Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Tip
Microsoft Fabric Data Warehouse è un data warehouse relazionale su scala aziendale su una base data lake, con un'architettura futura, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con il data warehousing, iniziare con Fabric Data Warehouse. I carichi di lavoro esistenti del pool SQL dedicated possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
In questa esercitazione si apprenderà come eseguire l'analisi esplorativa dei dati usando set di dati aperti esistenti, senza alcuna configurazione di archiviazione necessaria. Combini diversi set di dati aperti di Azure usando il pool SQL serverless. È quindi possibile visualizzare i risultati in Synapse Studio per Azure Synapse Analytics.
In questa esercitazione, tu:
- Accedere al pool SQL serverless predefinito
- Accedere ai set di dati aperti di Azure per usare i dati dell'esercitazione
- Eseguire l'analisi dei dati di base con SQL
Accedere al pool SQL serverless
Ogni area di lavoro include un pool SQL serverless preconfigurato da usare denominato Integrato. Per accedervi:
- Aprire l'area di lavoro e selezionare l'hub Sviluppo .
- Selezionare il +pulsante Aggiungi nuova risorsa ".
- Selezionare Script SQL.
È possibile usare questo script per esplorare i dati senza dover riservare capacità SQL.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Accedere ai dati del tutorial
Tutti i dati usati in questa esercitazione sono ospitati nell'account di archiviazione azureopendatastorage, che contiene set di dati aperti di Azure per l'uso aperto nelle esercitazioni come questa. È possibile eseguire tutti gli script così come sono direttamente dall'area di lavoro, purché l'area di lavoro possa accedere a una rete pubblica.
In questa esercitazione si usa un set di dati relativo alle corse dei taxi di New York City (NYC):
- Date e orari di ritiro e riconsegna
- Punti di ritiro e consegna
- Distanze dei viaggi
- Tariffe dettagliate
- Tipi di tariffa
- Tipi di pagamento
- Numero di passeggeri segnalato dall'autista
La funzione OPENROWSET(BULK...) consente di accedere ai file di Archiviazione di Azure.
[OPENROWSET](develop-openrowset.md) legge il contenuto di un'origine dati remota, ad esempio un file, e lo restituisce come set di righe.
Per acquisire familiarità con i dati dei taxi di NYC, eseguire la query seguente:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
Altri set di dati accessibili
Allo stesso modo, è possibile eseguire una query sul set di dati di festività pubbliche con la query seguente:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
È anche possibile eseguire una query sul set di dati relativi al meteo con la query seguente:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
Altre informazioni sul significato delle singole colonne sono disponibili nelle descrizioni dei set di dati:
Inferenza automatica dello schema
Poiché i dati vengono archiviati nel formato di file Parquet, è disponibile l'inferenza automatica dello schema. È possibile eseguire query sui dati senza elencare i tipi di dati di tutte le colonne nei file. È anche possibile usare il meccanismo delle colonne virtuali e la funzione filepath per filtrare un determinato sottoinsieme di file.
Nota
Le regole di confronto predefinite sono SQL_Latin1_General_CP1_CI_ASIf. Per regole di confronto non predefinite, tenere in considerazione la distinzione tra maiuscole e minuscole.
Se si crea un database con regole di confronto con distinzione tra maiuscole e minuscole quando si specificano le colonne, assicurarsi di usare il nome corretto della colonna.
Un nome di colonna tpepPickupDateTime è corretto, mentre tpeppickupdatetime non funziona in regole di confronto non predefinite.
Analisi delle serie temporali, della stagionalità e degli outlier
È possibile riepilogare il numero annuale di corse di taxi con la query seguente:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
Il frammento seguente mostra il risultato per il numero annuale di corse di taxi:

I dati possono essere visualizzati in Synapse Studio passando da una visualizzazione Tabella a una visualizzazione Grafico. È possibile scegliere tra diversi tipi di grafico, ad esempio ad area, a barre, istogramma, a linee, a torta e a dispersione. In questo caso, verrà tracciato un istogramma con la colonna Categoria impostata su current_year:

In questa visualizzazione è riportata una tendenza di numeri di corse in diminuzione nel corso degli anni. Presumibilmente, questo decremento è dovuto al recente aumento di popolarità delle aziende di ride-sharing.
Nota
Al momento della stesura di questa esercitazione, i dati per 2019 sono incompleti. Di conseguenza, si è verificato un enorme calo nel numero delle corse per quell'anno.
È possibile incentrare l'analisi su un singolo anno, ad esempio il 2016. La query seguente restituisce il conteggio giornaliero dei viaggi durante quell'anno.
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
Il frammento seguente mostra il risultato di questa query:

Anche in questo caso, è possibile visualizzare i dati tracciando l'istogramma con la colonna Categoria impostata su current_day e la colonna Legenda (serie) su rides_per_day.
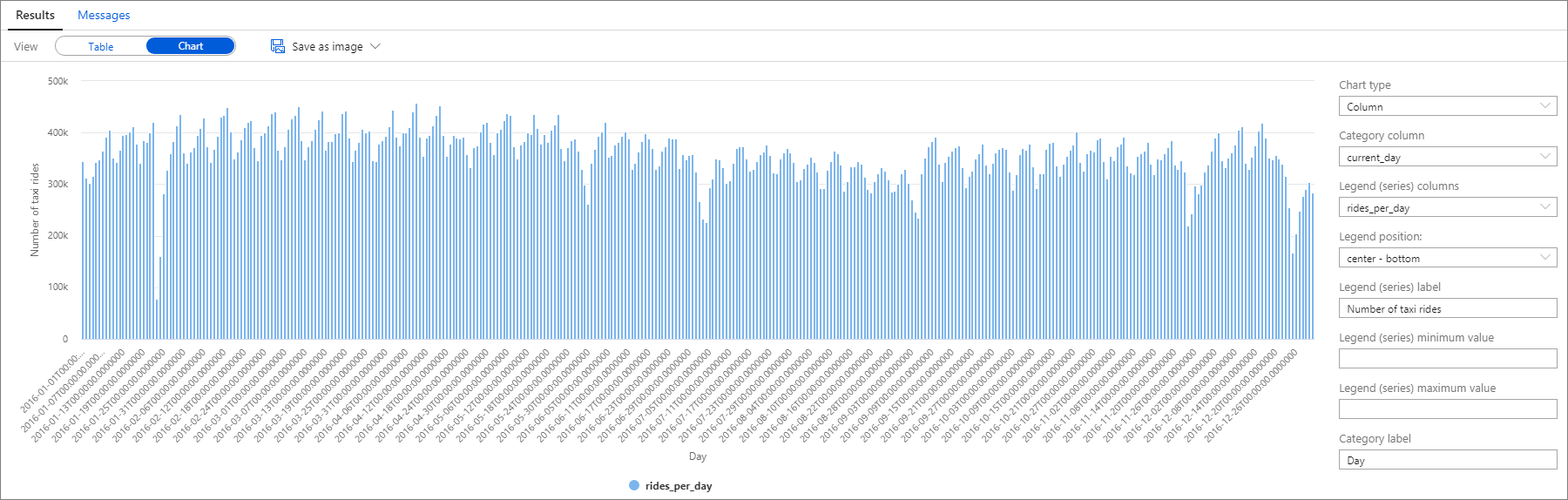
Dal grafico del tracciato si evince un modello settimanale, con il sabato come giorno di punta. Durante i mesi estivi, il numero di corse di taxi è inferiore a causa delle vacanze. Sono anche visibili anche alcuni cali significativi nel numero di corse di taxi senza un modello chiaro che evidenzi quando e perché si verificano.
Verrà ora illustrata la correlazione tra il calo del numero di corse e le festività pubbliche. Verificare se esiste una correlazione incrociando il set di dati delle corse dei taxi di NYC con quello delle festività pubbliche:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC

Evidenziare il numero di corse di taxi durante le festività pubbliche. A tale scopo, scegliere current_day per la colonna Categoria e rides_per_day e holiday_rides come colonne Legenda (serie).

Dal tracciato, si osserva che durante le festività pubbliche il numero di corse di taxi è inferiore. Il 23 gennaio si registra un importante calo inspiegabile. A questo punto, verrà controllato il meteo di New York per il giorno in questione tramite una query sul set di dati meteo:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

I risultati della query indicano che il calo del numero di corse di taxi è stato dovuto a:
- Quel giorno, c'è stata una bufera di neve a New York con circa 30 cm di neve.
- Una temperatura particolarmente fredda, inferiore a zero gradi Celsius.
- Un vento forte (circa 10 m/s).
Questa esercitazione ha illustrato in che modo un analista di dati può eseguire rapidamente analisi esplorative dei dati. È possibile combinare set di dati diversi usando il pool SQL serverless e visualizzare i risultati con Azure Synapse Studio.
Contenuto correlato
Per informazioni su come connettere il pool SQL serverless a Power BI Desktop e creare report, vedere l'articolo Connettere un pool SQL serverless a Power BI Desktop e creare report.
Per informazioni su come usare tabelle esterne nel pool SQL serverless, vedere Usare tabelle esterne con Synapse SQL