Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come eseguire il debug di un'applicazione che usa C++ Accelerated Massive Parallelism (C++ AMP) per sfruttare i vantaggi dell'unità di elaborazione grafica (GPU). Usa un programma di riduzione parallela che somma una matrice di numeri interi di grandi dimensioni. In questa procedura dettagliata sono illustrate le seguenti attività:
- Avvio del debugger GPU.
- Ispezione dei thread GPU nella finestra Thread GPU.
- Uso della finestra Parallel Stacks per osservare contemporaneamente gli stack di chiamate di più thread GPU.
- Utilizzare la finestra Parallel Watch per ispezionare i valori di una singola espressione tra più thread contemporaneamente.
- Segnalazione, blocco, scongelamento e raggruppamento di thread GPU.
- Esecuzione di tutti i thread di un riquadro in una posizione specifica nel codice.
Prerequisiti
Prima di iniziare questa procedura dettagliata:
Annotazioni
Le intestazioni C++ AMP sono deprecate a partire da Visual Studio 2022 versione 17.0.
L'inclusione di eventuali intestazioni AMP genererà errori di compilazione. Definire _SILENCE_AMP_DEPRECATION_WARNINGS prima di includere eventuali intestazioni AMP per disattivare gli avvisi.
- Leggere la Panoramica di C++ AMP.
- Assicurarsi che i numeri di riga vengano visualizzati nell'editor di testo. Per altre informazioni, vedere Procedura: Visualizzare i numeri di riga nell'editor.
- Assicurarsi di eseguire almeno Windows 8 o Windows Server 2012 per supportare il debug nell'emulatore software.
Annotazioni
I nomi o i percorsi visualizzati per alcuni elementi dell'interfaccia utente di Visual Studio nelle istruzioni seguenti potrebbero essere diversi nel computer in uso. L'edizione di Visual Studio disponibile e le impostazioni usate determinano questi elementi. Per altre informazioni, vedere Personalizzazione dell'IDE.
Per creare il progetto di esempio
Le istruzioni per la creazione di un progetto variano a seconda della versione di Visual Studio in uso. Assicurarsi di avere selezionato la versione corretta della documentazione sopra il sommario in questa pagina.
Per creare il progetto di esempio in Visual Studio
Sulla barra dei menu scegliere File>Nuovo>Progetto per aprire la finestra di dialogo Crea nuovo progetto.
Nella parte superiore della finestra di dialogo impostare Linguaggio su C++ , impostare Piattaforma su Windows e impostare Tipo di progetto su Console.
Nell'elenco filtrato dei tipi di progetto scegliere App console e quindi scegliere Avanti. Nella pagina successiva immettere
AMPMapReducenella casella Nome per specificare un nome per il progetto e specificare il percorso del progetto se ne vuole uno diverso.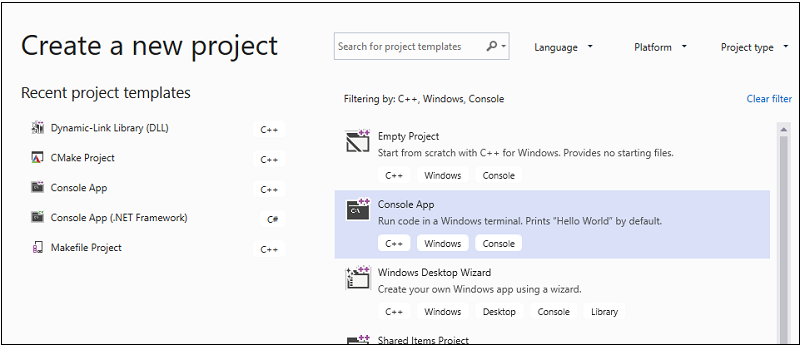
Scegliere il pulsante Crea per creare il progetto client.
Successivo:
Aprire AMPMapReduce.cpp e sostituirne il contenuto con il codice seguente.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }Sulla barra dei menu scegliere File>Salva tutto.
In Esplora soluzioni aprire il menu di scelta rapida per AMPMapReduce e quindi scegliere Proprietà.
Nella finestra di dialogo Pagine delle proprietà, in Proprietà di configurazione, scegliere C/C++>Intestazioni precompilate.
Per la proprietà Intestazione precompilata, selezionare Not Using Precompiled Headers (Non utilizzare intestazioni precompilate) e quindi scegliere il pulsante OK.
Nella barra dei menu scegliere Compila>Compila soluzione.
Debug del codice della CPU
In questa procedura si userà il debugger Windows locale per assicurarsi che il codice della CPU in questa applicazione sia corretto. Il segmento particolarmente interessante del codice della CPU in questa applicazione è il ciclo for nella funzione reduction_sum_gpu_kernel. Controlla la riduzione parallela basata su albero eseguita sulla GPU.
Per eseguire il debug del codice della CPU
In Esplora soluzioni aprire il menu di scelta rapida per AMPMapReduce e quindi scegliere Proprietà.
Nella finestra di dialogo Pagine delle proprietà, in Proprietà di configurazione, scegliere Debugging. Verificare che Debugger Windows locale sia selezionato nell'elenco Debugger per l'avvio.
Torna all'Editor del codice.
Impostare punti di interruzione sulle righe di codice illustrate nella figura seguente (circa le righe 67 riga 70).

Punti di interruzione CPUSulla barra dei menu scegliere Debug>Avvia debug.
Nella finestra Variabili locali osservare il valore per
stride_sizefinché non viene raggiunto il punto di interruzione alla riga 70.Sulla barra dei menu scegliere Debug>Termina debug.
Debug del codice GPU
Questa sezione illustra come eseguire il debug del codice GPU, ovvero il codice contenuto nella sum_kernel_tiled funzione. Il codice GPU calcola la somma di interi per ogni "blocco" in parallelo.
Per eseguire il debug del codice GPU
In Esplora soluzioni aprire il menu di scelta rapida per AMPMapReduce e quindi scegliere Proprietà.
Nella finestra di dialogo Pagine delle proprietà, in Proprietà di configurazione, scegliere Debugging.
Nell'elenco Debugger da avviare selezionare Debugger Windows locale.
Nell'elenco Tipo di debugger, verificare che Auto sia selezionato.
Auto è il valore predefinito. Nelle versioni precedenti a Windows 10, solo GPU è il valore richiesto anziché Auto.
Scegli il pulsante OK.
Impostare un punto di interruzione alla riga 30, come illustrato nella figura seguente.

Punto di interruzione GPUSulla barra dei menu scegliere Debug>Avvia debug. I punti di interruzione nel codice della CPU alle righe 67 e 70 non vengono eseguiti durante il debug GPU perché tali righe di codice vengono eseguite sulla CPU.
Per usare la finestra Thread della GPU
Per aprire la finestra Thread GPU, nella barra dei menu, scegliere Debug>Windows>Thread GPU.
È possibile esaminare lo stato dei thread GPU nella finestra Thread GPU visualizzata.
Ancorare la finestra dei Thread GPU nella parte inferiore di Visual Studio. Scegliere il pulsante Expand Thread Switch per visualizzare le caselle di testo del riquadro e del thread. La finestra Thread GPU mostra il numero totale di thread GPU attivi e bloccati, come illustrato nella figura seguente.

la Finestra Thread GPU313 riquadri vengono allocati per questo calcolo. Ogni riquadro contiene 32 thread. Poiché il debug GPU locale si verifica in un emulatore software, sono presenti quattro thread GPU attivi. I quattro thread eseguono le istruzioni contemporaneamente e quindi passano insieme all'istruzione successiva.
Nella finestra Thread GPU sono presenti quattro thread GPU attivi e 28 thread GPU bloccati nell'istruzione tile_barrier::wait definita alla riga 21, (
t_idx.barrier.wait();). Tutti i 32 thread GPU appartengono al primo riquadro,tile[0]. Una freccia punta alla riga che include il thread corrente. Per passare a un thread diverso, usare uno dei metodi seguenti:Nella riga del thread a cui passare nella finestra Thread GPU, aprire il menu di scelta rapida e scegliere Passa al thread. Se la riga rappresenta più thread, si passerà al primo thread in base alle coordinate del thread.
Immettere i valori di piastrella e thread nelle caselle di testo corrispondenti e quindi scegliere il pulsante Cambia thread.
Nella finestra Stack di Chiamate viene visualizzato lo stack di chiamate del thread GPU corrente.
Per usare la finestra Stack Paralleli
Per aprire la finestra Stack paralleli, nella barra dei menu, scegliere Debug>Windows>Stack paralleli.
È possibile usare la finestra Stack paralleli per esaminare contemporaneamente gli stack frame di più thread GPU.
Ancorare la finestra Stack paralleli nella parte inferiore di Visual Studio.
Assicurarsi che Threads sia selezionato nell'elenco nell'angolo superiore sinistro. Nell'illustrazione seguente, la finestra Stack Paralleli mostra una visualizzazione incentrata sullo stack di chiamate dei thread GPU che hai visto nella finestra Thread GPU.

Finestra Stack in parallelo32 thread sono passati dall'istruzione
_kernel_stublambda nella chiamata di funzioneparallel_for_eache quindi alla funzionesum_kernel_tiled, in cui si verifica la riduzione parallela. 28 thread su 32 sono progrediti fino all'istruzionetile_barrier::waite rimangono bloccati sulla riga 22, mentre gli altri quattro thread rimangono attivi nella funzionesum_kernel_tiledsulla riga 30.È possibile esaminare le proprietà di un thread GPU. Sono disponibili nella finestra GPU Threads nella finestra Ricca DataTip della finestra Parallel Stacks. Per visualizzarli, posizionare il puntatore sul frame dello stack di
sum_kernel_tiled. Nella figura seguente viene illustrato il DataTip.
Descrizione dati thread GPUPer altre informazioni sulla Finestra Stack Paralleli, vedere Uso della Finestra Stack Paralleli.
Per usare la finestra Watch parallelo
Per aprire la finestra Osservazione Parallela, nella barra dei menu scegliere Debug>Windows>Osservazione Parallela>Osservazione Parallela 1.
È possibile usare la Finestra Controllo Parallelo per esaminare i valori di un'espressione in più thread.
Ancorare la finestra Watch parallelo 1 nella parte inferiore di Visual Studio. Nella tabella della finestra Orologio parallelo sono presenti 32 righe. Ognuno corrisponde a un thread GPU visualizzato sia nella finestra Thread GPU che nella finestra Stack paralleli . È ora possibile immettere espressioni i cui valori si desidera esaminare in tutti i 32 thread GPU.
Selezionare l'intestazione Aggiungi Watch, immettere
localIdx, e quindi premere INVIO.Selezionare di nuovo l'intestazione Aggiungi monitor, digitare
globalIdx, e quindi scegliere il tasto Invio.Selezionare di nuovo l'intestazione Aggiungi monitor, digitare
localA[localIdx[0]], e quindi scegliere il tasto Invio.È possibile ordinare in base a un'espressione specificata selezionando l'intestazione di colonna corrispondente.
Selezionare l'intestazione di colonna localA[localIdx[0]] per ordinare la colonna. La figura seguente mostra i risultati dell'ordinamento in base a localA[localIdx[0]].

Risultati ordinamentoÈ possibile esportare il contenuto nella finestra Parallel Watch in Excel scegliendo il pulsante Excel e quindi scegliendo Apri in Excel. Se Excel è installato nel computer di sviluppo, il pulsante apre un foglio di lavoro di Excel che contiene il contenuto.
Nell'angolo superiore destro della finestra Parallel Watch c'è un controllo filtro per usare espressioni booleane e filtrare il contenuto. Immettere
localA[localIdx[0]] > 20000nella casella di testo del controllo filtro e quindi premere il tasto Invio.La finestra contiene ora solo thread su cui il
localA[localIdx[0]]valore è maggiore di 20000. Il contenuto è ancora ordinato in base allalocalA[localIdx[0]]colonna, ovvero l'azione di ordinamento scelta in precedenza.
Contrassegno dei thread GPU
È possibile contrassegnare thread GPU specifici in modo da contrassegnarli nella finestra Thread GPU, nella finestra Osservazione Parallela o nel DataTip nella finestra Stack Paralleli. Se una riga nella finestra Thread GPU contiene più di un thread, contrassegnare quella riga contrassegna tutti i thread contenuti al suo interno.
Per contrassegnare i thread GPU
Selezionare l'intestazione di colonna [Thread] nella finestra Osservazione Parallela 1 per ordinare in base all'indice del riquadro e all'indice del thread.
Sulla barra dei menu scegliere Debug>continua, che determina l'avanzamento dei quattro thread attivi fino alla barriera successiva (definita alla riga 32 di AMPMapReduce.cpp).
Scegliere il simbolo del flag sul lato sinistro della riga che contiene i quattro thread che sono ora attivi.
La figura seguente mostra i quattro thread contrassegnati attivi nella finestra Thread GPU.
Finestra Thread GPU con thread contrassegnati.
Thread attivi nella finestra Thread GPULa finestra Monitoraggio Parallelo e il DataTip della finestra Stack Paralleli indicano entrambi i thread contrassegnati.
Se si desidera concentrarsi sui quattro thread contrassegnati, è possibile scegliere di visualizzare solo i thread contrassegnati. Limita gli elementi visualizzati nelle finestre Thread GPU, Monitoraggio parallelo e Stack paralleli.
Scegliere il pulsante Mostra solo contrassegnati in una delle finestre o sulla barra degli strumenti Posizione di Debug. La figura seguente mostra il pulsante Mostra solo contrassegnati sulla barra degli strumenti Posizione di Debug.

Pulsante Mostra solo contrassegnatiOra le finestre Thread GPU, Osservazione parallela e Stack parallelo visualizzano solo i thread contrassegnati.
Blocco e scongelamento di thread GPU
È possibile bloccare (sospendere) e riprendere i thread della GPU dalla finestra Thread della GPU o dalla finestra di controllo parallelismo. È possibile bloccare e scongelare i thread della CPU nello stesso modo; per informazioni, vedere Procedura: Usare la finestra Thread.
Per congelare e scongelare i thread GPU
Scegliere il pulsante Mostra solo i contrassegnati per visualizzare tutti i thread.
Sulla barra dei menu scegliere Debug>Continua.
Aprire il menu di scelta rapida per la riga attiva e quindi scegliere Blocca.
La seguente illustrazione della finestra Thread GPU mostra che tutti e quattro i thread sono bloccati.

Thread bloccati nella finestra dei Thread della GPUAnalogamente, la finestra Osservazione parallela mostra che tutti e quattro i thread risultano bloccati.
Sulla barra dei menu scegliere Debug>Continua per consentire ai quattro thread GPU successivi di andare oltre la barriera alla riga 22 e di raggiungere il punto di interruzione alla riga 30. La finestra GPU Threads mostra che i quattro thread precedentemente congelati rimangono congelati, restando attivi.
Sulla barra dei menu scegliere Debug, Continua.
Nella finestra Parallel Watch è anche possibile scongelare singoli o più thread GPU.
Per raggruppare i thread della GPU
Nel menu di scelta rapida per uno dei thread nella finestra Thread GPU scegliere Raggruppa per, Indirizzo.
I thread nella finestra Thread GPU vengono raggruppati in base all'indirizzo. L'indirizzo corrisponde all'istruzione in disassembly in cui si trova ogni gruppo di thread. 24 thread si trovano alla riga 22 in cui viene eseguito il metodo tile_barrier::wait. 12 thread sono all'istruzione per la barriera alla riga 32. Quattro di questi thread vengono contrassegnati. Otto thread si trovano nel punto di interruzione alla riga 30. Quattro di questi thread sono congelati. La figura seguente mostra i thread raggruppati nella finestra Thread GPU.

Thread raggruppati nella finestra Thread GPUÈ anche possibile eseguire l'operazione Raggruppa per aprendo il menu di scelta rapida per la griglia dei dati della finestra Parallel Watch. Selezionare Raggruppa per e quindi scegliere la voce di menu corrispondente alla modalità di raggruppamento dei thread.
Esecuzione di tutti i thread in una posizione specifica nel codice
Tutti i thread in un determinato riquadro vengono eseguiti fino alla riga che contiene il cursore usando Esegui riquadro corrente fino al cursore.
Per eseguire tutti i thread nella posizione contrassegnata dal cursore
Nel menu di scelta rapida per i thread bloccati, scegliere Scongela.
Nell'editor di codice inserire il cursore nella riga 30.
Nel menu di scelta rapida dell'Editor del codice, scegliere Esegui il riquadro corrente fino al cursore.
I 24 thread precedentemente bloccati alla barriera alla linea 21 sono passati alla riga 32. È visualizzato nella finestra GPU Threads.
Vedere anche
Panoramica di C++ AMP
Debug del codice GPU
Procedura: Usare la finestra Thread GPU
Procedura: Usare la finestra di monitoraggio parallelo
Analisi del codice AMP C++ con il visualizzatore di concorrenza