Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione spiega come abilitare il connettore Synapse Studio integrato in Log Analytics. È quindi possibile raccogliere e inviare metriche e log dell'applicazione Apache Spark all'area di lavoro Log Analytics. Infine, è possibile usare una cartella di lavoro di Monitoraggio di Azure per visualizzare le metriche e i log.
Configurare informazioni sull’area di lavoro
Seguire questa procedura per configurare le informazioni necessarie in Synapse Studio.
Passaggio 1: creare un'area di lavoro Log Analytics
Per creare questa area di lavoro, vedere una delle risorse seguenti:
- Creare un'area di lavoro nel portale di Azure.
- Creare un'area di lavoro con l'interfaccia della riga di comando di Azure.
- Creare e configurare un'area di lavoro n Monitoraggio di Azure usando PowerShell.
Passaggio 2: Raccogliere informazioni di configurazione
Usare una delle opzioni seguenti per preparare la configurazione.
Opzione 1: configurare con l'ID e la chiave dell'area di lavoro Log Analytics
Raccogliere i valori seguenti per la configurazione di Spark:
-
<LOG_ANALYTICS_WORKSPACE_ID>: ID dell'area di lavoro Log Analytics. -
<LOG_ANALYTICS_WORKSPACE_KEY>: chiave di Log Analytics. Per trovarla, nel portale di Azure andare a Area di lavoro Log Analytics>Agenti>Chiave primaria.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.secret <LOG_ANALYTICS_WORKSPACE_KEY>
In alternativa, usare le proprietà seguenti:
spark.synapse.diagnostic.emitters: LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret: <LOG_ANALYTICS_WORKSPACE_KEY>
Opzione 2: configurare con Azure Key Vault
Nota
È necessario concedere l'autorizzazione del segreto di lettura agli utenti che inviano applicazioni Apache Spark. Per ulteriori informazioni, vedere Fornire l'accesso a chiavi, certificati e segreti di Key Vault con un controllo degli accessi in base al ruolo di Azure. Quando si abilita questa funzionalità in una pipeline di Synapse, è necessario usare l'opzione 3. È necessario ottenere il segreto da Azure Key Vault utilizzando l'identità gestita del workspace.
Per configurare Azure Key Vault per archiviare la chiave dell'area di lavoro, seguire questa procedura:
Crea e accedi al tuo Key Vault nel portale di Azure.
Concedere l'autorizzazione corretta agli utenti o alle identità gestite dell'area di lavoro.
Nella pagina delle impostazioni per il Key Vault, selezionare Segreti.
Seleziona Genera/Importa.
Nella schermata Crea un segreto selezionare i seguenti valori:
-
Nome: immettere un nome per il segreto. Per impostazione predefinita, immettere
SparkLogAnalyticsSecret. -
Valore: Inserisci il
<LOG_ANALYTICS_WORKSPACE_KEY>per il segreto. - Lasciare invariati gli altri valori predefiniti. Seleziona Crea.
-
Nome: immettere un nome per il segreto. Per impostazione predefinita, immettere
Raccogliere i valori seguenti per la configurazione di Spark:
-
<LOG_ANALYTICS_WORKSPACE_ID>: l'ID dello spazio di lavoro Log Analytics. -
<AZURE_KEY_VAULT_NAME>: nome dell'insieme di credenziali delle chiavi configurato. -
<AZURE_KEY_VAULT_SECRET_KEY_NAME>(facoltativo): nome del segreto nell'insieme di credenziali delle chiavi per la chiave dell'area di lavoro. Il valore predefinito èSparkLogAnalyticsSecret.
-
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
In alternativa, usare le proprietà seguenti:
spark.synapse.diagnostic.emitters LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret.keyVault: <AZURE_KEY_VAULT_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.secretName: <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Nota
È anche possibile archiviare l'ID dell'area di lavoro in Key Vault. Fare riferimento ai passaggi precedenti e archiviare l'ID dell'area di lavoro con il nome del segreto SparkLogAnalyticsWorkspaceId. In alternativa, è possibile usare la configurazione spark.synapse.logAnalytics.keyVault.key.workspaceId per specificare il nome del segreto ID dell’area di lavoro in Key Vault.
Opzione 3. Configurare con un servizio collegato
Nota
In questa opzione è necessario concedere l'autorizzazione del segreto di lettura all'identità gestita dell'area di lavoro. Per ulteriori informazioni, vedere Fornire l'accesso a chiavi, certificati e segreti di Key Vault con un controllo degli accessi in base al ruolo di Azure.
Per configurare un servizio collegato di Key Vault in Synapse Studio per archiviare la chiave dell'area di lavoro, seguire questa procedura:
Seguire tutti i passaggi della sezione precedente, "Opzione 2".
Creare un servizio collegato Key Vault in Synapse Studio:
a) Vai su Synapse Studio>Gestisci>Servizi collegati e seleziona Nuovo.
b. Nella casella di ricerca cercare Azure Key Vault.
c. Immettere un nome per il servizio collegato.
d. Scegli il tuo key vault e seleziona Crea.
Aggiungere un elemento
spark.synapse.logAnalytics.keyVault.linkedServiceNamealla configurazione di Apache Spark.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.logAnalytics.keyVault.linkedServiceName <LINKED_SERVICE_NAME>
In alternativa, usare le proprietà seguenti:
spark.synapse.diagnostic.emitters LA
spark.synapse.diagnostic.emitter.LA.type: "AzureLogAnalytics"
spark.synapse.diagnostic.emitter.LA.categories: "Log,EventLog,Metrics"
spark.synapse.diagnostic.emitter.LA.workspaceId: <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.diagnostic.emitter.LA.secret.keyVault: <AZURE_KEY_VAULT_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.secretName: <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.diagnostic.emitter.LA.secret.keyVault.linkedService: <AZURE_KEY_VAULT_LINKED_SERVICE>
Per un elenco delle configurazioni di Apache Spark, vedere Configurazioni di Apache Spark disponibili
Passaggio 3: Creare una configurazione di Apache Spark
È possibile creare una configurazione di Apache Spark nell'area di lavoro e quando si crea la definizione del processo Apache Spark o Notebook è possibile selezionare la configurazione di Apache Spark che si vuole usare con il pool di Apache Spark. Quando si seleziona questa voce, vengono visualizzati i dettagli della configurazione.
Selezionare Gestisci>configurazioni di Apache Spark.
Selezionare Il pulsante Nuovo per creare una nuova configurazione di Apache Spark.
Dopo aver selezionato Nuovo pulsante, verrà aperta la nuova pagina di configurazione di Apache Spark.
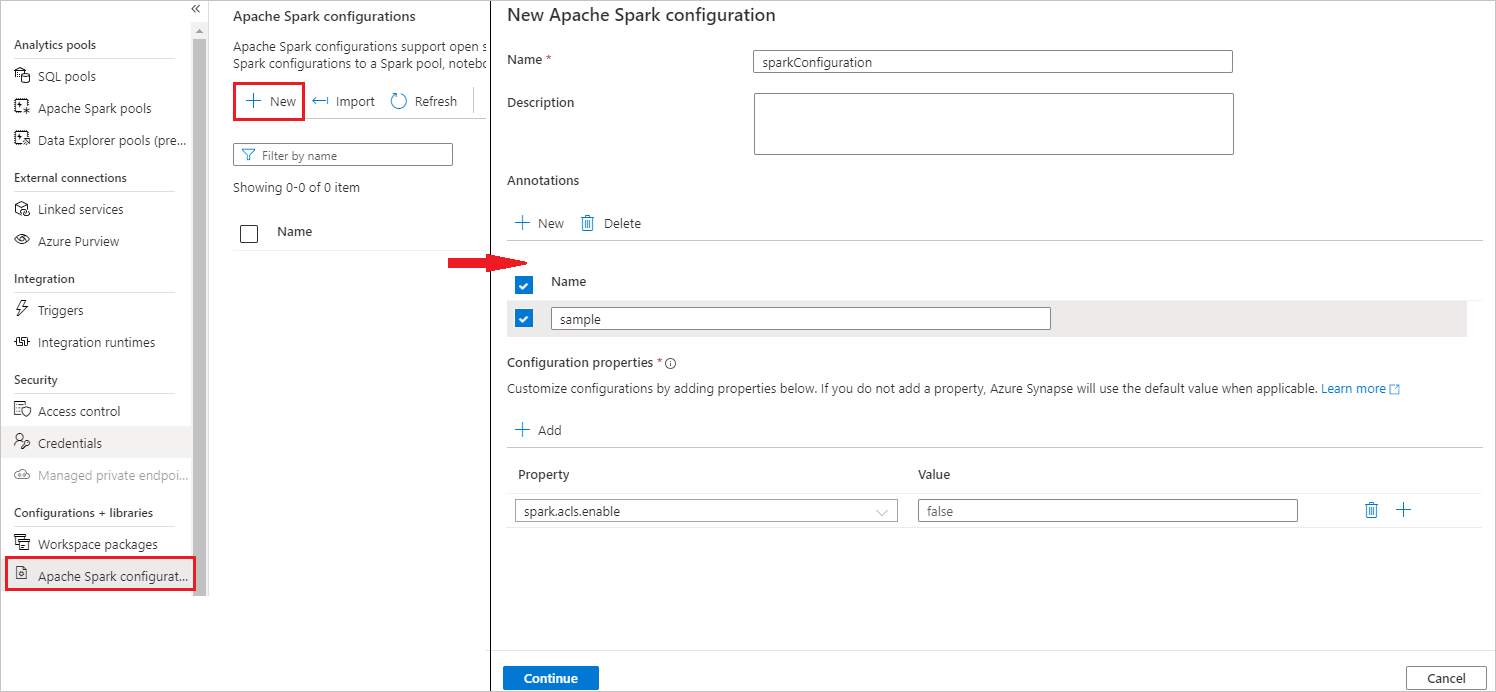
In Nomeè possibile immettere il nome preferito e valido.
In Descrizioneè possibile immettere una descrizione.
In Annotazioni, è possibile aggiungere annotazioni facendo clic sul pulsante Nuovo; è anche possibile eliminare le annotazioni esistenti selezionando e facendo clic sul pulsante Elimina.
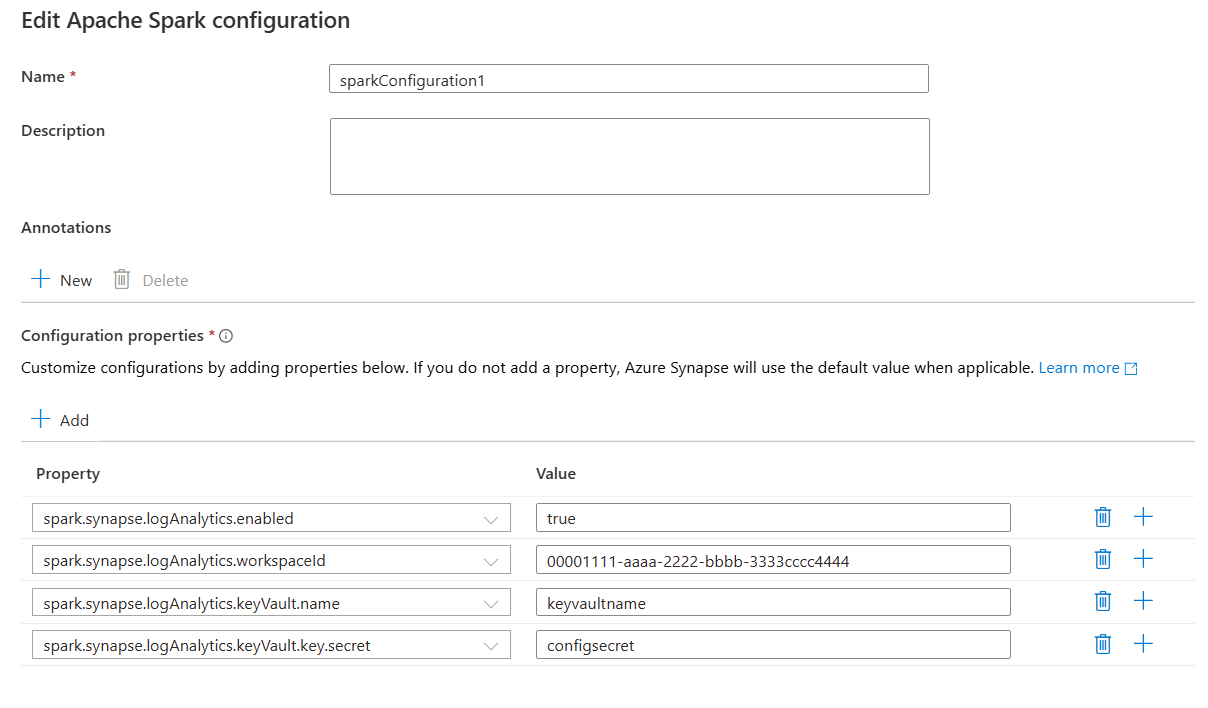
Per Proprietà di configurazione, aggiungere tutte le proprietà dall'opzione di configurazione scelta selezionando il pulsante Aggiungi . Per Proprietà aggiungere il nome della proprietà come elencato e per Valore usare il valore raccolto durante il passaggio 2. Se non si aggiunge una proprietà, Azure Synapse userà il valore predefinito, se applicabile.
Inviare un'applicazione Apache Spark e visualizzare i log e le metriche
In tal caso, eseguire la procedura seguente:
Inviare un'applicazione Apache Spark al pool di Apache Spark configurato nel passaggio precedente. È possibile usare uno dei modi seguenti per eseguire questa operazione:
- Eseguire un notebook in Synapse Studio.
- In Synapse Studio inviare un processo batch Apache Spark tramite una definizione di processo Apache Spark.
- Eseguire una pipeline contenente l'attività Apache Spark.
Andare all'area di lavoro Log Analytics specificata e visualizzare le metriche e i log dell'applicazione all'avvio dell'esecuzione dell'applicazione Apache Spark.
Scrivere log di applicazioni personalizzati
È possibile usare la libreria Apache Log4j per scrivere log personalizzati.
Esempio per Scala:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Esempio per PySpark:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
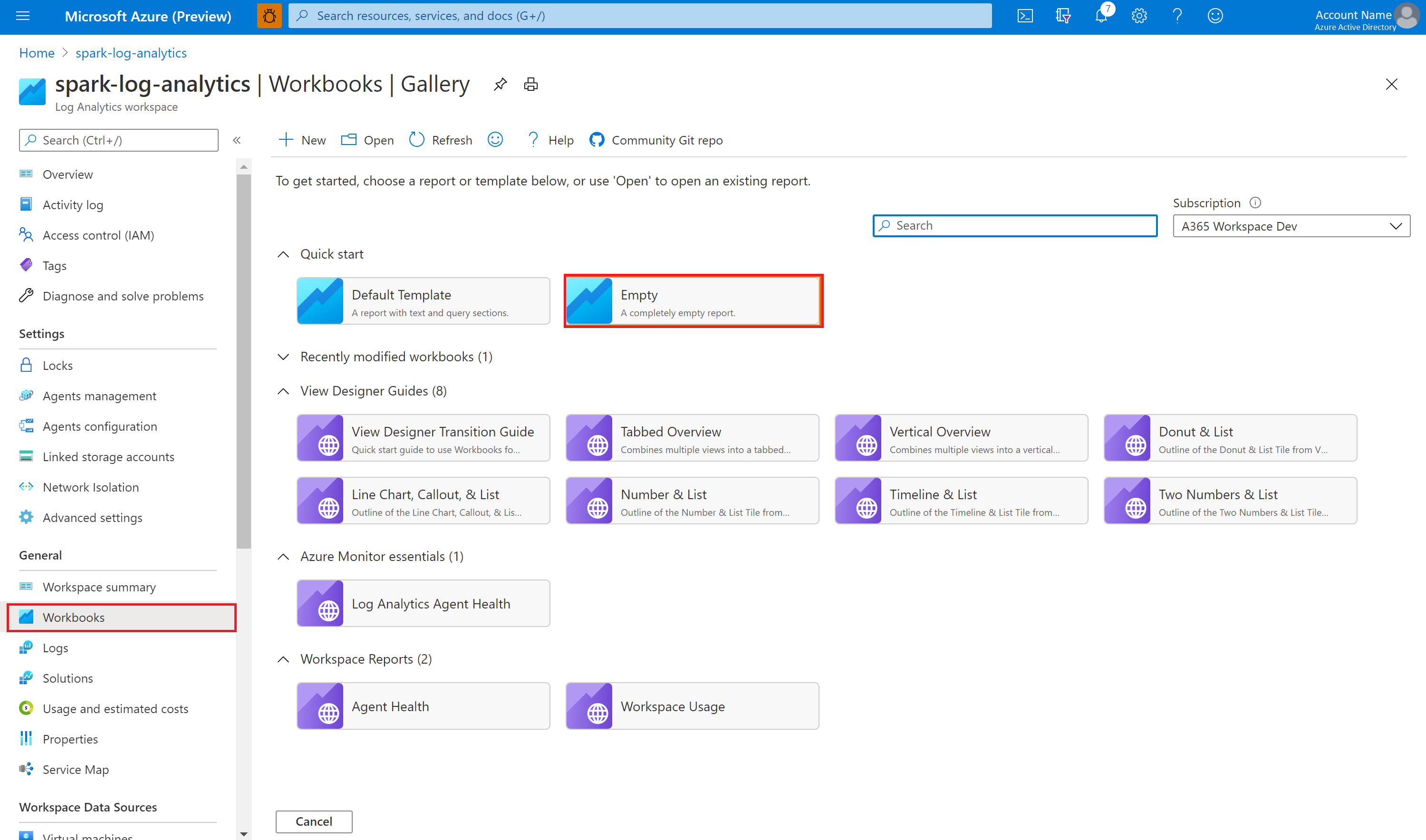
Usare la cartella di lavoro di esempio per visualizzare le metriche e i log
Aprire e copiare il contenuto del file della cartella di lavoro.
Nel portale di Azure selezionare l'area di lavoro Log Analytics>Cartelle di lavoro.
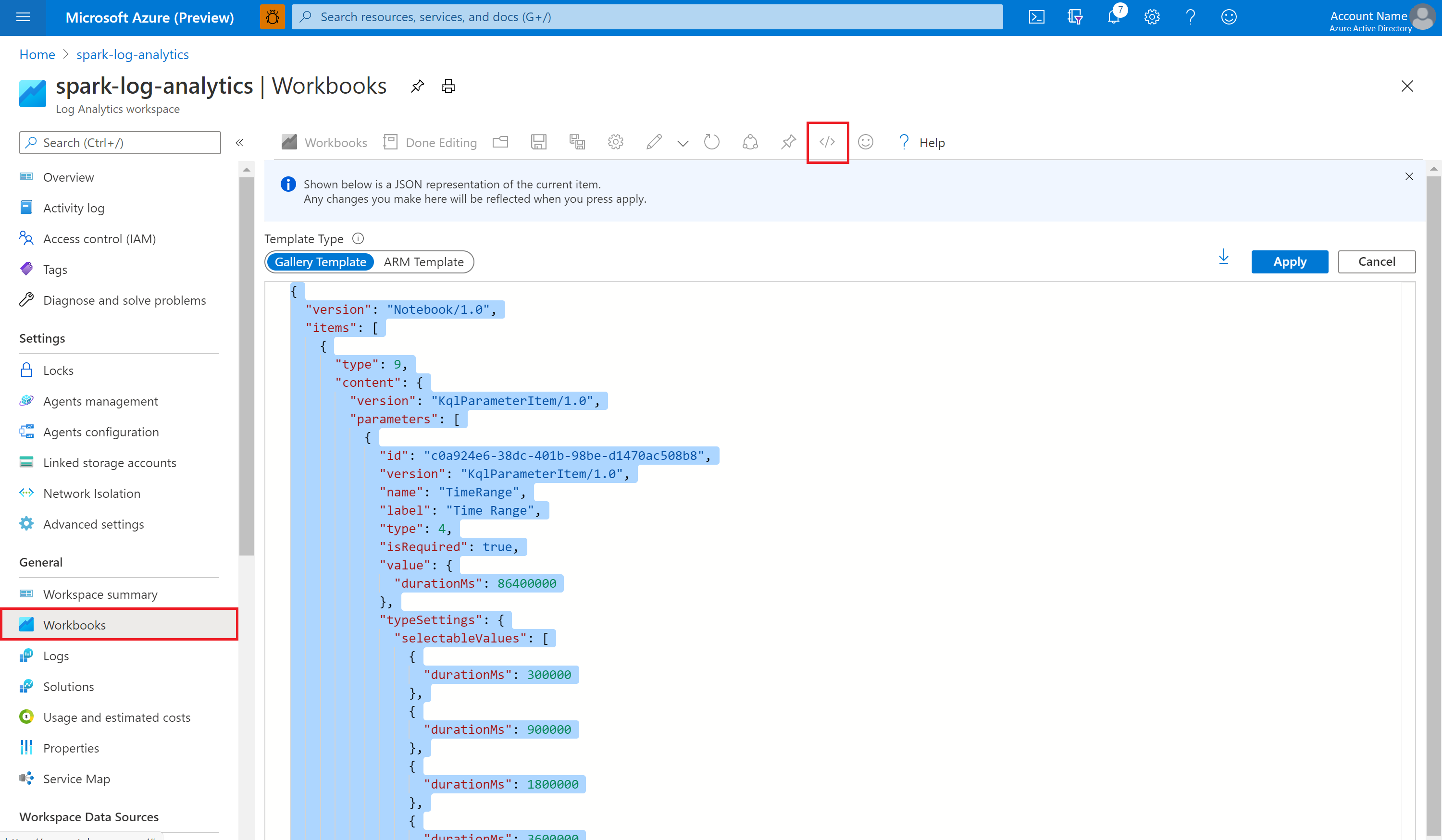
Aprire la cartella di lavoro Vuota. Usare la modalità Editor avanzato selezionando l'icona </>.
Incollare su qualsiasi codice JSON esistente.
Selezionare Applica seguito da Fine modifica.
Inviare quindi l'applicazione Apache Spark al pool di Apache Spark configurato. Dopo che l'applicazione passa a uno stato in esecuzione, scegliere l'applicazione in esecuzione nell'elenco a discesa delle cartelle di lavoro.
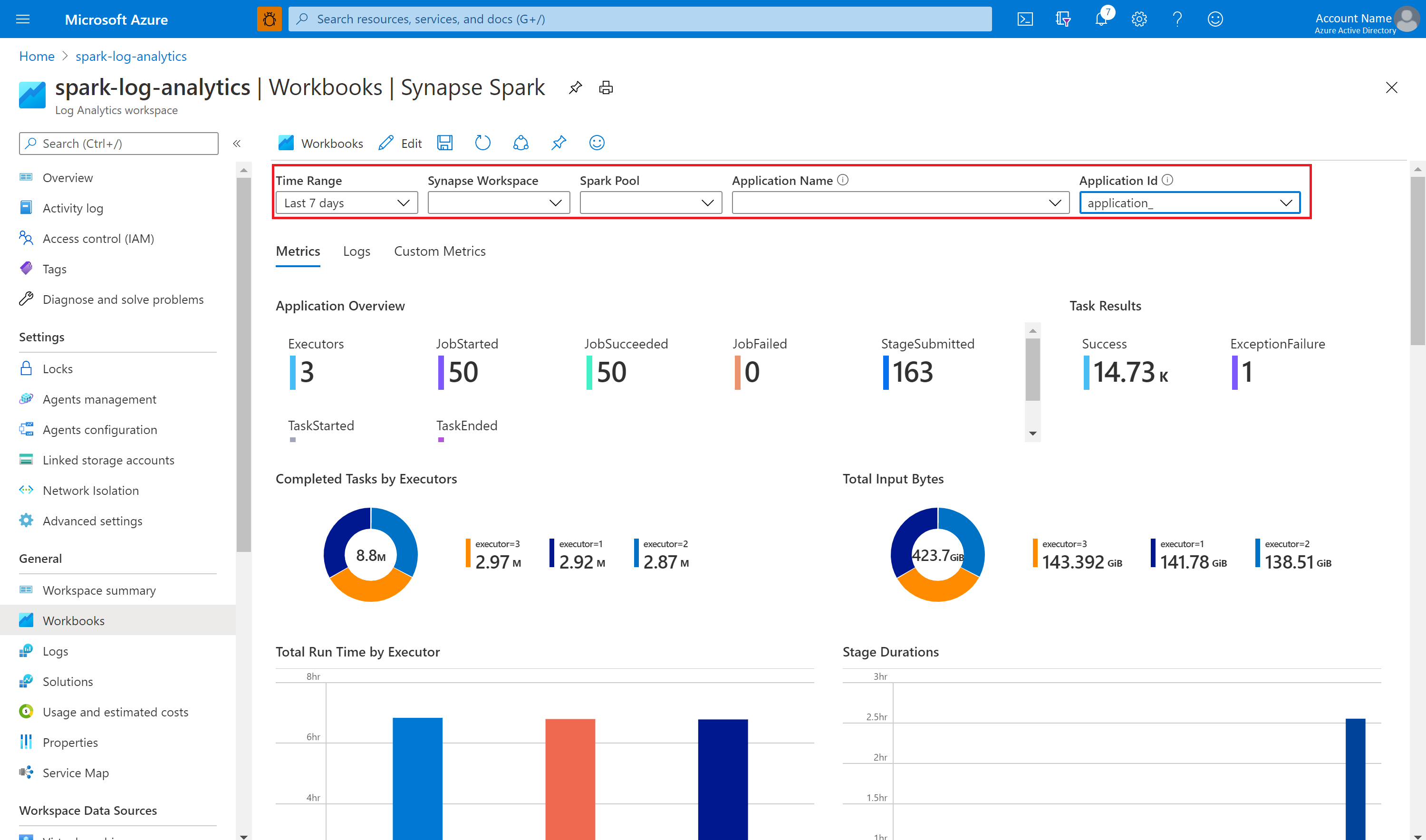
È possibile personalizzare la cartella di lavoro. Ad esempio, è possibile usare query Kusto e configurare gli avvisi.
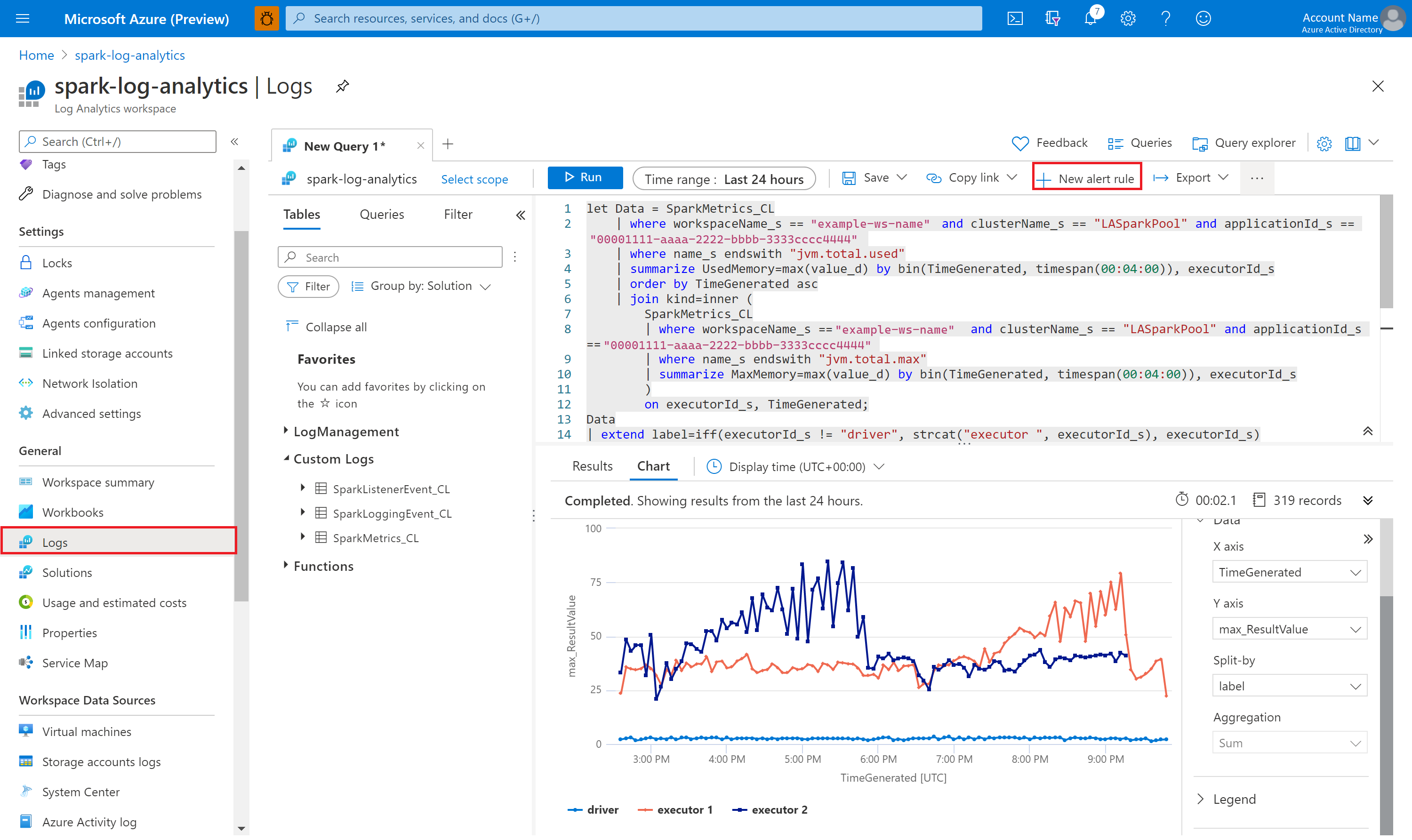
Eseguire query sui dati con Kusto
Di seguito è riportato un esempio di esecuzione di query sugli eventi di Apache Spark:
SparkListenerEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Di seguito è riportato un esempio di esecuzione di query sui log del driver e sugli executor dell'applicazione Apache Spark:
SparkLoggingEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Di seguito è riportato un esempio di query sulle metriche di Apache Spark:
SparkMetrics_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
Creare e gestire avvisi
Gli utenti possono eseguire query per valutare metriche e log a una frequenza impostata e generare un avviso in base ai risultati. Per ulteriori informazioni, vedere Creare, visualizzare e gestire avvisi di registro utilizzando Monitoraggio di Azure.
Area di lavoro di Synapse con protezione dall'esfiltrazione dati abilitata
Dopo aver creato l'area di lavoro di Synapse con la protezione dell'esfiltrazione dei dati abilitata.
Quando si vuole abilitare questa funzionalità, è necessario creare richieste di connessione dell'endpoint privato gestito per gli ambiti di collegamento privato di Monitoraggio di Azure (AMPLS) nei tenant di Microsoft Entra approvati dell'area di lavoro.
È possibile seguire i passaggi seguenti per creare una connessione gestita di endpoint privato agli ambiti di collegamento privato di Azure Monitor (AMPLS):
- Se non esiste già un AMPLS, è possibile seguire la configurazione della connessione del collegamento privato di Azure Monitor per crearne una.
- Passare a AMPLS nel portale di Azure, nella pagina Risorse di Monitoraggio di Azure selezionare Aggiungi per aggiungere la connessione all'area di lavoro Log Analytics di Azure.
- Passare a Synapse Studio > Gestisci > endpoint privati gestiti, selezionare il pulsante Nuovo, selezionare Ambiti di collegamento privato di Azure Monitor e continuare.
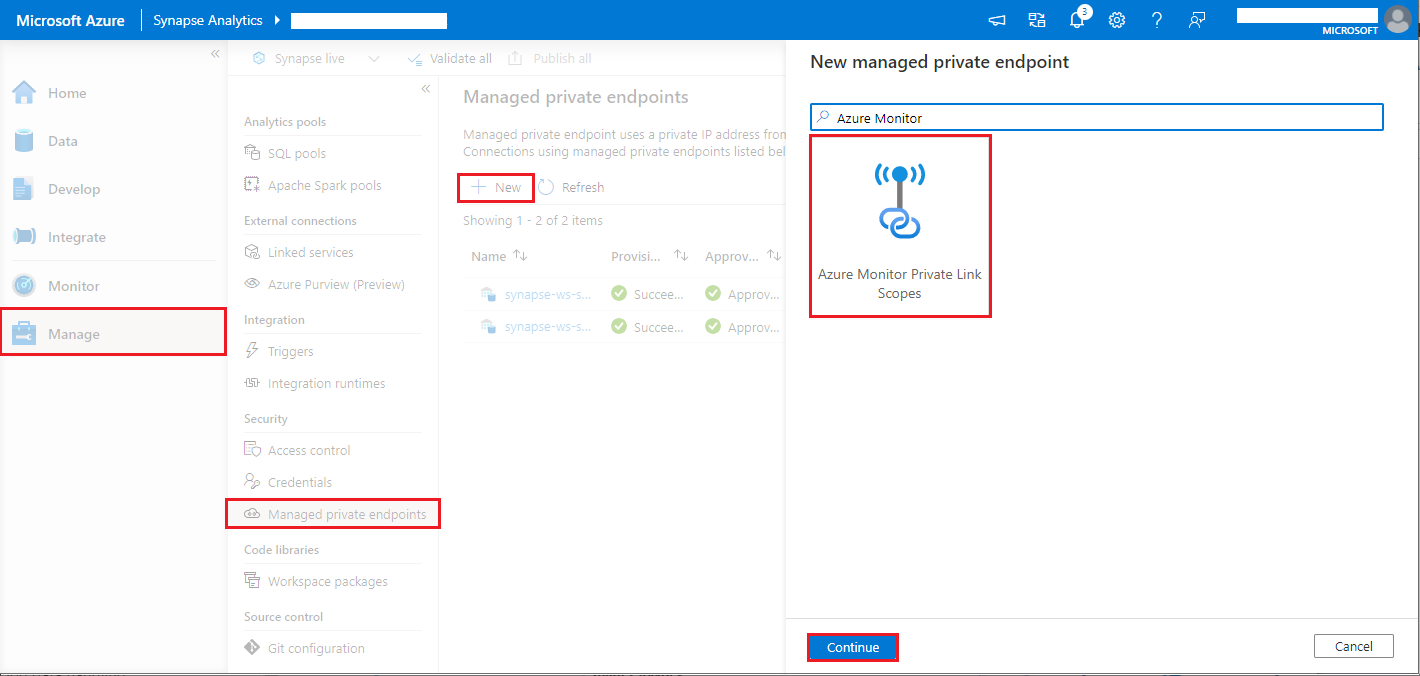
- Scegliere l'ambito del collegamento privato per il Monitor di Azure che hai creato, e selezionare Crea.
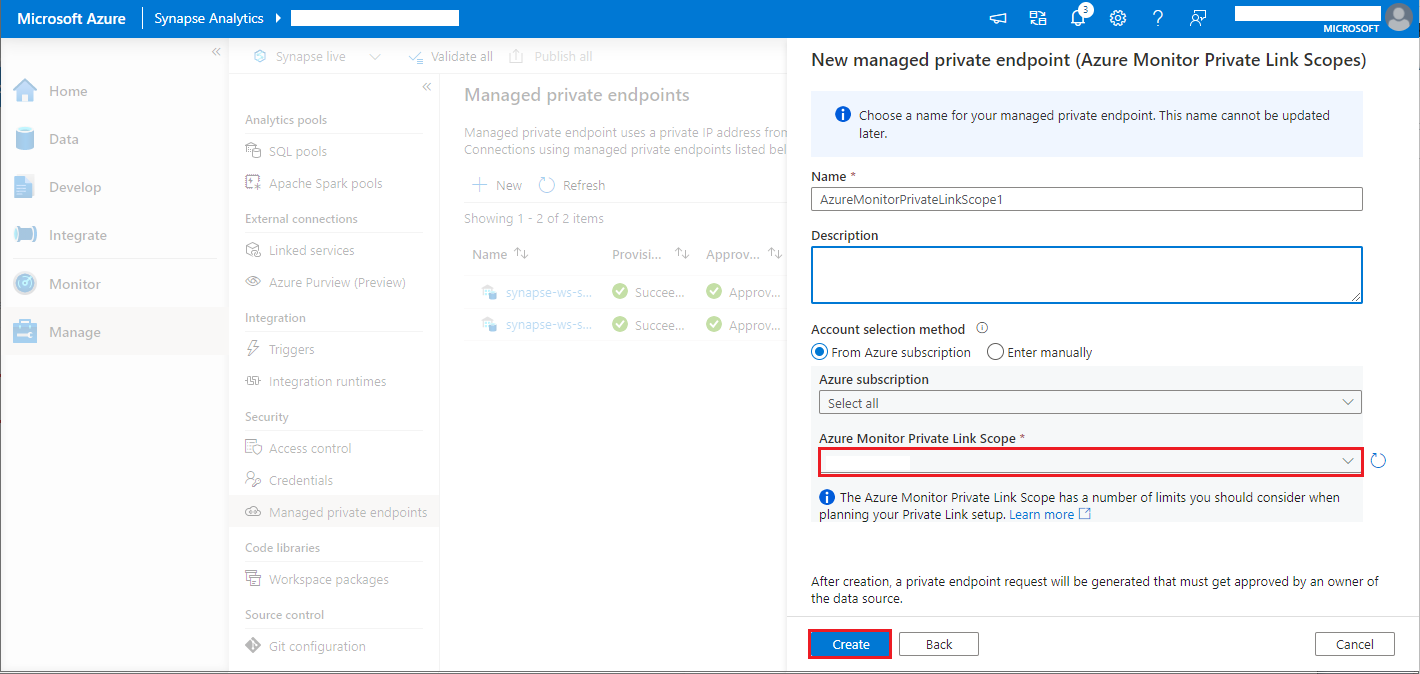
- Attendere alcuni minuti per il provisioning dell'endpoint privato.
- Passare nuovamente agli ambiti di collegamento privato di Monitoraggio di Azure nel portale di Azure e nella pagina Connessioni endpoint private selezionare la connessione di cui è stato effettuato il provisioning e Approva.
Nota
- L'oggetto AMPLS presenta molti limiti da considerare durante la pianificazione della configurazione del collegamento privato. Per una revisione più approfondita di questi limiti, vedere Limiti AMPLS.
- Controllare se si dispone dell'autorizzazione necessaria per creare un endpoint privato gestito.
Configurazioni disponibili
| Impostazione | Descrizione |
|---|---|
spark.synapse.diagnostic.emitters |
Obbligatorio. Nomi delle destinazioni, separati da virgole, degli emettitori diagnostici. Ad esempio, MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Obbligatorio. Tipo di destinazione predefinito. Per abilitare la destinazione di Azure Log Analytics, AzureLogAnalytics deve essere incluso in questo campo. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Facoltativo. Categorie di log selezionate separate da virgole. I valori disponibili includono DriverLog, ExecutorLog, EventLog e Metrics. Se non è impostato, il valore predefinito è tutte le categorie. |
spark.synapse.diagnostic.emitter.<destination>.workspaceId |
Obbligatorio. Per abilitare la destinazione di Azure Log Analytics, workspaceId deve essere incluso in questo campo. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Facoltativo. Contenuto segreto (chiave di Log Analytics). Nel portale di Azure, per trovarlo, passa nell'area di lavoro Azure Log Analytics, Agenti, Chiave primaria. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Obbligatorio se .secret non viene specificato. Nome del Key Vault di Azure in cui è archiviato il segreto (AccessKey o SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Obbligatorio se si specifica .secret.keyVault. Nome del segreto dell'insieme di credenziali delle chiavi di Azure in cui è archiviato il segreto. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Facoltativo. Il nome del servizio collegato di Azure Key Vault. Quando abilitata nella pipeline di Synapse, è necessario ottenere il segreto dall'Azure Key Vault. Assicurarsi che l'identità del servizio gestito abbia accesso in lettura all'insieme di credenziali delle chiavi di Azure. |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Facoltativo. I nomi dei logger Log4j delimitati da virgole; è possibile specificare i log da raccogliere. Ad esempio: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Facoltativo. I nomi dei logger log4j delimitati da virgole; è possibile specificare i log da raccogliere. Ad esempio: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Facoltativo. I suffissi del nome della metrica Spark delimitati da virgole; è possibile specificare le metriche da raccogliere. Ad esempio:jvm.heap.used |