Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Microsoft Spark Utilities (MSSparkUtils) è un pacchetto predefinito che consente di eseguire facilmente attività comuni. È possibile usare MSSparkUtils per lavorare con i file system, per ottenere variabili di ambiente, per concatenare i notebook e per lavorare con i segreti. MSSparkUtils è disponibile in PySpark (Python)notebook , Scala.NET Spark (C#), e e R (Preview) e nelle pipeline synapse.
Prerequisiti
Configurare l'accesso ad Azure Data Lake Storage Gen2
I notebook di Synapse usano il pass-through Di Microsoft Entra per accedere agli account ADLS Gen2. È necessario essere un Collaboratore ai dati dei BLOB di archiviazione per accedere all'account ADLS Gen2 (o alla cartella).
Le pipeline di Synapse usano l'identità del servizio gestito dell'area di lavoro per accedere agli account di archiviazione. Per usare MSSparkUtils nelle attività della pipeline, l'identità dell'area di lavoro deve essere Collaboratore ai dati dei BLOB di archiviazione per accedere all'account o alla cartella ADLS Gen2.
Seguire questa procedura per assicurarsi che l'IDENTITÀ dell'area di lavoro e l'IDENTITÀ dell'area di lavoro Microsoft Entra abbiano accesso all'account ADLS Gen2:
Aprire il portale di Azure e l'account di archiviazione a cui si vuole accedere. È possibile passare al contenitore specifico a cui si vuole accedere.
Selezionare Controllo di accesso (IAM) nel pannello sinistro.
Selezionare Aggiungi>Aggiungi assegnazione di ruolo per aprire la pagina Aggiungi assegnazione di ruolo.
Assegnare il ruolo seguente. Per la procedura dettagliata, vedere Assegnare ruoli di Azure usando il portale di Azure.
Impostazione Valore Ruolo Collaboratore dati BLOB di archiviazione Assegna accesso a USER e MANAGEDIDENTITY Membri l'account Microsoft Entra e l'identità dell'area di lavoro Nota
Il nome dell'identità gestita è anche il nome dell'area di lavoro.
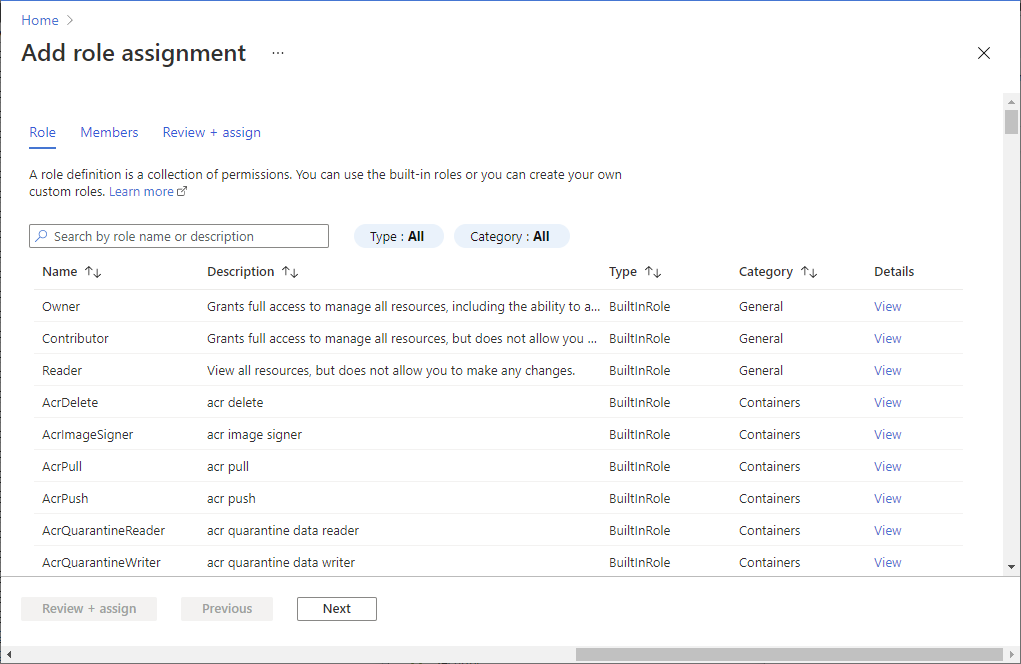
Seleziona Salva.
È possibile accedere ai dati in ADLS Gen2 con Synapse Spark tramite l'URL seguente:
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Configurare l'accesso a Archiviazione BLOB di Azure
Synapse usa la firma di accesso condiviso (SAS) per accedere alle Archiviazione BLOB di Azure. Per evitare di esporre le chiavi di firma di accesso condiviso nel codice, è consigliabile creare un nuovo servizio collegato nell'area di lavoro di Synapse all'account Archiviazione BLOB di Azure a cui si vuole accedere.
Seguire questa procedura per aggiungere un nuovo servizio collegato per un account Archiviazione BLOB di Azure:
- Aprire Azure Synapse Studio.
- Selezionare Gestisci nel pannello sinistro e selezionare Servizi collegati in Connessioni esterne.
- Cercare Archiviazione BLOB di Azure nel pannello Nuovo servizio collegato a destra.
- Selezionare Continua.
- Selezionare il Archiviazione BLOB di Azure Account per accedere e configurare il nome del servizio collegato. Suggerire l'uso della chiave account per il metodo di autenticazione.
- Selezionare Test connessione per verificare che le impostazioni siano corrette.
- Selezionare Crea prima e fare clic su Pubblica tutto per salvare le modifiche.
È possibile accedere ai dati in Archiviazione BLOB di Azure con Synapse Spark tramite l'URL seguente:
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Ecco un esempio di codice:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Configurare l'accesso ad Azure Key Vault
È possibile aggiungere un'istanza di Azure Key Vault come servizio collegato per gestire le credenziali in Synapse. Seguire questa procedura per aggiungere un'istanza di Azure Key Vault come servizio collegato Synapse:
Selezionare Gestisci nel pannello sinistro e selezionare Servizi collegati in Connessioni esterne.
Cercare Azure Key Vault nel pannello Nuovo servizio collegato a destra.
Selezionare l'account di Azure Key Vault per accedere e configurare il nome del servizio collegato.
Selezionare Test connessione per verificare che le impostazioni siano corrette.
Selezionare Crea prima e fare clic su Pubblica tutto per salvare la modifica.
I notebook di Synapse usano il pass-through Microsoft Entra per accedere ad Azure Key Vault. Le pipeline di Synapse usano l'identità dell'area di lavoro per accedere ad Azure Key Vault. Per assicurarsi che il codice funzioni sia nel notebook che nella pipeline di Synapse, è consigliabile concedere l'autorizzazione di accesso segreto sia per l'account Microsoft Entra che per l'identità dell'area di lavoro.
Seguire questa procedura per concedere l'accesso segreto all'identità dell'area di lavoro:
- Aprire il portale di Azure e l'insieme di credenziali delle chiavi di Azure a cui si vuole accedere.
- Selezionare i criteri di accesso nel pannello sinistro.
- Selezionare Aggiungi criteri di accesso:
- Scegliere Chiave, Segreto e Gestione certificati come modello di configurazione.
- Selezionare l'account Microsoft Entra e l'identità dell'area di lavoro (uguale al nome dell'area di lavoro) nell'entità di selezione o assicurarsi che sia già assegnata.
- Selezionare Seleziona e aggiungi.
- Selezionare il pulsante Salva per eseguire il commit delle modifiche.
Utilità di file system
mssparkutils.fsfornisce utilità per l'uso di vari file system, tra cui Azure Data Lake Storage Gen2 (ADLS Gen2) e Archiviazione BLOB di Azure. Assicurarsi di configurare l'accesso ad Azure Data Lake Storage Gen2 e Archiviazione BLOB di Azure in modo appropriato.
Usare i comandi seguenti per una panoramica dei metodi disponibili:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
Il risultato è il seguente:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Elencare file
Elencare il contenuto di una directory.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Visualizzazione delle proprietà di file
Restituisce le proprietà del file, inclusi il nome file, il percorso del file, le dimensioni del file, l'ora di modifica del file e se si tratta di una directory e di un file.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Creare una nuova directory
Crea la directory specificata se non esiste e le directory padre necessarie.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Copia file
Copia un file o una directory. Supporta la copia tra file system.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
File di copia con prestazioni elevate
Questo metodo offre un modo più rapido per copiare o spostare file, in particolare volumi elevati di dati.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Nota
Il metodo supporta solo il runtime di Azure Synapse per Apache Spark 3.3 e Azure Synapse Runtime per Apache Spark 3.4.
Contenuto file in anteprima
Restituisce fino ai primi byte 'maxBytes' del file specificato come stringa codificata in UTF-8.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Sposta file
Sposta un file o una directory. Supporta lo spostamento tra file system.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Scrivere il file
Scrive la stringa specificata in un file codificato in UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Accodare contenuto a un file
Aggiunge la stringa specificata a un file codificato in UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Nota
-
mssparkutils.fs.append()emssparkutils.fs.put()non supportano la scrittura simultanea nello stesso file a causa della mancanza di garanzie di atomicità. - Quando si usa l'API
mssparkutils.fs.appendin unforciclo per scrivere nello stesso file, è consigliabile aggiungere un'istruzionesleepintorno a 0,5s~1s tra le scritture ricorrenti. Questo perché l'operazionemssparkutils.fs.appendinternaflushdell'API è asincrona, quindi un breve ritardo contribuisce a garantire l'integrità dei dati.
Eliminare un file o una directory
Rimuove un file o una directory.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Utilità notebook
Non supportato.
È possibile usare le utilità del notebook MSSparkUtils per eseguire un notebook o uscire da un notebook con un valore . Usare il comando seguente per ottenere una panoramica dei metodi disponibili:
mssparkutils.notebook.help()
Ottenere i risultati:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Nota
Le utilità notebook non sono applicabili per le definizioni processo Apache Spark (SJD).
Fare riferimento a un notebook
Fare riferimento a un notebook e restituirne il valore di uscita. È possibile eseguire chiamate di funzione di annidamento in un notebook in modo interattivo o in una pipeline. Il notebook a cui si fa riferimento verrà eseguito nel pool di Spark di cui il notebook chiama questa funzione.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Ad esempio:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
Al termine dell'esecuzione, verrà visualizzato un collegamento di snapshot denominato "Visualizza esecuzione notebook: Nome notebook" visualizzato nell'output della cella, è possibile fare clic sul collegamento per visualizzare lo snapshot per questa esecuzione specifica.

Fare riferimento all’esecuzione più notebook in parallelo
Il metodo mssparkutils.notebook.runMultiple() consente di eseguire più notebook in parallelo o con una struttura topologica predefinita. L'API usa un meccanismo di implementazione multithread all'interno di una sessione Spark, il che comporta che le risorse di calcolo vengono condivise dalle esecuzioni del notebook di riferimento.
Con mssparkutils.notebook.runMultiple() è possibile:
Eseguire più notebook contemporaneamente senza attendere il completamento di ognuno.
Specificare le dipendenze e l'ordine di esecuzione per i notebook usando un formato JSON semplice.
Ottimizzare l'uso delle risorse di calcolo Spark e ridurre i costi dei progetti Synapse.
Visualizzare gli snapshot di ogni record di esecuzione del notebook nell'output ed eseguire il debug/monitorare comodamente le attività del notebook.
Ottenere il valore di uscita di ogni attività di esecuzione e usarlo in attività downstream.
È anche possibile provare a eseguire mssparkutils.notebook.help("runMultiple") per trovare l'esempio e l'uso dettagliato.
Di seguito è riportato un semplice esempio di esecuzione di un elenco di notebook in parallelo usando questo metodo:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
Il risultato dell'esecuzione del notebook radice è il seguente:

Di seguito è riportato un esempio di notebook in esecuzione con struttura topologica con mssparkutils.notebook.runMultiple(). Usare questo metodo per orchestrare facilmente i notebook tramite un'esperienza di codice.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Nota
- Il metodo supporta solo il runtime di Azure Synapse per Apache Spark 3.3 e Azure Synapse Runtime per Apache Spark 3.4.
- Il grado di parallelismo dell'esecuzione di più notebook è limitato alla risorsa di calcolo totale disponibile di una sessione Spark.
Uscire da un notebook
Chiude un notebook con un valore. È possibile eseguire chiamate di funzione di annidamento in un notebook in modo interattivo o in una pipeline.
Quando si chiama una funzione exit() da un notebook in modo interattivo, Azure Synapse genererà un'eccezione, salterà l'esecuzione di celle secondarie e manterrà attiva la sessione Spark.
Quando si orchestra un notebook che chiama una
exit()funzione in una pipeline di Synapse, Azure Synapse restituirà un valore di uscita, completerà l'esecuzione della pipeline e arresterà la sessione Spark.Quando si chiama una
exit()funzione in un notebook a cui si fa riferimento, Azure Synapse interromperà l'ulteriore esecuzione nel notebook a cui si fa riferimento e continuerà a eseguire le celle successive nel notebook che chiamano larun()funzione. Ad esempio: Notebook1 ha tre celle e chiama unaexit()funzione nella seconda cella. Notebook2 ha cinque celle e chiamaterun(notebook1)nella terza cella. Quando si esegue Notebook2, Notebook1 verrà arrestato nella seconda cella quando si raggiunge laexit()funzione. Notebook2 continuerà a eseguire la quarta cella e la quinta cella.
mssparkutils.notebook.exit("value string")
Ad esempio:
Il notebook sample1 individua nella cartella/ con le due celle seguenti:
- la cella 1 definisce un parametro di input con valore predefinito impostato su 10.
- la cella 2 esce dal notebook con input come valore di uscita.
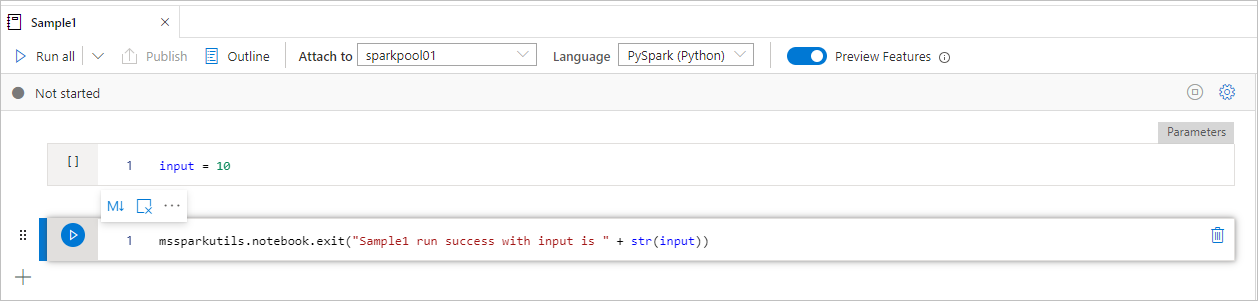
È possibile eseguire Sample1 in un altro notebook con i valori predefiniti:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Il risultato è il seguente:
Sample1 run success with input is 10
È possibile eseguire Sample1 in un altro notebook e impostare il valore di input su 20:
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
Il risultato è il seguente:
Sample1 run success with input is 20
È possibile usare le utilità del notebook MSSparkUtils per eseguire un notebook o uscire da un notebook con un valore . Usare il comando seguente per ottenere una panoramica dei metodi disponibili:
mssparkutils.notebook.help()
Ottenere i risultati:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Fare riferimento a un notebook
Fare riferimento a un notebook e restituirne il valore di uscita. È possibile eseguire chiamate di funzione di annidamento in un notebook in modo interattivo o in una pipeline. Il notebook a cui si fa riferimento verrà eseguito nel pool di Spark di cui il notebook chiama questa funzione.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Ad esempio:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
Al termine dell'esecuzione, verrà visualizzato un collegamento di snapshot denominato "Visualizza esecuzione notebook: Nome notebook" visualizzato nell'output della cella, è possibile fare clic sul collegamento per visualizzare lo snapshot per questa esecuzione specifica.
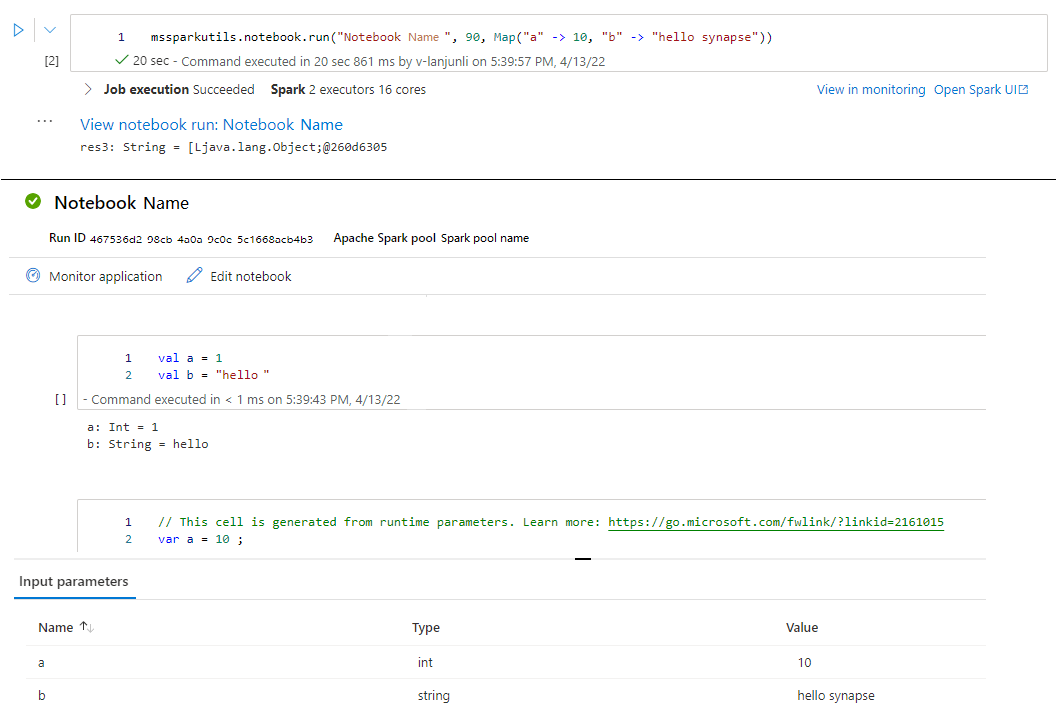
Uscire da un notebook
Chiude un notebook con un valore. È possibile eseguire chiamate di funzione di annidamento in un notebook in modo interattivo o in una pipeline.
Quando si chiama una funzione in
exit()modo interattivo, Azure Synapse genererà un'eccezione, ignora l'esecuzione di celle secondarie e mantiene attiva la sessione Spark.Quando si orchestra un notebook che chiama una
exit()funzione in una pipeline di Synapse, Azure Synapse restituirà un valore di uscita, completerà l'esecuzione della pipeline e arresterà la sessione Spark.Quando si chiama una
exit()funzione in un notebook a cui si fa riferimento, Azure Synapse interromperà l'ulteriore esecuzione nel notebook a cui si fa riferimento e continuerà a eseguire le celle successive nel notebook che chiamano larun()funzione. Ad esempio: Notebook1 ha tre celle e chiama unaexit()funzione nella seconda cella. Notebook2 ha cinque celle e chiamaterun(notebook1)nella terza cella. Quando si esegue Notebook2, Notebook1 verrà arrestato nella seconda cella quando si raggiunge laexit()funzione. Notebook2 continuerà a eseguire la quarta cella e la quinta cella.
mssparkutils.notebook.exit("value string")
Ad esempio:
Sample1 notebook individua in mssparkutils/folder/ con le due celle seguenti:
- la cella 1 definisce un parametro di input con valore predefinito impostato su 10.
- la cella 2 esce dal notebook con input come valore di uscita.
È possibile eseguire Sample1 in un altro notebook con i valori predefiniti:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
Il risultato è il seguente:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
È possibile eseguire Sample1 in un altro notebook e impostare il valore di input su 20:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
Il risultato è il seguente:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
È possibile usare le utilità del notebook MSSparkUtils per eseguire un notebook o uscire da un notebook con un valore . Usare il comando seguente per ottenere una panoramica dei metodi disponibili:
mssparkutils.notebook.help()
Ottenere i risultati:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Fare riferimento a un notebook
Fare riferimento a un notebook e restituirne il valore di uscita. È possibile eseguire chiamate di funzione di annidamento in un notebook in modo interattivo o in una pipeline. Il notebook a cui si fa riferimento verrà eseguito nel pool di Spark di cui il notebook chiama questa funzione.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Ad esempio:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
Al termine dell'esecuzione, verrà visualizzato un collegamento di snapshot denominato "Visualizza esecuzione notebook: Nome notebook" visualizzato nell'output della cella, è possibile fare clic sul collegamento per visualizzare lo snapshot per questa esecuzione specifica.
Uscire da un notebook
Chiude un notebook con un valore. È possibile eseguire chiamate di funzione di annidamento in un notebook in modo interattivo o in una pipeline.
Quando si chiama una funzione in
exit()modo interattivo, Azure Synapse genererà un'eccezione, ignora l'esecuzione di celle secondarie e mantiene attiva la sessione Spark.Quando si orchestra un notebook che chiama una
exit()funzione in una pipeline di Synapse, Azure Synapse restituirà un valore di uscita, completerà l'esecuzione della pipeline e arresterà la sessione Spark.Quando si chiama una
exit()funzione in un notebook a cui si fa riferimento, Azure Synapse interromperà l'ulteriore esecuzione nel notebook a cui si fa riferimento e continuerà a eseguire le celle successive nel notebook che chiamano larun()funzione. Ad esempio: Notebook1 ha tre celle e chiama unaexit()funzione nella seconda cella. Notebook2 ha cinque celle e chiamaterun(notebook1)nella terza cella. Quando si esegue Notebook2, Notebook1 verrà arrestato nella seconda cella quando si raggiunge laexit()funzione. Notebook2 continuerà a eseguire la quarta cella e la quinta cella.
mssparkutils.notebook.exit("value string")
Ad esempio:
Il notebook sample1 individua nella cartella/ con le due celle seguenti:
- la cella 1 definisce un parametro di input con valore predefinito impostato su 10.
- la cella 2 esce dal notebook con input come valore di uscita.
È possibile eseguire Sample1 in un altro notebook con i valori predefiniti:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Il risultato è il seguente:
Sample1 run success with input is 10
È possibile eseguire Sample1 in un altro notebook e impostare il valore di input su 20:
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
Il risultato è il seguente:
Sample1 run success with input is 20
Utilità delle credenziali
È possibile usare le utilità delle credenziali MSSparkUtils per ottenere i token di accesso dei servizi collegati e gestire i segreti in Azure Key Vault.
Usare il comando seguente per ottenere una panoramica dei metodi disponibili:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Ottenere il risultato:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Nota
Attualmente getSecretWithLS(linkedService, secret) non è supportato in C#.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Ottenere un token
Restituisce il token Microsoft Entra per un determinato gruppo di destinatari, nome (facoltativo). La tabella seguente elenca tutti i tipi di destinatari disponibili:
| Tipo di gruppo di destinatari | Valore letterale stringa da usare nella chiamata API |
|---|---|
| Archiviazione di Azure | Storage |
| Azure Key Vault (Archivio chiavi di Azure) | Vault |
| Gestione di Azure | AzureManagement |
| Azure SQL Data Warehouse (dedicato e serverless) | DW |
| Azure Synapse | Synapse |
| Azure Data Factory | ADF |
| Esplora dati di Azure | AzureDataExplorer |
| Database di Azure per MySQL | AzureOSSDB |
| Database di Azure per MariaDB | AzureOSSDB |
| Database di Azure per PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Convalidare il token
Restituisce true se il token non è scaduto.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Ottenere stringa di connessione o credenziali per il servizio collegato
Restituisce stringa di connessione o credenziali per il servizio collegato.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Ottenere un segreto usando l'identità dell'area di lavoro
Restituisce il segreto dell'insieme di credenziali delle chiavi di Azure per un determinato nome, nome segreto e nome del servizio collegato usando l'identità dell'area di lavoro. Assicurarsi di configurare l'accesso ad Azure Key Vault in modo appropriato.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Ottenere un segreto usando le credenziali utente
Restituisce il segreto di Azure Key Vault per un determinato nome, nome segreto e nome del servizio collegato di Azure Key Vault usando le credenziali utente.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Inserire un segreto usando l'identità dell'area di lavoro
Inserisce il segreto di Azure Key Vault per un determinato nome, nome segreto e nome del servizio collegato di Azure Key Vault usando l'identità dell'area di lavoro. Assicurarsi di configurare l'accesso ad Azure Key Vault in modo appropriato.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Inserire un segreto usando l'identità dell'area di lavoro
Inserisce il segreto di Azure Key Vault per un determinato nome, nome segreto e nome del servizio collegato di Azure Key Vault usando l'identità dell'area di lavoro. Assicurarsi di configurare l'accesso ad Azure Key Vault in modo appropriato.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Inserire un segreto usando l'identità dell'area di lavoro
Inserisce il segreto di Azure Key Vault per un determinato nome, nome segreto e nome del servizio collegato di Azure Key Vault usando l'identità dell'area di lavoro. Assicurarsi di configurare l'accesso ad Azure Key Vault in modo appropriato.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Inserire un segreto usando le credenziali utente
Inserisce il segreto di Azure Key Vault per un determinato nome, nome segreto e nome del servizio collegato di Azure Key Vault usando le credenziali utente.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Inserire un segreto usando le credenziali utente
Inserisce il segreto di Azure Key Vault per un determinato nome, nome segreto e nome del servizio collegato di Azure Key Vault usando le credenziali utente.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Inserire un segreto usando le credenziali utente
Inserisce il segreto di Azure Key Vault per un determinato nome, nome segreto e nome del servizio collegato di Azure Key Vault usando le credenziali utente.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Utilità dell'ambiente
Eseguire i comandi seguenti per ottenere una panoramica dei metodi disponibili:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Ottenere il risultato:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Ottenere il nome utente
Restituisce il nome utente corrente.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Ottenere l'ID utente
Restituisce l'ID utente corrente.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Ottenere l'ID processo
Restituisce l'ID processo.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Ottenere il nome dell'area di lavoro
Restituisce il nome dell'area di lavoro.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Ottenere il nome del pool
Restituisce il nome del pool di Spark.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Ottenere l'ID cluster
Restituisce l'ID cluster corrente.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Contesto di runtime
Mssparkutils runtime utils espone 3 proprietà di runtime, è possibile usare il contesto di runtime mssparkutils per ottenere le proprietà elencate di seguito:
- Notebookname : il nome del notebook corrente restituirà sempre il valore sia per la modalità interattiva che per la modalità pipeline.
- Pipelinejobid : l'ID di esecuzione della pipeline restituirà il valore in modalità pipeline e restituirà una stringa vuota in modalità interattiva.
- Activityrunid : l'ID di esecuzione dell'attività del notebook restituirà il valore in modalità pipeline e restituirà una stringa vuota in modalità interattiva.
Attualmente il contesto di runtime supporta sia Python che Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Gestione della sessione
Arrestare una sessione interattiva
Invece di fare clic manualmente sul pulsante Arresta, a volte è più pratico arrestare una sessione interattiva chiamando un'API nel codice. Per questi casi, viene fornita un'API mssparkutils.session.stop() per supportare l'arresto della sessione interattiva tramite codice, disponibile per Scala e Python.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() L'API arresterà la sessione interattiva corrente in modo asincrono in background, arresta la sessione Spark e rilascia le risorse occupate dalla sessione in modo che siano disponibili per altre sessioni nello stesso pool.
Nota
Non è consigliabile chiamare API predefinite del linguaggio come sys.exit in Scala o sys.exit() in Python nel codice, perché tali API uccidono semplicemente il processo dell'interprete, lasciando attiva la sessione spark e le risorse non rilasciate.
Dipendenze del pacchetto
Se si vogliono sviluppare notebook o processi in locale ed è necessario fare riferimento ai pacchetti pertinenti per gli hint di compilazione/IDE, è possibile usare i pacchetti seguenti.