Usare Pandas per leggere/scrivere dati di Azure Data Lake Storage Gen2 nel pool di Apache Spark serverless in Synapse Analytics
Informazioni su come usare Pandas per leggere/scrivere dati in Azure Data Lake Storage Gen2 (ADLS) usando un pool di Apache Spark serverless all’interno di Azure Synapse Analytics. Gli esempi in questa esercitazione illustrano come leggere i dati CSV con Pandas nei file Synapse, excel e parquet.
Questa esercitazione illustra come:
- Lettura/Scrittura di dati ADLS Gen2 con Pandas in una sessione Spark.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Area di lavoro di Azure Synapse Analytics con un account di archiviazione di Azure Data Lake Storage Gen2 configurato come risorsa archiviazione predefinita (o archiviazione primaria). È necessario essere il Collaboratore ai dati del BLOB della risorsa di archiviazione del file system di Data Lake Storage Gen2 con cui si lavora.
Un pool di Apache Spark serverless nell'area di lavoro di Azure Synapse Analytics. Per i dettagli, vedere Creare un pool di Spark in Azure Synapse.
Configurare l'account secondario di Azure Data Lake Storage Gen2 (che non è l'area di lavoro di Synapse per impostazione predefinita). È necessario essere il Collaboratore ai dati del BLOB della risorsa di archiviazione del file system di Data Lake Storage Gen2 con cui si lavora.
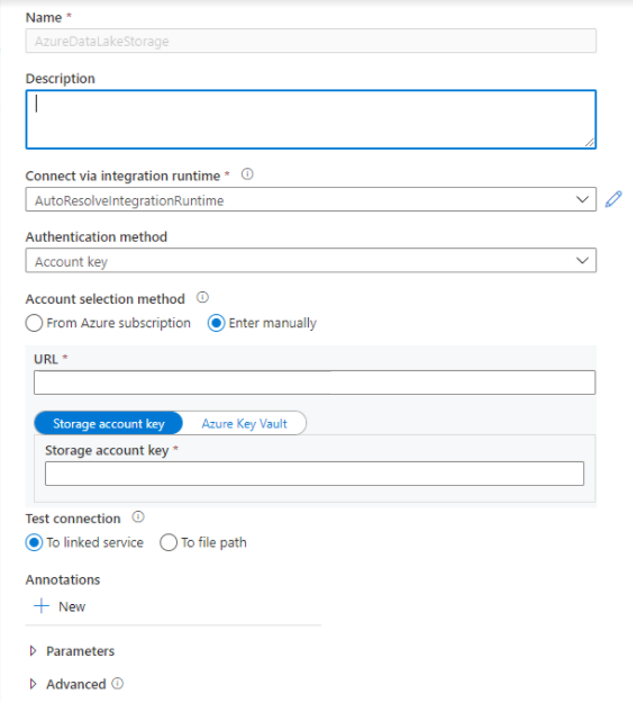
Crea servizi collegati - In Azure Synapse Analytics si usano i servizi collegati per definire le informazioni di connessione ad altri servizi. In questa esercitazione si aggiungerà un servizio collegato Azure Synapse Analytics e Azure Data Lake Storage Gen2.
- Aprire Azure Synapse Studio e selezionare la scheda Gestisci.
- In Connessioni esterne selezionare Servizi collegati.
- Per aggiungere un servizio collegato, selezionare Nuovo.
- Selezionare il riquadro Azure Data Lake Storage Gen2 nell'elenco e scegliere Continua.
- Immettere le credenziali di autenticazione. La chiave dell'account, l'entità servizio (SP), le credenziali e l'identità del servizio gestito sono attualmente tipi di autenticazione supportati. Assicurarsi che l'opzione Collaboratore ai dati del BLOB di archiviazione sia assegnata nell'archiviazione per SP e MSI prima di sceglierla per l'autenticazione. Connessione di test per verificare che le credenziali siano corrette. Selezionare Crea.
Importante
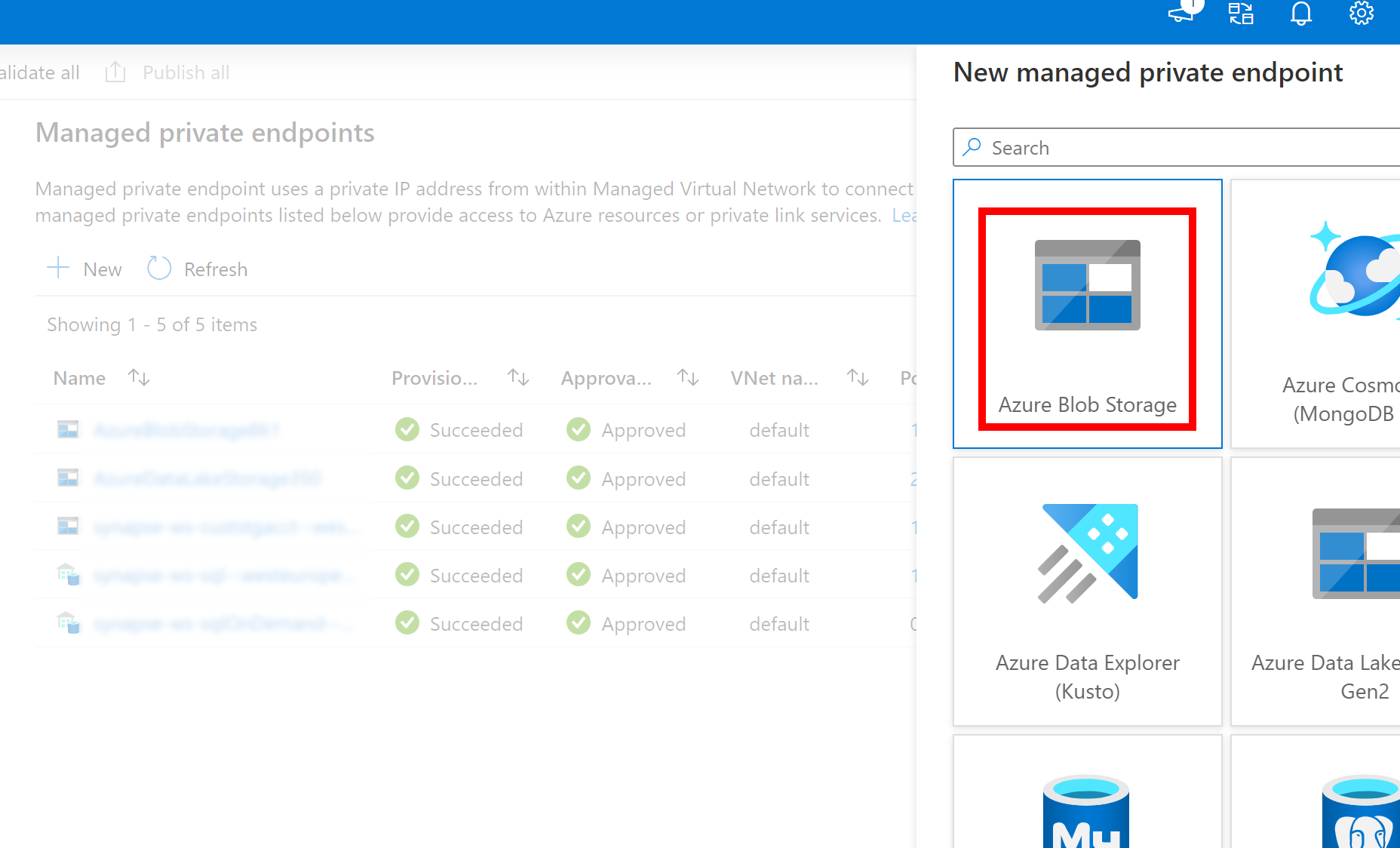
- Se il Servizio collegato creato in precedenza per Azure Data Lake Storage Gen2 usa un endpoint privato gestito (con un URI dfs), è necessario creare un altro endpoint privato gestito secondario usando l'opzione Archiviazione BLOB di Azure (con un URI BLOB), per assicurarsi che il codice fsspec/adlfs interno possa connettersi usando l'interfaccia BlobServiceClient.
- Nel caso in cui l'endpoint privato gestito secondario non sia configurato correttamente, verrà visualizzato un messaggio di errore simile a ServiceRequestError: Impossibile connettersi all'host [storageaccountname].blob.core.windows.net:443 ssl:True [Nome o servizio sconosciuto]
Nota
- La funzionalità Pandas è supportata in un pool di Apache Spark serverless Python 3.8 e Spark3 in Azure Synapse Analytics.
- Supporto disponibile per le versioni seguenti: pandas 1.2.3, fsspec 2021.10.0, adlfs 0.7.7
- Sono disponibili funzionalità per supportare l'URI di Azure Data Lake Storage Gen2 (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) e l'URL breve FSSPEC (abfs[s]://container_name/file_path).
Accedere al portale di Azure
Accedere al portale di Azure.
Lettura/Scrittura di dati nell'account di archiviazione ADLS predefinito dell'area di lavoro di Synapse
Pandas può leggere/scrivere dati ADLS specificando il percorso del file direttamente dall'archiviazione di ADLS Gen 2 predefinita .
Eseguire il codice seguente.
Nota
Aggiornare l'URL del file in questo script prima di eseguirlo.
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
Lettura/Scrittura di dati con l'account ADLS secondario
Pandas è in grado di leggere/scrivere dati di account ADLS secondari:
- utilizzando servizio collegato (con opzioni di autenticazione: chiave dell'account di archiviazione, entità servizio, identità di servizio gestita e credenziali).
- uso delle opzioni di archiviazione per passare direttamente ID client e segreto, chiave di firma di accesso condiviso, chiave dell'account di archiviazione e stringa di connessione.
Eseguire il codice seguente.
Nota
Aggiornare l'URL del file e il nome del servizio collegato in questo script prima di eseguirlo.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Esempio di lettura/scrittura di file Parquet
Eseguire il codice seguente.
Nota
Aggiornare l'URL del file in questo script prima di eseguirlo.
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Esempio di lettura/scrittura di file di Microsoft Excel
Eseguire il codice seguente.
Nota
Aggiornare l'URL del file in questo script prima di eseguirlo.
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')