windows Server (o cluster) può sincronizzare fino a 30 condivisioni file di Azure (account di archiviazione identico o differente). Mantenere il numero di elementi per gruppo di sincronizzazione entro 100 milioni di elementi (file e cartelle) per condivisione. L’ideale sarebbe rimanere al di sotto di 20 o 30 milioni di elementi per condivisione. |
Stesso approccio illustrato in precedenza |
| 5 | Più file server con singolo (condivisione o volume radice) nella stessa condivisione file di Azure di destinazione (consolidamento) | No | Un gruppo di sincronizzazione non può usare l'endpoint cloud (condivisione file di Azure) già configurato in un altro gruppo di sincronizzazione. Anche se un gruppo di sincronizzazione può avere endpoint server in file server diversi, i file non possono essere distinti. |
Seguire le indicazioni riportate nello scenario 1 precedente con considerazioni aggiuntive sulla destinazione di un solo file server alla volta. |
Creare una tabella di mapping

Usare le informazioni precedenti per determinare il numero di condivisioni file di Azure necessarie e quali parti dei dati esistenti finiranno nelle varie condivisioni file di Azure.
Creare una tabella che registra le considerazioni effettuate in modo da potervi fare riferimento quando è necessario. Rimanere organizzati è importante perché può essere facile perdere i dettagli del piano di mapping quando si esegue il provisioning di molte risorse di Azure contemporaneamente. Scaricare il file di Excel seguente da usare come modello per facilitare la creazione del mapping.

|
Scaricare un modello di mapping dello spazio dei nomi. |
Passaggio 5: Effettuare il provisioning di condivisioni file di Azure
Una condivisione file di Azure è archiviata nel cloud in un account di archiviazione di Azure. Un altro livello di considerazioni sulle prestazioni si applica qui.
Se esistono condivisioni molto attive (condivisioni usate da molti utenti e/o applicazioni), due condivisioni file di Azure potrebbero raggiungere il limite di prestazioni di un account di archiviazione.
È preferibile distribuire gli account di archiviazione con una sola condivisione file ciascuno. È possibile raggruppare più condivisioni file di Azure nello stesso account di archiviazione se si dispone di condivisioni di archiviazione o si prevede un'attività giornaliera bassa.
Queste considerazioni si applicano maggiormente all'accesso al cloud diretto (tramite una macchina virtuale di Azure) rispetto a Sincronizzazione file di Azure. Se si prevede di usare solo Sincronizzazione file di Azure in queste condivisioni, il raggruppamento di più condivisioni in un singolo account di archiviazione di Azure è accettabile.
Se è stato creato un elenco delle condivisioni, è necessario eseguire il mapping di ogni condivisione all'account di archiviazione in cui si troverà.
Nella fase precedente è stato determinato il numero appropriato di condivisioni. In questo passaggio si ha un mapping degli account di archiviazione alle condivisioni file. A questo punto, distribuire il numero appropriato di account di archiviazione di Azure con il numero appropriato di condivisioni file di Azure.
Accertarsi che l'area di ogni account di archiviazione sia la stessa e corrisponda all'area della risorsa del servizio di sincronizzazione archiviazione già distribuita.
Attenzione
Se si crea una condivisione file di Azure con un limite di 100 TiB, tale condivisione può usare solo le opzioni di ridondanza di archiviazione con ridondanza locale o ZRS. Considerare le esigenze di ridondanza dell'archiviazione prima di usare 100 condivisioni file TiB.
Le condivisioni file di Azure vengono comunque create con un limite di 5 TiB per impostazione predefinita. Seguire la procedura descritta in Creare una condivisione file di Azure per creare una condivisione file di grandi dimensioni.
Un'altra considerazione quando si distribuisce un account di archiviazione riguarda la ridondanza di Archiviazione di Azure. Vedere Opzioni di ridondanza di Archiviazione di Azure.
Anche i nomi delle risorse sono importanti. Ad esempio, se si raggruppano più condivisioni per il reparto risorse umane in un account di archiviazione di Azure, è necessario assegnare un nome appropriato all'account di archiviazione. Analogamente, quando si assegna un nome alle condivisioni file di Azure, è consigliabile usare nomi simili a quelli usati per le controparti locali.
Impostazioni account di archiviazione
Esistono molte configurazioni che è possibile eseguire in un account di archiviazione. L'elenco di controllo seguente deve essere usato per le configurazioni dell'account di archiviazione. Ad esempio, è possibile modificare la configurazione di rete al termine della migrazione.
- Firewall e reti virtuali: Disabilitato: non configurare restrizioni IP o limitare l'accesso dell'account di archiviazione a una rete virtuale specifica. L'endpoint pubblico dell'account di archiviazione viene usato durante la migrazione. Tutti gli indirizzi IP dalle macchine virtuali di Azure devono essere consentiti. È consigliabile configurare le regole del firewall nell'account di archiviazione dopo la migrazione.
- Endpoint privati: Supportato: è possibile abilitare gli endpoint privati, ma l'endpoint pubblico viene usato per la migrazione e deve rimanere disponibile.
Passaggio 6: Configurare le cartelle di destinazione di Windows Server
Nei passaggi precedenti sono stati considerati tutti gli aspetti che determineranno i componenti delle topologie di sincronizzazione. È ora possibile preparare il server per ricevere i file per il caricamento.
Creare tutte le cartelle che verranno sincronizzate ognuna con la propria condivisione file di Azure. È importante seguire la struttura di cartelle documentata in precedenza. Se ad esempio si è deciso di sincronizzare più condivisioni SMB locali in una singola condivisione file di Azure, è necessario inserirle in una cartella radice comune nel volume. Creare ora questa cartella radice di destinazione nel volume.
Il numero di condivisioni file di Azure di cui si effettua il provisioning deve corrispondere al numero di cartelle create in questo passaggio e al numero di volumi da sincronizzare a livello radice.
Passaggio 7: Distribuire l'agente di Sincronizzazione file di Azure
In questa sezione viene installato l'agente di Sincronizzazione file di Azure nell'istanza di Windows Server.
La guida alla distribuzione spiega che è necessario disattivare Configurazione sicurezza avanzata di Internet Explorer. Questa misura di sicurezza non è applicabile con Sincronizzazione file di Azure. La disattivazione consente di eseguire l'autenticazione in Azure senza problemi.
Aprire PowerShell. Installare i moduli PowerShell necessari usando i comandi seguenti. Accertarsi di installare il modulo completo e il provider NuGet quando viene chiesto.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
Se si verificano problemi durante il raggiungimento di Internet dal server, è il momento di risolverli. Sincronizzazione file di Azure usa qualunque connessione di rete disponibile a Internet. È supportata anche la richiesta di un server proxy per raggiungere Internet. È possibile configurare ora un proxy a livello di computer o, durante l'installazione dell'agente, specificare un proxy che verrà usato solo da Sincronizzazione file di Azure.
Se la configurazione un proxy implica la necessità di aprire i firewall per il server, questo approccio potrebbe essere accettabile per l'utente. Al termine dell'installazione del server, dopo aver completato la registrazione del server, un report di connettività di rete mostrerà gli URL degli endpoint esatti in Azure con cui Sincronizzazione file di Azure deve comunicare per l'area selezionata. Il report indica anche perché è necessaria la comunicazione. È possibile usare il report per bloccare i firewall intorno al server a URL specifici.
È anche possibile adottare un approccio più conservativo in cui non si aprono i firewall. È possibile, invece, limitare il server a comunicare con spazi dei nomi DNS di livello superiore. Per altre informazioni, vedere Impostazioni di proxy e firewall di Sincronizzazione file di Azure. Seguire le procedure di rete consigliate.
Al termine dell'installazione guidata del server, verrà aperta una procedura guidata di registrazione del server. Registrare il server nella risorsa di Azure del servizio di sincronizzazione archiviazione precedente.
Questi passaggi sono descritti in modo più dettagliato nella guida alla distribuzione, che include i moduli di PowerShell da installare per primi: Installazione dell'agente di Sincronizzazione file di Azure.
Usare l'agente più recente. È possibile scaricarlo dall'Area download MicrosoftAgente di Sincronizzazione file di Azure.
Dopo aver completato correttamente l'installazione e la registrazione del server, è possibile controllare se questo passaggio è stato completato correttamente. Passare alla risorsa del Servizio di sincronizzazione archiviazione nel portale di Azure. Nel menu a sinistra, passare a Server registrati. Verrà visualizzato l'elenco del server.
Passaggio 8: Configurare la sincronizzazione
Questo passaggio collega tutte le risorse e le cartelle configurate nell'istanza di Windows Server durante i passaggi precedenti.
- Accedere al portale di Azure.
- Individuare la risorsa del Servizio di sincronizzazione archiviazione.
- Creare un nuovo gruppo di sincronizzazione all'interno della risorsa del Servizio di sincronizzazione archiviazione per ogni condivisione file di Azure. Nella terminologia di Sincronizzazione file di Azure, la condivisione file di Azure diventerà un endpoint cloud nella topologia di sincronizzazione che si sta descrivendo con la creazione di un gruppo di sincronizzazione. Quando si crea il gruppo di sincronizzazione, assegnargli un nome familiare in modo da riconoscere il set di file sincronizzato. Accertarsi di fare riferimento alla condivisione file di Azure con un nome corrispondente.
- Dopo aver creato il gruppo di sincronizzazione, verrà visualizzata una riga nell'elenco dei gruppi di sincronizzazione. Selezionare il nome (un collegamento) per visualizzare il contenuto del gruppo di sincronizzazione. La condivisione file di Azure verrà visualizzata in Endpoint cloud.
- Individuare il pulsante Aggiungi endpoint server. La cartella nel server locale di cui è stato effettuato il provisioning diventerà il percorso per questo endpoint server.
Avviso
Assicurarsi di attivare la suddivisione in livelli nel cloud. Questa operazione è necessaria se il server locale non ha spazio sufficiente per archiviare le dimensioni totali dei dati nell'archiviazione cloud StorSimple. Impostare temporaneamente i criteri di suddivisione in livelli sullo spazio disponibile del volume al 99% e tornare a un livello più ragionevole dopo il completamento della migrazione.
Ripetere i passaggi di creazione del gruppo di sincronizzazione e di aggiunta della cartella server corrispondente come endpoint server per tutte le condivisioni file di Azure e i percorsi del server che devono essere configurati per la sincronizzazione.
Passaggio 9: Copiare i file
L'approccio di migrazione di base prevede una copia con RoboCopy dall'appliance virtuale StorSimple a Windows Server e da Sincronizzazione file di Azure a condivisioni file di Azure.
Eseguire la prima copia locale nella cartella di destinazione del server Windows:
- Identificare la prima posizione nell'appliance StorSimple virtuale.
- Identificare la cartella corrispondente in Windows Server in cui Sincronizzazione file di Azure è già configurata.
- Avviare la copia con RoboCopy
Il comando RoboCopy seguente richiamerà i file dall'archiviazione di Azure StorSimple all'istanza locale di StorSimple e quindi li sposterà nella cartella di destinazione di Windows Server. Windows Server li sincronizzerà con le condivisioni file di Azure. Quando il volume locale di Windows Server è pieno, si avvierà il cloud a livelli per i file già sincronizzati. Il cloud a livelli genererà spazio sufficiente per continuare la copia dall'appliance virtuale StorSimple. Il cloud a livelli effettua una verifica una volta all'ora per controllare cosa sia stato sincronizzato e liberare spazio su disco così da raggiungere il 99% di spazio disponibile.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Commutatore | Significato |
|---|---|
/MT:n |
Consente l'esecuzione di Robocopy in multithreading. L’impostazione predefinita per n è 8. Il massimo è di 128 thread. Anche se un numero elevato di thread facilita la saturazione della larghezza di banda disponibile, non è detto che la migrazione sarà sempre più veloce con più thread. I test con File di Azure tra 8 e 20 dimostrano prestazioni bilanciate per l'esecuzione di una copia iniziale. Le esecuzioni successive di /MIR sono progressivamente influenzate dal rapporto tra calcolo disponibile e la larghezza di banda di rete disponibile. Per le esecuzioni successive, il valore del conteggio dei thread dovrà avvicinarsi al numero di core del processore e al conteggio dei thread per core. Valutare se i core devono essere riservati ad altre eventuali attività di un server di produzione. I test con File di Azure hanno dimostrato che fino a 64 thread producono prestazioni ottimali, ma solo se i processori possono mantenerli attivi contemporaneamente. |
/R:n |
Numero massimo di nuovi tentativi per un file che non viene copiato al primo tentativo. Robocopy proverà n volte prima che il file non riesca a copiare definitivamente nell'esecuzione. È possibile ottimizzare le prestazioni dell'esecuzione: scegliere un valore pari a due o tre se si ritiene che i problemi di timeout abbiano causato errori in passato. Ciò può essere più comune rispetto ai collegamenti WAN. Scegliere nessun nuovo tentativo o un valore di uno se si ritiene che la copia del file non sia riuscita perché era attivamente in uso. Un nuovo tentativo dopo alcuni secondi potrebbe non essere sufficiente per lo stato in uso del file da modificare. Gli utenti o le app che contengono il file aperto potrebbero richiedere più ore. In questo caso, accettando che il file non è stato copiato e recuperandolo in una delle successive esecuzioni di Robocopy pianificate, la copia del file potrebbe avvenire correttamente. Ciò consente all'esecuzione corrente di terminare più velocemente senza ritardi dovuti a molti tentativi che alla fine finiscono nella maggior parte in errori di copia a causa di file ancora aperti oltre il timeout di ripetizione dei tentativi. |
/W:n |
Specifica il tempo in cui Robocopy rimane in attesa prima di provare a ripetere un'operazione di copia di un file che ha avuto esito negativo in un tentativo precedente. n è il numero di secondi di attesa tra i tentativi. /W:n viene spesso usato insieme a /R:n. |
/B |
Esegue Robocopy nella stessa modalità che verrebbe usata da un'applicazione di backup. Questa opzione consente a Robocopy di spostare i file per cui l'utente corrente non dispone delle autorizzazioni. L'opzione di backup dipende dall'esecuzione del comando di Robocopy in una console con privilegi elevati di amministratore o in una finestra di PowerShell. Se si usa Robocopy per File di Azure, accertarsi di montare le condivisioni file di Azure usando la chiave di accesso dell'account di archiviazione e non usare un'identità di dominio. In caso contrario, i messaggi di errore potrebbero impedire una risoluzione del problema in modo intuitivo. |
/MIR |
(Mirror da origine a destinazione.) Consente a Robocopy di copiare solo i delta tra origine e destinazione. Le sottodirectory vuote verranno copiate. Gli elementi (file o cartelle) modificati o non presenti nella destinazione verranno copiati. Gli elementi presenti nella destinazione ma non nell'origine verranno rimossi (eliminati) dalla destinazione. Quando si usa questa opzione, le strutture delle cartelle di origine e di destinazione devono essere identiche. Corrispondenza significa copiare dal livello corretto di origine e cartella al livello di cartella corrispondente nella destinazione. Solo a questo punto una copia "di recupero" può avere esito positivo. Quando l'origine e la destinazione non corrispondono, l'uso di /MIR causerà eliminazioni e creazione di nuove copie su larga scala. |
/IT |
Verifica che venga mantenuta la fedeltà in determinati scenari di mirror. Ad esempio, se si verifica un cambiamento di ACL e un aggiornamento degli attributi in un file tra due esecuzioni di Robocopy, il file viene contrassegnato come nascosto. Senza /IT, Robocopy potrebbe non rilevare il cambiamento di ACL e la modifica potrebbe non essere trasferita alla posizione di destinazione. |
/COPY:[copyflags] |
La fedeltà della copia del file. Impostazione predefinita: /COPY:DAT. Flag di copia: D= Dati, A= Attributi, T= Timestamp, S= Sicurezza = NTFS ACL, O= Informazioni sul proprietario, U= Informazioni di controllo. Le informazioni di controllo non possono essere archiviate in una condivisione file di Azure. |
/DCOPY:[copyflags] |
Fedeltà per la copia delle directory. Impostazione predefinita: /DCOPY:DA. Flag di copia: D= Dati, A= Attributi, T= Timestamp. |
/NP |
Specifica che non verrà visualizzato l'avanzamento della copia per ogni file e cartella. La visualizzazione dell'avanzamento riduce notevolmente le prestazioni di copia. |
/NFL |
Specifica che i nomi dei file non vengono registrati. Aumenta le prestazioni di copia. |
/NDL |
Specifica che i nomi delle directory non vengono registrati. Aumenta le prestazioni di copia. |
/XD |
Specifica le directory da escludere. Quando si esegue Robocopy nella radice di un volume, considerare l'esclusione della cartella System Volume Information nascosta. Se usato come progettato, tutte le informazioni contenute sono specifiche del volume esatto su questo sistema esatto e possono essere rigenerare su richiesta. La copia di queste informazioni non sarà utile nel cloud o quando i dati vengono copiati in un altro volume di Windows. Lasciare questo contenuto dietro non deve essere considerato come perdita di dati. |
/UNILOG:<file name> |
Scrive lo stato nel file di log come Unicode. (Sovrascrive il log esistente.) |
/L |
Solo per un'esecuzione di test I file devono essere solo elencati. Non verranno copiati o eliminati e non verranno applicati timestamp. Spesso usato con /TEE per l'output della console. Potrebbe essere necessario rimuovere i flag dello script di esempio, come /NP, /NFL e /NDL, per ottenere risultati di test correttamente documentati. |
/LFSM |
Solo per le destinazioni con archiviazione a livelli. Non supportato quando la destinazione è una condivisione SMB remota. Specifica che Robocopy opera in "modalità spazio disponibile insufficiente". Questa operazione è utile solo per le destinazioni con archiviazione a livelli che potrebbero esaurire la capacità locale prima del completamento di Robocopy. È stata aggiunta appositamente per l'uso con una destinazione abilitata per cloud a livelli di Sincronizzazione file di Azure. Può essere usata indipendentemente da Sincronizzazione file di Azure. In questa modalità Robocopy viene sospeso ogni volta che lo spazio libero del volume di destinazione scende al di sotto di un valore minimo a causa di una copia del file. Questo valore può essere specificato dalla forma /LFSM:n del flag. Il parametro n è specificato in base 2: nKB, nMB o nGB. Se /LFSM viene specificato senza un valore di limite minimo esplicito, il limite minimo viene impostato sul 10% delle dimensioni del volume di destinazione. La modalità spazio libero insufficiente non è compatibile con /MT, /EFSRAW o /ZB. Il supporto per /B è stato aggiunto in Windows Server 2022. Vedere la sezione Windows Server 2022 e RoboCopy LFSM di seguito per altre informazioni, incluse informazioni dettagliate su un bug e una soluzione alternativa correlati. |
/Z |
Usare con cautela Copia i file in modalità di riavvio. Questa operazione è consigliata solo in un ambiente di rete instabile. Riduce significativamente le prestazioni di copia a causa della registrazione aggiuntiva. |
/ZB |
Usare con cautela Usa la modalità di riavvio. Se viene negato l'accesso, questa opzione usa la modalità di backup. Questa opzione riduce significativamente le prestazioni di copia a causa del checkpoint. |
Importante
È consigliabile l'uso di Windows Server 2022. Quando si usa Windows Server 2019, accertarsi che sia installato il livello di patch più recente o almeno l’aggiornamento del sistema operativo KB5005103. Contiene correzioni importanti per determinati scenari di Robocopy.
Quando si esegue il comando RoboCopy per la prima volta, gli utenti e le applicazioni accedono ancora ai file e alle cartelle StorSimple e possono apportare modifiche. È possibile che RoboCopy abbia elaborato una directory e sia passato alla successiva, quindi un utente nel percorso di origine (StorSimple) aggiunge, modifica o elimina un file che ora non verrà elaborato in questa esecuzione corrente di RoboCopy. Va bene.
La prima esecuzione consiste nello spostare la maggior parte dei dati in locale, in Windows Server e di eseguire il backup nel cloud tramite Sincronizzazione file di Azure. Questa operazione può richiedere molto tempo, a seconda di quanto segue:
- la larghezza di banda per il download
- la velocità di richiamo del servizio cloud StorSimple
- la larghezza di banda in upload
- il numero di elementi (file e cartelle) che devono essere elaborati da entrambi i servizi
Al termine dell'esecuzione iniziale, eseguire di nuovo il comando.
La seconda volta finirà più velocemente, perché dovrà trasportare solo le modifiche apportate dopo l'ultima esecuzione. Queste modifiche sono probabilmente locali già in StorSimple, perché sono recenti. Ciò riduce ulteriormente il tempo perché la necessità di richiamo dal cloud è ridotta. Tuttavia, nuove modifiche possono accumularsi durante questa seconda esecuzione.
Ripetere questo processo fino a quando non si è soddisfatti della quantità di tempo necessario per il completamento come periodo accettabile di tempo di inattività.
Quando si considerano i tempi di inattività accettabili e si è pronti a portare offline la posizione di StorSimple, eseguire questa operazione. Ad esempio, rimuovere la condivisione SMB in modo che nessun utente possa accedere alla cartella o eseguire qualsiasi altro passaggio appropriato che impedisca la modifica del contenuto in questa cartella in StorSimple.
Eseguire un ultimo round di RoboCopy. Questo raccoglierà eventuali modifiche che potrebbero essere state perse. Il tempo necessario per questo passaggio finale dipende dalla velocità dell'analisi RoboCopy. È possibile stimare il tempo (uguale al tempo di inattività) misurando la durata dell'esecuzione precedente.
Creare una condivisione nella cartella di Windows Server ed eventualmente modificare la distribuzione DFS-N in modo che punti a essa. Assicurarsi di impostare le stesse autorizzazioni a livello di condivisione della condivisione SMB StorSimple.
È stata completata la migrazione di una condivisione o di un gruppo di condivisioni in una radice o un volume comune, a seconda di ciò che è stato eseguito in precedenza.
È possibile provare a eseguire alcune di queste copie in parallelo. È consigliabile elaborare l'ambito di una condivisione file di Azure alla volta.
Avviso
Dopo aver spostato tutti i dati dal StorSimple a Windows Server e aver completato la migrazione: tornare a tutti i gruppi di sincronizzazione nel portale di Azure e modificare il valore della percentuale di spazio disponibile del volume del cloud a livelli in modo che sia più adatto per l'utilizzo della cache, ad esempio 20%.
I criteri per lo spazio libero nel volume a livelli cloud agisce su un livello di volume con potenzialmente più endpoint server sincronizzati da quest'ultimo. Se si dimentica di regolare lo spazio disponibile in un solo endpoint server, la sincronizzazione continuerà ad applicare la regola più restrittiva e tenterà di mantenere lo spazio libero su disco del 99% e la cache locale non verrà eseguita come previsto. A meno che l'obiettivo non sia quello di avere solo lo spazio dei nomi per un volume che contiene solo dati di archiviazione a cui si accede raramente, sarà necessario modificare i criteri di spazio libero in ogni endpoint server.
Risoluzione dei problemi
Il problema più probabile è che il comando RoboCopy abbia esito negativo con "Volume completo" sul lato Windows Server. In tal caso, la velocità di download è probabilmente migliore della velocità di caricamento. Il cloud a livelli agisce una volta ogni ora per evacuare il contenuto dal disco locale di Windows Server sincronizzato.
Consentire all'avanzamento della sincronizzazione e al cloud a livelli di liberare spazio su disco. È possibile osservarlo in Esplora file in Windows Server.
Quando Windows Server dispone di capacità disponibile sufficiente, la ripetizione del comando risolverà il problema. Non succede nulla quando si arriva a questa situazione, è possibile procedere senza problemi. L'unico inconveniente è dover ripetere il comando.
Potrebbero verificarsi anche altri problemi di Sincronizzazione file di Azure. In questo caso, vedere la Guida alla risoluzione dei problemi di Sincronizzazione file di Azure.
La velocità e la frequenza di successo di una determinata esecuzione RoboCopy dipenderanno da diversi fattori:
- Operazioni di I/O al secondo nell'archiviazione di origine e di destinazione;
- Larghezza di banda di rete disponibile tra origine e destinazione;
- Possibilità di elaborare rapidamente file e cartelle in uno spazio dei nomi;
- Numero di modifiche tra le esecuzioni di RoboCopy;
- Dimensioni e numero di file che è necessario copiare;
Considerazioni sulle operazioni di I/O al secondo e sulla larghezza di banda
In questa categoria è necessario prendere in considerazione le capacità dell'archiviazione di origine, l'archiviazione di destinazione e la rete che le connette. La velocità effettiva massima possibile è determinata dal più lento di questi tre componenti. Assicurarsi che l'infrastruttura di rete sia configurata per supportare velocità di trasferimento ottimali alle migliori capacità.
Attenzione
Mentre la copia il più veloce possibile è spesso più desiderabile, prendere in considerazione l'utilizzo della rete locale e dell'appliance NAS per altre attività, spesso critiche per l'azienda.
La copia più veloce possibile potrebbe non essere auspicabile quando esiste un rischio che la migrazione possa monopolizzare le risorse disponibili.
- Valutare quando è preferibile nell'ambiente eseguire le migrazioni: durante il giorno, negli orari di minore attività o durante i fine settimana.
- Prendere in considerazione anche QoS di rete in Windows Server per limitare la velocità di RoboCopy.
- Evitare operazioni non necessarie per gli strumenti di migrazione.
RoboCopy può inserire ritardi tra pacchetti specificando l'opzione /IPG:n in cui n viene misurata in millisecondi tra i pacchetti RoboCopy. L'uso di questo commutatore consente di evitare il monopolio delle risorse su dispositivi vincolati di I/O e collegamenti di rete affollati.
/IPG:n non può essere usato per una limitazione di rete precisa a un determinato Mbps. Usare invece QoS di rete di Windows Server. RoboCopy si basa interamente sul protocollo SMB per tutte le esigenze di rete. L'uso di SMB è il motivo per cui RoboCopy non può influenzare la velocità effettiva di rete stessa, ma può rallentarne l'uso.
Una linea di pensiero simile si applica alle operazioni di I/O al secondo osservate sul NAS. Le dimensioni del cluster nel volume NAS, le dimensioni dei pacchetti e una matrice di altri fattori influenzano le operazioni di I/O al secondo osservate. L'introduzione del ritardo tra pacchetti è spesso il modo più semplice per controllare il carico sul NAS. Testare più valori, ad esempio da circa 20 millisecondi (n=20) a multipli di tale numero. Dopo aver introdotto un ritardo, è possibile valutare se le altre app possono ora funzionare come previsto. Questa strategia di ottimizzazione consentirà di trovare la velocità ottimale di RoboCopy nell'ambiente in uso.
Velocità di elaborazione
RoboCopy attraverserà lo spazio dei nomi a cui punta e valuterà ogni file e cartella per la copia. Ogni file verrà valutato durante una copia iniziale e durante le copie di recupero. Ad esempio, esecuzioni ripetute di RoboCopy /MIR nelle stesse posizioni di archiviazione di origine e di destinazione. Queste esecuzioni ripetute sono utili per ridurre al minimo i tempi di inattività per utenti e app e migliorare la percentuale complessiva di successo dei file migrati.
Spesso si considera la larghezza di banda come fattore più limitante in una migrazione e ciò può essere vero. Tuttavia, la possibilità di enumerare uno spazio dei nomi può influenzare il tempo totale per copiare ancora di più per spazi dei nomi più grandi con file più piccoli. Si consideri che la copia di 1 TiB di file di piccole dimensioni richiederà molto più tempo rispetto alla copia di 1 TiB di meno file più grandi, presupponendo che tutte le altre variabili rimangano invariate. Pertanto, è possibile che si verifichi un trasferimento lento se si esegue la migrazione di un numero elevato di file di piccole dimensioni. Si tratta di un comportamento previsto.
La causa di questa differenza è la potenza di elaborazione necessaria per esaminare uno spazio dei nomi. RoboCopy supporta copie multithread tramite il parametro /MT:n in cui n indica il numero di thread da usare. Pertanto, quando si effettua il provisioning di un computer in particolare per RoboCopy, prendere in considerazione il numero di core del processore e la relazione con il numero di thread fornito. Nella maggior parte dei casi è di due thread per core. Il numero di core e thread di un computer è un punto dati importante per decidere quali valori multithread /MT:n è necessario specificare. Considerare anche il numero di processi RoboCopy che si prevede di eseguire in parallelo in un determinato computer.
Più thread copieranno l'esempio di 1 TiB di file di piccole dimensioni in modo notevolmente più veloce rispetto a un numero inferiore di thread. Allo stesso tempo, l'investimento di risorse aggiuntive sui nostri 1 TiB di file più grandi potrebbe non produrre benefici proporzionali. Un numero elevato di thread tenterà di copiare più file di grandi dimensioni in rete contemporaneamente. Questa attività di rete aggiuntiva aumenta la probabilità di essere vincolati dalla velocità effettiva o dalle operazioni di I/O al secondo di archiviazione.
Durante un primo RoboCopy in una destinazione vuota o in un'esecuzione differenziale con molti file modificati, è probabile che la velocità effettiva della rete sia vincolata. Iniziare con un conteggio elevato dei thread per un'esecuzione iniziale. Un numero elevato di thread, anche oltre i thread attualmente disponibili nel computer, consente di saturare la larghezza di banda di rete disponibile. Le esecuzioni /MIR successive influiscono progressivamente sull'elaborazione degli elementi. Meno modifiche in un'esecuzione differenziale significano meno trasporto di dati in rete. La velocità dipende ora dalla capacità di elaborare gli elementi dello spazio dei nomi piuttosto che spostarli tramite il collegamento di rete. Per le esecuzioni successive, associare il valore del numero di thread al numero di core del processore e al numero di thread per core. Valutare se i core devono essere riservati per altre attività che un server di produzione potrebbe avere.
Suggerimento
Regola generale: la prima esecuzione di RoboCopy, che sposterà molti dati di una rete a latenza più elevata, trae vantaggio dal provisioning eccessivo del numero di thread (/MT:n). Le esecuzioni successive copiano meno differenze e probabilmente si passa dalla velocità effettiva di rete vincolata ai vincoli di calcolo. In queste circostanze, è spesso preferibile associare il conteggio dei thread RoboCopy ai thread effettivamente disponibili nel computer. Il provisioning eccessivo in questo scenario può portare a un maggior numero di cambiamenti di contesto nel processore, probabilmente rallentando la copia.
Evitare operazioni non necessarie
Evitare modifiche su larga scala nello spazio dei nomi. Ad esempio, lo spostamento di file tra directory, la modifica delle proprietà su larga scala o la modifica delle autorizzazioni (ACL NTFS). In particolare le modifiche ACL possono avere un impatto elevato perché spesso hanno un effetto di modifica a catena sui file inferiori nella gerarchia di cartelle. Le conseguenze possono essere le seguenti:
- il tempo di esecuzione del processo RoboCopy potrebbe risultare esteso perché ogni file e cartella interessato da una modifica ACL deve essere aggiornato
- potrebbe essere necessario copiare nuovamente i dati spostati in precedenza. Ad esempio, sarà necessario copiare più dati quando le strutture delle cartelle cambiano dopo la copia dei file già copiati in precedenza. Un processo RoboCopy non può "riprodurre" una modifica dello spazio dei nomi. Il processo successivo deve eliminare i file precedentemente trasportati nella struttura di cartelle precedente e caricare nuovamente i file nella nuova struttura di cartelle.
Un altro aspetto importante consiste nell'usare lo strumento RoboCopy in modo efficace. Con lo script RoboCopy consigliato, si creerà e si salverà un file di log per gli errori. È possibile che si verifichino errori di copia. Si tratta di un evento normale. Questi errori spesso rendono necessario eseguire più round di uno strumento di copia come RoboCopy. Un'esecuzione iniziale, ad esempio da un NAS a DataBox o da un server a una condivisione file di Azure. Infine, una o più esecuzioni aggiuntive con l'opzione /MIR per intercettare e riprovare i file che non sono stati copiati.
È consigliabile prepararsi a eseguire più round di RoboCopy in base a un determinato ambito dello spazio dei nomi. Le esecuzioni successive verranno completate più velocemente perché hanno meno contenuti da copiare, ma sono vincolate sempre più dalla velocità di elaborazione dello spazio dei nomi. Quando si eseguono più round, è possibile velocizzare ogni round impedendo a RoboCopy di copiare inutilmente tutto in una determinata esecuzione. Questi commutatori RoboCopy possono fare una differenza significativa:
/R:nn = frequenza con cui si riprova a copiare un file non riuscito e/W:nn = numero di secondi di attesa tra i tentativi
/R:5 /W:5 è un'impostazione ragionevole che è possibile regolare in base alle proprie esigenze. In questo esempio, la copia di un file non riuscita verrà ritentata cinque volte, con un tempo di attesa di cinque secondi tra i tentativi. Se la copia del file non riesce ancora, il processo RoboCopy successivo riproverà. Spesso la copia di file che non riesce perché i file sono in uso o a causa di problemi di timeout potrebbe essere completata correttamente in questo modo.
Windows Server 2022 e RoboCopy LFSM
L'opzione RoboCopy /LFSM può essere usata per evitare che un processo RoboCopy non riesca con un errore di volume completo. RoboCopy viene sospeso ogni volta che una copia di file porta lo spazio disponibile del volume di destinazione al di sotto di un valore limite.
Usare RoboCopy con Windows Server 2022. Solo questa versione di RoboCopy contiene importanti correzioni di bug e funzionalità che rendono il commutatore compatibile con i flag aggiuntivi necessari nella maggior parte delle migrazioni. Ad esempio, compatibilità con il flag /B.
/B segue RoboCopy nella stessa modalità che verrebbe usata da un'applicazione di backup. Questa opzione consente a RoboCopy di spostare i file per cui l'utente corrente non dispone delle autorizzazioni.
In genere, RoboCopy può essere eseguito nell'origine, nella destinazione o in un terzo computer.
Importante
Se si intende usare /LFSM, RoboCopy deve essere eseguito nel server di Sincronizzazione file di Azure di destinazione di Windows Server 2022.
Si noti anche che con /LFSM è necessario usare anche un percorso locale per la destinazione, non un percorso UNC. Ad esempio, come percorso di destinazione, è consigliabile usare E:\Nomecartella anziché un percorso UNC come \\NomeServer\NomeCartella.
Attenzione
La versione attualmente disponibile di RoboCopy in Windows Server 2022 presenta un bug che causa il conteggio delle pause rispetto al conteggio degli errori per file. Applicare la soluzione alternativa seguente.
I flag /R:2 /W:1 consigliati aumentano la probabilità che la copia di un file non sia riuscito a causa di una pausa indotta da /LFSM. In questo esempio, se un file non è copiato dopo 3 pause perché /LFSM ha causato la sospensione, RoboCopy non completa la copia del file. La soluzione alternativa consiste nell'usare valori più elevati per /R:n e /W:n. Un buon esempio è /R:10 /W:1800 (10 tentativi di 30 minuti ciascuno). In questo modo, l'algoritmo di suddivisione in livelli di Sincronizzazione file di Azure deve avere il tempo necessario per creare spazio nel volume di destinazione.
Questo bug è stato risolto ma la correzione non è ancora disponibile pubblicamente. Controllare questo paragrafo per gli aggiornamenti sulla disponibilità della correzione e su come distribuirlo.
Nota
Sono ancora presenti domande o si sono verificati problemi?
Il supporto tecnico è a disposizione: 
Collegamenti pertinenti
Contenuto della migrazione:
Contenuto di Sincronizzazione file di Azure:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per