Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo è la prima parte di una serie in sette parti che offre indicazioni su come eseguire la migrazione da Netezza ad Azure Synapse Analytics. L'obiettivo di questo articolo è illustrare le procedure consigliate per progettazione e prestazioni.
Panoramica
A causa della fine del supporto di IBM, molti utenti esistenti dei sistemi di data warehouse Netezza vogliono sfruttare le innovazioni offerte dagli ambienti cloud moderni. Gli ambienti cloud IaaS (Infrastructure-as-a-Service) e PaaS (Platform-as-a-Service) consentono di delegare attività come la manutenzione dell'infrastruttura e lo sviluppo della piattaforma al provider di servizi cloud.
Suggerimento
Oltre a un semplice database, l'ambiente Azure include un set completo di funzionalità e strumenti.
Anche se Netezza e Azure Synapse Analytics sono entrambi database SQL che usano tecniche di elaborazione parallela elevata (MPP) per ottenere prestazioni di query elevate su volumi di dati di dimensioni eccezionali, esistono alcune differenze di base nell'approccio:
I sistemi Netezza legacy vengono spesso installati in locale e usano hardware proprietario, mentre Azure Synapse è basato sul cloud e usa archiviazione e risorse di calcolo di Azure.
L'aggiornamento di una configurazione Netezza è un'operazione impegnativa, che richiede hardware fisico aggiuntivo e processi di dump e ricaricamento o di riconfigurazione del database potenzialmente lunghi. Poiché le risorse di archiviazione e calcolo sono separate nell'ambiente Azure e hanno funzionalità di ridimensionamento elastico, tali risorse possono essere dimensionate verso l'alto o verso il basso in modo indipendente.
È possibile sospendere o ridimensionare Azure Synapse in base alle esigenze per ridurre l'utilizzo e i costi delle risorse.
Microsoft Azure è un ambiente cloud disponibile a livello globale, altamente sicuro e scalabile, che include Azure Synapse all'interno di un ecosistema di strumenti e funzionalità di supporto. Il diagramma seguente riepiloga l'ecosistema Azure Synapse.
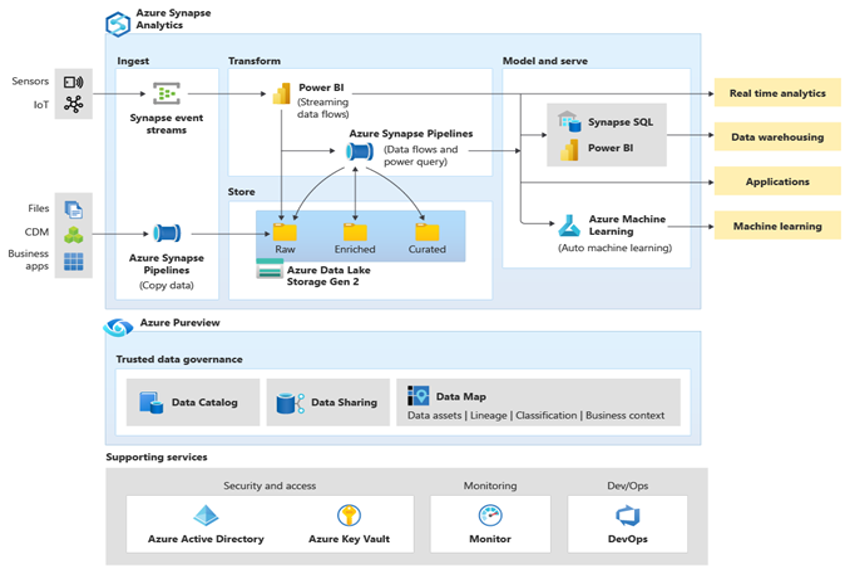
Azure Synapse offre prestazioni ottimali del database relazionale usando tecniche come MPP e più livelli di memorizzazione nella cache automatizzata per i dati usati di frequente. I risultati di queste tecniche possono essere verificati in benchmark indipendenti, ad esempio quello eseguito di recente da GigaOm, che confronta Azure Synapse con altre offerte diffuse di data warehouse sul cloud. I clienti che eseguono la migrazione all'ambiente Azure Synapse ottengono molti vantaggi, tra cui:
Prestazioni più elevate e rapporto prezzo/prestazioni migliorato.
Maggiore agilità e tempo di creazione del valore più breve.
Procedure più rapide di distribuzione di server e sviluppo di applicazioni.
Scalabilità elastica, pagando solo per l'utilizzo effettivo.
Sicurezza e conformità migliorate.
Riduzione dei costi di archiviazione e ripristino di emergenza.
Riduzione del costo totale di proprietà, migliore controllo dei costi e riduzione delle spese operative (OPEX).
Per ottimizzare questi vantaggi, eseguire la migrazione di dati e applicazioni nuovi o esistenti alla piattaforma Azure Synapse. In molte organizzazioni la migrazione include lo spostamento di un data warehouse esistente da una piattaforma locale legacy, ad esempio Netezza, ad Azure Synapse. A livello generale, il processo di migrazione include questi passaggi:
Preparazione
Definire l'ambito: cosa includere nella migrazione.
Creare un inventario dei dati e dei processi da migrare.
Definire le modifiche al modello di dati (se presenti).
Definire il meccanismo di estrazione dei dati di origine.
Identificare gli strumenti e le funzionalità di Azure e di terze parti appropriati da usare.
Eseguire preventivamente il training del personale sulla nuova piattaforma.
Configurare la piattaforma di destinazione di Azure.
Migrazione
Iniziare con un progetto semplice e di piccole dimensioni.
Automatizzare laddove possibile.
Sfruttare gli strumenti e le funzionalità predefiniti di Azure per ridurre le attività di migrazione.
Eseguire la migrazione dei metadati per tabelle e viste.
Eseguire la migrazione dei dati cronologici da gestire.
Eseguire la migrazione o il refactoring di stored procedure e processi aziendali.
Eseguire la migrazione o il refactoring dei processi di caricamento incrementale di ETL/ELT.
Dopo la migrazione
Monitorare e documentare tutte le fasi del processo.
Usare l'esperienza acquisita per creare un modello per le migrazioni future.
Riprogettare il modello di dati se necessario (usando nuove prestazioni e scalabilità della piattaforma).
Testare le applicazioni e gli strumenti di query.
Eseguire il benchmark delle prestazioni delle query e ottimizzarle.
Questo articolo fornisce informazioni generali e linee guida per l'ottimizzazione delle prestazioni durante la migrazione di un data warehouse da un ambiente Netezza esistente ad Azure Synapse. L'obiettivo dell'ottimizzazione delle prestazioni è ottenere le stesse prestazioni del data warehouse in Azure Synapse dopo la migrazione dello schema.
Considerazioni relative alla progettazione
Ambito migrazione
Quando si prepara la migrazione da un ambiente Netezza, prendere in considerazione le opzioni di migrazione seguenti.
Scegliere il carico di lavoro per la migrazione iniziale
In genere, gli ambienti Netezza legacy si sono evoluti nel tempo per includere più aree soggette e carichi di lavoro misti. Quando si decide dove iniziare un progetto di migrazione, scegliere un'area in cui sarà possibile:
Dimostrare l'efficacia della migrazione ad Azure Synapse concretizzando rapidamente i vantaggi del nuovo ambiente.
Consentire al personale tecnico interno di acquisire esperienza pertinente con i processi e gli strumenti che userà per eseguire la migrazione di altre aree.
Creare un modello per altre migrazioni specifiche per l'ambiente Netezza di origine e gli strumenti e i processi correnti già presenti.
Un buon candidato per una migrazione iniziale da un ambiente Netezza supporta gli elementi precedenti e:
Implementa un carico di lavoro BI/Analytics anziché un carico di lavoro OLTP (Online Transaction Processing).
Dispone di un modello di dati, ad esempio uno schema star o snowflake, di cui è possibile eseguire la migrazione con una modifica minima.
Suggerimento
Creare un inventario degli oggetti di cui è necessario eseguire la migrazione e documentare il processo di migrazione.
Il volume dei dati trasferiti in una migrazione iniziale deve essere sufficientemente grande da illustrare le funzionalità e i vantaggi dell'ambiente Azure Synapse, ma non troppo grande da dimostrare rapidamente il valore. Una dimensione nell'intervallo da 1 a 10 terabyte è tipica.
Per il progetto di migrazione iniziale, ridurre al minimo il rischio, il lavoro e il tempo di migrazione in modo da poter visualizzare rapidamente i vantaggi dell'ambiente cloud di Azure. Sia gli approcci di migrazione "lift and shift" che di migrazione in più fasi limitano l'ambito della migrazione iniziale solo ai data mart e non affrontano aspetti di migrazione più ampi, ad esempio la migrazione ETL e la migrazione cronologica dei dati. Tuttavia, è possibile risolvere questi aspetti nelle fasi successive del progetto dopo che il livello data mart migrato viene riempito di dati e dei processi di compilazione necessari.
Migrazione lift-and-shift o approccio in più fasi
In generale, esistono due tipi di migrazione indipendentemente dallo scopo e dall'ambito della migrazione pianificata: "lift and shift" (così com'è) e un approccio in più fasi che incorpora le modifiche.
Lift-and-shift
In una migrazione "lift and shift", un modello di dati esistente, come uno schema star, viene sottoposto a migrazione senza modifiche alla nuova piattaforma Azure Synapse. Questo approccio riduce al minimo i rischi e i tempi di migrazione diminuendo il lavoro necessario per sfruttare i vantaggi del passaggio all'ambiente cloud di Azure. La migrazione lift-and-shift è ideale per i seguenti scenari:
- È disponibile un ambiente Netezza esistente con un singolo data mart di cui eseguire la migrazione o
- È presente un ambiente Netezza esistente con dati già in uno schema star o snowflake ben progettato oppure
- Si hanno pressioni in termini di tempo e costi per passare a un ambiente cloud moderno.
Suggerimento
L'approccio "lift and shift" è un buon punto di partenza, anche se le fasi successive implementano le modifiche al modello di dati.
Approccio in più fasi che incorpora le modifiche
Se un data warehouse legacy si è evoluto in un lungo periodo di tempo, potrebbe essere necessario riprogettarlo per mantenere i livelli di prestazioni necessari. Potrebbe anche essere necessario riprogettare per supportare nuovi dati, ad esempio flussi IoT (Internet delle cose). Come parte del processo di re-engineering, eseguire la migrazione ad Azure Synapse per ottenere i vantaggi di un ambiente cloud scalabile. La migrazione può includere anche una modifica nel modello di dati sottostante, ad esempio uno spostamento da un modello Inmon a un data vault.
Microsoft consiglia di spostare il modello di dati esistente così com'è in Azure e di sfruttare le prestazioni e la flessibilità dell'ambiente Azure per applicare le modifiche di nuova progettazione. In questo modo, è possibile usare le funzionalità di Azure per apportare le modifiche senza influire sul sistema di origine esistente.
Usare Azure Data Factory per implementare una migrazione basata sui metadati
È possibile automatizzare e orchestrare il processo di migrazione usando le funzionalità dell'ambiente Azure. Questo approccio riduce al minimo l'impatto sulle prestazioni nell'ambiente Netezza esistente, che potrebbe essere già vicino a raggiungere la capacità massima.
Azure Data Factory è un servizio di integrazione di dati basato sul cloud che consente di creare flussi di lavoro basati sui dati nel cloud che orchestrano e automatizzano lo spostamento e la trasformazione dei dati stessi. È possibile usare Data Factory per creare e pianificare flussi di lavoro basati sui dati (pipeline) che inseriscono dati da archivi dati diversi. Data Factory può elaborare e trasformare i dati usando servizi di calcolo, ad esempio Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics e Azure Machine Learning.
Quando si prevede di usare le funzionalità di Data Factory per gestire il processo di migrazione, creare metadati che elenchino tutte le tabelle di dati di cui eseguire la migrazione e la relativa posizione.
Differenze di progettazione tra Netezza e Azure Synapse
Come accennato in precedenza, esistono alcune differenze di base nell'approccio tra i database Netezza e Azure Synapse Analytics, che vengono illustrate di seguito.
Più database rispetto a un singolo database e schemi
L'ambiente Netezza spesso contiene più database separati. Ad esempio, potrebbero essere presenti database separati per: tabelle di inserimento dati e gestione temporanea, tabelle di core warehouse e data mart (talvolta definiti livello semantico). I processi di pipeline ETL o ELT possono implementare join tra database e spostare i dati tra i database separati.
Al contrario, l'ambiente Azure Synapse contiene un singolo database e usa schemi per separare le tabelle in gruppi separati logicamente. È consigliabile usare una serie di schemi all'interno del database di Azure Synapse di destinazione per simulare i database separati migrati dall'ambiente Netezza. Se si usano già schemi nell'ambiente Netezza, potrebbe essere necessario usare una nuova convenzione di denominazione per spostare le tabelle e le viste Netezza esistenti nel nuovo ambiente. Ad esempio, è possibile concatenare i nomi di tabella e schema Netezza esistenti nel nuovo nome della tabella Azure Synapse e quindi usare i nomi dello schema nel nuovo ambiente per mantenere i nomi originali dei database distinti. Se la denominazione del consolidamento dello schema presenta punti, Azure Synapse Spark potrebbe avere problemi. Sebbene sia possibile usare viste SQL sopra le tabelle sottostanti per gestire le strutture logiche, esistono potenziali svantaggi per questo approccio:
Le viste in Azure Synapse sono di sola lettura. È quindi necessario apportare eventuali aggiornamenti ai dati nelle tabelle di base sottostanti.
Potrebbero essere già presenti uno o più livelli di visualizzazioni e l'aggiunta di un ulteriore livello potrebbe influire sulle prestazioni e sul supporto perché le visualizzazioni annidate sono difficili da gestire in caso di problemi.
Suggerimento
Combinare più database in un database singolo all'interno di Azure Synapse e usare i nomi degli schemi per separare logicamente le tabelle.
Considerazioni sulle tabelle
Quando si esegue la migrazione di tabelle tra ambienti diversi, in genere vengono trasferiti solo i dati non elaborati e i metadati che li descrivono fisicamente. Altri elementi di database del sistema di origine, ad esempio gli indici, in genere non vengono trasferiti perché potrebbero non essere necessari o potrebbero essere implementati in modo diverso nel nuovo ambiente.
Le ottimizzazioni delle prestazioni nell'ambiente di origine, ad esempio gli indici, indicano dove è possibile aggiungere l'ottimizzazione delle prestazioni nel nuovo ambiente. Ad esempio, se le query nell'ambiente Netezza di origine usano spesso mappe di zona, ciò suggerisce che debba essere creato un indice non cluster all'interno di Azure Synapse. Altre tecniche di ottimizzazione delle prestazioni native, come ad esempio la replica di tabelle, possono essere più applicabili rispetto alla creazione diretta di indici equivalenti.
Suggerimento
Gli indici esistenti indicano candidati per l'indicizzazione nel warehouse migrato.
Tipi di oggetto di database Netezza non supportati
Le funzionalità specifiche di Netezza possono spesso essere sostituite dalle funzionalità di Azure Synapse. Tuttavia, alcuni oggetti di database Netezza non sono supportati direttamente in Azure Synapse. L'elenco seguente di oggetti di database Netezza non supportati descrive come ottenere una funzionalità equivalente in Azure Synapse.
Mappe di zona: in Netezza, le mappe di zona vengono create e gestite automaticamente per i tipi di colonna seguenti e vengono usate in fase di query per limitare la quantità di dati da analizzare:
-
INTEGERcolonne di lunghezza pari o inferiore a 8 byte. - Colonne temporali, ad esempio
DATE,TIMEeTIMESTAMP. - Colonne
CHAR, se fanno parte di una vista materializzata e sono menzionate nella clausolaORDER BY.
È possibile individuare le colonne con mappe di zona usando l'utilità
nz_zonemap, inclusa nel toolkit NZ. Azure Synapse non include mappe di zona, ma è possibile ottenere risultati analoghi usando altri tipi di indice definiti dall'utente e/o di partizionamento.-
Clustered base tables (CBT): in Netezza, le CBT vengono comunemente utilizzate per le tabelle dei fatti, che possono contenere miliardi di record. L'analisi di una tabella di grandi dimensioni richiede un tempo di elaborazione considerevole perché per ottenere i record pertinenti può essere necessaria una scansione di tabella completa. L'organizzazione dei record in tabelle cluster di base restrittive consente a Netezza di raggruppare i record in extent simili o identici. Il processo crea anche mappe di zona che migliorano le prestazioni riducendo la quantità di dati da analizzare.
In Azure Synapse, è possibile ottenere un risultato simile tramite il partizionamento e/o usando altri indici.
Viste materializzate: Netezza supporta le viste materializzate e consiglia di usare una o più viste materializzate per tabelle di grandi dimensioni con molte colonne se solo poche colonne vengono usate regolarmente nelle query. Le viste materializzate vengono aggiornate automaticamente dal sistema quando i dati nella tabella di base vengono aggiornati.
Azure Synapse supporta le viste materializzate, con la stessa funzionalità di Netezza.
Mappatura dei tipi di dati Netezza
La maggior parte dei tipi di dati Netezza ha un equivalente diretto in Azure Synapse. La tabella seguente illustra l'approccio consigliato per il mapping dei tipi di dati Netezza ad Azure Synapse.
| Tipo di dati Netezza | Tipo di dati di Azure Synapse |
|---|---|
| BIGINT | BIGINT |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CARATTERE VARIABILE(n) | VARCHAR(n) |
| CARATTERE(n) | CHAR(n) |
| DATA | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| PRECISIONE DOPPIA | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVALLO | I tipi di dati INTERVAL non sono attualmente supportati direttamente in Azure Synapse, ma possono essere calcolati usando funzioni temporali come DATEDIFF. |
| DENARO | DENARO |
| CARATTERE NAZIONALE VARIABILE(n) | NVARCHAR(n) |
| Carattere Nazionale(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| real | real |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | I tipi di dati spaziali, ad esempio ST_GEOMETRY, non sono attualmente supportati in Azure Synapse, ma i dati possono essere archiviati come VARCHAR o VARBINARY. |
| TEMPO | TEMPO |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| TIMESTAMP | DATETIME |
Suggerimento
Valutare il numero e i tipi di dati non supportati durante la fase di preparazione della migrazione.
I fornitori di terze parti offrono strumenti e servizi per automatizzare la migrazione, incluso il mapping dei tipi di dati. Se uno strumento ETL di terze parti è già in uso nell'ambiente Netezza, usarlo per implementare le trasformazioni dei dati necessarie.
Differenze di sintassi SQL DML
Esistono differenze di sintassi SQL DML tra Netezza SQL e Azure Synapse T-SQL. Tali differenze sono descritte in dettaglio in Ridurre al minimo i problemi di SQL per le migrazioni di Netezza.
STRPOS: in Netezza, la funzioneSTRPOSrestituisce la posizione di una substring all'interno di una stringa. La funzione equivalente in Azure Synapse èCHARINDEXcon l'ordine degli argomenti invertito. Ad esempio,SELECT STRPOS('abcdef','def')...in Netezza equivale aSELECT CHARINDEX('def','abcdef')...in Azure Synapse.AGE: Netezza supporta l'operatoreAGEper assegnare l'intervallo tra due valori temporali, come timestamp o date, ad esempio:SELECT AGE('23-03-1956','01-01-2019') FROM.... In Azure Synapse usareDATEDIFFper ottenere l'intervallo, ad esempioSELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM.... Prendere nota della sequenza di rappresentazione della data.NOW(): Netezza usaNOW()per rappresentareCURRENT_TIMESTAMPin Azure Synapse.
Funzioni, stored procedure e sequenze
Quando si esegue la migrazione di un data warehouse da un ambiente maturo come Netezza, è probabile che sia necessario eseguire la migrazione di elementi diversi da tabelle e viste semplici. Controllare se gli strumenti all'interno dell'ambiente Azure possono sostituire le funzionalità di funzioni, stored procedure e sequenze perché in genere è più efficiente usare gli strumenti predefiniti di Azure rispetto a ricodificarli per Azure Synapse.
Come parte della fase di preparazione, creare un inventario di oggetti di cui è necessario eseguire la migrazione, definire un metodo per gestirli e allocare risorse appropriate nel piano di migrazione.
I partner di integrazione dei dati offrono strumenti e servizi in grado di automatizzare la migrazione di funzioni, stored procedure e sequenze.
Le sezioni seguenti illustrano ulteriormente la migrazione di funzioni, stored procedure e sequenze.
Funzioni
Come per la maggior parte dei prodotti di database, Netezza supporta funzioni definite dall'utente e di sistema all'interno di un'implementazione SQL. Quando si esegue la migrazione di una piattaforma di database legacy ad Azure Synapse, è in genere possibile eseguire la migrazione di funzioni di sistema comuni senza modifiche. Alcune funzioni di sistema potrebbero avere una sintassi leggermente diversa, ma tutte le modifiche necessarie possono essere automatizzate.
Per le funzioni di sistema Netezza o le funzioni arbitrarie definite dall'utente che non hanno equivalenti in Azure Synapse, ricodificarle usando un linguaggio di ambiente di destinazione. Le funzioni di Netezza definite dall'utente vengono codificate in linguaggio nzlua o C++. Azure Synapse usa il linguaggio di programmazione Transact-SQL per implementare le funzioni definite dall'utente.
Procedure memorizzate
La maggior parte dei prodotti di database moderni supporta l'archiviazione delle procedure all'interno del database. Netezza offre il linguaggio NZPLSQL, basato su POSTGRES PL/pgSQL, a questo scopo. Una stored procedure contiene in genere istruzioni SQL e logica procedurale e restituisce dati o uno stato.
Azure Synapse supporta stored procedure con T-SQL, quindi è necessario codificare tutte le stored procedure sottoposte a migrazione in tale linguaggio.
Sequenze
In Netezza una sequenza è un oggetto di database denominato, creato tramite CREATE SEQUENCE. Una sequenza offre valori numerici univoci tramite il metodo NEXT VALUE FOR. È possibile usare i numeri univoci generati come valori di chiave surrogata per le chiavi primarie.
Azure Synapse non implementa CREATE SEQUENCE, ma è possibile implementare sequenze usando colonne IDENTITY o codice SQL che genera il numero di sequenza successivo in una serie.
Estrarre metadati e dati da un ambiente Netezza
Generazione DDL (Data Definition Language)
Lo standard SQL ANSI definisce la sintassi di base per i comandi DDL (Data Definition Language). Alcuni comandi DDL, ad esempio CREATE TABLE e CREATE VIEW, sono comuni sia a Netezza che ad Azure Synapse, ma sono stati estesi per offrire funzionalità specifiche dell'implementazione.
È possibile modificare gli script CREATE TABLE e CREATE VIEW di Netezza esistenti per ottenere definizioni equivalenti in Azure Synapse. A tale scopo, potrebbe essere necessario usare tipi di dati modificati e rimuovere o modificare clausole specifiche di Netezza, ad esempio ORGANIZE ON.
All'interno dell'ambiente Netezza, le tabelle del catalogo di sistema specificano la definizione di tabella e vista corrente. A differenza della documentazione gestita dall'utente, le informazioni sul catalogo di sistema sono sempre complete e sincronizzate con le definizioni di tabella correnti. Usando utilità come nz_ddl_table è possibile accedere alle informazioni del catalogo di sistema per generare istruzioni DDL CREATE TABLE che creano tabelle equivalenti in Azure Synapse.
È anche possibile usare strumenti di migrazione ed ETL di terze parti che elaborano le informazioni del catalogo di sistema per ottenere risultati simili.
Estrazione dei dati da Netezza
È possibile estrarre dati di tabella non elaborati dalle tabelle Netezza in file delimitati flat, ad esempio file CSV, usando utilità Netezza standard come nzsql e nzunload o tramite tabelle esterne. È quindi possibile comprimere i file delimitati flat usando gzip e caricare i file compressi in Archivio BLOB di Azure usando AzCopy o strumenti di trasporto dati di Azure come Azure Data Box.
Estrarre i dati della tabella nel modo più efficiente possibile. Usare l'approccio con tabelle esterne perché è il metodo di estrazione più veloce. Eseguire più estratti in parallelo per ottimizzare la velocità effettiva di estrazione dei dati. L'istruzione SQL seguente esegue un'estrazione di tabella esterna:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
Se è disponibile una larghezza di banda di rete sufficiente, è possibile estrarre i dati da un sistema Netezza locale direttamente in tabelle di Azure Synapse o in Archiviazione dati BLOB di Azure. A tale scopo, usare processi di Data Factory, la migrazione dei dati di terze parti o prodotti ETL.
Suggerimento
Usare le tabelle esterne Netezza per un'estrazione dei dati più efficiente.
I file di dati estratti devono contenere testo delimitato in formato CSV, ORC (Optimized Row Columnar) o Parquet.
Per altre informazioni sulla migrazione dei dati e dell'ETL da un ambiente Netezza, vedere Migrazione dei dati, ETL e caricamento per le migrazioni Netezza.
Consigli per le prestazioni delle migrazioni Netezza
L'obiettivo dell'ottimizzazione delle prestazioni è far sì che queste siano identiche o migliori dopo la migrazione ad Azure Synapse.
Analogie nei concetti relativi all'approccio di ottimizzazione delle prestazioni
Molti concetti di ottimizzazione delle prestazioni per i database Netezza sono veri anche per i database di Azure Synapse. Ad esempio:
Usare la distribuzione dei dati per collocare i dati da aggiungere allo stesso nodo di elaborazione.
Usare il tipo di dati più piccolo per una determinata colonna per risparmiare spazio di archiviazione e accelerare l'elaborazione delle query.
Assicurarsi che le colonne da unire abbiano lo stesso tipo di dati per ottimizzare l'elaborazione dei join e ridurre la necessità di trasformazioni di dati.
Per aiutare l'ottimizzatore a produrre il miglior piano di esecuzione, assicurati che le statistiche siano aggiornate.
Monitorare le prestazioni usando le funzionalità predefinite del database per assicurarsi che le risorse vengano usate in modo efficiente.
Suggerimento
Definire la priorità della familiarità con le opzioni di ottimizzazione in Azure Synapse all'inizio di una migrazione.
Differenze nell'approccio di ottimizzazione delle prestazioni
Questa sezione illustra le differenze di implementazione dell'ottimizzazione delle prestazioni di basso livello tra Netezza e Azure Synapse.
Opzioni di distribuzione dei dati
Per le prestazioni, Azure Synapse è stato progettato con l'architettura a più nodi e usa l'elaborazione parallela. Per ottimizzare le prestazioni delle tabelle, è possibile definire un'opzione di distribuzione dei dati nelle istruzioni CREATE TABLE usando DISTRIBUTION in Azure Synapse e DISTRIBUTE ON in Netezza.
A differenza di Netezza, Azure Synapse supporta i join locali tra una tabella di piccole dimensioni e una tabella di grandi dimensioni tramite la replica di tabelle di piccole dimensioni. Si consideri, ad esempio, una tabella di piccole dimensioni e una tabella dei fatti di grandi dimensioni all'interno di un modello di schema a stella. Azure Synapse può replicare la tabella delle dimensioni più piccole in tutti i nodi per garantire che il valore di qualsiasi chiave di join per la tabella di grandi dimensioni abbia una riga di dimensione corrispondente disponibile in locale. Il sovraccarico della replicazione di una tabella dimensionale è relativamente basso per una tabella di piccole dimensioni. Per le tabelle di grandi dimensioni, un approccio alla distribuzione hash è più appropriato. Per altre informazioni sulle opzioni di distribuzione dei dati, vedere Linee guida sulla progettazione per l'uso di tabelle replicate e Linee guida per la progettazione di tabelle distribuite.
Indicizzazione dei dati
Azure Synapse supporta diverse opzioni di indicizzazione definibili dall'utente con un'operazione e un utilizzo diversi rispetto alle mappe delle zone gestite dal sistema in Netezza. Per altre informazioni sulle diverse opzioni di indicizzazione in Azure Synapse, vedere Indici nelle tabelle del pool SQL dedicato.
Le mappe delle zone gestite dal sistema esistenti all'interno di un ambiente Netezza di origine offrono un'indicazione utile dell'utilizzo dei dati e delle colonne candidate per l'indicizzazione nell'ambiente Azure Synapse.
Partizionamento dei dati
In un data warehouse aziendale le tabelle dei fatti possono contenere miliardi di righe. Il partizionamento ottimizza le prestazioni di manutenzione e query di queste tabelle suddividendole in parti separate per ridurre la quantità di dati elaborati. In Azure Synapse l'istruzione CREATE TABLE definisce la specifica di partizionamento per una tabella.
È possibile usare un solo campo per tabella per il partizionamento. Spesso si tratta di un campo data perché molte query vengono filtrate in base a data o intervallo di date. È possibile modificare il partizionamento di una tabella dopo il caricamento iniziale usando l'istruzione CREATE TABLE AS (CTAS) per ricreare la tabella con una nuova distribuzione. Per una descrizione dettagliata del partizionamento in Azure Synapse, vedere Tabelle di partizionamento nel pool SQL dedicato.
Statistiche delle tabelle dati
È necessario assicurarsi che le statistiche sulle tabelle dati siano aggiornate includendo un passaggio di statistiche nei processi ETL/ELT.
PolyBase o COPY INTO per il caricamento dei dati
PolyBase supporta un caricamento efficiente di grandi quantità di dati in un data warehouse usando flussi di caricamento paralleli. Per altre informazioni, vedere Strategia di caricamento dei dati PolyBase.
COPY INTO supporta anche l'inserimento dati con velocità effettiva elevata e:
Recupero dei dati da tutti i file all'interno di una cartella e sottocartelle.
Recupero dei dati da più posizioni nello stesso account di archiviazione. È possibile specificare più posizioni usando percorsi delimitati da virgole.
Azure Data Lake Storage (ADLS) e Azure Blob Storage.
Formati di file CSV, PARQUET e ORC.
Gestione dei carichi di lavoro
L'esecuzione di carichi di lavoro misti può causare problemi di risorse nei sistemi sovraccarichi. Uno schema corretto di gestione del carico di lavoro comporta una gestione efficace delle risorse, ne assicura l'utilizzo altamente efficiente e massimizza il ritorno sugli investimenti. Classificazione del carico di lavoro, importanza del carico di lavoro e isolamento del carico di lavoro per dare maggiore controllo sul modo in cui il carico di lavoro usa le risorse di sistema.
La guida alla gestione del carico di lavoro descrive le tecniche per analizzare il carico di lavoro, gestire e monitorare l'importanza del carico di lavoro e i passaggi per convertire una classe di risorse in un gruppo di carico di lavoro. Usare il portale di Azure e le query T-SQL in DMV per monitorare il carico di lavoro e garantire che le risorse applicabili vengano usate in modo efficiente.
Passaggi successivi
Per informazioni su ETL e caricamento per la migrazione di Netezza, vedere l'articolo successivo di questa serie: Migrazione dei dati, ETL e caricamento per le migrazioni Netezza.