Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
.NET per Apache Spark offre supporto .NET gratuito, open source e multipiattaforma per Spark.
Fornisce associazioni .NET per Spark, che consente di accedere alle API Spark tramite C# e F#. Con .NET per Apache Spark è anche possibile scrivere ed eseguire funzioni definite dall'utente per Spark scritte in .NET. Le API .NET per Spark consentono di accedere a tutti gli aspetti dei dataframe Spark che consentono di analizzare i dati, tra cui Spark SQL, Delta Lake e Structured Streaming.
È possibile analizzare i dati con .NET per Apache Spark tramite definizioni di processi batch Spark o con notebook interattivi di Azure Synapse Analytics. Questo articolo illustra come usare .NET per Apache Spark con Azure Synapse usando entrambe le tecniche.
Importante
.NET per Apache Spark è un progetto open source sotto la guida della .NET Foundation che attualmente richiede la libreria .NET 3.1, la quale ha raggiunto lo stato di non più supportata. Si vuole informare gli utenti di Azure Synapse Spark della rimozione della libreria .NET per Apache Spark nel runtime di Azure Synapse per Apache Spark versione 3.3. Gli utenti possono fare riferimento ai criteri di supporto di .NET per altri dettagli su questa questione.
Di conseguenza, non sarà più possibile per gli utenti usare le API Apache Spark tramite C# e F# oppure eseguire codice C# nei notebook all'interno di Synapse o tramite le definizioni dei processi Apache Spark in Synapse. È importante notare che questa modifica influisce solo sul runtime di Azure Synapse per Apache Spark 3.3 e versioni successive.
Microsoft continuerà a supportare .NET per Apache Spark in tutte le versioni precedenti del runtime di Azure Synapse in base alle fasi del ciclo di vita. Tuttavia, non sono previsti piani per supportare .NET per Apache Spark in Azure Synapse Runtime per Apache Spark 3.3 e versioni future. Si consiglia agli utenti con carichi di lavoro esistenti scritti in C# o F# di eseguire la migrazione a Python o Scala. Gli utenti sono invitati a prendere nota di queste informazioni e pianificare di conseguenza.
Inviare operazioni batch usando la definizione del compito Spark
Guarda il tutorial per informazioni su come usare Azure Synapse Analytics per creare definizioni di processi di lavoro Apache Spark per i pool di Synapse Spark. Se l'app non è stata inserita in un pacchetto per l'invio ad Azure Synapse, completare la procedura seguente.
dotnetConfigurare le dipendenze dell'applicazione per la compatibilità con Synapse Spark. La versione di .NET Spark necessaria verrà annotata nell'interfaccia di Synapse Studio nella configurazione del pool di Apache Spark nella casella degli strumenti Gestisci.
Creare il progetto come applicazione console .NET che genera un eseguibile Ubuntu x86.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Eseguire i comandi seguenti per pubblicare l'app. Assicurarsi di sostituire mySparkApp con il percorso dell'app.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Comprimere il contenuto della cartella di pubblicazione,
publish.zipad esempio, creato come risultato del passaggio 1. Tutti gli assembly devono trovarsi nella radice del file ZIP e non deve essere presente alcun livello di cartella intermedio. Ciò significa che quando si decomprimepublish.zip, tutti gli assembly vengono estratti nella directory di lavoro corrente.In Windows:
Usando Windows PowerShell o PowerShell 7, creare un .zip dal contenuto della directory di pubblicazione.
Compress-Archive publish/* publish.zip -UpdateIn Linux:
Aprire una shell bash, accedere alla directory bin che contiene tutti i file binari pubblicati ed eseguire il comando seguente.
zip -r publish.zip
.NET per Apache Spark in notebook di Azure Synapse Analytics
I notebook sono un'ottima opzione per creare prototipi di pipeline e scenari .NET per Apache Spark. È possibile iniziare a lavorare con, comprendere, filtrare, visualizzare e rappresentare i dati in modo rapido ed efficiente.
I data engineer, i data scientist, gli analisti aziendali e i tecnici di Machine Learning sono tutti in grado di collaborare su un documento condiviso e interattivo. Vedi risultati immediati dall'esplorazione dei dati e puoi visualizzare i tuoi dati nello stesso notebook.
Come usare .NET per notebook Apache Spark
Quando si crea un nuovo notebook, si sceglie un kernel di linguaggio per esprimere la vostra logica di business. Il supporto del kernel è disponibile per diversi linguaggi, tra cui C#.
Per usare .NET per Apache Spark nel notebook di Azure Synapse Analytics, selezionare .NET Spark (C#) come kernel e collegare il notebook a un pool di Apache Spark serverless esistente.
Il notebook .NET Spark si basa sulle esperienze interattive .NET e offre esperienze C# interattive con la possibilità di usare .NET per Spark immediatamente utilizzando la variabile di sessione Spark spark già preimpostata.
Installare pacchetti NuGet nei notebook
È possibile installare pacchetti NuGet di propria scelta nel notebook usando il #r nuget comando magic prima del nome del pacchetto NuGet. Il diagramma seguente illustra un esempio:
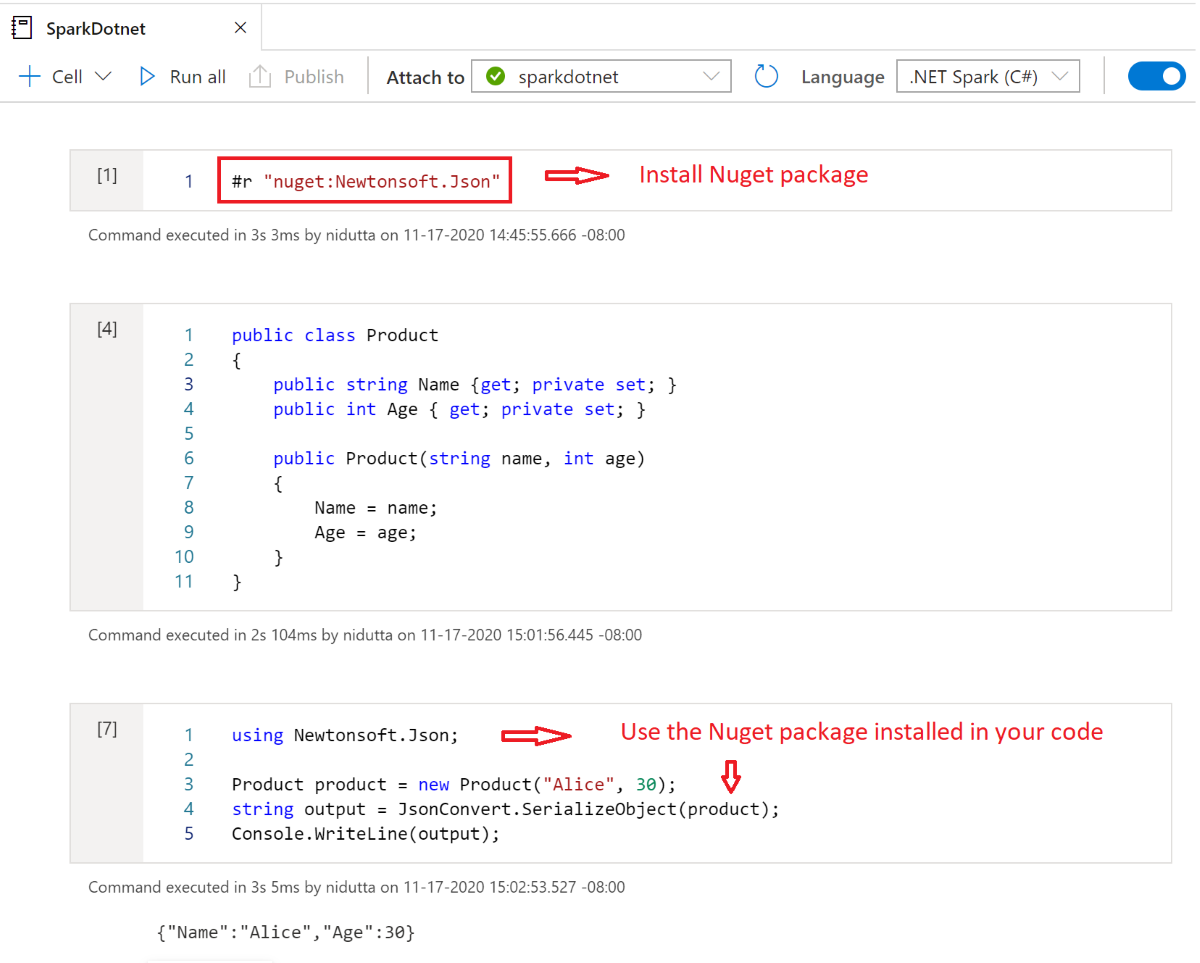
Per altre informazioni su come usare i pacchetti NuGet nei notebook, vedere la documentazione interattiva di .NET.
Funzionalità del kernel .NET per Apache Spark C#
Quando si usa .NET per Apache Spark nel notebook di Azure Synapse Analytics, sono disponibili le funzionalità seguenti:
- HTML dichiarativo: genera l'output dalle celle usando la sintassi HTML, ad esempio intestazioni, elenchi puntati e persino visualizzazione di immagini.
- Semplici istruzioni C#, ad esempio assegnazioni, stampa nella console, generazione di eccezioni e così via.
- Blocchi di codice C# a più righe, ad esempio istruzioni if, cicli foreach, definizioni di classi e così via.
- Accesso alla libreria C# standard, ad esempio System, LINQ, Enumerables e così via.
- Supporto per le funzionalità del linguaggio C# 8.0.
-
sparkcome variabile predefinita per concedere l'accesso alla sessione di Apache Spark. - Supporto per la definizione di funzioni definite dall'utente .NET che possono essere eseguite in Apache Spark. È consigliabile scrivere e chiamare UDF per le esperienze interattive in ambienti .NET per Apache Spark per imparare a usare UDF in .NET per esperienze interattive Apache Spark.
- Supporto per la visualizzazione dell'output dai processi Spark usando grafici diversi ( ad esempio linee, barre o istogrammi) e layout (ad esempio singolo, sovrapposto e così via) usando la
XPlot.Plotlylibreria. - Possibilità di includere pacchetti NuGet nel notebook C#.
Risoluzione dei problemi
OutOfMemoryError: spazio heap java all'indirizzo org.apache.spark
Dotnet Spark 1.0.0 usa un'architettura di debug diversa da 1.1.1+. Sarà necessario usare la versione 1.0.0 per la versione pubblicata e la versione 1.1.1+ per il debug locale.