Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il diagramma del processo fisico nel portale di Azure consente di visualizzare le metriche chiave del processo con il nodo di streaming in formato diagramma o tabella, ad esempio: utilizzo del CPU, utilizzo della memoria, eventi di input, ID partizione e ritardo limite. Consente di identificare la causa di un problema durante la risoluzione dei problemi.
Questo articolo illustra come usare il diagramma dei processi fisici per analizzare le prestazioni di un processo e identificare rapidamente il collo di bottiglia nel portale di Azure.
Importante
La funzionalità è attualmente disponibile in ANTEPRIMA. Vedere le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure per termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale.
Identificare il parallelismo di un processo
Il processo con parallelizzazione è lo scenario scalabile in Analisi di flusso che può offrire la migliore prestazione. Se un processo non è in modalità parallela, probabilmente presenta un certo collo di bottiglia per le prestazioni. È importante identificare se un processo è in modalità parallela oppure no. Il diagramma di processo fisico fornisce un grafico visivo per illustrare il parallelismo del processo. Nel diagramma del processo fisico, se c’è un'interazione dei dati tra nodi di streaming diversi, questo processo è un processo non parallelo che richiede maggiore attenzione. Ad esempio, il diagramma di processo non parallelo seguente:

È possibile valutarne l'ottimizzazione al processo in parallelo (come l’esempio di seguito) riscrivendo la query o aggiornando le configurazioni di input/output con il simulatore del diagramma del processo all'interno dell'estensione ASA di Visual Studio Code o dell'editor di query nel portale di Azure. Per maggiori informazioni, vedere Ottimizzare la query usando il simulatore del diagramma processi (anteprima).

Metriche chiave per identificare il collo di bottiglia di un processo parallelo
Il ritardo della filigrana e gli eventi di input accumulati sono le metriche chiave per determinare le prestazioni del processo di Analisi di flusso. Se il ritardo della filigrana del processo aumenta continuamente e gli eventi di input si accumulano, il processo non riesce a tenere il passo con la frequenza degli eventi di input e produce output in modo tempestivo. Dal punto di vista della risorsa di calcolo, le risorse CPU e di memoria vengono usate a livello elevato quando questo caso si verifica.
Il diagramma dei processi fisici visualizza insieme queste metriche chiave nel diagramma, per fornire un quadro completo e poter identificare facilmente il collo di bottiglia.

Per maggiori informazioni sulla definizione delle metriche, vedere Dimensione del nome del nodo di Analisi di flusso di Azure.
Identificare gli eventi di input non uniformi distribuiti (data-skew)
Quando si dispone di un processo già in esecuzione in modalità parallela, ma si osserva un ritardo limite massimo, usare questo metodo per determinarne la causa.
Per trovare la causa radice, aprire il diagramma dei processi fisici nel portale di Azure. Selezionare Diagramma processo (anteprima) in Monitoraggio e passare a Diagramma fisico.
Dal diagramma fisico è possibile identificare facilmente se tutte le partizioni hanno un ritardo limite massimo o solo alcune di esse, visualizzando il valore di ritardo limite in ogni nodo o scegliendo l'impostazione della mappa termica ritardo limite per ordinare i nodi di streaming (scelta consigliata):

Dopo aver applicato le impostazioni della mappa termica effettuate in precedenza, si avranno i nodi di streaming con un ritardo limite massimo nell'angolo in alto a sinistra. Successivamente, è possibile verificare se i nodi di streaming corrispondenti hanno più eventi di input significativi rispetto ad altri. Per questo esempio, streamingnode#0 e streamingnode#1 presentano più eventi di input.

È possibile controllare ulteriormente il numero di partizioni allocate singolarmente ai nodi di streaming, per scoprire se più eventi di input sono causati da più partizioni allocate o se una partizione specifica ha più eventi di input. Per questo esempio, tutti i nodi di streaming hanno due partizioni. Significa che streamingnode#0 e streamingnode#1 hanno una determinata partizione specifica che contiene più eventi di input rispetto ad altre partizioni.
Per individuare la partizione con più eventi di input rispetto ad altre partizioni in streamingnode#0 e streamingnode#1, seguire i seguenti passaggi:
- Selezionare Aggiungi grafico nella sezione grafico
- Aggiungere eventi di input in metrica e ID partizione nella barra di divisione
- Selezionare Applicaper visualizzare il grafico degli eventi di input
- Spuntare streamingnode#0 e streamingnode#1 nel diagramma
Verrà visualizzato il grafico qui sotto con la metrica degli eventi di input filtrata in base alle partizioni nei due nodi di streaming.

Quale ulteriore azione è possibile effettuare?
Come illustrato nell'esempio, le partizioni (0 e 1) hanno più dati di input rispetto ad altre partizioni. Questo è chiamato asimmetria dei dati. I nodi di streaming che elaborano le partizioni con asimmetria dei dati devono usare più risorse di CPU e memoria rispetto ad altri. Questo squilibrio porta a prestazioni più lente e aumenta il ritardo limite. È possibile controllare l'utilizzo del CPU e della memoria nei due nodi di streaming e nel diagramma fisico. Per attenuare il problema, è necessario fare una ripartizione più uniforme dei dati di input.
Identificare la causa del sovraccarico del CPU o della memoria
Quando un processo parallelo ha un ritardo limite crescente, senza la situazione di asimmetria dei dati menzionata in precedenza, ciò può essere dovuto a una grande quantità di dati in tutti i nodi di streaming che impedisce le prestazioni. È possibile verificare tale caratteristica nel processo usando il diagramma fisico.
Aprire il diagramma dei processi fisici, andare al portale di Azure del processo in Monitoraggio, selezionare Diagramma processi (anteprima) e passare a Diagramma fisico. Verrà visualizzato il diagramma fisico caricato come riportato di seguito.
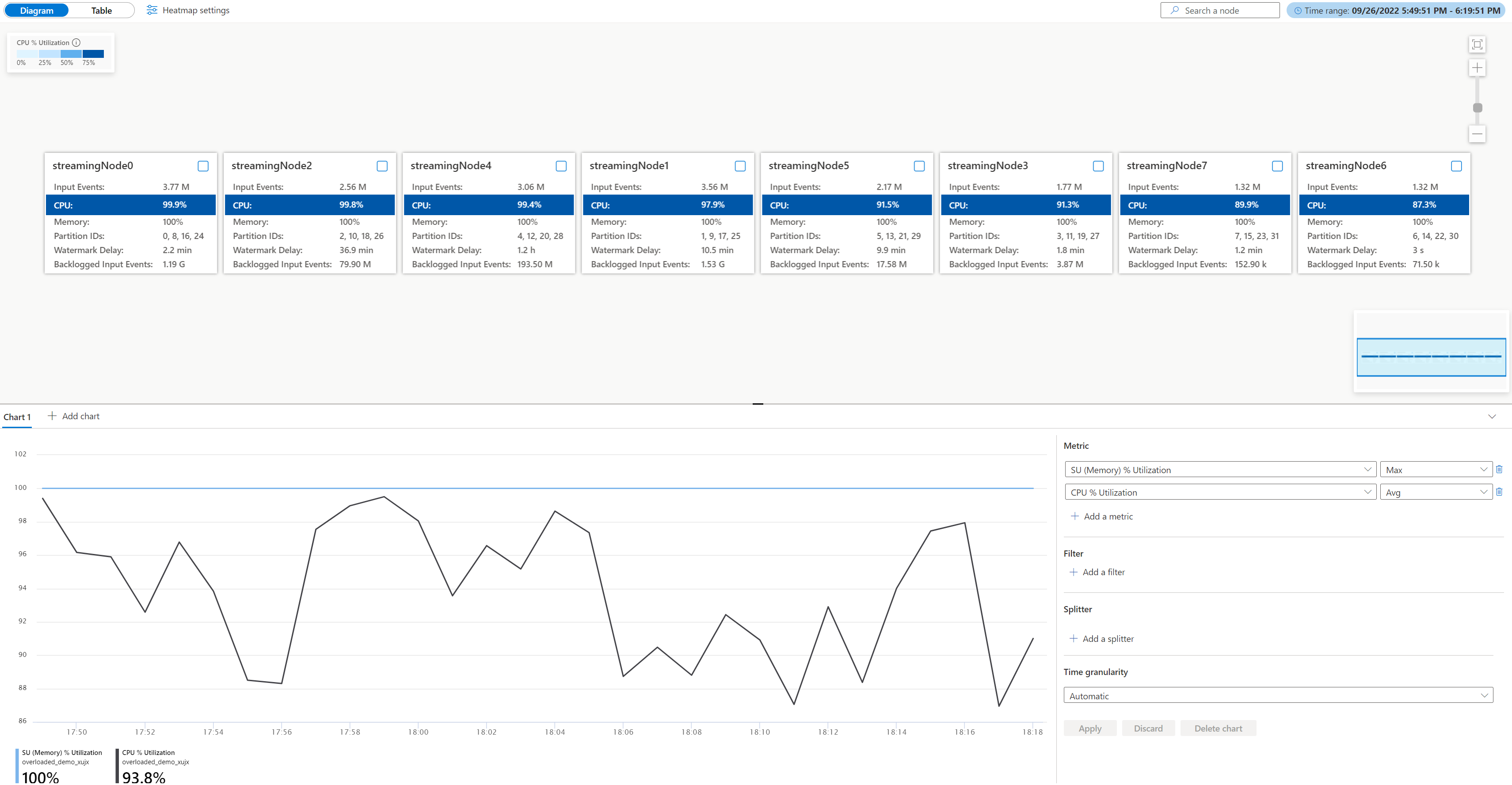
Verificare l'utilizzo del CPU e della memoria in ogni nodo di streaming per controllare se l'utilizzo in tutti i nodi di streaming è troppo elevato. Se l'utilizzo del CPU e Unità di archiviazione è elevato (superiore all'80%) in tutti i nodi di streaming, è possibile concludere che questo processo ha una grande quantità di dati elaborati all'interno di ogni nodo di streaming.
Dal caso precedente, l'utilizzo del CPU è circa il 90% e l'utilizzo della memoria è già pari al 100%. Mostra che ogni nodo di streaming sta esaurendo la risorsa per elaborare i dati.
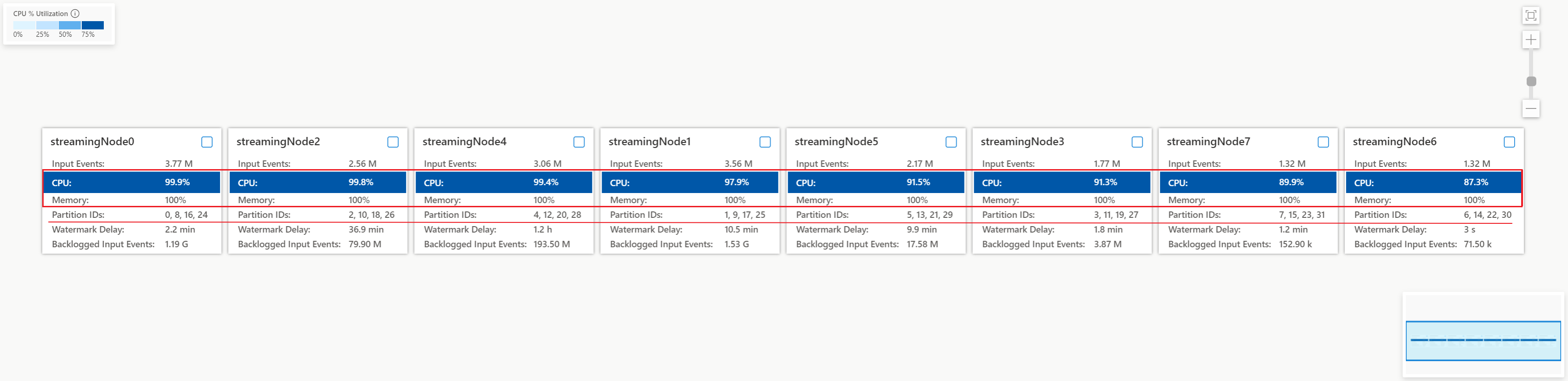
Controllare il numero di partizioni allocate in ogni nodo di streaming al fine di poter valutare se sono necessari più nodi di streaming per bilanciare le partizioni, al fine di ridurre il carico dei nodi di streaming esistenti.
Nel presente caso, ogni nodo di streaming ha quattro partizioni allocate che assomigliano troppo a un nodo di streaming.


Quale ulteriore azione è possibile effettuare?
Valutare la possibilità di ridurre il numero di partizioni per ogni nodo di streaming in modo da ridurre i dati di input. È possibile raddoppiare le SU allocate a ogni nodo di streaming a due partizioni per nodo aumentando il numero di nodi di streaming da 8 a 16. In alternativa, è possibile quadruplicare le SU in modo che ogni nodo di streaming gestisca i dati da una partizione.
Per maggiori informazioni sulla relazione tra nodo di streaming e unità di streaming, vedere Informazioni sull'unità di streaming e il nodo di streaming.
Cosa è consigliabile fare se il ritardo limite aumenta ancora quando un nodo di streaming gestisce i dati da una partizione? Fare una ripartizione degli input con più partizioni per ridurre la quantità di dati in ogni partizione. Per maggiori dettagli, vedere Usare la ripartizione per ottimizzare i processi di Analisi di flusso di Azure.
Passaggi successivi
- Presentazione di Analisi di flusso
- Diagramma dei processi di Analisi di flusso (anteprima) nel portale di Azure
- Metriche del processo Analisi di flusso di Azure
- Scalabilità dei processi di Analisi di flusso
- Informazioni di riferimento sul linguaggio di query di Analisi di flusso
- Analizzare le prestazioni dei processi di Analisi di flusso usando metriche e dimensioni