Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come usare il plug-in Azure Toolkit for IntelliJ per sviluppare applicazioni Apache Spark scritte in Scala e quindi inviarle a un pool di Apache Spark serverless direttamente dall'ambiente di sviluppo integrato (IDE) di IntelliJ. È possibile usare il plug-in in vari modi:
- Sviluppare e inviare un'applicazione Spark in Scala in un pool di Spark.
- Accedere alle risorse dei pool di Spark.
- Sviluppare ed eseguire un'applicazione Spark in Scala localmente.
In questa esercitazione apprenderai a:
- Usare Azure Toolkit for IntelliJ
- Sviluppare applicazioni Apache Spark
- Inviare l'applicazione ai pool di Spark
Prerequisiti
Plug-in Azure Toolkit versione 3.27.0-2019.2 - Eseguire l'installazione dal repository di plug-in IntelliJ
Plug-in Scala - Eseguire l'installazione dal repository di plug-in IntelliJ.
Il prerequisito seguente si applica solo agli utenti di Windows:
Quando si esegue l'applicazione Spark Scala locale in un computer Windows, potrebbe essere restituita un'eccezione, come spiegato in SPARK-2356, che si verifica a causa di un file WinUtils.exe mancante in Windows. Per risolvere questo errore, scaricare il file eseguibile WinUtils in un percorso come C:\WinUtils\bin. È quindi necessario aggiungere una variabile di ambiente HADOOP_HOME e impostare il valore della variabile su C:\WinUtils.
Creare un'applicazione Spark in Scala per un pool di Spark
Avviare IntelliJ IDEA e selezionare Crea nuovo progetto per aprire la finestra Nuovo progetto.
Selezionare Apache Spark/HDInsight nel riquadro sinistro.
Selezionare Spark Project with Samples(Scala) (Progetto Spark con esempi (Scala)) dalla finestra principale.
Nell'elenco Strumento di compilazione selezionare uno dei tipi seguenti:
- Maven, per ottenere supporto per la creazione guidata di un progetto Scala.
- SBT, per la gestione delle dipendenze e la compilazione per il progetto Scala.
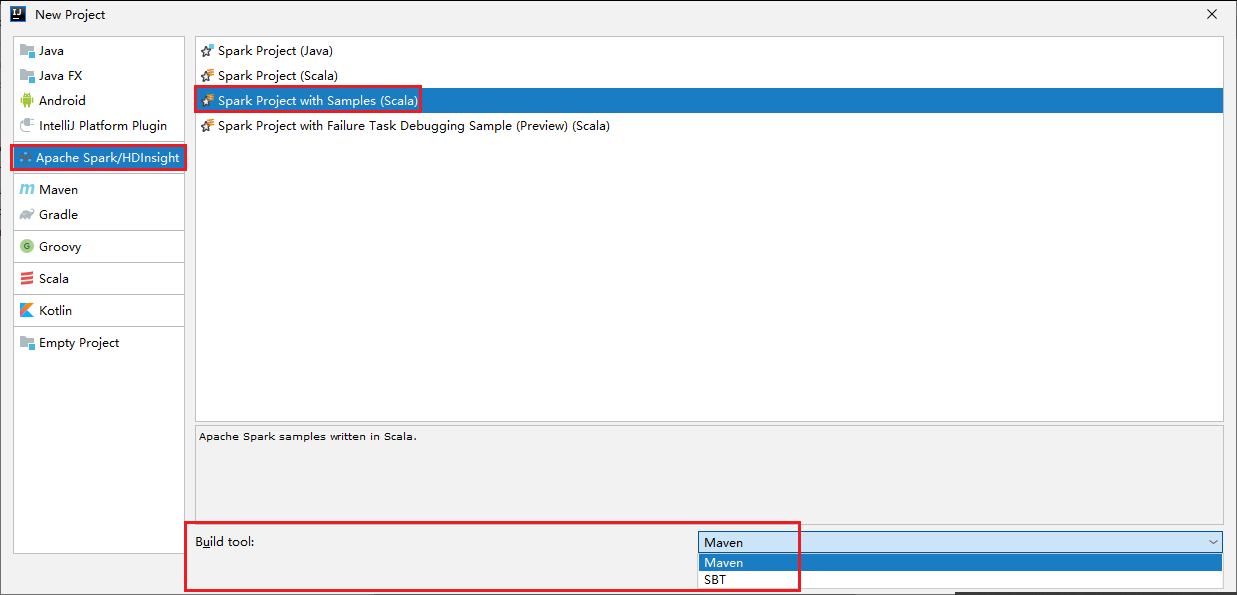
Selezionare Avanti.
Nella finestra Nuovo progetto specificare le informazioni seguenti:
Proprietà Descrizione Nome progetto Immetti un nome. In questa esercitazione viene usato myApp.Posizione del progetto Immettere il percorso desiderato in cui salvare il progetto. Project SDK (SDK progetto) Potrebbe essere vuoto al primo uso di IDEA. Selezionare New (Nuovo) e passare al proprio JDK. Versione Spark La creazione guidata integra la versione corretta dell'SDK di Spark e Scala. Qui è possibile scegliere la versione di Spark necessaria. 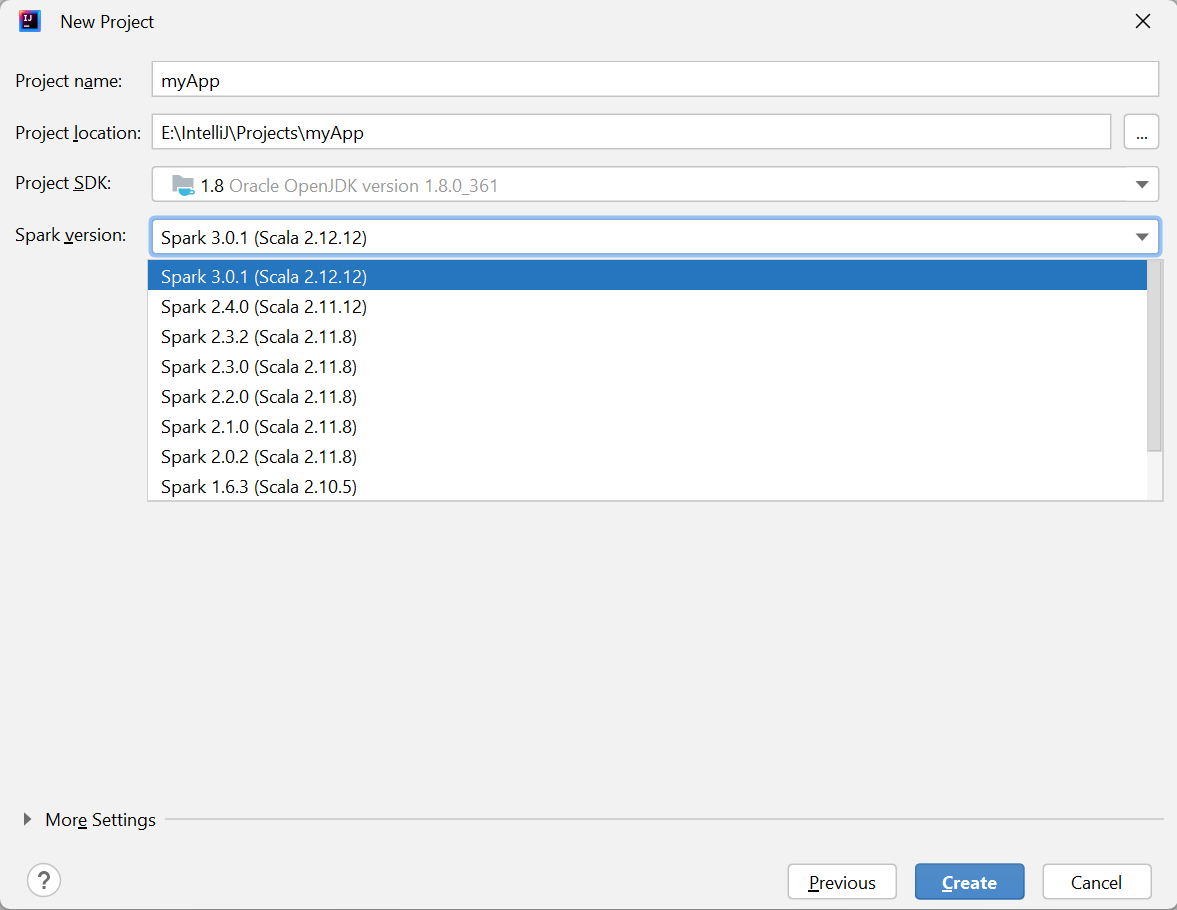
Selezionare Fine. Potrebbero occorrere alcuni minuti prima che il progetto diventi disponibile.
Il progetto Spark crea automaticamente un artefatto. Per visualizzare l'artefatto, eseguire questa operazione:
a. Dalla barra dei menu passare a File>Struttura del progetto....
b. Dalla finestra Struttura del progetto, selezionare Artefatti.
c. Selezionare Annulla dopo aver visualizzato l'elemento.
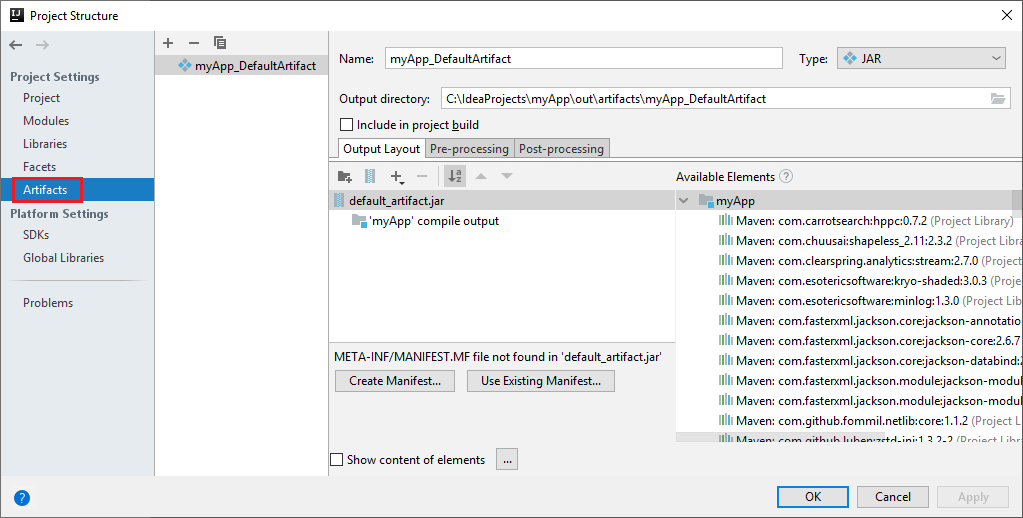
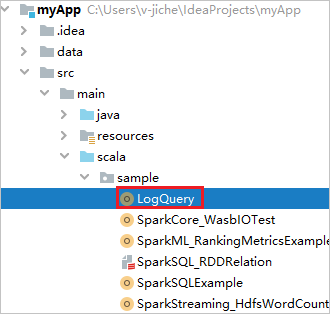
Trovare LogQuery in myApp>src>main>scala>sample>LogQuery. Questa esercitazione usa LogQuery per l'esecuzione.
Connettersi ai pool di Spark
Accedere alla sottoscrizione di Azure per connettersi ai pool di Spark.
Accedere alla sottoscrizione di Azure.
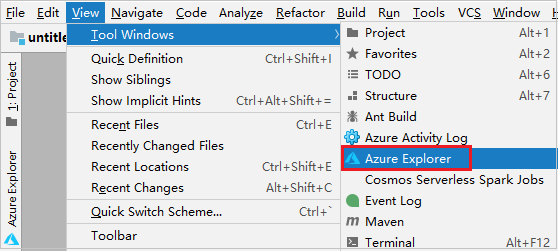
Dalla barra dei menu, passare a Visualizza>strumento Windows>Azure Explorer.
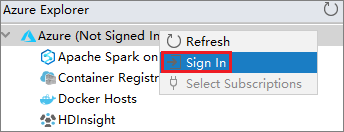
Da Azure Explorer, fare clic con il pulsante destro del mouse sul nodo Azure e quindi scegliere Sign In (Accedi).
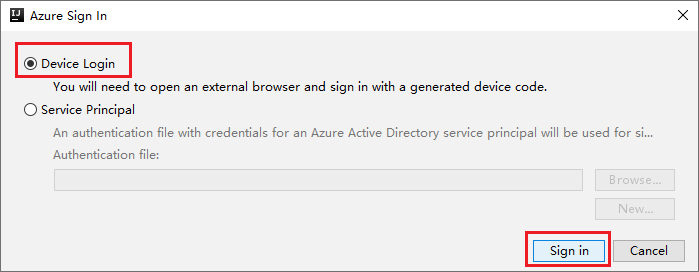
Nella finestra di dialogo Azure Sign In (Accesso ad Azure) scegliere Accesso dispositivo e quindi selezionare Accedi.
Nella finestra di dialogo Accesso dispositivo selezionare Copia e apri.
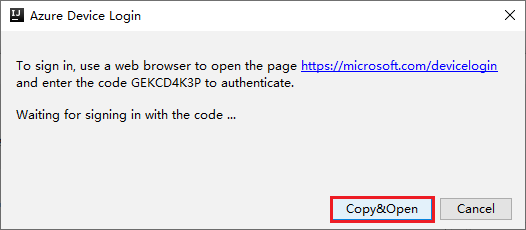
Nell'interfaccia del browser incollare il codice e quindi selezionare Avanti.
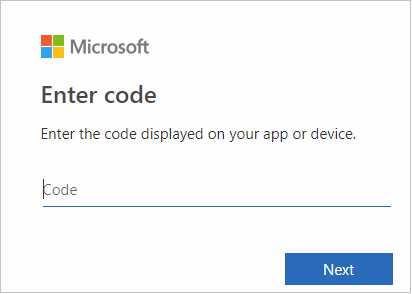
Immettere le credenziali di Azure e quindi chiudere il browser.
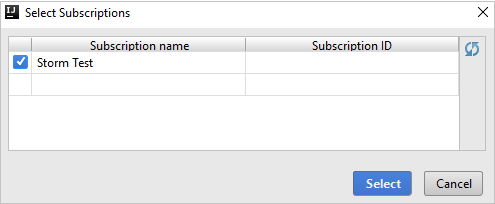
Dopo l'accesso, la finestra di dialogo Selezionare le sottoscrizioni elenca tutte le sottoscrizioni di Azure associate alle credenziali. Selezionare la sottoscrizione e quindi Seleziona.
In Azure Explorer espandere Apache Spark on Synapse (Apache Spark in Synapse) per visualizzare le aree di lavoro disponibili nelle sottoscrizioni.
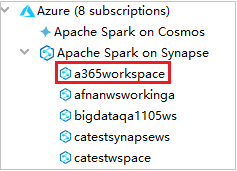
Per visualizzare i pool di Spark, è possibile espandere ulteriormente un'area di lavoro.
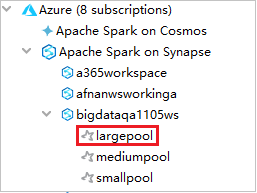
Eseguire in modalità remota un'applicazione Spark in Scala in un pool di Spark
Dopo aver creato un'applicazione Scala, è possibile eseguirla in modalità remota.
Aprire la finestra Run/Debug Configurations (Esecuzione/Debug configurazioni) selezionando l'icona.
Nella finestra di dialogo Run/Debug Configurations (Esecuzione/Debug configurazioni) selezionare + e quindi Apache Spark on Synapse.
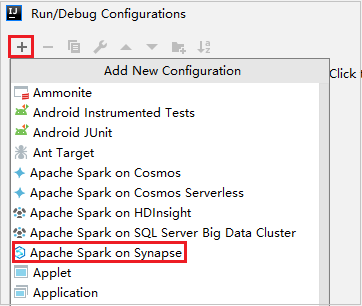
Nella finestra Run/Debug Configurations (Esecuzione/Debug configurazioni) specificare i valori seguenti e quindi selezionare OK:
Proprietà valore Pool di Spark Selezionare i pool di Spark in cui eseguire l'applicazione. Selezionare un artefatto da inviare Lasciare l'impostazione predefinita. Nome della classe principale Il valore predefinito corrisponde alla classe principale del file selezionato. È possibile modificare la classe selezionando i puntini di sospensione (...) e scegliendo una classe diversa. Configurazioni del processo È possibile modificare i valori e la chiave predefiniti. Per altre informazioni, vedere Apache Livy REST API (API REST di Apache Livy). Argomenti della riga di comando È possibile immettere gli argomenti divisi da uno spazio per la classe principale, se necessario. Referenced Jars (file JAR di riferimento) e Referenced Files (file di riferimento) È possibile immettere i percorsi per file e jar di riferimento, se presenti. È anche possibile selezionare i file nel file system virtuale di Azure, che attualmente supporta solo cluster di Azure Data Lake Storage Gen2. Per altre informazioni, vedere Configurazione di Apache Spark e Come caricare risorse nel cluster. Archivio di caricamento del processo Espandere per visualizzare le opzioni aggiuntive. Tipo di archiviazione Nell'elenco a discesa selezionare Use Azure Blob to upload (Usa BLOB di Azure per caricare) o Use cluster default storage account to upload (Usa l'account di archiviazione predefinito del cluster per caricare). Account di archiviazione Immettere l'account di archiviazione. Chiave di archiviazione Immettere la chiave di archiviazione. Contenitore di archiviazione Selezionare il contenitore di archiviazione dall'elenco a discesa una volta immessi Account di archiviazione e chiave di archiviazione. 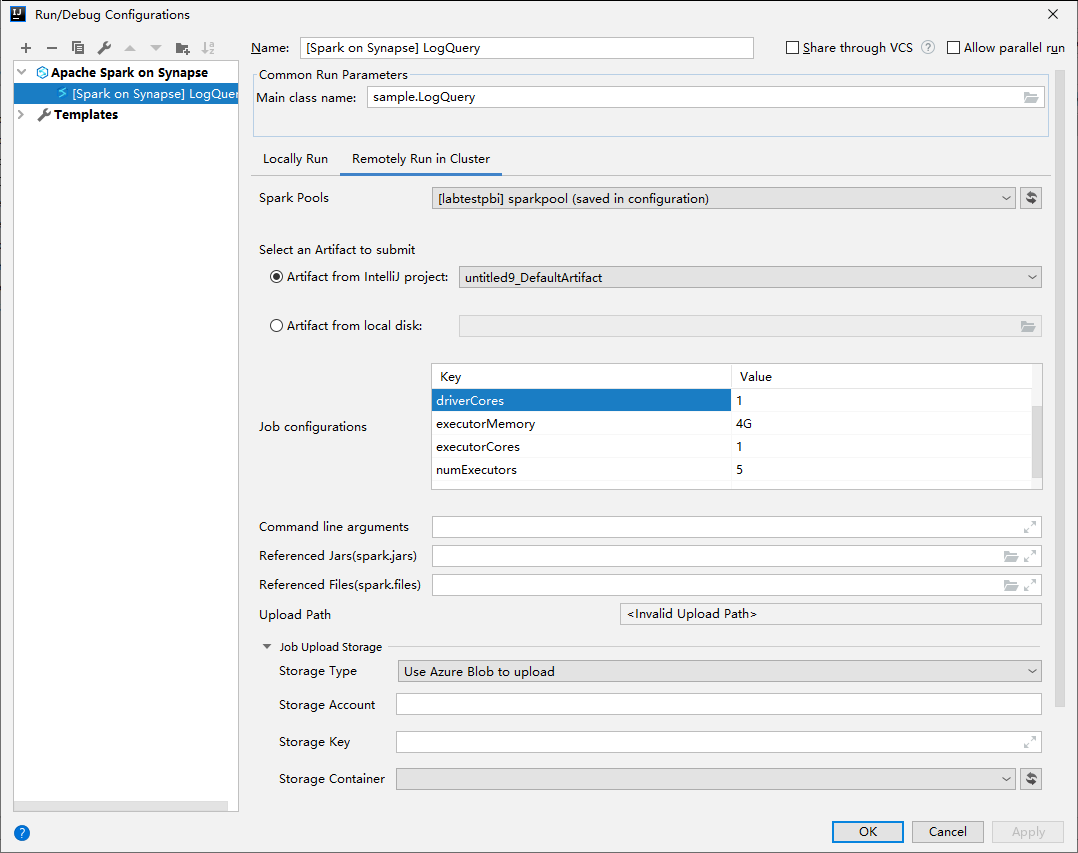
Selezionare l'icona SparkJobRun per inviare il progetto al pool di Spark selezionato. La scheda Remote Spark Job in Cluster (Processo Spark remoto nel cluster) visualizza lo stato dell'esecuzione del processo, nella parte inferiore. È possibile arrestare l'applicazione selezionando il rosso.

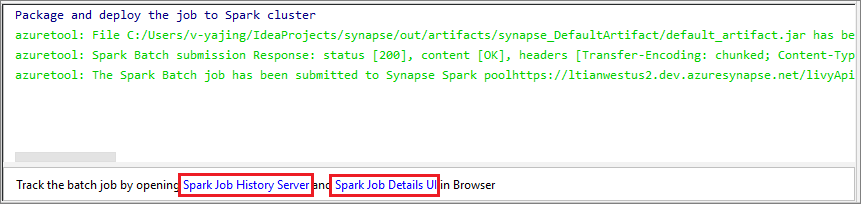
Esecuzione/Debug locale di applicazioni Apache Spark
È possibile seguire le istruzioni riportate di seguito per configurare l'esecuzione locale e il debug locale per il processo di Apache Spark.
Scenario 1: Eseguire l'esecuzione locale
Aprire la finestra di dialogo Run/Debug Configurations (Esecuzione/Debug configurazioni) e selezionare il segno più (+). Selezionare quindi l'opzione Apache Spark on Synapse (Apache Spark in Synapse). Per salvare, immettere le informazioni per Nome e Nome della classe principale.
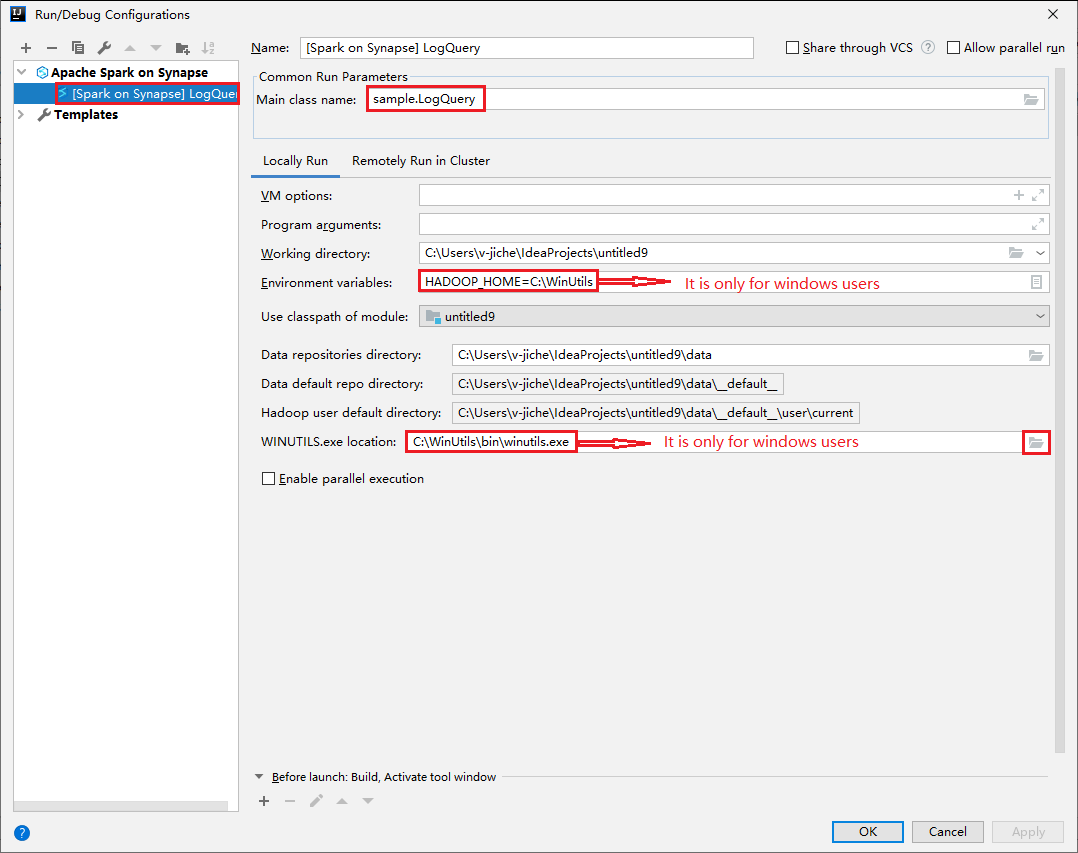
- Le variabili di ambiente e il percorso di WinUtils.exe sono validi solo per gli utenti di Windows.
- Variabili di ambiente: la variabile di ambiente del sistema può essere rilevata automaticamente se è stata impostata in precedenza e non è necessario aggiungerla manualmente.
- WinUtils.exe Location: è possibile specificare il percorso di WinUtils selezionando l'icona della cartella a destra.
Quindi selezionare il pulsante per la riproduzione locale.

Una volta completata l'esecuzione locale, se lo script include l'output, è possibile controllare il file di output da data>default (dati > predefinito).
Scenario 2: Eseguire il debug locale
Aprire lo script LogQuery e impostare i punti di interruzione.
Selezionare l'icona Local debug (Debug locale) per eseguire il debug locale.

Accedere e gestire l'area di lavoro Synapse
In Azure Explorer è possibile eseguire varie operazioni all'interno di Azure Toolkit for IntelliJ. Dalla barra dei menu, passare a Visualizza>strumento Windows>Azure Explorer.
Avviare l'area di lavoro
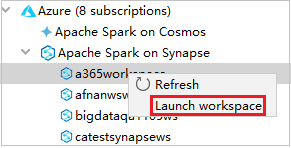
Da Azure Explorer passare a Apache Spark on Synapse (Apache Spark in Synapse) ed espandere la voce.
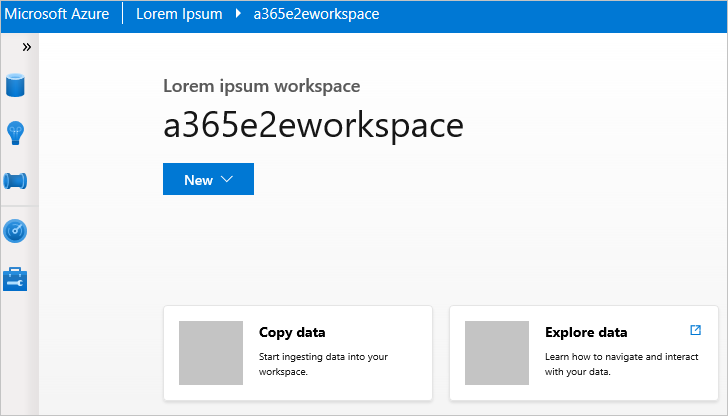
Fare clic con il pulsante destro del mouse su un'area di lavoro, scegliere Launch workspace per aprire il sito Web.
Console Spark
È possibile eseguire la console locale Spark (Scala) o eseguire la console della sessione Spark Livy interattiva (Scala).
Console locale Spark (Scala)
Assicurarsi di aver soddisfatto il prerequisito relativo al file WINUTILS.EXE.
Dalla barra dei menu passare a Run>Edit Configurations... (Esegui > Modifica configurazioni).
Dalla finestra Run/Debug Configurations (Esecuzione/Debug configurazioni) nel riquadro a sinistra, passare a Apache Spark on Synapse>[Spark on Synapse] myApp (Apache Spark in Synapse > [Spark in Synapse] myApp).
Nella finestra principale selezionare la scheda Locally Run (Esecuzione locale).
Specificare i valori seguenti e quindi selezionare OK:
Proprietà valore Variabili di ambiente Verificare che il valore di HADOOP_HOME sia corretto. WINUTILS.exe location (Percorso di WINUTILS.exe) Assicurarsi che il percorso sia corretto. 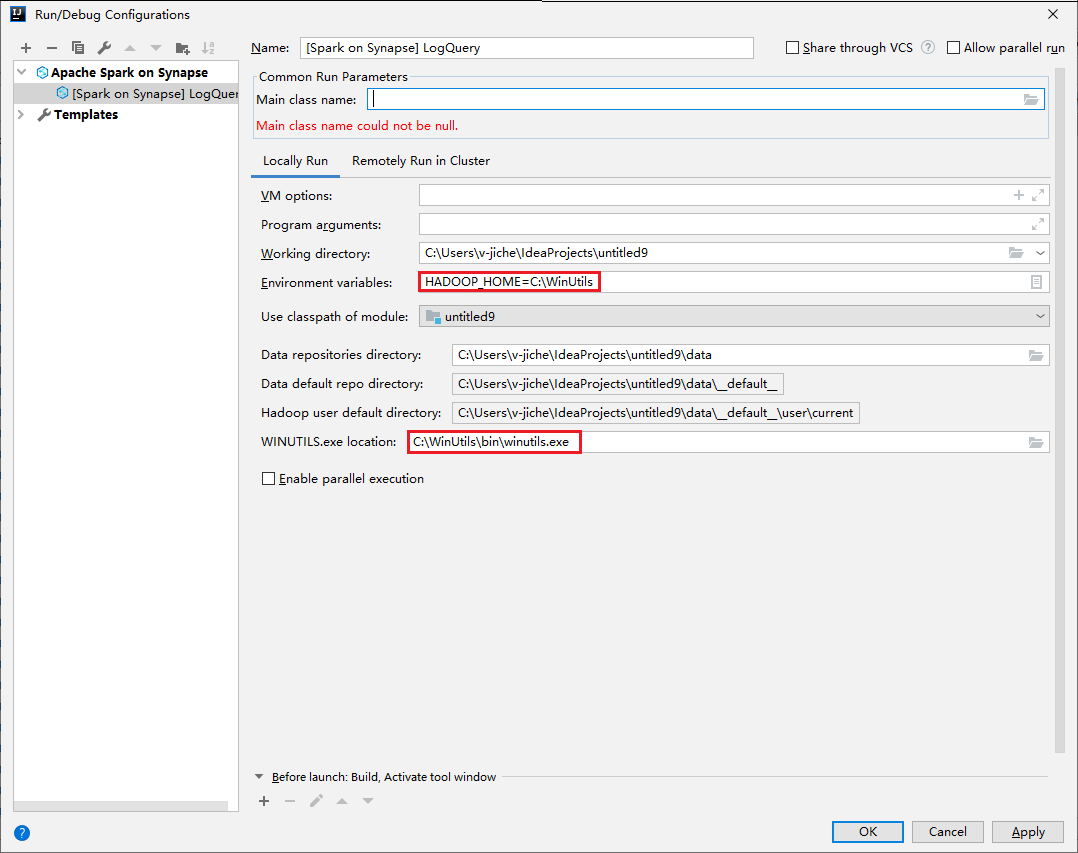
Da Project (Progetto) passare a myApp>src>main>scala>myApp.
Dalla barra dei menu passare a Tools>Spark Console>Run Spark Local Console(Scala) (Strumenti > Console Spark > Esegui console locale Spark - Scala).
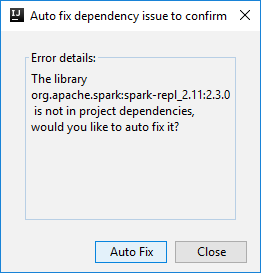
Potrebbero venire visualizzate due finestre di dialogo in cui viene chiesto se si vuole correggere automaticamente le dipendenze. In caso affermativo, selezionare Auto Fix (Correggi automaticamente).
La console dovrebbe essere simile all'immagine seguente. Nella finestra della console digitare
sc.appNamee quindi premere CTRL+INVIO. Verrà visualizzato il risultato. È possibile arrestare la console locale selezionando il pulsante rosso.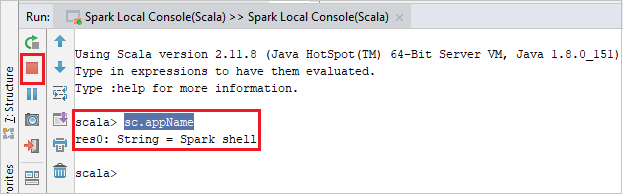
Console della sessione Spark Livy interattiva (Scala)
È supportata solo in IntelliJ 2018.2 e 2018.3.
Dalla barra dei menu passare a Run>Edit Configurations... (Esegui > Modifica configurazioni).
Dalla finestra Run/Debug Configurations (Esecuzione/Debug configurazioni) nel riquadro a sinistra, passare a Apache Spark on Synapse>[Spark on Synapse] myApp (Apache Spark in Synapse > [Spark in Synapse] myApp).
Dalla finestra principale selezionare la scheda Remotely Run in Cluster (Esecuzione remota nel cluster).
Specificare i valori seguenti e quindi selezionare OK:
Proprietà valore Nome della classe principale Selezionare il nome della classe principale. Pool di Spark Selezionare i pool di Spark in cui eseguire l'applicazione. 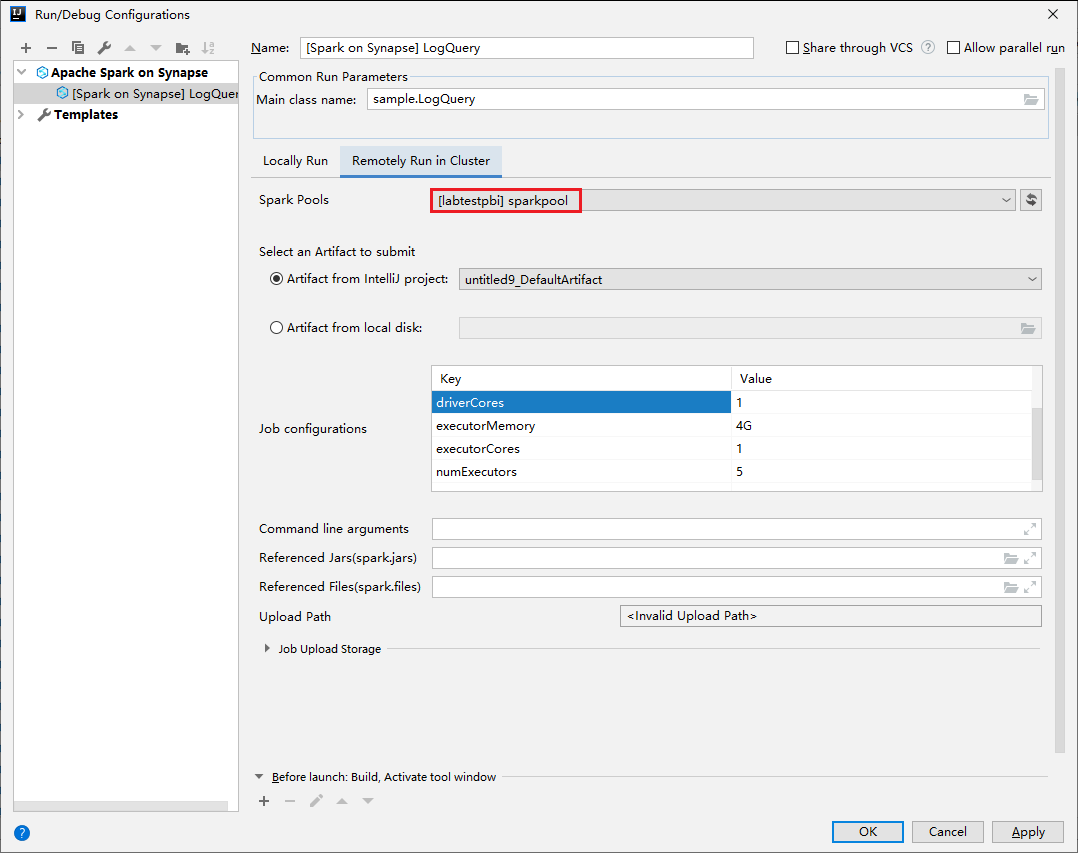
Da Project (Progetto) passare a myApp>src>main>scala>myApp.
Dalla barra dei menu passare a Tools>Spark Console>Run Spark Livy Interactive Session Console(Scala) (Strumenti > Console Spark > Esegui console della sessione Spark Livy interattiva -Scala).
La console dovrebbe essere simile all'immagine seguente. Nella finestra della console digitare
sc.appNamee quindi premere CTRL+INVIO. Verrà visualizzato il risultato. È possibile arrestare la console locale selezionando il pulsante rosso.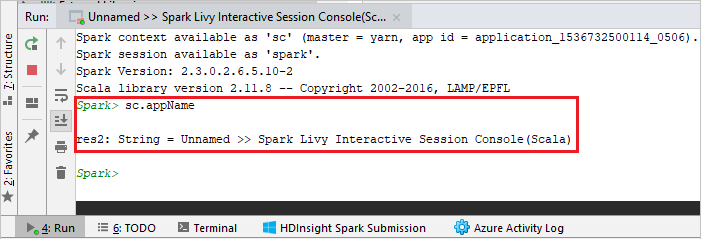
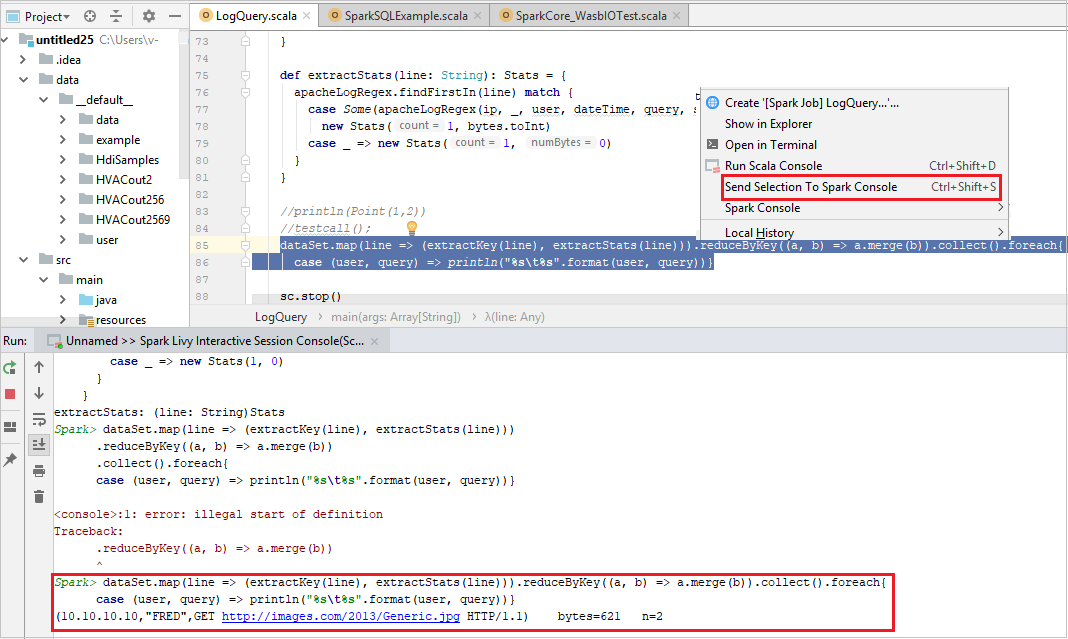
Inviare la selezione alla console Spark
È possibile scegliere di visualizzare il risultato dello script inviando codice alla console locale o alla console della sessione Livy interattiva (Scala). A tale scopo, è possibile evidenziare il codice nel file Scala e quindi fare clic con il pulsante destro del mouse su Send Selection To Spark Console (Invia selezione alla console Spark). Il codice selezionato verrà inviato alla console ed eseguito. Il risultato verrà visualizzato dopo il codice nella console. La console controllerà gli errori, se presenti.