Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come creare una configurazione di Apache Spark per synapse Studio. È possibile gestire la configurazione di Apache Spark creata in modo standardizzato e quando si crea la definizione del processo Notebook o Apache Spark è possibile selezionare la configurazione di Apache Spark che si desidera usare con il pool di Apache Spark. Quando si seleziona questa voce, vengono visualizzati i dettagli della configurazione.
Creare una configurazione di Apache Spark
È possibile creare configurazioni personalizzate da punti di ingresso diversi, ad esempio dalla pagina di configurazione di Apache Spark di un pool di Spark esistente.
Creare configurazioni personalizzate nelle configurazioni di Apache Spark
Seguire questa procedura per creare una configurazione di Apache Spark in Synapse Studio.
Selezionare Gestisci>configurazioni di Apache Spark.
Selezionare Nuovo per creare una nuova configurazione di Apache Spark oppure selezionare Importa un file di .json locale nell'area di lavoro.
Dopo aver selezionato Nuovo pulsante, verrà aperta la nuova pagina di configurazione di Apache Spark.
In Nomeè possibile immettere il nome preferito e valido.
In Descrizioneè possibile immettere una descrizione.
In Annotazioni, è possibile aggiungere annotazioni facendo clic sul pulsante Nuovo; è anche possibile eliminare le annotazioni esistenti selezionando e facendo clic sul pulsante Elimina.
In Proprietà di configurazione, personalizzare la configurazione facendo clic sul pulsante Aggiungi per aggiungere proprietà. Se non si aggiunge una proprietà, Azure Synapse userà il valore predefinito, se applicabile.
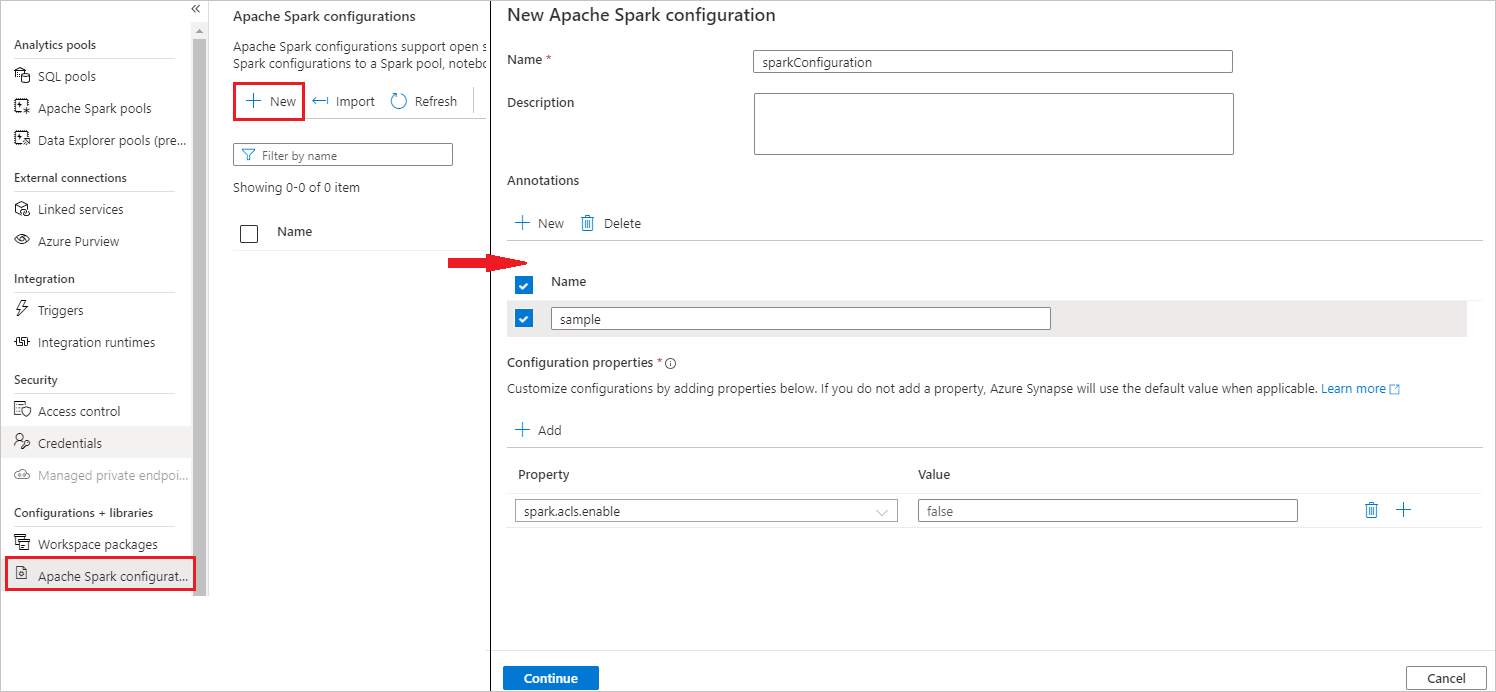
Selezionare il pulsante Continua .
Selezionare il pulsante Crea al termine della convalida.
Pubblica tutto.
Nota
La funzionalità di configurazione di Caricamento di Apache Spark è stata rimossa.
I pool che usano una configurazione caricata devono essere aggiornati. Aggiornare la configurazione del pool selezionando una configurazione esistente o creando una nuova configurazione nel menu di configurazione di Apache Spark per il pool. Se non è selezionata alcuna nuova configurazione, i processi per questi pool verranno eseguiti usando la configurazione predefinita nelle impostazioni del sistema Spark.
Creare una configurazione di Apache Spark nel pool di Apache Spark già esistente
Seguire questa procedura per creare una configurazione di Apache Spark in un pool di Apache Spark esistente.
Selezionare un pool di Apache Spark esistente e selezionare l'azione "..." bottone.
Selezionare la configurazione di Apache Spark nell'elenco dei contenuti.
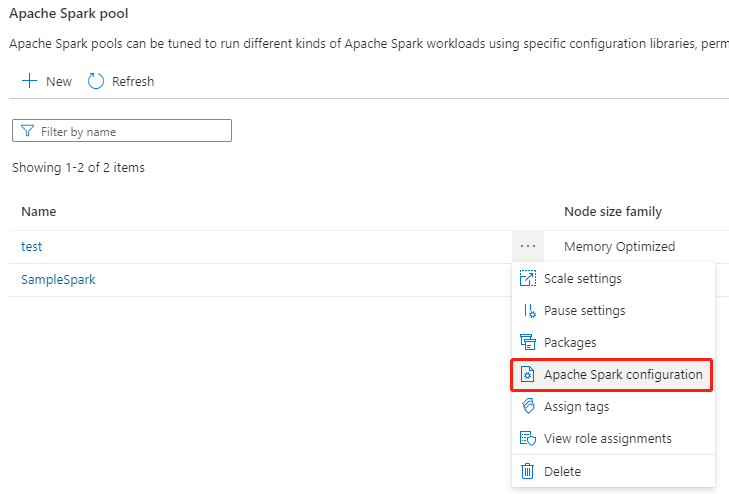
Per la configurazione di Apache Spark, è possibile selezionare una configurazione già creata dall'elenco a discesa oppure selezionare +Nuovo per creare una nuova configurazione.
Se si seleziona +Nuovo, verrà aperta la pagina Configurazione di Apache Spark ed è possibile creare una nuova configurazione seguendo la procedura descritta in Creare configurazioni personalizzate nelle configurazioni di Apache Spark.
Se si seleziona una configurazione esistente, i dettagli di configurazione verranno visualizzati nella parte inferiore della pagina, è anche possibile selezionare il pulsante Modifica per modificare la configurazione esistente.
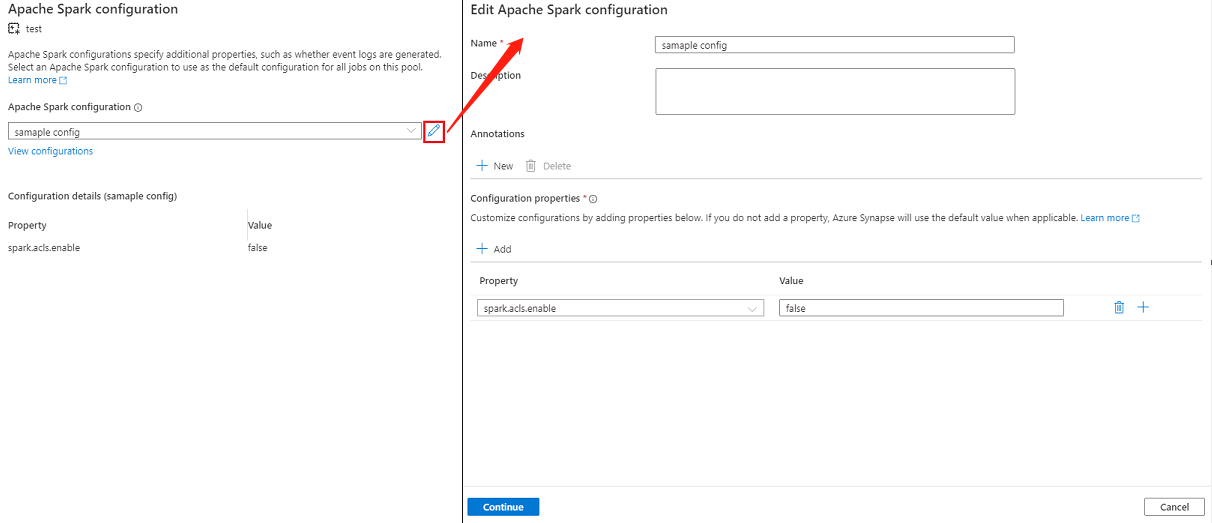
Selezionare Visualizza configurazioni per aprire la pagina Seleziona una configurazione . Tutte le configurazioni verranno visualizzate in questa pagina. È possibile selezionare una configurazione che si desidera usare in questo pool di Apache Spark.
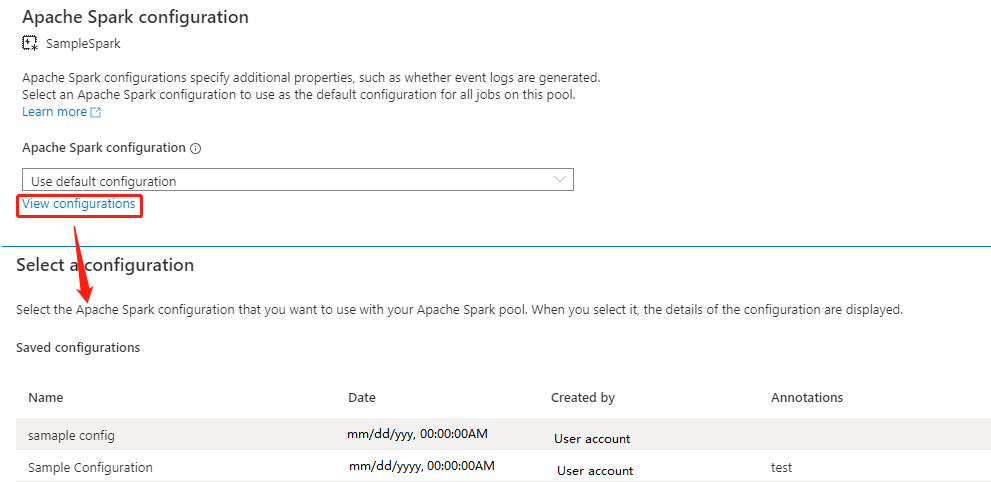
Selezionare il pulsante Applica per salvare l'azione.
Creare una configurazione di Apache Spark nella sessione di configurazione del notebook
Se è necessario usare una configurazione di Apache Spark personalizzata durante la creazione di un notebook, è possibile crearla e configurarla nella sessione di configurazione seguendo questa procedura.
Creare un notebook nuovo/Aprire un notebook esistente.
Aprire le proprietà di questo notebook.
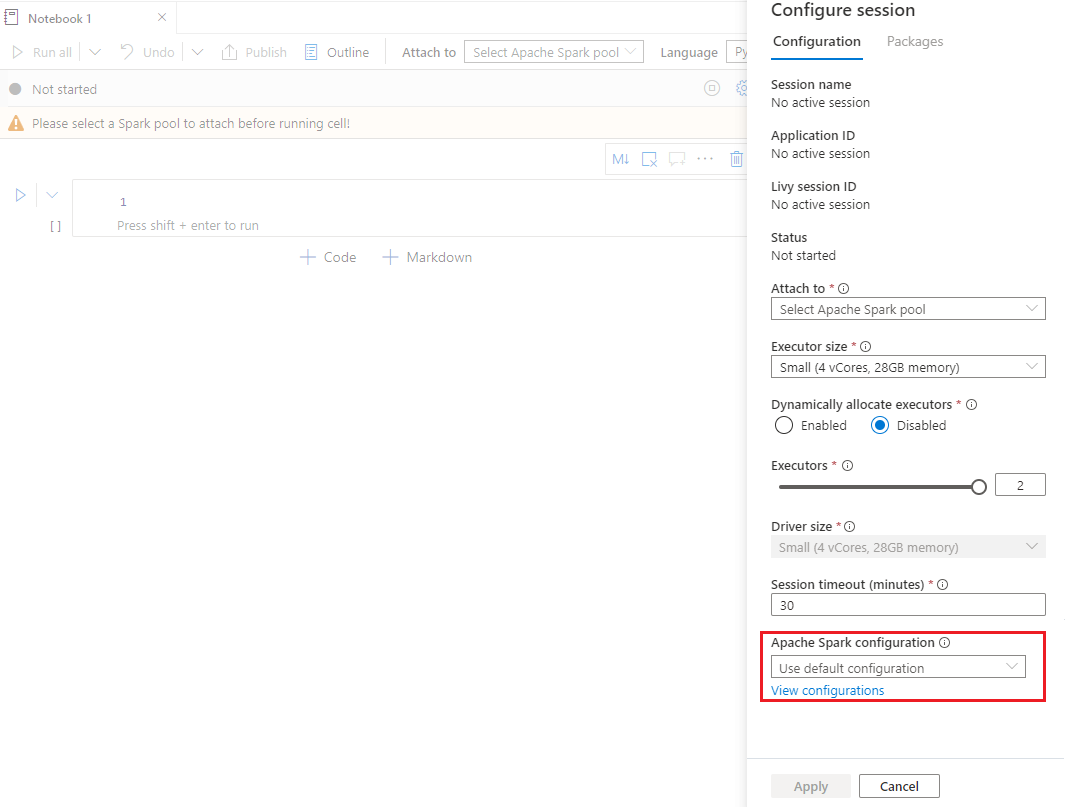
Selezionare Configura sessione per aprire la pagina Configura sessione.
Scorrere verso il basso la pagina configura sessione, per la configurazione di Apache Spark, espandere il menu a discesa. È possibile selezionare Nuovo pulsante per creare una nuova configurazione. In alternativa, selezionare una configurazione esistente, se si seleziona una configurazione esistente, selezionare l'icona Modifica per passare alla pagina Modifica configurazione di Apache Spark per modificare la configurazione.
Selezionare Visualizza configurazioni per aprire la pagina Seleziona una configurazione . Tutte le configurazioni verranno visualizzate in questa pagina. È possibile selezionare una configurazione da usare.
Creare una configurazione di Apache Spark nelle definizioni dei processi Apache Spark
Quando si crea una definizione di processo Spark, è necessario usare la configurazione di Apache Spark, che può essere creata seguendo questa procedura:
Creare una definizione di processo Apache Spark nuova/aperta esistente.
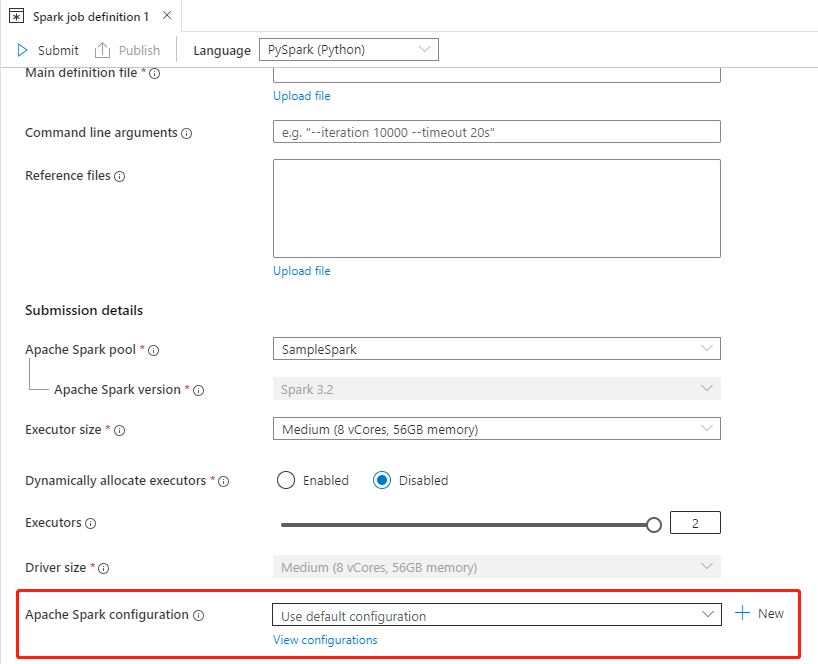
Per la configurazione di Apache Spark, è possibile selezionare il pulsante Nuovo per creare una nuova configurazione. In alternativa, selezionare una configurazione esistente nel menu a discesa, se si seleziona una configurazione esistente, selezionare l'icona Modifica per passare alla pagina Modifica configurazione di Apache Spark per modificare la configurazione.
Selezionare Visualizza configurazioni per aprire la pagina Seleziona una configurazione . Tutte le configurazioni verranno visualizzate in questa pagina. È possibile selezionare una configurazione da usare.
Nota
Se la configurazione di Apache Spark nel notebook e la definizione del processo Apache Spark di configurazione Apache Spark non esegue operazioni speciali, durante l'esecuzione del processo verrà usata la configurazione predefinita.
Importare ed esportare una configurazione di Apache Spark
È possibile importare una configurazione .txt/.conf/.json in tre formati e quindi convertirla in artefatto e pubblicarla. È anche possibile esportare in uno di questi tre formati.
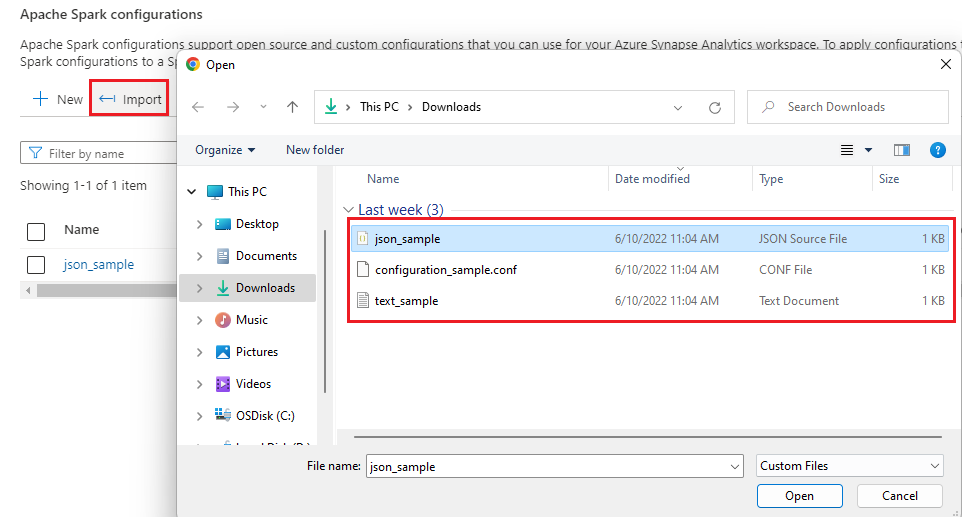
Importare la configurazione .txt/.conf/.json da locale.
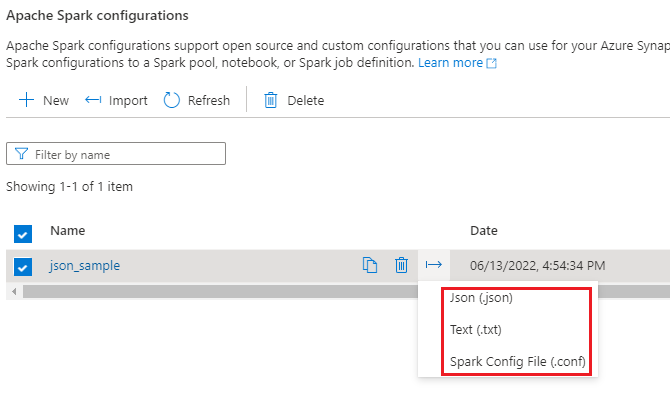
Esportare la configurazione .txt/.conf/.json in locale.
Per file di configurazione .txt e .conf, è possibile fare riferimento agli esempi seguenti:
spark.synapse.key1 sample
spark.synapse.key2 true
# spark.synapse.key3 sample2
Per file di configurazione .json, è possibile fare riferimento agli esempi seguenti:
{
"configs": {
"spark.synapse.key1": "hello world",
"spark.synapse.key2": "true"
},
"annotations": [
"Sample"
]
}
Nota
Synapse Studio continuerà a supportare i file di configurazione basati su terraform o bicep.