Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il team di Azure Synapse Studio ha creato due nuove API di montaggio/smontaggio nel pacchetto Microsoft Spark Utilities (mssparkutils). È possibile usare queste API per collegare l'archiviazione remota (Azure Blob Storage, Azure Data Lake Storage Gen2 o Azure condivisione file) a tutti i nodi di lavoro (nodo driver e nodi di lavoro). Al termine dell'archiviazione, è possibile usare l'API file locale per accedere ai dati come se fossero archiviati nel file system locale. Per altre informazioni, vedere Introduction to Microsoft Spark Utilities.
L'articolo illustra come usare le API di montaggio/smontaggio nell'area di lavoro. Si apprenderà:
- Come montare Data Lake Storage Gen2, Blob Storage o Azure condivisione file.
- Come accedere ai file nel punto di montaggio tramite l'API del file system locale.
- Come accedere ai file nel punto di montaggio usando l'API
mssparkutils fs. - Come accedere ai file nel punto di montaggio usando l'API di lettura Spark.
- Come smontare il punto di montaggio.
Avviso
Azure Data Lake Storage Gen1 archiviazione non è supportata. È possibile eseguire la migrazione a Data Lake Storage Gen2 seguendo le linee guida per la migrazione di Azure Data Lake Storage Gen1 a Gen2 prima di usare le API di montaggio.
Montare l'archiviazione
Questa sezione illustra come montare Data Lake Storage Gen2 passaggio per passaggio come esempio. Il montaggio di Blob Storage e Azure condivisione file funziona in modo analogo.
Nell'esempio si presuppone che si disponga di un account Data Lake Storage Gen2 denominato storegen2. L'account ha un contenitore denominato mycontainer che si vuole montare /test nel pool di Spark.
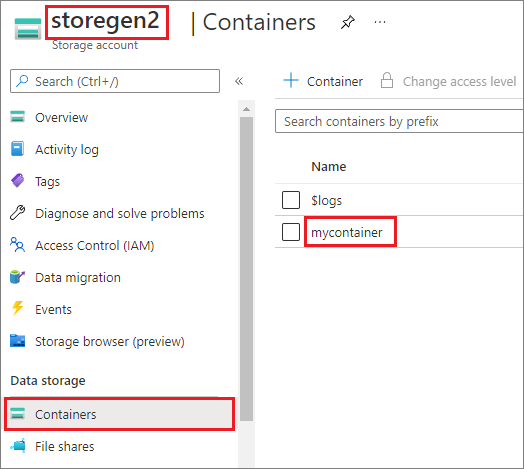
Per montare il contenitore denominato mycontainer, mssparkutils è prima necessario verificare se si dispone dell'autorizzazione per accedere al contenitore. Attualmente, Azure Synapse Analytics supporta tre metodi di autenticazione per l'operazione di montaggio del trigger: linkedService, accountKey e sastoken.
Montare usando un servizio collegato (scelta consigliata)
È consigliabile montare un trigger tramite il servizio collegato. Questo metodo evita perdite di sicurezza, perché mssparkutils non archivia alcun segreto o valori di autenticazione. Recupera invece mssparkutils sempre i valori di autenticazione dal servizio collegato per richiedere i dati BLOB dall'archiviazione remota.
È possibile creare un servizio collegato per Data Lake Storage Gen2 o Blob Storage. Attualmente, Azure Synapse Analytics supporta due metodi di autenticazione quando si crea un servizio collegato:
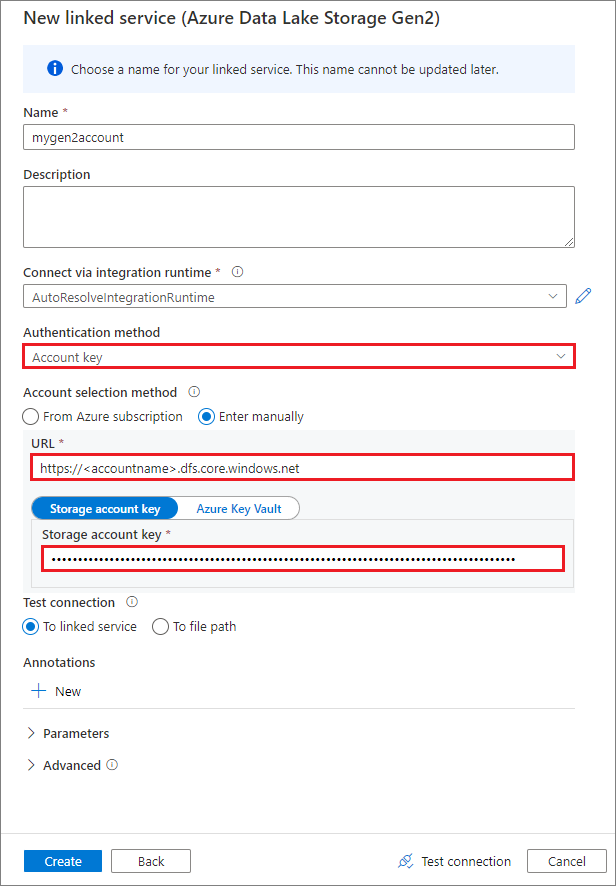
Creare un servizio collegato usando una chiave dell'account
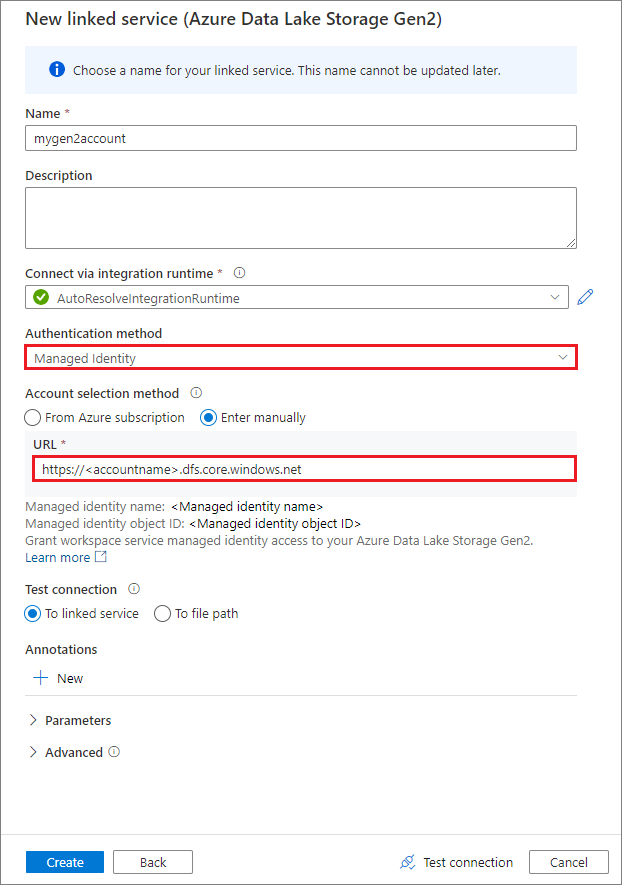
Creare un servizio collegato usando un'identità gestita assegnata dal sistema
Importante
- Se il servizio collegato precedentemente creato per Azure Data Lake Storage Gen2 usa un endpoint privato gestito (con un dfs) , è necessario creare un altro endpoint privato gestito secondario usando il Azure Blob Storage opzione (con un URI blob) per assicurarsi che il codice interno fsspec/adlfs possa connettersi usando l'interfaccia BlobServiceClient.
- Nel caso in cui l'endpoint privato gestito secondario non sia configurato correttamente, verrà visualizzato un messaggio di errore simile a ServiceRequestError: Impossibile connettersi all'host [storageaccountname].blob.core.windows.net:443 ssl:True [Nome o servizio sconosciuto]
Nota
Se si crea un servizio collegato usando un'identità gestita come metodo di autenticazione, assicurarsi che il file MSI dell'area di lavoro abbia il ruolo Collaboratore ai dati dei BLOB di archiviazione del contenitore montato.
Dopo aver creato correttamente il servizio collegato, è possibile montare facilmente il contenitore nel pool di Spark usando il codice Python seguente:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Nota
Potrebbe essere necessario importare mssparkutils se non è disponibile:
from notebookutils import mssparkutils
Non è consigliabile montare una cartella radice, indipendentemente dal metodo di autenticazione usato.
Parametri di montaggio:
- fileCacheTimeout: i BLOB verranno memorizzati nella cache nella cartella temporanea locale per 120 secondi per impostazione predefinita. Durante questo periodo, blobfuse non verificherà se il file è aggiornato o meno. È possibile impostare il parametro per modificare il timeout predefinito. Quando più client modificano contemporaneamente i file, per evitare incoerenze tra file locali e remoti, è consigliabile abbreviare il tempo di cache o persino modificarlo su 0 e ottenere sempre i file più recenti dal server.
- timeout: il timeout dell'operazione di montaggio è 120 secondi per impostazione predefinita. È possibile impostare il parametro per modificare il timeout predefinito. Quando sono presenti troppi executor o quando si verifica il timeout del montaggio, è consigliabile aumentare il valore.
- scope: il parametro di ambito viene usato per specificare l'ambito del montaggio. Il valore predefinito è "job". Se l'ambito è impostato su "processo", il montaggio è visibile solo al cluster corrente. Se l'ambito è impostato su "area di lavoro", il montaggio è visibile a tutti i notebook nell'area di lavoro corrente e il punto di montaggio viene creato automaticamente se non esiste. Aggiungere gli stessi parametri all'API di smontaggio per smontare il punto di montaggio. Il montaggio a livello di area di lavoro è supportato solo per l'autenticazione del servizio collegato.
È possibile usare questi parametri come indicato di seguito:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Montaggio tramite token di firma di accesso condiviso o chiave dell'account
Oltre al montaggio tramite un servizio collegato, mssparkutils supporta il passaggio esplicito di una chiave dell'account o di un token di firma di accesso condiviso (SAS) come parametro per montare la destinazione.
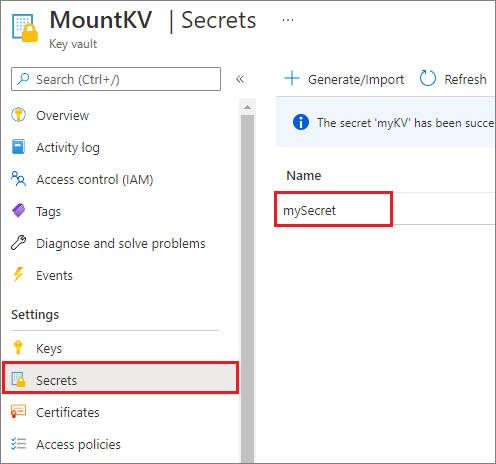
Per motivi di sicurezza, è consigliabile usare le identità gestite e l'autenticazione Microsoft Entra anziché le chiavi dell'account o i token di firma di accesso condiviso, quando possibile. Se è necessario usare le chiavi dell'account, archiviarle in Azure Key Vault (come illustrato nello screenshot di esempio seguente). È quindi possibile recuperarli usando l'API mssparkutil.credentials.getSecret . Per altre informazioni, vedere Autorizzare l'accesso ai dati in Azure Storage.
Ecco il codice di esempio:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Nota
Per motivi di sicurezza, non archiviare le credenziali nel codice.
Accedere ai file nel punto di montaggio usando l'API mssparkutils fs
Lo scopo principale dell'operazione di montaggio è consentire ai clienti di accedere ai dati archiviati in un account di archiviazione remoto usando un'API del file system locale. È anche possibile accedere ai dati usando l'API mssparkutils fs con un percorso montato come parametro. Il formato del percorso usato qui è leggermente diverso.
Supponendo di aver montato il contenitore Data Lake Storage Gen2 mycontainer in /test usando l'API di montaggio. Quando si accede ai dati tramite un'API del file system locale:
- Per le versioni di Spark minori o uguali a 3.3, il formato del percorso è
/synfs/{jobId}/test/{filename}. - Per le versioni di Spark maggiori o uguali a 3.4, il formato del percorso è
/synfs/notebook/{jobId}/test/{filename}.
È consigliabile usare un mssparkutils.fs.getMountPath() per ottenere il percorso accurato:
path = mssparkutils.fs.getMountPath("/test")
Nota
Quando si monta l'archiviazione con workspace ambito, il punto di montaggio viene creato nella /synfs/workspace cartella . Ed è necessario usare mssparkutils.fs.getMountPath("/test", "workspace") per ottenere il percorso accurato.
Quando si vuole accedere ai dati usando l'API mssparkutils fs , il formato del percorso è simile al seguente: synfs:/notebook/{jobId}/test/{filename}. È possibile osservare che synfs viene usato come schema in questo caso, anziché come parte del percorso montato. Naturalmente, è anche possibile usare lo schema del file system locale per accedere ai dati. Ad esempio: file:/synfs/notebook/{jobId}/test/{filename}.
I tre esempi seguenti illustrano come accedere a un file con un percorso del punto di montaggio usando mssparkutils fs.
Elencare directory:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Leggere il contenuto del file:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Creare una directory:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Accedere ai file nel punto di montaggio usando l'API di lettura Spark
È possibile specificare un parametro per accedere ai dati tramite l'API di lettura Spark. Il formato del percorso è lo stesso quando si usa l'API mssparkutils fs .
Leggere un file da un account di archiviazione Data Lake Storage Gen2 montato
Nell'esempio seguente si presuppone che un account di archiviazione Data Lake Storage Gen2 sia già stato montato e quindi il file venga letto usando un percorso di montaggio:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Nota
Quando si monta l'archiviazione usando un servizio collegato, è consigliabile impostare in modo esplicito la configurazione del servizio collegato Spark prima di usare lo schema synfs per accedere ai dati. Per informazioni dettagliate, vedere Archiviazione di ADLS Gen2 con i servizi collegati.
Leggere un file da un account Blob Storage montato
Se è stato montato un account Blob Storage e si vuole accedervi usando mssparkutils o l'API Spark, è necessario configurare in modo esplicito il token di firma di accesso condiviso tramite la configurazione di Spark prima di provare a montare il contenitore usando l'API di montaggio:
Per accedere a un account Blob Storage usando
mssparkutilso l'API Spark dopo un montaggio di trigger, aggiornare la configurazione di Spark come illustrato nell'esempio di codice seguente. È possibile ignorare questo passaggio se si vuole accedere alla configurazione di Spark solo usando l'API file locale dopo il montaggio.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Creare il servizio collegato
myblobstorageaccounte montare l'account Blob Storage usando il servizio collegato:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Montare il contenitore Blob Storage e quindi leggere il file usando un percorso di montaggio tramite l'API file locale:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Leggere i dati dal contenitore Blob Storage montato tramite l'API di lettura Spark:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Smontare il punto di montaggio
Usare il codice seguente per smontare il punto di montaggio (/test in questo esempio):
mssparkutils.fs.unmount("/test")
Limitazioni note
Il meccanismo di smontaggio non è automatico. Al termine dell'esecuzione dell'applicazione, per smontare il punto di montaggio per rilasciare lo spazio su disco, è necessario chiamare in modo esplicito un'API di smontaggio nel codice. In caso contrario, il punto di montaggio esisterà ancora nel nodo al termine dell'esecuzione dell'applicazione.
Il montaggio di un account di archiviazione Data Lake Storage Gen1 non è supportato per il momento.