Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida introduttiva si apprenderà come copiare un notebook di Machine Learning di esempio dalla raccolta di Synapse Analytics nell'area di lavoro, modificarlo ed eseguirlo.
Prerequisiti
- Area di lavoro di Azure Synapse Analytics con un account di archiviazione azure Data Lake Archiviazione Gen2 configurato come risorsa di archiviazione predefinita. È necessario essere il collaboratore ai dati blob Archiviazione del file system di Data Lake Archiviazione Gen2 con cui si lavora.
- Pool di Spark nell'area di lavoro di Azure Synapse Analytics.
Copiare il notebook nell'area di lavoro
Aprire l'area di lavoro e selezionare Learn dalla home page.
Nel Centro conoscenze selezionare Sfoglia raccolta.
Nella raccolta selezionare Notebook.
Trovare e selezionare un notebook dalla raccolta.
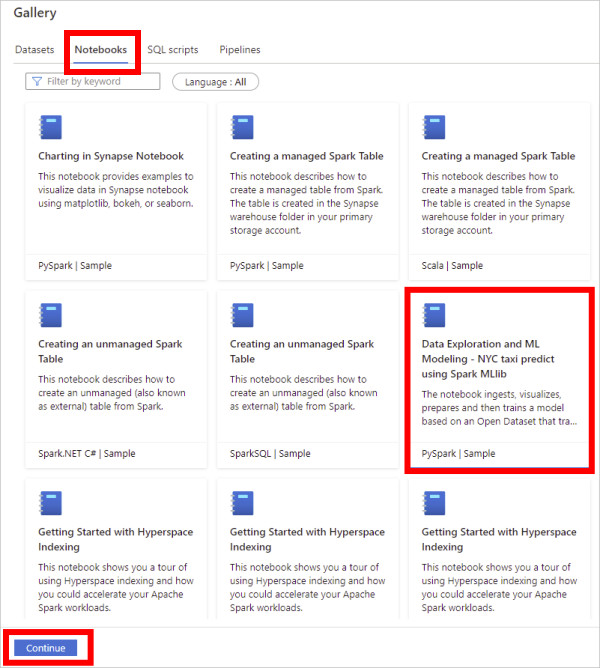
Selezionare Continua.
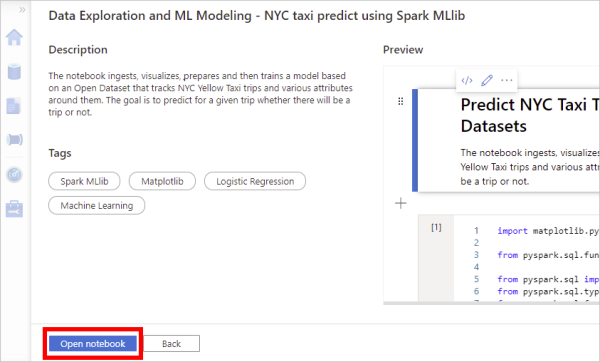
Nella pagina di anteprima del notebook selezionare Apri notebook. Il notebook di esempio viene copiato nell'area di lavoro e aperto.
Nel menu Connetti a nel notebook aperto selezionare il pool di Apache Spark.
Salvare il notebook
Per salvare il notebook selezionando Pubblica sulla barra dei comandi dell'area di lavoro.
Copia del notebook di esempio
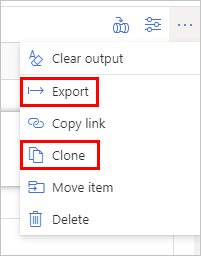
Per creare una copia di questo notebook, fare clic sui puntini di sospensione nella barra dei comandi superiore e selezionare Clona per creare una copia nell'area di lavoro o Esporta per scaricare una copia del file del notebook (.ipynb).
Pulire le risorse
Per assicurarsi che l'istanza di Spark venga arrestata al termine, terminare tutte le sessioni connesse (notebook). Il pool si arresta quando viene raggiunto il tempo di inattività specificato nel pool di Apache Spark. È anche possibile selezionare Arresta sessione dalla barra di stato in alto a destra del notebook.