Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un modo per migliorare le prestazioni di un processo di Analisi di flusso di Azure consiste nell'applicare il parallelismo nella query. Questo articolo illustra come usare la simulazione di processi in portale di Azure e Visual Studio Code (VS Code) per valutare il parallelismo delle query per un processo di Analisi di flusso. Si apprenderà come visualizzare un'esecuzione di query con un numero diverso di unità di streaming e migliorare il parallelismo delle query in base ai suggerimenti di modifica.
Che cos'è la query parallela?
Il parallelismo delle query divide il carico di lavoro di una query creando più processi (o nodi di streaming) e lo esegue in parallelo. Riduce notevolmente il tempo di esecuzione complessivo della query e quindi sono necessarie meno ore di streaming.
Affinché un processo sia parallelo, tutti gli input, gli output e i passaggi di query devono essere allineati e usare le stesse chiavi di partizione. Il partizionamento della logica di query è determinato dalle chiavi usate per le aggregazioni (GROUP BY).
Per altre informazioni sulla parallelizzazione delle query, vedere Sfruttare la parallelizzazione delle query in Analisi di flusso di Azure.
Usare la simulazione di processi in VS Code
La funzionalità Simulazione processi simula il modo in cui il processo esegue la topologia in Azure. In questa esercitazione si apprenderà a migliorare le prestazioni delle query in base ai suggerimenti di modifica e a eseguirla in parallelo. Ad esempio, viene usato un processo nonparallele che accetta i dati di input da un hub eventi e invia i risultati a un altro hub eventi.
Prerequisiti:
- Estensione ASA Tools per VS Code. Se non è ancora stato installato, seguire questa guida per l'installazione.
- Configurare l'input live e l'output live per il processo di Analisi di flusso.
- È necessario includere l'input attivo e l'output nella query.
Nota
La simulazione processo non può simulare la topologia in esecuzione del processo per gli input e gli output locali. Nessun dato verrà inviato alla destinazione di output durante la simulazione.
Aprire il progetto ASA in VS Code. Passare al file di query *.asaql e selezionare Simula processo per avviare Simulazione processi.

Nella scheda Diagramma viene visualizzato il numero di nodi di streaming allocati al processo e il numero di partizioni in ogni nodo di streaming. Lo screenshot seguente è un esempio di processo nonparallele in cui i dati vengono trasmessi tra i nodi.
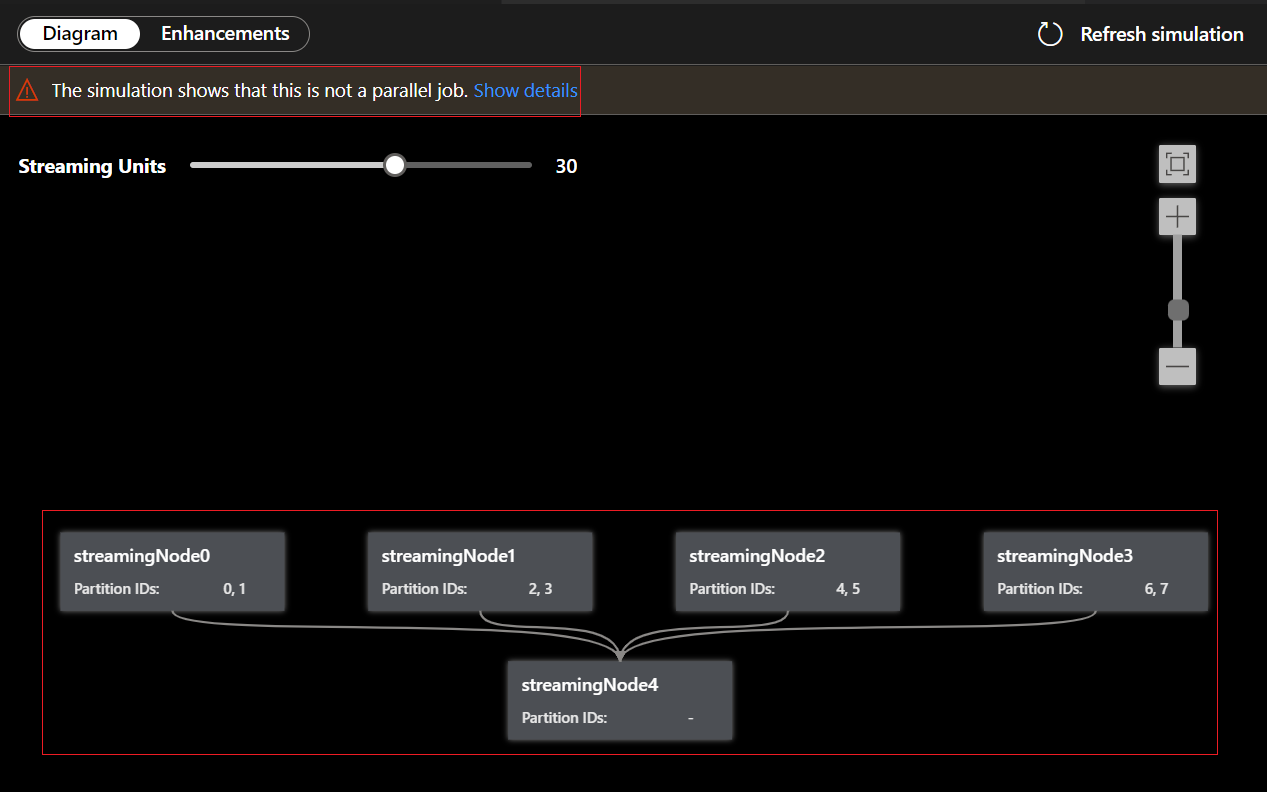
Poiché questa query non è in parallelo, è possibile selezionare la scheda Miglioramenti per visualizzare i suggerimenti relativi al miglioramento della query.

Selezionare il passaggio di query nell'elenco dei miglioramenti, vengono evidenziate le righe corrispondenti ed è possibile modificare la query in base ai suggerimenti.
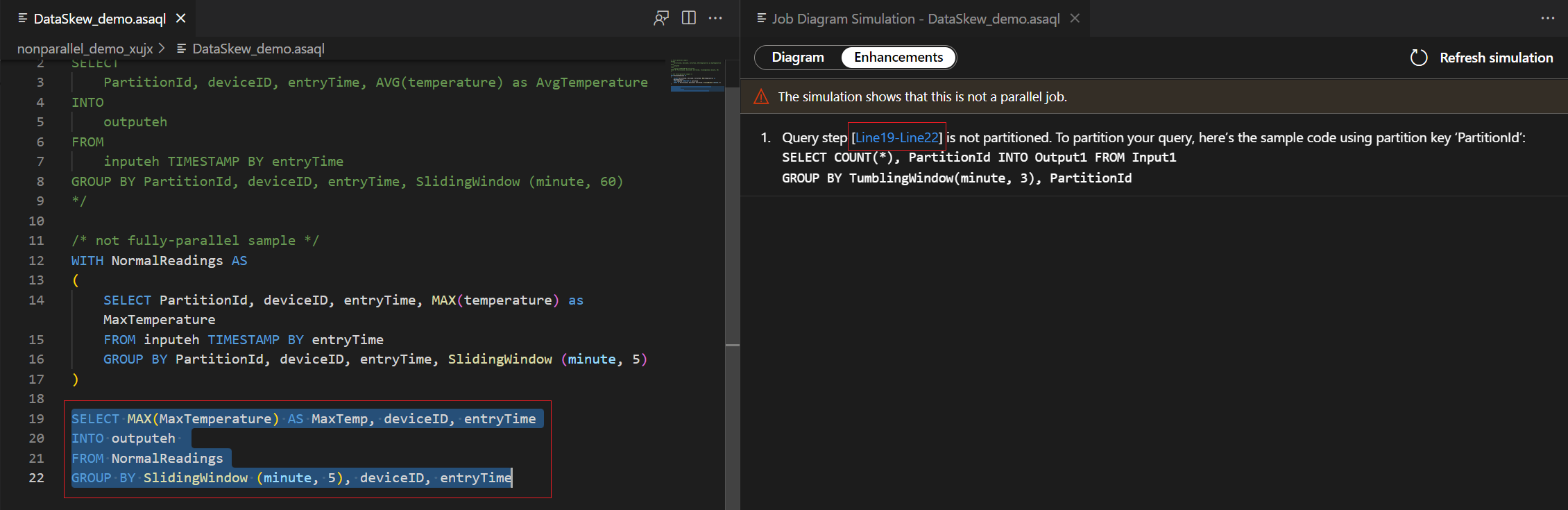
Nota
Si tratta di suggerimenti di modifica per migliorare il parallelismo delle query. Tuttavia, se si usa la funzione di aggregazione tra tutte le partizioni, la presenza di una query parallela potrebbe non essere applicabile per gli scenari.
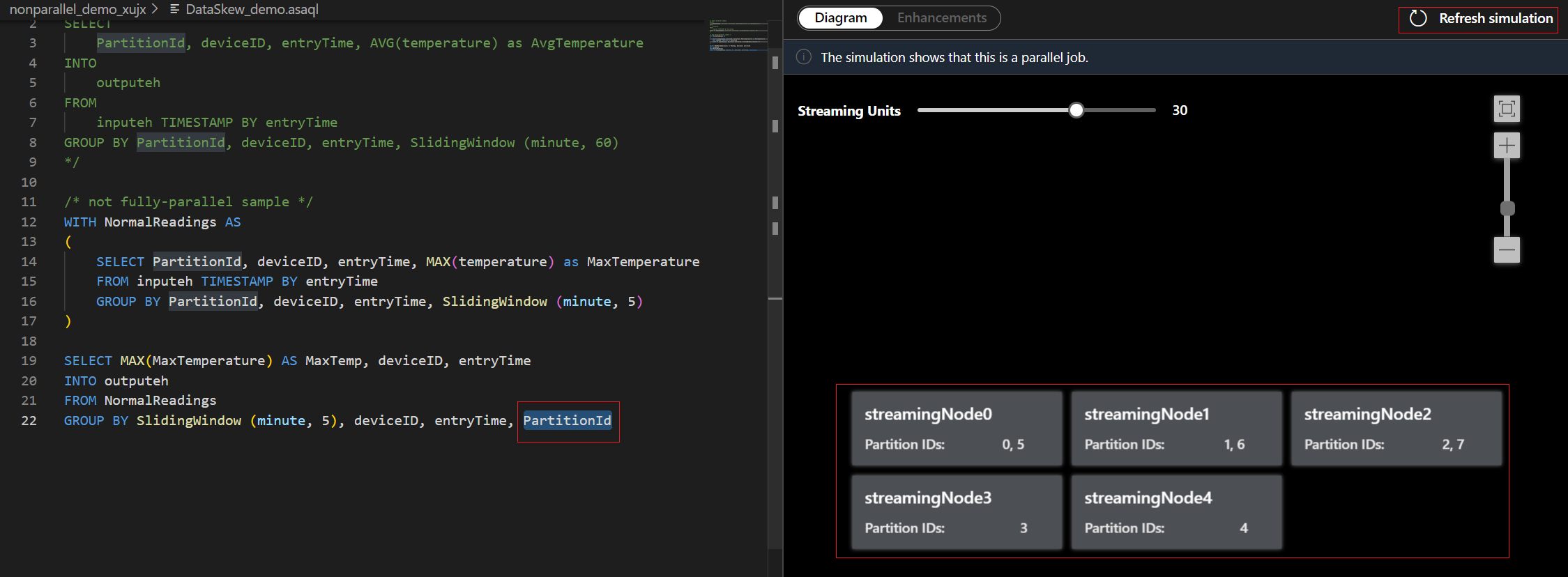
Per questo esempio, aggiungere PartitionId alla riga 22 e salvare la modifica. È quindi possibile usare La simulazione di aggiornamento per ottenere il nuovo diagramma.
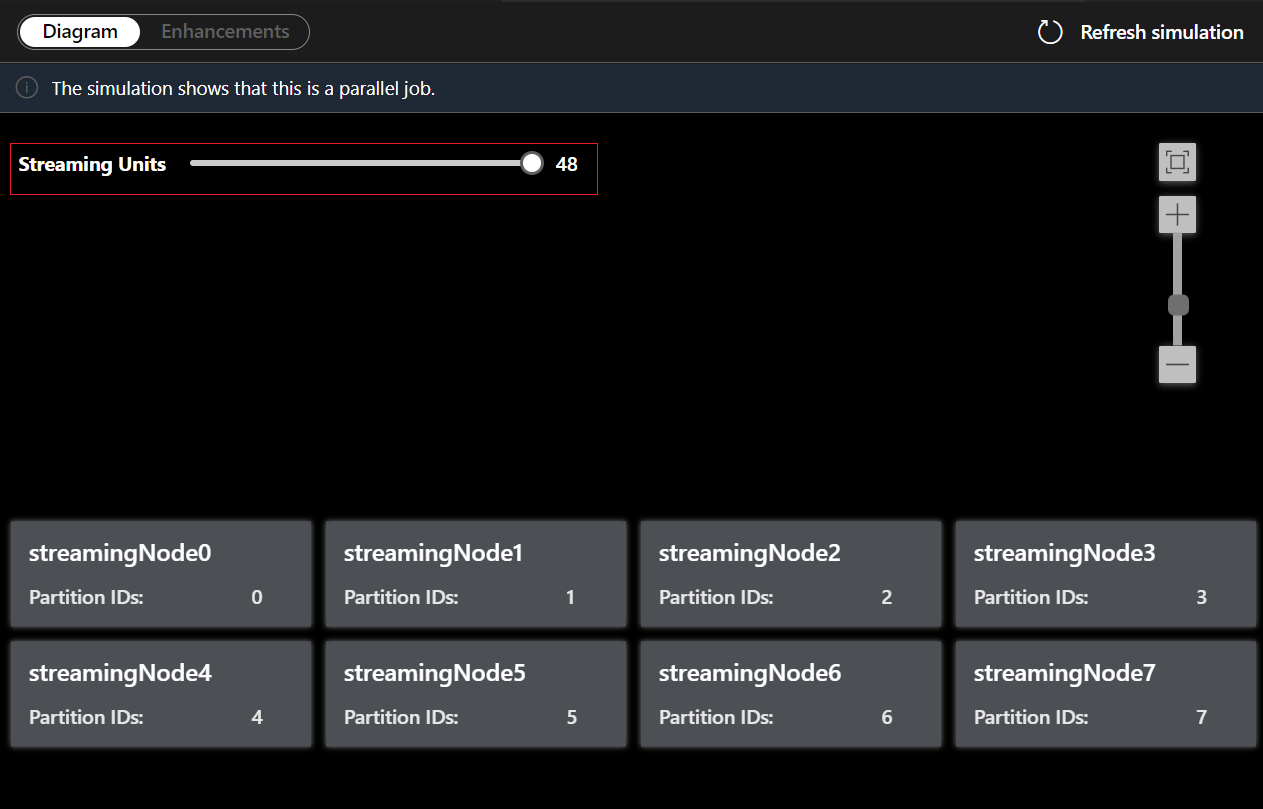
È anche possibile modificare le unità di streaming per stimolare la modalità di allocazione dei nodi di streaming con unità di streaming diverse. Offre un'idea del numero di UR necessarie per gestire il carico di lavoro.






Usare la simulazione di processi nel portale di Azure
- Passare all'editor di query in portale di Azure e selezionare Simulazione processi nel riquadro inferiore. Simula il processo che esegue la topologia in base alla query e alle unità di streaming predefinite.
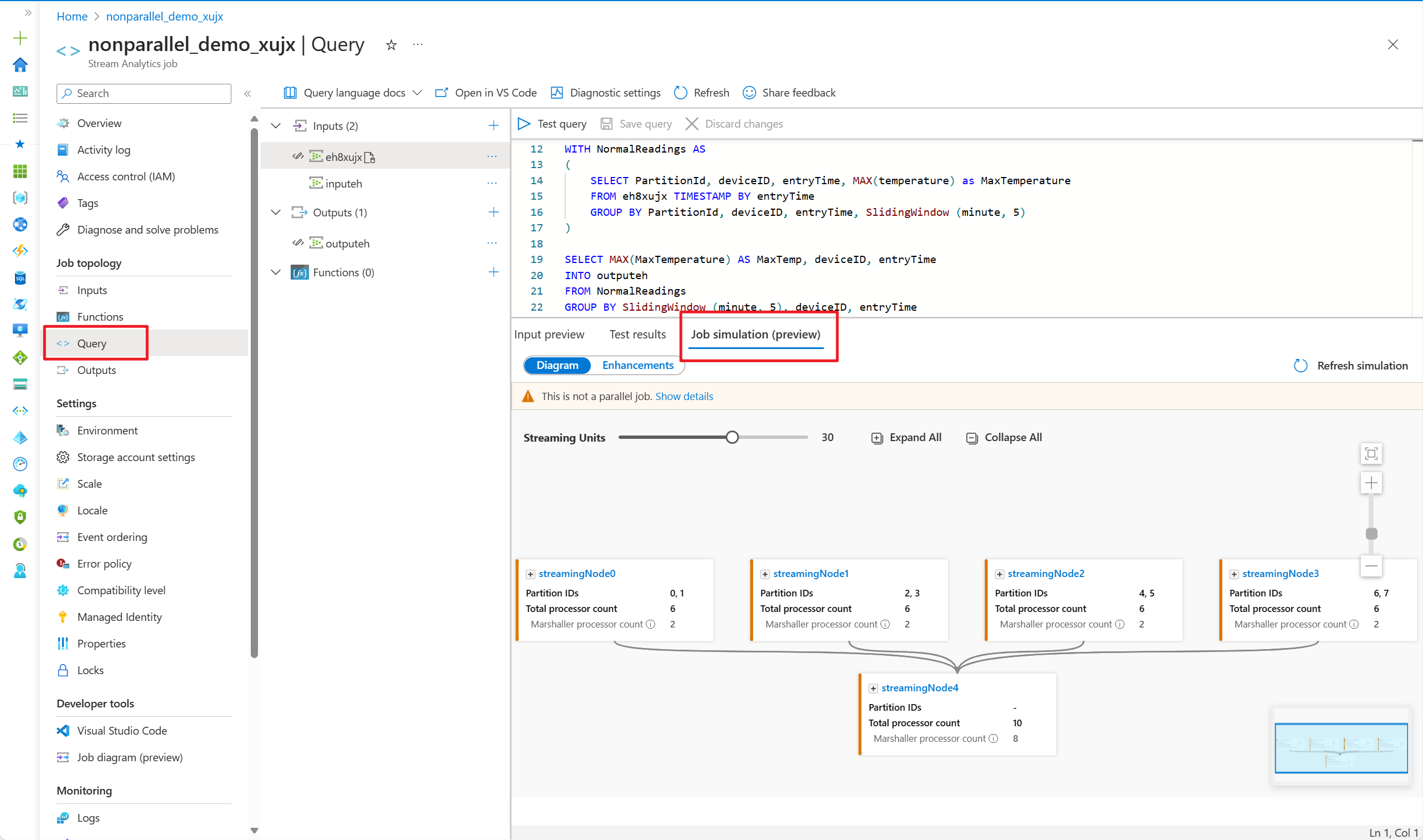
- Selezionare Miglioramenti per visualizzare i suggerimenti per migliorare il parallelismo delle query.

- Modificare le unità di streaming per visualizzare il numero di unità di streaming necessarie per la gestione del carico di lavoro.
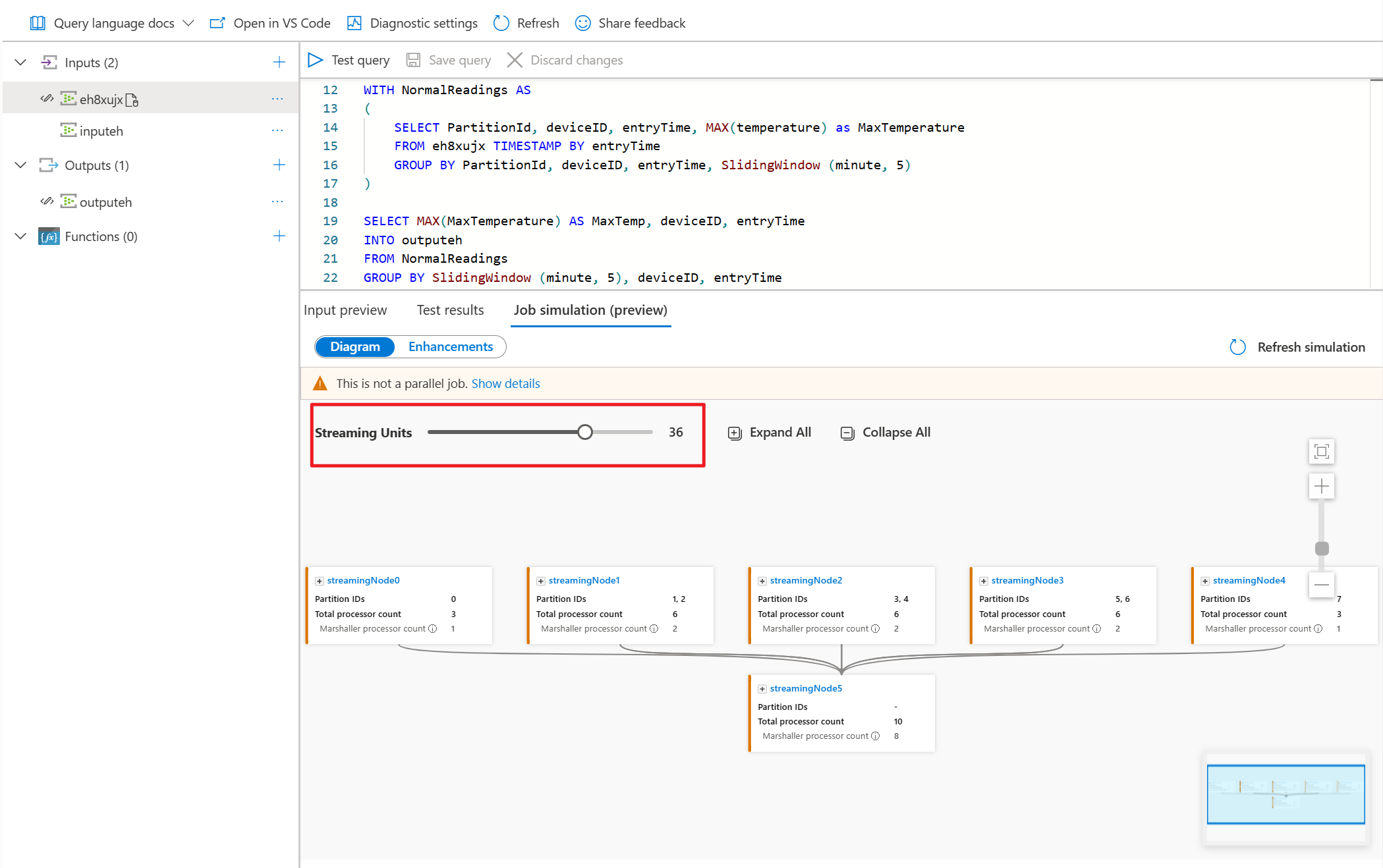



Diagramma a livello di processore
Dopo aver modificato le unità di streaming per simulare la topologia del processo, è possibile espandere uno dei nodi di streaming per osservare come vengono elaborati i dati a livello di processore.

Il diagramma a livello di processore consente di:
- osservare come le partizioni di input vengono allocate ed elaborate in ogni nodo di streaming.
- scoprire qual è il cambio di tempo per ogni processore di elaborazione.
- specificare informazioni su se i processori di input e output sono allineati in parallelo.
Per eseguire il mapping del processore con il passaggio della query, selezionare due volte nel diagramma. Questa funzionalità consente di individuare i passaggi di query che eseguono l'aggregazione.

Suggerimenti per i miglioramenti
Ecco le spiegazioni per i miglioramenti:
| Tipo | Significato |
|---|---|
| Partizione personalizzata non supportata | Modificare la chiave di partizione 'xxx' di input in 'xxx'. |
| Numero di partizioni non corrispondenti | L'input e l'output devono avere lo stesso numero di partizioni. |
| Chiavi di partizione non corrispondenti | L'input, l'output e ogni passaggio di query devono usare la stessa chiave di partizione. |
| Numero di partizioni di input non corrispondenti | Tutti gli input devono avere lo stesso numero di partizioni. |
| Chiavi di partizione di input non corrispondenti | Tutti gli input devono usare la stessa chiave di partizione. |
| Livello di compatibilità basso | Aggiornare CompatibilityLevel nel file JobConfig.json . |
| Chiave di partizione di output non trovata | È necessario usare la chiave di partizione specificata per l'output. |
| Partizione personalizzata non supportata | È possibile usare solo chiavi di partizione predefinite. |
| Passaggio di query che non usa la partizione | La query non usa alcuna clausola PARTITION BY. |
Passaggi successivi
Per altre informazioni sulla parallelizzazione delle query e sul diagramma dei processi, vedere queste esercitazioni: