Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Nel mondo dei Big Data, dati non elaborati e non organizzati vengono spesso archiviati in sistemi di archiviazione relazionali, non relazionali e di altro tipo. I dati non elaborati non hanno tuttavia intrinsecamente un contesto o significato appropriato per generare informazioni utili per gli analisti, i data scientist e i responsabili delle decisioni aziendali.
I Big Data necessitano di un servizio che possa orchestrare e rendere operativi i processi per ottimizzare questi enormi archivi di dati non elaborati trasformandoli in informazioni aziendali di utilità pratica. Azure Data Factory è un servizio cloud gestito creato per questi complessi progetti ETL (Hybrid Extract-Transform-Load), extract-load-transform (ELT) e integrazione dei dati.
Funzionalità di Azure Data Factory
Compressione dei dati: durante l'attività di copia dei dati, è possibile comprimere i dati e scrivere i dati compressi nella fonte dati di destinazione. Questa funzionalità consente di ottimizzare l'utilizzo della larghezza di banda nella copia dei dati.
Supporto completo della connettività per origini dati diverse: Azure Data Factory offre un ampio supporto per la connettività per la connessione a origini dati diverse. Questa funzionalità è utile quando si desidera eseguire il pull o la scrittura di dati da origini dati diverse.
Trigger di eventi personalizzati: Azure Data Factory consente di automatizzare l'elaborazione dei dati usando trigger di eventi personalizzati. Questa funzionalità consente di eseguire automaticamente una determinata azione quando si verifica un evento specifico.
Anteprima e convalida dei dati: durante l'attività di copia dei dati vengono forniti strumenti per l'anteprima e la convalida dei dati. Questa funzionalità consente di assicurarsi che i dati vengano copiati e scritti correttamente nell'origine dati di destinazione.
Flussi di dati personalizzabili: Azure Data Factory consente di creare flussi di dati personalizzabili. Questa funzionalità consente di aggiungere azioni o passaggi personalizzati per l'elaborazione dei dati.
Sicurezza integrata: Azure Data Factory offre funzionalità di sicurezza integrate, ad esempio l'integrazione di Microsoft Entra ID e il controllo degli accessi in base al ruolo per controllare l'accesso ai flussi di dati. Questa funzionalità aumenta la sicurezza nell'elaborazione dei dati e protegge i dati.
Scenari di utilizzo
Si prenda ad esempio una società di giochi che raccoglie petabyte di log generati dai giochi nel cloud. La società intende analizzare questi log per ottenere informazioni sui clienti, tra cui preferenze, dati demografici e comportamento di utilizzo. Vuole anche identificare opportunità di up-selling e cross-selling, sviluppare nuove funzionalità interessanti per promuovere la crescita del business e fornire un'esperienza migliore ai clienti.
Per analizzare questi log, la società deve usare dati di riferimento presenti in un archivio dati locale, ad esempio le informazioni sui clienti, sui giochi e sulle campagne di marketing. L'azienda vuole usare questi dati dall'archivio dati locale, combinandoli con dati di log aggiuntivi presenti in un archivio dati cloud.
Per estrarre informazioni dettagliate, si spera di elaborare i dati aggiunti usando un cluster Spark nel cloud (Azure HDInsight) e pubblicare i dati trasformati in un data warehouse cloud, ad esempio Azure Synapse Analytics per creare facilmente un report. La società vuole automatizzare il flusso di lavoro e monitorarlo e gestirlo in una pianificazione giornaliera. Intende anche eseguirlo quando vengono aggiunti file a un contenitore dell'archivio BLOB.
Azure Data Factory è la piattaforma che risolve questi scenari di dati. Si tratta del servizio di integrazione dei dati e ETL basato sul cloud che consente di creare flussi di lavoro basati sui dati per orchestrare lo spostamento dei dati e trasformare i dati su larga scala. Usando Azure Data Factory, è possibile creare e pianificare flussi di lavoro basati sui dati (denominati pipeline) in grado di inserire dati da archivi dati diversi. È possibile creare processi ETL complessi che trasformano visivamente i dati con flussi di dati o usando servizi di calcolo come Azure HDInsight Hadoop, Azure Databricks e database SQL di Azure.
È anche possibile pubblicare i dati trasformati in archivi dati, ad esempio Azure Synapse Analytics per le applicazioni di Business Intelligence (BI) da utilizzare. In definitiva, tramite Azure Data Factory, i dati non elaborati possono essere organizzati in archivi dati significativi e data lake per decisioni aziendali migliori.
Come funziona?
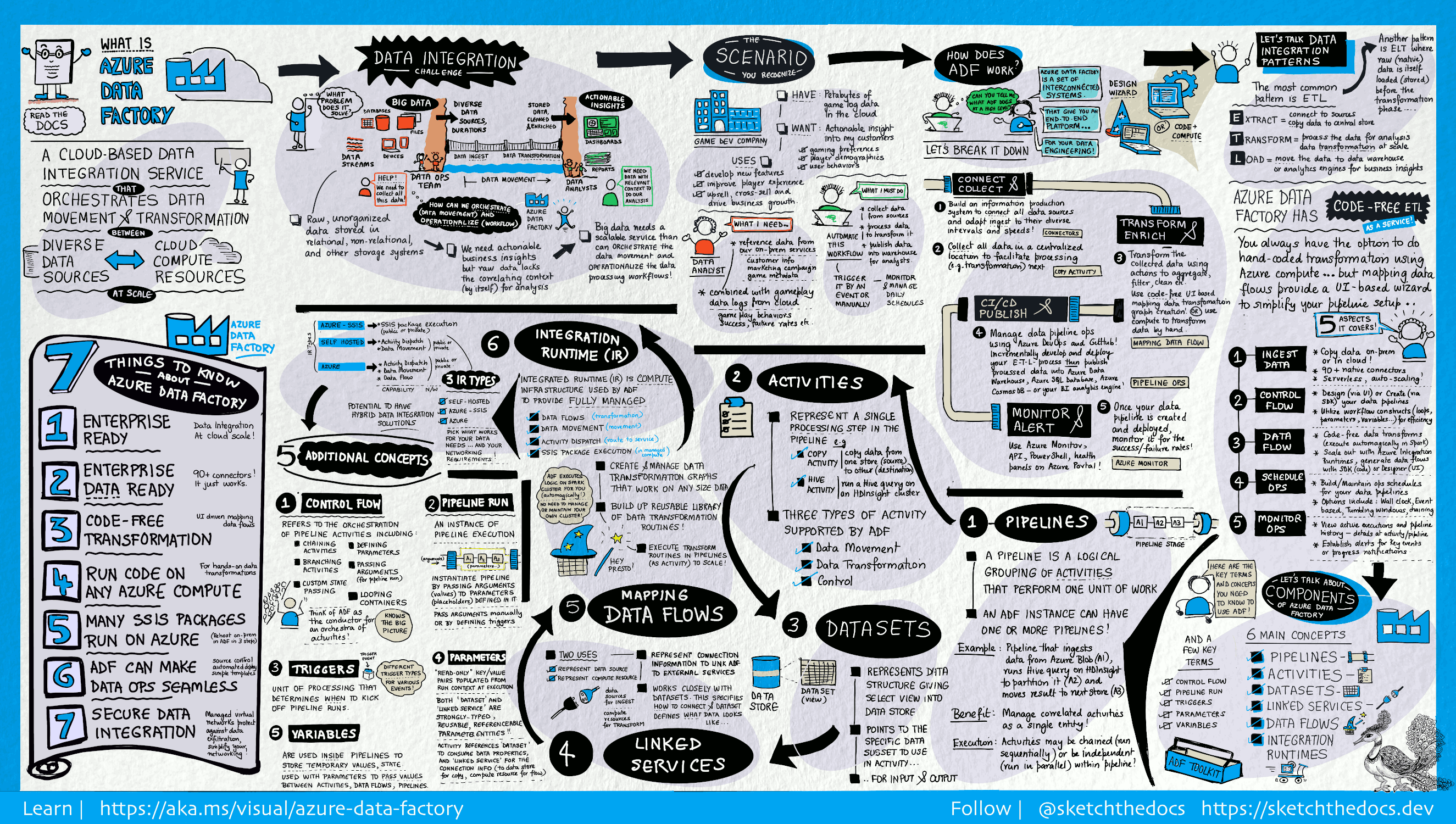
Data Factory contiene una serie di sistemi interconnessi che mettono a disposizione una piattaforma end-to-end completa per gli ingegneri dei dati.

Questa guida visiva offre una panoramica dettagliata dell'architettura completa di Data Factory:

Per visualizzare altri dettagli, selezionare l'immagine precedente per eseguire lo zoom avanti o passare all'immagine ad alta risoluzione. Informazioni sullo sviluppo di questa guida visiva e sul progetto Sketch the Docs.
{kind=link}
Connettersi e raccogliere
Le aziende hanno dati di vari tipi archiviati in origini disomogenee in locale e nel cloud; dati strutturati, non strutturati e semistrutturati vengono tutti ricevuti a velocità e a intervalli diversi.
Il primo passaggio per creare un sistema di produzione di informazioni consiste nel connettere tutte le origini di dati e di elaborazione necessarie, come servizi SaaS, database, condivisioni file, FTP e servizi Web. Il secondo passaggio prevede di spostare i dati in una posizione centralizzata in base alla necessità per l'elaborazione successiva.
Senza Data factory le grandi imprese devono creare componenti personalizzati per lo spostamento dei dati oppure scrivere servizi personalizzati per l'integrazione delle origini dati e delle elaborazioni. Integrare e gestire tali sistemi è costoso e complesso. Questi sistemi spesso non forniscono neppure il monitoraggio e gli avvisi di livello aziendale, oltre ai controlli che solo un servizio completamente gestito può offrire.
Con Data Factory è possibile usare l'attività di copia in una pipeline di dati per spostare i dati dagli archivi dati di origine sia in locale che nel cloud a un archivio dati centralizzato nel cloud per analisi aggiuntive. Ad esempio, è possibile raccogliere dati in Azure Data Lake Storage e trasformare i dati in un secondo momento usando servizi di calcolo come Azure Databricks o flussi di dati di mapping. È anche possibile raccogliere dati nell'archiviazione BLOB di Azure e trasformarli in un secondo momento usando un cluster Azure HDInsight Hadoop.
Trasformare e arricchire
Dopo che i dati sono presenti in un archivio dati centralizzato nel cloud, elaborare o trasformare i dati raccolti usando i flussi di dati di mapping di Azure Data Factory. I flussi di dati permettono agli ingegneri dei dati di creare e gestire grafici di trasformazione dei dati eseguiti in Spark senza la necessità di avere competenze in programmazione o cluster Spark.
Se si preferisce eseguire trasformazioni di codice a mano, Azure Data Factory supporta le attività esterne per l'esecuzione delle trasformazioni nei servizi di calcolo, ad esempio HDInsight Hadoop, Azure Databricks e Machine Learning.
CI/CD e pubblicazione
Data Factory offre supporto completo per CI/CD delle pipeline di dati usando Azure DevOps e GitHub. È quindi possibile sviluppare e distribuire in modo incrementale i processi ETL prima di pubblicare il prodotto finito. Dopo aver trasformato i dati grezzi in una forma fruibile e pronta per l'uso aziendale, caricate i dati in Azure Synapse Analytics, database SQL di Azure, Azure Cosmos DB o in qualsiasi motore di analisi a cui gli utenti aziendali possano accedere dai loro strumenti di business intelligence.
Monitorare
Dopo aver creato e distribuito la pipeline di integrazione dei dati, traendo valore aziendale dai dati elaborati, monitorare le attività pianificate e le pipeline per verificarne i tassi di successo e di errore. Azure Data Factory offre il supporto predefinito per il monitoraggio delle pipeline tramite Monitoraggio di Azure, API, PowerShell, log di Monitoraggio di Azure e pannelli di integrità nel portale di Azure.
Concetti principali
Una sottoscrizione a Azure potrebbe includere una o più istanze di Azure Data Factory (o fabbriche di dati). Azure Data Factory è costituito dai componenti chiave seguenti:
- Pipeline
- Attività
- Set di dati
- Servizi collegati
- Flussi di dati
- Runtime di integrazione
Questi componenti forniscono la piattaforma nella quale è possibile comporre flussi di lavoro basati sui dati con passaggi per lo spostamento e la trasformazione dei dati stessi.
Pipeline
Una fabbrica di dati può comprendere una o più pipeline. Una pipeline è un raggruppamento logico di attività che esegue un'unità di lavoro. L'insieme delle attività di una pipeline esegue un'operazione. Ad esempio, una pipeline può contenere un gruppo di attività che inserisce dati da un BLOB Azure e quindi esegue una query Hive in un cluster HDInsight per partizionare i dati.
La pipeline offre il vantaggio di poter gestire le attività come un set anziché singolarmente. Le attività in una pipeline possono essere concatenate per funzionare in modo sequenziale o indipendentemente in parallelo.
Mappatura dei flussi di dati
Creare e gestire grafici della logica di trasformazione dei dati che è possibile usare per trasformare i dati di qualsiasi dimensione. È possibile creare una libreria riutilizzabile di routine di trasformazione dei dati ed eseguire tali processi in modo con scalabilità orizzontale dalle pipeline di Azure Data Factory. Azure Data Factory esegue la logica in un cluster Spark che viene avviato e arrestato secondo necessità. Non dovrai mai gestire o mantenere i cluster.
Attività
Le attività rappresentano un passaggio di elaborazione in una pipeline. È ad esempio possibile usare un'attività di copia per copiare i dati da un archivio dati all'altro. Analogamente, è possibile usare un'attività Hive, che esegue una query Hive in un cluster Azure HDInsight, per trasformare o analizzare i dati. Data Factory supporta tre tipi di attività: attività di spostamento dei dati, attività di trasformazione dei dati e attività di controllo.
Set di dati
I set di dati rappresentano strutture di dati all'interno degli archivi dati, che puntano o fanno riferimento ai dati da usare nelle attività come input o output.
Servizi collegati
I servizi collegati sono molto simili a stringhe di connessione e definiscono le informazioni necessarie per la connessione di Data Factory a risorse esterne. In sintesi, un servizio collegato definisce la connessione all'origine dati, mentre un set di dati rappresenta la struttura dei dati. Ad esempio, un servizio collegato Archiviazione di Azure specifica un stringa di connessione per connettersi all'account Archiviazione di Azure. Inoltre, un set di dati BLOB Azure specifica il contenitore BLOB e la cartella che contiene i dati.
In Data factory i servizi collegati vengono usati per i due scopi seguenti:
Per rappresentare un archivio data che include, ad esempio, un database SQL Server, un database Oracle, una condivisione file o un account di archiviazione BLOB Azure. Per un elenco degli archivi dati supportati, vedere l'articolo sull'attività di copia.
Per rappresentare una risorsa di calcolo che può ospitare l'esecuzione di un'attività. Ad esempio, l'attività HDInsightHive viene eseguita in un cluster HDInsight Hadoop. Vedere l'articolo sulla trasformazione di dati per un elenco di attività di trasformazione e degli ambienti di calcolo supportati.
Runtime di Integrazione
In Data Factory, un'attività definisce l'azione da eseguire. Un servizio collegato definisce un archivio dati o un servizio di calcolo di destinazione. Un runtime di integrazione funge da ponte tra l'attività e i servizi collegati. Vi fa riferimento il servizio o l'attività collegata e fornisce l'ambiente di calcolo da cui l'attività viene eseguita o inviata. In questo modo, l'attività può essere eseguita nell'area più vicina possibile all'archivio dati o al servizio di calcolo di destinazione nel modo più efficiente soddisfacendo al contempo le esigenze di sicurezza e conformità.
Trigger
I trigger rappresentano l'unità di elaborazione che determina quando deve essere avviata l'esecuzione di una pipeline. Esistono diversi tipi di trigger per i diversi tipi di eventi.
Esecuzioni della pipeline
Un'esecuzione di pipeline è un'istanza dell'esecuzione della pipeline. Le istanze delle esecuzioni di pipeline vengono create in genere passando gli argomenti ai parametri definiti nelle pipeline. Gli argomenti possono essere passati manualmente o all'interno della definizione di trigger.
Parametri
I parametri sono coppie chiave-valore della configurazione di sola lettura. I parametri sono definiti nella pipeline. Gli argomenti per i parametri definiti vengono passati durante l'esecuzione dal contesto di esecuzione creato da un trigger o da una pipeline eseguita manualmente. Le attività all'interno della pipeline consumano i valori dei parametri.
Un set di dati è un parametro fortemente tipizzato e un'entità referenziabile/riutilizzabile. Un'attività può fare riferimento a set di dati e può usare le proprietà contenute nella definizione del set di dati.
Anche un servizio collegato è un parametro fortemente tipizzato contenente le informazioni di connessione a un archivio dati o a un ambiente di calcolo. È anche un'entità riutilizzabile/referenziabile.
Flusso di controllo
Il flusso di controllo è un'orchestrazione delle attività della pipeline che include il concatenamento di attività in una sequenza, la creazione di rami, la definizione di parametri a livello di pipeline e il passaggio di argomenti durante la chiamata della pipeline su richiesta o da un trigger. Include anche il passaggio di stati personalizzati e i contenitori di ciclo, vale a dire gli iteratori For-Each.
Variabili
Le variabili possono essere usate all'interno delle pipeline per archiviare valori temporanei e anche in combinazione con altri parametri per consentire il passaggio di valori tra pipeline, flussi di dati e altre attività.
Contenuto correlato
Ecco i documenti importanti da consultare per i passaggi successivi: