Volumi NFS v4.1 in Azure NetApp Files per SAP HANA
Azure NetApp Files fornisce condivisioni NFS native che è possibile usare per i volumi /hana/shared, /hana/data e /hana/log. Per usare le condivisioni NFS basate su Azure NetApp Files per i volumi/hana/data e /hana/log, è necessario il protocollo NFS v4.1. Se le condivisioni sono basate su Azure NetApp Files, l’uso del protocollo NFS v3 non è supportato per i volumi /hana/data e /hana/log.
Importante
L’uso protocollo NFS v3 implementato in Azure NetApp Files non è supportato per i volumi /hana/data e /hana/log. Da un punto di vista funzionale, per i volumi /hana/data e /hana/logè obbligatorio l’utilizzo del protocollo di NFS 4.1. Da un punto di vista funzionale, per il volume /hana/shared è invece possibile usare il protocollo NFS v3 o NFS v4.1.
Considerazioni importanti
Quando si prende in considerazione Azure NetApp Files per SAP NetWeaver e SAP HANA, tenere presente le considerazioni importanti seguenti:
Per i limiti del volume e del pool di capacità, vedere Limiti delle risorse di Azure NetApp Files.
Le condivisioni NFS basate su Azure NetApp Files e le macchine virtuali che montano tali condivisioni devono trovarsi nella stessa Rete virtuale di Azure o nelle reti virtuali con peering nella stessa area.
La rete virtuale selezionata deve avere una subnet delegata ad Azure NetApp Files. Per il carico di lavoro SAP, è consigliabile configurare un intervallo /25 per la subnet delegata ad Azure NetApp Files.
È importante che le macchine virtuali abbiano distribuito una sufficiente prossimità all'archiviazione di Azure NetApp per una latenza più bassa, ad esempio richiesta da SAP HANA per le scritture di log di rollforward.
- Azure NetApp Files offre nel frattempo funzionalità per distribuire volumi NFS in specifici zone di disponibilità di Azure. Tale prossimità di zona sarà sufficiente nella maggior parte dei casi per ottenere una latenza inferiore a 1 millisecondo. La funzionalità è disponibile in anteprima pubblica e descritta nell'articolo Gestire il posizionamento del volume della zona di disponibilità per Azure NetApp Files. Questa funzionalità non richiede alcun processo interattivo con Microsoft per raggiungere la prossimità tra la macchina virtuale e i volumi NFS allocati.
- Per ottenere la massima prossimità ottimale, è disponibile la funzionalità dei gruppi di volumi di applicazioni. Questa funzionalità non è solo alla ricerca della prossimità ottimale, ma per il posizionamento ottimale dei volumi NFS, in modo che i volumi di dati e di rollforward di HANA vengano gestiti da controller diversi. Lo svantaggio è che questo metodo richiede un processo interattivo con Microsoft per aggiungere le macchine virtuali.
Assicurarsi che la latenza dal server di database al volume di Azure NetApp Files sia misurata e inferiore a 1 millisecondo
La velocità effettiva di un volume di Azure NetApp è una funzione della quota del volume e del livello di servizio, come documentato in Livelli di servizio per Azure NetApp Files. Quando si ridimensionano i volumi di Azure NetApp di HANA, verificare che la velocità effettiva risultante soddisfi i requisiti di sistema HANA. In alternativa, prendere in considerazione l'uso di un pool di capacità QoS manuale in cui la capacità del volume e la velocità effettiva possono essere configurate e ridimensionate in modo indipendente (in questo documento sono riportati esempi specifici di SAP HANA
Provare a "consolidare" i volumi per ottenere prestazioni più elevate in un volume più grande, ad esempio usare un volume per /sapmnt, /usr/sap/trans, ... se possibile
Azure NetApp Files offre criteri di esportazione: è possibile controllare i client consentiti, il tipo di accesso, come ad esempio lettura e scrittura, sola lettura e così via.
L'ID utente per sidadm e l'ID gruppo per
sapsysnelle macchine virtuali devono corrispondere alla configurazione in Azure NetApp Files.Implementare i parametri del sistema operativo Linux indicati nella nota SAP 3024346
Importante
Per carichi di lavoro SAP HANA, è fondamentale una bassa latenza. Collaborare con il rappresentante Microsoft per assicurarsi che le macchine virtuali e i volumi Azure NetApp Files vengano distribuiti in prossimità.
Importante
Se si verifica una mancata corrispondenza tra l'ID utente per sidadm e l'ID gruppo per sapsys tra la macchina virtuale e la configurazione di Azure NetApp, le autorizzazioni per i file nei volumi Di Azure NetApp montate nella macchina virtuale verranno visualizzate come nobody. Assicurarsi di specificare l'ID utente corretto per sidadm e l'ID gruppo per sapsys quando si acquisisce un nuovo sistema in Azure NetApp Files.
Opzione di montaggio NCONNECT
Nconnect è un'opzione di montaggio per i volumi NFS ospitati in Azure NetApp Files che consente al client NFS di aprire più sessioni su un singolo volume NFS. L'uso di nconnect con un valore maggiore di 1 attiva anche il client NFS per l'uso di più sessioni RPC sul lato client (nel sistema operativo guest) per gestire il traffico tra il sistema operativo guest e i volumi NFS montati. L'utilizzo di più sessioni che gestiscono il traffico di un volume NFS, ma anche l'utilizzo di più sessioni RPC può gestire scenari di prestazioni e velocità effettiva come:
- Montaggio di più volumi NFS ospitati in Azure NetApp Files con livelli di servizio diversi in una macchina virtuale
- La velocità effettiva di scrittura massima per un volume e una singola sessione Linux è compresa tra 1,2 e 1,4 GB/s. La presenza di più sessioni su un volume NFS ospitato in Azure NetApp Files può aumentare la velocità effettiva
Per le versioni del sistema operativo Linux che supportano nconnect come opzione di montaggio e alcune importanti considerazioni sulla configurazione di nconnect, in particolare con endpoint server NFS diversi, leggere il documento Procedure consigliate per le opzioni di montaggio NFS linux per Azure NetApp Files.
Dimensionamento per il database HANA in Azure NetApp Files
La velocità effettiva di un volume di Azure NetApp è una funzione delle dimensioni del volume e del livello di servizio, come documentato in Livelli di servizio per Azure NetApp Files.
È importante comprendere che la relazione tra le prestazioni è la dimensione e che esistono limiti fisici per un endpoint di archiviazione del servizio. Ogni endpoint di archiviazione verrà inserito dinamicamente nella subnet delegata di Azure NetApp Files al momento della creazione del volume e riceverà un indirizzo IP. I volumi di Azure NetApp Files possono, a seconda della capacità disponibile e della logica di distribuzione, condividere un endpoint di archiviazione
La tabella seguente dimostra che potrebbe avere senso creare un volume "Standard" di grandi dimensioni per archiviare i backup e che non ha senso creare un volume "Ultra" maggiore di 12 TB perché la capacità massima della larghezza di banda fisica di un singolo volume verrebbe superata.
Se è necessaria più della velocità effettiva di scrittura massima per il volume /hana/data rispetto a una singola sessione Linux, è anche possibile usare il partizionamento del volume di dati SAP HANA come alternativa. Il partizionamento del volume di dati SAP HANA esegue lo striping dell'attività di I/O durante il ricaricamento dei dati o i punti di salvataggio HANA in più file di dati HANA che si trovano in più condivisioni NFS. Per altri dettagli sullo striping del volume di dati HANA, vedere gli articoli seguenti:
- Guida dell'amministratore di HANA
- Blog su SAP HANA - Partizionamento dei volumi di dati
- Nota SAP n. 2400005
- Nota SAP #2700123
| Dimensione | Velocità effettiva Standard | Velocità effettiva Premium | Velocità effettiva Ultra |
|---|---|---|---|
| 1 TB | 16 MB/sec | 64 MB/sec | 128 MB/sec |
| 2 TB | 32 MB/sec | 128 MB/sec | 256 MB/sec |
| 4 TB | 64 MB/sec | 256 MB/sec | 512 MB/sec |
| 10 TB | 160 MB/sec | 640 MB/sec | 1.280 MB/sec |
| 15 TB | 240 MB/sec | 960 MB/sec | 1.400 MB/sec1 |
| 20 TB | 320 MB/sec | 1.280 MB/sec | 1.400 MB/sec1 |
| 40 TB | 640 MB/sec | 1.400 MB/sec1 | 1.400 MB/sec1 |
1: limiti di velocità effettiva di lettura di scrittura o singola sessione (nel caso in cui l'opzione di montaggio NFS nconnect non venga usata)
È importante comprendere che i dati sono scritti nelle stesse unità SSD nel back-end di archiviazione. La quota di prestazioni del pool di capacità è stata creata per poter gestire l'ambiente. Gli indicatori KPI dell'archiviazione sono uguali per tutte le dimensioni del database HANA. In quasi tutti i casi, questo presupposto non rispecchia la realtà e le aspettative del cliente. Le dimensioni dei sistemi HANA non implicano necessariamente che un sistema di piccole dimensioni richiede una velocità effettiva di archiviazione ridotta e un sistema di grandi dimensioni richiede una velocità effettiva di archiviazione elevata. In genere, tuttavia, è possibile prevedere requisiti di velocità effettiva più elevati per le istanze di database HANA di dimensioni maggiori. A causa delle regole di dimensionamento di SAP per l'hardware sottostante, le istanze di HANA più grandi prevedono anche più risorse di CPU e un parallelismo superiore in attività come il caricamento dei dati dopo il riavvio di istanze. Di conseguenza, le dimensioni del volume devono essere adottate in base alle aspettative e ai requisiti dei clienti. e non basate unicamente sui requisiti di capacità.
Durante la progettazione dell'infrastruttura per SAP in Azure, è necessario tenere presente alcuni requisiti minimi di velocità effettiva di archiviazione (per i sistemi di produzione) da SAP. Questi requisiti si traducono in caratteristiche minime della velocità effettiva di:
| Tipo di volume e di I/O | Indicatore KPI minimo imposto da SAM | Livello di servizio Premium | Livello di servizio Ultra |
|---|---|---|---|
| Scrittura nel volume di log | 250 MB/sec | 4 TB | 2 TB |
| Scrittura nel volume di dati | 250 MB/sec | 4 TB | 2 TB |
| Lettura dal volume di dati | 400 MB/sec | 6,3 TB | 3,2 TB |
Poiché tutti e tre gli indicatore KPI sono obbligatori, il volume /hana/data deve essere dimensionato per la capacità più ampia, in modo da soddisfare i requisiti minimi di lettura. Se si usano pool di capacità QoS manuali, le dimensioni e la velocità effettiva dei volumi possono essere definite in modo indipendente. Poiché sia la capacità che la velocità effettiva vengono prelevate dallo stesso pool di capacità, il livello di servizio e le dimensioni del pool devono essere sufficientemente grandi per offrire le prestazioni totali (vedere l'esempio qui)
Per i sistemi HANA, che non richiedono una larghezza di banda elevata, la velocità effettiva del volume di Azure NetApp Files può essere ridotta in base a una dimensione di volume inferiore o, usando QoS manuale, regolando direttamente la velocità effettiva. Nel caso in cui un sistema HANA richieda una maggiore velocità effettiva, il volume potrebbe essere adattato ridimensionando la capacità online. Per i volumi di backup non sono definiti indicatori KPI. Tuttavia, la velocità effettiva del volume di backup è essenziale per un ambiente con prestazioni buone. Le prestazioni del volume di dati e di log devono essere progettate in base alle aspettative dei clienti.
Importante
Indipendentemente dalla capacità distribuita in un singolo volume NFS, la velocità effettiva dovrebbe raggiungere l'intervallo di larghezza di banda di 1,2-1,4 GB/sec utilizzata da un consumer in una singola sessione. Questa operazione ha a che fare con l'architettura sottostante dell'offerta Azure NetApp Files e i relativi limiti di sessione Linux per NFS. I numeri relativi a prestazioni e velocità effettiva, come documentato nell'articolo Risultati dei test di benchmark delle prestazioni per Azure NetApp Files sono stati eseguiti su un volume NFS condiviso con più macchine virtuali client e, di conseguenza, più sessioni. Questo scenario è diverso dallo scenario misurato in SAP in cui viene misurata la velocità effettiva da una singola macchina virtuale rispetto a un volume NFS ospitato in Azure NetApp Files.
Per soddisfare i requisiti di velocità effettiva minima di SAP per dati e log e in base alle linee guida per /hana/shared, le dimensioni consigliate sono le seguenti:
| Volume | Dimensione Livello Archiviazione Premium |
Dimensione Livello Archiviazione Ultra |
Protocollo NFS supportato |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6,3 TiB | 3,2 TiB | v4.1 |
| /hana/shared (aumento) | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | v3 o v4.1 |
| /hana/shared (ampliamento) | 1 x RAM del nodo di lavoro per quattro nodi di lavoro |
1 x RAM del nodo di lavoro per quattro nodi di lavoro |
v3 o v4.1 |
| /hana/logbackup | 3 RAM | 3 RAM | v3 o v4.1 |
| /hana/backup | 2 RAM | 2 RAM | v3 o v4.1 |
Per tutti i volumi, è consigliabile usare NFS v4.1.
Esaminare attentamente le considerazioni relative al dimensionamento di /hana/shared, in base alle dimensioni appropriate del volume /hana/shared contribuisce alla stabilità del sistema.
Le dimensioni per i volumi di backup sono stime. È necessario definire requisiti esatti in base ai processi di carichi di lavoro e operazioni. Per i backup, è possibile consolidare molti volumi per diverse istanze di SAP HANA in uno o due volumi più grandi, che potrebbero avere un livello di servizio inferiore di Azure NetApp Files.
Nota
Le raccomandazioni per il dimensionamento di Azure NetApp Files riportate in questo documento fanno riferimento ai requisiti minimi definiti da SAP per i provider di infrastruttura. Nelle distribuzioni reali dei clienti e negli scenari di carico di lavoro, questo potrebbe non essere sufficiente. Considerare quindi queste indicazioni come punto di inizio e adattarle in base ai requisiti del carico di lavoro specifico.
È pertanto possibile valutare la possibilità di distribuire una velocità effettiva simile per i volumi di Azure NetApp Files, come indicato per l'archiviazione su disco Ultra già. Prendere in considerazione anche le dimensioni elencate per i volumi per i diversi SKU di VM, come già fatto nelle tabelle del disco Ultra.
Suggerimento
È possibile ridimensionare i volumi Azure NetApp Files in modo dinamico, senza dover eseguire l'operazione unmount per i volumi, arrestare le macchine virtuali o SAP HANA. Questo consente la flessibilità di soddisfare le esigenze di velocità effettiva previste e non previste per le applicazioni.
La documentazione su come distribuire una configurazione con scalabilità orizzontale di SAP HANA con nodo standby usando i volumi NFS v4.1 basati su Azure NetApp Files viene pubblicata in SAP HANA scale-out con nodo standby in macchine virtuali di Azure con Azure NetApp Files in SUSE Linux Enterprise Server.
Impostazioni del kernel Linux
Per distribuire correttamente SAP HANA in Azure NetApp Files, è necessario implementare le impostazioni del kernel Linux in base alla nota SAP 3024346.
Per i sistemi che usano la disponibilità elevata usando pacemaker e Azure Load Balancer, è necessario implementare le impostazioni seguenti nel file /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
I sistemi in esecuzione senza pacemaker e Azure Load Balancer devono implementare queste impostazioni in /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Distribuzione con prossimità di zona
Per ottenere una prossimità di zona delle VM e dei volumi NFS, è possibile seguire le istruzioni descritte in Gestire il posizionamento dei volumi di zona di disponibilità per Azure NetApp Files. Con questo metodo, le VM e i volumi NFS si trovano nella stessa zona di disponibilità di Azure. Nella maggior parte delle aree di Azure questo tipo di prossimità deve essere sufficiente per ottenere una latenza inferiore a 1 millisecondo per le scritture di rollforward del log di rollforward per SAP HANA. Questo metodo non richiede alcun lavoro interattivo con Microsoft per la collocazione e l'aggiunta di VM in un data center specifico. Di conseguenza, è possibile modificare le dimensioni e le famiglie di VM all'interno di tutti i tipi e le famiglie di VM offerti nella zona di disponibilità distribuita. Pertanto, è possibile reagire in modo flessibile in condizioni di chanign o spostarsi più velocemente in dimensioni o famiglie di macchine virtuali più convenienti. È consigliabile usare questo metodo per sistemi non di produzione e sistemi di produzione che possono funzionare con latenze di log di rollforward che sono più vicine a 1 millisecondo. La funzionalità attualmente è in anteprima pubblica.
Distribuzione tramite il gruppo di volumi di applicazioni (AVG) di Azure NetApp Files per SAP HANA
Per distribuire volumi di Azure NetApp Files con prossimità alla macchina virtuale, è stata sviluppata una nuova funzionalità denominata gruppo di volumi di applicazioni di Azure NetApp Files per SAP HANA (AVG). È disponibile una serie di articoli che documentano la funzionalità. È consigliabile iniziare con l'articolo Informazioni sul gruppo di volumi di applicazioni di Azure NetApp Files per SAP HANA. Durante la lettura degli articoli, diventa chiaro che l'uso di AVG comporta anche l'uso di gruppi di posizionamento di prossimità di Azure. I gruppi di posizionamento di prossimità vengono usati dalla nuova funzionalità per il collegamento ai volumi che vengono creati. Per garantire che nel corso della durata del sistema HANA, le macchine virtuali non verranno spostate dai volumi di Azure NetApp Files, è consigliabile usare una combinazione di Avset/PPG per ognuna delle zone in cui si esegue la distribuzione. L'ordine di distribuzione sarà simile al seguente:
- Usando il modulo, è necessario richiedere l'aggiunta dell'AvSet vuoto a un HW di calcolo per assicurarsi che le VM non vengano spostate
- Assegnare un PPG al set di disponibilità e avviare una VM assegnata a tale set di disponibilità
- Usare il gruppo di volumi dell'applicazione Azure NetApp Files per la funzionalità SAP HANA per distribuire i volumi HANA
La configurazione del gruppo di posizionamento di prossimità per l'uso di AVG in modo ottimale sarà simile alla seguente:
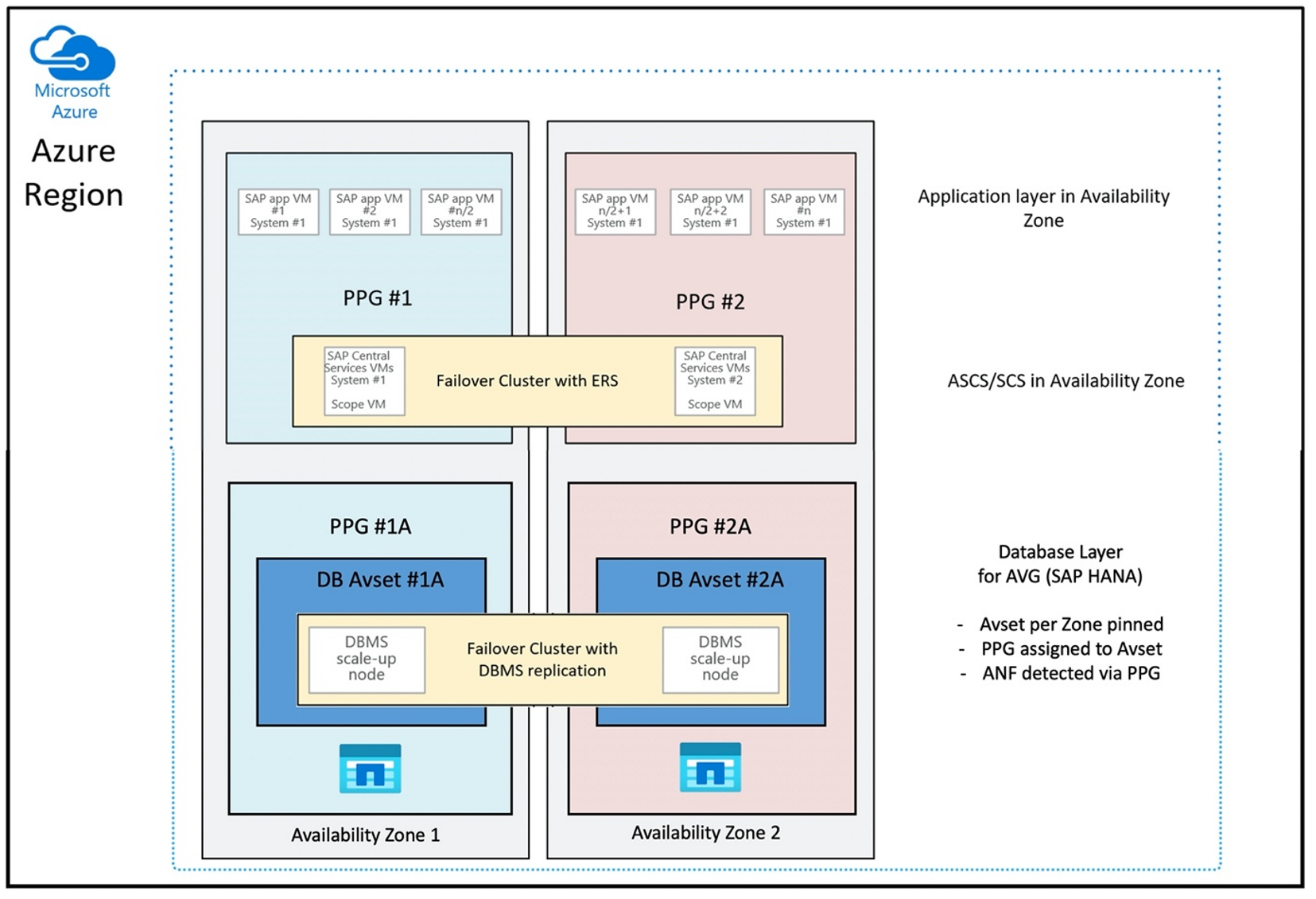
Il diagramma mostra che si userà un gruppo di posizionamento di prossimità di Azure per il livello DBMS. In tal modo, può essere usato insieme agli AVG. È consigliabile includere solo le macchine virtuali che eseguono le istanze HANA nel gruppo di posizionamento di prossimità. Il gruppo di posizionamento di prossimità è necessario, anche se viene usata una sola macchina virtuale con una singola istanza HANA, affinché avg identifichi la prossimità più vicina dell'hardware di Azure NetApp Files. E per allocare il volume NFS in Azure NetApp Files il più vicino possibile alle macchine virtuali che usano i volumi NFS.
Questo metodo genera risultati ottimali in relazione alla bassa latenza. Non solo avvicinando più possibile i volumi NFS e le VM virtuali. Tuttavia, vengono effettuate anche considerazioni relative alla collocazione di dati e volumi redo log in controller diversi nel back-end NetApp. Lo svantaggio, tuttavia, consiste nel fatto che la distribuzione delle VM viene aggiunta a un solo data center. In tal modo, si perde la flessibilità nella modifica dei tipi e delle famiglie di VM. Di conseguenza, è consigliabile limitare questo metodo ai sistemi che richiedono imprescindibilmente una latenza di archiviazione così bassa. Per tutti gli altri sistemi, è consigliabile tentare la distribuzione con una distribuzione di zona tradizionale della macchina virtuale e di Azure NetApp Files. Nella maggior parte dei casi questo è sufficiente in termini di bassa latenza. In questo modo si garantisce anche una manutenzione e un'amministrazione semplificate della macchina virtuale e di Azure NetApp Files.
Disponibilità
Gli aggiornamenti e gli upgrade del sistema ANF vengono applicati senza impatto sull'ambiente del cliente. Il contratto di servizio definito è 99,99%.
Volumi e indirizzi IP e pool di capacità
Con ANF, è importante comprendere come viene generata l'infrastruttura sottostante. Un pool di capacità è solo un costrutto che fornisce un budget di capacità e prestazioni e un'unità di fatturazione in base al livello di servizio del pool di capacità. Un pool di capacità non ha alcuna relazione fisica con l'infrastruttura sottostante. Quando si crea un volume nel servizio, viene creato un endpoint di archiviazione. A questo endpoint di archiviazione viene assegnato un singolo indirizzo IP per fornire l'accesso ai dati al volume. Se si creano diversi volumi, tutti i volumi vengono distribuiti tra la flotta bare metal sottostante associata a questo endpoint di archiviazione. ANF ha una logica che distribuisce automaticamente i carichi di lavoro dei clienti una volta che i volumi o/e la capacità dell'archiviazione configurata raggiungono un livello predefinito interno. È possibile notare questi casi perché un nuovo endpoint di archiviazione, con un nuovo indirizzo IP, viene creato automaticamente per accedere ai volumi. Il servizio ANF non fornisce il controllo del cliente su questa logica di distribuzione.
Volume di log e volume di backup del log
Il "volume di log" (/hana/log) viene usato per scrivere il log di rollforward online. Pertanto, ci sono file aperti che si trovano in questo volume e non ha senso creare uno snapshot di questo volume. I file di log di rollforward online vengono archiviati o sottoposti a backup nel volume di backup del log dopo che il file di log di rollforward online è pieno o viene eseguito un backup del log di rollforward. Per garantire prestazioni di backup ragionevoli, il volume di backup del log richiede una buona velocità effettiva. Per ottimizzare i costi di archiviazione, può essere utile consolidare il volume di backup del log di più istanze HANA. In questo modo più istanze di HANA usano lo stesso volume e scrivono i backup in directory diverse. Usando un consolidamento di questo tipo, è possibile ottenere una maggiore velocità effettiva perché è necessario aumentare il volume.
Lo stesso vale per il volume in cui si usano backup completi del database HANA in scrittura.
Backup
Oltre ai backup di streaming e al servizio Back di Azure che esegue il backup di database SAP HANA, come descritto nell'articolo Guida al backup per SAP HANA in Azure Macchine virtuali, Azure NetApp Files apre la possibilità di eseguire backup snapshot basati sull'archiviazione.
SAP HANA supporta:
- Supporto del backup di snapshot basato sull'archiviazione per un singolo sistema di contenitori con SAP HANA 1.0 SPS7 e versioni successive
- Supporto del backup di snapshot basato sull'archiviazione per ambienti HANA multi-database (MDC) con un singolo tenant con SAP HANA 2.0 SPS1 e versioni successive
- Supporto del backup di snapshot basato sull'archiviazione per ambienti HANA multi-database (MDC) con più tenant con SAP HANA 2.0 SPS4 e versioni successive
La creazione di backup snapshot basati sull'archiviazione è una semplice procedura in quattro passaggi,
- Creazione di uno snapshot del database HANA (interno): un'attività che è necessario eseguire
- SAP HANA scrive i dati nei file di dati per creare uno stato coerente nell'archiviazione: HANA esegue questo passaggio in seguito alla creazione di uno snapshot HANA
- Creare uno snapshot nel volume /hana/data nella risorsa di archiviazione. È necessario eseguire un passaggio o strumenti. Non è necessario eseguire uno snapshot nel volume /hana/log
- Eliminare lo snapshot del database HANA (interno) e riprendere il normale funzionamento: un passaggio da eseguire
Avviso
Manca l'ultimo passaggio o non riesce a eseguire l'ultimo passaggio ha un impatto grave sulla domanda di memoria di SAP HANA e può causare un arresto di SAP HANA
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Questa procedura di backup dello snapshot può essere gestita in vari modi, usando vari strumenti. Un esempio è lo script Python "ntaphana_azure.py" disponibile in GitHub https://github.com/netapp/ntaphana Questo è il codice di esempio, fornito "così come è" senza manutenzione o supporto.
Attenzione
Uno snapshot in sé non è un backup protetto perché si trova nella stessa risorsa di archiviazione fisica del volume di cui è stato appena creato uno snapshot. È obbligatorio "proteggere" almeno uno snapshot al giorno in una posizione diversa. Questa operazione può essere eseguita nello stesso ambiente, in un'area di Azure remota o in Archiviazione BLOB di Azure.
Soluzioni disponibili per il backup coerente con l'applicazione basata su snapshot di archiviazione:
- Microsoft What is app Azure lication Consistent Snapshot tool è uno strumento da riga di comando che consente la protezione dei dati per i database di terze parti. Gestisce tutte le orchestrazioni necessarie per inserire i database in uno stato coerente con l'applicazione prima di acquisire uno snapshot di archiviazione. Dopo l'acquisizione dello snapshot di archiviazione, lo strumento restituisce i database a uno stato operativo. AzAcSnap supporta i backup basati su snapshot per istanze Large di HANA e Azure NetApp Files. Per altre informazioni, vedere l'articolo Che cos'è app Azure strumento snapshot coerente con la app Azure
- Per gli utenti dei prodotti di backup Commvault, un'altra opzione è Commvault IntelliSnap V.11.21 e versioni successive. Questa o versioni successive di Commvault offrono supporto per gli snapshot di Azure NetApp Files. L'articolo Commvault IntelliSnap 11.21 fornisce altre informazioni.
Eseguire il backup dello snapshot usando l'archiviazione BLOB di Azure
Il backup nell'archiviazione BLOB di Azure è un metodo conveniente e rapido per risparmiare backup di snapshot di archiviazione del database HANA basati su ANF. Per salvare gli snapshot nell'archivio BLOB di Azure, è preferibile usare lo strumento AzCopy. Scaricare la versione più recente di questo strumento e installarla, ad esempio, nella directory bin in cui è installato lo script Python da GitHub. Scaricare lo strumento AzCopy più recente:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
La funzionalità più avanzata è l'opzione SYNC. Se si usa l'opzione SYNC, azcopy mantiene sincronizzata l'origine e la directory di destinazione. L'utilizzo del parametro --delete-destination è importante. Senza questo parametro, azcopy non elimina i file nel sito di destinazione e l'utilizzo dello spazio sul lato di destinazione aumenta. Creare un contenitore BLOB in blocchi nell'account di archiviazione di Azure. Creare quindi la chiave di firma di accesso condiviso per il contenitore BLOB e sincronizzare la cartella snapshot con il contenitore BLOB di Azure.
Ad esempio, se uno snapshot giornaliero deve essere sincronizzato con il contenitore BLOB di Azure per proteggere i dati. E solo uno snapshot deve essere mantenuto, è possibile usare il comando seguente.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Passaggi successivi
Leggi l'articolo: