Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come arricchire facilmente i dati in pool SQL dedicati con modelli di Machine Learning predittivi. I modelli creati dai data scientist sono ora facilmente accessibili ai professionisti dei dati per l'analisi predittiva. Un professionista dei dati in Azure Synapse Analytics può semplicemente selezionare un modello dal Registro modelli di Azure Machine Learning per la distribuzione nei pool SQL di Azure Synapse e avviare stime per arricchire i dati.
In questa esercitazione si apprenderà come:
- Eseguire il training di un modello di Machine Learning e registrarlo nel registro di modelli di Azure Machine Learning.
- Usare la procedura guidata di assegnazione di punteggi di SQL per avviare previsioni nel pool SQL dedicato.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Area di lavoro di Azure Synapse Analytics con un account di archiviazione di Azure Data Lake Storage Gen2 configurato come risorsa di archiviazione predefinita. È necessario essere il Collaboratore ai dati del BLOB di archiviazione del file system di Data Lake Storage Gen2 con cui si lavora.
- Pool SQL dedicato nell'area di lavoro di Azure Synapse Analytics. Per informazioni dettagliate, vedere Creare un pool SQL dedicato.
- Servizio collegato di Azure Machine Learning nell'area di lavoro di Azure Synapse Analytics. Per informazioni dettagliate, vedere Creare un servizio collegato di Azure Machine Learning in Azure Synapse.
Accedere al portale di Azure
Accedi al portale di Azure.
Eseguire il training di un modello in Azure Machine Learning
Prima di iniziare, verificare che la versione di sklearn sia 0.20.3.
Prima di eseguire tutte le celle nel notebook, verificare che l'istanza di calcolo sia in esecuzione.
Passare all'area di lavoro di Azure Machine Learning.
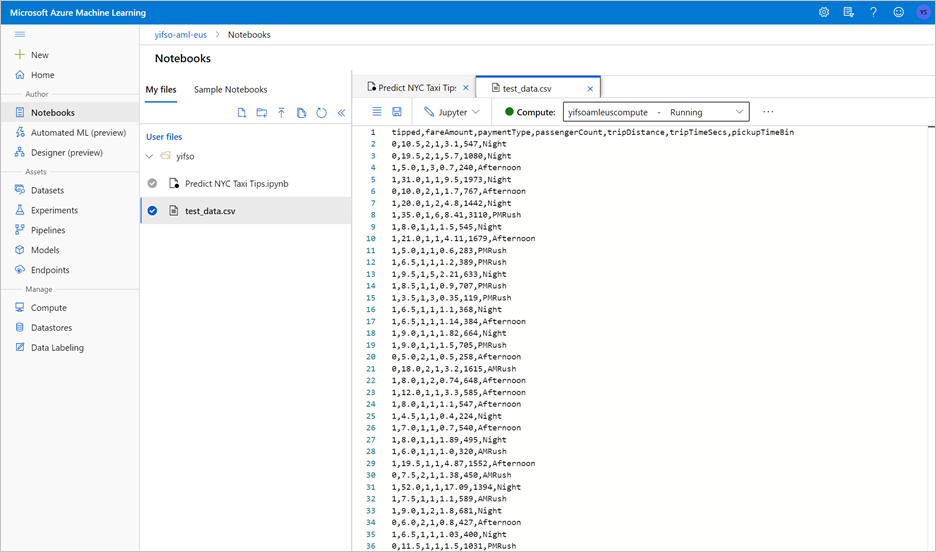
Scarica Predict NYC Taxi Tips.ipynb.
Aprire l'area di lavoro di Azure Machine Learning in Azure Machine Learning Studio.
Passare a Notebook>Carica file. Selezionare quindi il file Predict NYC Taxi Tips.ipynb scaricato e caricato.
Dopo aver caricato e aperto il notebook, selezionare Esegui tutte le celle.
Una delle celle potrebbe non riuscire e chiedere di eseguire l'autenticazione in Azure. Eseguire un controllo negli output delle celle, quindi eseguire l'autenticazione nel browser seguendo il collegamento e immettendo il codice. Eseguire di nuovo il notebook.
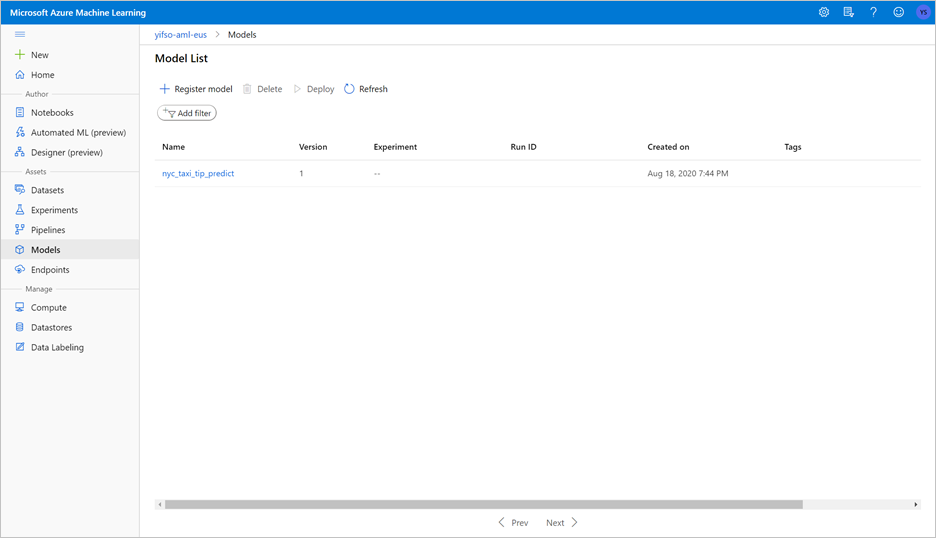
Il notebook eseguirà il training di un modello ONNX e lo registrerà con MLflow. Passare a Modelli per verificare che il nuovo modello sia registrato correttamente.
L'esecuzione del notebook esporta anche i dati di test in un file CSV. Scaricare il file CSV nel sistema locale. Successivamente, si importerà il file CSV in un pool SQL dedicato e si useranno i dati per testare il modello.
Il file CSV viene creato nella stessa cartella del file del notebook. Selezionare Aggiorna in Esplora file se non viene visualizzato immediatamente.
Avviare stime con la procedura guidata per l'assegnazione dei punteggi SQL
Aprire l'area di lavoro di Azure Synapse con Synapse Studio.
Passare a Dati>Collegato>Account di archiviazione. Caricare
test_data.csvnell'account di archiviazione predefinito.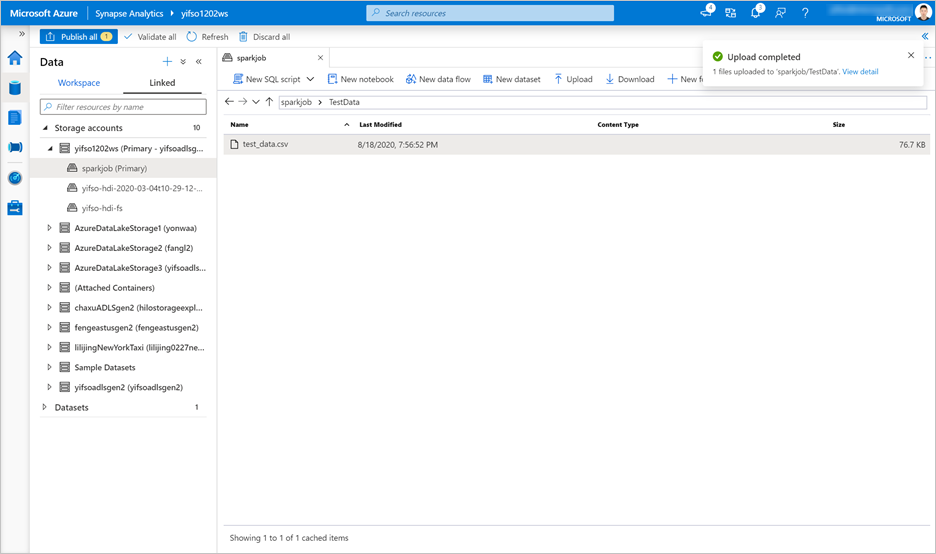
Passare a Sviluppo>Script SQL. Creare un nuovo script SQL da caricare
test_data.csvnel pool SQL dedicato.Annotazioni
Aggiornare l'URL del file in questo script prima di eseguirlo.
IF NOT EXISTS (SELECT * FROM sys.objects WHERE NAME = 'nyc_taxi' AND TYPE = 'U') CREATE TABLE dbo.nyc_taxi ( tipped int, fareAmount float, paymentType int, passengerCount int, tripDistance float, tripTimeSecs bigint, pickupTimeBin nvarchar(30) ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ) GO COPY INTO dbo.nyc_taxi (tipped 1, fareAmount 2, paymentType 3, passengerCount 4, tripDistance 5, tripTimeSecs 6, pickupTimeBin 7) FROM '<URL to linked storage account>/test_data.csv' WITH ( FILE_TYPE = 'CSV', ROWTERMINATOR='0x0A', FIELDQUOTE = '"', FIELDTERMINATOR = ',', FIRSTROW = 2 ) GO SELECT TOP 100 * FROM nyc_taxi GO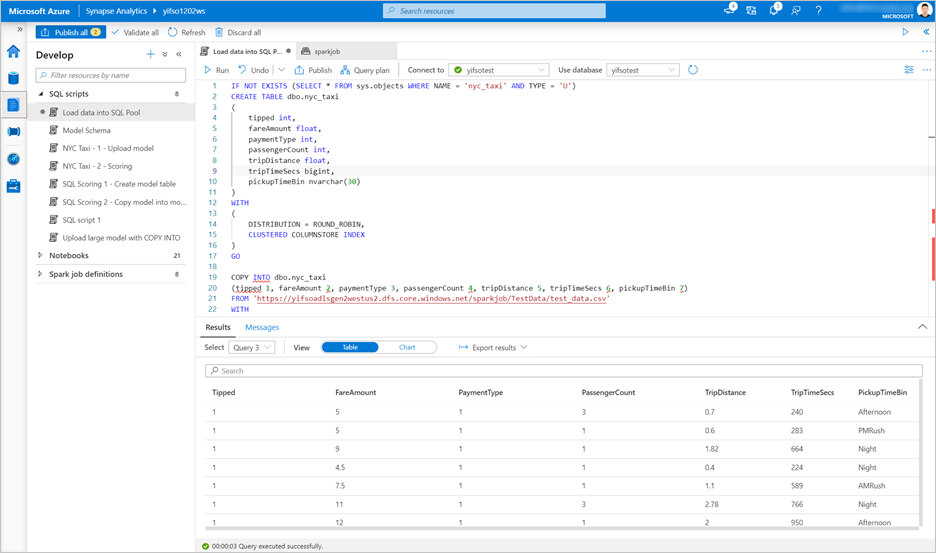
Vai a Dati>Workspace. Aprire la procedura guidata di assegnazione dei punteggi SQL facendo clic con il pulsante destro del mouse sulla tabella del pool SQL dedicato. Selezionare Machine Learning>Predict con un modello.
Annotazioni
L'opzione di Machine Learning non viene visualizzata a meno che non sia stato creato un servizio collegato per Azure Machine Learning. Consultare i Prerequisiti all'inizio di questa esercitazione.
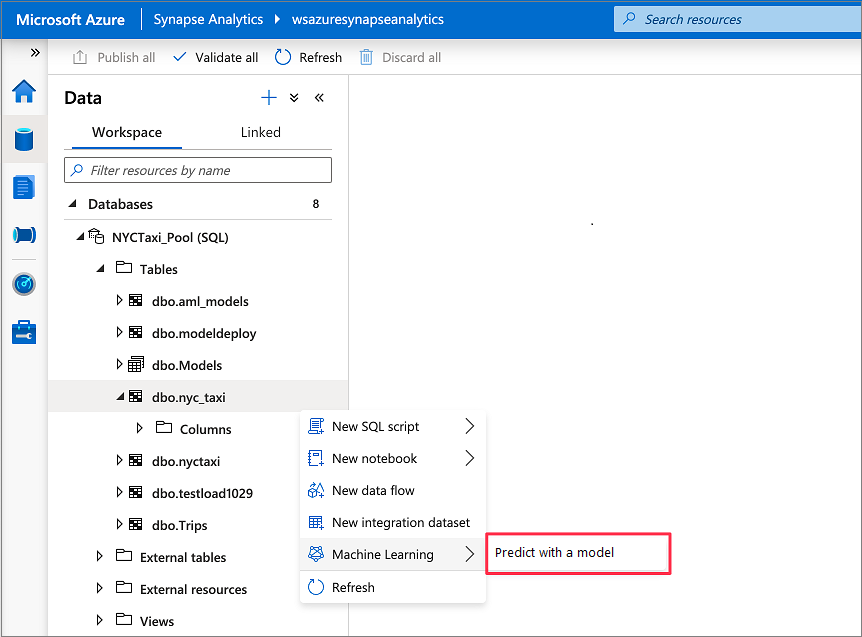
Selezionare un'area di lavoro di Azure Machine Learning collegata nella casella a discesa. Questo passaggio carica un elenco di modelli di Machine Learning dal Registro modelli dell'area di lavoro di Azure Machine Learning scelta. Attualmente sono supportati solo i modelli ONNX, quindi questo passaggio visualizzerà solo i modelli ONNX.
Selezionare il modello appena sottoposto a training e quindi selezionare Continua.
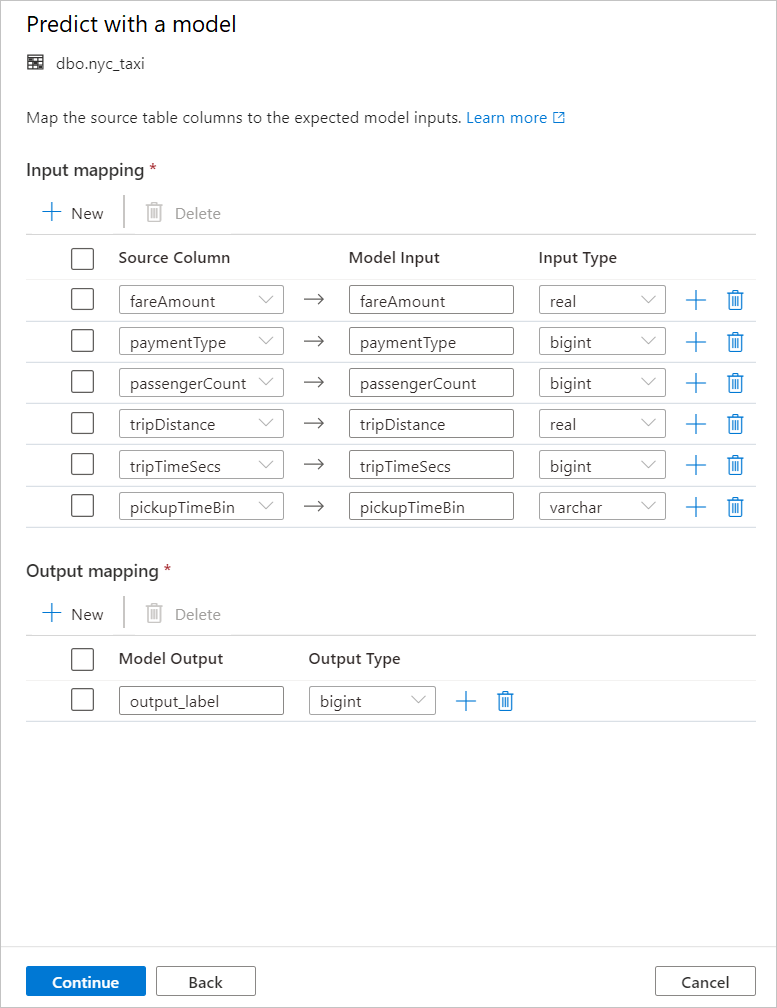
Mappare le colonne della tabella sugli input del modello e specificare gli output del modello. Se il modello viene salvato nel formato MLFlow e la firma del modello viene popolata, il mapping verrà eseguito automaticamente usando una logica basata sulla somiglianza dei nomi. L'interfaccia supporta anche il mapping manuale.
Seleziona Continua.
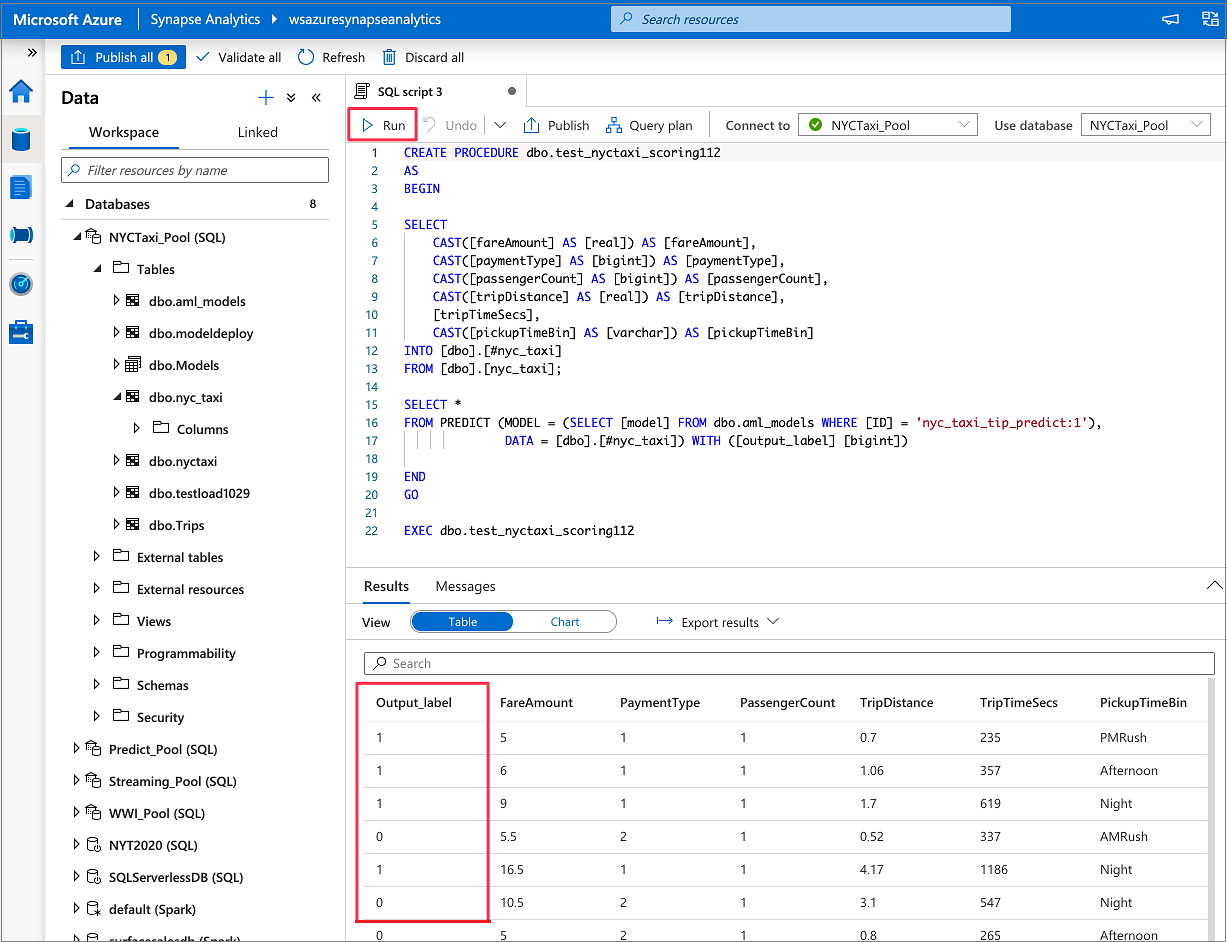
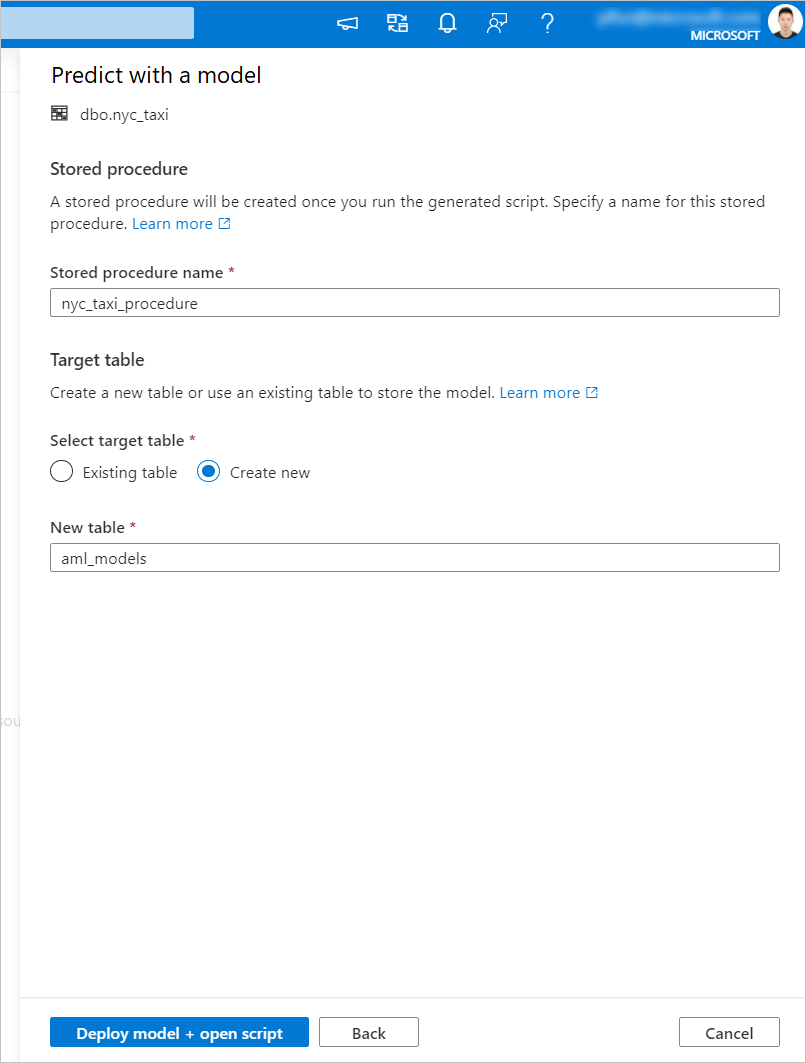
Il codice T-SQL generato viene racchiuso all'interno di una procedura memorizzata. Questo è il motivo per cui è necessario fornire un nome per la stored procedure. Il file binario del modello, inclusi i metadati (versione, descrizione e altre informazioni), verrà copiato fisicamente da Azure Machine Learning a una tabella del pool SQL dedicata. È quindi necessario specificare la tabella in cui salvare il modello.
È possibile scegliere Tabella esistente o Crea nuovo. Al termine, selezionare Distribuisci modello e script aperto per distribuire il modello e generare uno script di stima T-SQL.
Dopo aver generato lo script, selezionare Esegui per eseguire l'assegnazione dei punteggi e ottenere stime.