Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un notebook in Azure Synapse Analytics (notebook di Synapse) è un'interfaccia Web che consente di creare file che contengono codice, visualizzazioni e testo narrativo in tempo reale. I notebook possono essere usati per convalidare idee ed eseguire esperimenti rapidi per ottenere informazioni cognitive dettagliate dai dati. I notebook sono anche ampiamente usati per la preparazione e la visualizzazione dei dati, l'apprendimento automatico e altri scenari di Big Data.
Con un notebook di Synapse è possibile:
- Iniziare senza attività di configurazione.
- Aiutano a mantenere i dati protetti con le funzionalità di sicurezza aziendali predefinite.
- Analizzare i dati tra formati non elaborati (ad esempio CSV, TXT e JSON), formati di file elaborati (ad esempio Parquet, Delta Lake e ORC) e file di dati tabulari SQL in Spark e SQL.
- Ottenere produttività con funzionalità avanzate di creazione e visualizzazione dei dati predefinite.
Questo articolo descrive come usare i notebook in Synapse Studio.
Creare un notebook
È possibile creare un nuovo notebook o importarne uno esistente in un'area di lavoro di Azure Synapse da Esplora oggetti. Selezionare il menu Sviluppo. Selezionare il pulsante +, quindi selezionare Notebook oppure fare clic con il pulsante destro del mouse su Notebook e quindi selezionare Nuovo notebook o Importa. I notebook di Synapse riconoscono i file IPYNB di Jupyter Notebook standard.
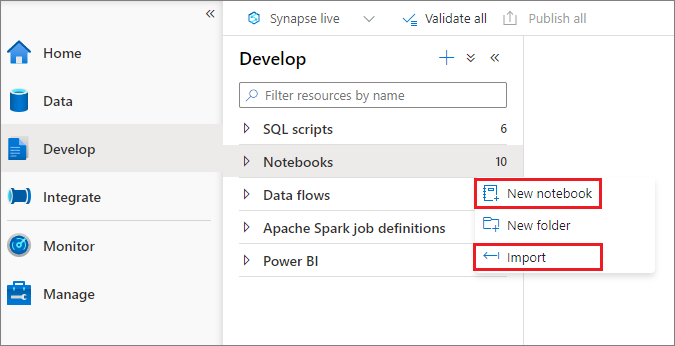
Sviluppare i notebook
I notebook sono costituiti da celle, che sono singoli blocchi di codice o testo che è possibile eseguire in modo indipendente o come gruppo.
Le sezioni seguenti descrivono le operazioni per lo sviluppo di notebook:
- Aggiungere una cella
- Impostare il linguaggio primario
- Usare più linguaggi
- Usare tabelle temporanee per fare riferimento ai dati in più lingue
- Usare IntelliSense in stile IDE
- Usare frammenti di codice
- Formattare le celle di testo usando i pulsanti della barra degli strumenti
- Annullare o ripetere un'operazione di cella
- Aggiungere un commento a una cella di codice
- Spostare una cella
- Copiare una cella
- Eliminare una cella
- Comprimere l'input di una cella
- Comprimere l'output di una cella
- Usare una struttura a notebook
Nota
Nei notebook viene creata automaticamente un'istanza SparkSession, che viene archiviata in una variabile denominata spark. È disponibile anche una variabile per SparkContext denominata sc. Gli utenti possono accedere direttamente a queste variabili, ma non devono modificarne i valori.
Aggiungere una cella
Esistono diversi modi per aggiungere una nuova cella al notebook:
Passare con il mouse sullo spazio tra due celle e selezionare Codice o Markdown.
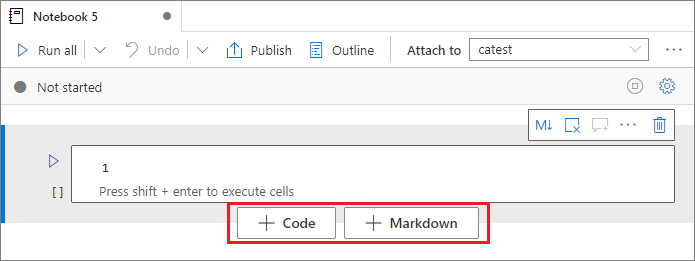
Usare tasti di scelta rapida in modalità comando. Selezionare il tasto A per inserire una cella sopra la cella corrente. Selezionare il tasto B per inserire una cella sotto la cella corrente.
Impostare il linguaggio primario
I notebook di Synapse supportano quattro linguaggi Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
È possibile impostare il linguaggio primario per le celle appena aggiunte dall'elenco a discesa Linguaggio sulla barra dei comandi superiore.
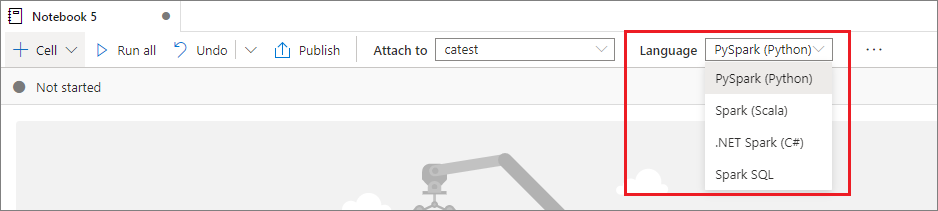
Usare più linguaggi
È possibile usare più linguaggi in un notebook specificando il comando magic corretto per il linguaggio all'inizio di una cella. Nella tabella seguente sono elencati i comandi magic per passare da un linguaggio all'altro nelle celle.
| Comando magic | Lingua | Descrizione |
|---|---|---|
%%pyspark |
Python | Eseguire una query Python su SparkContext. |
%%spark |
Scala | Eseguire una query Scala su SparkContext. |
%%sql |
Spark SQL | Eseguire una query Spark SQL su SparkContext. |
%%csharp |
.NET per Spark C# | Eseguire una query .NET per Spark C# su SparkContext. |
%%sparkr |
R | Eseguire una query R su SparkContext. |
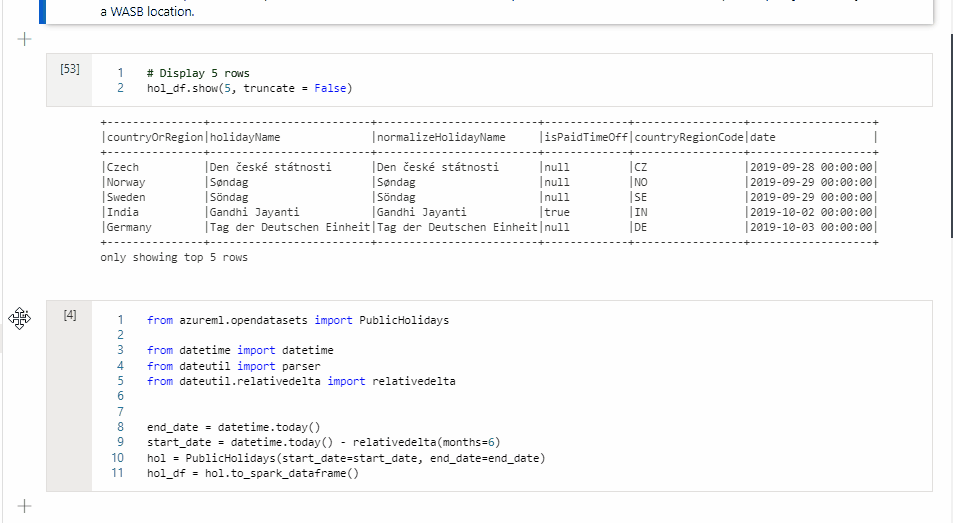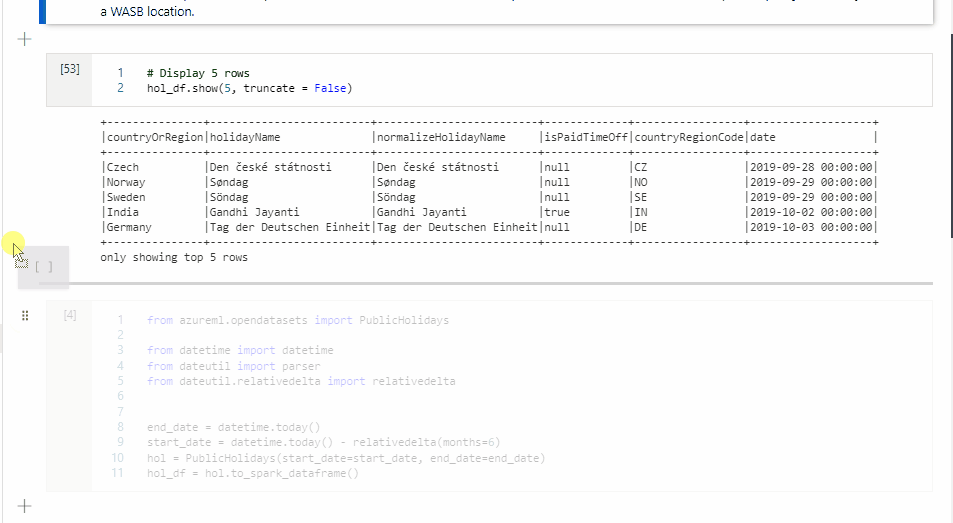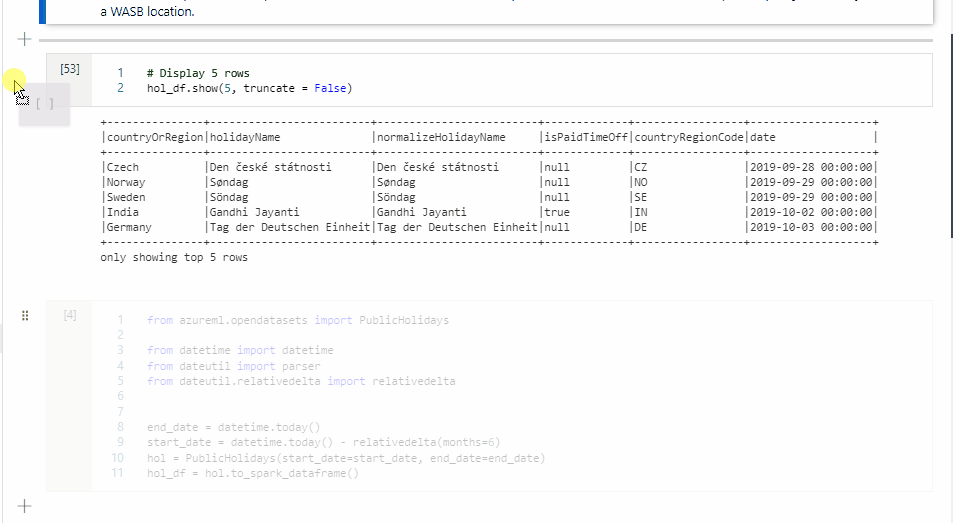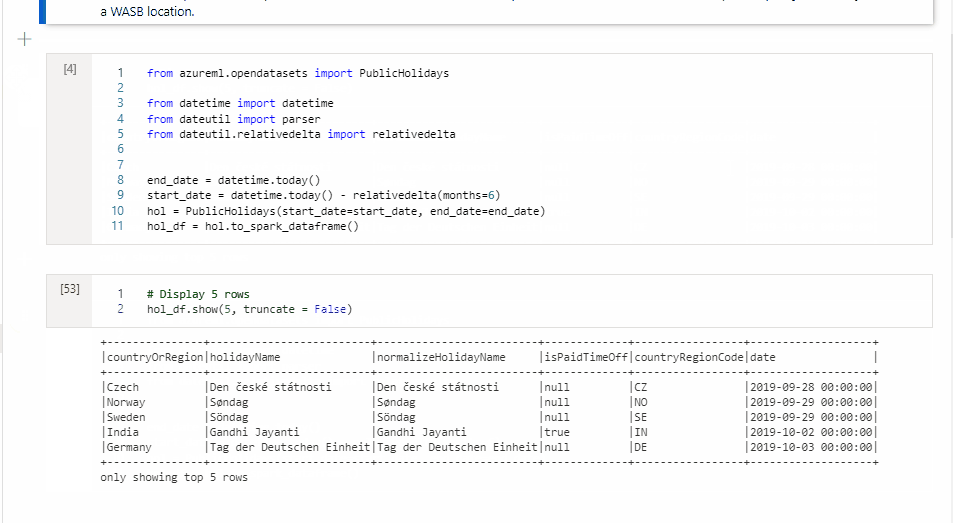
L'immagine seguente illustra un esempio di come scrivere una query PySpark usando il comando magic %%pyspark o una query Spark SQL usando il comando magic %%sql in un notebook Spark (Scala). Il linguaggio primario per il notebook è impostato su PySpark.

Usare tabelle temporanee per fare riferimento ai dati in più linguaggi
Non è possibile fare riferimento a dati o variabili direttamente tra linguaggi diversi in un notebook di Synapse. In Spark è possibile fare riferimento a una tabella temporanea in più linguaggi. Ecco un esempio di come leggere un dataframe Scala in PySpark e Spark SQL usando una tabella temporanea Spark come soluzione alternativa:
Nella cella 1 leggere un DataFrame da un connettore del pool SQL usando Scala e creare una tabella temporanea:
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )Nella cella 2 eseguire una query sui dati usando Spark SQL:
%%sql SELECT * FROM mydataframetableNella cella 3 usare i dati in PySpark:
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
Usare IntelliSense in stile IDE
I notebook di Synapse sono integrati nell'editor Monaco e consentono di aggiungere la funzionalità IntelliSense di tipo IDE all'editor di celle. Le funzionalità di evidenziazione della sintassi, l'indicatore di errore e il completamento automatico del codice consentono di scrivere codice e identificare i problemi più velocemente.
Le funzionalità di IntelliSense hanno livelli di maturità diversi per i diversi linguaggi. Usare la tabella seguente per sapere cosa è supportato.
| Lingue | Evidenziazione della sintassi | Generatore di errori di sintassi | Completamento del codice della sintassi | Completamento del codice della variabile | Completamento del codice della funzione di sistema | Completamento del codice della funzione utente | Rientro automatico | Riduzione del codice |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| Spark (Scala) | Sì | Sì | Sì | Sì | Sì | Sì | No | Sì |
| Spark SQL | Sì | Sì | Sì | Sì | Sì | No | No | No |
| .NET per Spark (C#) | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
È necessaria una sessione Spark attiva per trarre vantaggio dal completamento del codice variabile, dal completamento del codice della funzione di sistema e dal completamento del codice della funzione utente per .NET per Spark (C#).
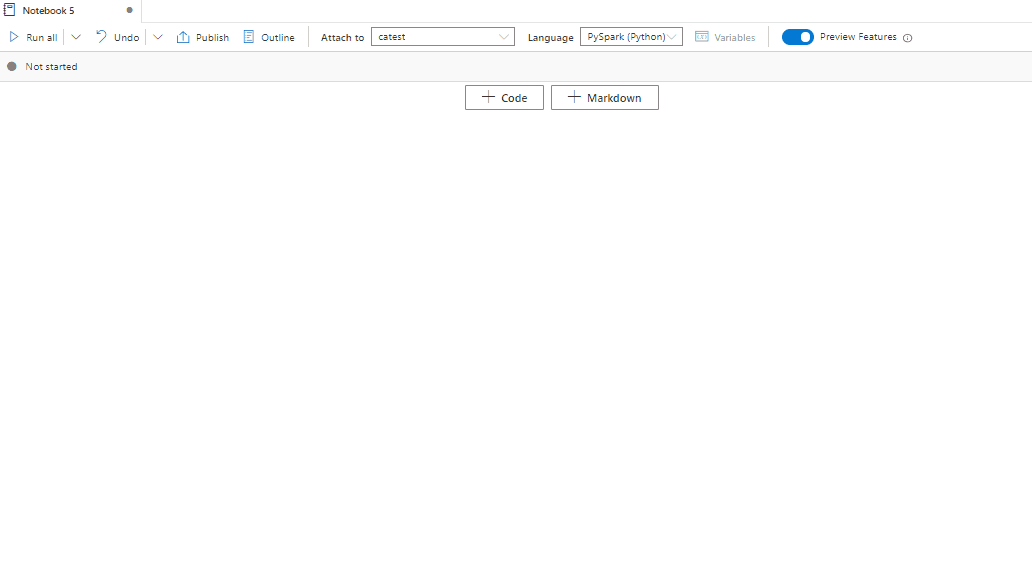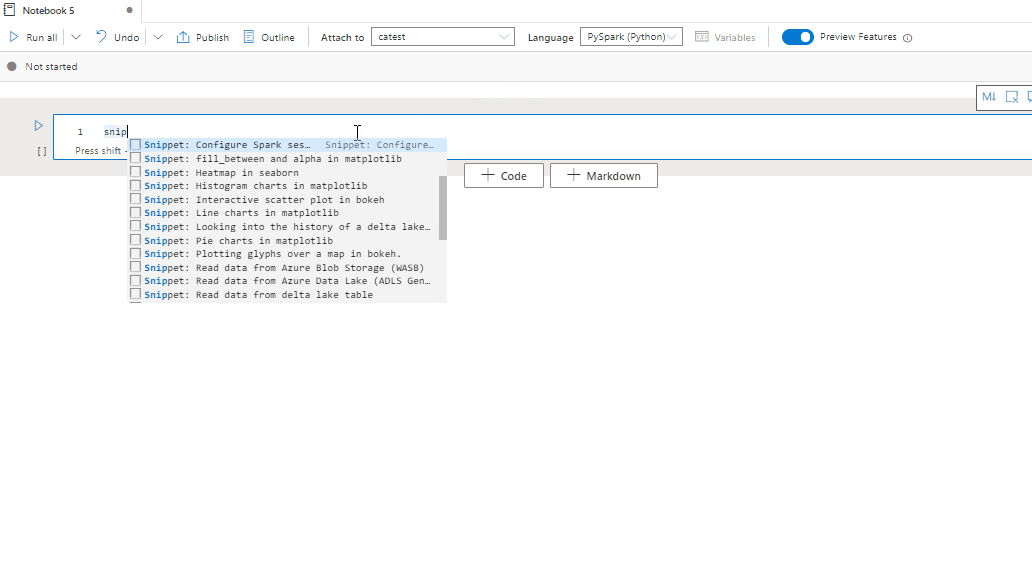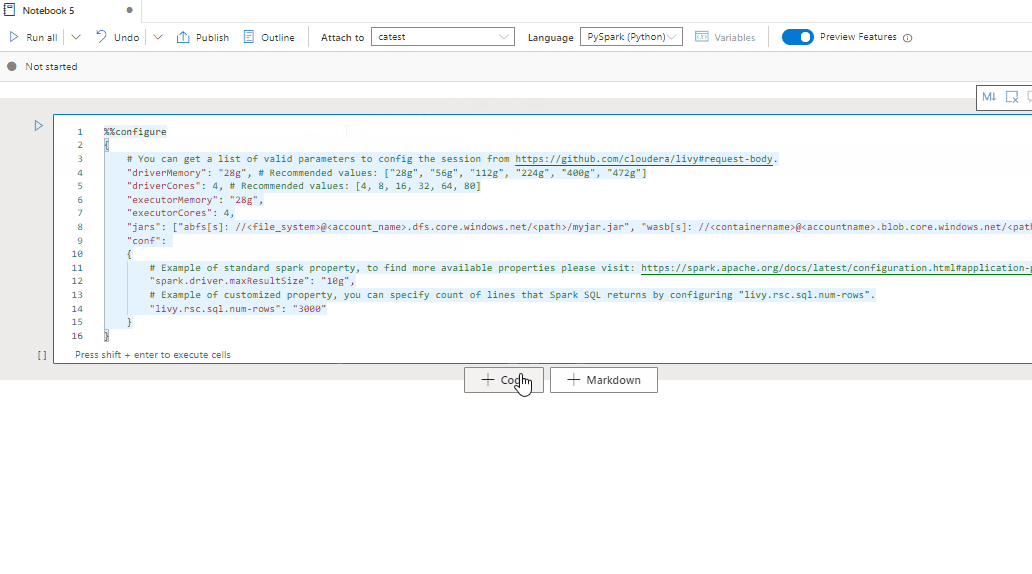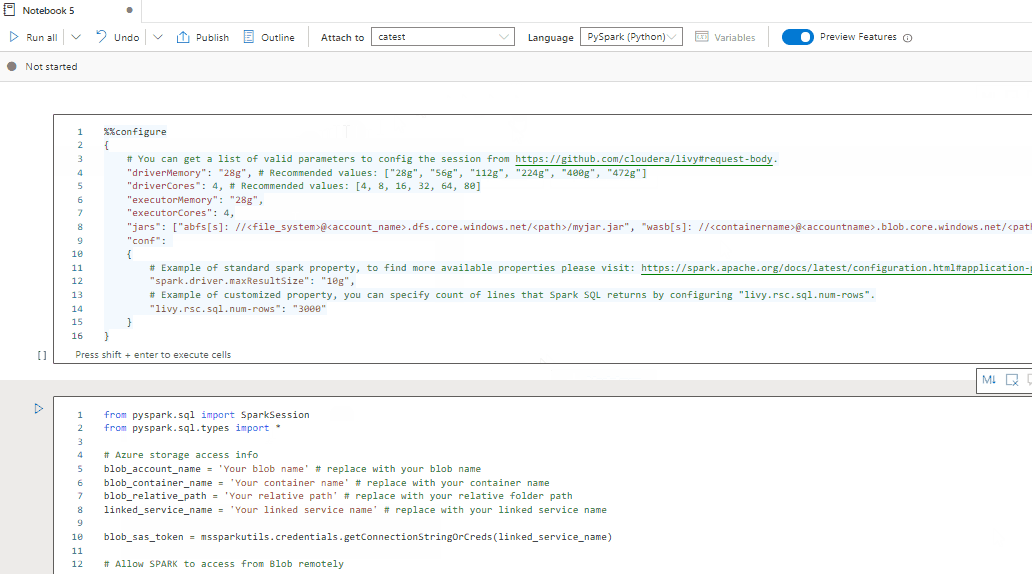
Usare frammenti di codice
I notebook di Synapse forniscono frammenti di codice che semplificano l'immissione di modelli di codice usati comunemente. Questi modelli includono la configurazione della sessione Spark, la lettura dei dati come dataframe Spark e i grafici di disegno usando Matplotlib.
I frammenti di codice vengono visualizzati nei tasti di scelta rapida di IntelliSense di stile IDE in combinazione con altri suggerimenti. Il contenuto dei frammenti di codice è allineato al linguaggio della cella del codice. È possibile visualizzare frammenti di codice disponibili immettendo un frammento di codice o qualsiasi parola chiave visualizzata nel titolo del frammento nell'editor di celle del codice. Ad esempio, immettendo read, è possibile visualizzare l'elenco dei frammenti di codice per leggere i dati da varie origini dati.
Formattare le celle di testo usando i pulsanti della barra degli strumenti
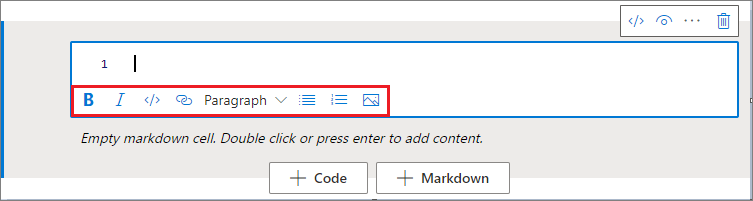
È possibile usare i pulsanti di formato sulla barra degli strumenti della cella di testo per eseguire azioni Markdown comuni. Queste azioni includono la creazione di testo in grassetto, la creazione di paragrafi e intestazioni tramite un menu a discesa, l'inserimento di codice, l'inserimento di un elenco non ordinato, l'inserimento di un elenco ordinato, l'inserimento di un collegamento ipertestuale e l'inserimento di un'immagine da un URL.
Annullare o ripetere un'operazione di cella
Per revocare le operazioni di cella più recenti, selezionare il pulsante Annulla o Ripeti oppure selezionare il tasto Z o MAIUSC+Z. È ora possibile annullare o ripetere fino a 10 operazioni cronologiche delle celle.

Le operazioni di cella supportate includono:
- Inserire o eliminare una cella. È possibile revocare le operazioni di eliminazione selezionando Annulla. Questa azione mantiene il contenuto del testo insieme alla cella.
- Riordinare una cella.
- Attivare o disattivare una cella di parametri.
- Eseguire la conversione tra una cella di codice e una cella Markdown.
Nota
Non è possibile annullare operazioni di testo o di commento in una cella.
Aggiungere un commento a una cella di codice
Selezionare il pulsante Commenti sulla barra degli strumenti del notebook per aprire il riquadro Commenti.
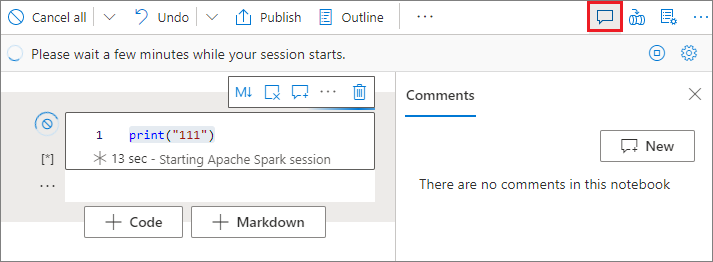
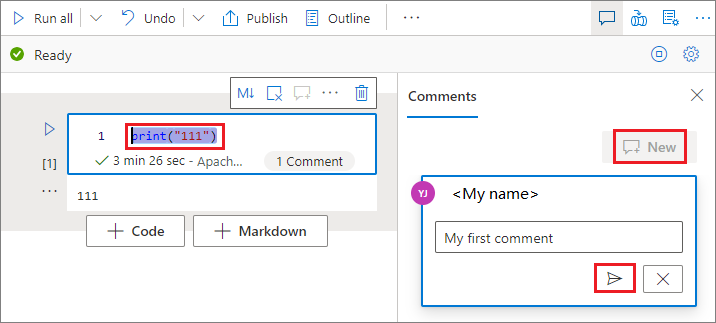
Selezionare il codice nella cella di codice, selezionare Nuovo nel riquadro Commenti, aggiungere commenti e quindi selezionare il pulsante Pubblica commento.
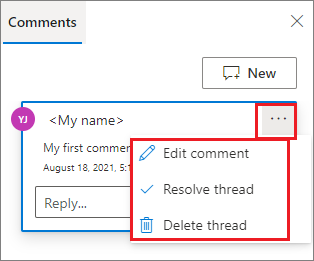
Se necessario, è possibile eseguire le azioni Modifica commento, Risolvi thread ed Elimina thread selezionando i puntini di sospensione Altro (...) accanto al commento.
Spostare una cella
Per spostare una cella, selezionare il lato sinistro della cella e trascinarla nella posizione desiderata.
Copiare una cella
Per copiare una cella, creare prima di tutto una nuova cella, quindi selezionare tutto il testo nella cella originale, copiarlo e incollarlo nella nuova cella. Quando la cella è in modalità di modifica, i tasti di scelta rapida tradizionali per selezionare tutto il testo sono limitati alla cella.
Suggerimento
I notebook di Synapse forniscono anche frammenti di codice di modelli di codice di uso comune.
Eliminare una cella
Per eliminare una cella, selezionare il pulsante Elimina a destra della cella.
È anche possibile usare tasti di scelta rapida in modalità comando. Selezionare MAIUSC+D per eliminare la cella corrente.
Comprimere l'input di una cella
Per comprimere l'input della cella corrente, selezionare i puntini di sospensione Altri comandi (...) sulla barra degli strumenti della cella e quindi selezionare Nascondi input. Per espandere l'input, selezionare Mostra input mentre la cella è compressa.
Comprimere l'output di una cella
Per comprimere l'output della cella corrente, selezionare i puntini di sospensione Altri comandi (...) sulla barra degli strumenti della cella e quindi selezionare Nascondi output. Per espandere l'output, selezionare Mostra output mentre l'output della cella è nascosto.
Usare la struttura di un notebook
La struttura (sommario) presenta la prima intestazione Markdown di qualsiasi cella Markdown in una finestra della barra laterale, ai fini della navigazione rapida. La barra laterale della struttura è ridimensionabile e comprimibile per adattarsi allo schermo nel modo migliore possibile. Per aprire o nascondere la barra laterale, selezionare il pulsante Struttura sulla barra dei comandi del notebook.
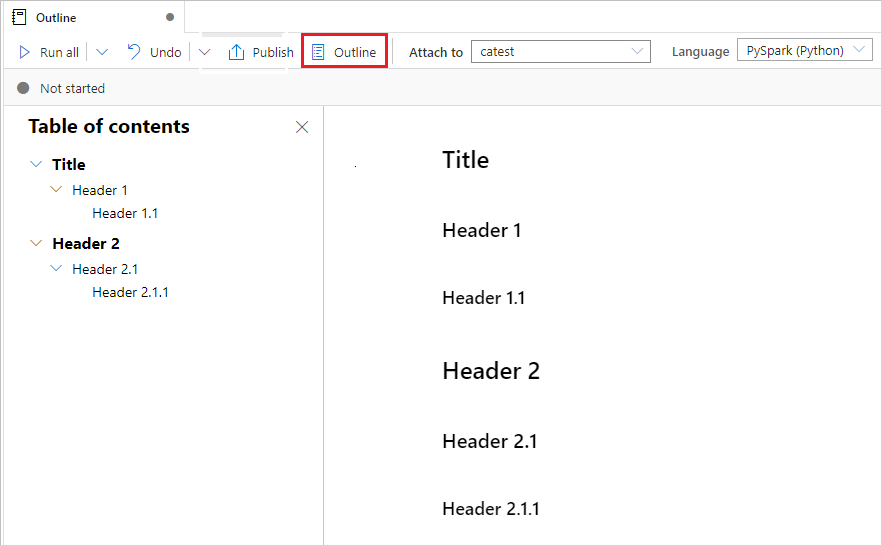
Eseguire un notebook
È possibile eseguire le celle di codice nel notebook singolarmente o tutte insieme. Lo stato e l'avanzamento di ogni cella sono visualizzati nel notebook.
Nota
L'eliminazione di un notebook non annulla automaticamente i processi attualmente in esecuzione. Se è necessario annullare un processo, passare all'hub Monitoraggio e annullarlo manualmente.
Eseguire una cella
Esistono diversi modi per eseguire il codice in una cella:
Passare il puntatore del mouse sulla cella da eseguire e quindi selezionare il pulsante Esegui cella oppure CTRL+INVIO.

Usare tasti di scelta rapida in modalità comando. Selezionare MAIUSC+INVIO per eseguire la cella corrente e selezionare la cella sottostante. Selezionare ALT+INVIO per eseguire la cella corrente e inserire una nuova cella sotto di essa.
Eseguire tutte le celle
Per eseguire tutte le celle del notebook corrente in sequenza, selezionare il pulsante Esegui tutto.

Eseguire tutte le celle al di sopra o al di sotto
Per eseguire tutte le celle sopra la cella corrente in sequenza, espandere l'elenco a discesa per il pulsante Esegui tutto e quindi selezionare Esegui celle precedenti. Selezionare Esegui celle seguenti per eseguire tutte le celle sotto quella corrente in sequenza.

Annulla tutte le celle in esecuzione
Per annullare le celle in esecuzione o le celle in attesa nella coda, selezionare il pulsante Annulla tutto.

Fare riferimento a un notebook
Per fare riferimento a un altro notebook all'interno del contesto del notebook corrente, usare il comando magic %run <notebook path>. Tutte le variabili definite nel notebook di riferimento sono disponibili nel notebook corrente.
Ecco un esempio:
%run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
Il riferimento al notebook funziona sia in modalità interattiva che in pipeline.
Il comando magic %run presenta queste limitazioni:
- Il comando supporta chiamate annidate ma non chiamate ricorsive.
- Il comando supporta il passaggio di un percorso assoluto o un nome di notebook solo come parametro. Non supporta i percorsi relativi.
- Il comando supporta attualmente solo quattro tipi di valore di parametro:
int,float,boolestring. Non supporta le operazioni di sostituzione delle variabili. - I notebook a cui si fa riferimento devono essere pubblicati. È necessario pubblicare i notebook per farvi riferimento, a meno che non si selezioni l'opzione per abilitare un riferimento a un notebook non pubblicato. Synapse Studio non riconosce i notebook non pubblicati dal repository Git.
- I notebook a cui si fa riferimento non supportano profondità delle istruzioni superiori a cinque.
Usare Esplora variabili
Un notebook di Synapse fornisce un'esplorazione delle variabili predefinita sotto forma di tabella che elenca le variabili nella sessione Spark corrente per le celle PySpark (Python). La tabella include colonne per nome variabile, tipo, lunghezza e valore. Altre variabili vengono visualizzate automaticamente man mano che vengono definite nelle celle di codice. La selezione di ogni intestazione di colonna ordina le variabili nella tabella.
Per aprire o nascondere Esplora variabili, selezionare il pulsante Variabili sulla barra dei comandi del notebook.
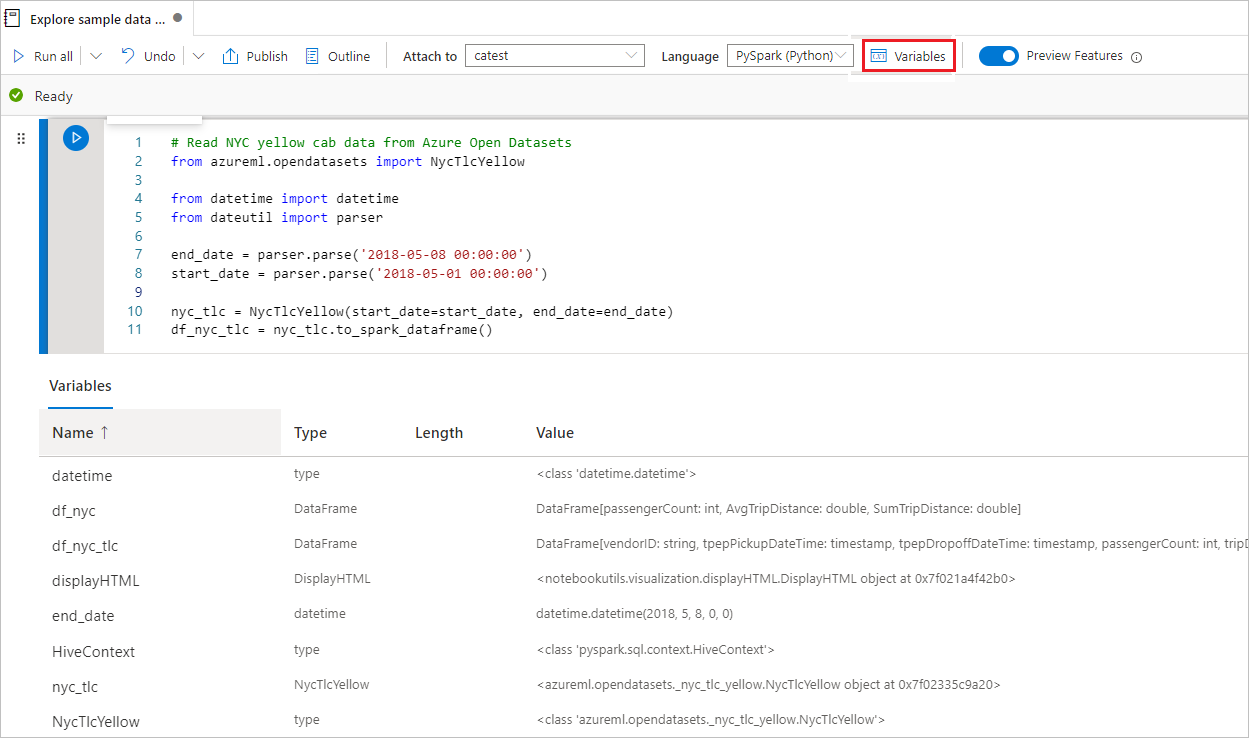
Nota
Esplora variabili supporta solo Python.
Usare l'indicatore di stato della cella
Sotto la cella viene visualizzato lo stato dettagliato di un'esecuzione di cella per visualizzarne lo stato corrente. Al termine dell'esecuzione della cella, viene visualizzato un riepilogo con la durata totale e l'ora di fine e rimane per riferimento futuro.

Usare l'indicatore di stato Spark
Il notebook di Synapse è puramente basato su Spark. Le celle di codice vengono eseguite nel pool di Apache Spark serverless in modalità remota. Un indicatore di stato del processo Spark con una barra di stato in tempo reale consente di comprendere lo stato di esecuzione del processo.
Il numero di attività per ogni processo o fase consente di identificare il livello parallelo del processo Spark. È anche possibile eseguire un'analisi più approfondita dell'interfaccia utente Spark di uno specifico processo (o fase) selezionando il collegamento nel nome del processo (o della fase).
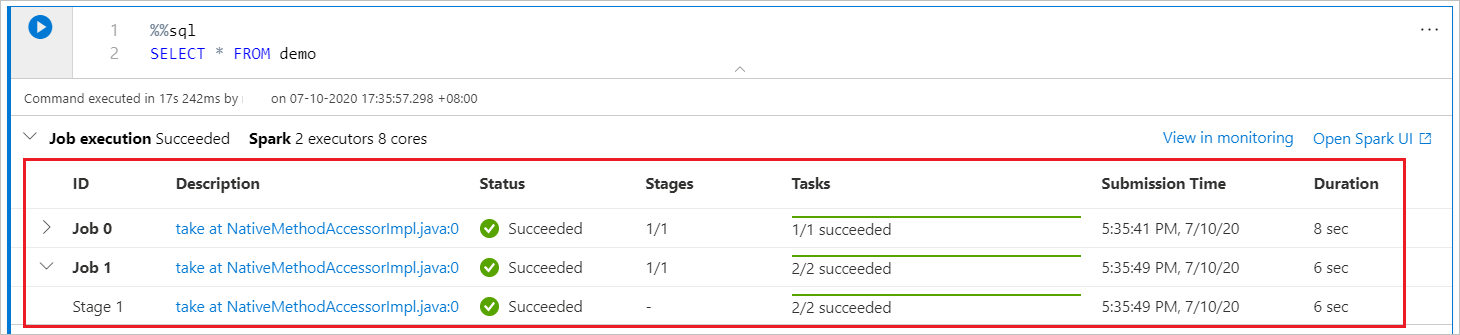
Configurare una sessione Spark
Nel riquadro Configura sessione, che è possibile trovare selezionando l'icona a forma di ingranaggio nella parte superiore del notebook, è possibile specificare la durata del timeout, il numero di executor e le dimensioni degli executor da assegnare alla sessione Spark corrente. Riavviare la sessione Spark per rendere effettive le modifiche alla configurazione. Tutte le variabili del notebook memorizzate nella cache vengono cancellate.
È anche possibile creare una configurazione dalla configurazione di Apache Spark o selezionare una configurazione esistente. Per informazioni dettagliate, vedere Gestire la configurazione di Apache Spark.
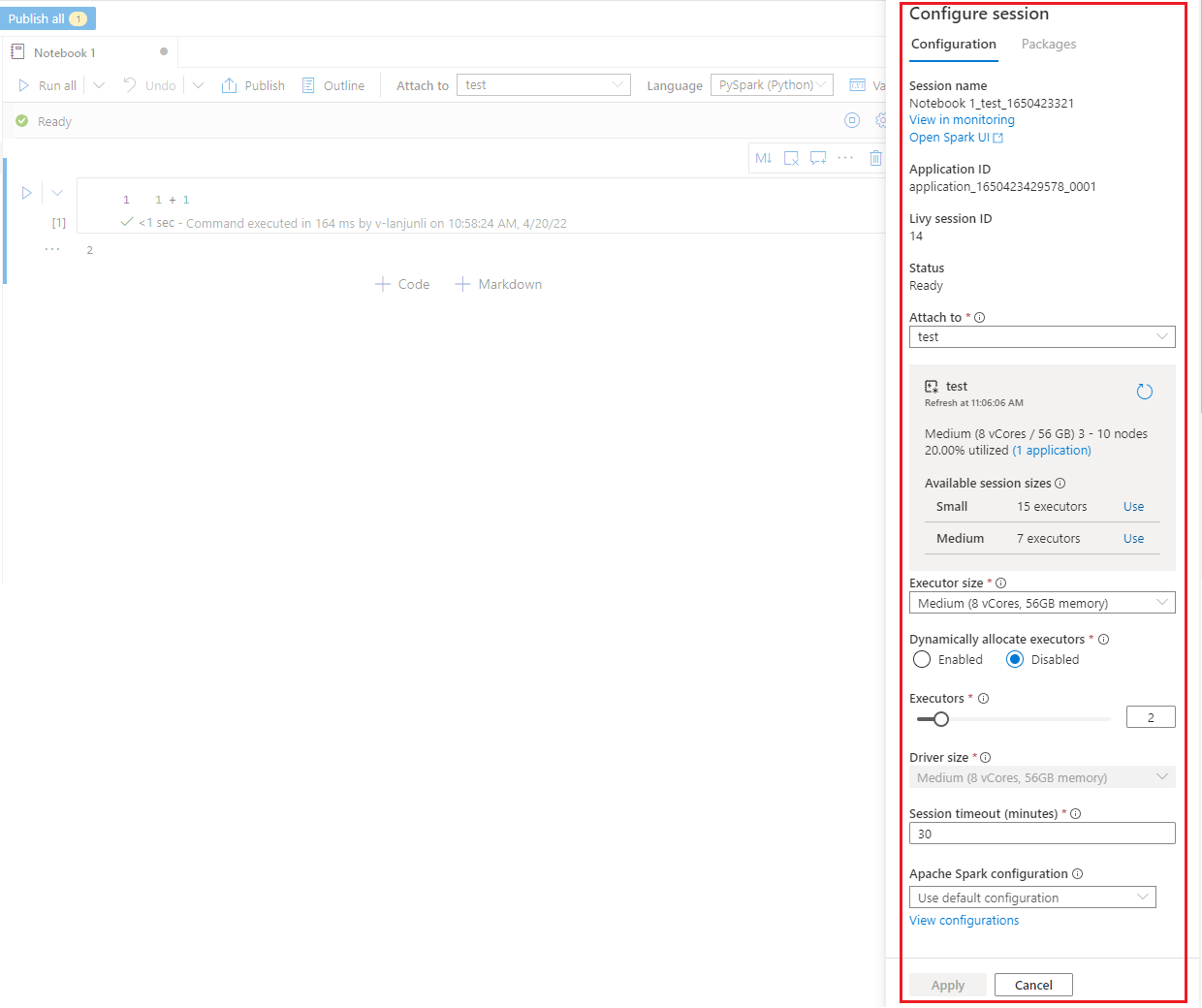
Comando Magic per la configurazione di una sessione Spark
È anche possibile specificare le impostazioni della sessione Spark tramite il comando magic %%configure. Per rendere effettive le impostazioni, riavviare la sessione Spark.
È consigliabile eseguire %%configure all'inizio del notebook. Di seguito è riportato un esempio. Per l'elenco completo dei parametri validi, vedere le informazioni su Livy in GitHub.
%%configure
{
//You can get a list of valid parameters to configure the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of a standard Spark property. To find more available properties, go to https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of a customized property. You can specify the count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Ecco alcune considerazioni per il comando magic %%configure:
- È consigliabile usare lo stesso valore per
driverMemoryeexecutorMemoryin%%configure. È anche consigliabile chedriverCoreseexecutorCoresabbiano lo stesso valore. - È possibile usare
%%configurenelle pipeline di Synapse, ma se non viene impostata nella prima cella di codice, l'esecuzione della pipeline avrà esito negativo perché non può riavviare la sessione. - Il comando
%%configureusato inmssparkutils.notebook.runviene ignorato, ma il comando usato in%run <notebook>continua a essere eseguito. - È necessario usare le proprietà di configurazione Spark standard nel corpo
"conf". Non sono supportati riferimenti di primo livello per le proprietà di configurazione di Spark. - Alcune proprietà speciali di Spark non saranno effettive nel corpo
"conf", incluso"spark.driver.cores","spark.executor.cores""spark.driver.memory","spark.executor.memory"e"spark.executor.instances".
Configurazione della sessione con parametri da una pipeline
È possibile usare la configurazione della sessione con parametri per sostituire i valori nel comando magic %%configure con parametri di esecuzione della pipeline (attività del notebook). Quando si prepara una cella di codice %%configure, è possibile eseguire l'override dei valori predefiniti usando un oggetto simile al seguente:
{
"activityParameterName": "parameterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParameterFromPipelineNotebookActivity"
}
L'esempio seguente mostra i valori predefiniti di 4 e "2000", che sono anche configurabili:
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
Il notebook usa il valore predefinito se lo si esegue direttamente in modalità interattiva o se l'attività del notebook della pipeline non fornisce un parametro corrispondente a "activityParameterName".
Durante la modalità di esecuzione della pipeline, è possibile usare la scheda Impostazioni per configurare le impostazioni per un'attività del notebook della pipeline.
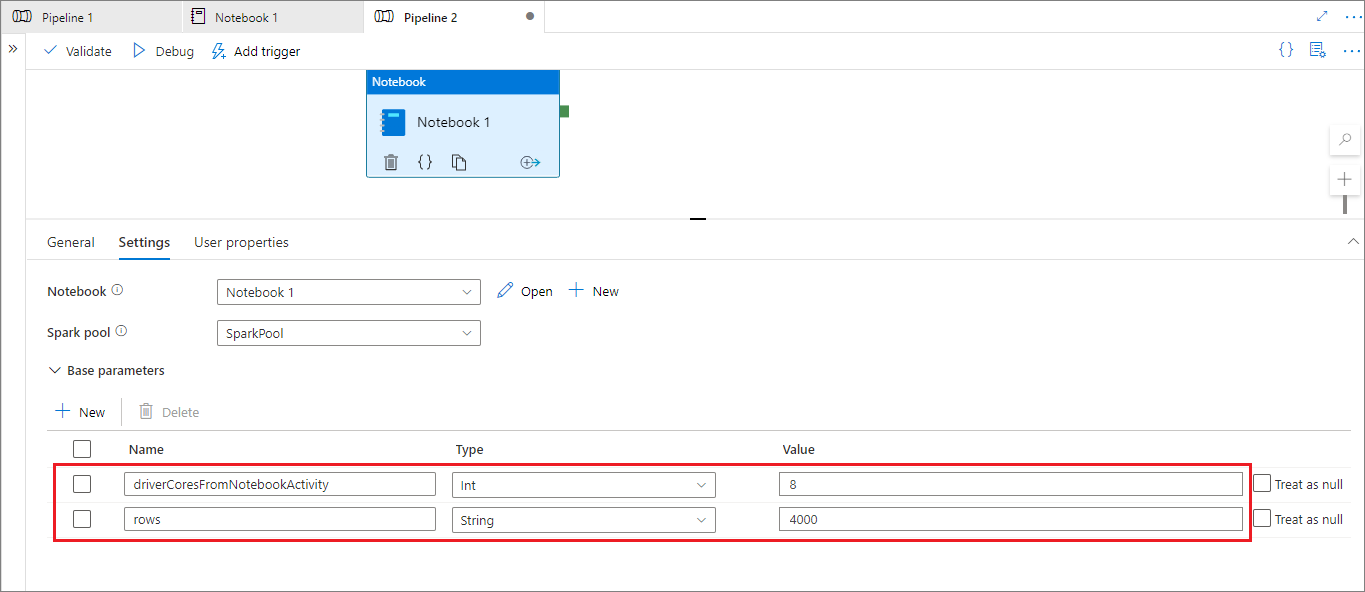
Per modificare la configurazione della sessione, il nome del parametro dell'attività del notebook della pipeline deve essere uguale a activityParameterName nel notebook. In questo esempio, durante un'esecuzione della pipeline, 8 sostituisce driverCores in %%configure e 4000 sostituisce livy.rsc.sql.num-rows.
Se un'esecuzione della pipeline ha esito negativo dopo aver usato il comando magic %%configure, è possibile ottenere altre informazioni sull'errore eseguendo la cella magic %%configure nella modalità interattiva del notebook.
Importare i dati in un notebook
È possibile caricare dati da Azure Data Lake Storage Gen 2, Archivio BLOB di Azure e pool SQL, come illustrato negli esempi di codice seguenti.
Leggere un file CSV da Azure Data Lake Storage Gen2 come dataframe Spark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Leggere un file CSV da Archivio BLOB di Azure come dataframe Spark
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow Spark to access from Azure Blob Storage remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Leggere i dati dall'account di archiviazione primario
È possibile accedere direttamente ai dati nell'account di archiviazione primario. Non è necessario fornire le chiavi private. In Esplora dati, fare clic con il pulsante destro del mouse su un file e selezionare Nuovo notebook per visualizzare un nuovo notebook con un estrattore di dati generato automaticamente.

Usare widget di IPython
I widget sono oggetti Python con eventi che hanno una rappresentazione nel browser, spesso sotto forma di comando come un dispositivo di scorrimento o una casella di testo. I widget IPython funzionano solo in ambienti Python. Attualmente non sono supportati in altri linguaggi (ad esempio Scala, SQL o C#).
Procedura per usare i widget IPython
Importare il modulo
ipywidgetsper usare il framework Jupyter Widgets:import ipywidgets as widgetsUsare la funzione di primo livello
displayper eseguire il rendering di un widget o lasciare un'espressione di tipowidgetall'ultima riga della cella di codice:slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderEseguire la cella. Il widget viene visualizzato nell'area di output.
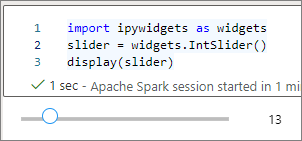
È possibile usare diverse chiamate display() per eseguire il rendering della stessa istanza del widget più volte; tuttavia, le suddette rimangono sincronizzate tra loro:
slider = widgets.IntSlider()
display(slider)
display(slider)

Per eseguire il rendering di due widget indipendenti l'uno dall'altro, creare due istanze del widget:
slider1 = widgets.IntSlider()
slider2 = widgets.IntSlider()
display(slider1)
display(slider2)
Widget supportati
| Tipo di widget | Widget |
|---|---|
| Numerico |
IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Booleano |
ToggleButton, Checkbox, Valid |
| Selezione |
Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| String |
Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| Riproduzione (animazione) |
Date picker, Color picker, Controller |
| Contenitore/layout |
Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Limitazioni note
La tabella seguente elenca i widget attualmente non supportati, insieme alle soluzioni alternative:
Funzionalità Soluzione alternativa OutputwidgetÈ invece possibile usare la funzione print()per scrivere testo instdout.widgets.jslink()È possibile usare la funzione widgets.link()per collegare due widget simili.FileUploadwidgetNon disponibile. La funzione globale
displayfornita da Azure Synapse Analytics non supporta la visualizzazione di più widget in una sola chiamata, ovverodisplay(a, b). Questo comportamento è diverso dalla funzione IPythondisplay.Se si chiude un notebook che contiene un widget IPython, non è possibile visualizzare o interagire con il widget finché non si esegue di nuovo la cella corrispondente.
Salvare i notebook
È possibile salvare un singolo notebook o tutti i notebook nell'area di lavoro:
Per salvare le modifiche apportate a un singolo notebook, selezionare il pulsante Pubblica sulla barra dei comandi del notebook.

Per salvare tutti i notebook nell'area di lavoro, selezionare il pulsante Pubblica tutti i sulla barra dei comandi dell'area di lavoro.

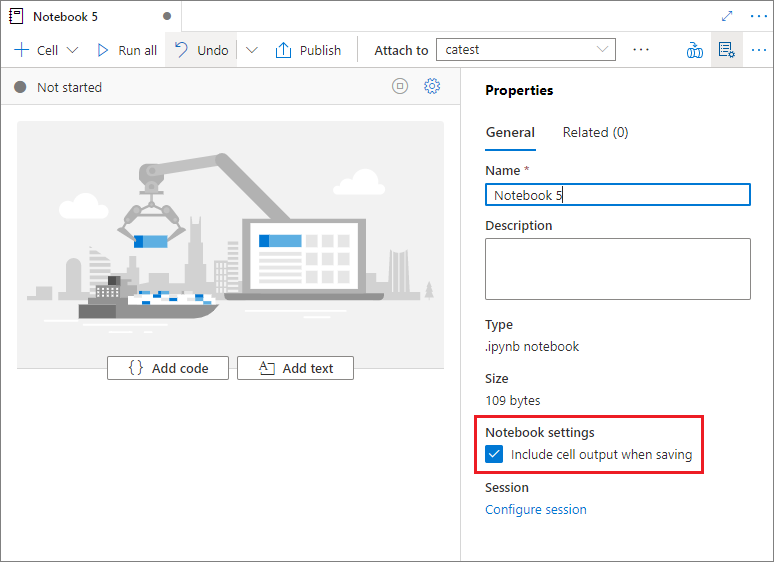
Nel riquadro Proprietà del notebook è possibile configurare se includere l'output della cella durante il salvataggio.
Usare i comandi magic
È possibile usare i comandi magic noti di Jupyter nei notebook di Synapse. Esaminare gli elenchi seguenti dei comandi magic attualmente disponibili. Indicare i casi d'uso in GitHub in modo che sia possibile continuare a creare altri comandi magic per soddisfare le proprie esigenze.
Nota
Nelle pipeline di Synapse sono supportati solo i comandi magic seguenti: %%pyspark, %%spark, %%csharp e%%sql.
Comandi magic disponibili per le righe:
%lsmagic, %time, %timeit, %history, %run, %load
Comandi magic disponibili per le celle:
%%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Fare riferimento a un notebook non pubblicato
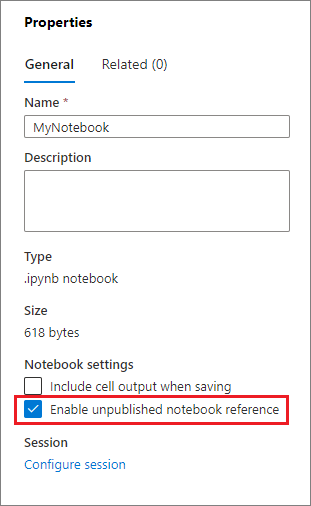
Fare riferimento a un notebook non pubblicato è utile quando si vuole eseguire il debug in locale. Quando si abilita questa funzionalità, l'esecuzione di un notebook recupera il contenuto corrente nella cache Web. Se si esegue una cella che include un'istruzione del notebook di riferimento, si fa riferimento ai notebook presentati nel browser notebook corrente anziché a una versione salvata in un cluster. Altri notebook possono fare riferimento alle modifiche nell'editor di notebook senza richiedere la pubblicazione (modalità dinamica) o il commit (modalità Git) delle modifiche. Usando questo approccio, è possibile evitare l'inquinamento delle librerie comuni durante il processo di sviluppo o debug.
È possibile abilitare il riferimento a un notebook non pubblicato selezionando la casella di controllo appropriata nel riquadro Proprietà.
Nella tabella seguente vengono confrontati i casi. Anche se %run e mssparkutils.notebook.run hanno lo stesso comportamento, la tabella usa %run come esempio.
| Case | Disabilitazione | Abilitare |
|---|---|---|
| Modalità Live | ||
Nb1 (pubblicato) %run Nb1 |
Eseguire la versione pubblicata di Nb1 | Eseguire la versione pubblicata di Nb1 |
Nb1 (nuovo) %run Nb1 |
Error | Eseguire il nuovo Nb1 |
Nb1 (pubblicato in precedenza, modificato) %run Nb1 |
Eseguire la versione pubblicata di Nb1 | Eseguire la versione modificata di Nb1 |
| Modalità Git | ||
Nb1 (pubblicato) %run Nb1 |
Eseguire la versione pubblicata di Nb1 | Eseguire la versione pubblicata di Nb1 |
Nb1 (nuovo) %run Nb1 |
Error | Eseguire il nuovo Nb1 |
Nb1 (non pubblicato, sottoposto a commit) %run Nb1 |
Error | Esecuzione sottoposta a commit Nb1 |
Nb1 (pubblicato in precedenza, sottoposto a commit) %run Nb1 |
Eseguire la versione pubblicata di Nb1 | Eseguire la versione di cui è stato eseguito il commit di Nb1 |
Nb1 (pubblicato in precedenza, nuovo in ramo corrente) %run Nb1 |
Eseguire la versione pubblicata di Nb1 | Eseguire il nuovo Nb1 |
Nb1 (non pubblicato, precedentemente sottoposto a commit, modificato) %run Nb1 |
Error | Eseguire la versione modificata di Nb1 |
Nb1 (pubblicato e sottoposto a commit in precedenza, modificato) %run Nb1 |
Eseguire la versione pubblicata di Nb1 | Eseguire la versione modificata di Nb1 |
Riepilogo:
- Se si disabilita il riferimento a un notebook non pubblicato, eseguire sempre la versione pubblicata.
- Se si abilita il riferimento a un notebook non pubblicato, l'esecuzione di riferimento adotta sempre la versione corrente del notebook visualizzata nell'esperienza utente del notebook.
Gestire le sessioni attive
È possibile riutilizzare le sessioni del notebook senza dover avviarne di nuove. Nei notebook di Synapse è possibile gestire le sessioni attive in un unico elenco. Per aprire l'elenco, selezionare i puntini di sospensione (...) e quindi selezionare Gestisci sessioni.
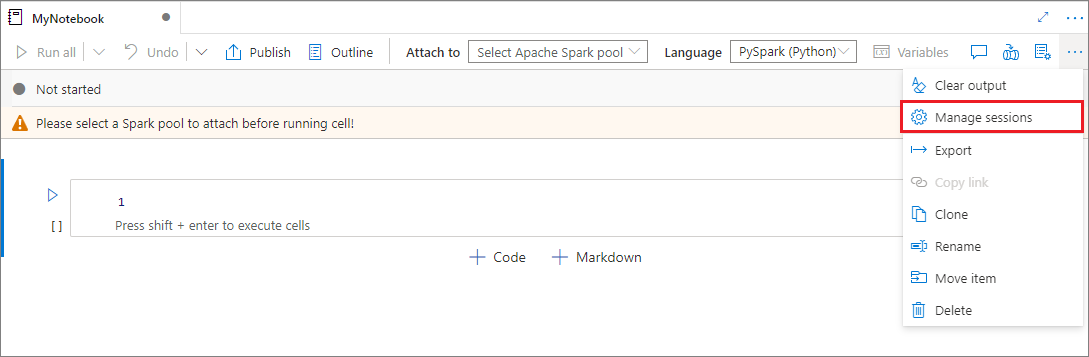
Il riquadro Sessioni attive elenca tutte le sessioni nell'area di lavoro corrente avviata da un notebook. L'elenco mostra le informazioni sulla sessione e i notebook corrispondenti. Le azioni Rimuovi con notebook, Arresta la sessione e Visualizza nel monitoraggio sono disponibili qui. È anche possibile connettere il notebook selezionato a una sessione attiva avviata da un altro notebook. La sessione viene quindi scollegata dal notebook precedente (se non è inattiva) e collegata a quella corrente.
Usare i log Python in un notebook
È possibile trovare i log Python e impostare diversi livelli e formati di log usando il codice di esempio seguente:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize the log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# Logger that uses the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# Logger that uses the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Visualizzare la cronologia dei comandi di input
I notebook di Synapse supportano il comando magic %history per stampare la cronologia dei comandi di input per la sessione corrente. Il comando magic %history è simile al comando IPython di Jupyter standard e funziona per più contesti di linguaggio in un notebook.
%history [-n] [range [range ...]]
Nel codice precedente, -n è il numero di esecuzione di stampa. Il valore range può essere:
-
N: stampare il codice della cellaNtheseguita. -
M-N: stampare il codice dall'oggettoMthalla cellaNtheseguita.
Ad esempio, per stampare la cronologia di input dalla prima alla seconda cella eseguita, usare %history -n 1-2.
Integrare un notebook
Aggiungere un notebook a una pipeline
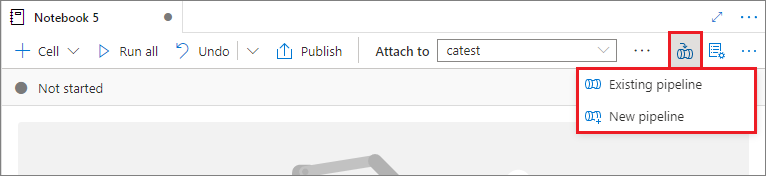
Selezionare il pulsante Aggiungi alla pipeline nell'angolo in alto a destra per aggiungere un notebook a una pipeline esistente o creare una nuova pipeline.
Designare una cella di parametri
Per parametrizzare il notebook, selezionare i puntini di sospensione (...) per accedere ad altri comandi sulla barra degli strumenti delle celle. Selezionare quindi Attiva/Disattiva cella di parametri per designare la cella come cella di parametri.
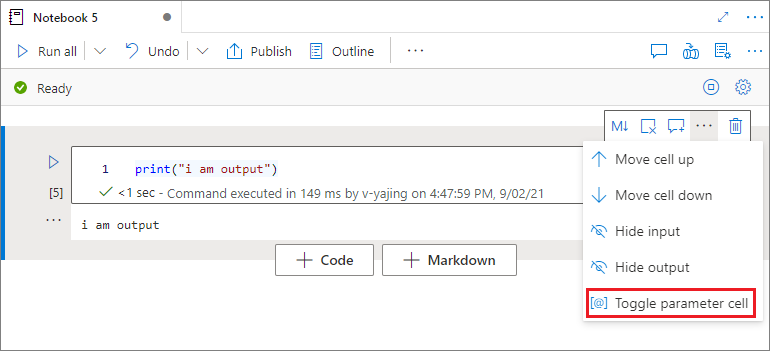
Azure Data Factory cerca la cella del parametro e considera questa cella come predefinita per i parametri passati in fase di esecuzione. Il motore di esecuzione aggiunge una nuova cella sotto la cella del parametro con parametri di input per sovrascrivere i valori predefiniti.
Assegnare i valori dei parametri da una pipeline
Dopo aver creato un notebook con parametri, è possibile eseguirlo da una pipeline usando un'attività del notebook di Synapse. Dopo aver aggiunto l'attività al canvas della pipeline, è possibile impostare i valori dei parametri nella sezione Parametri di base della scheda Impostazioni.
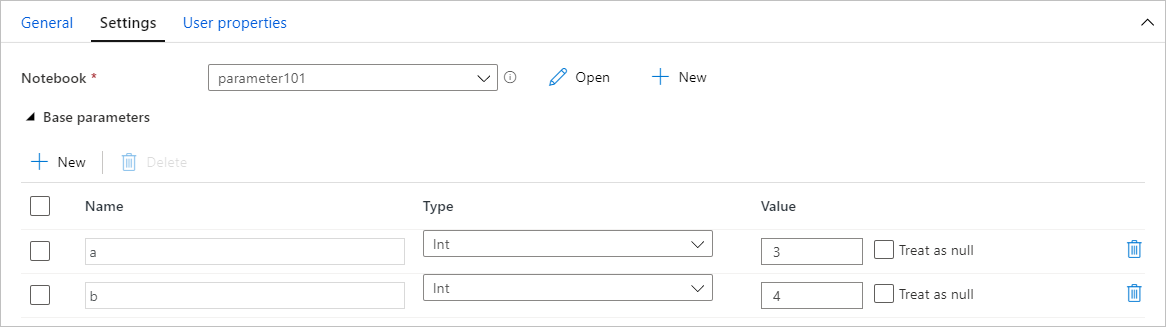
Quando si assegnano valori di parametro, è possibile usare il linguaggio delle espressioni della pipeline o le variabili di sistema.
Usare i tasti di scelta rapida
Analogamente ai notebook di Jupyter, i notebook di Synapse hanno un'interfaccia utente modale. La tastiera esegue diverse operazioni a seconda della modalità in cui si trova la cella del notebook. I notebook di Synapse supportano le due modalità seguenti per una cella di codice:
Modalità di comando: una cella è in modalità comando quando non viene richiesto di digitare alcun cursore di testo. Quando una cella è in modalità di comando, è possibile modificare il notebook nel suo complesso, ma non digitare in singole celle. Immettere la modalità di comando selezionando il tasto ESC o usando il mouse per selezionare all'esterno dell'area dell'editor di una cella.

Modalità di modifica: quando una cella è in modalità di modifica, un cursore di testo richiede di digitare nella cella. Attivare la modalità di modifica selezionando il tasto INVIO o usando il mouse per selezionare l'area dell'editor di una cella.

Tasti di scelta rapida in modalità comando
| Azione | Collegamento ai notebook di Synapse |
|---|---|
| Eseguire la cella corrente e selezionare in basso | MAIUSC + Invio |
| Eseguire la cella corrente e inserire in basso | ALT + INVIO |
| Esegui cella corrente | Ctrl + INVIO |
| Selezionare la cella in alto | Freccia SU |
| Selezionare la cella in basso | Giù |
| Seleziona la cella precedente | K |
| Seleziona la cella successiva | J |
| Inserire la cella in alto | Un |
| Inserire la cella in basso | G |
| Eliminare le celle selezionate | Maiusc+D |
| Passare alla modalità di modifica | INVIO |
Tasti di scelta rapida in modalità di modifica
| Azione | Collegamento ai notebook di Synapse |
|---|---|
| Spostare il cursore in alto | Freccia SU |
| Spostare in cursore in basso | Giù |
| Annulla | CTRL+Z |
| Ripeti | CTRL+Y |
| Inserimento/Rimozione di commenti | CTRL+/ |
| Eliminare la parola prima | CTRL+BACKSPACE |
| Eliminare la parola dopo | CTRL+CANC |
| Andare all'inizio della cella | CTRL + HOME |
| Andare alla fine della cella | CTRL + FINE |
| Andare a sinistra di una parola | CTRL + SINISTRA |
| Andare a destra di una parola | CTRL + DESTRA |
| Seleziona tutto | CTRL+A |
| Impostare un rientro | CTRL+] |
| Annullare l'impostazione di un rientro | CTRL+[ |
| Passare alla modalità comandi | ESC |
Contenuto correlato
- Notebook di Synapse di esempio
- Avvio rapido: creare un pool di Apache Spark in Azure Synapse Analytics con gli strumenti Web
- Che cos'è Apache Spark in Azure Synapse Analytics?
- Usare .NET per Apache Spark con Azure Synapse Analytics
- Documentazione di .NET per Apache Spark
- Documentazione di Azure Synapse Analytics