Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Analisi di flusso di Azure può restituire dati in formato JSON in Azure Cosmos DB. Consente l'archiviazione dei dati e le query a bassa latenza sui dati JSON non strutturati. Questo articolo illustra alcune procedure consigliate per l'implementazione di questa configurazione (Analisi di flusso in Cosmos DB). Se non si ha familiarità con Azure Cosmos DB, vedere la documentazione di Azure Cosmos DB per iniziare.
Nota
- Attualmente Analisi di flusso supporta la connessione ad Azure Cosmos DB solo tramite l'API SQL. Altre API di Azure Cosmos DB non sono ancora supportate. Se Analisi di flusso punta agli account Azure Cosmos DB creati con altre API, i dati potrebbero non essere archiviati correttamente.
- Consigliamo di impostare il tuo processo al livello di compatibilità 1.2 quando utilizzi Azure Cosmos DB come output.
Nozioni di base di Azure Cosmos DB come destinazione di output
L'output di Azure Cosmos DB in Analisi di flusso consente la scrittura dei risultati di elaborazione del flusso come output JSON nei contenitori di Azure Cosmos DB. Analisi di flusso non crea contenitori nel database. È invece necessario crearli in anticipo. È quindi possibile controllare i costi di fatturazione dei contenitori di Azure Cosmos DB. È anche possibile ottimizzare le prestazioni, la coerenza e la capacità dei contenitori direttamente usando l'API di Azure Cosmos DB. Le sezioni seguenti illustrano in dettaglio alcune opzioni del contenitore per Azure Cosmos DB.
Ottimizzare coerenza, disponibilità e latenza
In base ai requisiti dell'applicazione, Azure Cosmos DB consente di ottimizzare il database e i contenitori e di bilanciare coerenza, disponibilità, latenza e velocità effettiva.
A seconda dei livelli di coerenza di lettura richiesti dello scenario rispetto alla latenza di lettura e scrittura, è possibile scegliere un livello di coerenza per l'account del database. È possibile migliorare la velocità effettiva aumentando le unità richiesta (UR) nel contenitore. Per impostazione predefinita, Azure Cosmos DB consente anche l'indicizzazione sincrona per ogni operazione CRUD nel contenitore. Questa opzione è un'altra opzione utile per controllare le prestazioni di scrittura/lettura in Azure Cosmos DB. Per altre informazioni, rivedere l'articolo Modificare i livelli di coerenza del database e delle query.
Upsert di Analisi di flusso
L'integrazione di Analisi di flusso di Azure con Azure Cosmos DB consente di inserire o aggiornare i record nel contenitore in base a una determinata colonna ID documento. L'operazione viene definita anche upsert. Analisi di flusso usa un approccio upsert ottimistico. Gli aggiornamenti avvengono solo quando un inserimento fallisce a causa di un conflitto di ID documento.
Con il livello di compatibilità 1.0, Analisi di flusso esegue questo aggiornamento come operazione PATCH, in modo da consentire aggiornamenti parziali al documento. Analisi di flusso aggiunge nuove proprietà o sostituisce in modo incrementale una proprietà esistente. Le modifiche apportate ai valori delle proprietà di matrice nel documento JSON comportano, tuttavia, la sovrascrittura dell'intera matrice, cioè, la matrice non viene unita.
Con 1.2, il comportamento di upsert viene modificato per inserire o sostituire il documento. La sezione successiva sul livello di compatibilità 1.2 descrive ulteriormente questo comportamento.
Se il documento JSON in ingresso dispone di un campo ID esistente, il campo viene usato automaticamente come colonna di ID documento in Azure Cosmos DB. Le scritture successive vengono trattate di conseguenza, portando a una delle seguenti situazioni:
- Gli ID univoci generano operazioni di inserimento.
- ID duplicati e ID documento impostati su ID generano operazioni di upsert.
- ID duplicati e ID documento non impostati generano un errore dopo il primo documento.
Se si desidera salvare tutti i documenti, inclusi quelli che hanno un ID duplicato, rinominare il campo ID nella query (usando la parola chiave AS). Consentire ad Azure Cosmos DB di creare il campo ID o sostituire l'ID con il valore di un'altra colonna (usando la parola chiave AS o usando l'impostazioneID documento).
Partizionamento dei dati in Azure Cosmos DB
Con Azure Cosmos DB le partizioni vengono scalate automaticamente in base al carico di lavoro. È quindi consigliabile usare contenitori illimitati per partizionare i dati. Durante la scrittura in contenitori illimitati, Stream Analytics utilizza un numero di scrittori paralleli uguale a quello usato nel passaggio di query precedente o nello schema di partizionamento degli input.
Nota
Analisi di flusso di Azure supporta solo un numero illimitato di contenitori con chiavi di partizione di primo livello. Ad esempio, /region è supportata. Le chiavi di partizione annidate (ad esempio /region/name) non sono supportate.
A seconda della chiave di partizione scelta, è possibile che venga visualizzato questo avviso:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
È importante scegliere una proprietà della chiave di partizione con molti valori distinti e che consente di distribuire il carico di lavoro in modo uniforme tra questi valori. Come artefatto naturale del partizionamento, le richieste che coinvolgono la stessa chiave di partizione sono limitate dalla velocità effettiva massima di una singola partizione.
Le dimensioni di archiviazione per i documenti che appartengono allo stesso valore della chiave di partizione sono limitate a 20 GB (il limite di dimensioni della partizione fisica è 50 GB). Una chiave di partizione ideale è quella che viene visualizzata spesso come filtro nelle query e ha una cardinalità sufficiente per garantire che la soluzione sia scalabile.
Le chiavi di partizione usate per le query di Analisi di flusso e Azure Cosmos DB non devono essere identiche. Le topologie completamente parallele consigliano di usare la chiave di partizione di input, PartitionId, come chiave di partizione della query di Analisi di flusso, ma potrebbe non essere la scelta consigliata per la chiave di partizione di un contenitore di Azure Cosmos DB.
Una chiave di partizione è anche il limite per le transazioni nelle *stored procedure* e nei *trigger* per Azure Cosmos DB. È necessario scegliere la chiave di partizione in modo che i documenti che si verificano insieme nelle transazioni condividano lo stesso valore della chiave di partizione. L'articolo Partizionamento in Azure Cosmos DB fornisce altri dettagli sulla scelta di una chiave di partizione.
Per i contenitori fissi di Azure Cosmos DB, Stream Analytics non consente alcun modo di scalare in su o in fuori dopo che sono pieni. Tali contenitori hanno un limite massimo di 10 GB e velocità effettiva di 10.000 UR al secondo. Per eseguire la migrazione dei dati da un contenitore fisso a un contenitore illimitato, ad esempio con una velocità effettiva di almeno 1000 UR al secondo e una chiave di partizione, usare lo strumento di migrazione dati o la libreria di feed di modifiche.
La possibilità di scrivere in più contenitori fissi è in fase di deprecazione. Non è consigliabile per la scalabilità orizzontale del processo di Analisi di flusso.
Velocità effettiva migliorata con il livello di compatibilità 1.2
Con il livello di compatibilità 1.2, Stream Analytics supporta l'integrazione nativa per la scrittura in blocco in Azure Cosmos DB. Questa integrazione consente di scrivere in modo efficace in Azure Cosmos DB massimizzando il throughput e gestendo in modo efficiente il throttling delle richieste.
Il meccanismo di scrittura migliorato è disponibile con un nuovo livello di compatibilità a causa della differenza nel comportamento di upsert. Con i livelli precedenti a 1.2, il comportamento di upsert consiste nell'inserimento o nell'unione del documento. Con 1.2, il comportamento di upsert viene modificato per inserire o sostituire il documento.
Con i livelli precedenti a 1.2, Analisi di flusso usa una stored procedure personalizzata per eseguire l'upsert bulk dei documenti per ogni chiave di partizione in Azure Cosmos DB. In quel contesto, un batch viene scritto come una transazione. Anche quando un singolo record raggiunge un errore temporaneo (limitazione), è necessario ritentare l'intero batch. Questo comportamento rende gli scenari con una limitazione ancora ragionevole relativamente lenti.
L'esempio seguente mostra due processi di Analisi di flusso identici che leggono dallo stesso input di Hub eventi di Azure. Entrambi i processi di Stream Analytics sono completamente partizionati utilizzando una query pass-through e scrivono su contenitori identici di Azure Cosmos DB. Le metriche a sinistra provengono dall'attività configurata con il livello di compatibilità 1.0. Le metriche a destra sono configurate con 1.2. Una chiave di partizione di un contenitore Azure Cosmos DB è un GUID univoco che proviene dall'evento di input.
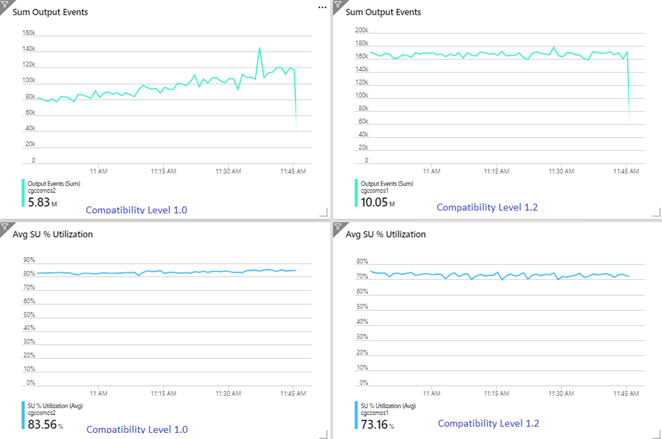
La frequenza degli eventi in ingresso in Hub eventi è due volte superiore rispetto alla configurazione di esecuzione dei contenitori di Azure Cosmos DB (20.000 UR), perciò in Azure Cosmos DB è prevista la limitazione delle richieste. Tuttavia, il processo con 1.2 sta scrivendo in modo coerente a una velocità effettiva superiore (eventi di output al minuto) e con una media inferiore di % di utilizzo unità di streaming. Nel tuo ambiente, questa differenza dipende da pochi altri fattori. Questi fattori includono la scelta del formato dell'evento, la dimensione degli eventi/messaggi di input, le chiavi di partizione e la query.
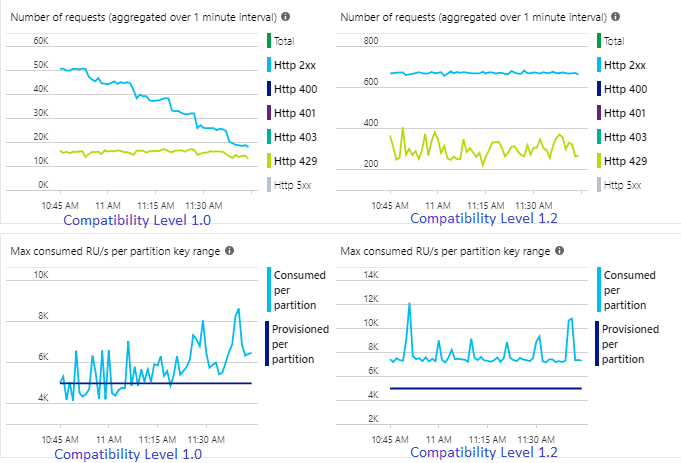
Con la versione 1.2, Stream Analytics è più intelligente nell'utilizzare il 100% della capacità di elaborazione disponibile in Azure Cosmos DB con poche nuove sottomissioni dovute al throttling o al rate limiting. Questo comportamento offre un'esperienza migliore per altri carichi di lavoro come le query in esecuzione nel contenitore contemporaneamente. Per informazioni sull'aumento delle dimensioni di Analisi di flusso con Azure Cosmos DB come sink da 1.000 fino a 10.000 messaggi al secondo, provare questo progetto di esempio di Azure.
Il throughput dell'output di Azure Cosmos DB è identico nelle versioni 1.0 e 1.1. È consigliabile usare il livello di compatibilità 1.2 in Analisi di flusso con Azure Cosmos DB.
Impostazioni di Azure Cosmos DB per l'output JSON
L'uso di Cosmos DB come output in Analisi di flusso genera la seguente richiesta di informazioni.
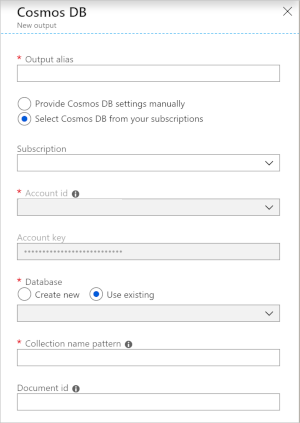
| Campo | Descrizione |
|---|---|
| Alias di output | Alias per fare riferimento a questo output nella query di Analisi di flusso di Azure. |
| Abbonamento | Sottoscrizione di Azure. |
| ID del conto | Nome o URI endpoint dell'account Azure Cosmos DB. |
| Chiave dell'account | Chiave di accesso condiviso per l'account Azure Cosmos DB. |
| Banca dati | Nome del database Azure Cosmos DB. |
| Nome contenitore | Il nome del contenitore, ad esempio MyContainer. Deve esistere un contenitore denominato MyContainer. |
| ID documento | Facoltativo. Nome della colonna negli eventi di output usato come chiave univoca su cui devono basarsi le operazioni di inserimento o aggiornamento. Se si lascia vuoto, tutti gli eventi vengono inseriti, senza alcuna opzione di aggiornamento. |
Dopo aver configurato l'output di Azure Cosmos DB, è possibile usarlo nella query come destinazione di un'istruzione INTO. Quando si usa un output di Azure Cosmos DB in questo modo, una chiave di partizione deve essere impostata in modo esplicito.
Il record di output deve contenere una colonna con distinzione tra maiuscole e minuscole denominata in base alla chiave di partizione in Azure Cosmos DB. Per ottenere una maggiore parallelizzazione, è possibile che l'istruzione richieda una clausola PARTITION BY che usa la stessa colonna.
Ecco una query di esempio:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Gestione degli errori e tentativi
Se si verifica un errore temporaneo, l'indisponibilità del servizio o la limitazione del traffico quando Stream Analytics invia eventi ad Azure Cosmos DB, Stream Analytics ritenta indefinitamente di completare correttamente l'operazione. Non tenta invece di eseguire nuovi tentativi per gli errori seguenti:
- Non autorizzato (codice errore HTTP 401)
- Non trovato (codice errore HTTP 404)
- Errore: Vietato (codice errore HTTP 403)
- BadRequest (codice errore HTTP 400)
Problemi comuni
Un vincolo di indice univoco viene aggiunto alla raccolta e i dati di output di Analisi di flusso violano questo vincolo. Assicurarsi che i dati di output di Analisi di flusso non violano vincoli univoci o rimuovono vincoli. Per altre informazioni, vedere Vincoli di chiave univoca in Azure Cosmos DB.
La
PartitionKeycolonna non esiste.La
Idcolonna non esiste.